
2023년 3월 6일부터 @cloudnet study를 시작 하였다.
[24단계 실습으로 정복하는 쿠버네티스][이정훈 지음]의 책을 기본으로 학습을 한다.
운영을 하면서도 부족한 부분을 배울 수 있을 것이란 기대감과 함께 시작한 수업이나 숙제를 하지 못해서 발생하는 불상사를 경험하지 않고 5주간의 스터디를 잘 마무리 했으면 좋겠다.
4주차 스터디 내용을 정리해 본다.
4주차에는 쿠버네티스 모니터링 시스템에 대해서 스터디 및 실습을 진행하였다.
내가 속해 있는 회사에서도 쿠버네티스 클러스터를 운영 중이고 클러스터 모니터링을 프로메테우스&그라파나로 진행하고 있어서 그 구축 과정속에서 정리 헀던 내용을 남겨보고자 한다.
그라파나란
- 그라파나는 데이터를 시각화하여 분석 및 모니터링을 용이하게 해주는 오픈소스 분석 플랫폼 이다.
- 여러 데이터 소스를 연동하여 사용 할 수 있으며, 시각화 된 데이터들을 대시보드로 만들 수 있다.
그라파나가 사용되는 이유
- 무료 버전으로 쉽고/빠르게 기본적인 시각화가 모두 가능하다.
- 그라파나는 플러그 가능한 데이터소스 모델을 가지고 있으며 Graphite, Prometheus, Elasticsearch, OpenTSDB 및 InfluxDB와 같은 가장 널리 사용되는 시계열 데이터베이스를 풍부하게 지원 한다.
- 구글 Stackdriver, Amazon Cloudwatch, Microsoft Azure Cloudwatch, Microsoft Azure 및 MySQL 및 Postrgres와 같은 SQL 데이터베이스와 같은 클라우드 모니터링 공급 업체를 기본적으로 지원한다.
- 그라파나는 많은 장소의 데이터를 단일 대시보드로 결합 할 수 있는 유일한 도구이다.
그라파나 설치
- 그라파나는 다양한 방식으로 설치를 지원 한다.
- 이번 정리에선 프로메테우스와 마찬가지로 Helm Chart 와 ArgoCD를 활용한 배포 방법에 대해서 정리하도록 하겠다.
그라파나 Helm Charts
- Grafana Helm Charts repo를 추가하고 다운 받는다
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
helm pull grafana/grafana
- 압축 파일을 다운 받고 해제
tar xzf grafana-6.52.4.tgz
$ tree ./
./
├── Chart.yaml
├── README.md
├── ci
│ ├── default-values.yaml
│ ├── with-affinity-values.yaml
