가상 메모리 개념
메모리?
메모리란 프로그램과 프로그램 수행에 필요한 데이터 및 코드를 저장하는 장치임.
메모리는 크게 내부 기억장치인 주기억장치와 외부 기억장치인 보조 기억장치로 분류됨.
DRAM(RAM, DDR4) 등의 메모리, CPU 안에 있는 레지스터(register)와 캐쉬(cache memory) 등이 전자에 해당됨.
SSD, HDD 등이 후자에 해당됨.
가상 메모리란?
가상 메모리는 메모리가 실제 메모리보다 많아 보이게 하는 기술로, 어떤 프로세스가 실행될 때 메모리에 해당 프로세스 전체가 올라가지 않더라도 실행이 가능하다는 점에 착안하여 고안되었음.
가상 메모리를 구현하기 위해서는 컴퓨터가 특수 메모리 관리 하드웨어를 갖추고 있어야만 한다. 💨 바로 MMU(Memory Management Unit)!
◻ MMU는 가상주소를 물리주소로 변환하고, 메모리를 보호하는 기능을 수행함.
◻ MMU를 사용하게 되면, CPU가 각 메모리에 접근하기 이전에 메모리 주소 번역 작업이 수행됨.
◻ 그러나 메모리를 일일이 가상 주소에서 물리적 주소로 번역하게 되면 작업 부하가 너무 높아지므로, MMU는 RAM을 여러 부분(페이지, pages)로 나누어 각 페이지를 하나의 독립된 항목으로 처리함.
◻ 페이지 및 주소 번역 정보를 기억하는 작업이 가상 메모리를 구현하는 데 있어 결정적인 절차임.
가상 메모리의 크기
✅ 가상 메모리의 크기
이론적으로 가상 메모리는 무한대의 크기이다. 그렇지만 실제로 가상 메모리의 최대 크기는 그 컴퓨터 시스템이 가진 물리 메모리의 최대 크기로 한정되며 CPU의 비트에 따라 결정된다.
◻ 가상 메모리에서 메모리 관리자가 사용할 수 있는 메모리의 전체 크기
💨 물리 메모리 + 스왑 영역
✅ 가상 메모리의 주소
가상 메모리 시스템의 모든 프로세스는 물리 메모리와 별개로 자신이 메모리의 어느 위치에 있는지 상관없이 0번지부터 시작하는 연속된 메모리 공간을 가진다.
◻ 동적 주소 변환
💨 가상 주소를 실제 메모리의 물리 주소로 변환
◼ 가상 메모리의 메모리 분할 방식
- 세그먼테이션 기법 (가변 분할 방식)
- 페이징 기법 (고정 분할 방식)
- 세그먼테이션 - 페이징 혼용 기법
페이징 기법과 페이지 테이블 매핑 방식
고정 분할 방식을 이용한 가상 메모리 관리 기법으로, 물리 주소 공간을 같은 크기로 나눠 사용한다.
💨 가상 주소의 분할된 각 영역은 페이지라 한다.
💨 물리 메모리의 영역은 프레임이라 한다.
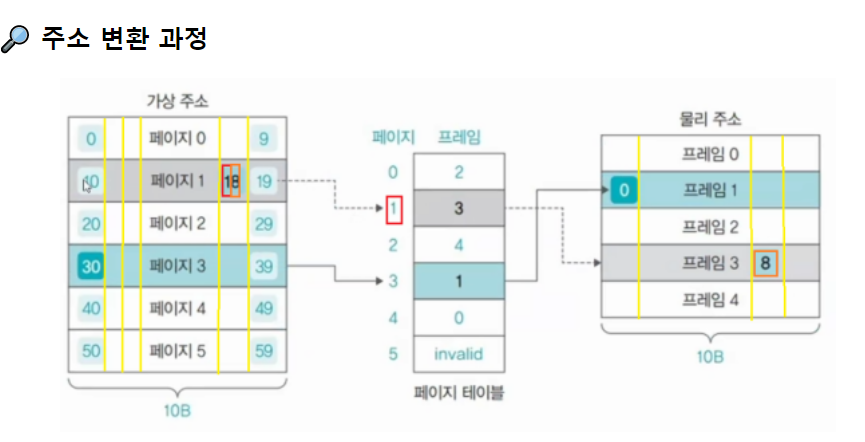
정형화된 주소 변환
가상 주소를 VA = <P, D>로 표현한다.
