개요
스파게티 코드를 작성하지 않으려면 프로그램을 설계하는 능력이 중요하다.
체계적이고 확장성이 좋으며 변경에 민감하지 않아야 나중에 유연하게 고칠 수 있는 프로그램이 된다고 한다.
하지만 처음부터 좋은 설계를 하는 것은 쉽지 않다. 실패했던 경험이 쌓여야 어느 기능을 분리 시키고, 합쳐야 하는지 직감적으로 알 수 있기 때문이다.
마치 데이터베이스 수업 시간 때 들었던 관계형 데이터베이스 설계가 생각난다.
하지만 감각이나 센스가 중요한 데이터 베이스에도 1차 정규형, 2차 정규형과 같이 "이럴 때는 이렇게 해야 한다."라는 명확한 기준을 제시해 주는 방법이 존재한다.
객체지향에도 위와 같은 기틀인 SOLID 5 가자 설계 원칙이 있다.
SOLID 원칙은 객체 지향 설계를 할 때에 명확한 기준을 제공하는데, 이런 규칙은 경험이 없어도 좋은 프로그램 설계를 할 수 있도록 도와준다.
-
단일 책임 원칙 (Single responsibility principle; SRP)
-
개방-폐쇄 원칙 (Open-closed principle; OCP)
-
리스코프 치환 원칙 (Liskov substitution principle; LSP)
-
인터페이스 분리 원칙 (Interface segregation principle; ISP)
-
의존 역전 원칙 (Dependency inversion principle; DIP)
이번에는 이 다섯 가지 원칙들을 공부한 것을 정리해 보자
1. 단일 책임 원칙 (Single responsibility principle; SRP)
첫 번째는단일 책임 원칙이다.
"클래스는 단 한개의 책임을 가져야 한다."
단일 책임 원칙은 다섯 가지 원칙 중에서 가장 중요한 원칙인데, 객체 지향의 기본은 하나의 책임을 객체에게 할당하는 데에 있기 때문이다.
따라서 이 원칙이 지켜지지 않을 경우 다른 원칙을 지켜도 무용지물이 될 수 있다.
단일 책임의 원칙을 지키는지, 지키지 않는 지를 구분하려면 지키지 않았을 때에 일어나는 현상에 대해 알아야 합니다.
만약 하나의 클래스가 하나의 임무를 담당하지 않고 여러 가지의 임무를 담당한다면 어떻게 될까?
먼저 실수할 만한 상황을 가정하여 의도적으로 하나의 클래스에 두 임무를 부여해 보자.
"HTML 프로토콜을 이용하여 데이터를 불러와 화면에 보여주자."
public class DataViewer {
public void display(){
String data=getHtmlData();
updateUi(data);
}
public String getHtmlData(){
HttpClient client=new HttpClient();
client.connect();
String string=client.getResponese();
return string;
}
private void updateUi(String data){
ui.changeData(data);
}
}
데이터를 화면에 보여주기 위해서는 먼저 데이터를 불러와야 한다.
데이터를 html으로 받아오는 행동이 선행되어야 하기 때문에 무심코 DataViewer 클래스에 데이터를 가져오는 메소드를 작성하는 실수를 할 수 있다. 아직 까진 문제가 되지 않는다.
하지만 이러한 상황에서 http 통신을 socket통신으로 바꾸게 된다면, 또 이 여파로 데이터 타입 또한 byte로 바뀐다면 어떻게 될까?
클래스 내부에는 display와 getHtmlData가 String 타입으로 묶여 있다. 또한 display와 updateUi가 String으로 묶여 있다.
따라서 모든 데이터 타입을 바꿔 주어야 한다.
public class DataViewer {
public void display(){
byte[] data=getHtmlData(); //변경 1: 바이트 타입으로 변경
updateUi(data);
}
public byte[] getHtmlData(){
SocketClient client=new SocketClient(); //변경 2: 소켓으로 변경
client.connect(server,port);
byte[] bytes=client.getResponese();//변경 3: 통신 방식 변경의 여파로 byte 타입으로 변경.
return bytes;
}
private void updateUi(byte[] data){//변경 4: 매개변수 타입 변경.
ui.changeData(data);
}
}통신 방식 하나만 달라져도 데이터 타입이 바뀌며 그 여파로 많은 메소드들도 바꾸어야 한다.
더 복잡한 구조로 되어 있다면 바꾸어야 할 코드들이 훨씬 많을 것이다.
따라서 서로 영향을 받지 않아야 할 책임들이 영향을 받게 된다.
이러한 문제점을 고치려면 서로 다른 책임을 다른 클래스에 작성하여 분리하고, 양쪽 모두 데이터의 변화에 유연하게 데이터를 적절한 타입으로 추상화 한다면 해결할 수 있다.
