1. Array<Int> vs IntArray
얼마 전 코딩테스트를 준비하는데 가능한 언어가 Kotlin, Swift 뿐이라 열심히 Kotlin으로 코테를 준비하고 있었다. (보통은 파이썬으로 코테를 하는데... 꽤 당황스러웠다.)
그러던 중 의문이 들었던 게 문제에 주어지는 Int형 배열의 자료형이 Array<Int>로 나올 때도 있고 IntArray로 나올 때도 있었다는 것이다.
작동하는 방법 자체는 거의 비슷한 거 같은데 무슨 차이가 있을까? 궁금한 마음에 살펴보기로 했다.
2. 기본형 타입(Primitive Type) vs 참조형 타입(Reference Type)
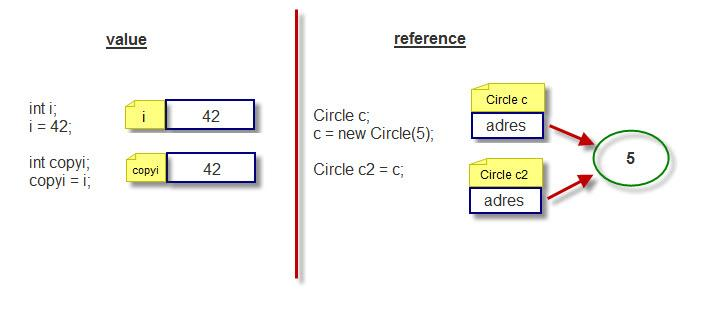
Java 변수에는 크게 2종류가 있다.
바로 기본형 타입(Primitive Type)과 참조형 타입(Reference Type)이다.
기본형 타입에는 논리형(boolean), 문자형(char), 정수형(byte, short, int, long), 실수형(float, double)이 존재한다.
이들 기본형 타입 변수들의 특징은
- 변수의 선언과 동시에 메모리 생성
- 모든 값 타입은 메모리의 스택(stack)에 저장됨
- 저장공간에 실제 자료 값을 가진다
반면에 참조형 타입이란 기본형 타입을 제외한 나머지를 말한다고 보면 된다. 배열, 클래스, 인터페이스 등등 모두 참조형이다.
참조형 타입은 기본형 타입과는 다르게
- 실제 값이 저장되지 않고, 자료가 저장된 공간의 주소를 저장한다.
- 메모리의 힙(heap)에 실제 값을 저장하고, 그 참조값(주소값)을 갖는 변수는 스택에 저장한다.
위 내용을 그림으로 요약하자면 아래와 같다.
3. Wrapper 클래스와 박싱, 언박싱
이처럼 자바 변수는 기본형 타입과 참조형 타입으로 나뉘어져있는데 이로 인해 생길 수 있는 문제가 있다.
예를 들어 특정 메소드가 인수로 객체 타입만을 요구한다면 기본형 타입 변수를 사용할 수 없게 되어버리는 것이다.
또한, 멀티스레드 환경에서 기본형 변수를 동기화 데이터로 사용하려면 이를 객체화해야 할 필요가 있다.
이를 위해서 나온 개념이 바로 Wrapper 클래스이다.
Wrapper 클래스는 자바의 모든 기본형 타입을 값으로 갖는 객체를 생성할 수 있다.
값을 포장하여 해당 값을 갖는 새로운 객체로 만들어준다고 생각하면 이해가 쉬울 것이다.
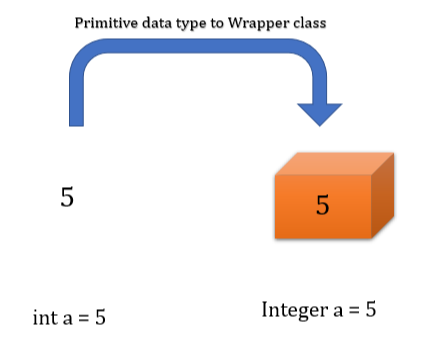
int a = 10; // 기존의 기본형 타입으로 선언
Integer b = new Integer(10); 기본형 타입을 래퍼 클래스를 이용해 객체화기본형 타입과 참조형 타입을 다루다 보면 자연스럽게 위와 같은 객체화 작업을 수행하거나 반대로 객체화된 변수를 다시 기본형 타입으로 값을 꺼내야 할 필요가 생긴다.
이러한 동작을 박싱(boxing), 언박싱(unboxing)이라고 한다.
- 박싱(Boxing): 기본 타입의 데이터 → 래퍼 클래스의 인스턴스로 변환
- 언박싱(UnBoxing): 래퍼 클래스의 인스턴스에 저장된 값 → 기본 타입의 데이터로 변환
이러한 박싱, 언박싱 작업은 당연히 프로그램 실행 시 추가적인 연산 작업을 필요로 하고 지나치게 많은 박싱, 언박싱 작업이 발생할 경우 성능에 영향을 미칠 수 있다.
따라서, 볼륨이 큰 프로그램을 짠다거나 할 때는 박싱, 언박싱 같은 오토 캐스팅(auto casting) 작업이 지나치게 많이 발생하는 건 아닌지 꼼꼼히 살펴봐야한다.
3. 다시 Array<Int> vs IntArray
다시 돌아와서 Kotlin의 Arrat<Int\>와 IntArray 두 배열을 살펴보자. 위에 쭉 설명해서 알겠지만 이 둘의 차이점은 바로 int 정수 타입을 기본형으로 사용하냐 참조형으로 사용하냐의 차이이다.
Kotlin의 Array<Int>는 참조형 타입 변수를 사용하며 자바에서 Integer[] 동일한 개념이라고 볼 수 있다.
한편, IntArray는 기본형 타입 변수를 사용하며 자바의 int[]와 같은 개념이다.
이는 정수형 변수 뿐만 아니라 자바에서 사용되는 모든 기본형 타입으로 존재할 수 있는 변수들에 모두 해당되는 이야기이다.
물론 Array<Int>와 IntArray를 서로 변환하는 것은 어렵지 않다.
Array<Int>는 toIntArray() 메소드를 이용해서 IntArray 타입으로 바꿀 수 있으며 그 반대는 toTypedArray() 메소드를 이용하면 된다.
하지만 위에서도 적었듯이 이러한 박싱, 언박싱 과정은 프로그램 수행 과정에서 오버헤드를 일으키기 때문에 적절하게 사용하는 것이 중요하다.
레퍼런스
1. ☕ JAVA 변수의 기본형 & 참조형 타입 차이 이해하기
2. ☕ 자바 Wrapper 클래스와 Boxing & UnBoxing 총정리
3. 10 Difference between Primitive and Reference variable in Java - Example Tutorial