◻ VA는 가상 주소
◻ P는 페이지
◻ D는 페이지 처음 위치에서 해당 주소까지의 거리
🎈 페이징 기법의 주소 변환 과정
VA = <P,D> ➡ PA = <F,D>
페이지 테이블
시스템 내에는 여러 개의 프로세스가 존재하고, 각 프로세스는 하나의 페이지 테이블을 가지며, 페이지 테이블은 운영체제 영역에 있다. 따라서 페이지 테이블의 크기가 너무 커지면 프로세스가 실제로 사용할 수 있는 메모리영역이 줄어든다.
페이지 테이블 전체를 메모리에서 관리하느냐, 일부를 스왑 영역에서 관리하느냐에 따라 가상 주소를 물리 주소로 변환하는 방법이 달라진다.
💨테이블 매핑 방식
◻ 직접 매핑
◻ 연관 매핑
◻ 집합-연관 매핑
◻ 역 매핑
- 직접 매핑
페이지 테이블 전체가 운영체제 영역에 있는 경우 직접 매핑을 진행한다.
◻ 이 경우 별다른 부가 작업 없이 바로 주소 변환이 가능하여 직접 매핑이라고 한다
◻ 변환 속도가 가장 빠르다
◻ 페이지 테이블의 시작 주소는 페이지 테이블 기준 레지스터(PTBR)가 가지고 있다
- 연관 매핑
페이지 테이블 전부를 스왑 영역에서 관리하는 경우 연관 매핑을 진행한다.
◻ 일부 테이블만 무작위로 물리 메모리에 가져오는 방식이다
◻ 원하는 프레임 번호가 있다면 페이지 테이블을 다 검색해야 한다
◻ 캐시 시스템과 매우 유사하다
- 집합-연관 매핑
연관 매핑의 문제를 개선한 방식으로 페이지 테이블을 하나 더 생성한다.
◻ 일정한 묶음으로 모아놓아 디렉터리 매핑이라고도 부른다
◻ 전체 테이블은 스왑 영역에 존재한다
◻ 일부 테이블은 묶음 단위로 메모리에 존재한다
- 역 매핑
앞 세 가지 매핑과 반대로 페이지 테이블을 구성하는 방식이다.
◻ 앞 세 가지(직접, 연관, 집합-연관) 매핑에선 페이지 번호를 기준으로 테이블 구성
◻ 역 매핑에서는 물리 메모리의 프레임 번호를 기준으로 테이블 구성
◻ 실제 프레임 수와 행의 수가 같다
세그멘테이션 기법과 주소 변환 방식
가상 메모리를 서로 크기가 다른 논리적 단위인 세그먼트(Segment)로 분할
가변 분할 방식을 이용한 가상 메모리 관리 기법으로, 물리 메모리를 프로세스의 크기에 따라 가변적으로 나누어 사용한다.
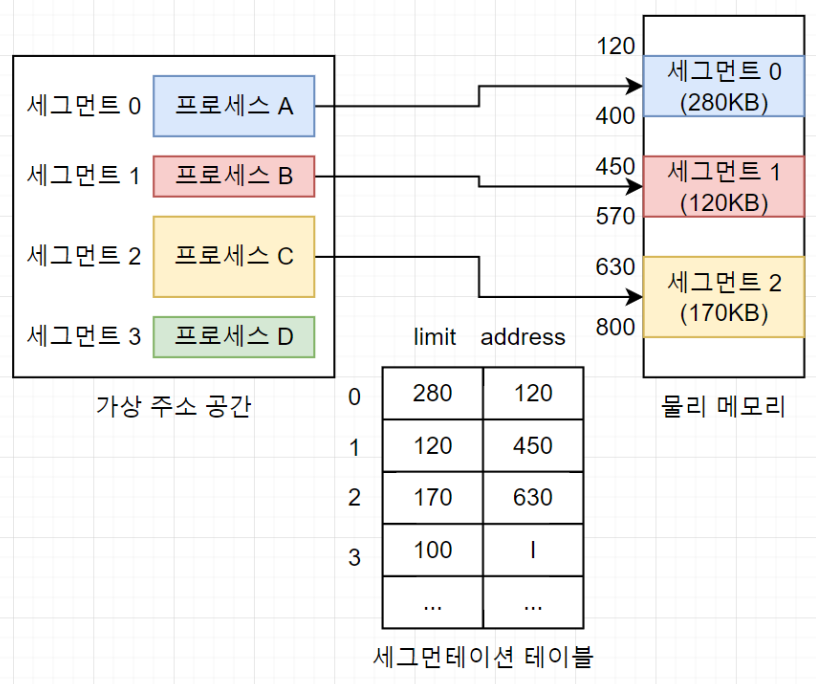
세그먼테이션 테이블에는 세그먼테이션 크기를 나타내는 limit와 물리 메모리 상의 시작 주소를 나타내는 address가 있다.
