- 멀티 프로그래밍을 하는 OS 에서는 필수
- 멀티 프로그래밍이란 ? 하나의 CPU가 여러개의 프로세스를 동시적으로 실행하는 것
- 따라서 CPU 스케쥴링은 하나의 CPU로 여러개의 프로세스를 처리할 때, CPU의 효율성을 증대하기 위해서 CPU 스케쥴링이 필요
- 실제로 CPU-burst보다 I/O -burst가 높기 때문에 CPU 스케쥴링으로 효율성 증대 가능
CPU-burst: 실제 CPU를 사용하는 시간I/O-burs: CPU 사용을 위해wait, ready하는 시간
CPU 스케쥴러 구현 시 고려해야 할 것
- 메모리에 로드 되어있는 프로세스 중에 어떤 프로세스한테 CPU를 할당해줄 것인가?
-ready 상태에 있는 프로세스 중에서, CPU를 할당 해주는 프로세스를 선택하는 것 - 현재 CPU에 running 하고 있는 프로세스가 종료 된 후, ready queue에서 대기 중인 프로세스 중에서 어떤 프로세스를 선택해야 하는가 ?
Ready Queue 구현 방법: 우선 순위 큐로 구현하여 우선순위를 부여
선점형(Preemptive) vs 비선점형(Non-Preemptive)
선점형
현재 CPU를 점유하고 있는 프로세스가 있어도 스케쥴러가 해당 프로세스를 중단 시키고, 새로운 프로세스를 할당시킬 수 있는 방법
비선점형
현재 CPU를 점유하고 있는 프로세스가 있다면 해당 프로세스의 작업이 모두 종료될 때 까지 기다린 후 새로운 프로세스를 할당 할 수 있는 방법
CPU 스케쥴링 시 Decision Making
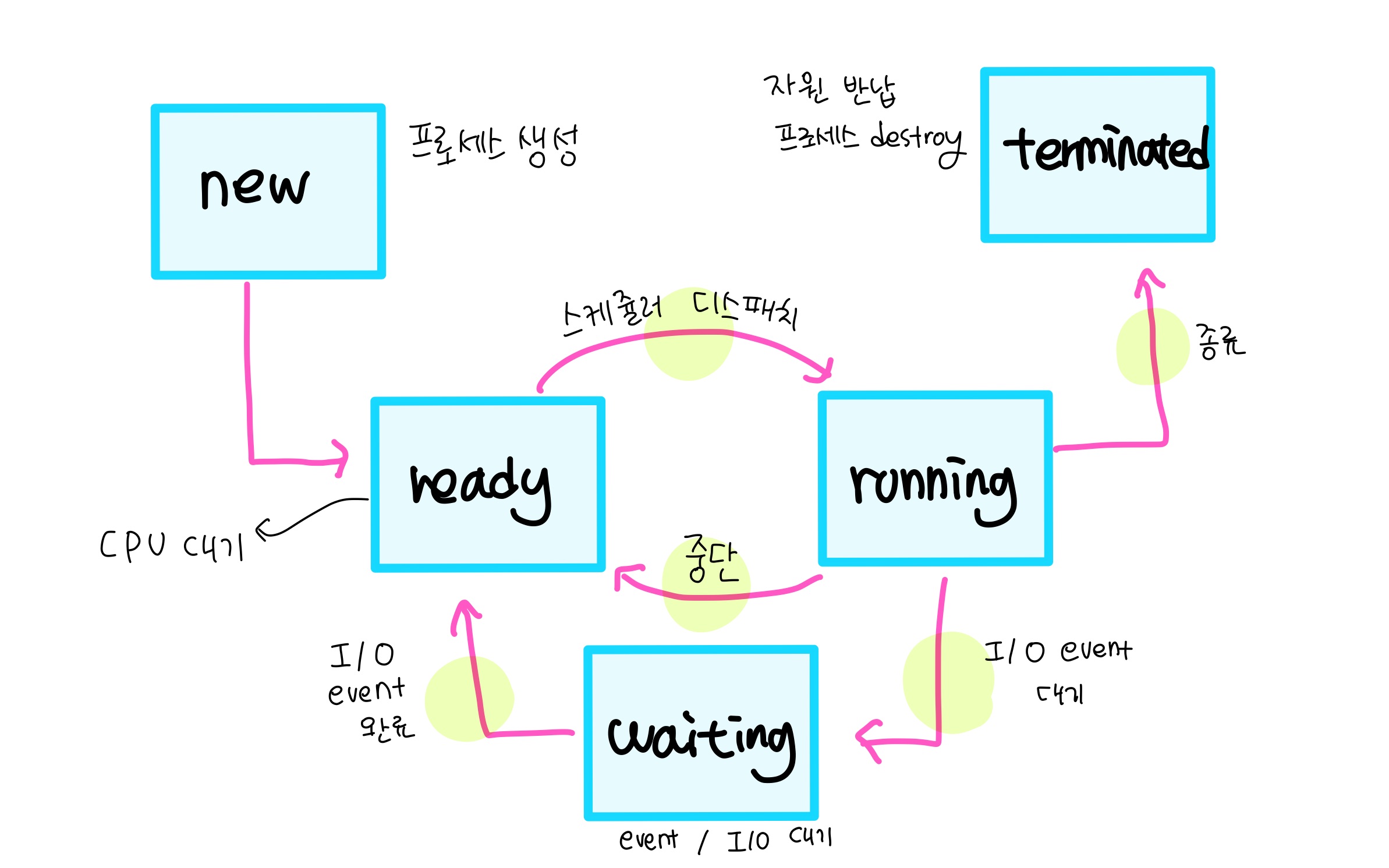
- Running -> Waiting (비선점형)
- ex) running 중이다가 I/O 작업이 들어왔을 경우
- Running -> Ready (선점형)
- Waiting -> Ready (선점형)
- ex) I/O 작업이 모두 종료 된 후, 다시 CPU를 점유하러 ready 상태로 이동
- 프로세스 종료 (비선점형)
Dispatcher
CPU 코어의 Control을 넘겨주는 모듈
- Context를 하나의 프로세스에서 다른 프로세스로 넘겨준다.
- User Mode로 변경해준다.
스케쥴러와의 차이점
- 스케쥴러 : 어떤 프로세스에 CPU를 할당할지 선택하는 역할
