Redis로 Lock을 구현하기 전에 우선 분산락의 개념에 대해서 잠깐 알아보자
분산락
- 여러 서버로 구성된 분산 시스템에서 데이터의 동시 접근을 제어하기 위한 메커니즘
- 분산 시스템에서는 데이터 일관성을 유지하면서 동시성을 관리하는 것이 중요
- 분산 락을 사용하여 여러 서버 간의 데이터 접근을 동기화할 수 있음
- race condition에서 하나의 공유자원에 접근할 때, 데이터의 결함이 발생하지 않도록 원자성을 보장
-> AWS로 분산 서버를 만들어서 사용시, Mysql보다 Redis를 사용해서 분산락을 이용하는 편이 성능상 이점이 있을 것으로 보인다.
Redis Lock
1. Lettuce
이론
- setnx 명령어를 활용하여 분산락을 구현
- key와 value를 set할 때 기존 값이 없을 때만 set하는 명령어
- spin lock 방식
- 쓰레드가 lock을 사용할 수 있는지 반복적으로 확인하면서 시도
- 반환값 (1 : 성공 0 : 실패)
- 예시- 쓰레드1이 키가 1인 데이터를 레디스에 set하면 처음엔 1이 없으므로 성공
- 쓰레드2가 키가 1인 데이터를 set하려 하면 1이 이미 있으므로 실패
- 성공을 위해 일정시간 마다 재시도하는 로직을 작성해서 성공할 때 까지 시도
- 장점
- 비동기 및 논블로킹 네트워크 통신을 지원하여 다수의 클라이언트가 비동기적으로 Lock을 획득하거나 해제할 수 있어서 시스템 성능을 향상
- Redis 클라이언트 라이브러리를 사용하기 때문에 빠른 읽기와 쓰기 작업을 처리할 수 있어서 Lock을 획득하거나 해제하는 데 빠른 응답 시간을 제공
- 단점
- Lock을 구현하려면 Redis의 기능과 명령어를 활용하여 직접 락 메커니즘을 구현
-> 직접 구현해야 해서 어렵고, 각각의 기능을 따로 구현해야 하기 때문에 유지 보수 힘듬 - 계속 해서 재시도를 요청하는 로직이기 때문에 Redis에 과부하가 올 수 있음
- 분산락을 제공하지 않기 때문에 직접 구현해야 함
- Lock을 구현하려면 Redis의 기능과 명령어를 활용하여 직접 락 메커니즘을 구현
테스트
- 재고 100개, 100번 실행 시