페이징 기법에서는 메모리를 같은 크기의 페이지 단위로 분할하기 때문에 매핑 테이블에 크기 정보를 유지할 필요가 없다.
하지만 세그먼테이션 기법에서는 프로세스의 크기에 따라 메모리를 분할하기 때문에 매핑 테이블에 크기 정보를 포함한다.
각 세그먼트가 자신에게 주어진 메모리 영역을 넘어가면 안되기 때문에 세그먼트의 크기 정보에는 크기를 뜻하는 'size'대신 제한을 의미한 'limit'을 사용한다.
세그먼테이션 기법의 주소 변환
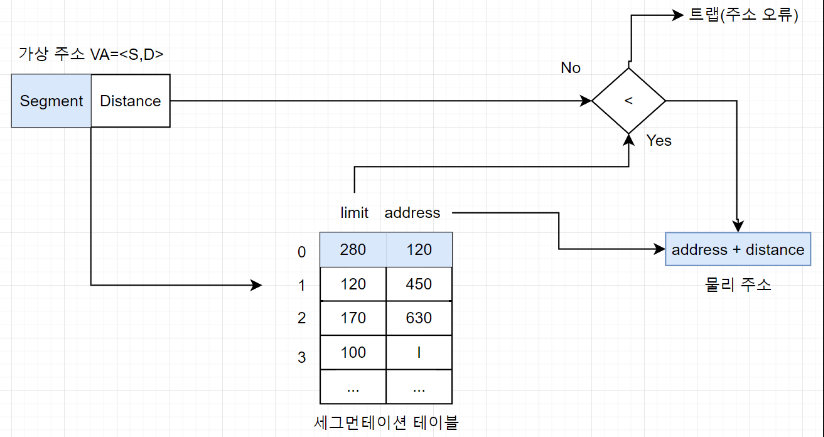
세그먼테이션 기법에서는 가상 주소를 VA=<S,D>로 표현한다.
여기서 S는 세그먼트 번호(segment number), D는 세그먼트 시작 지점에서 해당 주소까지의 거리(address)를 의미한다.
가상 메모리 시스템에서 사용자에게 보이는 메모리는 항상 0부터 시작하므로 페이징 기법이든 세그먼테이션 기법이든 D는 사용자가 지정한 주소 그 자체이다
-
먼저 가상 주소를 구한다. 프로세스 A는 세그먼트 0으로 분할되었으므로, S는 0이고, D는 32이다. 따라서 가상 주소는 VA=<0,32>이다.
-
세그먼테이션 테이블에서 세그먼트 0의 시작 주소를 알아낸 후 시작 주소 120에 거리 32를 더하여 물리 주소 152번지를 구한다. 이떄 메모리 관리자는 거리가 세그먼트의 크기보다 큰 지 검사한다. 만약 크다면 메모리를 벗어나는 것이므로 메모리 오류를 출력하고 해당 프로세스를 강제 종료한다. 크지 않다면 물리 주소를 구한다.
-
물리 주소 152번지에 접근하여 원하는 데이터를 읽거나 쓴다.
세그먼테이션-페이징 혼용 기법
페이징 기법과 세그먼테이션 기법은 각각 장단점을 가지고 있다. 페이징 기법은 물리 메모리를 같은 크기로 나누어 관리하기 때문에 메모리 관리가 수월한 반면 페이지 테이블의 크기가 크다. 또한 세그먼테이션 기법은 페이지 테이블의 크기를 작게 유지할 수 있으냐 물리 메모리의 외부 단편화로 인해 추가적인 관리가 불가피하다. 세그먼테이션-페이징 혼용 기법은 이 두 기법의 장점만 취한 가상 메모리 관리 기법이다.
