👉 오늘 한 일
- special lecture : 통계
- sql 과제
통계 특강
통계로 무엇을 할 수 있는가
데이터 분석가 -> 의사결정권자가 이해할 수 있는 수준까지의 통계 역량이 있으면 됨
통계 분석을 통해서 할 수 있는 일들
-
대상의 특성을 수치로 표현하기
- 대상을 관찰할 수 있는 특성은 무엇이든 수치화 가능(양적, 질적 다)
- 수치가 객관적이지 않아도 됨(e.g. 만족도)
- 수치가 대상을 파악하기에 좋은 성질을 가지고 있나?
-
부분을 통해 전체를 추측하기
- 대부분의 경우 대상의 일부만을 관찰할 수 있음
- 현실에서는 우연과 불확실성 존재
- 부분을 통해 전체를 '합리적으로' 추측해야 함
-
비교하기
- 대상들 사이에 어떤 차이가 존재하는가
- 그 차이가 정말 존재하는가?
- 대상들 자체의 특성으로 인해 발생한 것인가?(우연에 의한 것이 아닌가?)
-
예측하기
- 미래에 대한 예측만을 의미하는 것은 아님
- 어떤 특성은 다른 특성보다 쉽게 알 수 있음
- 한 대상의 여러 특성들은 서로 관련이 있음
- 쉽게 알 수 있는 특성으로 알기 어려운 특성 예측
-
영향력을 미치는 변수 찾기
- 대상의 한 가지 특성은 여러 가지 특성으로부터 영향 받음
- 목적으로 하는 특성에 영향이 큰 변수를 분별
-
지수(index) 만들기
- 대상의 특성 중에는 직접적으로 관찰하기 어려운 것이 있음(e.g. 사랑)
- 이러한 특성은 관찰 가능한 다른 특성들과 연관을 맺고 있음
- 관찰 가능한 특성들을 바탕으로 관찰하기 어려운 특성을 지표화할 수 있음
-
비슷한 것끼리 모으기
- 비슷한 것을 모아서 하나의 집단으로 인식하면 편리한 경우가 있음
통계 분석 예시
- 주거지 추천
- 주거지별 특징을 지수화
- 라이프스타일에 맞는 주거지를 추천
- 당근마켓 매물 분석
- 스팸의 시기별 가격 변화
- 매물 제목과 조회수의 관계 분석
등등..
이상한 통계학의 용어
- 번역이 상한 경우 : 모수(parameter)
- 분모와 관련 x, 엄마랑도 관련 x
- 시간이 지나며 의미가 변한 경우 : 회귀분석
- 돌아가는(회귀) 것과는 관련 없음
- 사고방식의 차이 : 통계적 가설 검정
- 일반적인 과학의 가설 검정과는 전혀 다른 관점을 가짐(실증주의 vs 반증주의)
변수의 종류
범주형 변수
- 종류, 이름에 해당
- 숫자로 표기해도 양적인 개념이 아님
- 대부분의 연산이 의미 없음
연속형 변수
- 연속적인 형태
- 간격이 일정하고 연산이 의미 있음
기술통계
기술통계 : 데이터를 묘사, 설명
- 중심 경향치 : 데이터가 어디에 몰려있는가
- 평균, 중앙값
- 분위수 : 데이터에서 각각의 순위가 어느 정도인가
- 변산성 측정치 : 데이터가 어떻게 퍼져있는가
- 범위 : 최대값 - 최소값
- IQR : 3분위수 - 1분위수
- 분산, 표준편차
히스토그램 : 데이터를 구간별로 나눠 각 구간의 사례 수를 막대그래프로 그린 것
커널 밀도 추정(kde) : 데이터의 밀도를 추정하여 그린 곡선
모집단과 표본
모집단(population) : 연구의 관심이 되는 집단 전체
표본(sample) : 특정 연구에서 선택된 모집단의 부분 집합
- 대부분의 경우 집단 전체를 전수조사하기는 어려우므로 무작위로 표본을 추출하여 모집단에 대해 추론
파라미터 : 어떤 시스템의 특성을 나타내는 값
모수 : 모집단의 파라미터 -> 모집단의 특성을 나타내는 값
- 모집단의 평균 : 모평균
- 모집단의 분산 : 모분산
- 모수를 구하기 위해서는 전수조사가 필요하지만 사실상 어려움
- "표본의 크기"를 "모수" 라고 하는 경우도 있으나 잘못된 표현
통계량(sample statistic) : 표본에서 얻어진 수로 계산한 값(=통계치)
