
HanBitN MSA?
한빛N MSA(Micro Seminar Assemble)는 한빛미디어 디지털콘텐츠개발연구소에서 준비한 세미나 시리즈다. 학교와, 학원 등에서 다루지는 않지만, 현업에서 일을 할 때 필요한 지식, 기술, 정보 등을 전달하는 걸 목표로 진행되는 세미나다.

Search-driven learning - 개발 주니어들을 위한 검색 방법론
👥: 개발을 하고 싶어? 그럼 검색을 잘 해야돼...
개발자라면 한번쯤 궁금했던, 궁금할법한 내용이다. 과연 그들이 말하는 '잘 검색하는 방법'은 과연 무엇일까? 특히나 그동안의 세미나 시리즈에서 검색 방법론은 내 시선을 끄는 주제였기에 되게 흥미롭게 들었다.
발표를 맡았던 박순영님은 실무에 있던 입장에서 주니어들이 겪을 수 있는 시행착오, 그리고 이 과정에서 얻은 정보가 향후 커리어나 전문성 측면으로 어떻게 이어지는지 고민하며 이번 세미나를 준비하셨다고 한다.
주제가 검색 방법론이라고 이런걸 막 거창하게 설명하는 세미나는 아니다. 뭔가 거창한걸 생각하고 이 게시글을 눌렀다면 약간 실망할 수 있다. 나같은 경우는 '반드시 어떤 방법론을 꼭 얻어가겠다!'라는 자세보다, '누군가의 축적된 경험을 공유받는 시간'으로 생각하며 들었다.
그렇다고 내용이 빈약했냐고 묻는다면 그건 또 아니다. 어떤 기준으로 검색 결과의 신뢰성을 평가하고, 얻어진 내용을 어떻게 활용해 다음 커리어로 잇는지 얻어갈 수 있었던 세미나였다.
무엇보다도 이런 일련의 과정이 그들이 말하는 '검색 잘하는 법'에 가깝지 않을까.
본 게시글에 사용된 강의 자료는 한빛미디어의 지원을 받았습니다.
검색과 학습
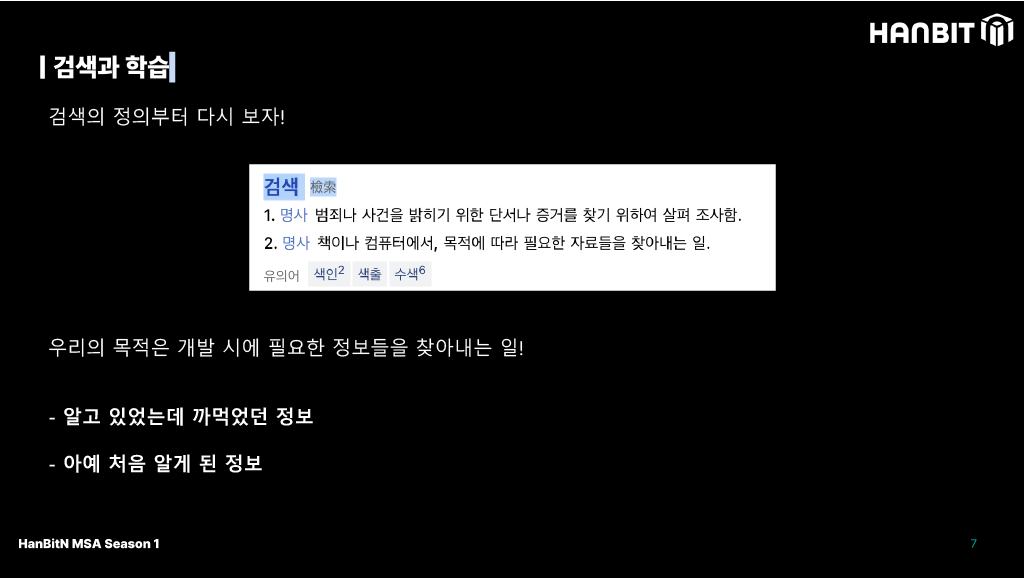
검색과 학습에 대한 내용을 개발자의 입장, 실무적인 내용으로 구간을 좁혀보자!
