
1. CRA & CSR
CRA란?
초기개발 환경 세팅을 말하며 아무런 초기 설정이 없어도 CRA통해 React기반의 SPA (Single Page Application:는 말 그대로 한 개의 페이지로 이루어진 어플리케이션) 사이트를 구현 할 수 있게 됐다.
Web pack, babel등 복잡한 세팅을 거치지 않아서 React기반의 웹 프로젝트 확산에 큰 기여를 하였다.
그! 런! 데! 이렇게 평화로운 곳에 한가지 큰 문제점이 발생하는데...!

CRA로 build한 프로젝트가 검색에 걸리지 않는 큰 문제점이 발생한다.
원인은 CRA는 오직 CSR(Client Side Rendering)로 실행되기 때문이었다.
그렇다면 여기에서 'CSR'이란? (SSR과 거진 반대 개념)
(* 우선, CSR에 대해서 이야기하자면 Index.html이라는 빈껍데기가 ‘똑똑'하고 있는 모습을 상상해보면서 살펴보면 더 좋다.)
- 웹 페이지의 렌더링이 클라이언트(브라우저) 측에서 일어나는 것을 의미.
- 브라우저는 최초 요청에서 html, js, css 확장자의 파일을 차례로 다운로드.
- 최초로 불러온 html의 내용은 비어있음. (html, body 태그만 존재)
- js 파일의 다운로드가 완료된 다음, 해당 js 파일이 dom을 빈 html 위에 그리기 시작.
- 백엔드 호출을 최소화 할 수 있음
- 최초 호출 때만 html, js, css를 요청
- 이후에는 화면에서 변화가 일어나야 하는 만큼의 데이터만 요청 (ex. JSON)
- 라우팅(새로운 페이지로 이동)을 하더라도 html 자체가 바뀌는 것이 아니라 JavaScript 차원에서 새로운 화면을 그려내는 것!
2) SEO(Search Engine Optimization) & SSR(Server Side Rendering)
웹 크롤러(검색 엔진 봇)가 각 사이트를 돌아다니며 조사하는 상황이라 가정하자.
(fyi, 웹 크롤러는 사이트의 업데이트와 생성/삭제를 계속해서 찾아보고 구글등 웹사이트의 DB 업데이트 한다.)
-
CSR
크롤러: 똑똑똑
크롤러: 페이지를 요청
200번대 응답을 받음
근데 ‘어랏?’ index.html 이라는 ‘빈 집’ 받음
조사를 하지 못하고 구글봇 퇴장
js파일 다운로드되며 페이지 로드
하지만 이미 크롤러는 떠났고 따라서 검색노출 안됨😩 -
SSR(+SSG)
크롤러: 똑똑똑
크롤러: 페이지를 요청
(사이트 주인이 웹크롤러 맞이) “안녕하세요 저희 사이트는요..!”
조사를 다 하고 구글봇 퇴장
검색 노출 성공적으로 됨😃
그렇다면 편하게 ‘CRA통해 React기반의 SPA사이트를 구현’하면서 + ‘검색에 걸리게’하려면?
그 대안으로, 첫 요청만 SSR로 보내주고 그 다음부턴 CSR로 그려주면 어떨끼?
그렇게 해서 두개를 섞어서 쓰게 되었다!
- CSR + SSR?
하단에 원리와 구조를 사진과 함께 이해해보자.
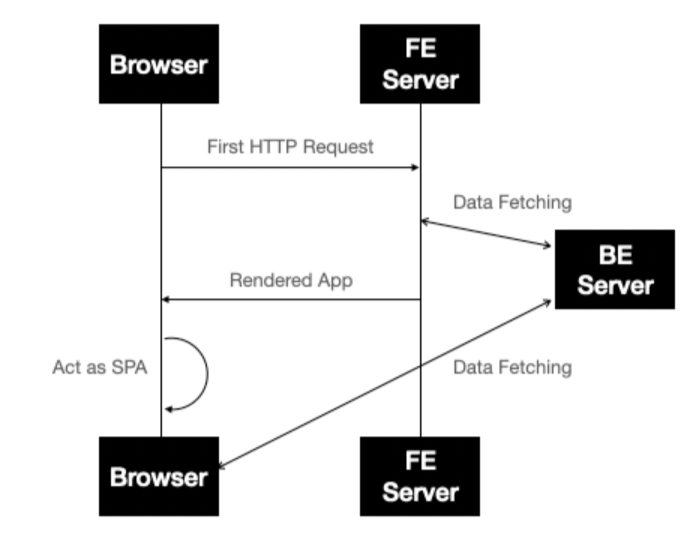
(원리 구조 사진 참조!)
브라우저가 페이지를 여려면 프론트 서버에 요청 보낸다
비어있는 html이 아닌 reactDOMServer로 리액트 자체에서 그린다.
html파일이 로드되었으니 이제 js가 받아져야 한다.
- 다음과 같은 과정을 거쳐 SSR이 진행된다 (링크)
- 유저가 브라우저에
/를 입력. - 미리 실행되고 있는 FE 서버가 요청을 받고 서버사이드 렌더링.
- 만들어진 html 을 브라우저에게 보냄.
- 브라우저가 응답받은 html 을 그림.
- html 에 기능을 부여할
index.js파일을 다운로드 받음. (hydration) - 다운로드가 완료된 이후,
go to second링크를 클릭. /second로 라우팅하고 second 페이지 코드를 생성.
- 유저가 브라우저에
