
🦁🦁✏
👉 오늘 한 일
- 주간 키워드 정리
주간 키워드 정리(kaggle)
키워드 : Kaggle

캐글 소개
2010년에 만들어진 “예측 모델 분석 대회 플랫폼”으로서 데이터 과학 및 머신러닝 경진대회를 주최하는 온라인 커뮤니티입니다. 기업과 단체에서 데이터와 해결과제 및 상금을 등록하면 개인 및 팀 단위의 데이터 과학을 연구하는 학생 및 과학자들이 문제를 해결하기 위해 도전합니다.
캐글에는 방대한 데이터, 유능한 데이터 과학자, 훌륭한 코드, 좋은 문화가 있어 데이터 과학 역량을 쌓는 데 최적의 플랫폼입니다. 이뿐만 아니라 전세계에서 데이터 과학을 연구하는 사람들의 커뮤니티, 학생들을 위한 가이드, 현업에서 일하는 과학자들의 지침서와 같은 역할도 합니다.
캐글은 2010년 설립되어 2017년 구글에 인수되었습니다. 구글이 인수할 만큼 영향력 있는 플랫폼입니다. 가입자 수는 2017년 6월에 100만 명이었는데, 바로 다음 해인 2018년 8월에 200만 명으로 2배가 되었습니다. 2022년 3월에는 900만 명을 넘어서는 등 지금도 빠르게 커가고 있습니다.
장점
웹 기반 플랫폼이기 때문에 인터넷만 연결되면 전 세계 누구나 참여할 수 있습니다. 캐글에 탑제된 노트북 덕에 개발 환경 구축에 신경 쓸 필요가 없습니다.
개인이나 작은 기업에서 쉽게 접할 수 없는 다양한 데이터로 데이터 과학과 머신러닝을 연습해볼 수 있고, 같은 목표로 대회에 참여한 전 세계 데이터 과학자들과 교류할 수 있습니다. 또한 자신이 작성한 노트북을 다른 사람들과 공유하며 공유된 노트북을 이용해 성능 좋은 모델을 개발 할 수 있습니다.