- 표본의 평균 : 표본평균
- 표본의 분산 : 표본분산
- "모집단의 통계량" 이라는 표현은 없음. 통계량은 표본에서 구한 값
- "표본의 모수" 같은 말도 없음. 모수는 모집단에서 구한 값
표집(표본추출. sampling) : 모집단에서 표본을 추출하는 절차
- 표집 단위(sampling unit) : 측정의 단위
- e.g. 개인, 상품 등
- 표집틀(sampling frame) : 표집 대상의 목록
무작위 표집(random sampling) : 일정한 확률에 따라 표본을 선택
단순 무작위 표집(simple random sampling) : 모든 사례를 동일 확률로 추출
-
계통표집(systematic sampling) : 첫 번째 요소는 무작위로 선정한 후 목록의 매번 k 번째 요소를 표본으로 선정
- 주기성이 있다면 왜곡 가능성
-
층화표집(stratified random sampling) : 모집단을 이루는 각 계층별로 무작위 추출
- 모집단이 서로 다른 하위 집단들로 이뤄져 있을 경우에 사용
-
집락표집(cluster random sampling) : 모집단을 클러스터로 나눈 후 집락 중 일부를 무작위로 선택
- 선택된 클러스터에서 표본을 추출
- 층화추출과 달리 클러스터들이 서로 비슷해야 함
추정
추정 : 통계량으로부터 모수를 추측하는 절차
- 점 추정(point estimate) : 하나의 수치로 추정
- 구간 추정(interval estimate) : 구간으로 추정
신뢰구간(confidence interval) : 통계량 +- 오차범위
- 대표적인 구간 추정 방법
- 모수가 있을 법한 범위로 추정
- 모든 통계량에는 신뢰구간 존재
신뢰 수준(confidence level) : 신뢰구간에 모수가 존재하는 표본의 비율
- 신뢰수준이 높음 -> 많은 표본을 포함 -> 더 넓은 오차범위 -> 정보가 적음
- 신뢰수준이 낮음 -> 적은 표본을 포함 -> 더 좁은 오차범위 -> 정보가 많음
- 신뢰구간이 좁으면 신뢰수준이 낮으므로 타협이 필요(보통 95,99 사용)
평균의 신뢰구간
- 평균의 경우 이론적으로 신뢰구간을 간단히 구할 수 있음
- 다른 통계량은 부트스트래핑 등의 복잡한 계산이 필요
부스트스트래핑(booststrapping)
- 평균과 달리 중간값, 최빈값 등의 통계량은 표집분포의 형태를 간단히 알기 어려움
- 표본이 충분히 크면 부트스트래핑이라는 시뮬레이션 기법을 사용해서 신뢰구간을 추정
신뢰구간에 영향을 주는 요소
- 신뢰구간이 좁을 수록 예측된 모수의 범위가 좁으므로 유용
- 신뢰수준 낮추기 : 큰 의미 x
- 표본의 변산성 낮추기 : 실험과 측정을 정확히 해서 변산성을 낮춤
- 표본의 크기를 키우기 : 가장 쉬운 방법이나 시간과 비용이 증가
통계적 가설검정
귀무가설(H0) : 기각하고자 하는 가설
대립가설(H1) : 주장하고자 하는 가설
귀무가설을 기각하는 논리 : A -> B 라는 명제는 not B -> not A 라는 대우명제와 동치
- 귀무가설이 참이면(A), 현재 결과가 나올 확률이 높다(B)
- 현재 결과가 나올 확률이 낮으면(not B) 귀무가설이 거짓이다(not A)
귀무가설을 채택하지 않는 논리 : A -> B 라는 명제가 성립해도 B -> A 가 반드시 성립하는 것은 아님
- 통계적 가설검정을 만든 로널드 피셔의 반증주의적 과학철학을 반영
- 귀무가설이 참이면(A) 현재 결과가 나올 확률이 높다(B)
- 현재 결과가 나올 확률이 높아도(B) 귀무가설이 참(A) 이라고 할 수는 없음
- p-value가 유의수준보다 높아도 귀무가설을 채택하지 않고, 결론을 유보함.