│ ├── with-dashboard-json-values.yaml
│ ├── with-dashboard-values.yaml
│ ├── with-extraconfigmapmounts-values.yaml
│ ├── with-image-renderer-values.yaml
│ └── with-persistence.yaml
├── dashboards
│ └── custom-dashboard.json
├── templates
│ ├── NOTES.txt
│ ├── _helpers.tpl
│ ├── _pod.tpl
│ ├── clusterrole.yaml
│ ├── clusterrolebinding.yaml
│ ├── configmap-dashboard-provider.yaml
│ ├── configmap.yaml
│ ├── dashboards-json-configmap.yaml
│ ├── deployment.yaml
│ ├── extra-manifests.yaml
│ ├── headless-service.yaml
│ ├── hpa.yaml
│ ├── image-renderer-deployment.yaml
│ ├── image-renderer-hpa.yaml
│ ├── image-renderer-network-policy.yaml
│ ├── image-renderer-service.yaml
│ ├── image-renderer-servicemonitor.yaml
│ ├── ingress.yaml
│ ├── networkpolicy.yaml
│ ├── poddisruptionbudget.yaml
│ ├── podsecuritypolicy.yaml
│ ├── pvc.yaml
│ ├── role.yaml
│ ├── rolebinding.yaml
│ ├── secret-env.yaml
│ ├── secret.yaml
│ ├── service.yaml
│ ├── serviceaccount.yaml
│ ├── servicemonitor.yaml
│ ├── statefulset.yaml
│ └── tests
│ ├── test-configmap.yaml
│ ├── test-podsecuritypolicy.yaml
│ ├── test-role.yaml
│ ├── test-rolebinding.yaml
│ ├── test-serviceaccount.yaml
│ └── test.yaml
└── values.yaml
그라파나 차트 정보와 템플릿 파일들을 확인 할 수 있다.
필요한 Service port 및 구성에 대한 정보를 수정 하고