- 걸린 시간 : 4.332s
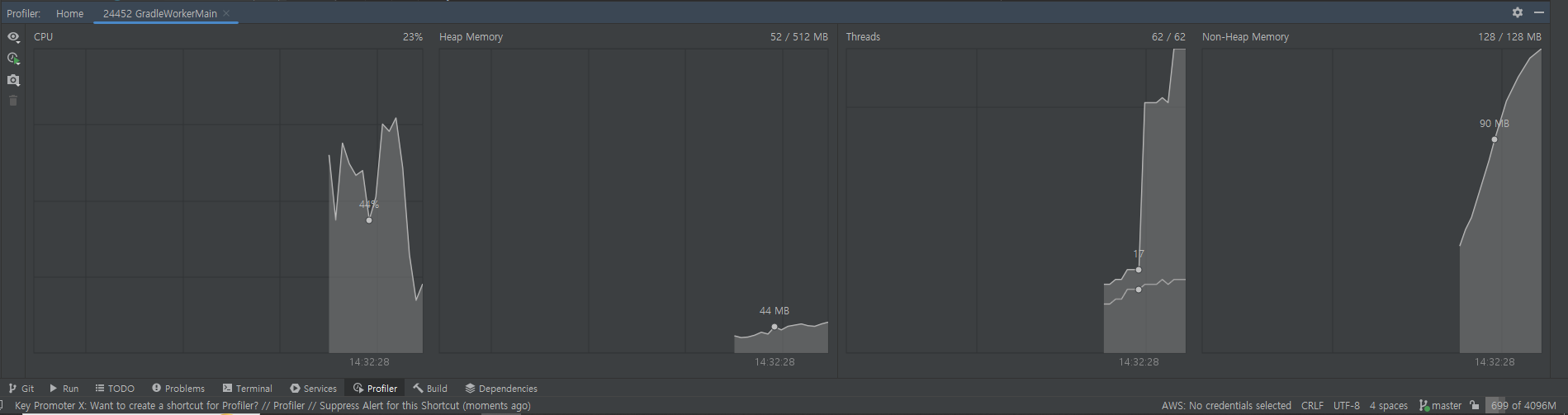
- 걸린 시간 : 4.332s
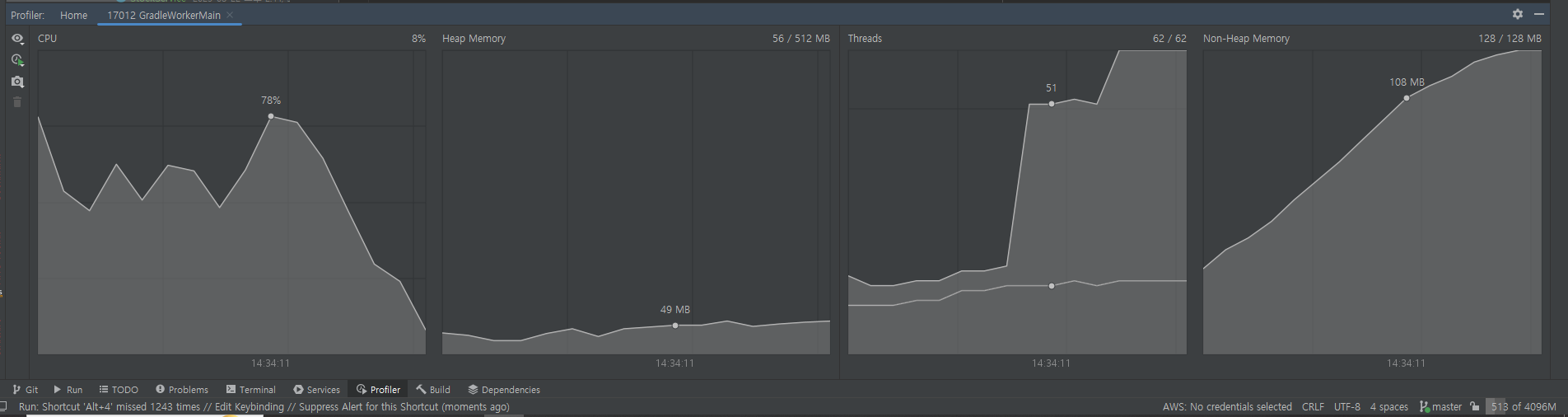
- 재고 100개, 100번 실행 시
- 걸린 시간 : 4.791s
- 걸린 시간 : 4.791s
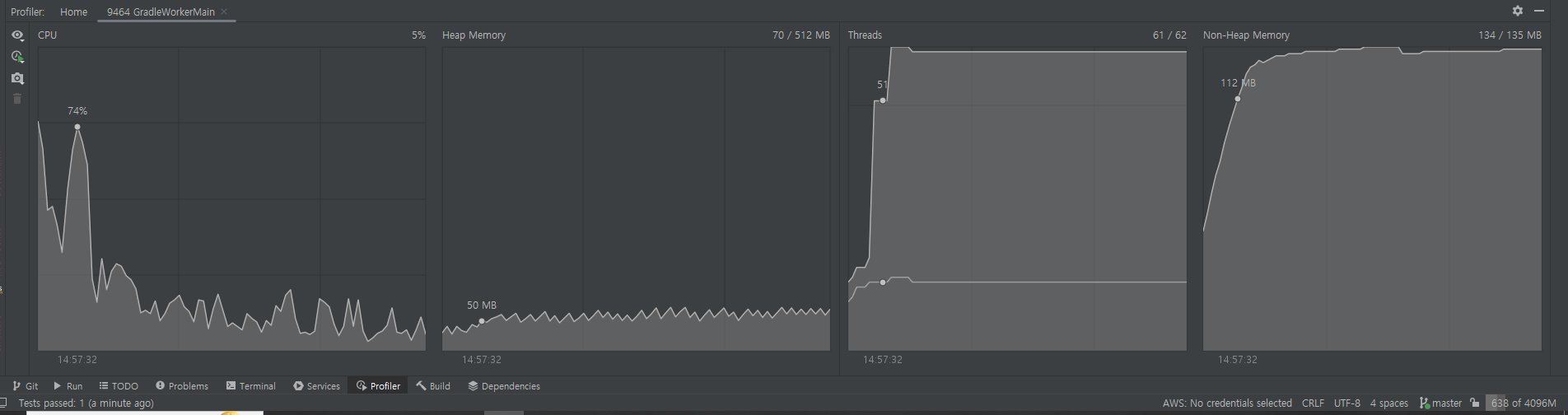
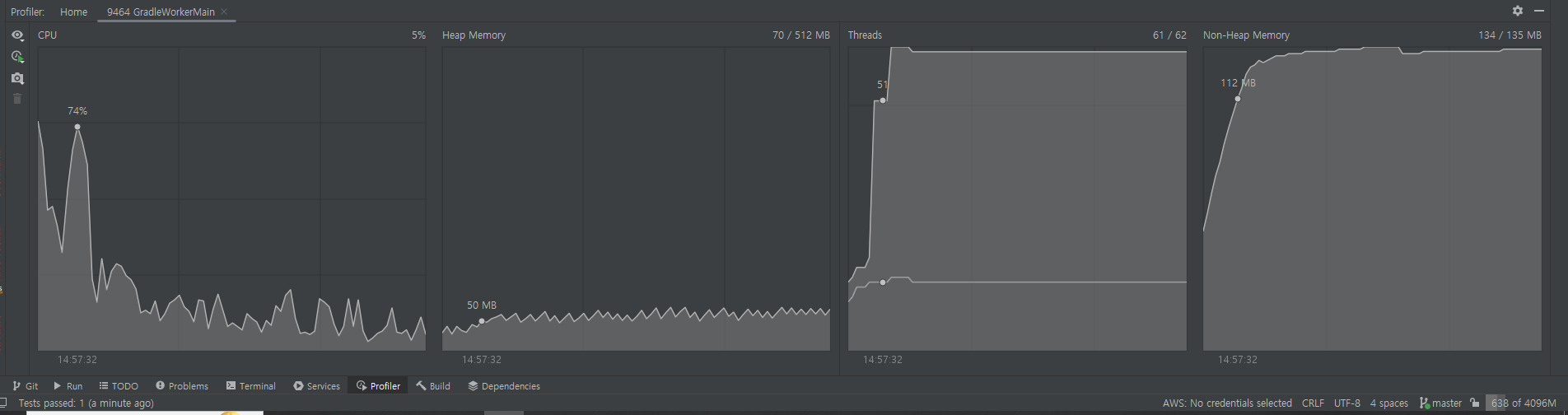
- 재고 1000개, 1000번 실행시
- 걸린 시간 : 38s
- 걸린 시간 : 38s
- 재고 100개, 10000번 실행 시
- 걸린 시간 : 84s
- 걸린 시간 : 84s
- 재고 1000개, 10000번 실행 시
- 걸린 시간 : 102s
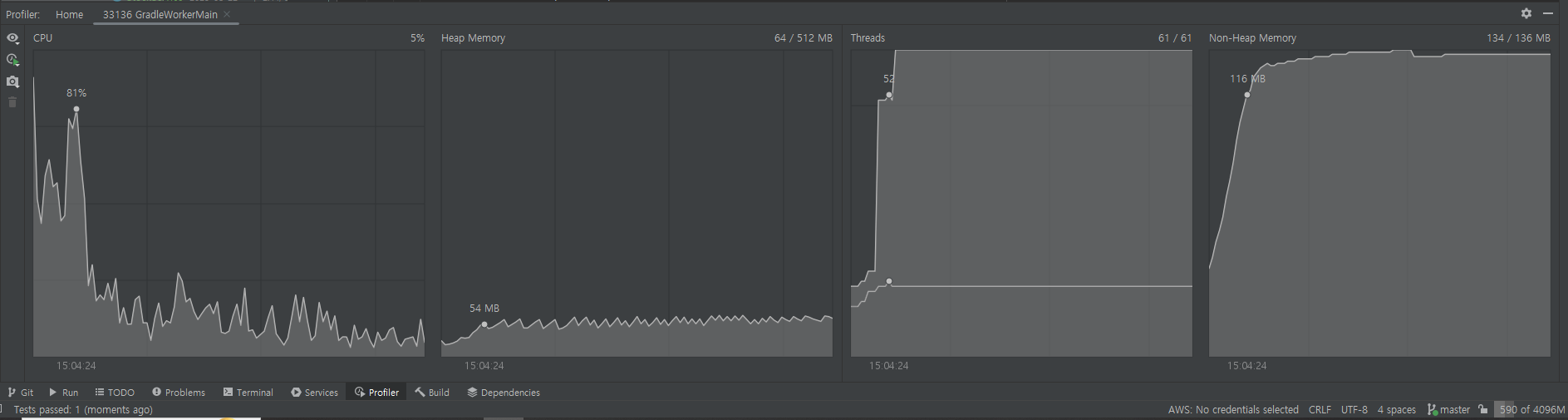
- 걸린 시간 : 102s
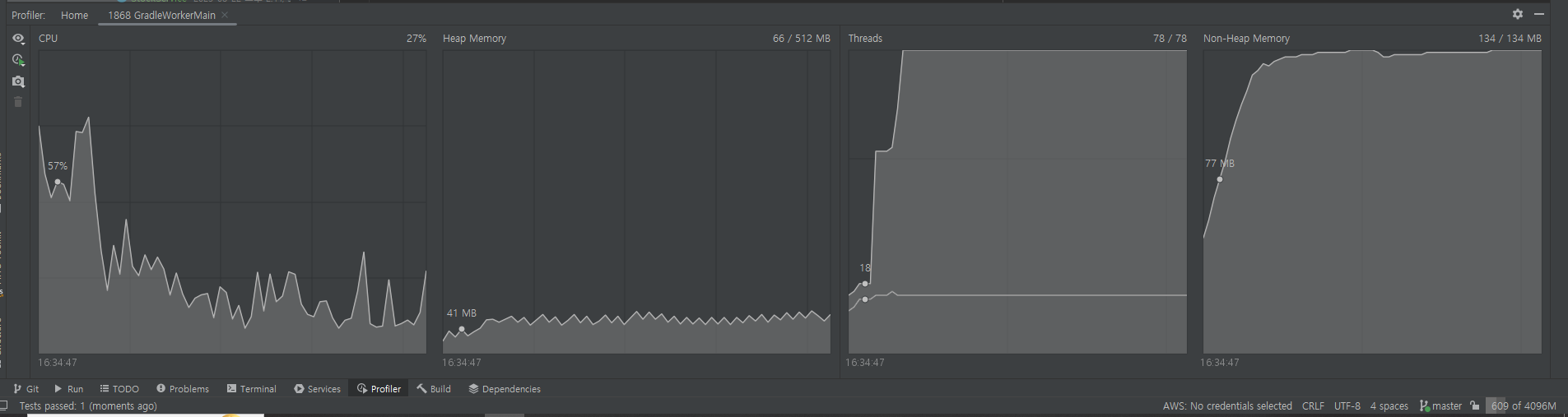
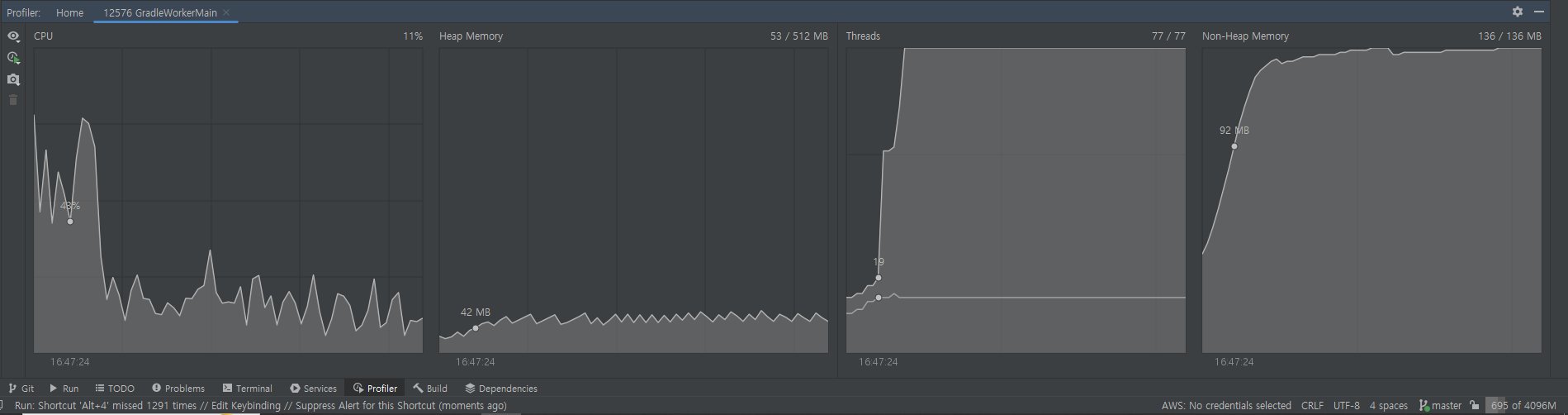
