
SQL
◻ SQL은 구조화된 쿼리 언어(structured Query Language)의 약자이다.
◻ RDBMS에서 데이터를 CRUD 할 수 있다.
◻ 이러한 RDBMS의 데이터는 정해진 스키마에 따라 DB테이블에 저장되며, 관계를 통해 여러 개의 테이블에 데이터가 분산된다.
+@ 특징
◻ 엄격한 스키마
데이터는 테이블 ROW에 저장되며, 각 테이블에는 명확하게 정의된 구조가 있다.
구조는 컬럼의 이름과 데이터유형으로 정의되며, 이를 어긴다면 RDBMS에 추가 할 수 없다.
◻ 관계
데이터들을 여러개의 테이블에 나눠서 데이터들의 중복을 피할 수 있다.
테이블을 나눠서 데이터를 저장하면, 테이블에서 중복 없이 하나의 데이터만을 관리하기 때문에, 다른 테이블에서 부정확한 데이터를 다룰 위험이 없다는 특징이 있다.
NOSQL
NOSQL 이란?
관계형 DB의 한계점으로 인해 새로운 DB인 NO_SQL이 탄생하였다.
기존 SQL과 반대되는 접근방식을 따르기 때문에 지어진 이름이다.
하지만 NOSQLDB 또는 비관계형 DB로도 관계형데이터를 저장할 수 있다.
특징
유연성 , 확장성 , 고성능 , 가용성
◻ 데이터가 고정되어 있지 않은 DB를 가리킨다.
◻ NOSQL에 스키마가 반드시 없는 것은 아니다.
◻ 유연한 스키마를 제공하며, 대량의 데이터와 높은 사용자 부하에서도 손쉬운 확장이 가능하다.
◻ 관계형 DB에서는 데이터를 입력할 때 스키마에 맞게 입력해야하는 반면, NOSQL에서는 데이터를 읽어올때 스키마에 따라 데이터를 읽어 온다. -> SCHEMA ON READ라 함.
◻ 데이터를 입력하는 방식에 따라, 데이터를 읽어올때 영향을 미친다.
KEY-VALUE 타입
속성을 Key-Value의 쌍으로 나타내는 데이터를 배열의 형태로 저장한다.
여기서 Key는 속성 이름을 뜻하고, Value는 속성에 연결된 데이터 값을 의미한다.
Redis, Dynamo 등이 대표적인 Key-Value 형식의 데이터베이스이다.
문서형(DOCUMENT) 타입
데이터를 테이블이 아닌 문서처럼 저장하는 데이터베이스를 의미한다.
많은 문서형 데이터베이스에서 JSON과 유사한 형식의 데이터를 문서화하여 저장한다.
각각의 문서는 하나의 속성에 대한 데이터를 가지고 있고, 컬렉션이라고 하는 그룹으로 묶어서 관리한다.
대표적인 문서형 데이터베이스에는 MongoDB 가 있다.
WIDE-COLUMN STORE DB
데이터베이스의 열(column)에 대한 데이터를 집중적으로 관리하는 데이터베이스이다.
각 열에는 key-value 형식으로 데이터가 저장되고, 컬럼 패밀리(column families)라고 하는 열의 집합체 단위로 데이터를 처리할 수 있다.
하나의 행에 많은 열을 포함할 수 있어서 유연성을 높다.
데이터 처리에 필요한 열을 유연하게 선택할 수 있다는 점에서 규모가 큰 데이터 분석에 주로 사용되는 데이터베이스 형식이다.
대표적인 wide-column 데이터베이스에는 Cassandra, HBase 가 있다.
그래프(GRAPH)데이터 베이스
자료구조의 그래프와 비슷한 형식으로 데이터 간의 관계를 구성하는 데이터베이스이다.
노드(nodes)에 속성별(entities)로 데이터를 저장한다.
각 노드간 관계는 선(edge)으로 표현한다.
대표적인 그래프 데이터베이스에는 Neo4J, InfiniteGraph 가 있다.