활용 사례
기업이나 단체는 자체적으로는 어려웠던 머신러닝 모델 개발 문제를 해결하고, 우수한 직원을 채용하기 위해 대회 성과를 활용하는 경향이 커지고 있습니다.
Why Kaggle?
- 데이터 과학 및 머신러닝 역량 강화
- 다양한 경진대회와 방대한 데이터셋을 경험
- 경진 대회 참여를 통해 머신 러닝 역량을 강화
- 공유와 경쟁의 상승효과
- 케글 메달 시스템을 통한 코드와 아이디어의 활발한 공유
- 경진 대회 참여를 통해 경쟁자와 경쟁하면서 역량 강화
- 개인이 접할 수 없는 환경
- 손쉽게 기업 데이터와 전세계 유능한 데이터 사이언티스트를 접할 수 있는 플랫폼
- 취업 시 우대
- 머신러닝/AI 분야의 채용 우대 사항에 ‘캐글 경진대회 입상 경험’ 항목이 있는 공고가 많아짐.
잡코리아 채용 - [잡코리아/알바몬] 머신러닝 인재 채용 | 잡코리아 (jobkorea.co.kr)
- 머신러닝/AI 분야의 채용 우대 사항에 ‘캐글 경진대회 입상 경험’ 항목이 있는 공고가 많아짐.

캐글의 구성 요소
Competitions
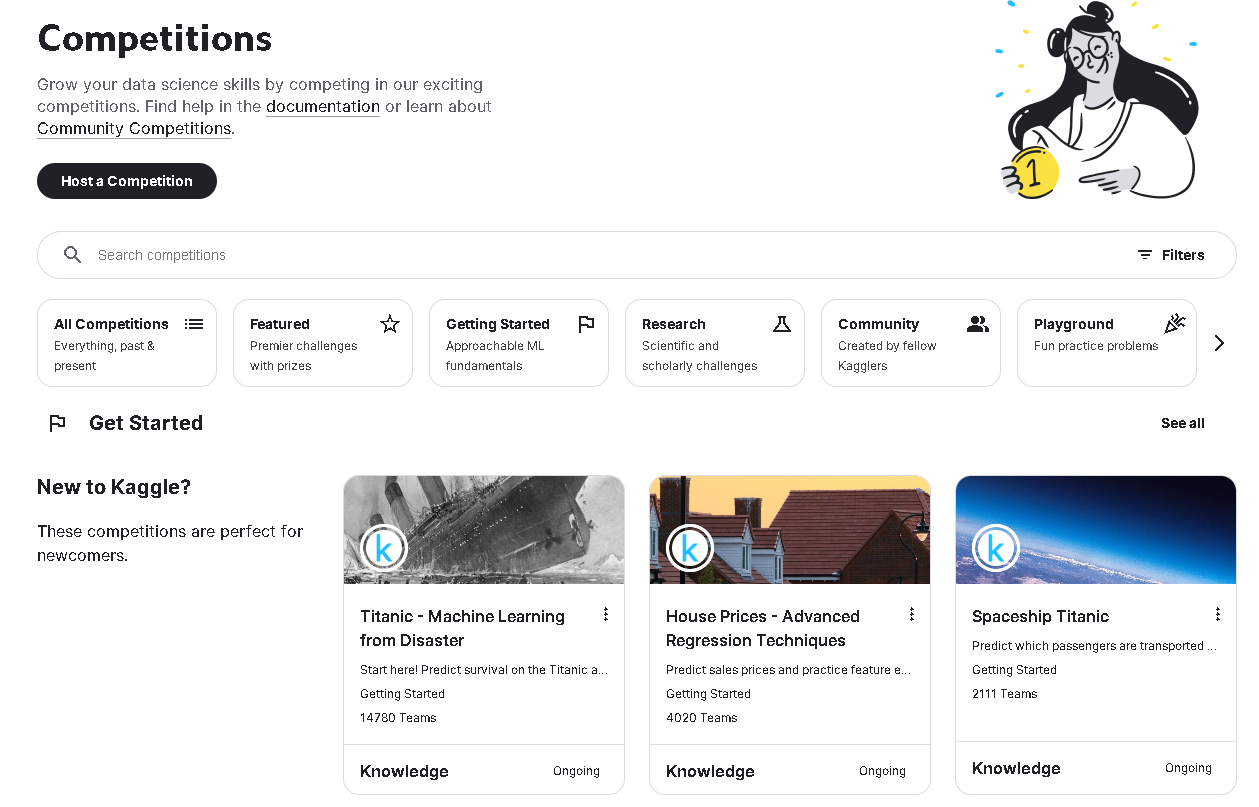
- [공식 설명서]
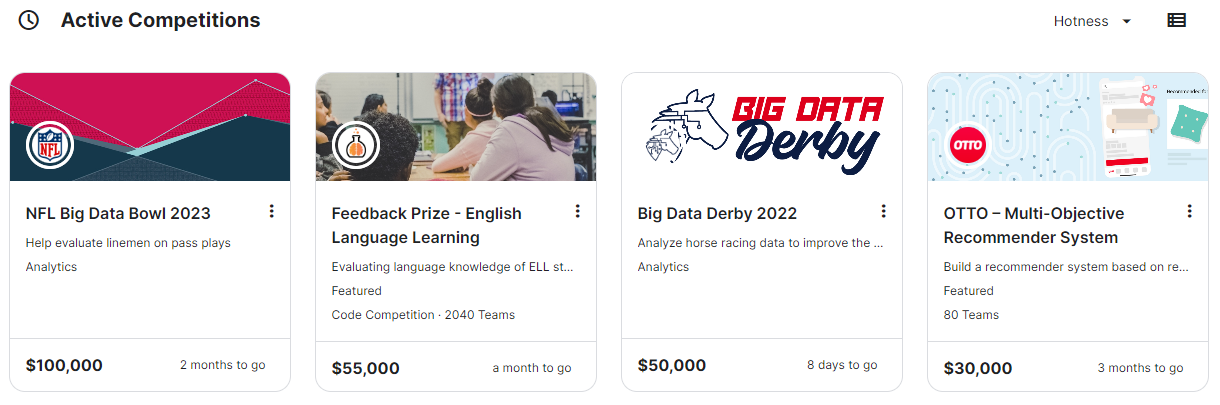
- 전 세계 누구나 참여할 수 있는 데이터 과학 및 머신러닝 대회를 볼 수 있습니다. 기업은 캐글에 데이터를 제공해 경진대회를 개최할 수 있습니다.
