
모든 코드에 의미를 담겠습니다.
5일만에 쓰는 velog.... 주말동안 React 부분에서 해야 될 과제들이 산더미처럼 있어서 개인적인 프론트엔드 공부를 할 여유가 없었던 것 같다(이것도 변명인가..? ㅎㅎ..)
조만간, 주말동안에 씨름을 했던 TypeScript with ESLint에 대해서도 한번 짚고 넘어갈 예정이다.
우선, 오늘은 프론트엔드 개발자라면 한번쯤은!!
들어봤을법한 브라우저의 렌더링에 대해서 좀 다뤄볼까 한다.
즉, 사용자에게 브라우저의 내용들이 어떻게 보여지는지에 대한 내용이다.
브라우저의 흐름 순서도에 대해서는 여러 velog에서 소개를 하고 있지만, 그 순서의 내부까지 자세하게 설명하고 있는 velog는 많이 못 본것같다.
그래서 네이버 D2에서 번역한 이스라엘 개발자 Tali Garsiel의 브라우저 동작에 대해서 조금씩 조금씩 내가 이해한바로 써 내려갈 예정이다.
그러므로, 다른 개발일지와는 다르게 이번 일지 같은 경우는 조금 장기적으로(?) 써내려가면서 천천히 곱씹어 가면서 써내려 갈 것 이다.
한 번에 못쓴다는 것을 돌려서 말하고 있는중...
우선 유저들이 현대사회에서 많이 쓰고있는, 크롬, 사파리, 파이어폭스, 인터넷 익스플로러 같은 것들이 브라우저라고 보면 되겠다.
그렇다면 브라우저의 정확한 정의는 무엇인가?
클라이언트 쪽에서 선택한 자원을 서버에 요청해서 요청한 파일을 브라우저라는 창에 뿌려주는 것.
프론트엔드 개발자로서, 비전공자인 내 입장에서 자원은 음? HTML과 CSS이 둘밖에 없지 않나? 라는 생각을 하지만!
아니다. 사실은 이미지파일도 요청할 수 있고 PDF파일도 요청해서 자료를 받아올 수 있다. 그런데, 프론트 엔드 개발자로써 거의 HTML CSS 파일로 요청해서 렌더링을 하기 때문에 다른 자원에 대해서 생각해보지는 않았다.
내가쓰는 개발일지에서는 HTML CSS의 자원만으로 어떻게 브라우저가 작동하는지에 대해서 써볼것!!
브라우저의 구조
- 사용자 인터페이스: 주소창, 북마크, 기본적인 것들
- 브라우저 엔진: 사용자 인터페이스와 렌더링 엔진 사이에서 흐름을 제어하는 엔진!
- 렌더링 엔진: HTML과 CSS를 컴퓨터가 이해할 수 있는 언어로 파싱하는 엔진!
- 통신: REST-API, APOLLO-QL등 데이터를 가져오게 하게끔 하는 네트워크
- 자바스크립트 해석기: 자바스크립트를 해석해주는 기계
- UI백엔드: 창같은 기본장치를 그리는 역할
- 자료 저장소: 모든 데이터를 웹 베이스에서 저장할 수 있게끔해주는 장치!
이 구조들에 대해서 하나씩 더 자세하게 살펴봐야되지만, 현재는 여기서 이 정도의 개념을 파악하고 한번 흐름을 파악해보자!
나는 일단 흥미가 생긴후에 지식을 습득해야지 이해가 잘가는 경우라 너무 원론적인 부분을 파다보면 코드 없이 이론으로는 머릿속에 안박히는 경우가 많다!