SQL VS NOSQL
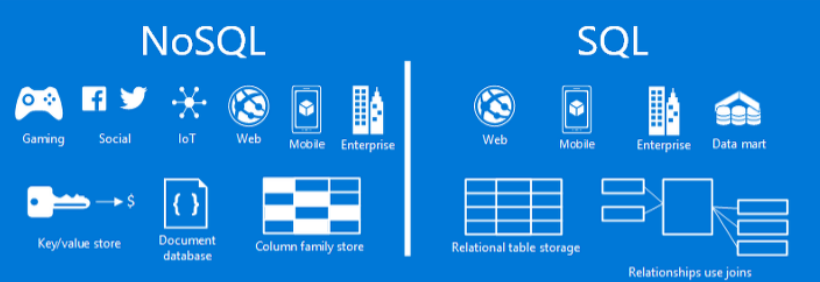
SQL 과 NOSQL의 차이
◻ 데이터 저장(storage)
NoSQL은 KEY-VALUE, DOCUMENT,WIDE-COLUMN ,GRAPH등의 방식으로 데이터를 저장한다.
관계형 데이터베이스는 SQL을 이용해서 데이터를 테이블에 저장한다.
미리 작성된 스키마를 기반으로 정해진 형식에 맞게 데이터를 저장해야한다.
◻ 스키마(Schema)
SQL을 사용하려면, 고정된 형식의 스키마가 필요하다.
다시 말해, 처리하려는 데이터 속성별로 열(column)에 대한 정보를 미리 정해두어야 한다.
스키마는 나중에 변경할 수 있지만, 이 경우 데이터베이스 전체를 수정하거나 오프라인(down-time)으로 전환할 필요가 있다.
NoSQL은 관계형 데이터베이스보다 동적으로 스키마의 형태를 관리할 수 있다.
행을 추가할 때 즉시 새로운 열을 추가할 수 있고, 개별 속성에 대해서 모든 열에 대한 데이터를 반드시 입력하지 않아도 된다.
◻ 쿼리(Querying)
쿼리는 데이터베이스에 대해서 정보를 요청하는 질의문이다.
관계형 데이터베이스는 테이블의 형식과 테이블간의 관계에 맞춰 데이터를 요청해야 한다.
그래서 정보를 요청할 때, SQL과 같이 구조화된 쿼리 언어를 사용한다.
비관계형 데이터베이스의 쿼리는 데이터 그룹 자체를 조회하는 것에 초점을 두고 있다.
그래서 구조화 되지 않은 쿼리 언어로도 데이터 요청이 가능하다.
UnQL(UnStructured Query Language)이라고 말하기도 한다.
◻ 확장성(Scalability)
일반적으로 SQL 기반의 관계형 데이터베이스는 수직적으로 확장하다.
높은 메모리, CPU를 사용하는 확장이라고도 한다.
데이터베이스가 구축된 하드웨어의 성능을 많이 이용하기 때문에 비용이 많이 든다.
여러 서버에 걸쳐서 데이터베이스의 관계를 정의할 수 있지만, 매우 복잡하고 시간이 많이 소모된다.
NoSQL로 구성된 데이터베이스는 수평적으로 확장한다.
보다 값싼 서버 증설, 또는 클라우드 서비스 이용하는 확장이라고도 한다.
NoSQL 데이터베이스를 위한 서버를 추가적으로 구축하면, 많은 트래픽을 보다 편리하게 처리할 수 있다.
그리고 저렴한 범용 하드웨어나 클라우드 기반의 인스턴스에 NoSQL 데이터베이스를 호스팅할 수 있어서, 수직적 확장보다 상대적으로 비용이 저렴하다.
| 항목 | NOSQL | 관계형 DB |
|---|---|---|
| 데이터모델 | - 서비스에 맞는 DB선택이 중요함 | - 엔티티 및 각 엔티티 간 관계를 정의함 |
| - 반 정규화에 의한 설계를 기본 | - 엔티티 정의 시 정규화에 의한 설계가 중요 | |
| - 비정형화 스키마 구조로 미리 스키마선언X | - DB요소에 대한 스키마를 엄격히 관리 | |
| 성능 | - 클러스터 크기,네트워크 및 애플리케이션에 의해 성능이결정 | - 성능 향상을 위해서는 성능 최적화 작업이 필요하다. |
| 인터페이스 | -쿼리 외 다양한 API를 통한 데이터 저장 및 검색이 가능 | -SQL을 통해서만 데이터 저장 및 검색이 가능하다. |
| 장점 | -쿼리 프로세싱이 단순화되어 대용량 데이터 처리 성능이 향상됨. | - 데이터 중복 배제로 데이터 이상 발생 및 용량 증가를 최소화함. |
| 단점 | -데이터 중복에 의해 데이터일관성이 저하되고 용량이증가 | -조인이 복잡한 경우 쿼리 프로세싱도 복잡해져 성능이 저하된다. |
참고
https://hanamon.kr/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4-sql-vs-nosql/