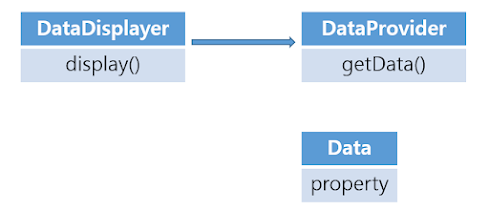
이렇듯 서로 다른 책임이 다른 클래스로 분리 되어 있다면 변경이 일어났을 때 서로 영향을 주지 않게 된다.
하지만 경험이 부족한 프로그래머는 단일 책임 원칙을 처음부터 잘 지키기 어렵다. 이러한 문제점을 잘 파악할 수 있는 방법은 무엇일까?
메소드를 실행시키는 것이 누구인지 파악하면 됩니다.
클래스의 사용자들이 서로 다른 하나의 메소드만을 사용한다면 다른 책임에 속할 가능성이 높다. 따라서 분리를 고려해 볼 대상이 된다.
2. 개방-폐쇄 원칙 (Open-closed principle; OCP)
두 번째는 개방 폐쇄 원칙 이다.
개방 폐쇄 원칙의 설명은 다음과 같은데,
"확장에는 열려 있어야 하고, 변경에는 닫혀 있어야 한다."
좀 더 쉽게 풀이하자면
기능을 변경하거나 확장할 수 있다.
그 기능을 사용하는 코드는 수정하지 않는다.
말이 조금 어렵지만, 우리는 이미 Interface를 사용하는 이유 에서 이러한 원칙을 해본 적이 있다.
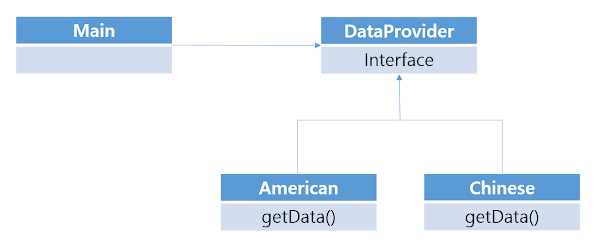
여기서 DataProvider라는 interface를 상속 받은 American과 Chinese는 서로 다른 기능을 하고, 서로 다른 타입이지만 DataProvider라는 같은 타입으로 묶을 수 있다.
따라서 Main에서 사용하는 메소드가 getData()인 것은 바뀌지 않는다
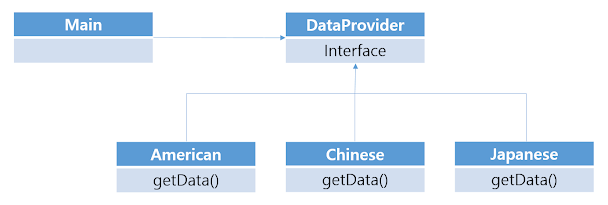
또한 DataProvider를 상속 받아 다른 기능인 Japanese를 확장할 수 있으며, 마찬가지로 Main에서 사용하는 메소드가 getData()인 것은 바뀌지 않는다.
따라서 확장에는 열려 있고, 변경에는 닫혀 있는 상태라고 할 수 있다.
개방 폐쇄 원칙을 지키는 또 다른 방법은 상속을 이용하는 방법이 있다.
"파일을 보내는 기능을 작성해 보자"
파일을 보내는 클래스를 미리 작성했다고 가정해 보자.
public class DataSender {
private Data data;
public DataSender(Data data){
this.data=data;
}
protected void sendData(){
//data sending
}
}위의sendData 메소드는 protected로, 확장 가능성이 있다고 명시 되어 있다.
따라서 DataSender 클래스를 상속 받는 클래스는 sendData를 이용하여 기능을 확장할 수 있다.
따라서 압축을 하여 보내는 기능이 필요하다고 느낄 때, 우리는 밑과 같이 클래스를 작성할 수 있다.
public class ZippedDataSender extends DataSender{
public ZippedDataSender(Data data) {
super(data);
}
@Override
protected void sendData(){
//zip data
super.sendData();
}
}
위의 클래스 DataSender의 입장에서 살펴 보면 확장에는 열려 있고
(protected void sendData is Overrode by ZippedDataSender)
변경에는 닫혀 있는(DataSender를 사용하는 클래스는 변경하지 않아도 된다.) 상태가 된다.
또한 데이터를 압축한 후 보내기는 데이터 보내기이다.이기 때문에 IS-A도 성립하게 된다.
3. 리스코프 치환 원칙 (Liskov substitution principle; LSP)
상위 타입의 객체를 하위 타입의 객체로 치환해도 상위 타입을 사용하는 프로그램은 정상적으로 동작해야 한다.