- Dispatcher : 스케쥴러의 결정에 따라 실제로 교환(swtiching)해주는 역할
CPU 스케쥴링의 문제
Ready Queue에 있는 프로세스 중에서 어떤 프로세스에게 CPU를 할당할 것인가를 결정하는 문제
CPU 스케쥴링의 목적
- CPU 사용량의 극대화
- Throughput 최대화
- Throughput : 단위 시간 내에 프로세스 완결의 수
- Turnaround Time 최소화
- Turnaround Time : 프로세스 도착부터 종료까지의 시간
- Waiting Time 최소화
- Waiting Time : 프로세스가 Ready Queue에서 대기하는 시간
- Waiting time 최소화 시, Turnaround Time이 최소화 되고, Throughput이 최대화 되며 CPU 사용량이 극대화 된다.
- Response Time 최소화
스케쥴링 알고리즘의 종류
- FCFS : First-Com, First-Served
- 먼저 도착한 프로세스를 먼저 처리
- SJF : Shortest Job First
- 작업 시간이 가장 짧은 프로세스를 먼저 처리
- RR : Round-Robin
- 시분할(Time-Sharing) 을 하여 CPU에 프로세스 할당
- Priority-based
- RR + 우선순위 부여하여 프로세스 할당
- MLQ : Multi Level Queue
- 각 레벨 별로 다른 알고리즘을 적용
- MLFQ : Multi Level Feedback Queue
- 멀티 레벨 + 피드백 반영
1. FCFS 알고리즘
CPU를 먼저 요청한 프로세스에게 할당해주는 방법
- 프로세스의 CPU-burst 시간에 따라서 대기시간이 달라진다.
- 비선점형 알고리즘이다.
문제점 - Convoy Effect
CPU-burst 시간이 큰 프로세스가 가장 먼저 오고, CPU-burst 시간이 짧은 여러개의 프로세스들이 그 후에 왔을 때 대기 시간이 매우 커지는 문제가 발생 할 수 있다.
2. SJF 알고리즘
CPU-burst가 가장 짧은 프로세스에 CPU에 먼저 할당해주는 방법으로, 대기 시간을 최소화 시킬 수 있다.
- CPU-burst가 가장 짧은 프로세스를 먼저 처리하면, 짧은 프로세스의 대기 시간이 감소하고, 긴 프로세스의 대기시간은 증가한다.