회사에서 사용하는 GitRepo에 코드를 등록한 후 ArgoCD를 통해서 배포를 해보도록 하겠다.
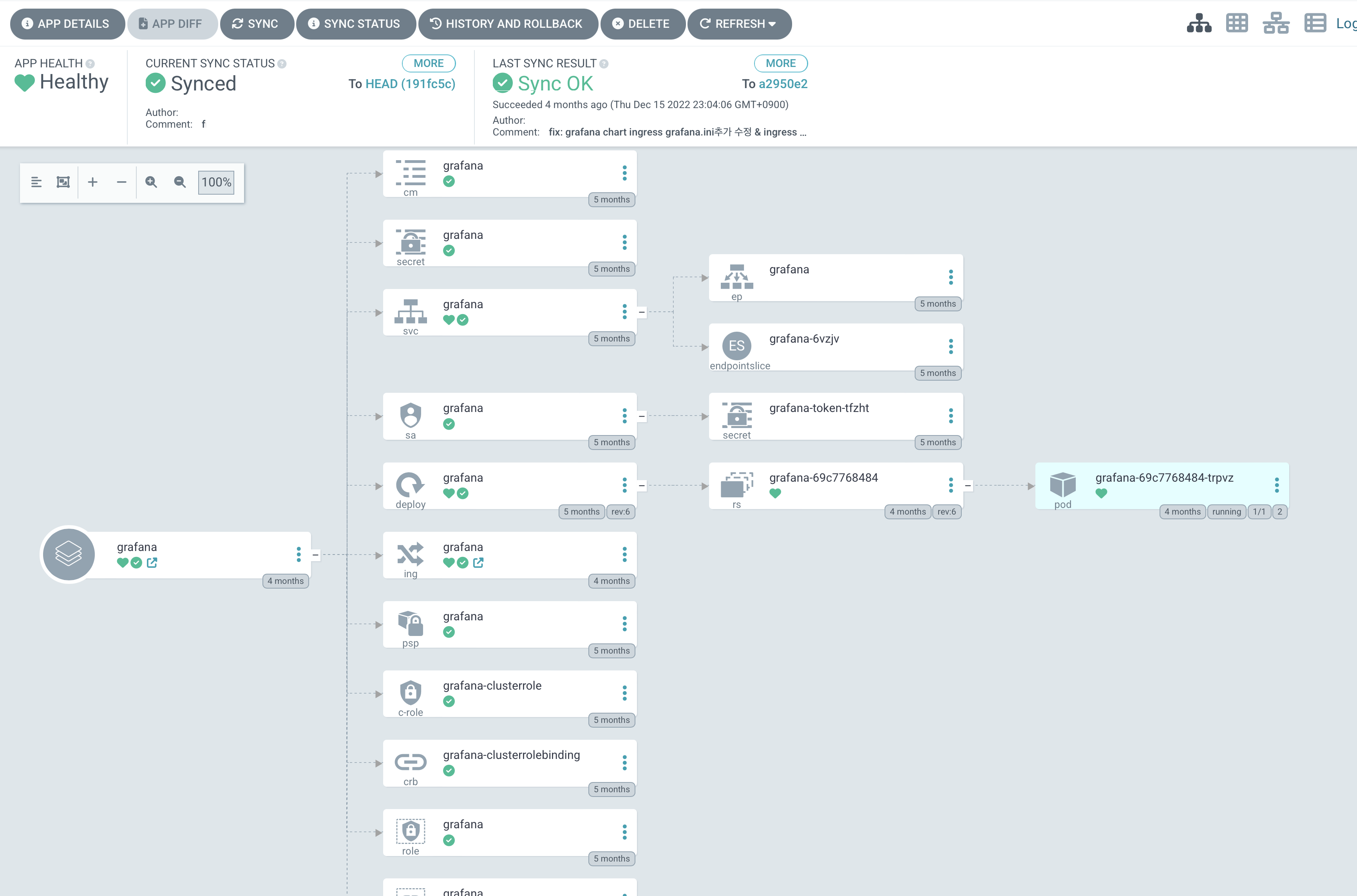
ArgoCD Applications 등록 및 배포
ArgoCD Applications 등록
- Applications Name 입력
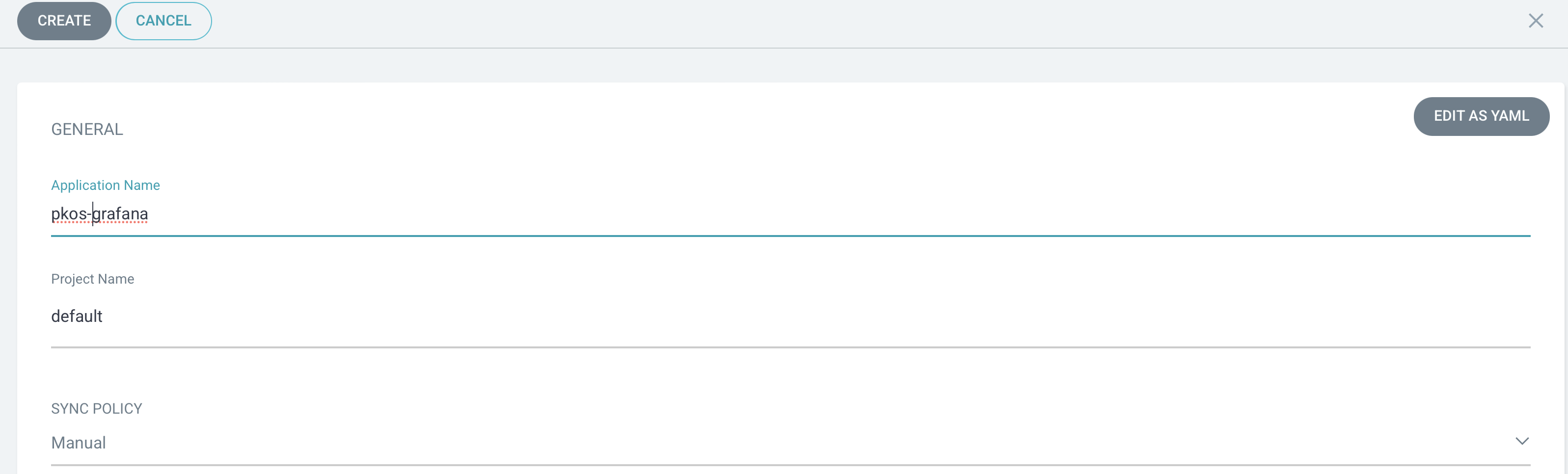
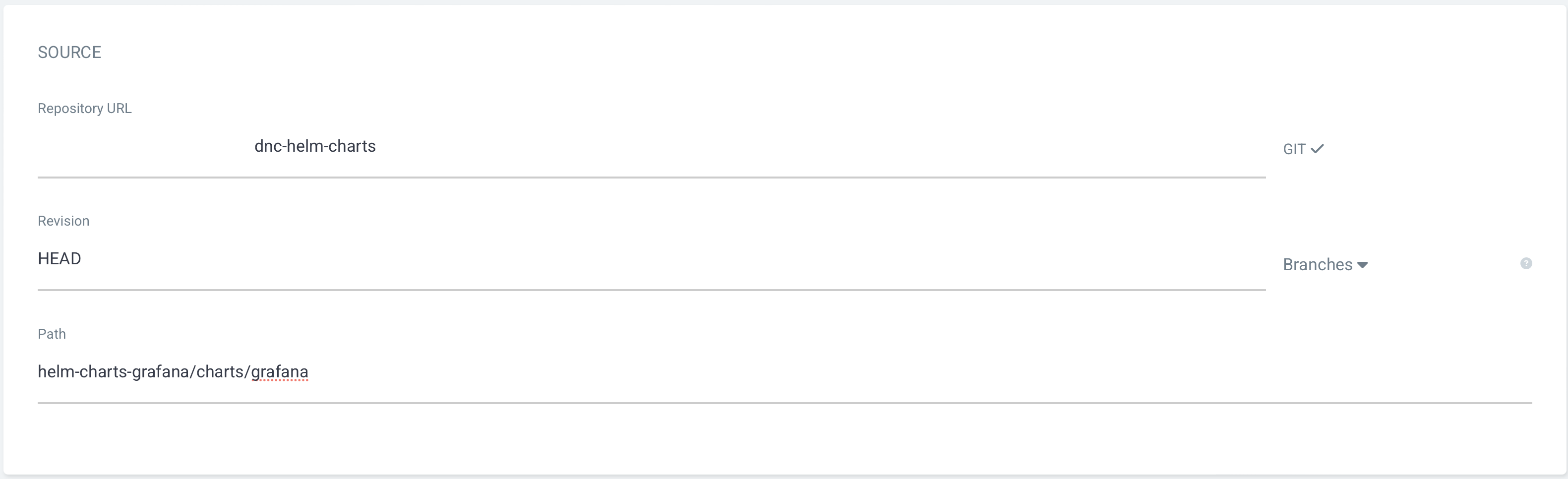
- Grafana Charts 코드가 등록된 GitRepo등록
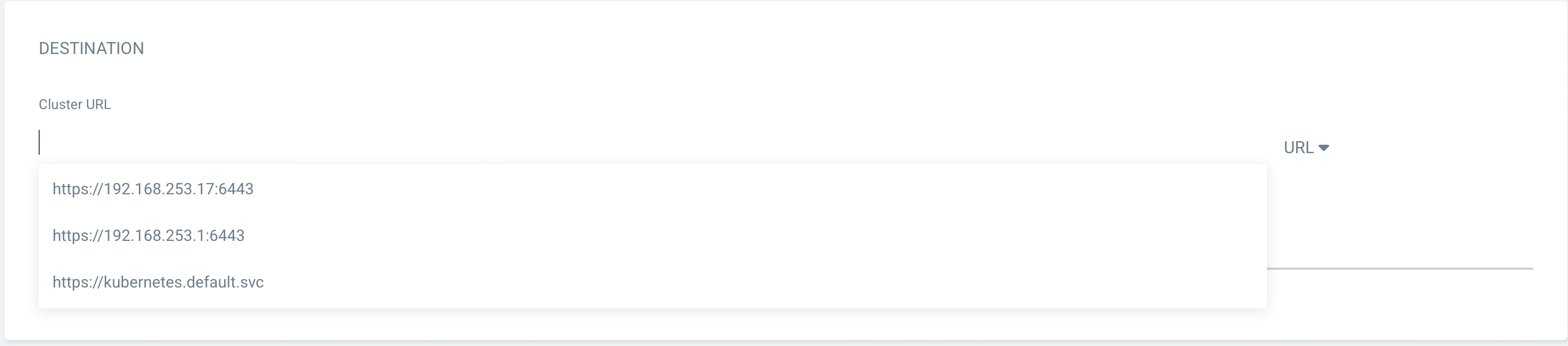
- 배포 할 K8S 클러스터를 지정한다
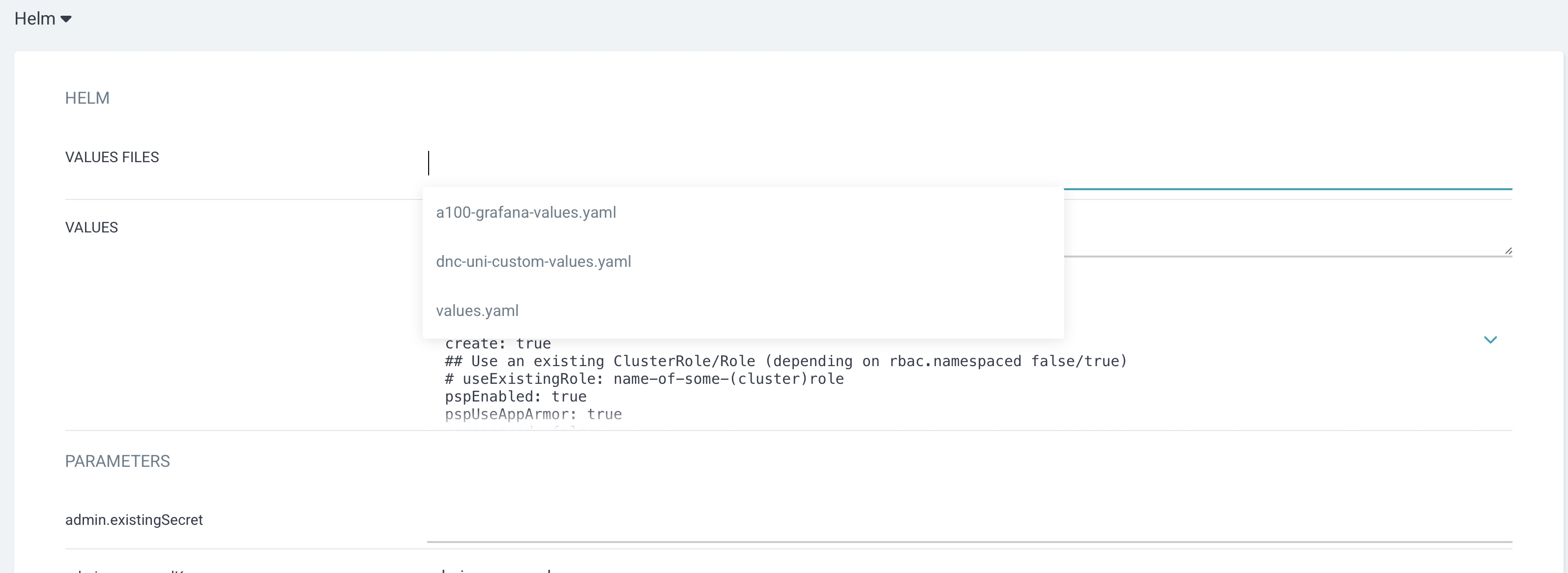
- 클러스터에 맞게 수정된 values.yaml 을 선택한다.
- 정상적으로 배포가 된 것을 확인한다
그라파나 접속 확인
- 배포 된 리소스를 확인 한다
프로메테우스와 함께 배포가 잘 되어 있으며 service/grafana의 NodePort 주소를 확인 후 서비스를 확인한다
$ k get all
NAME READY STATUS RESTARTS AGE
pod/grafana-69c7768484-trpvz 1/1 Running 2 111d
pod/prometheus-alertmanager-5f5d5f956-9zwn7 2/2 Running 2 127d
pod/prometheus-kube-state-metrics-77ddf69b4-2srfh 1/1 Running 1 127d
pod/prometheus-node-exporter-grbm2 1/1 Running 0 126d
pod/prometheus-node-exporter-klfzk 1/1 Running 2 (69d ago) 127d
pod/prometheus-node-exporter-vm6wd 1/1 Running 4 127d
pod/prometheus-pushgateway-969d94d55-tm9f2 1/1 Running 1 127d
pod/prometheus-server-5b87dc7765-gmskr 2/2 Running 3 127d
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/grafana NodePort 10.97.75.149 <none> 80:30001/TCP 154d
service/prometheus-alertmanager NodePort 10.102.238.47 <none> 80:30000/TCP 127d