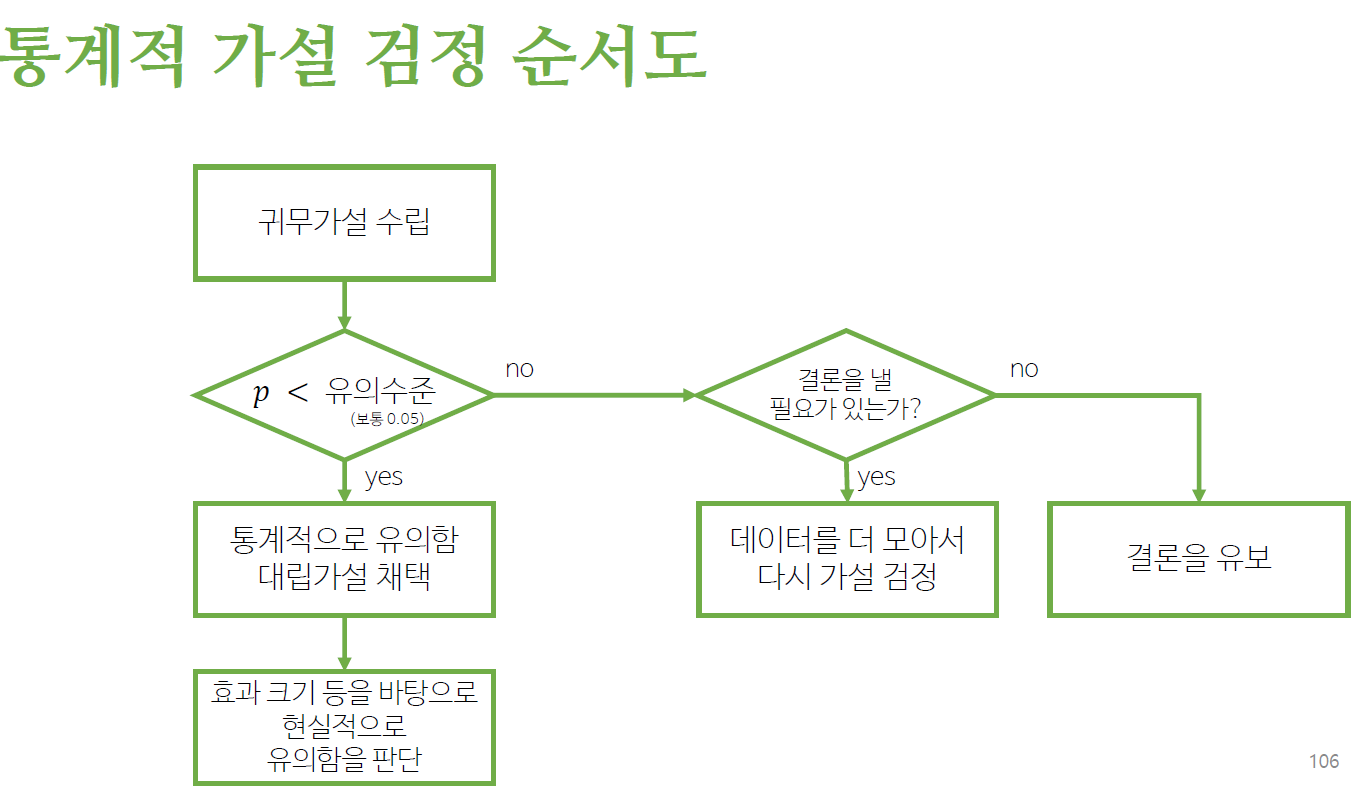
유의수준과 p값
p-value : 귀무가설을 바탕으로 데이터에서 관찰된 결과와 그 이상의 극단적 결과가 나올 확률을 계산한 것
유의수준(significance level) : p값을 바탕으로 높고 낮음을 판정하는 기준
- 그리스 문자 𝛼 알파 로 표기
- 보통 5%(=0.05) 를 사용
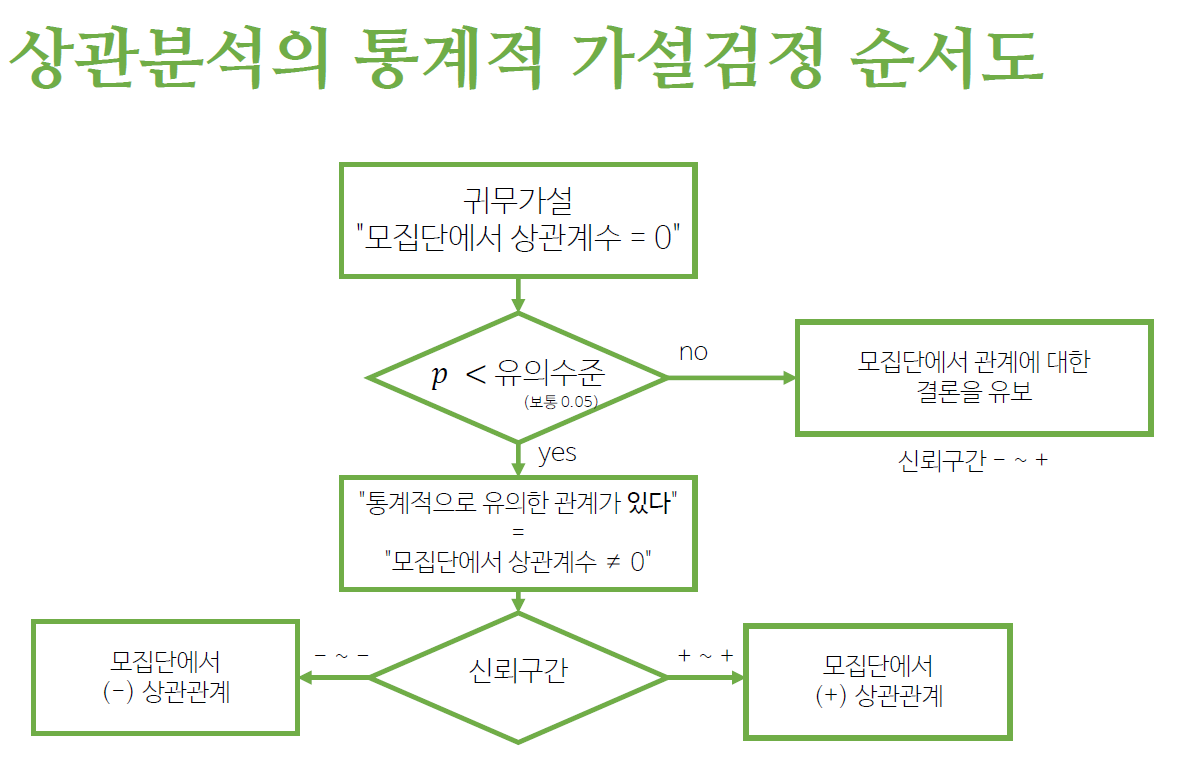
- 𝑝 < 𝛼면 귀무가설을 기각 -> 대립가설 채택
p > 유의수준
- 결론을 유보한다
- 결론을 내릴 필요가 있을 경우 데이터를 더 모은다
- 단, 반복해서 가설검정을 할 경우 유의수준을 조정한다
p < 유의수준
- 귀무가설을 기각한다
- 대립가설을 채택한다
- 흔히 통계적으로 유의하다(statistically significant)라고 표현. 현실적으로 유의한 것은 아님
- 어떠한 관계가 있다고 주장하기에 표본의 크기가 충분하다는 것으로 이해할 수 있음
- 통계적 유의함은 표본의 크기에 따라 달라지므로 반드시 현실적으로 유의미한 것은 아님
가설 검정의 결과
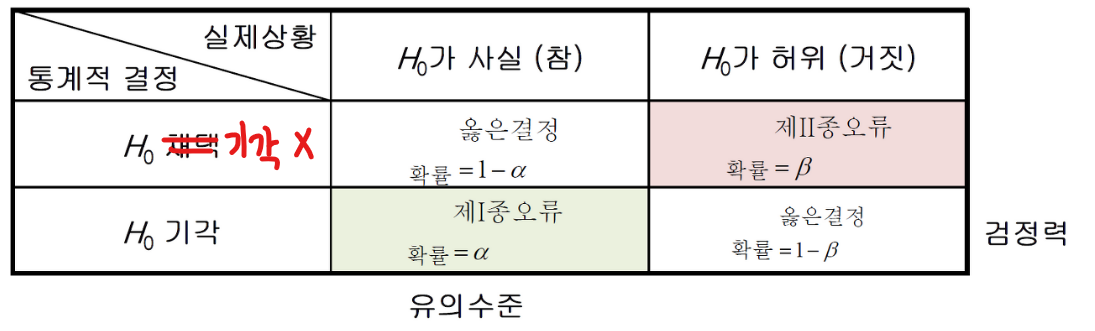
- 귀무가설이 참일 경우 1종 오류는 유의수준만큼 발생
- 유의수준을 낮추면 1종 오류가 감소하고 2종 오류가 증가
가설검정과 신뢰구간의 관계
통계적 가설검정과 신뢰구간은 동일한 이론의 양면
- 95% 신뢰구간이 귀무가설의 모수를 포함하지 않으면 5% 유의수준에서 가설검정은 귀무가설을 기각
데이터가 많을 수록
- 신뢰구간은 좁아짐
- p는 작아짐
p-value 에 영향을 주는 요소들
- 관찰된 통계량이 귀무가설에서 멀리 떨어져 있으면 p-value 가 작아짐
- 표본의 크기가 크면 p-value 가 작아짐
상관분석
상관계수(correlation coefficient) : 두 변수의 연관성을 1 ~ +1 범위의 수치로 나타낸 것
- 두 변수의 연관성을 파악하기 위해 사용
양의 상관관계 : 두 변수가 같은 방향으로 변화(하나가 증가하면 다른 하나도 증가)
음의 상관관계 : 두 변수가 다른 방향으로 변화(하나가 증가하면 다른 하나는 감소)
