
🦁🦁
👉 오늘 한 일
- K-MOOC(실습으로 배우는 머신러닝) 수강
실습으로 배우는 머신러닝
인공지능과 머신러닝 개요
과거의 AI(Traditional AI) : Knowledge Engineering
- 지식을 잘 조직해서 우리가 유용한 함수로 만들어줌
- 머신러닝에서 학습하는 함수를 사람이 직접 코딩을 함
최근의 AI(State of the Art) : 머신러닝, 딥러닝 등
- 데이터를 입력, function의 기본 형태를 컴퓨터에 알려줌. 그러면 트레이닝 과정을 통해서 최종적인 optimal function을 컴퓨터 스스로 학습
- 최근 트렌드는 인지 문제 즉, 패턴을 인지하는 문제
- 완벽한 머신러닝 알고리즘은 없음
머신러닝이 각광받는 이유
- 빅데이터 시대이기 때문
- 분산화된 컴퓨팅 장비(CPU -> GPU)
- GPU는 graphical한 프로세싱을 도와줌
- 분산해서 빠르게 쉬운 계산들을 처리할 수 있다는 게 굉장히 큰 장점
- 실제로 많은 산업에서 머신러닝을 이용해 기존에 없었던 가치를 만들어냄
머신러닝 학습 개념
Linear Regression 예제
- 대략적인 모델의 구조를 세움
- 로스함수(손실함수) 정의
- 실제와 모델에서 나오는 값의 차이를 최소화
머신러닝 프로세스 및 활용
손실함수를 최소화하는 알고리즘의 방법론
1. 휴리스틱(Heuristic) : 정확한 수리적인 최적화 기법을 적용하지 않고 대략적인 접근을 통해서 손실함수가 최소화가 되게끔 유도함
- K-Nearest Neighbor
- Decision tree
- Numerical optimization : 수리적으로 모델과 로스함수를 정의하고, 최적화하는 절차들도 정의됨
- Linear regression
- Logistic regression
- Support vector machine
- Neural network
모델의 복잡도가 올라갈수록 train error는 줄지만 validation error는 감소하다가 어느 시점부터는 상승함(overfitting)
- 너무 단순하면 underfitting 발생
model validation
방법 1. train 데이터셋으로만 검증(bad)
방법 2. train, test로 나눠서 검증(파라미터 튜닝 이후)
방법 3. train, validation, test로 나눠서 검증(가장 권장)
방법 4. cross-validation : 데이터셋을 test, train으로 나눈 뒤, train 안에서 서로 번갈아가면서 train과 validation 진행
머신러닝 분류 모델링
모델의 오차 : bias + variance
- 모델의 복잡도가 낮아질수록 bias는 증가, variance는 감소
- 모델이 복잡해질수록 bias는 감소, variance는 증가
KNN
KNN(K-Nearest Neighbors)
-
K는 임의의 상수
-
두 관측치의 거리가 가까우면 Label도 비슷하다
-
test 데이터셋을 기준으로 train 데이터셋의 K개 주변 관측치의 class에 대한 majority voting
-
lazy learning algorithm이라고도 함
-
범주형 변수는 더미변수로 처리해서 거리 계산
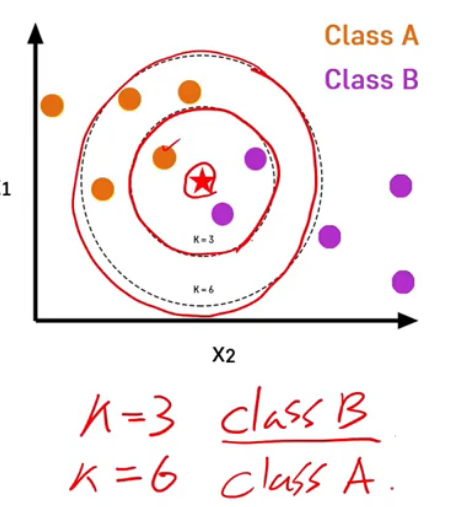
K가 KNN의 하이퍼파라미터가 됨
- K가 클수록 underfitting 가능성 높음, K가 작을수록 overfitting 가능성 높음
- validatin 데이터셋을 활용해 최적의 K 찾기
Logistic Regression
다중선형회귀 : 설명변수 X와 종속변수 y간의 관계를 선형으로 가정, 이를 가장 잘 표현할 수 있는 회귀 계수 추정
로지스틱 회귀 : y가 범주형 변수임. 일반 회귀분석과는 다르게 접근
y가 이진 변수일 때, 확률값을 선형회귀분석의 종속변수로 사용하는 것이 타당한가?