- 이 때 결과적으로 평균 대기시간은 줄어든다.
하지만, next CPU burst를 정확하게 측정 할 수는 없으므로, next CPU busrt를 예측하여 근사적으로 구현 할 수 있다.
어떻게 next CPU burst를 예측하는가?
과거에 측정된 CPU burst에 따라 예측 (지수적 평균을 구함) 한다. 하지만, 이를 실제로 구현하기는 어려워서 SJF 알고리즘이 사용되지는 않는다.
선점형 or 비선점형
- 현재 P1 실행 중, P1 보다 CPU burst가 더 짧은 P2가 요청될 경우 P1을 waiting 상태로 놓고 P2를 실행하는 구현방법 (
선점형) 과, P1 실행 종료 후 P2를 실행하는 구현 방법(비선점형)이 있다. - 비선점형의 경우는 P1->P2의 Next CPU burst 보다 Context Switching 비용을 고려한다.
- SRTF (Shortest-Remaining-Time-First) : 선점형 방식의 SJF 알고리즘
현재 실행중인 프로세스의 남은 시간 > 다음 프로세스의 실행 시간일 경우 선점한다.
3. RR (Round-Robin) 알고리즘
선점형으로 구현되는 FCFS 알고리즘으로, 시분할을 하여 프로세스에게 time quantum을 주고, 해당 time quantum만큼만 실행 후, 무조건 선점되도로 구현한다.
- time quantum : 프로세스에게 할당되는 최대 CPU 시간
프로세스 CPU burst < time quantum 일 경우
종료된 프로세스가 자발적으로 CPU를 release 해준다. 따라서, 스케쥴러는 ready queue에 있는 다음 프로세스를 실행한다.
프로세스 CPU burst > time quantum 일 경우
타이머가 종료되어 OS에 중단을 걸어주고, ready queue에 있는 다음 프로세스가 CPU를 점유하여 context switching이 일어난다. 이 때 중단된 프로세스는 ready queue의 맨 마지막으로 다시 삽입된다.
Time quantum의 적절한 분할이 성능의 향상의 Key
-
time quantum을 너무 크게 주면 결국 FCFS 알고리즘과 다를 바 없어진다.
-
time quantum을 너무 작게 주면, context switch가 많이 일어난다.
4. Priority-based 알고리즘
각 프로세스의 특정 우선순위를 부여한 후, 가장 우선순위가 높은 프로세스를 CPU에 할당 해주는 방법
- 만약 프로세스들 간의 우선순위가 같다면 FCFS방식으로 처리해준다.
- SJF 는 next CPU burst를 우선순위로 갖는 Priority-based 알고리즘의 일종
- 선점형과 비선점형 모두 구현 가능
문제점 - 기아 현상
우선순위가 낮은 프로세스는 무기한으로 대기하는 현상
해결방법 : Aging
오랜시간 대기하는 프로세스의 우선순위를 강제로 (점진적으로) 높여주는 방법
RR + Priority-based
가장 높은 우선순위의 프로세스를 먼저 실행시켜주되, 같은 우선순위를 같은 프로세스의 경우 RR 스케쥴링 방식을 적용한다.