리스코프 치환 원칙은 개방 폐쇄 원칙을 받쳐 주는 다형성에 관한 원칙을 제공한다.
다형성이란?
한 객체가 다양한 형태를 가질 수 있는 성질을 의미한다.
전 시간에 해 보았던 인터페이스를 상속한 객체가 인터페이스 타입으로 인스턴스 생성이 가능한 추상화나, 부모 클래스의 타입으로 자식 클래스를 생성 가능하게 하는 상속 등이 다형성에 속한다.(또한 오버로딩 등 많은 다형성이 있습니다.)
따라서 상위 타입을 하위 타입으로 치환하는 리스코프 치환 원칙은 상속의 다형성에 관한 것이고, 개방 폐쇄 원칙과 관련하여 이를 보완해 주는 원칙이다.
개방 폐쇄 원칙에서 추상화 또는 상속으로 여러 타입을 가질 수 있게 된 객체는 반드시 상위 타입의 객체를 가지며, 마찬가지로 상위 타입의 객체는 하위 타입의 객체를 가지게 된다.
이러한 상황에 상위 타입의 코드로 이루어진 메소드에서 하위 타입으로 대신해도 메소드에는 아무 문제가 없어야 한다는 의미다.
public class SuperClass {
public void someMethod(){
System.out.println("it is SuperClass");
}
}위 클래스를 상속받는 subClass를 생성해 보자.
public class SubClass extends SuperClass{
public void childMethod(){
System.out.println("it is SubClass");
}
}public class Main {
public static void main(String[] args){
printing(new SuperClass());
//인스턴스를 변경해도 printing 메소드는 정상적으로 작동함.
printing(new SubClass());
}
public static void printing(SuperClass instance){
//이 메소드는 무조건 it is SuperClass를 출력해야 한다.
instance.someMethod();
}
}위의 코드에서 printing 메소드는 SuperClass 타입을 매개변수로 받는다. 또한 printing 메소드의 임무는 무조건 it is SuperClass를 출력해야 한다.
SubClass는 자체적으로 childMethod라는 메소드도 가지고 있지만,
SuperClass의 someMethod라는 메소드를 상속 받아 가지고 있기 때문에 부모 타입으로 생성 되어도 someMethod라는 메소드를 실행하는데 아무런 문제가 없다!
따라서 위는 리스코프 치환 원칙을 지키는 코드라고 할 수 있다.
결과:
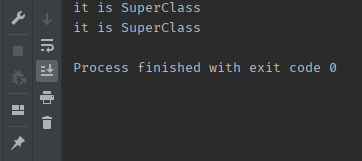
하지만 위의 상속의 예에는 맞지만 리스코프 치환 원칙을 어기는 상황이 있다.
대표적인 예로 원-타원 문제(Circle-ellipse problem) 가 있다.
이는 리스코프 치환 원칙의 계약에 관한 내용을 잘 설명해 준다.
원-타원 문제?
x,y평면 상에 a만큼의 반지름으로 원을 그리는 공식은 x2+y2=a2 이다. 피타고라스의 정리를 이용하여 a만큼의 빗변(반지름)을 가지기 위해선 √(x2+y2)=a가 되어야 하기 때문이다.
타원은 "두 점으로부터 거리의 합이 일정한 점들의 모임"이다.
위의 원과 비슷한 이유로 x,y평면 상에 세로축 2a, 가로축 2b만큼의 타원을 그리려면 피타고라스의 정리를 사용해 양 변을 정리하여 x2/a2+y2/b2=1의 식을 이용하여 그릴 수 있다.
만약 타원의 두 점의 위치가 같다면, 두 점으로부터 거리의 합이 일정한 점들을 모으면 원이 된다. 따라서 타원은 원이 아니지만, 원은 타원이 된다. 즉 타원이 좀 더 넓은 범위에 속한다.
이는 "원은 타원이다."라는 것이 성립하기 때문에 IS-A법칙이 맞게 된다. 따라서 우리는 타원의 클래스를 만들고, 그를 상속 시킨 원의 클래스를 만들 수 있게 된다.
먼저 타원 클래스를 만들어 보겠다.
public class Ellipse {
private int verticalAxis;
private int horizontalAxis;
public void setVerticalAxis(int verticalAxis){
this.verticalAxis=verticalAxis;
}
public void setHorizontalAxis(int horizontalAxis){
this.horizontalAxis=horizontalAxis;
}
public int getVerticalAxis(){
return verticalAxis;
}
public int getHorizontalAxis(){
return horizontalAxis;
}
}
이렇게 장축과 단축을 따로 설정하여 타원을 만드는 클래스를 작성하였다.
원은 타원과 다르게 지름 하나만 설정할 수 있다. 따라서 장축과 단축을 따로 설정할 필요가 없다.
