👉 오늘 한 일
- 벤츠 경진대회 - 부스팅 계열 모델 이어서
- SMOTE
- Confusion matrix
벤츠 경진대회 - 부스팅 계열 모델
💡부스팅 계열 모델 - XGBoost, LightGBM, CatBoost
💡XGBoost
-
xgboost는 GBT에서 병렬 학습을 지원하여 학습 속도가 빨라진 모델임
-
기본 GBT에 비해 더 효율적이고, 다양한 종류의 데이터에 대응할 수 있으며 이식성이 높음
-
캐글 등 머신러닝 경연 대회에서 우승 후보들이 사용하는 도구로 성능이 아주 좋음
-
XGBoost의 목표는 손실 함수가 최대한 감소하도록 하는 split point(분할점)를 찾는 것
🤔왜 learning_rate가 낮을 때 n_estimator 값을 높여야 과적합이 방지될까?
-
learning_rate를 줄인다면 가중치 갱신의 변동폭이 감소해서, 여러 학습기들의 결정 경계(decision boundary) 차이가 줄어들게 됨
-
n_estimators 를 늘린다면 생성하는 약한 모델(weak learner)가 늘어나게 되고, 약한 모델이 많아진만큼 결정 경계(decision boundary)가 많아지면서 모델이 복잡해지게 됨
-
즉, 부스팅알고리즘에서 n_estimators와 learning_rate는 trade-off 관계임
-
n_estimators(또는 learning_rate)를 늘리고, learning_rate(또는 n_estimators)을 줄인다면 서로 효과가 상쇄됩니다.
-
n_estimator 값이 너무 높으면 overfitting이 될수도 있음
🤔부스팅 모델은 왜 오버피팅에 민감할까?
- 이전 트리(이전 학습)가 다음 트리(다음 학습)에 영향을 주기 때문에
🤔배깅 모델은 시각화가 어려워 3rd party 도구를 따로 설치해야 시각화가 가능함. 그것도 개별 트리를 시각화 하는 것은 어려움. 그런데 부스팅 모델은 왜 시각화가 가능할까?
- 배깅모델은 병렬적으로 트리를 여러 개 생성하는데 부스팅은 순차적으로 생성하기 때문에
예제 코드
import xgboost as xgb
# 베이스라인 모델 구축
model_xgb = xgb.XGBRegressor(random_state=42, n_jobs=-1)
# fit
model_xgb.fit(X_train, y_train)
### fit 이후 가능
# feature importance 시각화
xgb.plot_importance(model_xgb)
# 트리 시각화
xgb.plot_tree(model_xgb, num_trees=1)
# r2 score 구하기
model_xgb.score(X_valid, y_valid)💡LightGBM
-
GOSS(Gradient based One Side Sampling)와 EFB(Exclusive Feature Bundling)를 적용해 XGBoost와 비교해 정확도는 유지하며, 학습 시간을 상당히 단축시킨 모델임
-
트리 기준 분할이 아닌 리프 기준 분할 방식을 사용함. 트리의 균형을 맞추지 않고 최대 손실 값을 갖는 리프 노드를 지속적으로 분할하면서 깊고 비대칭적인 트리를 생성
- 균형을 맞추지 않고 최대 손실 값(max delta loss)을 가지는 리프 노드를 지속적으로 분할하여 트리가 깊어지고 비대칭적인 트리 구조를 생성하여 예측 오류 손실을 최소화
