
👉 오늘 한 일
- 캐글 타이타닉 경진대회 실습
타이타닉 실습
경진대회 데이터셋은 train.csv , test.csv 형태로 제공되는 경우가 많아서 폴더로 관리
test 에 있는 데이터의 행은 삭제를 하면 안됨 => 삭제를 하면 예측해야 하는 문제인데 예측을 못 하기 때문에
타이타닉 데이터는 당뇨병 데이터에 비해 결측치도 많고, object type이 섞여있고, 데이터 크기도 조금 더 크기 때문에 더 난이도 있는 데이터셋임
인덱스 값이 같아야 값을 할당했을 때 바로 적용됨
tolist()를 적용하면 인덱스 값이 달라도 그냥 순서대로 값을 적용함- e.g.
submit["Survived"] = (test["Sex"] == "female").astype(int).tolist()
정규화 => 숫자 스케일의 차이가 클 때 값을 정규분포로 만들어 주거나 스케일 값을 변경해 주는 것
이상치 => 이상치를 제거하거나 대체
대체 => 결측치를 다른 값으로 대체
인코딩 => 호칭, 탑승지의 위치, 문자 데이터를 수치화, 너무 범위가 큰 수치 데이터를 구간화 해서 인코딩 할 수도 있음
정확도(accuracy) : 올바르게 예측한 샘플 개수 / 전체 샘플 개수

머신러닝 내부에서 수치데이터 외에 연산을 할 수 없기 때문에 수치형 데이터로 만들어서 가져옴
- 머신러닝 알고리즘에서 bool 값은 수치데이터로 취급함. 굳이 int로 변경하지 않아도 됨
Binary Encoding : 범주형 데이터를 0과 1을 사용하여 인코딩하는 기법. 이는 One-Hot Encoding과 유사해보일 수 있지만 다음과 같은 차이점이 존재함.
- One-Hot Encoding : 고유 값에 해당하는 변수만 1로 표시 → 1개의 변수가 N개의 변수로 분할됨
- Binary Encoding : 이진법을 통해 표시 → 1개의 변수가 log_{2}{N}log2N개의 변수로 분할됨
Binary Encoding은 훨씬 더 적은 변수만 필요로 한다는 장점이 있음.
- e.g. 3개의 카테고리가 있다면 Binary Encoding 시 2개 변수로 분할할 수 있음. 그 뿐만 아니라 100의 카테고리가 있다면 7개의 변수로 분할할 수 있음
Binary Encoding 진행 방식
- encoding을 할 변수의 카테고리에 임의로 순서(ordinal)를 부여
→ ex) 빵 = 1, 요거트 = 2, 머핀 = 3
- 부여된 순서에 대해 이진법 적용
→ ex) 빵 = 01, 요거트 = 10, 머핀 = 11
- 이진법으로 변환된 값에 대해 One-Hot Encoding의 방식으로 분할
범주형 데이터 다루기 : Feature Encoding
https://dacon.io/codeshare/4525
캐글은 하루에 10번만 제출 가능
-
어뷰징(잘못된 사용)
-
캐글에는 상금을 걸거나 채용을 걸거나 상을 걸고 하는 대회에 어뷰징이 있을 수 있기 때문. 그래서 하루 제출 횟수를 제한함. 한국 데이콘도 마찬가지
어뷰징 사례 : 광고에서 어뷰징 AD Fraud 광고사기, 게임사기 다양한 분야에 어뷰징이 있을 수 있음
gini & entropy
로그
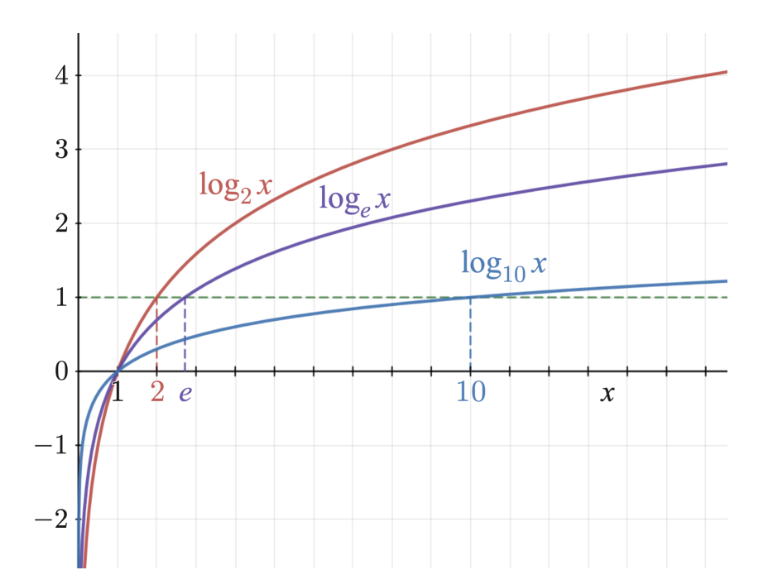
로그 그래프에서 이진로그, 자연로그, 상용로그의 공통점?
- x가 1일 때 y는 0임
- x는 음수를 가지지 않으며, 0보다 큰 값만 있음
- x가 1보다 작을 때, y값이 마이너스 무한대로 수렴
엔트로피 불순도 공식에서 마이너스를 취하는 이유?
- 로그에서 x가 1보다 작을 때 y값이 음수로 나오므로
지니계수, 엔트로피가 0인 것은 다른 값이 섞여있지 않음을 의미
- 0에 가까울수록 잘 나누어진 것
| 클래스 개수 | 최소엔트로피 | 최대엔트로피 |
|---|---|---|
| 2 == 2 ** 1 | 0 | 1 |
| 8 == 2 ** 3 | 0 | 3 |
| 16 == 2 ** 4 | 0 | 4 |
- 클래스의 개수에 따라 최대 엔트로피의 값이 달라짐
- multi-class classification
멀티 클래스 예제
https://dacon.io/competitions/official/235747/overview/description
지니불순도와 엔트로피를 사용하는 목적?
-
분류를 했을 때 True, False 로 완전히 나뉘지 않는데 이 때 값이 얼마나 섞여있는지 수치로 확인하기 위해서이고, 0에 가까울 수록 다른 값이 섞여있지 않은 상태. 분류의 분할에 대한 품질을 평가하고 싶을 때 사용함
-
실제 프로젝트 진행 시에는 시각화를 해보고 그 모델이 얼마나 잘 나뉘었는지 여러가지로 평가해 볼 수 있는데 이 때 함께 참고해 볼 수 있음. 이 때 함께 참고해 볼 수 있는 것은 피처 중요도, 교차검증(cross validation) 값 등이 있음
-
엔트로피나 지니불순도가 0이 될 때는 보통 샘플이 [1, 0] 이나 [2,0] 처럼 샘플의 개수가 적을 때가 많은데 이렇게 너무 자세하게 학습하면 일반화 하기 어려운 부분도 있음