- Profiler 캡쳐를 보면 알 수 있듯이, 앞선 락들과 같이 CPU 사용량이 증가하면 Thread를 더 만들어서 할당하여 CPU 사용량을 줄이는 것을 볼 수 있다.
- 시간을 보면 걸린 시간은 재고와 실행 횟수에 비례해서 늘어나는 것을 볼 수 있다.
- 결론
- Mysql을 사용하던 비관적락이나 낙관적락보다 성능이 떨어지는데
- 상황에 따라 Pessimistic lock이 Redisson lock보다 더 적합한 경우도 있을 수 있다.
- 단일 서버 환경이거나 데이터베이스 특성상 Pessimistic lock이 더 효과적인 경우일 수 있습니다.
- 따라서 AWS와 같은 분산 환경에서는 Redisson lock을 사용하는 것이 분산 서버에서의 락 관리에 더 효율적일 가능성이 높다.
2. Redisson
이론
-
'발행/구독(pub/sub)' 방식

-
채널을 하나 만들고 lock을 점유중인 쓰레드가 다음 lock을 점유하려는 쓰레드에게 점유가 끝났음을 알려주면서 lock을 주고 받는 방식
-
락 해제가 되었을 때나 그외 몇번만 시도하기 때문에 Redis에 부하를 줄여주게 됨
public void decrease (Long id, Long quantity) { RLock lock = redissonClient.getLock(id.toString()); try { boolean available = lock.tryLock(5, 3, TimeUnit.SECONDS); if (!available) { System.out.println("lock 획득 실패"); return; } stockService.decrease(id, quantity); } catch (InterruptedException e) { throw new RuntimeException(e); } finally { lock.unlock(); } } -
tryLock을 사용해서 락을 획득한다.
-
wait time 동안 lock의 획득을 시도하며, 이 시간이 초과되면 lock의 획득에 실패하고 tryLock 함수는 false를 리턴.