메모리 접근 권한
메모리 접근 권한은 메모리의 특정 번지에 저장된 데이터를 사용할 수 있는 권한이다.
읽기(read), 쓰기(write), 실행(execute), 추가(append) 권한이 있으며, 복합적으로 사용된다.
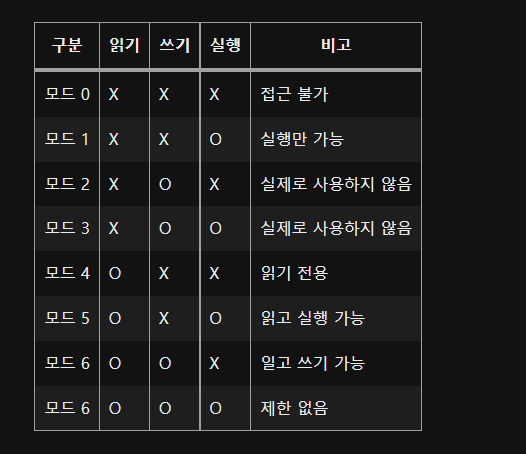
이론상으로는 네 가지 메모리 접근 권한을 모두 조합하면 16(2^4)가지 메모리 제어 방식(access control modes)이 나온다. 그러나 추가 권한의 경우 해당 데이터의 마지막에 새로운 데이터를 추가하는 것이므로 항상 쓰기 권한이 동반되어야 한다. 즉 쓰기 권한 없이 추가 권한을 사용할 수 없다.
따라서 추가 권한을 쓰기 권한과 같이 취급한다.
< 프로세스의 영역별 메모리 접근 권한 >
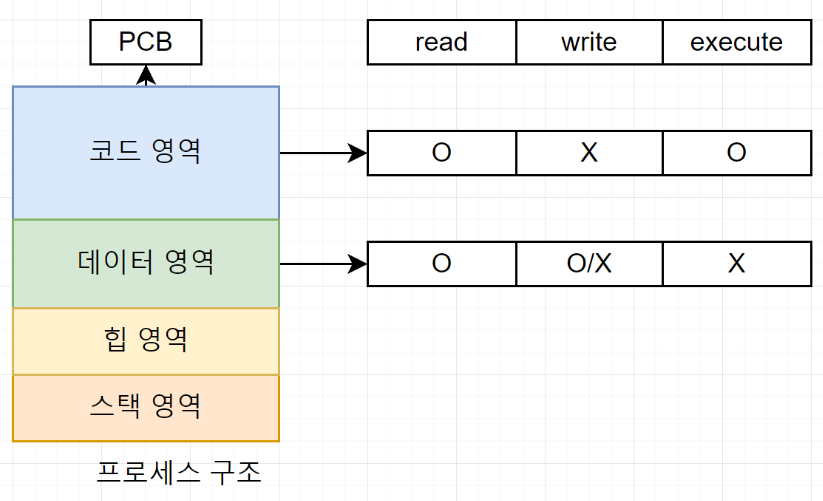
코드 영역과 데이터 영역의 접근 권한은 다음과 같다.
코드 영역:
자기 자신을 수정하는 프로그램은 없기 때문에 읽기 및 실행 권한을 가진다.
데이터 영역:
데이터는 크게 읽거나 쓸 수 있는 데이터와 읽기만 가능한 데이터로 나눌 수 있다.
일반적인 변수는 읽거나 쓸 수 있으므로, 읽기 및 쓰기 권한을 가지지만 상수(const)로 선언한 변수는 읽기 권한만 가진다.
캐시 매핑 기법
캐시 메모리란
◻ 캐시 메모리라고 하면 실제 메모리와 CPU 사이에서 빠르게 전달을 위해서 미리 데이터들을 저장해두는 좀더 빠른 메모리이다.
◻ 데이터 베이스를 매번 확인해야 하는것도 캐시서버를 이용한다면 빠른 응답을 해줄 수 있다.
◻ CPU와 메인 메모리 사이에 존재한다고 말할 수 있는데, CPU내에 존재할 수도 있고 역할이나 성능에 따라서는 CPU밖에 존재할 수도 있다. 빠른 CPU의 처리속도와 상대적으로 느린 메인 메모리에서의 속도의 차이를 극복하는 중간 버퍼 역할을 한다.