service/prometheus-kube-state-metrics ClusterIP 10.110.90.234 <none> 8080/TCP 127d
service/prometheus-node-exporter ClusterIP 10.101.239.48 <none> 9100/TCP 127d
service/prometheus-pushgateway ClusterIP 10.98.80.163 <none> 9091/TCP 127d
service/prometheus-server NodePort 10.96.192.234 <none> 80:30002/TCP 127d
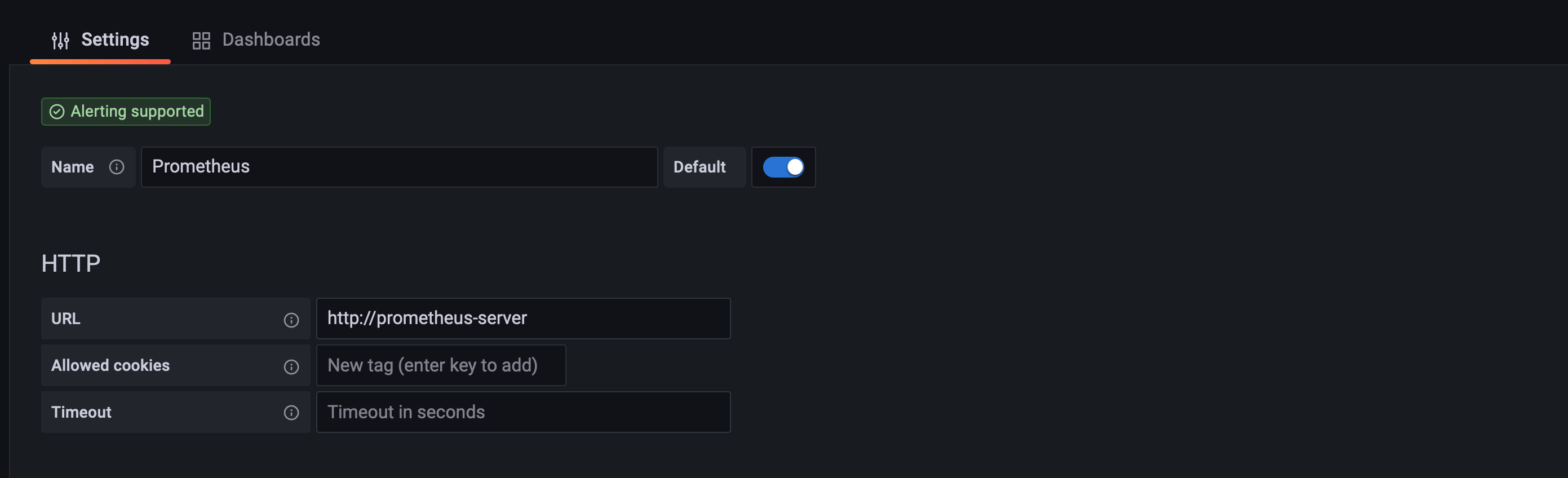
http://{masterNodeIP}:30001 주소를 통해서 정상적으로 그라파나 화면이 동작하는 것을 확인 할 수 있다
초기 아이디와 비번은 admin:admin 이다
참고로 비밀번호를 잊어버려서 초기화가 필요하면 다음과 같은 커멘드로 초기화 할 수 있다
kubectl exec -it grafana-6dc4875968-278jh grafana-cli admin reset-admin-password admin그라파나 데이터 소스 설정
- 그라파나 첫 로그인을 해서 진행해야 할 일은 프로메테우스 서버를 통해서 데이터를 읽어오기 위한 설정이라고 생각한다
왼쪽 하단 메뉴처럼 데이터 소스를 설정 할 수 있는 메뉴가 있다
- Data Sources를 통해서 현재 등록 된 데이터 소스 들을 확인 할 수 있다
현재 회사에선 로키와 프로메테우스 데이터를 활용하고 있음을 확인 할 수 있다
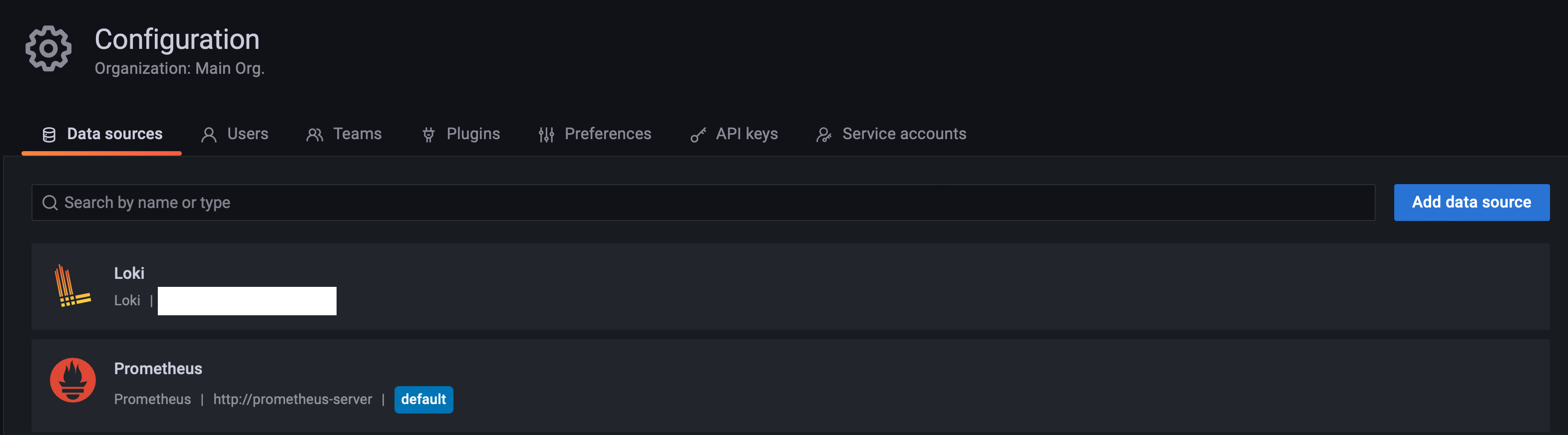
- Add data source를 눌러서 신규 데이터 소스를 등록한다
무료 버전임에도 많은 데이터를 읽어와서 모니터링이 가능하며 이 글에선 프로메테우스 서버를 설정해서 데이터를 얻어오게 설정하겠다.
- 다른 부분들은 기본 설정을 반영해도 되지만 HTTP URL부분은 프로메테우스 서버에 대한 정보를 입력해야 한다
위에 리소스 배포 된 내용을 확인하는 부분에서 프로메테우스 서비스의 cluster-ip를 입력해서 연동 여부를 체크가 할 수 있다.
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/prometheus-server NodePort 10.96.192.234 <none> 80:30002/TCP 127d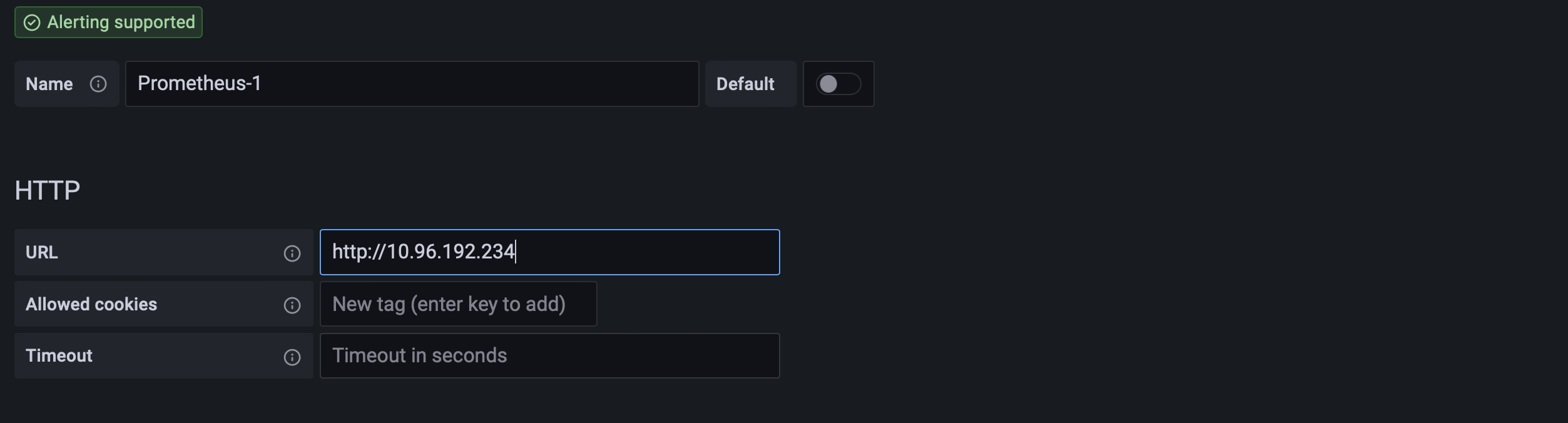