상관계수가 0 : 두 변수가 독립 , 한 변수의 변화로 다른 변수의 변화를 예측하지 못함
상관계수가 1 : 한 변수의 변화와 다른 변수의 변화가 정확히 일치
공분산 : X의 편차와 Y의 편차를 곱한 것의 평균 (X=Y 이면 분산과 같음)
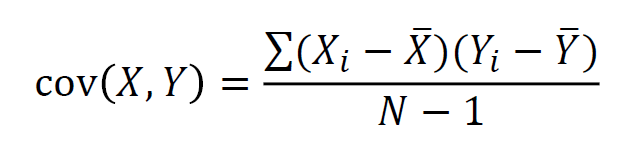
- 우상향하는 추세인 경우 +로 커짐
- 우하향하는 추세인 경우 -로 커짐
피어슨 상관계수 : 가장 대표적인 상관계수
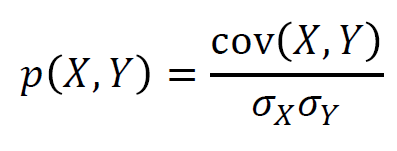
- 선형적인 상관계수를 측정
- 공분산을 두 변수의 표준편차로 나눔 -> -1 ~ +1 범위
- 상관계수는 우상향 또는 우하향하는 단조적 관계를 표현
- 복잡한 비단조적 관계는 잘 나타내지 못함
- 상관계수가 낮다고 해서 관계가 없는 것은 아님
회귀분석
지도학습(supervised learning) : 독립변수 x 를 이용하여 종속변수 y 를 예측하는 것
- 통계학에서 예측은 어떤 값에 대한 추론을 의미(시간적인 의미 X)
- 지도학습에서 예측은 변수들 사이의 패턴을 파악하여 한 변수로 다른 변수를 추론하는 것
- 시계열 분석 등에서 하는 미래에 대한 예측은 forecasting 이라고 구분
독립변수(independent variable) : 예측의 바탕이 되는 정보, 인과관계에서 원인, 입력값
종속변수(dependent variable) : 예측의 대상, 인과관계에서 결과, 출력값
회귀분석(regression)
- 종속변수가 연속형
- 예측값 - 실제값으로 정확성을 계산
분류(classification)
- 종속변수가 범주형
- 예측의 정확성을 다른 방식으로 계산
선형 모형
ŷ = wx + b
- ŷ : y의 예상치
- x : 독립변수
- w : 가중치 혹은 기울기
- b : 절편(x=0일 때 y의 예측치)
잔차 : 실제값과 예측값의 차이
sql 과제
solvesql 문제 풀이
- RFM 분석 1단계. 고객 별 점수 매기기
SELECT customer_id
, last_order_date
, cnt_orders
, sum_sales
, if(last_order_date >= "2020-12-01", 1, 0) recency