직접매핑(Direct Mapping)
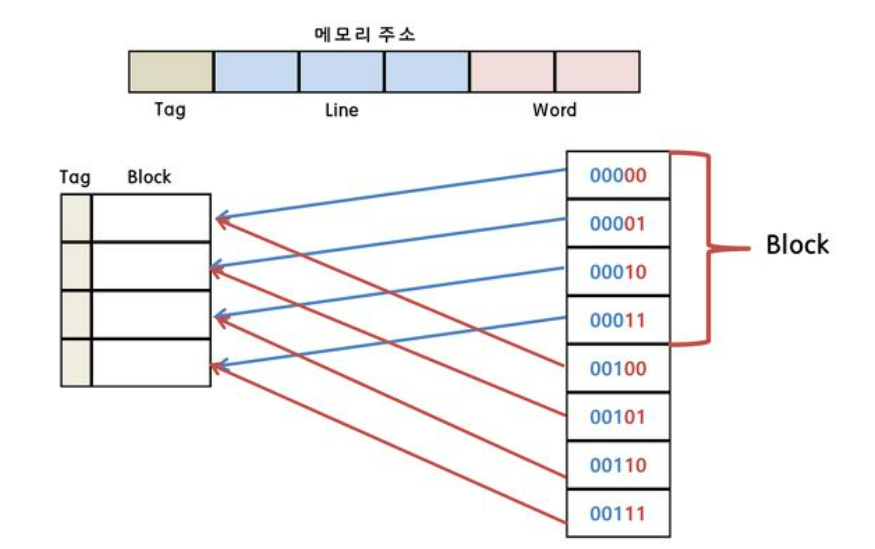
◻ 우선 메인 메모리에서 캐시로 데이터를 저장할 때 참조의 지역성 때문에 한번 퍼낼 때 인접한 곳까지 한꺼번에 캐시 메모리에 저장하고 이 때 단위를 블록(Block)이라고 한다.
그리고 캐쉬는 메인 메모리의 몇번째 블록인지를 알려주는 태그(Tag)도 함께 저장한다.
◻ 메모리 주소 중에 가장 뒷부분(붉은색)은 블럭의 크기를 의미한다.
지금 블럭의 크기가 4이므로 뒤의 두자리를 사용하여 블럭의 크기를 표현하였다.
그리고 이 영역은 블럭에 몇 번째에 원하는 데이터가 있는지 보여주는 지표가 되어 준다.
만일 위의 예에서 붉은 영역이 01이라면 블록의 두 번째 내용을 CPU에서 요청한 것이다.
◻ 같은 라인에 위치하는 데이터는 파란색 색칠한 영역에 의하여 구별이 가능하다.
예를 들면 메모리에 첫번째 요소 00000과 다섯번재 주소 00100은 캐시내에 같은 위치에 자리잡고 있어서 구별이 필요한데, 앞의 세자리 000과 001로 구별을 할 수 있다.
직접 매핑은 위의 사진처럼 캐시에 저장된 데이터들은 메인 메모리에서와 동일한 배열을 가지도록 매핑하는 방법을 말한다.
이와 같은 방식을 사용하기 때문에 매우 단순하고 탐색이 쉽다는 장점이 있다.
하지만 적중률(Hit ratio)가 낮다는 단점이 있다.