- 같은 클러스터 와 namespace에 있으면 클러스터 IP를 통해서 접근해도 충분히 사용 가능하다
허나 이외 조건의 서버에서 데이터를 얻어오는 부분이 있고 클러스터 IP가 변경되는 경우도 자주 발생 할 수 있기에 클러스터 IP가 아닌 FQDN 도메인을 활용해서 데이터소스를 등록하는 것을 추천한다.
그라파나 대시보드 및 Import 방법
-
그라파나의 여러 장점 중에 하는 다양한 대시보드 마켓이 있고 필요한 서비스나 솔루션에서 나오는 exporter 데이터를 활용한 대시보드 들이 다양하다는 것이다.
이러한 대시보드를 찾아서 import 해서 나에게 필요한 대시보드들을 만들 수 있다
-
kubernetes 관련 대시보드들을 추가해보겠다.
대시보드를 마켓에서 검색한다
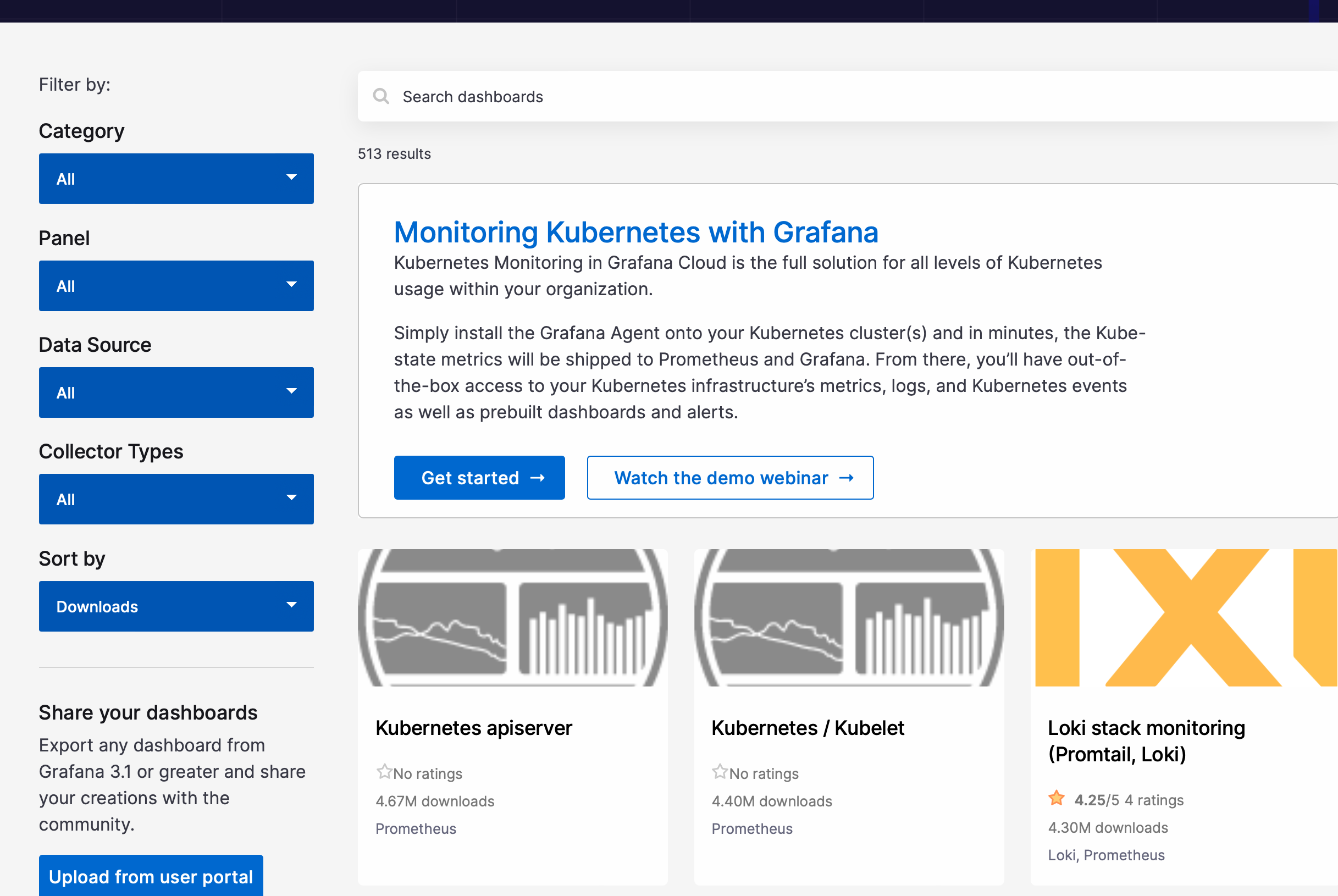
-
필요 대시보드에 들어가서 ID를 확인한다
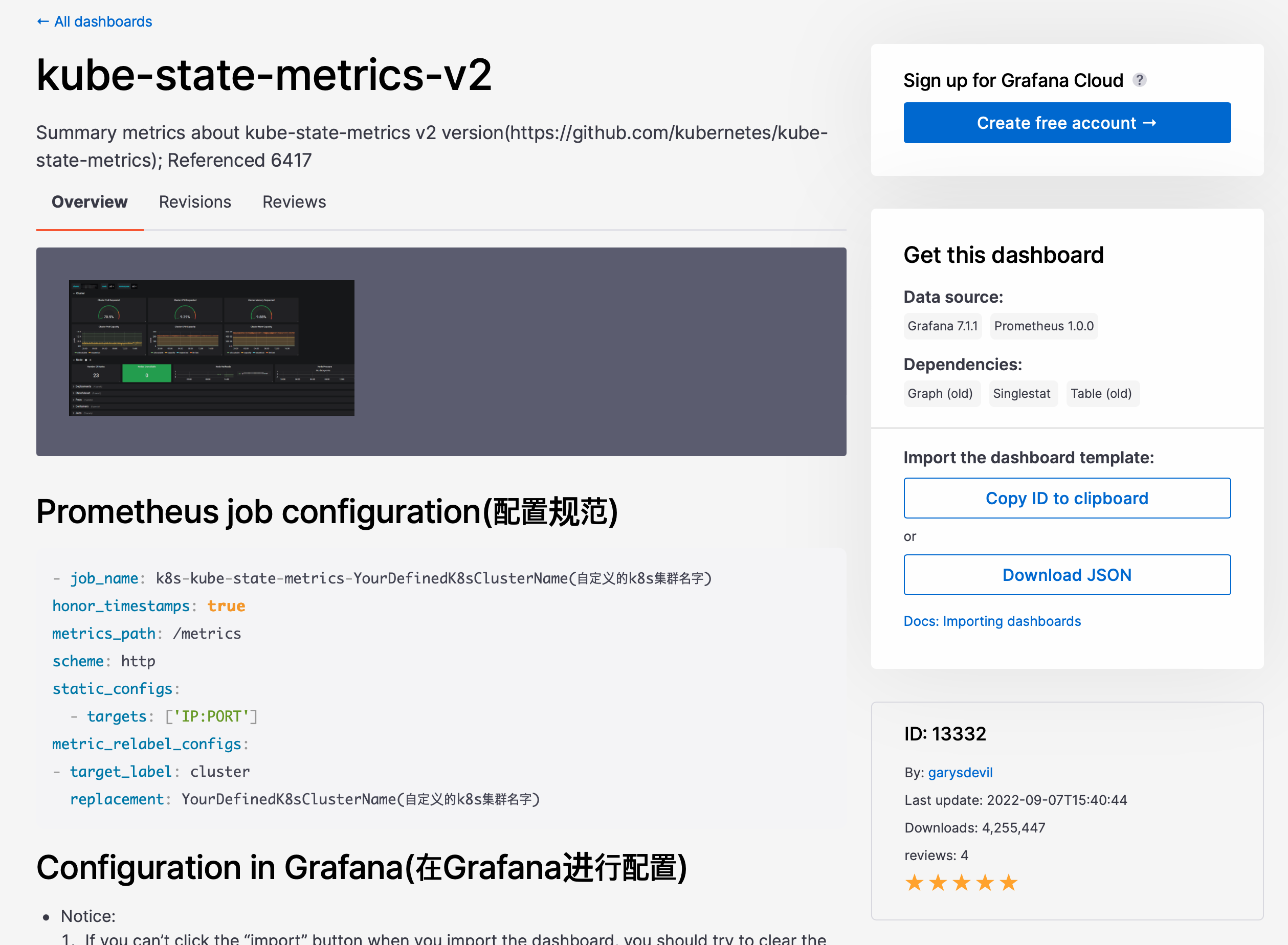
-
Grafana Dashboard import를 클릭한다
-
검색한 ID를 입력 하고 datasource를 선택한다
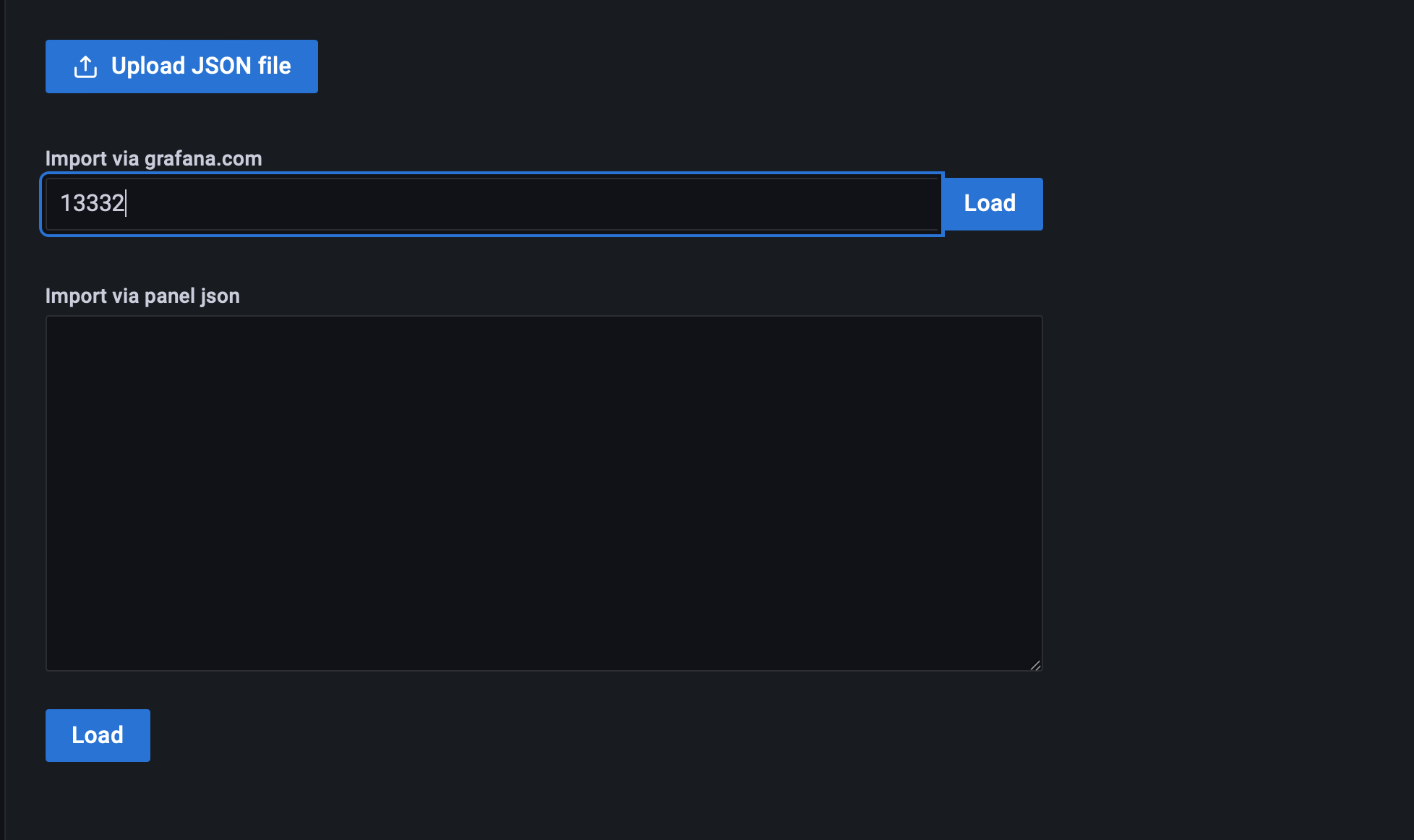
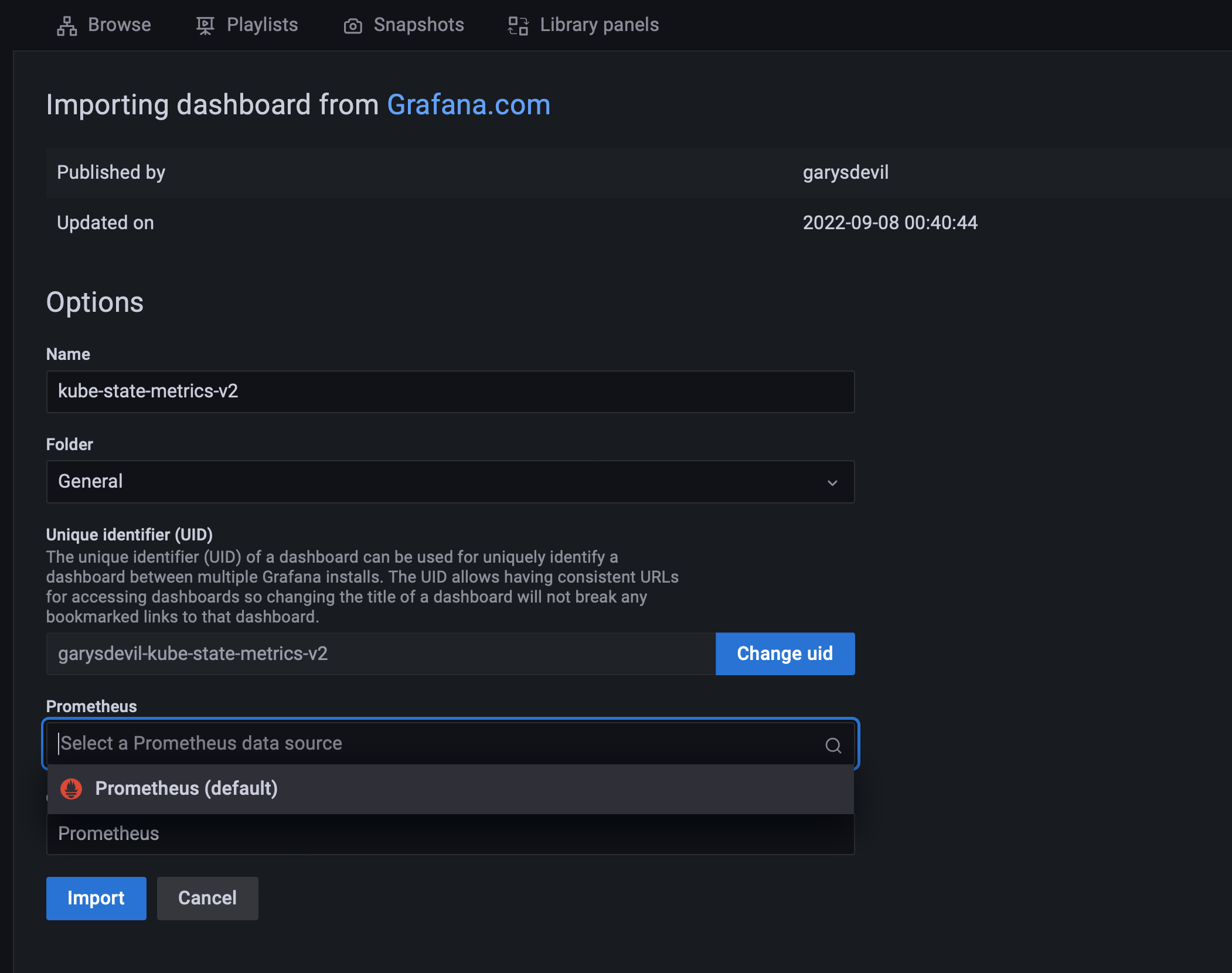
-
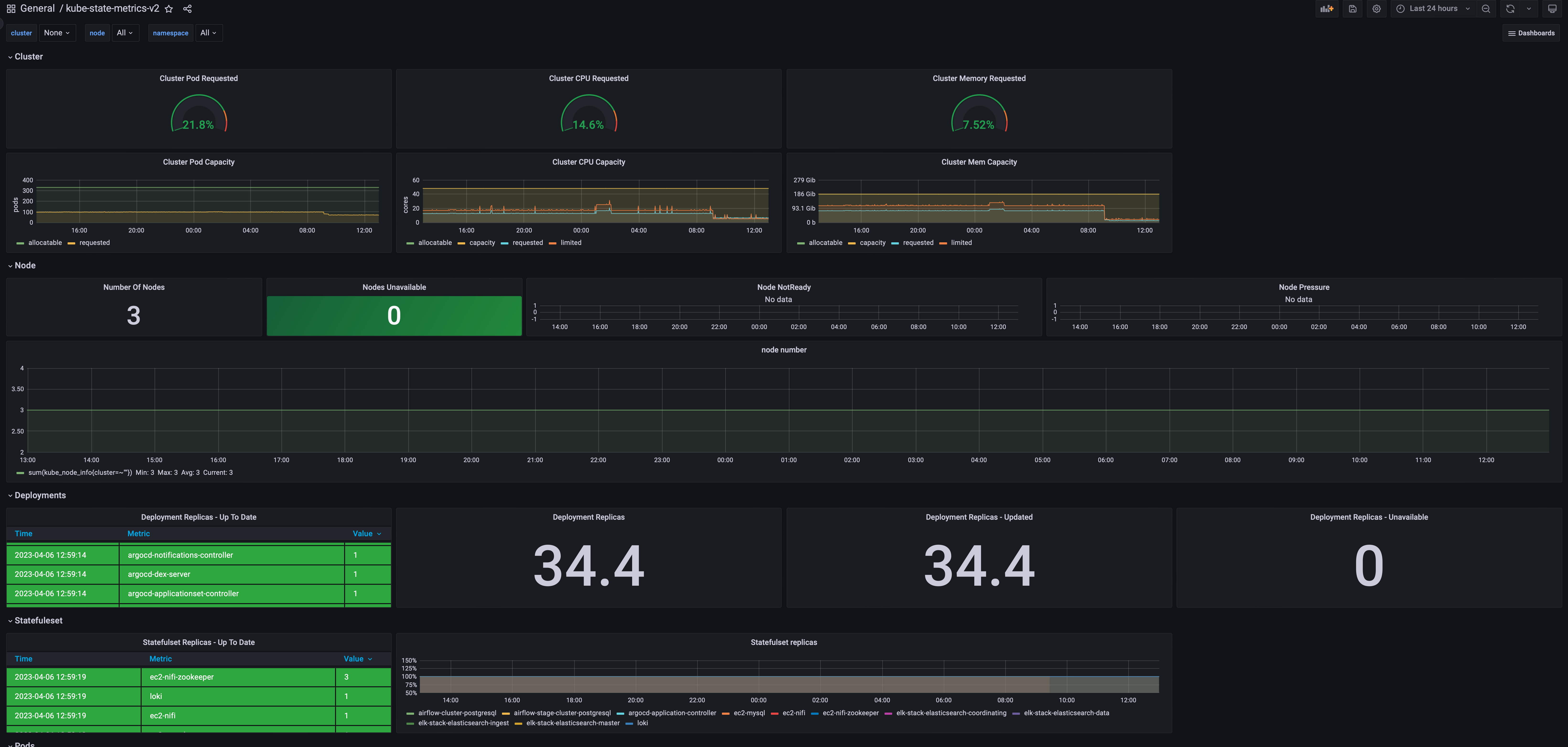
대시보드를 확인한다, 원하는 쿠버네티스 모니터링 대시보드가 추가 되었다.
- 내가 주로 사용하는 DashBoard ID 값이다
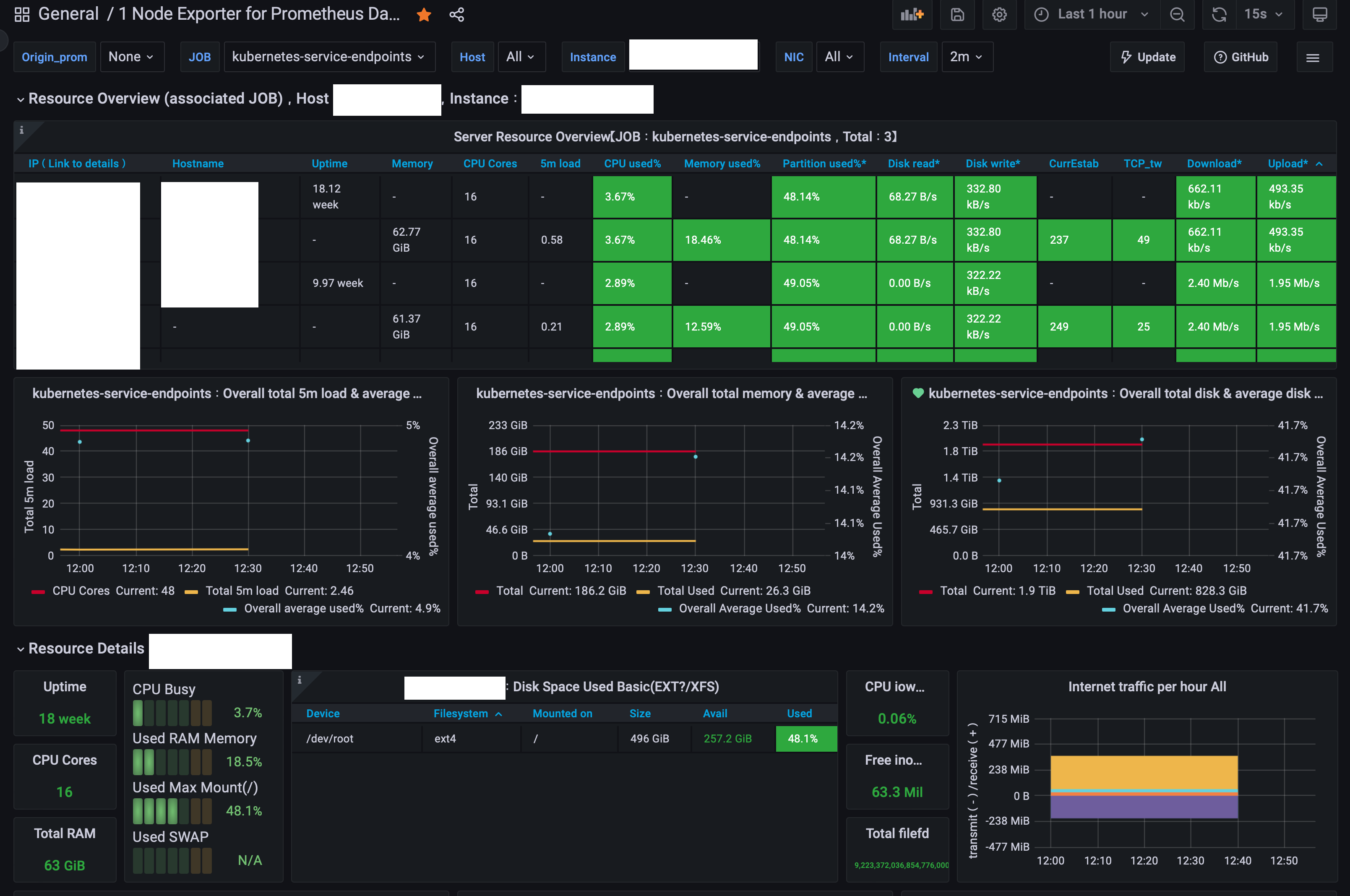
내가 회사에서 사용하는 대시보드은 5가지 정도 된다. Node 대시보드, Kubernetes 대시보드, docker 관련 대시보드, Logs 관련 대시보드들이다
추가적으로 GPU를 운영하는 클러스터 그라파나에선 DCGM 관련 대시보드도 사용한다.
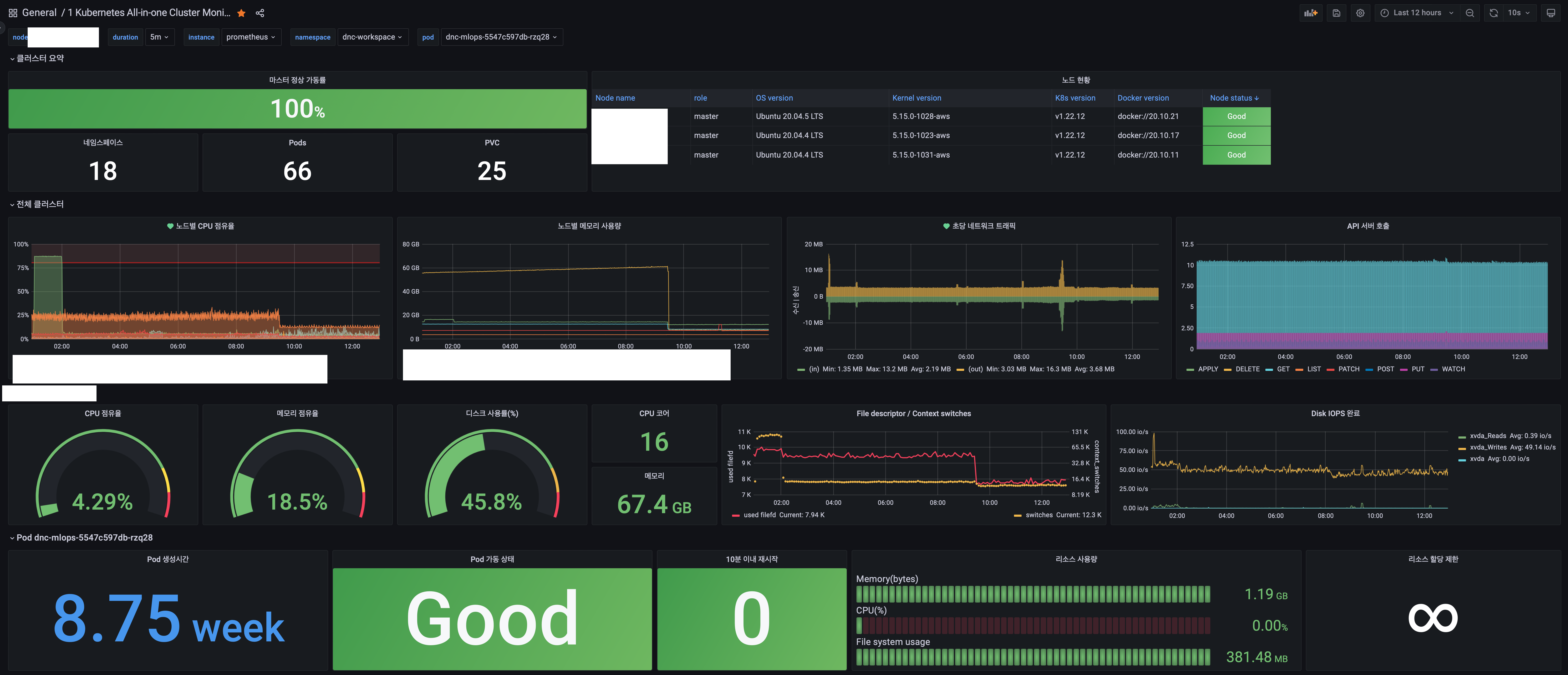
K8S Dashboard : 13770
Loki Dashboard : 13639
Node Dashboard : 11074
Container ashboard : 13946, 14282
DGCM Dashboard : 12239
그라파나 Alert를 활용한 상태 알림 받기
모니터링 시스템에서 가장 중요한 기능 중에 하나가 이상 상황이 발생 했을 때 알림을 받고 조치를 취하게하는 것이다 생각한다
프로메테우스 기능 중에 Alertmanager가 있고 다양한 레퍼런스가 존재하여서 사용하기에 좋지만
이번 포스팅에선 그라파나 기능 중 Alert에 대해서 소개하려고 한다.