하지만 setVerticalAxis, setHorizontalAxis 둘다 사용해야 하기 때문에 둘 중 하나만 메소드를 실행시켜도 두 변수 verticalAxis HorizontalAxis를 같은 값으로 초기화하도록 메소드를 override 해보자.
public class Circle extends Ellipse{
@Override
public void setVerticalAxis(int verticalAxis){
super.setVerticalAxis(verticalAxis);
super.setHorizontalAxis(verticalAxis);
}
@Override
public void setHorizontalAxis(int horizontalAxis){
super.setVerticalAxis(horizontalAxis);
super.setHorizontalAxis(horizontalAxis);
}
}이제 이 두 클래스가 리스코프 치환 원칙을 지키는지 알아 보자.
타원은 세로축과 가로축이 다른 값을 가질 수 있다. 따라서 우리가 원하는 축만 길이를 늘릴 수 있다.
이렇기 때문에 우리는 마음껏 세로축과 가로축을 세팅할 수 있다.
가로로 긴 타원을 만드는데, 가로축은 세로축의 두 배로 만들어 찌그러진 타원을 만들고 싶다고 가정해 보자.
그렇다면 세로축을 가져와 가로축을 세로축의 두 배로 변경할 수 있다.
public static void setLongEllipse(Ellipse ellipse){
int vertical=ellipse.getVerticalAxis();
ellipse.setHorizontalAxis(vertical*2);
}여기에 리스코프 치환 원칙을 적용시켜 매개변수에 circle이 들어 온다면 어떻게 될까?
가로축과 세로축이 같은 Circle은 위와 같이 가로축을 늘린다면 세로축도 같은 크기로 늘기 때문에 영원히 가로축이 세로축의 두 배가 되는 일은 일어나지 않는다.
따라서 예상하지 못한 곳에서 버그가 발생할 수 있다.
물론 instanceof로 인스턴스가 circle인지, ellipse인지 확인 후 예외를 처리할 수 있지만, 반대로 instanceof를 사용한다는 것은 리스코프 치환 원칙을 어긴다는 증거가 된다.
따라서 원과 타원은 상속 관계가 될 수 없고 따로 클래스를 작성하여야 한다.
이런 일이 발생하는 이유는 무엇일까?
ellipse의 setVerticalAxis 메소드는 이름 그대로 "세로축을 늘린다."라는 행동을 수행하는 메소드다.
따라서 우리는 메소드의 이름으로 "세로 축 만을 늘리는 메소드"라고 약속을 하고 있는 것이다.
하지만 circle 클래스에서 우리는 그 약속을 깨고 setVerticalAxis안에 setHorizontalAxis까지 수행하게 만들었습니다. 그러기에 리스코프 치환 원칙에 위배된다.
이번에는 확장에 관하여 한 가지 예를 들어 보겠다.
"우리 가게에 쿠폰 할인 이벤트를 하려고 한다. 하지만 몇몇 품목들은 할인에서 제외하도록 하려 한다. 어떻게 해야 할까?"
먼저 물건을 팔기 위해선 "물건"이란 클래스가 필요하다.
그럼 먼저 물건을 만들어 보자.
public class Item {
private int price;
public Item(int price){
this.price=price;
}
public void setPrice(int price){
this.price=price;
}
public int getPrice(){
return price;
}
}이제 쿠폰을 만들어서 아이템을 할인해 보자.
public class Coupon {
private double discountRate;
public Coupon(double discountRate){
this.discountRate=discountRate;
}
public double discount(Item item){
return item.getPrice()*discountRate;
}
}쿠폰을 가지고 있으면 discount 메소드를 사용하여 아이템의 가격을 할인하는 클래스를 만들었다.
자 이제 할인이 되지 않는 아이템을 만들어 보자.
할인이 되지 않는 아이템도 아이템이니(IS-A) 아이템을 상속하여 클래스를 만들어 보자.
public class SpecificItem extends Item{
public SpecificItem(int price) {
super(price);
}
}만약 여기서 Coupon의 discount에 Item 타입 대신에 SpecificItem이 들어 간다면 어떻게 될까?
SpecificItem은 할인이 가능할 것이다. 이러한 문제를 막기 위해서 우리는 간단히 생각해서 instanceof를 사용하는 방법을 떠올릴 것이다.
public class Coupon {
private double discountRate;
public Coupon(double discountRate){
this.discountRate=discountRate;
}
public double discount(Item item){
if(item instanceof SpecificItem)
return item.getPrice();
return item.getPrice()*discountRate;
}
}하지만 instanceof를 사용하면 리스코프 치환 원칙을 어기게 된다.