, if(cnt_orders >= 3, 1, 0) frequency
, if(sum_sales >= 500, 1, 0) monetary
FROM customer_stats- RFM 분석 3단계. 떠나간 VIP ❓
SELECT if(last_order_date >= "2020-12-01", 1, 0) recency
, if(cnt_orders >= 3, 1, 0) frequency
, if(sum_sales >= 500, 1, 0) monetary
, count(customer_id) customers
FROM customer_stats
GROUP BY recency, frequency, monetary
ORDER BY recency DESC- 가구 판매의 비중이 높았던 날 찾기(피봇)
SELECT order_date
, COUNT(DISTINCT CASE WHEN category = 'Furniture' THEN order_id END) furniture
, ROUND(COUNT(DISTINCT CASE WHEN category = 'Furniture' THEN order_id END) / COUNT(DISTINCT order_id) * 100,2) furniture_pct
FROM records
GROUP BY order_date
HAVING COUNT(distinct order_id) >= 10 AND furniture_pct >= 40
ORDER BY furniture_pct DESC, order_date- 이 펭귄의 성별은 무엇인가요?
SELECT COUNT(*) total
, COUNT(sex) sex_notnull
, COUNT(*) - COUNT(sex) sex_null
FROM penguinsHackerRank 문제풀이
- Type of Triangle
SELECT CASE
WHEN A + B <= C OR B + C <= A OR A + C <= B THEN "Not A Triangle"
WHEN A = B AND B = C THEN "Equilateral"
WHEN A = B OR B = C OR A = C THEN "Isosceles"
ELSE "Scalene"
END
FROM trianglesleetcode 문제풀이