우선 우리가 개발하다 필요한 정보를 검색하는 상황을 떠올리면 아래 2가지 경우가 대표적이다.
- 까먹은 정보를 다시 리마인드 하는 경우 (ex. 계속 Python만 쓰다 Java를 오랜만에 쓰는 경우)
- 처음 알게된 정보가 있는 경우 (ex. Spring을 모르는데 이걸 가지고 뭔가 해야되는 경우)

위 경우를 조금 더 풀어보면 리마인드, 트러블 슈팅, 스터디로 나눌 수 있다.
- 리마인드: 실제로 구현을 한 적이 많이 없어 애매할때 찾아보는 상황.
- 트러블 슈팅: 보통 비슷한 상황을 겪는 누군가의 솔루션을 찾을때의 상황.
- 스터디: 솔직히 단어만 들어본 것들. 내가 안다고 할 수 없는것들에 대해 정리하고, 이해하기 위한 자료를 찾을때의 상황.
검색을 하는 상황(실무)
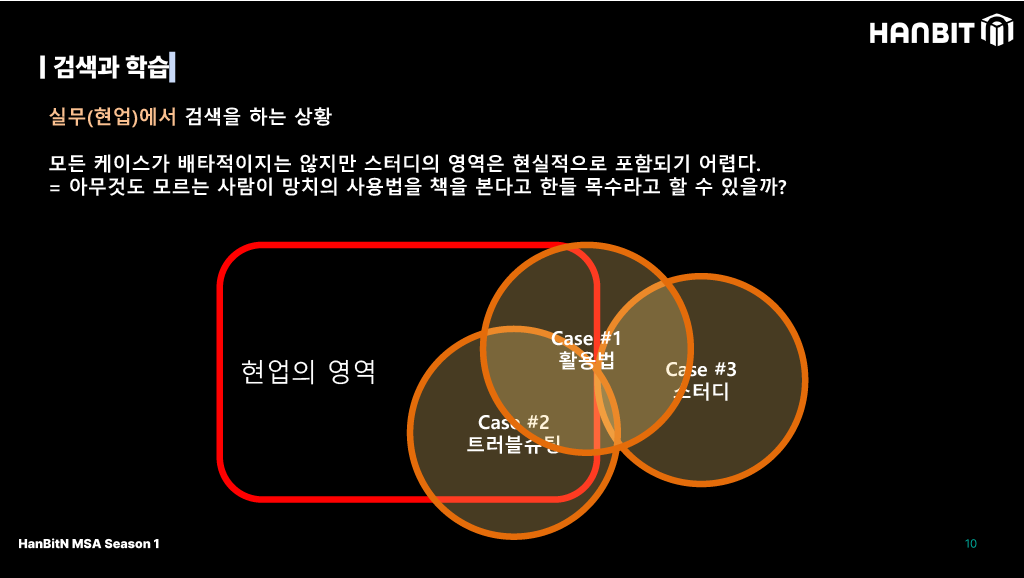
- 돈을 받는 입장이니 내 능력을 보여줘야 한다.
- 시간은 유한하고 제한적이다. 프로젝트는 무기한이 없다.
- 담당 분야의 전문가로 신뢰를 얻고, 이를 바탕으로 다른 직무에 신뢰성 있는 의견을 제안해야 한다.
실무 측면에서 생각하기 전에 현업을 전제해보면 위와 같은데, 시간이 유효하다는게 중요하다고 하셨다. 그런 의미에서 스터디에 한정해서는 실무적으로 검색하는 상황과는 분리되어야 한다.
취업을 했는데 잘 몰라서 해결을 못하고 하루를 날리는 경우를 생각해보자. 신입의 경우라면 사수가 있고, 회사 시스템이 있어 어느정도 문제가 되지 않지만, 연차가 쌓여 2~3년차가 되면 3년차 연봉을 가지고 이직할텐데 이런 경우엔 모르면 안되는거다. 그래서 스터디는 집에서 해야하는게 더 적합한 것 같고, 개발을 하기 전에 막힌걸 적어놨다 내재해서 들고갈 수 있도록 준비해야 된다고 말씀하셨다.