5. MLQ(Multi-Level Queue) 알고리즘
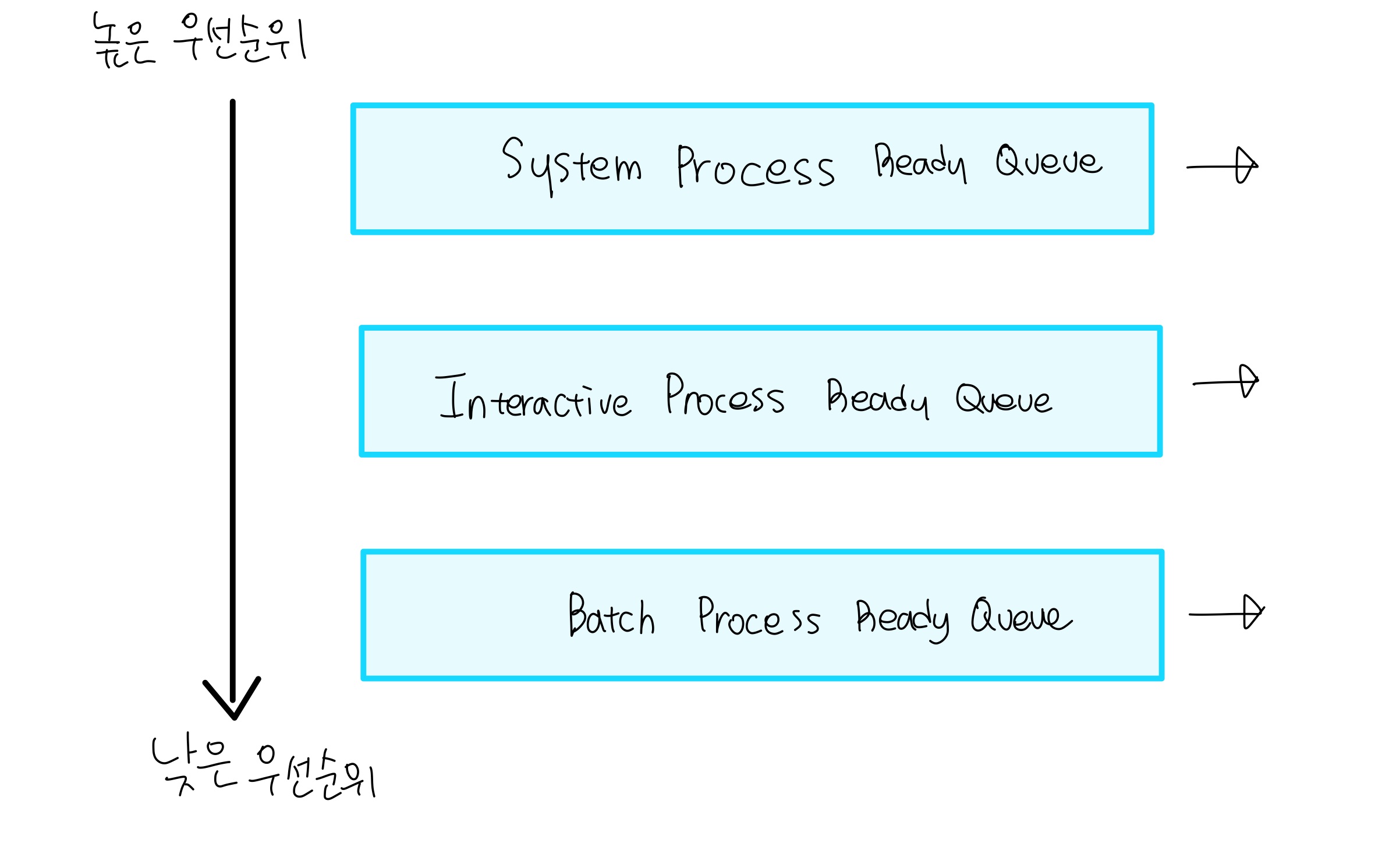
Priority-based 알고리즘을 심화시킨 것으로, 각 priority마다 ready queue를 독립적으로 부여해주는 방법이다.
문제점
- 가장 우선순위가 높은 Ready queue가 계속해서 채워질 경우, 다른 Ready Queue에 있는 프로세스들은 실행될 수 없다.
- 우선순위를 변형할 수 없으므로 유동적이지 못하다.
6. MLFQ (Multi-Level Feedback Queue) 알고리즘
MLQ 의 문제점을 보완한 방법으로, 프로세스가 여러 큐 사이를 이동 할 수 있는 알고리즘이다.