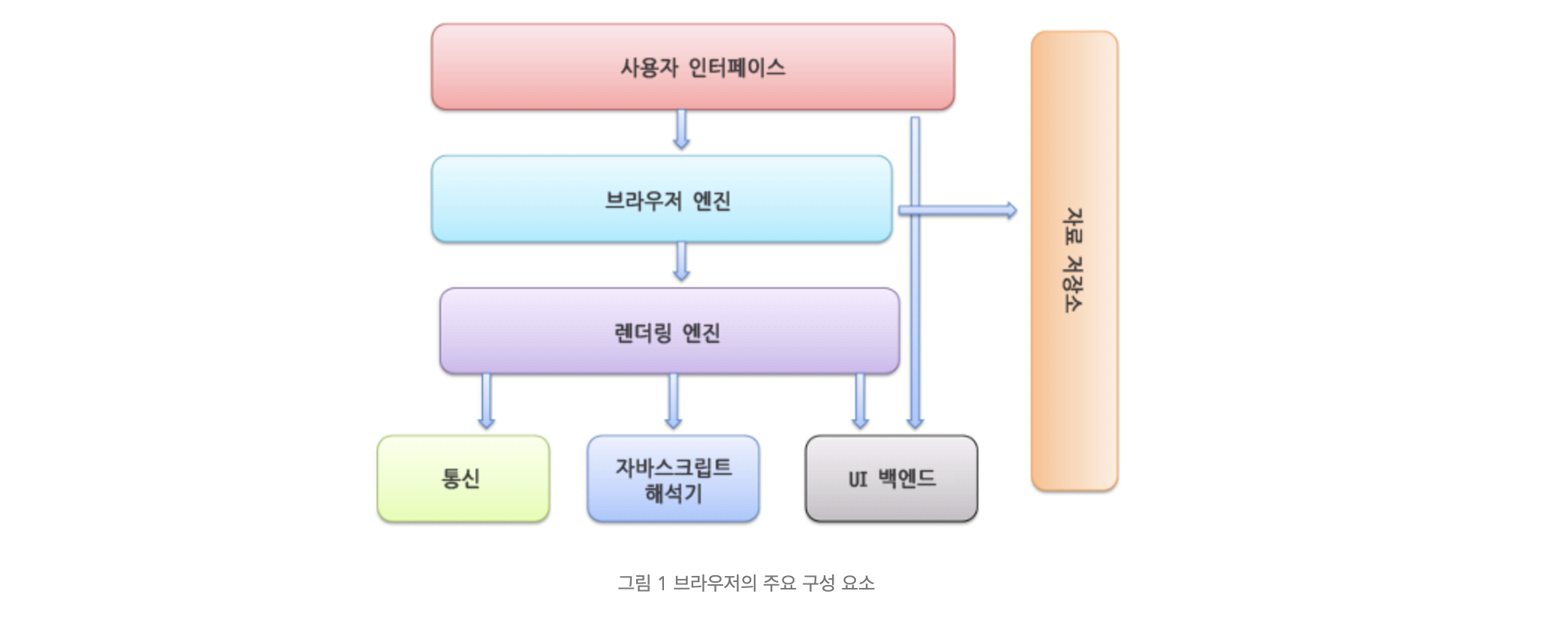
네이버 D2사이트에서 제공하는 브라우저 구조! 한번 참고해보면 좋을 것같다.
여기서 그러면 사용자에게 보여지는 화면을 뿌려주는 건 뭘까?
바로 렌더링 엔진이다!
렌더링엔진은 위에서 언급했듯이 HTML CSS 자료들을 파싱해서 화면에 뿌려주는 역할을 하는데 그 렌더링 과정에 대해서 알아야하지 않을까?
개인적으로 프론트엔드 개발자로써는 흐름에 대해서는 파악하고 있어야할 것같다.
렌더링 순서
- HTML, CSS을 파싱한다. 컴퓨터가 알아들을 수 있는 언어로 분리를 하는 것이다.
- HTML을 파싱한 이후에 DOM 트리를 생성하고 CSS의 스타일 요소도 파싱해서 어태치먼트로 합친다. CSS의 스타일 요소는 p 태그 div태그 속성자체를 요소라고 칭한다.
DOM 같은 경우는 객체지향형 모델이라고 보면 되겠다. ({}) 이 부분에 대해서 잘 모르겠다면 객체 지향형 모델, DOM, Virtual DOM에대해서 배우고 오면 더 이해가 쉬울 것 같다. - 그런 다음에, 시각화를 담당하는 렌더트리에 담아서 실행하고 배치!!