-
lock의 획득에 성공한 이후엔 lease time이 지나면 자동으로 lock을 해제
-
혹시나 lock 해제시 문제가 생길 수 도 있어서 finally에 unlock() 메서드 추가함
-
테스트
- 재고 100개, 100번 실행 시
- 걸린 시간 : 3.819s
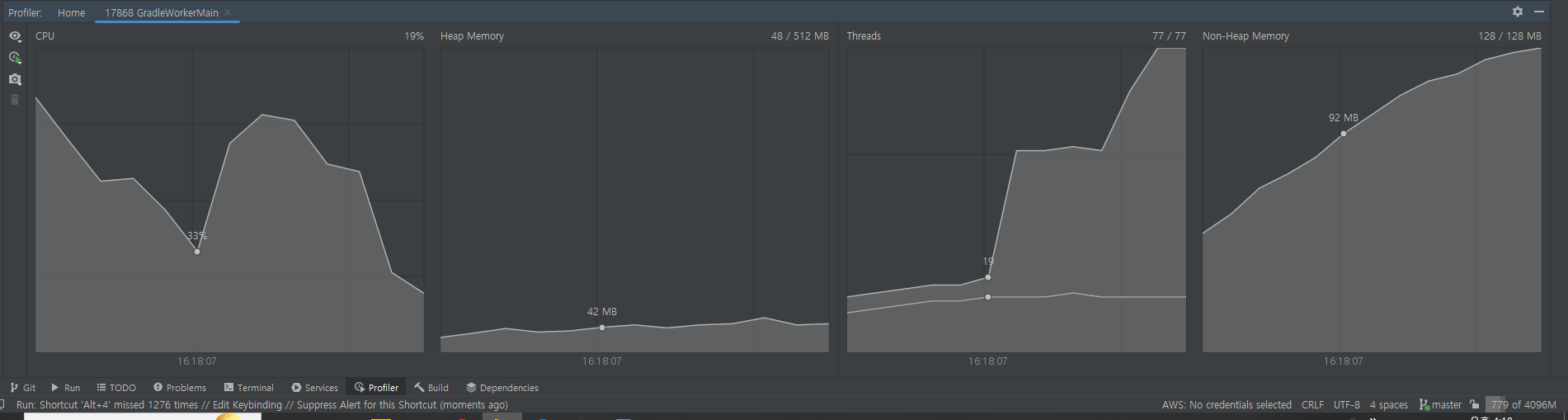
- 걸린 시간 : 3.819s
- 재고 1000개, 100번 실행 시
- 걸린 시간 : 3.862s
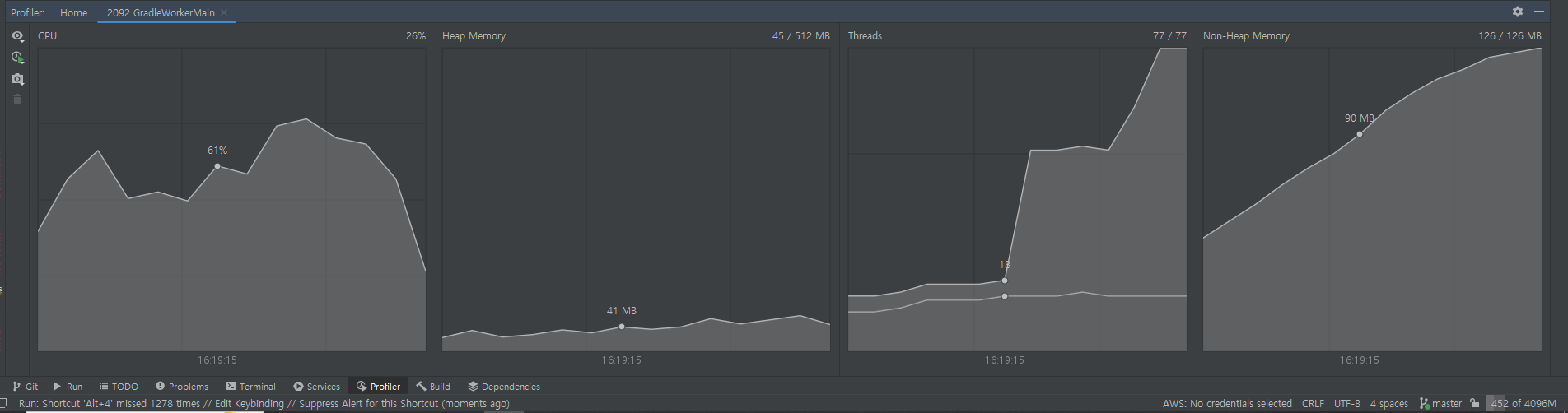
- 걸린 시간 : 3.862s
- 재고 1000개, 1000번 실행 시
- 걸린 시간 : 20s
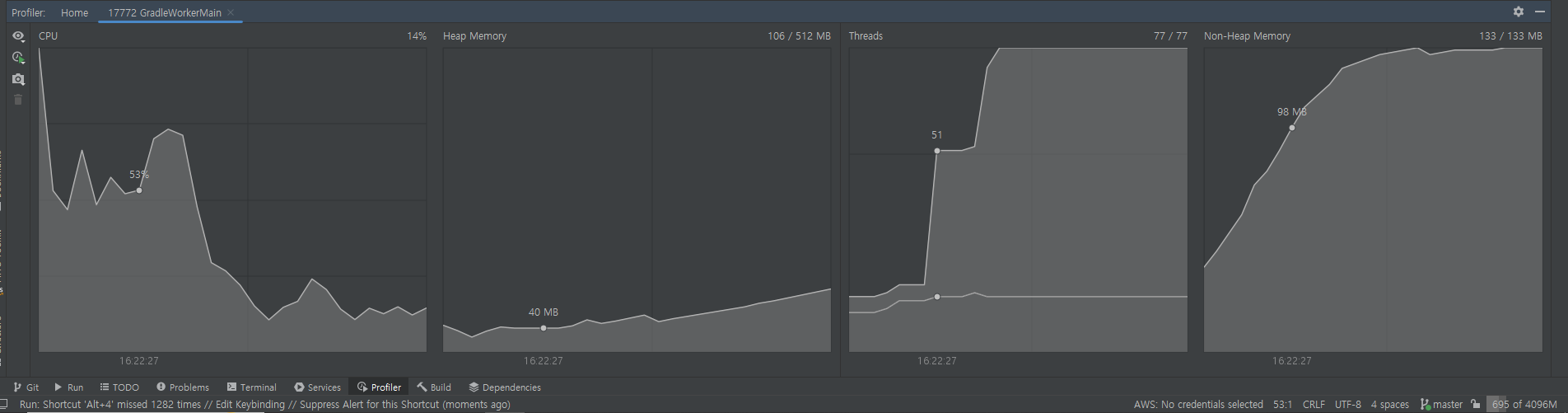
- 걸린 시간 : 20s
- 재고 100개, 10000번 실행 시
- 걸린 시간 : 66s
- 걸린 시간 : 66s
- 재고 1000개, 10000번 실행 시
- 걸린 시간 : 76s
- 걸린 시간 : 76s
- profiler를 통해 보면 똑같이 CPU 사용량이 증가하면 Thread를 더 만들어서 사용량을 분산 시키는 것을 볼 수 있다.