- 선형회귀의 우변은 범위에 제한이 없기 때문에 우변과 좌변의 범위가 다른 문제가 발생
- 분류 패턴의 문제에는 선형 함수가 적합하지 않음
- y에 대한 로짓함수(sigmoid function)를 회귀식의 종속변수로 사용
로지스틱 회귀의 목적 : 이진형태의 종속변수에 대해 회귀식 형태로 모델을 추정하는 것
🤔왜 회귀식인가?
- 변수의 통계적 유의성 분석 및 종속변수에 미치는 영향력 등을 알아볼 수 있음
로지스틱 회귀에 대한 손실함수 : cross entropy
경사하강법
근사적으로 표현할 수 있는 2차다항식 유도 -> 그 2차함수에서 기울기가 최소화되는 지점 찾기
💡learning rate
-
경사 하강법 최적화 알고리즘을 사용하여 훈련하는데서 나온 파라미터
-
모델의 weight가 업데이트 될 때마다 예상 오류에 대한 응답으로 모델을 조정하고 제어하면서 모델 학습에 영향을 주는 하이퍼 파라미터
-
Gradient descent algorithm을 사용할 때 cost 값의 미분한 값 앞에 알파라는 값이 오게 되는데 이 값이 Learning rate임. Learning rate은 어느 정도의 크기로 기울기가 줄어드는 지점으로 이동하겠는가를 나타내는 지표
-
확률적 경사 하강법(SGD : Stochastic Gradient Descent) : 데이터셋의 일부를 이용해 배치 방식으로 기울기를 추정. 극단적으로 데이터 하나만을 이용해서 할 수도 있음
경사하강법(gradient descent) 알고리즘은 학습률(Learning rate, Learning step)으로 알려진 스칼라를 곱해서 다음 점을 결정. 예를 들어 경사 크기가 2.5이고 학습률이 0.01이면 경사하강법 알고리즘은 이전 지점에서 0.025 떨어진 지점에서 다음 지점을 선택.
💡모멘텀
local minimum을 빠져나가기 위해 적용하는 방법론. local minimum을 추정할 때의 관성을 local minimum에 도달했을 때 더해줘서 더 좋은 local minimum 혹은 global minimum을 탐색하고자 함
- SGD + Momentum이 딥러닝에서 가장 많이 쓰임
SVM(Support Vector Machine)
SVM(Support Vector Machine) : 선형 분류, 비선형 분류, 회귀, 이상치 탐색에도 사용할 수 있는 머신러닝 방법론
-
딥러닝 이전 시대까지 널리 사용됨
-
복잡한 분류 문제를 잘 해결, 작거나 중간 크기를 가진 데이터에 적합
-
두 클래스 사이에서 가장 넓은 분류 경계선을 찾음(margin이 가장 큰 것)
-
스케일에 민감하기 때문에 변수들 간의 스케일을 잘 맞춰주는 것이 중요(
sklearn.StandardScaler())
💡support vector
- 각각의 클래스에서 분류 경계선을 지지하는(선과 맞닿아있는) 관측치
💡Hard margin vs soft margin
- Hard margin : 두 클래스가 하나의 선으로 완벽하게 나누어지는 경우 적용 가능한 방법
- soft margin : 일부 샘플들이 분류 경계선의 분류 결과에 맞지 않는 경우를 일정 수준 허용하는 방법
- C-penalty 파라미터로 조정. SVM의 하이퍼파라미터
- C 값이 작아질수록 마진은 커지지만 분류 정확도는 떨어짐(trade-off)
💡nonlinear SVM
polynomial kernel
- 다항식의 차수를 조절할 수 있는 효율적 계산 방법
gaussian RBF kernel
- 무한대 차수를 갖는 다항식으로 차원을 확장시키는 효과
- gamma : 고차항 차수에 대한 가중 정도
💡SVM regression
선형 회귀식을 중심으로 평행한 오차 한계선을 가정. 오차한계선 너비가 최대가 되면서 오차 한계선을 넘어가는 관측치들에 페널티를 부여하는 방식으로 선형회귀식 추정