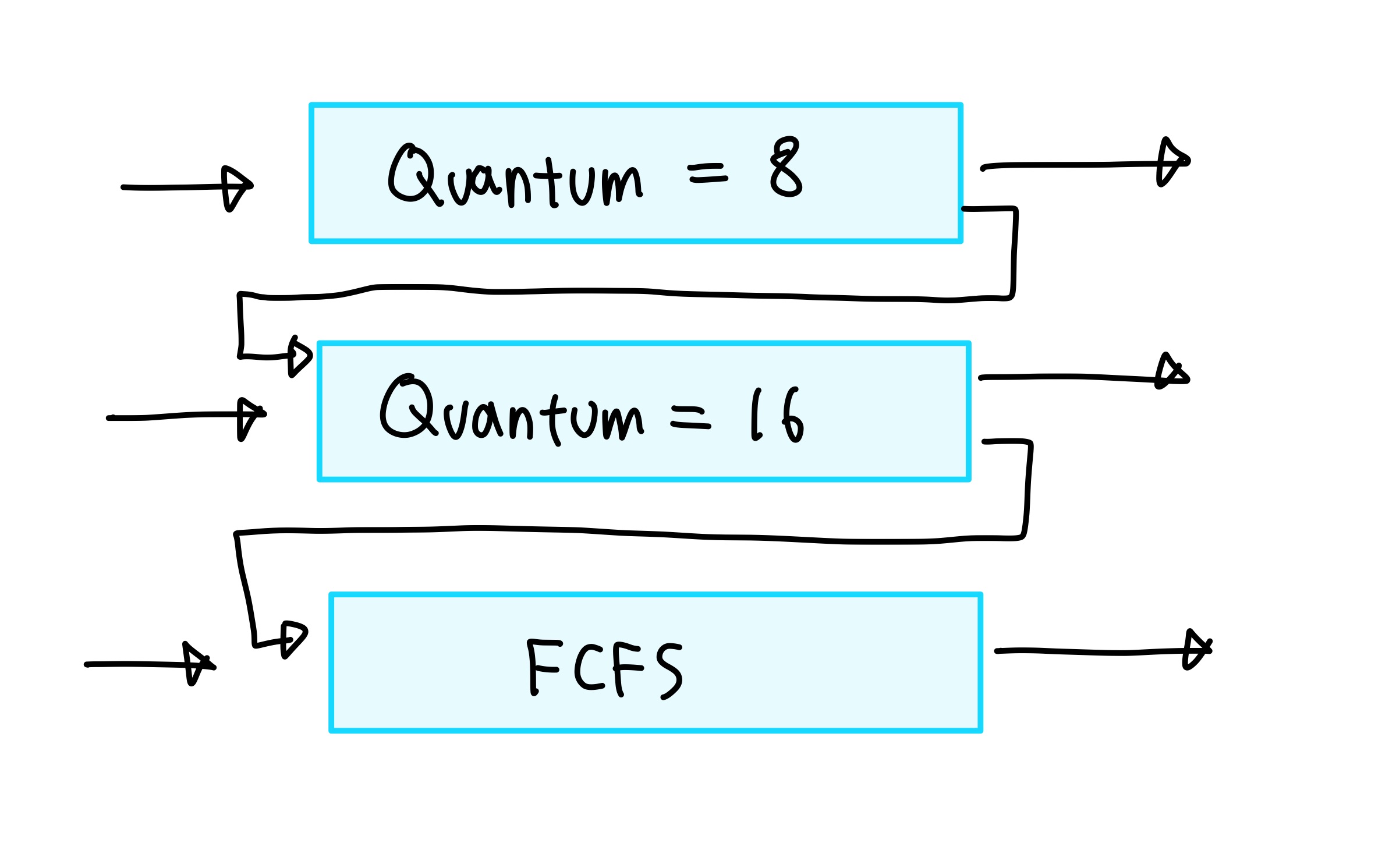
- MLQ 에서는 각 프로세스들이 우선순위에 따라서 다른 Ready Queue에 할당되었다면, MLFQ 에서는 프로세스들이 모두 같은 Ready Queue (맨 위에 있는 큐)에 들어온다.
- time quantum을 다 채운 프로세스는 그 아래에 있는 Ready Queue로 이동한다. 이 때, 두번째 Ready Queue는 이전의 Ready Queue보다 time quantum이 두배로 커져있다는 것이다.
- 마지막 큐는 FCFS로 처리된다.
왜 이렇게 구현하는가?
보통 CPU burst가 클 수록 중요도가 낮은 작업이다. 예를 들어 용량이 큰 게임을 다운로드(CPU burst 높음)와 I/O 작업(CPU burst 낮음) 의 차이이다.
이 때 하나의 프로세스가 time quantum을 다 채웠다는 것은, 그만큼 CPU burst가 높다는 것(CPU bound)을 의미하므로 FCFS로 처리하여 Context-Switching 비용을 아껴줄 수 있다.
따라서 대화형 프로세스 ( I/O 작업 ) 의 우선순위를 높여준다.
문제점 - 기아현상
MLFQ 역시도 기아현상이 발생할 수 있다. 계속해서 우선순위가 높은 프로세스만 들어온다면, FCFS로 처리되어야 하는 CPU bound 작업이 무기한으로 실행되지 않기 때문이다.
이 역시도 aging 방법으로 처리 할 수 있다.
참고
