오늘의 학습 리스트
- 는 변수가 많아지면 높아질 수 있다.
- 예를 들어, feature 수가 13개일 때랑
PolynomialFeatures()를 사용해서 feature 수가 105개 됐을 때 Linear Regression으로 학습 및 예측한 것에 대한 를 구하면 40%대와 80%대로 월등히 차이난다. - 그런데 이는 훈련 데이터셋이 그만큼 좋아졌다고 조금은 볼 수 있지만, 아래의 조정된 수식을 사용하면 얘기가 달라진다.
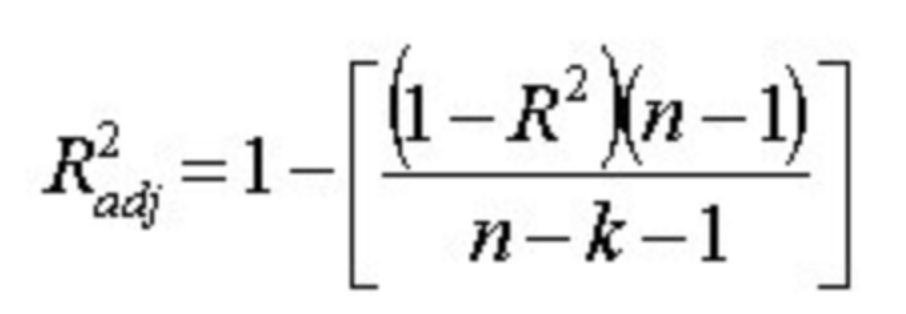
- 여기서 의미하는 건 n은 데이터 수이고 k가 변수의 수인데, 변수의 수가 많아져서 가 높아지는 걸 막겠다는 뜻이다.
- 그리고 데이터 수(n)이 많아지면 변수의 숫자가 별로 안 중요해진다.
- 그래서 이 조정된 를 사용하면
PolynomialFeatures()를 사용해도 결정계수 값이 비슷해진다. - 그래서 이 때는 정확도가 중요하면
PolynomialFeatures()이용, 그냥 변수별 설명력이 중요하면 간단한 첫번째 데이터셋을 이용하는 게 좋단다. - 출처 링크(https://ltlkodae.tistory.com/19)
- 예를 들어, feature 수가 13개일 때랑
-
텍스트 감성 분석(Sentiment Analysis)의 중요 포인트
- 적용 분야별 특성을 살린 사전 구축
- 데이터 수집 전략 구축
- Entry(대상), Aspect(어떤 부분), Opinion(감성 표현)... 아마 더 있겠지만, 감성 분석의 주된 분석 요점인 듯하다.
-
텍스트 분석 알면 알수록 심오하고, 재미있는 것 같다.
- 쓸모 있는 곳도 많은 것 같다...
- 동아비즈니스리뷰(링크) -> 이 글 굉장히 많은 인사이트를 준다.
- 감성사전이 잘 구축되어야 한다...
- 감성사전은 또 대상에 따라 긍, 부정이 바뀔 수도 있고
- 또 대상의 속성에 따라 달라질 수도 있다.
- 이런 점을 각각에 맞춰서 구축해놓는 작업이 정확한 모델을 쓰는 것만큼 중요하다.
- 특히 이런 텍스트 분석은 경영적인 측면에서 고객의 '날것의 소리'를 보여줄 수 있는 만큼 큰 도움이 될 수 있을 것 같다.
-
워드 임베딩
- 대표적인 게 Word2Vec
- 단어들을 저차원 벡터로 데이터 측면에서 많이 축소시켜 주고, 단어간 상관 관계를 벡터 내 위치(?) 혹은 벡터 간의 위치를 통해 알려줄 수 있어서 효과적이다.
-
아래의 문장은 제너레이터를 만든다.
- join 안에 제너레이터가 들어가도 각각의 값들을 연결시켜주나보다
- parenthesis 없이 그냥 쓰면
invalid syntax오류가 난다.