- 경진 대회는 대회에 따라 다르지만 보통 1~3개월 동안 진행되며, 참가자는 기업이 제공한 데이터를 분석하게 됩니다. 참가자는 기업에게 자신이 짠 코드를 제공하고 기업은 성능 좋은 모델을 개발한 참가자에게 상금을 지급합니다.
- Active Competitions에서 현재 진행하고 있는 모든 경진대회를 확인할 수 있습니다.
대회 유형
- All competitions: 모든 경진대회
- Getting Started(1. 시작): 이제 막 입문한 사람들을 위한 가장 쉬운 대회
- Playground(2. 놀이터): Getting Stated보다 난이도가 조금 있지만 초보자들을 위한 대회
- Featured(3. 본격): 머신러닝, 딥러닝으로 예측하는 일반적인 대회
: 본격적인 머신러닝 도전 무대로서 주로 상업적 목적이 있는 까다로운 예측 문제를 제시 - Research: 연구나 실험 목적을 갖는 특수한 형태의 대회, 실험적인 문제
- Community: 커뮤니티에서 주관하는 대회
대회 선택 팁
- 역량을 쌓기 위한 대회 참가
- 현재 진행 중인 대회 외에도 지난 대회로 연습이 가능
- 가장 최근에 종료된 대회에 참여하기. 최신 기술과 Solution들이 많이 공유되어 있음
- 대회에서 좋은 성과를 얻고 싶기 위해 참가
- 기한 내에 프로세스를 완성할 수 있는지 판단
- 해당 분야에 대한 도메인 지식 유무를 판단
- 현재 자신의 역량으로 충분히 승산이 있는지를 판단
Datasets
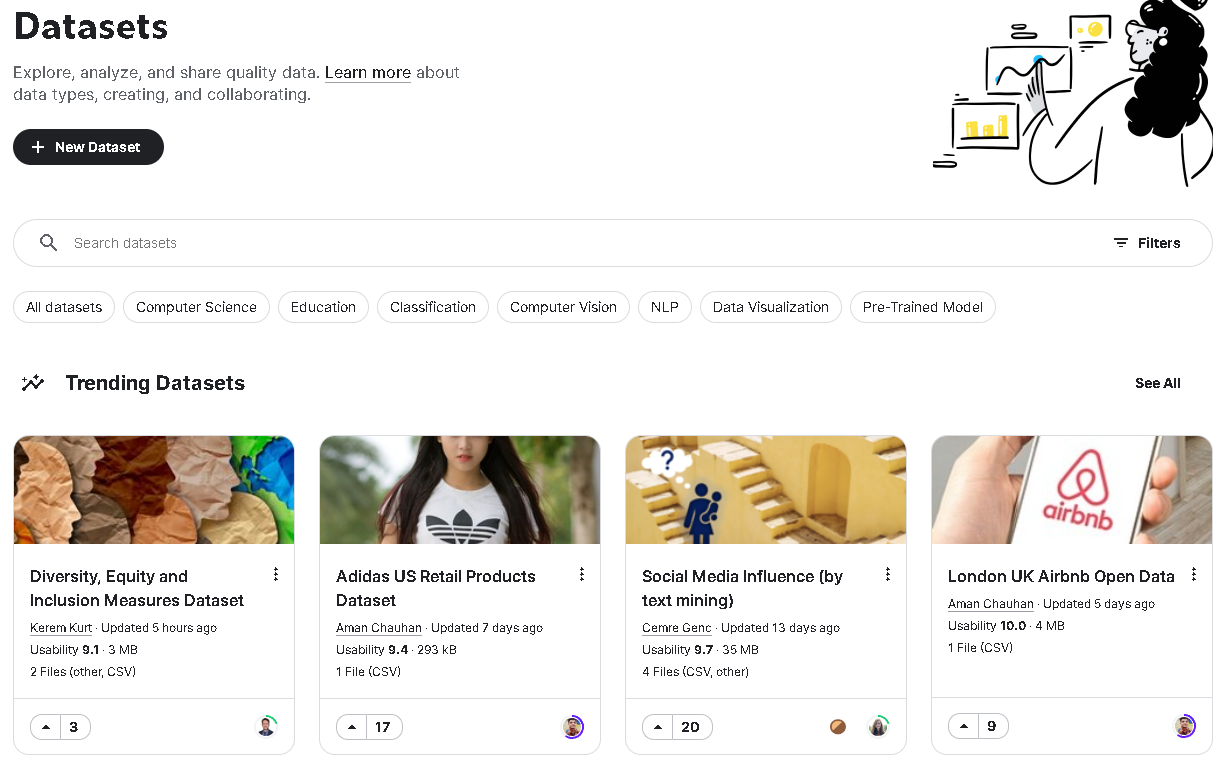
- [공식문서]
- Datasets 메뉴는 경진대회 없이 순수하게 데이터셋만 제공되는 영역입니다. 수많은 양질의 데이터를 구할 수 있습니다.