- Reformat Department Table
SELECT id,
SUM(CASE WHEN month = 'Jan' THEN revenue ELSE NULL END) as JAN_Revenue,
SUM(CASE WHEN month = 'Feb' THEN revenue ELSE NULL END) as Feb_Revenue,
SUM(CASE WHEN month = 'Mar' THEN revenue ELSE NULL END) as Mar_Revenue,
SUM(CASE WHEN month = 'Apr' THEN revenue ELSE NULL END) as Apr_Revenue,
SUM(CASE WHEN month = 'May' THEN revenue ELSE NULL END) as May_Revenue,
SUM(CASE WHEN month = 'Jun' THEN revenue ELSE NULL END) as Jun_Revenue,
SUM(CASE WHEN month = 'Jul' THEN revenue ELSE NULL END) as Jul_Revenue,
SUM(CASE WHEN month = 'Aug' THEN revenue ELSE NULL END) as Aug_Revenue,
SUM(CASE WHEN month = 'Sep' THEN revenue ELSE NULL END) as Sep_Revenue,
SUM(CASE WHEN month = 'Oct' THEN revenue ELSE NULL END) as Oct_Revenue,
SUM(CASE WHEN month = 'Nov' THEN revenue ELSE NULL END) as Nov_Revenue,
SUM(CASE WHEN month = 'Dec' THEN revenue ELSE NULL END) as Dec_Revenue
FROM department
GROUP BY id- Employees Earning More Than Their Managers(self join)
SELECT a.name Employee
FROM employee a
JOIN employee b
ON a.managerid = b.id
WHERE a.salary > b.salary