절대 Alertmanager 까지의 포스팅이 귀찮아서가 아니다
Alert을 받기 위한 여러 방법이 있겠지만 우리 회사에선 Slack 메신저를 사용하고 있기에 Slack 으로의 알림을 설정하고 동작하는 것을 확인해 보도록 하겠다
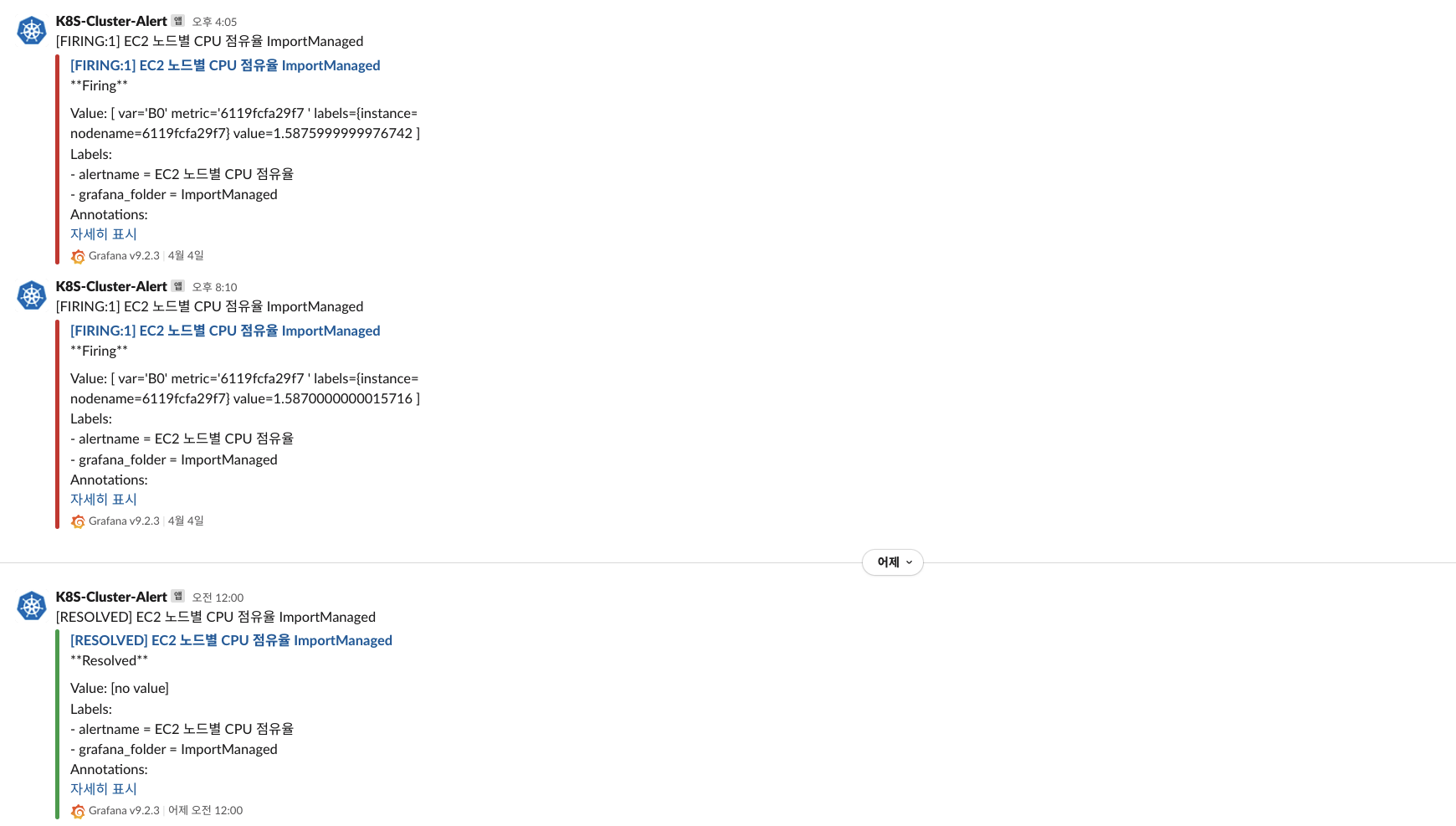
오늘도 많은 알림이 왔고 조치 또는 이슈가 해결 된 이후에 해결 된 알림이 온것을 확인 할 수 있다.
-
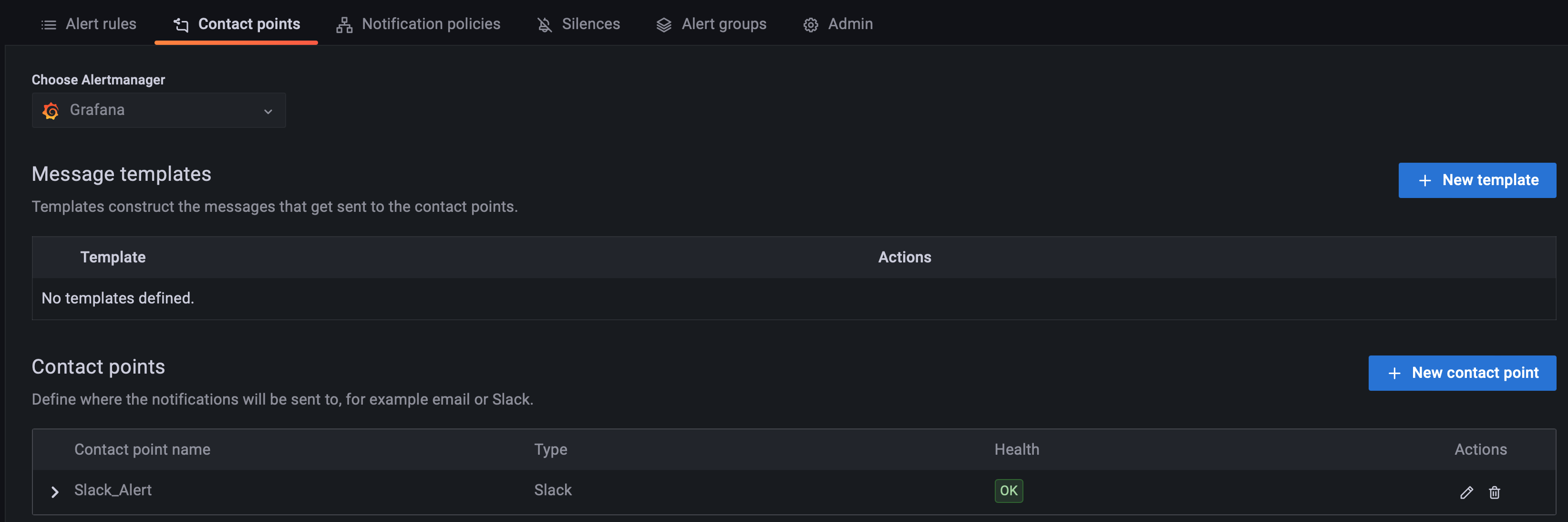
Slack 알림을 위해서 Slack 설정을 진행한다. Alert 메뉴에서 Contact points를 클릭해서 설정 화면으로 들어간다
-
New Contact point를 클릭 후 알림을 받을 chanel에 대한 webhook url을 입력 하도록 한다
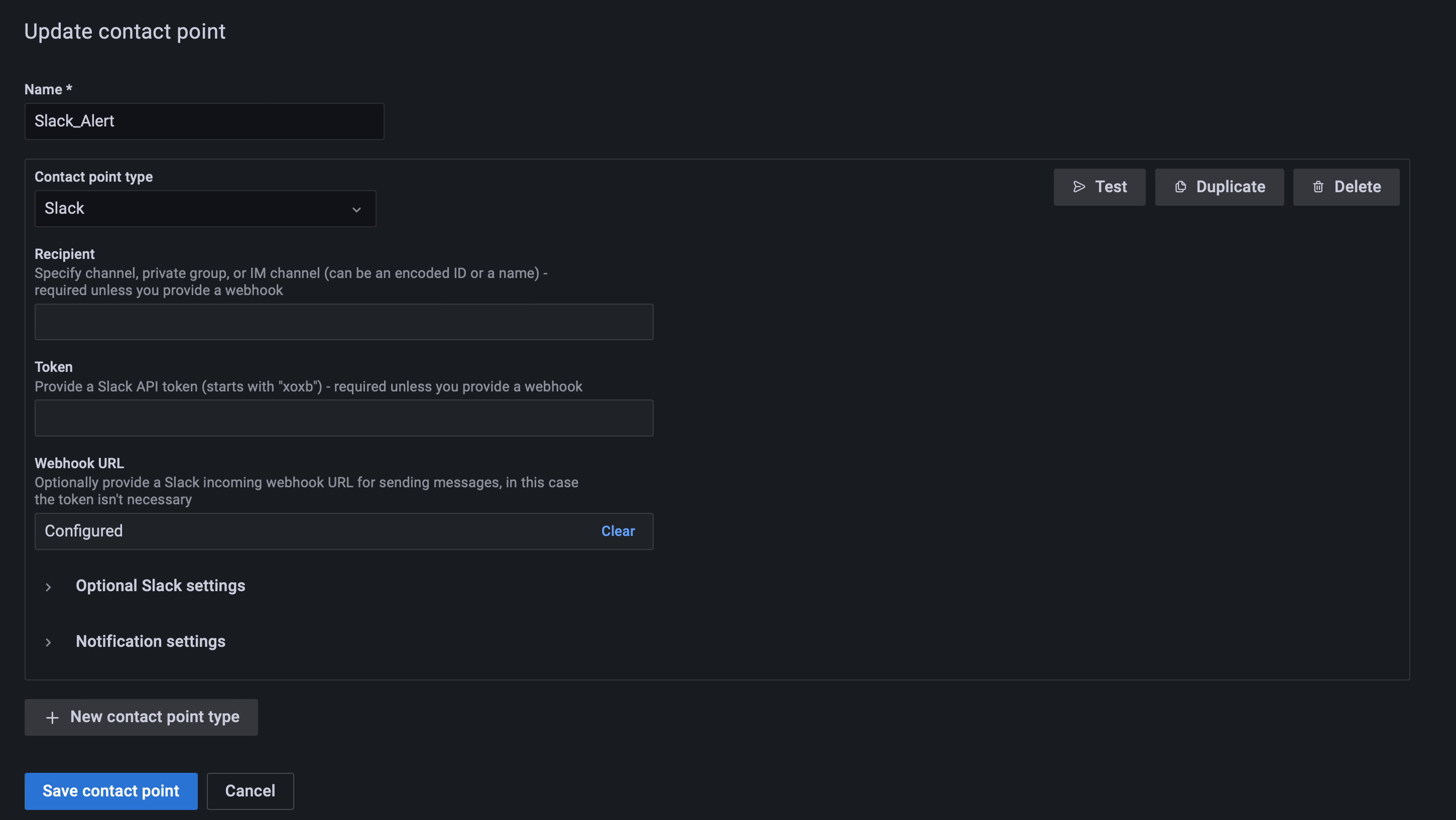
-
입력 후 알림 Test를 진행해 본다
정상적으로 알림이 설정 되고 채널에 전달 되는 것을 확인 할 수 있다.