상위 또는 하위 타입으로 바꿔도 정상 동작하지 않는다는 증거이기 때문이다.
또한 개방 폐쇄 원칙에 따라 Item은 확장에는 열려 있고 수정에는 닫혀 있어야 하지만, 이렇게 된 다면 Item 클래스의 하위 타입이 새로 생길 때 마다 기존에 있던 discount 코드를 계속 수정해야 할 지도 모른다.
이는 두 번째 원칙인 개방 폐쇄 원칙을 지키기 어렵게 만들게 된다.
우리는 어떻게 해결해야 할까?
위의 Item 클래스는 추상화가 덜 된 케이스이다.
할인되지 않는 상품이 추가되었다는 것은 "정해진 기간만 할인하는 상품", "출시 된 지 한 달 이내는 할인이 불가능한 상품" 등 여러 요구가 후에 생길 확률이 높다는 것이다.
따라서 Item 클래스에 할인이 되는지, 되지 않는 지를 결정하는 코드를 넣어 더욱 "확장에는 열려있고, 변경에는 닫힌 코드"로 만들어야 한다.
public class Item {
private int price;
public Item(int price){
this.price=price;
}
public void setPrice(int price){
this.price=price;
}
public int getPrice(){
return price;
}
//요구에 맞춰 확장
public boolean isDiscountAvailable(){
return true;
}
}public class SpecificItem extends Item{
public SpecificItem(int price) {
super(price);
}
@Override
public boolean isDiscountAvailable(){
return false;
}
}따라서 우리는 이후에 들어올 여러 할인 요구 사항도 맞춰서 편하게 확장할 수 있는 코드를 완성하였다.
public class Coupon {
private double discountRate;
public Coupon(double discountRate){
this.discountRate=discountRate;
}
public double discount(Item item){
if(item.isDiscountAvailable())
return item.getPrice()*discountRate;
return item.getPrice();
}
}이처럼 리스코프 치환 원칙은 개방 폐쇄 원칙을 좀 더 잘 파악할 수 있게 해 주는 기준을 제공한다는 것을 배웠다.
4. 인터페이스 분리 원칙 (Interface segregation principle; ISP)
밑은 인터페이스 분리 원칙의 정의이다.
클라이언트는 자신이 사용하는 메소드에만 의존해야 한다.
조금 말이 어렵다. 위키 백과에서는 어떻게 정의 되어있을까?
"인터페이스 분리 원칙은 클라이언트가 자신이 사용하지 않는 메소드에 의존하지 않아야 한다."
이렇게 말을 조금 바꾸어 본다면 이 원칙을 정의한 개발자가 무슨 상황에 처해서 곤란했는지 알 수 있다.
사용하지도 않는 메소드 때문에 코드를 바꾸거나 귀찮은 일을 경험했을 것이다.
이런 일이 어떤 상황에서 일어날까?
한 상황을 가정해 봅시다.
"음식점을 찾는 어플을 만드려고 한다. 음식점 찾기, 음식점 목록에서 음식점 삭제하기, 음식점 목록에 음식점 추가하기 이 4 가지의 기능을 만드려고 한다. 어떻게 해야 할까?"
이번 상황에서 만큼은 Java가 아닌 C++ 언어로 생각해 보자.
왜냐하면 C++에서 인터페이스 분리 원칙을 지켜야 하는 이유가 더욱 드러나기 때문이다.
위의 기능을 가지는 모듈, 또는 클래스를 restaurant service라고 해보자.
C++언어는 보통 헤더 파일과 cpp파일로 나누어 모듈을 개발한다.
헤더 파일에는 인터페이스처럼 메소드와 필드의 정의를, cpp파일에는 정의된 메소드와 필드를 구현하고 있다.
따라서 cpp 파일은 import처럼 #include 키워드를 이용하여 RestaurantService.h 헤더 파일을 가져와 구현한다.
구현이 다 되었다면, 이 기능을 사용하는 클래스(클라이언트)는 마찬가지로 #include를 사용하여 cpp 파일이 아닌 RestaurantService.h 파일을 가져와 사용하게 된다.
우리는 이 원칙을 지키지 않을 때, 어떠한 일이 벌어지는지 알아보기 위하여 일부러 "사용하지 않는 메소드를 의존"하게 만들어 보자.
RestaurantService.h에 우리가 구현해야 하는 음식점 찾기, 음식점 목록에서 음식점 삭제하기, 음식점 목록에 음식점 추가하기 기능 모두를 구현해 보자.
그럼 RestaurantService.h를 의존하는 파일들의 관계는 밑의 사진처럼 된다.

자 이제 실행을 해 보자.
C++은 컴파일과 링크를 직접 해주는 언어다.