- 배치가 되면, UI백엔드에서 각 노드를 살피면서 정확한 위치에 원하는 요소 및 뼈대들을 뿌린다고 보면 되겠다!
렌더링 엔진,즉 웹킷이냐 게코냐에 따라서 렌더링하는 동작방식과 명칭이 조금씩 다르지만 크게보면 흐름은 비슷하다고 보면 좋을 것 같다.
파싱과 돔 구조
- 렌더링에서 파싱과 돔 구조는 정말 중요하다고 하니 파싱에 대해서 조금 더 자세하게 살펴보자.
문서를 파싱하면 보통 결과는 문서 구조를 나타내는 노드 트리 (파싱트리)로 구성이 보통 된다.
예를들어)
2+ 3 -1 이면 2,3, 1, +, -1 를 각각 구별하는 노드들을 구성해서 트리형태로 만들어버리는 것이다.
파싱은 또 두가지로 나뉜다.
어휘를 분석하고 구문을 분석한다.
쉽게말하자면, 어휘분석을 통해 토큰자료형으로 잘게잘게 쪼갠다음에 각각 토큰이 구문 규칙에 맞는지 확인한 후에 파싱트리에 넣는것이다.
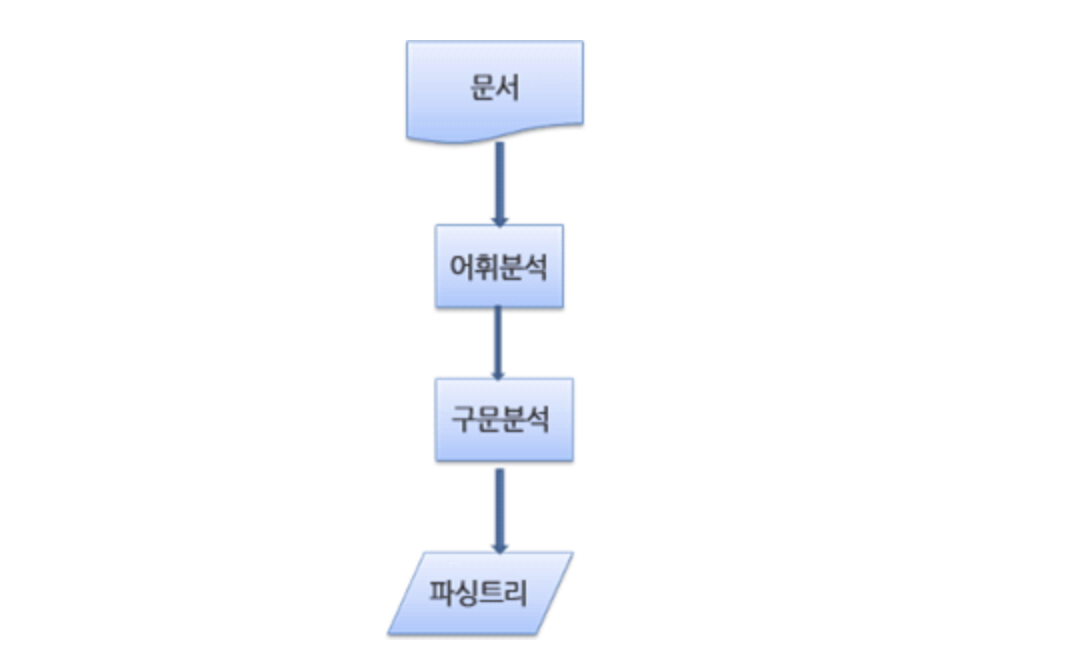
<네이버 D2 출처 파싱 순서>
그리고 난이후에, 파싱트리를 컴파일링하는것이다!
어휘는 정규표현식을 보통 따라서, 해당 정규표현식에 따라 토큰으로 각각 분류를 한다.
TO BE CONTINUED....
