
👉 오늘 한 일
- 비즈니스 데이터 분석 (1201 ~ )
비즈니스 데이터 분석
🤔pandas.style.background_gradient() 와 seaborn.heatmap()의 차이?
- pandas 의 background_gradient() => 변수마다 성질이 다를 때, 각 변수별로 스케일값을 표현.
- seaborn 의 heatmap() => 같은 성질의 변수를 비교할 때, 전체 수치데이터로 스케일값을 표현.
🤔아래 히스토그램을 어떻게 해석할 수 있을까?
- 값이 1 가까운 부분에 쏠려있고 이상치가 있음
🤔결제 테이블에는 무엇이 있을까? (어트리뷰트)
- 고객ID, 주문서ID, 총결제금액, 결제수단, 결제일자, PG사승인번호, 상태값(완료, 실패) 등
🤔라이브러리 버전이 업데이트 될 때마다 노티를 받을 수 있는 방법이 있을까?
- 공식 github 이슈를 메일로 받아보는게 가장 좋음
🤔라이브러리 최신버전을 사용하고 싶은데 다른 라이브러리와 호환 문제로 최신 버전을 사용할 수 없을 때는?
- 가상환경을 이용
🤔실제 비즈니스에서 중복 데이터는 왜 생길까?
- 중복 데이터는 게시판에 글을 쓸 때 네트워크가 불안정할 때 전송버튼을 두 번 누르거나 서버측 트래픽 이슈로 중복 해서 쌓이는 경우가 발생하기도 함. 요즘은 대부분 이런 이슈가 없도록 프론트, 백엔드 개발에서 고려해서 프로그램을 작성하지만 그래도 중복 이슈가 발생하기도 함
지표 계산
💡ARPPU 구하기
- ARPU(Average Revenue Per User) :
- 가입한 서비스에 대해 가입자 1명이 특정 기간 동안 지출한 평균 금액
- ARPU = 매출 / 중복을 제외한 순수 활동 사용자 수
- ARPPU(Average Revenue Per Paying User):
- 지불 유저 1명 당 한 달에 결제하는 평균 금액을 산정한 수치
# 계산
arppu = df_valid.groupby('InvoiceYM').agg({"TotalPrice" : "sum", "CustomerID" : "nunique"})
arppu.columns = ["sale_sum", "customer_count"]
arppu["ARPPU"] = arppu["sale_sum"] / arppu["customer_count"]
arppu.style.format("{:,.0f}")
# 시각화
arppu["ARPPU"].plot(figsize=(12,4), title="Monthly ARPPU");
# 고객별 구매 빈도수, 평균 구매 금액, 총 구매금액
cust_agg = df_valid.groupby("CustomerID").agg({"InvoiceNo" : ["nunique", "count"], "TotalPrice" : ["mean", "sum"]})
cust_agg.columns = ['nunique', 'count', 'mean', 'sum'] # 컬럼값이 튜플 형태로 들어가 있어서 바꿔줌- 지불 유저 한 명 당이므로 중복을 세지 않기 위해 CustomerID에
count가 아닌nunique사용
💡MAU 구하기
- 월별 활동한 이용자를 의미
# 계산
mau = df_valid.groupby("InvoiceYM")[["CustomerID"]].nunique()
# 시각화
mau.plot.bar(figsize=(12,4), rot=0, title="MAU(Monthly Active User)");
# 월별, 주문건, 중복을 제외한 주문제품 종류 수, 고객 수, 총 주문금액
df.groupby("InvoiceYM").agg({"InvoiceNo" : "count",
"StockCode": "nunique",
"CustomerID": "nunique",
"UnitPrice" : "sum",
"Quantity" : "sum",
"TotalPrice" : "sum"
})리텐션 구하기
🤔리텐션은 무엇일까?
- 코호트 기법에서 시간으로 묶어서 분석하는 것이 리텐션이고 리텐션으로는 이탈, 성장 등을 분석할 수 있음
- 이탈 - 지난 달에 구매한 사람이 이번달에도 구매했는가?
- 성장 - 지난 달에 비해 매출액이 늘어났는가?
🤔개월수로 구한다면 어떻게 구할까?
- 고객의 첫 구매월을 찾음. 첫 구매월과 해당 구매 시점의 월의 차이를 구하고 첫 구매한 달로부터 몇 달째 구매인지를 구함
- 고객의 해당 구매월 - 첫 구매월. => 해당 구매가 첫 구매로 부터 몇 번째 달의 구매인지를 구할 수 있음
# 월단위 데이터 처리
df_valid["해당구매월"] = pd.to_datetime(df_valid["InvoiceYM"])
# 모든 데이터에 적용하기 위해 transform 사용
df_valid["최초구매월"] = df_valid.groupby("CustomerID")["해당구매월"].transform("min")