따라서 밑과 같은 절차를 따르는 데,
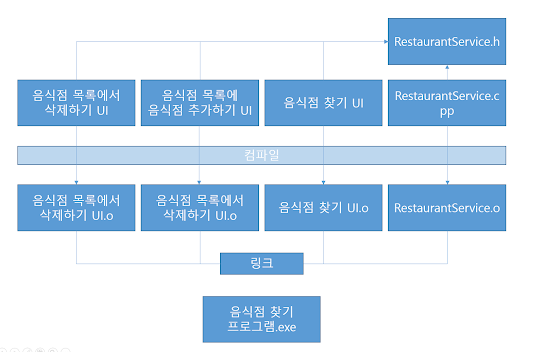
하나의 파일을 컴파일 하여 기계어로 번역한다.
기계어로 번역한 파일은 object(목적) 파일이라고 부른다.
이렇게 하나 하나 번역된 파일들을 한 군데로 모아 exe로 만들어 주는 것을 링크라고 한다.
링크는 원래 동적 링크와 정적 링크로 나뉘는데, 깊은 내용이니 여기에서는 정적 링크라 하자.
이렇게 링크롤 하고 나면 exe로 만들어져 파일을 실행할 수 있게 된다.
하지만 모든 설계 원칙이 그랬듯이, 문제는 프로그램의 변화에서 일어난다.
만약 음식점 삭제에서 요구 사항이 발생해 이를 바꾸자고 한다.
따라서 RestaurantService.h에 새로운 메소드를 작성하고 음식점 삭제 UI파일만 컴파일, 링크를 해주었다.
하지만 RestaurantService를 참조하는 파일은 음식점 삭제 UI뿐이 아니다.
따라서 RestaurantService를 참조하는 음식점 찾기 UI, 음식점 목록 보여주기 UI, 음식점 목록에 음식점 추가하기 UI 까지 모두 컴파일과 링크를 해 주어야 한다.
변경 점은 단 하나, 음식점 삭제하기 UI만 요구 사항이 들어 왔으나 이것과 상관 없는 파일들 까지 영향이 갔다.
SOLID원칙이 싫어한다고 계속 외쳐 대던 클래스간의 연결성 떨어트리기, 변경의 영향을 최소화 하기가 깨진 것이다!
이러한 일들을 해결하기 위해선 밑의 그림처럼 하나의 기능에 하나의 헤더 파일을 작성해야 한다. 그렇다면 다른 파일들을 컴파일 할 필요가 없어진다.
"난 C++을 사용할 일이 없는데, 이런 규칙을 따를 필요가 있나?"
실제로 이런 규칙은 Java에서는 재 컴파일을 하는 상황이 발생하지 않는다. 우리 유능한 JVM이 알아서 해 주기 때문이다. (JVM 만세)
하지만 이러한 규칙을 잘 지키면 Java에서도 장점은 분명히 있는데,
단일 책임 원칙을 지키기 쉬워 지기 때문이다.
단일 책임이 잘 지켜지지 않을 경우 한 기능의 변화가 다른 기능에게 영향을 미치기 쉽다는 것은 위에서 잘 봐왔다.
따라서 위의 단일 책임 원칙의 상황에서 기능 별로 인터페이스를 분리한다면
그 인터페이스를 상속 받은 클래스(클라이언트)는 서로 영향을 미치지 않는 클래스로 분리하게 된다.
이 이외에도 인터페이스 분리 원칙의 장점은 단일 책임 원칙이 잘 지켜 짐으로서 인터페이스의 재사용성이 늘어난다는 것이다.
인터페이스가 다른 기능 없이 한 기능에 집중하여 세부적으로 나누어져 있다면 이 인터페이스를 다시 사용할 가능성이 높아진다.
이 인터페이스가 재사용성이 높아 짐에 따라 이 것을 상속 받은 콘트리트 클래스 또한 재사용성이 높아지는 효과를 볼 수 있다.
코틀린 언어로 개발했음에도 불구하고, 음식점 클래스를 여러 곳에서 사용하고 나면 음식점 클래스의 자료형을 바꿀 때마다 클래스를 사용하는 클래스들도 다 바꿔야 했던 경험이 많았다.
(사실 자료형 추상화도 캡슐화도 안된 케이스..)
따라서 자바나 코틀린, 다른 객체 지향 언어들도 이 원칙을 지키면 단점보단 장점이 훨씬 많을 것이다.
5. 의존 역전 원칙 (Dependency inversion principle; DIP)
마지막은 의존 역전 원칙이다.
의존 역전 원칙의 정의는 다음과 같다.
"고수준 모듈은 저수준 모듈의 구현에 의존해선 안된다. 저수준 모듈이 고수준 모듈에서 정의한 추상 타입에 의존해야 한다."