수박 겉핥기식 트러블 슈팅

- 모르는 부분을 스택오버플로우에 잘 찾아보며 열심히 코드를 짠다.
- 돌려보고 에러가 나면, 일단 에러메시지를 복붙해 찾아본다.
- 추천을 많이 받거나, 코드가 있는 답변을 복붙해 다시 돌려본다.
- 역시나 안돌아간다. 다시 돌려본다음에 그제서야 답변을 읽어본다.
- 과정을 반복한다.
지난 세미나 리뷰에서도 썼던 개발 루틴이다. 트러블 슈팅을 위해 우리의 영원한 친구 스택오버플로우에서 솔루션을 찾아 적용했는데, 막상 돌려보니 더 꼬인 경험이 있지 않은가? 이러면 잡다한 생각이 머리를 가득 채우기 시작한다. 강연자분께선 사실 이런 경우는 너무 피상적으로 알고 있었기에 발생한 문제라고 하셨다.
문제에 대해 검색할때 제대로 해결하려면 결국 문제가 발생한 근본적인 원인을 꿰뚫어야 하는데, 이걸 모르는 상황에서 그냥 복붙만 하다가는 해결이 안된다는거다. 물론 복붙을 어떻게 잘 해서 해결책을 찾아내더라도 결과적으로 이게 활용할 수 있는지, 신뢰성이 있는 답인지도 모르고 거의 껍데기만 활용하는 꼴이다.
문제가 반복되면 일 못하는 사람이 된다.
이게 어떻게 이어지냐 한다면, 나중에 비슷한 상황이 또 발생했을때 솔루션을 찾고 해결하겠지만, 다른 기능을 넣었을때 또 비슷한 문제가 발견되고,,, 이런식으로 쭉 반복되면 회사에서 나에 대한 신뢰성이 떨어지고, 나 조차 근본적인 문제를 모르고 넘어가는 결과가 될 수 있다고 한다.
인덱싱
근본적인 문제를 파악하고 검색하거나, 모르면 조금 더 공부를 해야한다!
사실 우리가 솔루션을 검색하는걸 생각해보면 무의식적으로 스택오버플로우나, 다른 블로그 포스트를 휙휙 넘기며 볼텐데, 사실 여기에 들어있는 단어 하나하나가 어떤 내용인지 자세히 이해하지 못하고 넘어가는 경우가 많다. 이렇게 정확히 설명할 수 없는 개념들을 찾아 인덱싱을 해두자.
이렇게 해둔 인덱싱은 나중에 하나씩 공부하는 도구로 쓰거나, 비슷한 내용을 검색할때 써먹을 수 있다. (여기서 인덱싱은 단순히 강연자분이 제시한 개념이다.) 그러니 실무적으로는 문제를 해결하는데 주안점을 두되, 전혀 모르는 부분이 있다면 따로 학습할 부분으로 정리하자.
채널
검색 결과를 검증하는 것을 하나의 프로세스로 가지고 있어야 한다.
검색에 들어가기 전, 내가 검색하는 이 채널. 즉, 정보를 알려주는 사이트나 채널이 과연 믿을만한 정보인가? 얼마나 나한테 의미있는 정보를 줄것인가?를 판단해야 한다. 중요한건 채널로부터 온 어떤 결과를 기준을 가지고 검증을 하는 것이다. 이 채널은 약간 불안정할 수도 있다고 생각하고 접근해야 한다.
세미나에서 언급된 대표적 채널들 중 일부를 정리해봤다.
1. 공식문서 or 깃헙(a.k.a README.md), RFC, IEEE...

그나마 신뢰도가 높다고 볼 수 있는 채널이다. 당연히 프레임워크/표준문서 관련된 내용은 실제 개발자가 기여한 내용이기에 오류가 많이 적다.
공식문서인데 왜 신뢰도가 100%가 아니라 90%인가요?