# 첫 구매일로부터 몇 달 째의 구매일까?
year_diff = df_valid["해당구매월"].dt.year - df_valid["최초구매월"].dt.year
month_diff = df_valid["해당구매월"].dt.month - df_valid["최초구매월"].dt.month
# 같은 년도의 같은 월을 0이 아닌 1로 표시
df_valid["CohortIndex"] = (year_diff * 12) + month_diff + 1
# 리텐션 시각화
sns.countplot(data=df_valid, x="CohortIndex")
# 잔존 빈도 구하기
cohort_count = df_valid.groupby(["최초구매월", "CohortIndex"])["CustomerID"].nunique().unstack()
cohort_count.index = cohort_count.index.astype(str).str[:7]
# 잔존율 구하기
cohort_norm = cohort_count.div(cohort_count[1], axis=0)
# 시각화
sns.heatmap(cohort_norm, annot=True, fmt=".2f", cmap="Blues")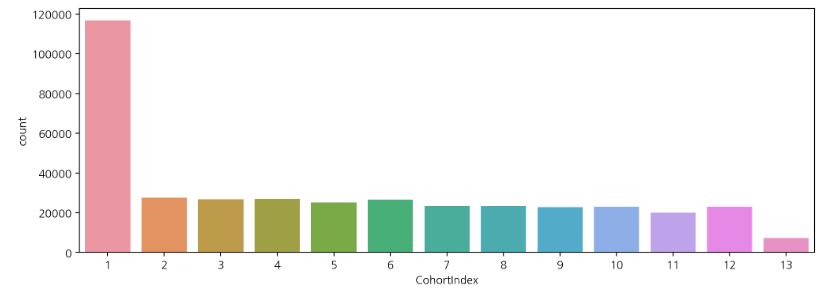
- 첫 달에만 구매하고 다음달 부터 구매하지 않는 사람이 많음
- 마케팅비를 많이 투자해서 고객을 유치했지만 유지가 잘 되지 않는 것
- 휴면 고객을 위한 이벤트, 쿠폰 등이 적절한 시점에 있으면 도움이 되겠다라는 계획을 세워볼 수 있음
RFM 분석
-
RFM은 가치있는 고객을 추출해내 이를 기준으로 고객을 분류할 수 있는 분석방법
-
구매 가능성이 높은 고객을 선정하기 위한 데이터 분석 방법
-
R(Recency) - 최근에 구매했는지?
-
F(Frequency) - 얼마나 자주 구매했는지?
-
M(Monetary) - 얼마나 많은 금액을 구매했는지?
- 이 기준으로 고객 Segment 를 나누는 것
-
가장 큰 과제는 그룹 경계를 정의하는 것
💡JD
출처 : nc soft 면접관 관점에서 채용후기
https://m.blog.naver.com/rlawoals93/221372472680
[서류전형]
1. 전반적으로 지원서의 수준 및 스펙(어학연수, 공모전, 아르바이트, 학점, 영어점수)이 매우 훌륭.
2. 서류를 통해서 개인의 전문성이나 직무에서의 역량을 파악하기는 힘들다.
3. 지원자의 성실함과 꼼꼼함을 확인하기 위한 자료
4. 대다수의 서류 형식이 비슷. 지원자의 90%가 핵심 주제를 대괄호([])로 묶는 등등..
5. 공모전 수상자의 우대조건이 명시되어 있었으나, 절반 가까운 지원자가 대회 참여 혹은 수상 경험이 존재
6. 정성적인 표현(ex. '끈기를 갖고 ~~ 뿌듯했다')보다는 정략적인 표현(ex. ~ 라이브러리를 이용하여 전처리, ~모델을 만들어 AUC가 높은 모델 선택)이 더 호감이 간다.
7. 전문 용어, 최신 기술을 어설프게 서술할 경우 반대 효과가 존재. 'LSTM을 활용하여 ~하겠다.'와 같이 기술의 이론을 잘 모른채 표현하는 것 처럼..
8. github, 블로그 등의 문서 외 자료가 인상적. 다만 방치해 놓은 사이트는 크게 도움이 되지 않을 듯.
9. 과도한 포부, 어설픈 조언은 오히려 역효과
- 게임 점유율을 40% 달성 시키겠다.
- 고객의 트렌드를 예측하도록 인적자원을 관리해야 한다.
- 번지수를 잘못 찾은 포부
- 알파고를 개발하겠다. (게임분석 부서 채용담당자이다.)
- 용량이 적은 게임을 개발 하겠다. (")
- 적절한 포부, 재미있는 표현은 호감
- 작은 성공을 꾸준히 이어가는 small win을 추구한다.
- 워러밸(working & learning balance)을 통해 발전하겠다.
- 최악은 잘못된 회사명, 정보 기재
- 구글, 네이버
- 마비노기
[면접]
1. 공통질의
- 공통질의에서 알고자 하는 것은 커뮤니케이션 능력, 호기심, 업무에 대한 관심사
- 지원자간에 답변 수준은 크게 차이가 없음
- 아쉬운 점은, 공통질의 2번 문항에서 모델링이나 시각화 기법에만 치중한 것. 데이터를 어떻게 수집하고 정제하고 어떤 가설을 갖고 분석할지 전체 흐름에 대한 체계적인 답변을 기대
-
질의 내용

-
면접 피드백
-
좋았던 점
1) 긴장하지 않는 태도
2) 회사, 팀 업무에 대한 질문을 적극적으로 하는 태도
3) 입사할 경우 하고 싶은 일을 구체적으로 제시하는 태도
4) 포트폴리오에 정성이 보이는 지원자
5) 직무관련 프로젝트를 경험한 지원자
6) 면접관 입장에서 새롭고 흥미로운 얘기를 설득력있게 전달할 수 있는 태도 -
아쉬웠던 점
1) 분류 모델링 기법을 잘못 표현(Latent Dirichlet Allocation, Linear Discriminant Analysis 혼용)
2) 면접관의 입맛에 맞는 모범 답안만을 준비한 지원자
3) 개인의 종교적인 신념을 지속적으로 강조하는 태도
4) 과도하게 긴장한 지원자
5) 자신감이 부족한 지원자(서류 전형을 통과할 생각을 못함, 학과 관련 전문성이 떨어짐)
📌오늘의 회고
- 사실(Fact) : ARPPU, MAU, 리텐션 등 여러 비즈니스 지표들을 구하기 위한 전처리 실습을 진행했다.
- 느낌(Feeling) : 판다스의 background gradient 기능과 seaborn의 heatmap 의 기능 차이를 새로 알았다.
- 교훈(Finding) : 처음부터 구현하면서 복습해봐야겠다.