- 전 세계 누구나 데이터를 올릴 수 있고, 다른 사람이 올려둔 데이터를 자유롭게 사용하여 분석 결과를 공유할 수 있습니다.
- 키워드 중심으로 검색하면 원하는 데이터를 찾을 수 있습니다.
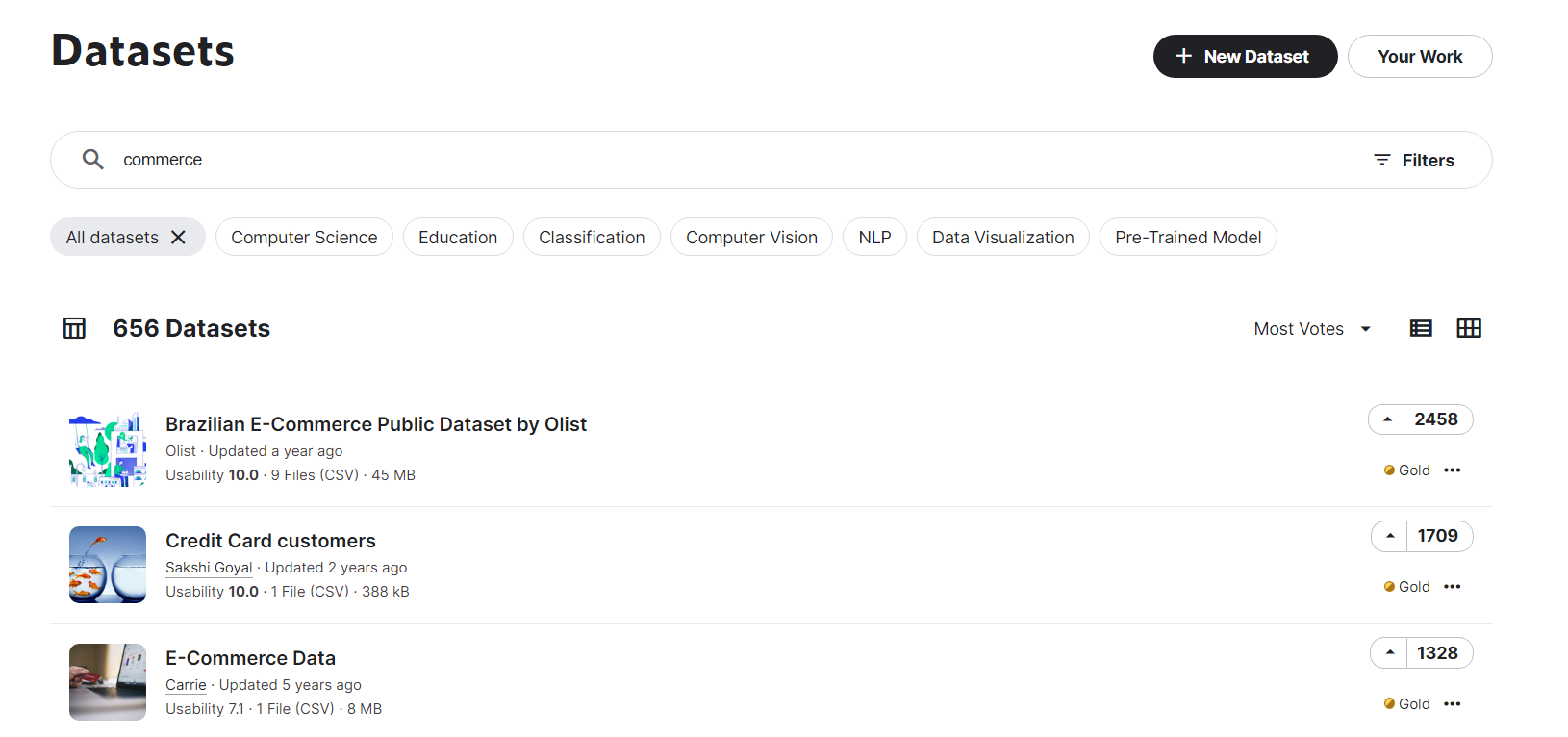
-
위의 사진처럼 commerce에 대한 데이터셋을 찾고 싶다면 “commerce”로 검색합니다.
-
검색 결과에서 제목 오른쪽에 메달이 표시되어 있는데 금, 은, 동 순으로 많은 사람이 추천했다는 뜻입니다. 많은 사람이 추천했다는 것은 그만큼 질이 좋은 데이터, 활용 가치가 높은 데이터일 확률이 높다는 뜻입니다. 메달 바로 위에 표시된 숫자가 추천수를 뜻합니다.
-
Kaggler 등급

- Kaggle은 경진대회, 데이터셋, 노트북, 토론마다 등급을 매깁니다. 등급을 높이기 위해서는 메달을 따야 합니다. 메달을 일정 개수 이상 모으면 등급이 올라갑니다.
- 등급 구성은 Novice, Contributor, Expert, Master, Grandmaster 와 같이 다섯 단계로 이루어져있습니다. Novice 등급으로 시작합니다.
- Contributor : '사진 등록, 거주지, 직업, 회사 등록, 휴대폰 인증, 노트북 1회 실행, 경진대회 1회 참여 및 제출, 1개 토론 참여, 다른 게시물에 추천 1개' 조건을 만족
- Expert : 경진대회 동메달 2개, 데이터셋 동메달 3개, 노트북 동메달 5개, 토론 동메달 50개를 모두 만족, 취업 우대 사항에 캐글 Expert를 기재하는 기업이 있을 정도로 Expert는 데이터 과학자로서 실력을 갖추었다는 증표