연관매핑(Associative Mapping)
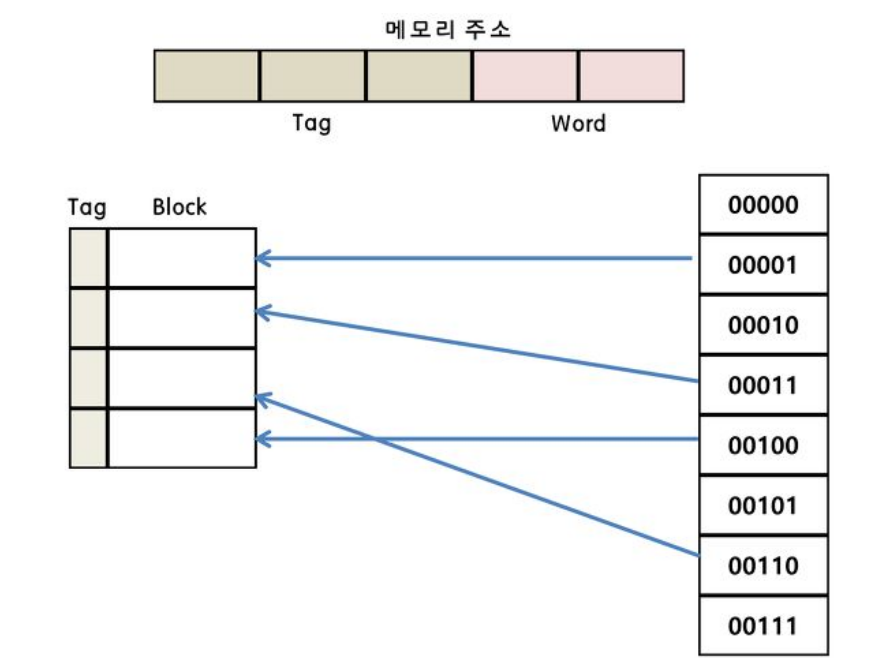
◻ 연관 매핑은 직접 매핑의 단점을 보완하기 위해 등장하였다.
◻ 캐시에 저장된 데이터들은 메인 메모리의 순서와는 아무런 관련이 없다.
◻ 이런 같은 방식을 사용하기 때문에 캐시를 전부 뒤져서 태그가 같은 데이터가 있는지 확인해야한다.
◻ 따라서 병렬 검사를 위해 복잡한 회로를 가지고 있는 단점(시간이 오래걸림)이 있지만 적중률이 높다는 장점이 있다.
직접연관매핑(Set Associative Mapping)
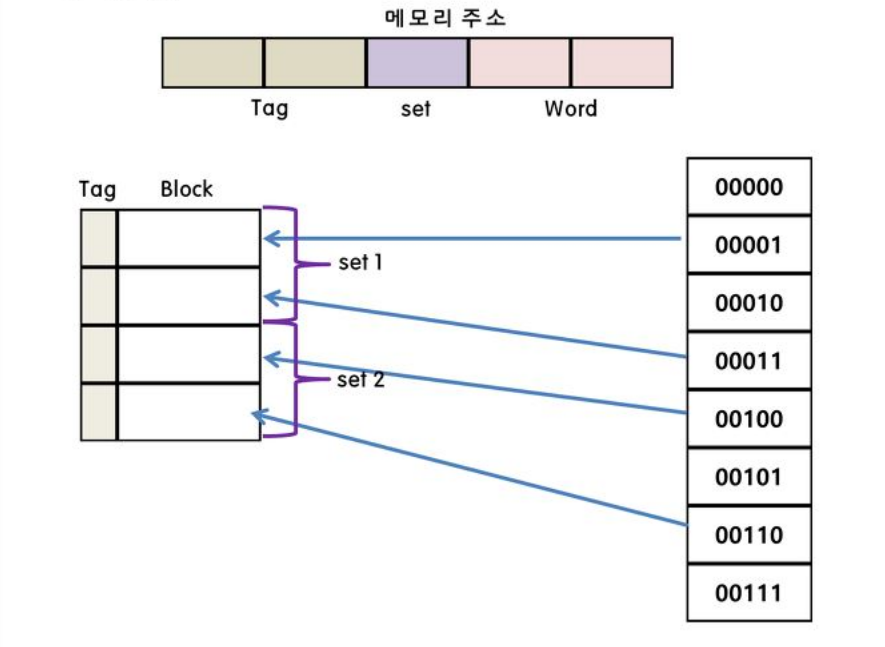
◻ set을 먼저 설정하고 -> 그 다음 어느 블록에 들어갈 것인지? (ex : 4-way면 4개 블록중 하나)
◻ 직접 매핑의 단순한 회로와 연관 매핑의 적중률 두 개의 장점만을 취하기 위해서 만들어진 방식이다.
◻ 각각의 라인들은 하나의 세트에 속해 있다.
◻ 세트 번호를 통해 영역을 탐색하므로 연관 매핑의 병렬 탐색을 줄일 수 있다.
◻ 그리고 모든 라인에 연관 매핑처럼 무작위로 위치하여 직접매핑의 단점도 보완하였다.
◻ 세트 안의 라인 수에 따라 n-way 연관 매핑이라고 한다.(ex: 2-way집합 연관 사상)
참고