새로 출시된지 얼마 안된 라이브러리(즉, 불안정한 상태)를 썼을때 당연히 해당 라이브러리의 자료들이 오류나 예외사항을 충분히 반영하지 못하는 경우가 많을 수 있다. 이런 경우 트러블 슈팅을 했을때 신뢰성도 없고, 해결책도 많이 없고, 더군다나 기본적으로 불안하다. 많은 시니어 개발자들이 안정적이지 않은(대부분 새로운) 프레임워크를 별로 달가워하지 않는게 이런 부분 때문이라고 한다.

RFC, IEEE?
표준 문서 자체가 엄청 꼼꼼해 스트레스를 많이 받을 정도로 읽기가 매우 힘들다. 그럼에도 읽어야 하는 이유는 표준이라는 이유 하나 때문인데, 표준을 알고 어떤 문제를 바라보는 것과 그렇지 않은 것은 큰 차이가 난다고 한다.
예전에 HTTP RFC를 읽고 HTTP 서버를 구현하는 프로젝트를 한 경험이 있었다. 문서 읽는게 구현보다 훨씬 어려웠던 경험이 있는데, 이거까지 알아야 하나 싶을 정도로 세세한 부분이 서술되어 있다. 문서를 한 번 쭉 보고 이해했다고 하기도 그렇고,,, 그렇다고 다시 보기엔 엄두가 안나는 그런 문서로 기억한다. 혹시나 궁금하면 RFC 7230~7235(HTTP/1.1)를 찾아보면 된다. 그때 생각하면 끔찍하다
2. 스택오버플로우

I tried it, but doesn't help.
검색하면 다들 믿고보는 스택오버플로우다. 주의할 부분은 이 친구가 생각보다 신뢰도가 높지 않은 부분이 많다는 점인데, 검색한 뒤 솔루션이라고 뜨는 코드를 무작정 가져오지 말고, 일단 판단을 하자. 특히나 스택오버플로우의 답변은 그 사람의 경험을 푼거라, general solution이 아닐 수 있다는 점(그 사람만의 특별한 환경에서 돌아가는 경우일 수도 있으니까!)을 항상 감안해야 한다. 이게 은근히 주니어 개발자들이 많이 놓치는 부분이라고 한다.
판단법이야 다양하겠지만 세미나에선 본문에 솔루션이 없는데 코멘트/스레드에서 갑자기 정답이 튀어나오는 경우도 있으니 사람들이 어떤 대화를 하는지를 봐야한다고 했다. 비슷한 경험을 하고 있다면 본인이 트러블 슈팅 과정에서 스택오버플로우를 어떻게 사용하는지 다시 돌아보자.
ETC
이외에도 채널로 언급된게 검색엔진, 유튜브&GPT였다. 검색엔진은 대표적인 구글링이라 그렇다 치고, 유튜브랑 GPT가 인덱싱&검증을 위한 도구로 나와 되게 신선하다고 생각했다. 솔직히 상상도 못한 조합이었다. 각 채널들의 특징을 살려 지식을 얻는 창구로 쓸 생각을 어떻게 할 수 있는걸까...
활용

기본적으로 구글링을 전제로 깔고 검색엔진 활용법을 소개해주셨다. 나도 검색할때 자주 쓰는 키워드들이 나와서 익숙했다. 문법이 힘들다면 advanced_search(고급 검색)에 들어가 검색하는 것도 방법이다.
- site:arxiv.org filetype:pdf word2vec "optimizing"
예를 들어 "word2vec 모델의 optimizing을 다루는 논문"을 찾고 싶다면 위처럼 치면 되겠다. 만약 키워드가 많은데 가중치를 주지 않으면 각 키워드를 동일한 가중치로 두기 때문에, 정말 많은 정보가 나올 수 있다. 그러니 조금 더 중요하다고 생각되는 키워드엔 강조("")를 해주자. 위 예시에서는 word2vec, optimizing 중에 optimizing에 조금 더 가중치를 둔 경우다.