- 하지만 다른 것들은 62개까지 쓰레드를 만들었는데 Redisson은 77개까지 만들었다. - 결론
- Lettuce보다 Redisson이 더 성능이 좋았음
MySQL과 Redis 비교
MySQL
- 이미 데이터베이스로 MySQL를 사용하고 있다면 별도의 비용없이 사용이 가능
- 어느정도의 트래픽까지는 문제없이 활용이 가능
- Redis보다는 성능이 좋지 않다. (다중, 분산 서버 상황에서)
Redis
- 활용중인 Redis가 없다면 별도로 구축해야하기 때문에 인프라 관리비용이 발생
- MySQL보다 성능이 좋다. (다중, 분산 서버 상황에서)
프로젝트를 진행할 때에는 로컬에서는 비관적락이 더 빨랐으나, AWS 서버에서 돌리지 않았고 로컬로 진행했기 때문에, AWS 연결이 되어서 분산 서버가 사용된다면 비관적락과 Redisson의 성능을 다시 비교해보고 어떤 방법을 사용할지 결정하는 것이 좋겠다.
프로젝트 코드 & 테스트 시간
참고
재고 시스템 - 레디스 락
Lettuce vs Redisson
Redis 분산락
재고 시스템으로 알아보는 동시성 이슈 해결방법