💡GOSS(Gradient based One Side Sampling) 기울기 기반 단측 샘플링
- 데이터에서 큰 Gradient를 가진 모든 인스턴스를 사용해서 무작위로 Sampling을 수행함
- 많이 틀린 데이터 위주로 샘플링
- 이 과정을 통해 행을 줄이게 됨
💡EFB 배타적 특성 묶음 (Exclusive Feature Bundling)
- 대규모 Features 수를 다루기 위한 것
- 열을 줄임
GBDT(Gradient Boosting Decision Tree)는 Feature 차원이 높고 데이터 크기가 클 경우, 가능한 모든 분할 지점의 Information Gain을 추정하기 위해 모든 데이터 인스턴스를 탐색해야 될 때 많은 시간을 소비해야 한다는 문제가 있음
💡CatBoost
-
기존 알고리즘과 비교하여 순열 기반 대안을 사용하여 범주형 기능을 해결하려고 시도하는 그레디언트 부스팅 프레임워크를 제공
-
기존 GBT의 느린 학습 속도와 과대적합 문제를 개선한 모델
-
category 타입으로 되어있으면 lightGBM, CatBoost에서 인코딩 없이 사용 가능
- catboost의 경우
cat_features파라미터에 카테고리 형태의 피처들을 지정해 주어야 함
- catboost의 경우
장점
- 범주형 피처에 대한 기본 처리(인코딩 하지 않아도 됨)
- 빠른 GPU 훈련
- 모델 및 기능 분석을 위한 시각화 및 도구
- 과적합을 극복하기 위해 순서가 있는 부스팅을 사용
- 자체적으로
grid_search()와randomized_search()를 제공
💡성능이 낮은 장비에서 n_jobs=-1을 쓰면 노트북이 dead kernel 이 되는 현상이 있음
- 성능이 낮은 장비거나 다른 작업이 많이 진행되고 있다면 n_jobs를 1로 설정하면 좀 나음
SMOTE
💡배경
-
분류 모델링 시 테스트 데이터셋의 정확도를 저하하는 요인 중 하나는 클래스 불균형임.
-
클래스 불균형은 모델링의 대상 데이터에서 각 클래스가 가지는 데이터의 양에서 차이가 큰 현상을 말함.
- e.g. 성별 예측 모형을 생성하기 위한 데이터가 여성 100명, 남성 500명임
-
이러한 불균형은 생성한 예측 모형이 특정 클래스(위에서는 남성)에 치우치게 만들거나, 적절한 평가를 어려워지게 하는 요인으로 작용함.
-
이러한 클래스 불균형을 해결하기 위한 방법 중 하나가 SMOTE임
💡개념
-
SMOTE(Synthetic Minority Over-sampling Technique)는 오버샘플링 기법 중 하나임
-
낮은 비율로 존재하는 클래스의 데이터를 최근접 이웃(K-NN) 알고리즘을 활용하여 새롭게 생성하는 방법
-
오버 샘플링 기법 중 단순 무작위 추출을 통해 데이터의 수를 늘리는 방법도 존재하는데, 데이터를 단순하게 복사하기 때문에 과적합 문제가 발생하기도 함
-
MOTE는 알고리즘을 기반으로 데이터를 생성하므로, 과적합 발생 가능성이 단순 무작위 방법보다 적음
Confusion matrix
🤔confusion matrix 가 책마다, 사이트마다 순서가 다 다른데 어떤 것을 기준으로 해야할까?
- 사이킷런 기준으로 보는게 그나마 덜 헷갈림
🤔왜 사용할까?