[TMI]
"codeforces라는 키워드를 꼭 넣어야만 알고리즘을 소개하는 글과 코드가 같이 나와요. 안그러면 알고리즘을 증명하는 수식/논문만 잔뜩 나오고 막상 찾으려는 코드는 없어 허탕을 칩니다."최근 알고리즘 동아리에서 대회를 치른 뒤, 제일 난이도 높은 문제의 해설을 하던 중에 들은 말이다. 키워드의 중요성이 이런게 아닐까.
질문과 키워드 최적화

여기까지 했다면 원하는 검색결과를 얻을때까지의 과정을 최적화해보자.
- 포괄적 주제로 접근
- 구체적 키워드로 좁히기
- Outdated 고려하기
- 체이닝&반복
세미나에선 최적화 과정을 트러블 슈팅을 예시로 설명해주셨다. 오류 메시지를 그대로 복붙하기 보다는 내 코드에만 한정된 정보를 우선 제거하고, 가장 구체성을 띄는 키워드에 상황에 대한 정보(실행환경, 의심가는 상황 등)을 추가해 한정지어 검색해야 된다는 점, 오류가 발생했을때의 버전을 고려해 검색하는 등 써먹기 좋은 팁들을 많이 배울 수 있었다.
각 과정별 내용을 다 적기엔 분량이 방대하기도 하고, 내가 직접 정리하는 것 보다 한빛미디어에서 제공하는 VOD를 직접 확인하는게 훨씬 도움이 될 것 같아 아래 링크를 남겨둔다. 이번 세미나의 핵심 부분이라 생각하니, 자세한 내용은 영상을 확인해보자.
적용
사실 소제목이 적용이긴 하지만, 상황에 맞는 솔루션을 똑부러지게 제시하기란 굉장히 힘든 일이다. 그래서 검색결과 이해에 대한 측면에서 '검색결과를 활용할 자격'에 대해 설명해주셨다.
언 발에 오줌누기식 대응은 그만두자.
취업을 위해 프로젝트를 하고, 포트폴리오를 만들어 면접에 간 경험이 있는가? 이건 실무에서 운영한 프로젝트가 아니기에, 교과서적인 내용만 가지고 개발한걸 설명하게 되고, 결국 실무적인 레벨에서 대답할 상황이 안된다. 이런 부분에서 실무에 비해 상대적으로 경험치가 얕다고 볼 수 있겠다.
그렇기에 실무에서 어떤 문제가 생긴다는건 내가 경험치를 쌓을 수 있는 기회가 된다. 책에 나오는 방법론들을 실무에 가져갔을때 오류가 난다면, 한 번도 이런적이 없었다며 스트레스를 받기 보다 새로운걸 깨닫고 다음엔 그 실수를 반복하지 않을 수 있는 성장의 발판으로 삼아야 한다.
이를 위해선 문제가 발생했을때 피상적인 부분만 해결하면 안된다. 근본적인 문제를 모르면 스킬도 늘지 않고 남는것도 없기 때문이다. 나에게 닥친 문제 상황은 반대로 나에게 교훈을 주는 상황이라고 생각하자.
내재화

앞서 말한 적용의 연장선이다. 몰랐던건 몰랐던대로 학습하는 물꼬가 될 수 있고, 또 다른 하나는 커리어를 유지하는 키가 된다. 그렇기에 새롭게 알게된 내용에 대해 드릴다운 분석을 해두자. 특히 실무에서 겪은 문제를 해결한 과정이 되게 쉽지 않았다면 잘 정리해야 한다. 이게 성과가 되고 면접에서 한마디 더 할 수 있는 요소가 된다.