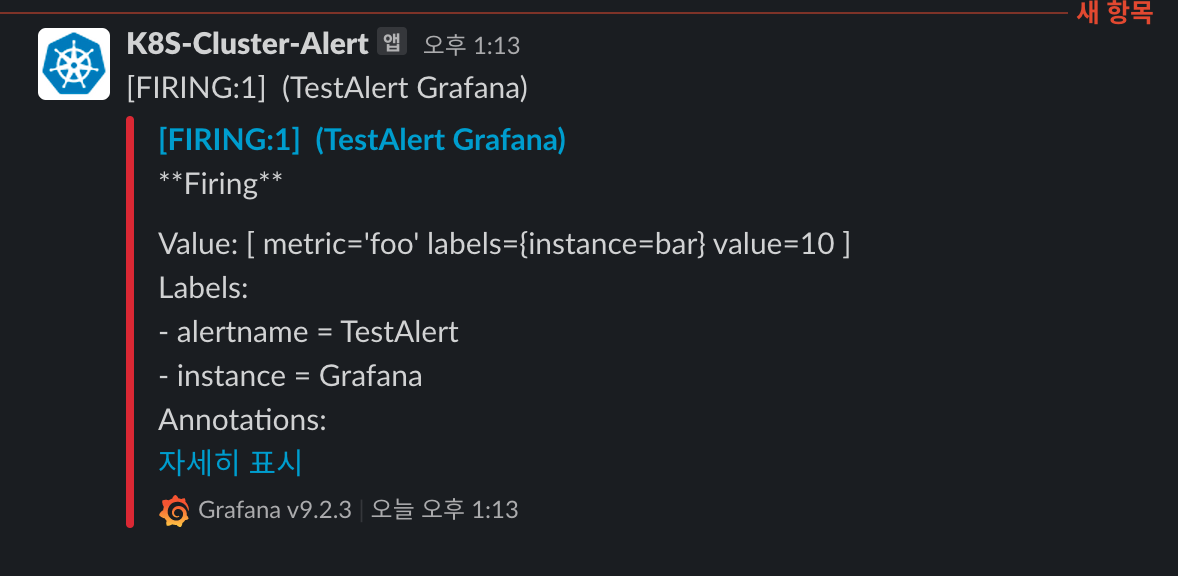
-
이제 대시보드에서 여러 패널 중 알림을 받고자 하는 패널에서 설정을 진행해 보도록 하겠다. 패널 타이틀 부분을 클릭하면 다음과 메뉴가 나오고 Edit 을 클릭하면 패널 설정 화면으로 이동한다.
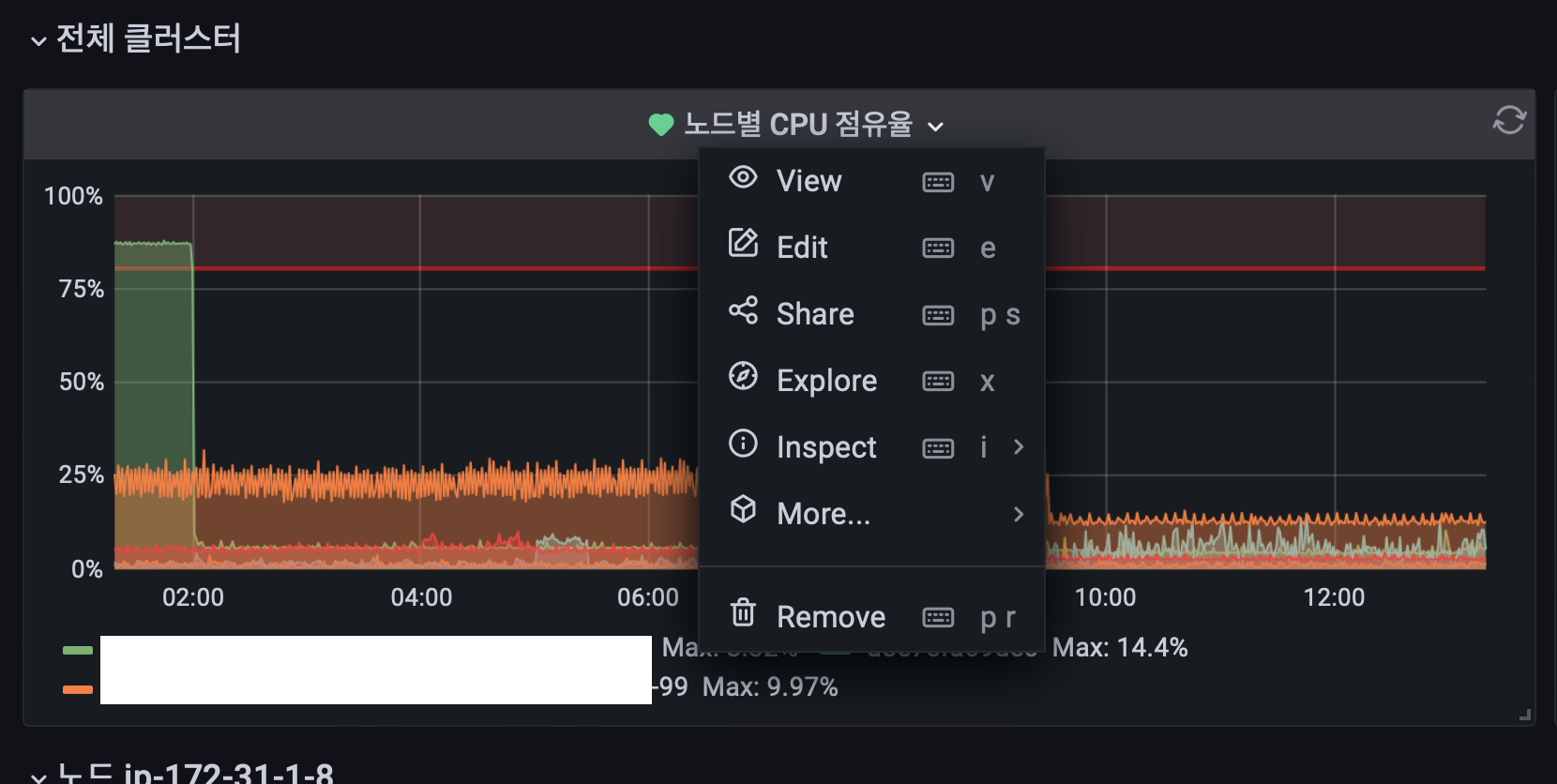
-
패널 설정 화면에서 중간 부분의 Alert 탭을 클릭한다( 이미 설정이 되어 있어서 (1)로 표시가 된다 )
Create alert rule from this panel을 클릭해서 alert의 조건을 설정해 준다
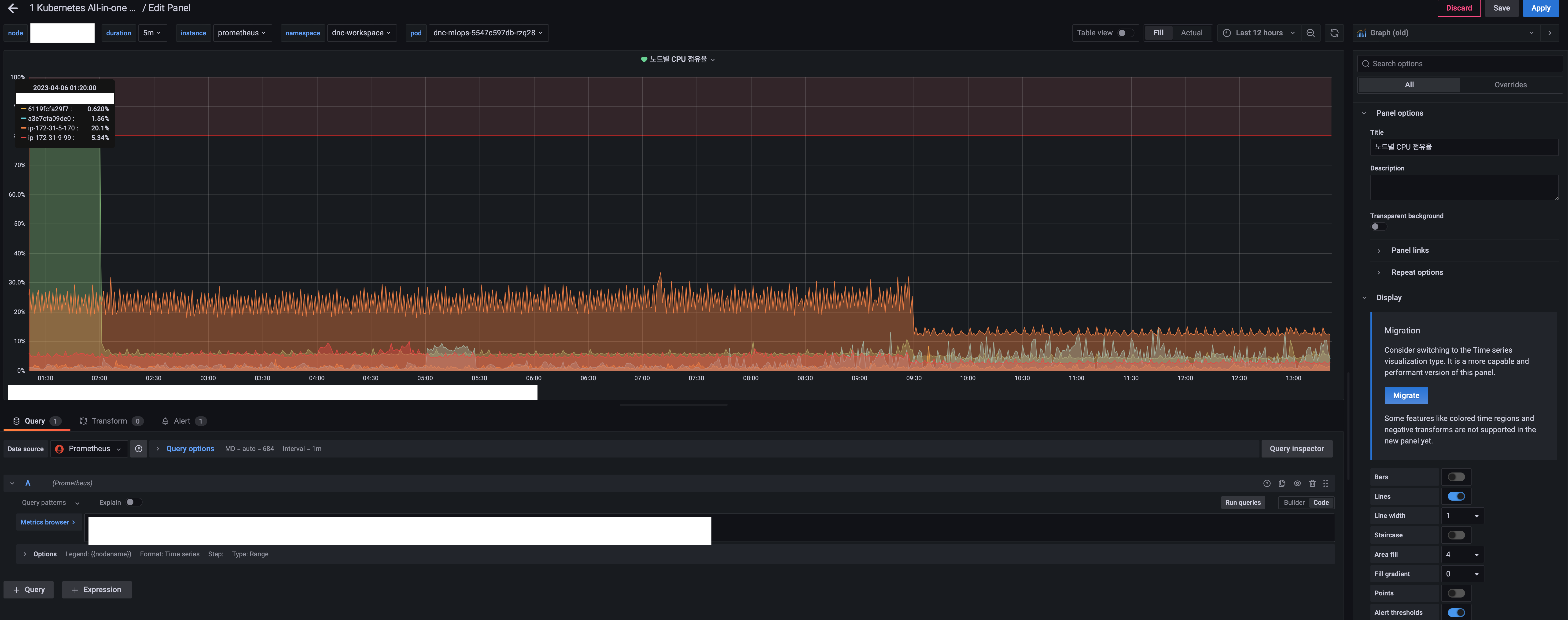
-
패널에서 보여주는 데이터를 기준으로 위험 값 또는 리스크 범주를 지정해서 그 기준에 부합(?) 할 경우 알림이 기존 contact point로 등록된 방식으로 전달 할 수 있다.