고수준은 무엇이고, 저수준은 무엇일까?
프로그래밍 언어는 고급 언어와 저급 언어로 나뉜다.
프로그래밍을 처음 배울 때, 고급 언어와 저급 언어라는 것을 배운다.
고급 언어는 C, C++, Python과 같이 인간에게 친숙한 언어,
저급 언어는 어셈블리, 기계어와 같이 기계에게 친숙한 언어이다.
고급 언어는 저급 언어에 비해 좀 더 인간에 가까운(추상적인) 사고로 작성해도 되는 언이이다.
이와 비슷하게 이해하면 되는데,
고수준 모듈이란 의미가 담겨있는 추상적인 모듈, 저수준 모듈은 구현에 가까운 모듈이다.
즉, 자세한 구현이 담긴 저수준 모듈은 의미가 담긴 추상적인 모듈을 개념을 의존해야 한다는 것이다.
우리가 팔을 움직일 때, "근육을 사용하여 얼마만큼 수축하라!" 라고 말하지 않는다.
그냥 팔을 움직인다고 생각하면 저수준인 근육은 고수준의 명령(뇌)을 따라(의존해서) 움직인다!
여러 상황 중에 한 가지 예시를 들어 보자.
"저장된 데이터를 변경하는 프로그램을 작성해 보자."
위의 예시는 많이 추상화된 예시이다.
데이터를 변경하는 행동에는 "데이터 불러오기","데이터 변경하기","데이터 저장하기"라는 구체적인 행동들이 따라오기 때문이다.
따라서 "데이터를 변경하는 프로그램"은 고수준,
불러오기, 변경하기 저장하기는 저수준이라고 볼 수 있다.
그럼 이 상태에서 저 원칙을 일부러 위반하여 무슨 현상이 일어나는 지 알아보자.
저장된 데이터를 변경하려면 먼저 데이터를 불러와야 한다.
따라서 Local에서 데이터를 불러오는 기능을 하는 클래스 DataReader를 작성하겠다.
public class DataReader {
public int getData(){
int data=0;
//some data reading logic
return data;
}
}그 다음 데이터를 변경하는 기능을 하는 클래스 DataChanger를 작성하자.
public class DataChanger {
public int dataChange(int data){
return data+5;
}
}이제 데이터를 저장하는 클래스 DataStorage를 작성하자.
public class DataStorage {
public void setData(int data){
//some data saving logic
}
}우리는 구체적인 저수준 기능 3 가지를 만들었다.
이제 고수준인 데이터를 변경하는 프로그램을 위의 3가지 모듈을 활용하여 만들어 보자.
public class JavaPractice {
public static void main(String[] args) {
//create instance
DataReader reader=new DataReader();
DataStorage storage=new DataStorage();
DataChanger changer=new DataChanger();
//flow logic
int data=reader.getData();
data=changer.dataChange(data);
storage.setData(data);
}
}먼저 각 기능을 하는 클래스의 인스턴스들을 생성하였다.
그 다음 읽기 -> 변경 -> 저장의 흐름에 맞게 flow logic을 작상하였다.
항상 그렇듯, 기획의 변경이 생겨 난다.
"데이터를 읽어 오는 방법을 로컬이 아니라 서버에서 받아오게 변경해야 할 것 같아요."
위와 같은 요구 사항이 들어 온다면 어떤 코드들이 변경 될까?
일단 DataReader 클래스가 변경될 것이다.
새로운 클래스 ServerDataLeader를 만들던지, 혹은 DataReader를 변경하여 서버에서도 데이터를 받아올 수 있게 말이다.
또한 흐름을 담당하는 클라이언트 클래스(main)도 변경되게 될 것이다.
DataReader의 인스턴스를 생성하고, 그 인스턴스의 메소드도 사용했기 때문이다.
각 클래스의 의미는 이러하다.
-
main - 데이터를 읽어와 변경하고 저장하는 흐름을 제어한다.
-
DataReader - 요구 사항에 맞는 데이터를 저장소에서 불러와 Return한다.
-
DataChanger - 데이터를 받고, 그 데이터를 변경한 후에 데이터를 Return 한다.
-
DataStorage - 데이터를 받고, 그 데이터를 요구 사항에 맞는 저장소에 저장한다.
우리는 데이터를 불러오는 기능 하나만을 변경했지만, 변경되는 것은 DataReader 하나만이 아닌 main까지 변경하게 되었다.
흐름을 제어하는 고수준 모듈인 main은 데이터를 불러오는 기능과는 상관이 없는데, 왜 변경되는 걸까?
이는 추상적인 고수준 모듈인 main이 구체적인 저수준 모듈인 DataReader를 "의존"했기 때문이다.
main에서는 Local에서 데이터를 불러오는 DataReader의 콘크리트 클래스 인스턴스를 직접 생성하고, 또 그 인스턴스의 메소드까지 직접 사용하였다.