- Master : 경진대회 금메달 1개, 은메달 2개, 데이터셋 금메달 1개, 은메달 4개, 노트북 은메달 10개, 토론 은메달 50개 포함하여 총 200개 메달
- Grandmaster : 경진대회 '솔로' 금메달 1개, 금메달 5개, 데이터셋 금메달 5개, 은메달 5개, 노트북 금메달 15개, 토론 금메달 50개 포함하여 총 500개 메달
Code
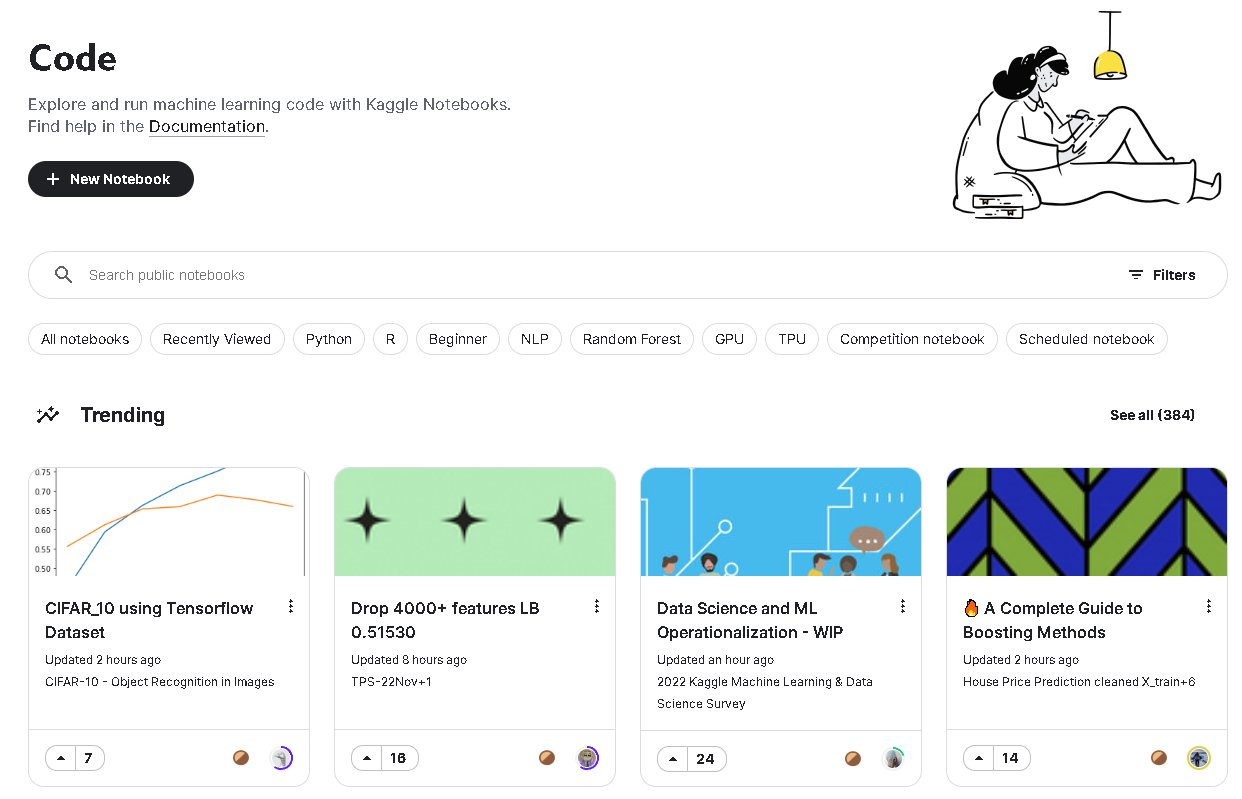
- [공식문서]
- Code 메뉴는 다른 사람이 올려놓은 캐글 코드(노트북)를 모아 놓은 페이지로 안내해줍니다. 경진대회와 연관된 코드도 있고, 데이터셋에 올라온 데이터를 분석한 코드도 있습니다.
- 노트북의 유형: **Scripts, Notebooks**
- 데이터셋과 마찬가지로 각 코드에도 메달이 표시되어 있습니다.
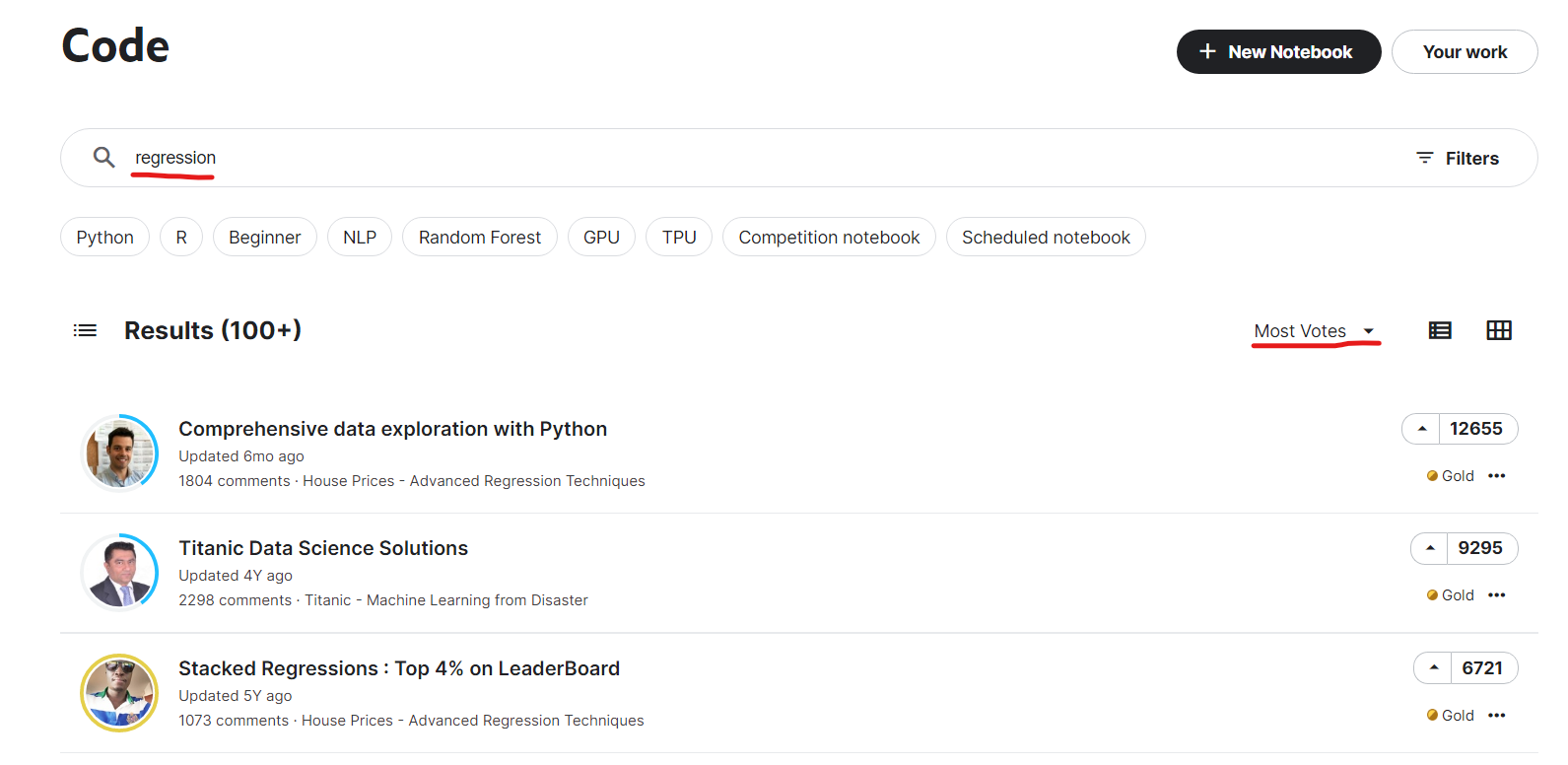
- 데이터셋과 마찬가지로 노트북도 원하는 키워드로 검색할 수 있습니다. 예컨대 회귀(regression)
와 관련된 노트북을 찾아보고 싶다면 검색창에 “regression”이라고 칩니다. - 기본적으로 “Hotness” 로 정렬
- “Hotness” : 노트북의 흥미도 (추천수 및 조회수와 같은 항목에서 높은 점수를 받은 최근에 작성된 노트북이거나, 오랫동안 플랫폼에서 일관되게 인기 있는 "최고의" 위대한 노트북)
- 나머지
- Most Votes : 역대 가장 인기 있는 노트북