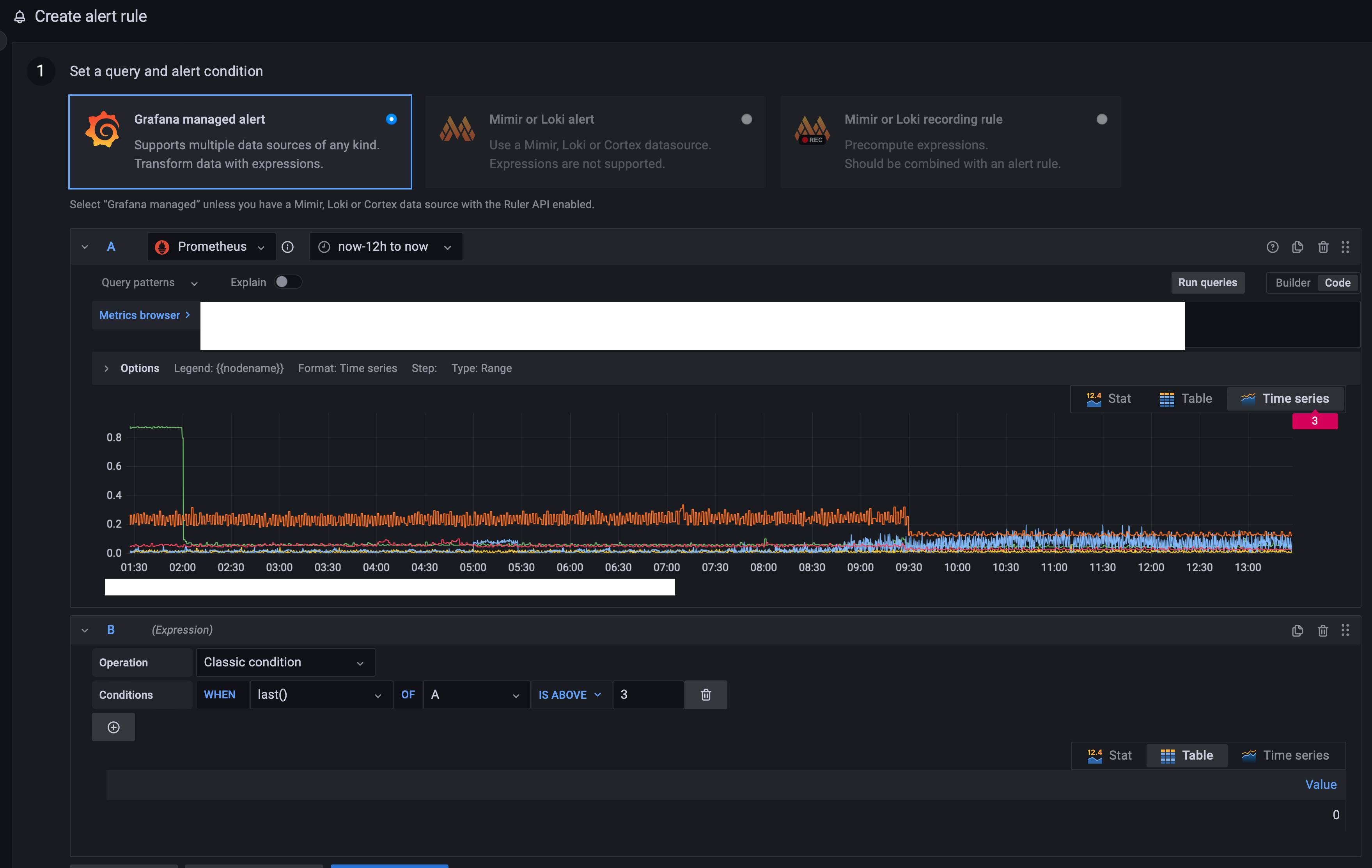
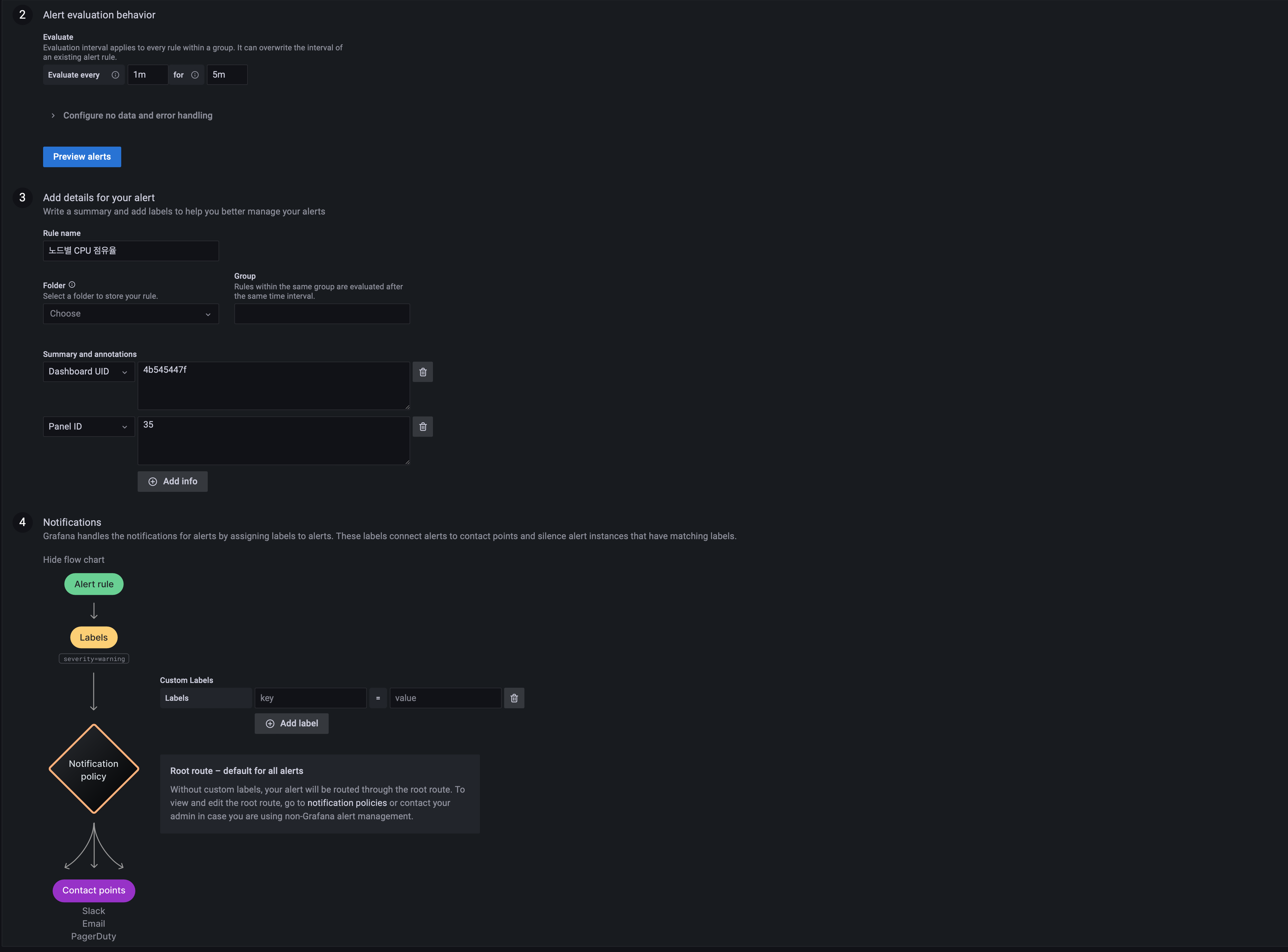
-
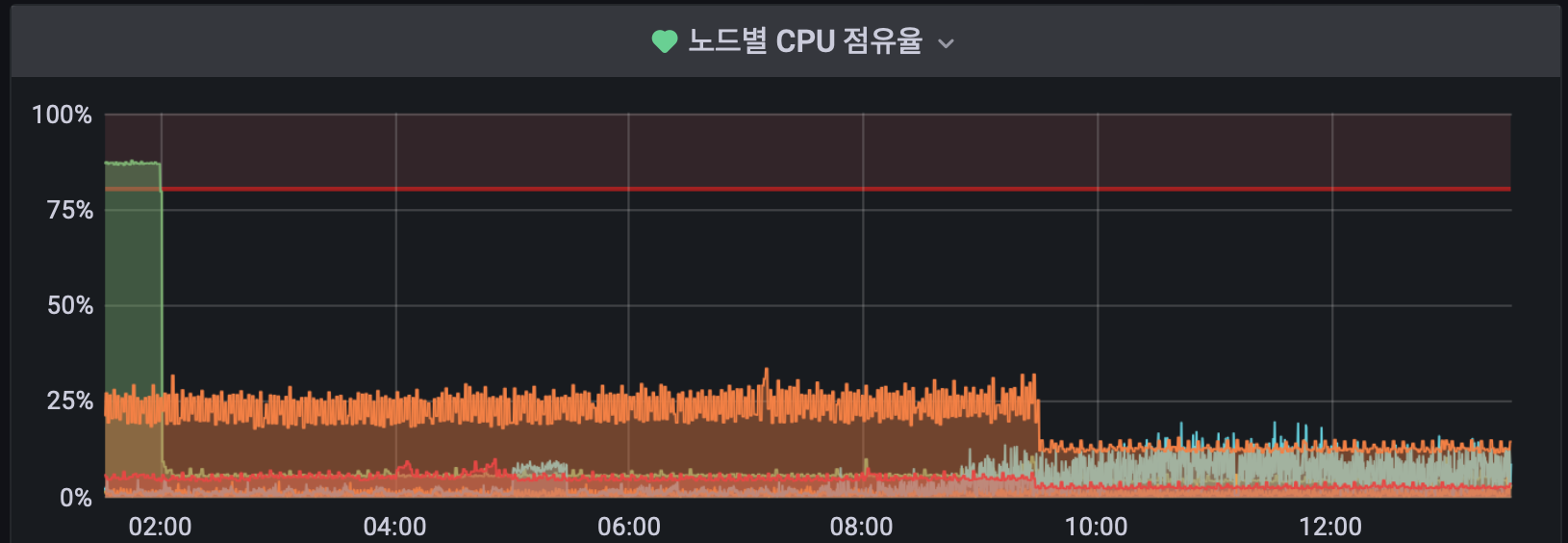
alert설정이 끝나면 대시보드 패널에서 그린 모양의 하트가 추가 된 것을 확인 할 수 있다. 조건이 걸린 패널이며 현재 alert상태가 아님을 표시한다. alert 발생하는 경우 빨간색의 하트가 표시된다
결론
PKOS2기 4주차 스터디를 진행하면서 학습한 내용을 회사에 구축한 시스템을 활용해서 정리해 보았다.
모니터링 시스템은 보안과 함께 회사내에서 꼭 필요한 시스템이라고 생각한다.
스터디를 통해서 더 간편하고 시스템 환경에 맞는 구성 방법에 대해서 스터디 하였고 실습을 진행해 보았다.
오늘 정리 한 위 내용들이 글을 읽고 있는 분들에게 조금이나마 도움이 되었으면 하는 바람이고
유료 시스템도 많지만 다양한 OSS 솔루션을 활용해서 시스템을 구축하는 것도 필요한 경험이라고 생각한다.
참고