따라서 main의 구현은 DataReader에 의존(DataReader 클래스의 구현에 좌지우지 된다.)한다고 볼 수 있다.
그렇기 때문에 DataReader가 변경이 된다면 main도 같이 변경되어야 한다.
이러한 문제점을 어떻게 해결해야 할까?
답은 또 추상화다.
위에서 말했다시피, 한 객체를 추상할 수록 고수준에 가깝다.
따라서 "데이터를 로컬에서 읽어온다."를 "데이터를 읽어온다."로 추상화 해야 한다.
추상화를 하기 위해 먼저 "데이터를 읽어 온다."라는 인터페이스를 작성하자.
public interface DataReader {
public int getData();
}이번에는 새로 들어온 요구 사항인 "서버에서 데이터를 읽어온다."를 의미하는 클래스 ServerDataReader를 작성해보자.
마찬가지로 DataReader를 상속한다.
public class ServerDataReader implements DataReader{
@Override
public int getData() {
int data=0;
//some data reading logic
return 0;
}
}이제 "Data Reader 인스턴스를 생성한다."라는 의미를 가진 팩토리 클래스 DataReaderFactory를 작성하자.
public class DataReaderFactory {
static public DataReader getDataReader(){
return new ServerDataReader();
}
}이제 이렇게 추상화 된 클래스를 main에 접목시키겠다.
이 인터페이스를 상속하는 클래스는 모두 interface 타입으로 생성할 수 있다.
또한 interface에 정의되어 있는 getData 메소드를 상속받은 클래스 모두 공통으로 가지고 있다.
따라서 콘크리트 클래스로 생성하던 방식에서 interface 타입으로 생성하는 방식으로 바꾼다면 같은 타입임에도 불구하고 다른 저수준 기능을 하는 코드를 작성할 수 있다.
그리고 같은 타입임에도 다른 인스턴스를 할당해 주는 역할을 해 주는 클래스인 DataReaderFactory를 따로 만들어 준 것이다.
이제 main은 이렇게 바뀔 것이다.
public class JavaPractice {
public static void main(String[] args) {
//change to interface type
DataReader reader= DataReaderFactory.getDataReader();
DataStorage storage=new DataStorage();
DataChanger changer=new DataChanger();
//flow logic
int data=reader.getData();
data=changer.dataChange(data);
storage.setData(data);
}
}아직 의존 중인 DattaStorage와 DataChanger도 위와 같은 방식으로 추상화 하여 바꿔 준다면 외부의 요구사항에 의해 바뀌지 않아도 되는 main이 완성될 것 이다.
만약 로컬과 서버 모두에서 상황에 따라 데이터를 받아와야 하는 상황이 생겼다면, 이제 "로컬에서 데이터를 받아온다."라는 의미를 가진 클래스를 하나 새로 만들고, "DataReader를 생성한다."라는 의미를 가진 DataReaderFactory를 수정한다면 main은 자신이 해야 할 일인 흐름제어만 담당하게 된다.
"코드의 양이 늘어 더 복잡해 진 것 아니야?"
이렇게 말할 수도 있겠다.
하지만 매우 많은 코드들이 있는 큰 프로젝트에서 이 정도의 양이 늘어난 것은 별로 크게 복잡해진 것이 아니다.
오히려 코드의 양이 늘어난 만큼 수정이 용이해진다.
추상화를 하여 의존성을 떨어트리면 한 객체당 하나의 책임을 가지게 되고, 이는 단일 책임 원칙을 지키기 쉬워진다.
또한 하나의 책임(기능)을 변경할 일이 생기면 그 책임이 변경됨에 따라 나올 여파를 신경 쓰지 않고 변경할 수 있게 되기 때문에 수정해야 할 코드를 찾기가 쉬워 진다.
위의 예시를 현실적으로 바라본다면,
Data Reading 기능을 변경할 때 산더미 많큼 쌓여있는 코드들과 클래스들 중에 이름이 일맥상통하는 ServerDataReader 클래스와 DataReaderFactory를 변경하는 것이
ServerDataReader 클래스와 이 클래스를 사용하는, 어디 있는지 모를 클래스들을 하나 하나 다 살펴보는 방법이 훨씬 어려울 것이다.
따라서 코드의 양이 많으면 많을 수록(큰 프로젝트일 수록) 이 방법은 더욱 빛이 날 것이다.
끝
이렇게 다섯 가지 설계 원칙을 알아 보았다!
가장 긴 글이 되었는데, 꼼꼼히 읽어보고 다시 공부하고 해 보자...
오류가 있다면 열심히 지적해 주세요!