# 숫자 벡터로 encode된 문장을 원래대로 decode하는 함수입니다.
def get_decoded_sentence(encoded_sentence, index_to_word):
return ' '.join(index_to_word[index] if index in index_to_word else '<UNK>' for index in encoded_sentence[1:]) #[1:]를 통해 <BOS>를 제외
print(get_decoded_sentence([1, 3, 4, 5], index_to_word))i if i % 2 == 0 else i+10 for i in [1,2,3,4,5]
>>>SyntaxError: invalid syntax
print(i if i % 2 == 0 else i+10 for i in [1,2,3,4,5])
>>><generator object <genexpr> at 0x7f14177228d0>-
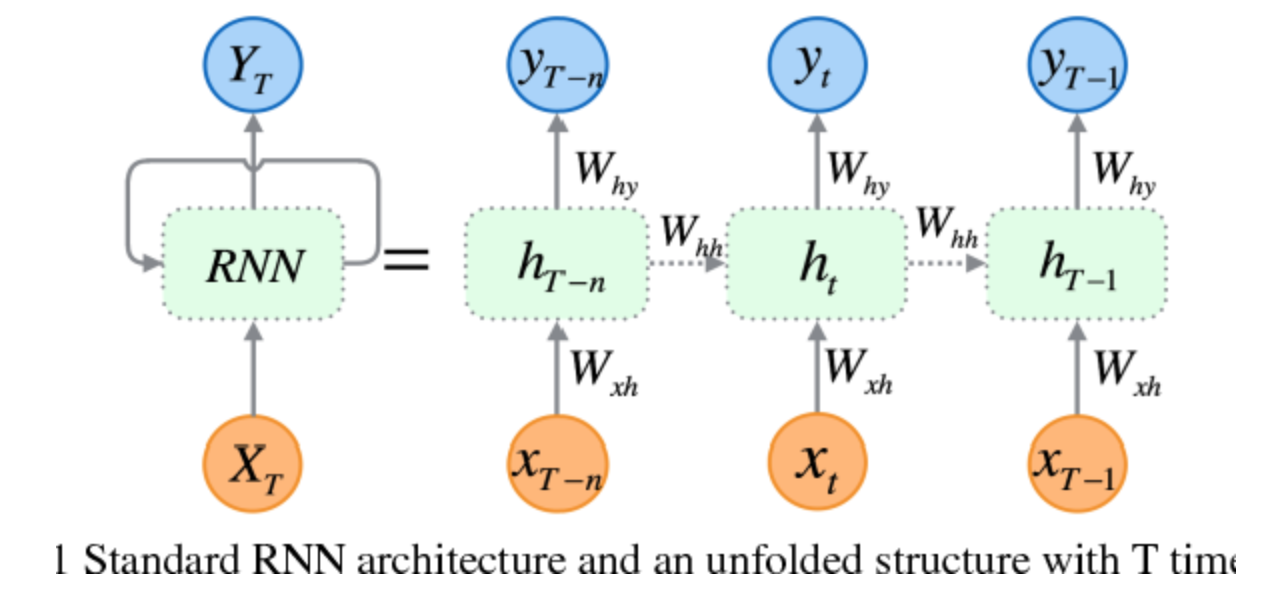
시퀀스 데이터(Sequence data)
: 사실 음성이 더 맞긴함 -
RNN은 state machine으로 설계됨
- state란 궁극적으로 문맥이 유지되는 것이라 보면 됨
- stateless한 것은 순차적이며 유기적인 질문에 문맥에 맞춰 답을 한 개씩 주는 게 아니라 전체의 답을 그 순간순간마다 주려 함
-
하나의 동일한 time-step의 데이터(혹은 데이터셋?)에 연관되는 가중치 w는 같다.(그래서
x -> RNN -> y)라고 단순하게 표현한다. -
꼭 RNN이어야 할까?
답을 하자면, 1-D Convolution Neural Network(1-D CNN)를 사용할 수도 있다.
이미지는 2-D CNN을 했는데, 문장은 1차원(단어를 여러 요소로 갖는)으로 해서 넣을 수도 있다.
이러면 그 벡터를 스캐닝하면서 특징을 추출한다.
그리고 병렬처리에 RNN보다 더 효율적이라 빠르다.
미니프로젝트(네이버영화리뷰, 한국어 감성 분석)
- 임베딩 레이어의 output_dim과 LSTM의 dimensionality는 같지 않아도 되나보다...
- 헷갈렸었는데, 일단 다르게 쓰는 코드들이 있다.
vocab_size = 10000
word_vector_dim = 32
model = tf.keras.Sequential()
model.add(tf.keras.layers.Embedding(vocab_size, word_vector_dim, input_shape=(None,)))
model.add(tf.keras.layers.LSTM(8?????))- 위의 경우는 아이펠 과제 중
word_vector_dim은 4였고, LSTM에는'8'이 써있길래 달라도 되나 싶어서 찾아봤는데, 아래의 경우가 있었다. - 이유는 잘 모르겠다...
embedding_dim = 100
hidden_units = 128
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim))
model.add(LSTM(hidden_units))- Dense 레이어의 숫자도 의미 파악이 필요하다.
- 일단 Dense layer 후 output 노드(뉴런)의 숫자인 것 같아서 previous layer output과는 숫자가 달라도 되는 것 같다.
- Global Average Pooling 이 사실 여러 종류란다....
- min, average, max 이렇게 종류가 있고 셋이 수식이 다른 것 같다.
- 그리고 keras 모델에
fit()을 계속 하면 계속 학습하는 거란다...- 모델 객체를 다시 생성하고 하면 초기화된다.
- 임베딩될 사전이 같다고 해서 항상 똑같은 모양으로 임베딩 되는 건 아닌가 보다.
- 이것도 random_state가 있으려나...
오늘의 감사거리
1) 그래도 word2vec에서 word->integer->vector가 되는 구조를 조금이나마 이해하게 됐다.

'어떻게든 자야겠어'라는 저 아이를 닮고 싶습니다