- Most Comments : 가장 많이 논의된 노트북
- Recently Created : 새로운 노트북의 실시간 스트림
- Recently Run : 실시간 활동 스트림
- Relevance : 쿼리와의 관련성을 기준으로 결과를 정렬
- Most Votes : 역대 가장 인기 있는 노트북
- 추천수가 많은 순으로 검색하고 싶다면 정렬 옵션을 ‘Most Votes’로 선택합니다. 그런데 제목에 regression이라는 단어가 없는 노트북도 있습니다. 이는 해시태그 때문입니다. 노트북을 만들 때 해시태그를 설정할 수 있는데, ‘regression’ 해시태그를 추가한 노트북도 함께 검색된 것입니다.
Discussions
- Q&A 공간입니다. 경진대회를 진행하며 궁금한 점을 다른 사람에게 물어볼 수 있습니다.
- 서로 의견을 공유하며 새로운 아이디어를 얻을 수도 있습니다. 주로 코드가 아닌 인사이트를 공유하며, 궁금한 점에 대한 솔루션 또한 공유합니다.
- 대회나 데이터 셋에 대한 문의, 또는 경진대회에 같이 참여할 팀원을 모집 하는 등 다방면으로 의견을 공유하고 아이디어를 얻을 수 있는 장입니다.
- 전 세계 유능한 데이터 과학자와 의견을 공유할 수 있다는 것은 굉장한 이점입니다.
Learn : 강좌
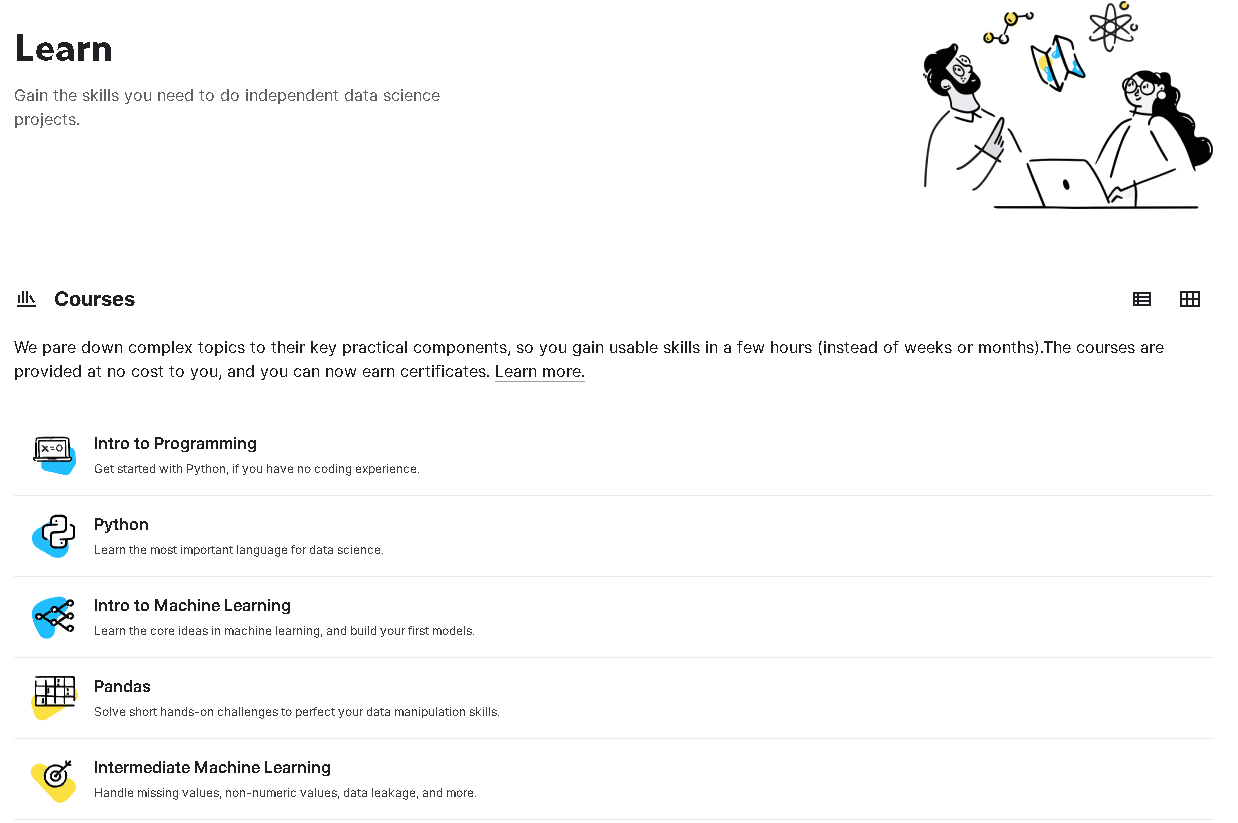
- 캐글 관련 강좌를 들을 수 있습니다. 파이썬, 머신러닝 입문, 머신러닝 중급, 데이터 시각화, 판다스, SQL기초, SQL고급, 딥러닝 기초 등 다양한 강좌가 있습니다.