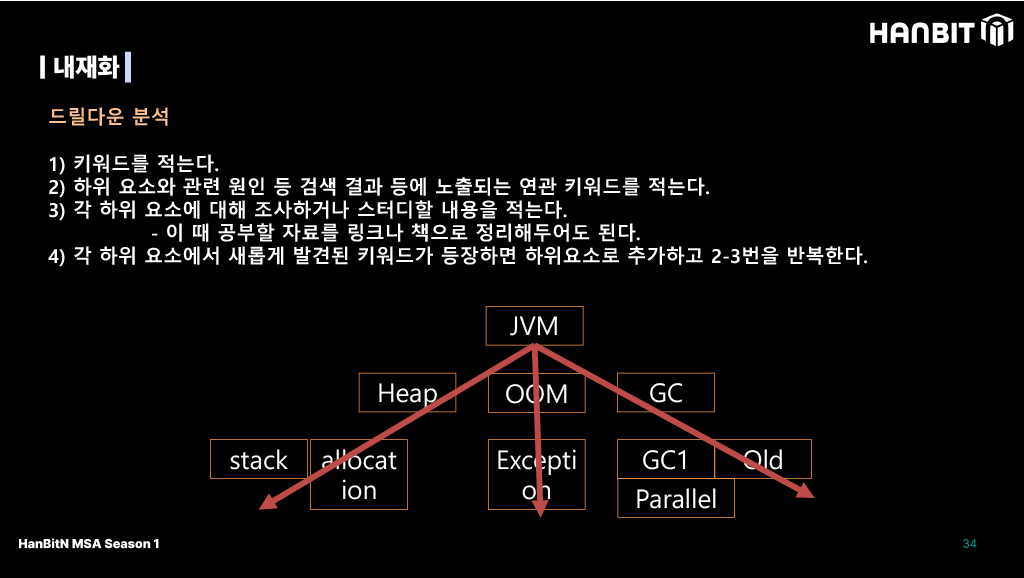
먼저 모르는 단어에서 시작해 연관된 검색결과를 보고, 연관 단어를 한번 더 밑에 적는 것 부터 시작한다. 이때 무엇을 위한 지식(해결책)인지, 왜 이렇게 해야되는지를 생각하면서 정리하는게 중요하다. 이렇게 계속 구조화 시키다보면 내가 몰랐던 내용을 찾고, 빠짐없이 공부하는 방법으로 쓸 수 있다.
자료구조를 공부할 당시 STL 헤더를 뜯어서 이해하겠다며 무작정 나선적이 있는데, 당시에 정리해둔걸 보니 드릴다운 분석과 비슷하게나마 정리했던 기억이 난다. 확실히 모르는 개념을 계층화 시켜 정리하면 나중에 리마인드할때 크게 도움이 된다.
후기
주변에 개발 좀 친다하는 사람들이나, 간혹 어느 행사의 QnA 세션에서 '이것만큼은 주니어들이 알아야 한다!'라는게 있냐고 질문을 던지면 검색하는 법을 알아야 한다는 답을 자주 들었다. 그렇다고 검색하는 법을 알려달라고 물었을때 '명확한 답변을 받았나?'를 떠올리면 그건 또 아니었다. 마치 음료수 자판기에 지폐를 넣었는데 음료수가 나오긴 커녕, 지폐가 반환되는걸 보는 느낌이었다.
생각해보면 흔히 '짬'으로 불리는 오랜 시간동안 축적된 경험(검색하는 법)을 남에게 바로 설명하는건 쉽지 않은 일이다. 설명한걸 상대가 전부 습득할리도 없을거고, 무엇보다 사람마다 잘 들어맞는 방법이 있다. 그래서 질문을 받았던 사람들이 애매한 스탠스를 보였던 것 같다. 이런 이유로 지난 세미나들과 비교했을때 도전적인 세미나였다고 본다.
어쩌면 이번 세미나에서 힌트를 얻을 수 있지 않을까 해서, 세미나를 듣는 내내 그들이 말하는 '검색 잘하는법'을 알고자 했다. 그것이 단순히 검색으로 솔루션을 빨리 찾는걸 의미할 수 있지만, 궁극적으로 검색을 통해 자신을 어떻게 잘 성장시키는지 아는걸 의미하는게 아니었을까 추측해본다.
위에 말은 거창하게 했지만 세미나 내용을 직접 활용해보고, 조금 바뀐게 있다고 느껴질쯤 후속글을 올려봐야겠다. 이 글을 보고 세미나의 전체 내용이 궁금해졌다면 아래 링크로 들어가 확인해보자!