- 불균형 데이터에서 accuracy 지표가 가지는 맹점 때문에 Precision과 Recall 지표가 필요하기 때문
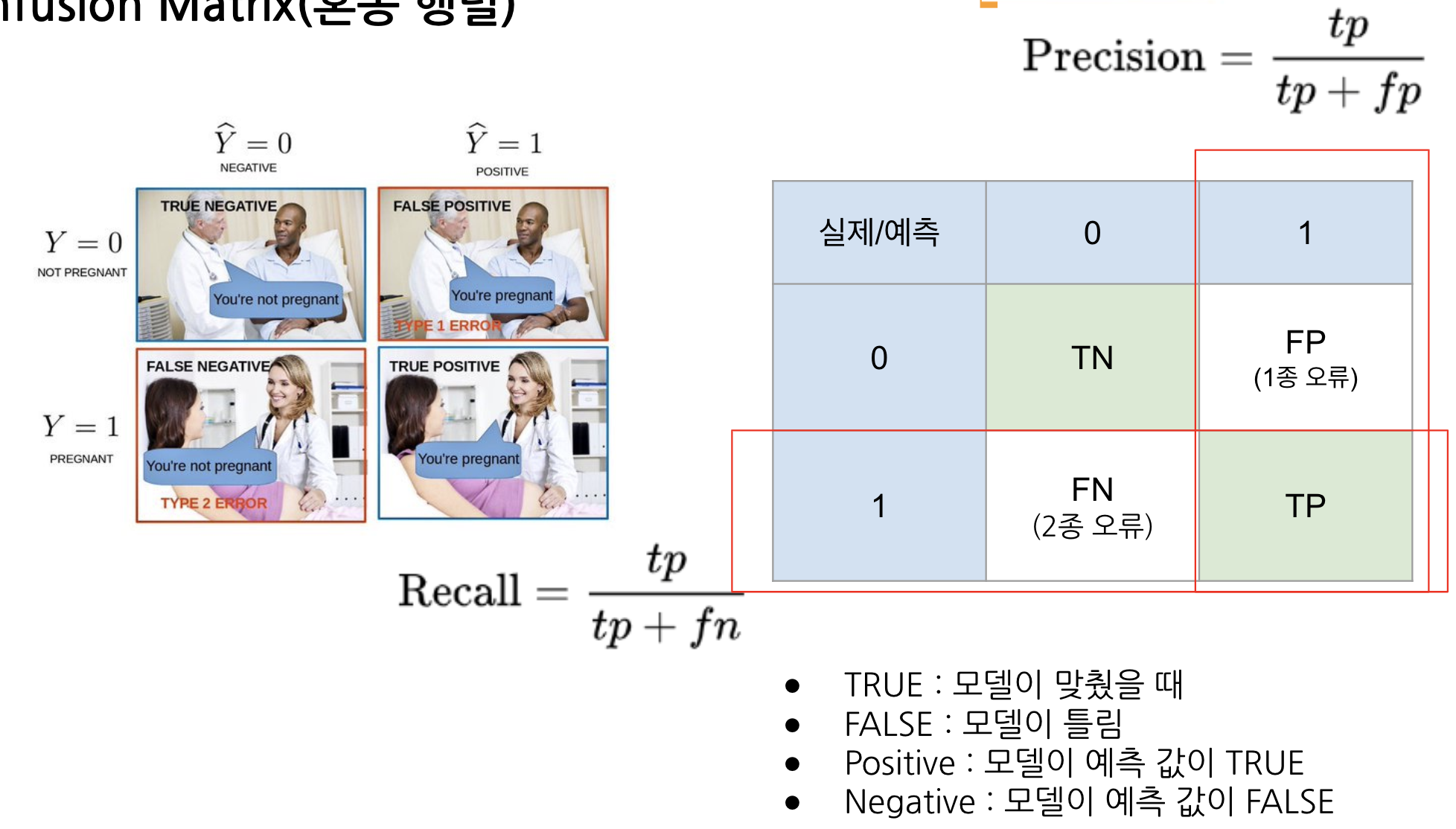
-
1종 오류와 2종 오류는 trade-off 관계임
-
예측값이 1인 것을 기준으로 하는 계산 => Precision
-
실제값이 1인것을 기준으로 하는 계산 => Recall
-
f1-score : precision과 recall의 조화평균(precision, recall 두개 다 중요한 경우 지표로 사용)
-
정답인데 못 찾은 것이 많다 => Recall 이 낮다
-
정답이 아닌데도 정답이라고 한 것이 많다 => Precision 이 낮다
📌오늘의 회고
- 사실(Fact) : 벤츠 경진대회를 통해 부스팅 계열 모델을 학습하고 분류 문제의 평가지표인 confusion matrix를 배웠다.
- 느낌(Feeling) : lightGBM과 CatBoost에서 인코딩 없이 범주형 데이터들을 처리해준다는 점이 편리해보였다.
- 교훈(Finding) : 부스팅 계열 모델들이 파라미터가 많아 나중에 사용하기 위해 어떤 기능을 하는지 정도는 알아둬야겠다.