- 빠르게 기초 개념을 복습하기에 유용합니다. 강좌를 마치면 수료증도 줍니다. 캐글 노트북으로 실습을 제공하니 캐글에 익숙해지는 데에도 도움이 될 것입니다.
캐글 API
Kaggle API 설치
- Docs
Kaggle API 설치는 pip 패키지로 인스톨 해주시면 됩니다.
Kaggle API Token 다운로드 (.json 파일)
먼저 Kaggle에 로그인 한 뒤 Account로 접속합니다.
바로 접속할 수 있는 주소는 다음과 같으며, username만 치환해 주신 뒤 접속하시면 됩니다. (혹은, 우측 상단에 프로필 사진을 클릭한 뒤 Account를 클릭하시면 됩니다.)
My Account 접속 주소
https://www.kaggle.com/<username>/account
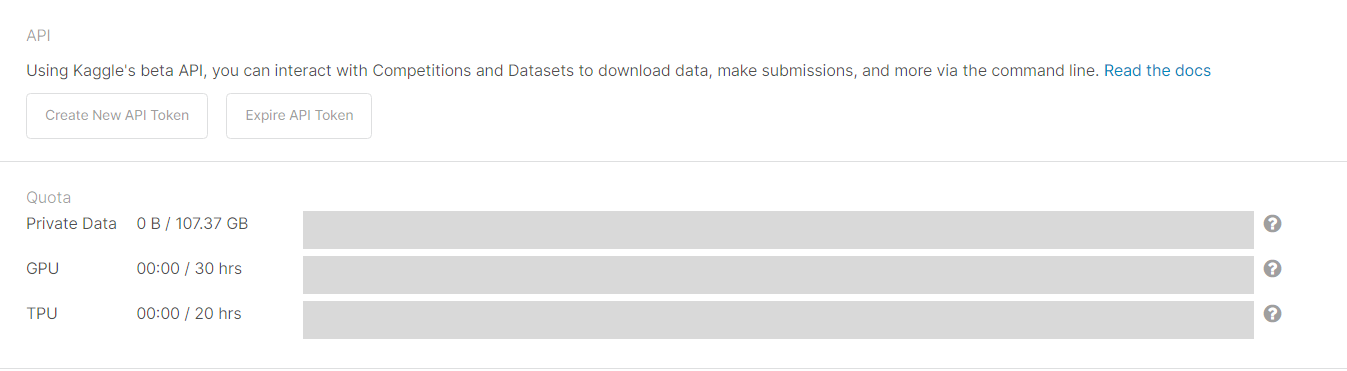
Account에 들어온 뒤, 스크롤을 내리다 보면 Create New API Token이 있습니다. 버튼을 누르면 Token을 생성합니다(kaggle.json 파일이 다운로드 됩니다).
OS별 설치 경로
Windows
C:\Users\<Windows-username>\.kaggle\kaggle.json
Mac OS / Linux (Unix-based)
~/.kaggle/kaggle.json
[필수 X] 보안을 위하여 다음과 같이 권한을 변경해 줄 수 있습니다.
chmod 600 ~/.kaggle/kaggle.json
Command Lists
- 설치한 kaggle api의 정보
- 진행중인 Competition List 살펴보기
kaggle competitions{list, files, download, submit, submissions, leaderboard}
# 경진대회 API의 도움말 보기
!kaggle competitions list -h
----------------------------------
usage: kaggle competitions list [-h] [--group GROUP] [--category CATEGORY]
[--sort-by SORT_BY] [-p PAGE] [-s SEARCH] [-v]
optional arguments:
-h, --help show this help message and exit
--group GROUP Search for competitions in a specific group. Default is 'general'. Valid options are 'general', 'entered', and 'inClass'
--category CATEGORY Search for competitions of a specific category. Default is 'all'. Valid options are 'all', 'featured', 'research', 'recruitment', 'gettingStarted', 'masters', and 'playground'
--sort-by SORT_BY Sort list results. Default is 'latestDeadline'. Valid options are 'grouped', 'prize', 'earliestDeadline', 'latestDeadline', 'numberOfTeams', and 'recentlyCreated'
-p PAGE, --page PAGE Page number for results paging. Page size is 20 by default
-s SEARCH, --search SEARCH
Term(s) to search for
-v, --csv Print results in CSV format (if not set print in table format)
----------------------------------
# commerce에 해당되는 경진대회 목록
!kaggle competitions list -s commerce
----------------------------------
ref deadline category reward teamCount userHasEntered
---------------------------------------- ------------------- -------- ------- --------- --------------
otto-recommender-system 2023-01-31 23:59:00 Featured $30,000 80 False
cdiscount-image-classification-challenge 2017-12-14 23:59:00 Featured $35,000 626 False
----------------------------------- 데이터셋 다운로드 하기
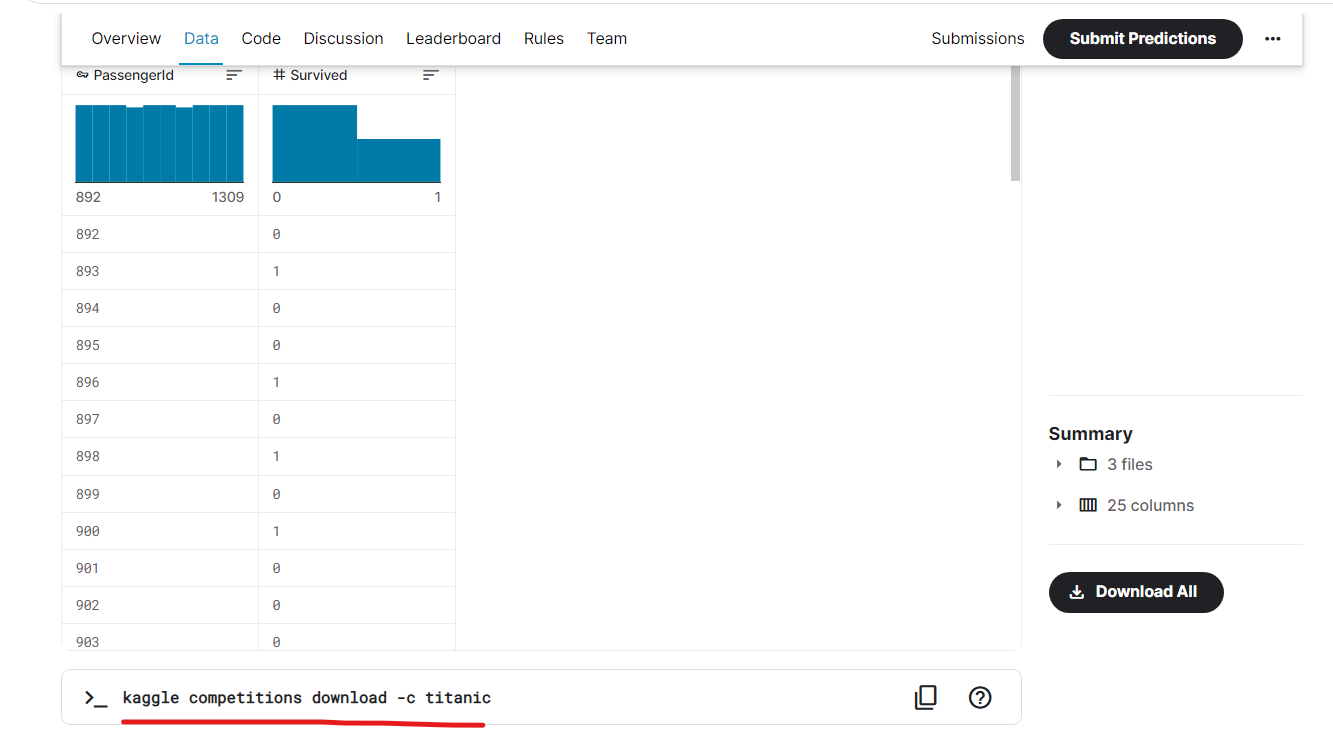
- 참고 : 캐글 경진대회 하단에서도 Kaggle API로 데이터를 받을 수 있는 Command Line 명령어를 알려줍니다.
# titanic 경진대회 데이터셋 보기
!kaggle competitions files -c titanic
----------------------------------
name size creationDate
--------------------- ---- -------------------
test.csv 28KB 2018-04-09 05:33:22
train.csv 60KB 2018-04-09 05:33:22
gender_submission.csv 3KB 2018-04-09 05:33:22
----------------------------------
# 데이터셋 다운로드(현재 위치에)
!kaggle competitions download -c titanic
# 경로 지정
# !kaggle competitions download -c titanic -p 경로위치이렇게 다운받은 데이터셋은 zip 파일이므로 파일의 압축을 풀어줘야 합니다. jupyter에서 한번에 처리할 수 있도록 shutil 라이브러리를 사용합니다.
import shutil
filename = 'titanic.zip' # 압축 해제할 파일 이름
extrac_dir = 'titanic' # 압축 해제할 폴더 이름
archive_format = 'zip' # 압축 파일 형태
shutil.unpack_archive(filename, extrac_dir, archive_format) # 현재 위치에 압축 해제- 제출하기
- 데이터셋 다운로드와 마찬가지로, 캐글 경진대회 submit란에 Command Line 명령어가 있습니다.
- 제출할 .csv 파일이 있는 디렉토리로 이동한 뒤, 복사한 명령어를 입력해주면 제출하게 됩니다.
- -f 옵션 뒤에는 내가 제출할 .csv file 이름을 적어야 합니다.
- -m옵션 뒤에는 제출할 때 간단한 message를 남길 수 있습니다.(Description)
kaggle competitions submit -c titanic -f submission.csv -m "Message"Successfully submitted to Titanic: Machine Learning from Disaster(kaggle) ← 메세지와 함께 성공적으로 제출되었음을 확인할 수 있습니다.
