
Divided Conquer
222-풀링
문제
조기 졸업을 꿈꾸는 종욱이는 요즘 핫한 딥러닝을 공부하던 중, 이미지 처리에 흔히 쓰이는 합성곱 신경망(Convolutional Neural Network, CNN)의 풀링 연산에 영감을 받아 자신만의 풀링을 만들고 이를 222-풀링이라 부르기로 했다.
다음은 8×8 행렬이 주어졌다고 가정했을 때 222-풀링을 1회 적용하는 과정을 설명한 것이다
-
행렬을 2×2 정사각형으로 나눈다.
-
각 정사각형에서 2번째로 큰 수만 남긴다. 여기서 2번째로 큰 수란, 정사각형의 네 원소를 크기순으로 a4 ≤ a3 ≤ a2 ≤ a1 라 했을 때, 원소 a2를 뜻한다.
-
2번 과정에 의해 행렬의 크기가 줄어들게 된다.
종욱이는 N×N 행렬에 222-풀링을 반복해서 적용하여 크기를 1×1로 만들었을 때 어떤 값이 남아있을지 궁금해한다.
랩실 활동에 치여 삶이 사라진 종욱이를 애도하며 종욱이의 궁금증을 대신 해결해주자.
입력
첫째 줄에 N(2 ≤ N ≤ 1024)이 주어진다. N은 항상 2의 거듭제곱 꼴이다. (N=2K, 1 ≤ K ≤ 10)
다음 N개의 줄마다 각 행의 원소 N개가 차례대로 주어진다. 행렬의 모든 성분은 -10,000 이상 10,000 이하의 정수이다.
출력
마지막에 남은 수를 출력한다.
예제 입력 1
4
-6 -8 7 -4
-5 -5 14 11
11 11 -1 -1
4 9 -2 -4
예제 입력 2
8
-1 2 14 7 4 -5 8 9
10 6 23 2 -1 -1 7 11
9 3 5 -2 4 4 6 6
7 15 0 8 21 20 6 6
19 8 12 -8 4 5 2 9
1 2 3 4 5 6 7 8
9 10 11 12 13 14 15 16
17 18 19 20 21 22 23 24
힌트
예제2는 본문에 이어 다음과 같은 과정으로 답을 구할 수 있다.
코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.StringTokenizer;
// https://www.acmicpc.net/problem/17829
public class two17829 {
private int[][] matrix;
public int solution() throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
int size = Integer.parseInt(reader.readLine());
matrix = new int[size][size];
for (int i = 0; i < size; i++) {
StringTokenizer tokenizer = new StringTokenizer(reader.readLine());
for (int j = 0; j < size; j++) {
matrix[i][j] = Integer.parseInt(tokenizer.nextToken());
}
}
return pooling(size, 0, 0);
}
public int pooling(int n, int x, int y) {
// 재귀 호출 하지 않고 계산한 결과를 반환
if (n == 2) {
int[] four = new int[] {
matrix[y][x],
matrix[y + 1][x],
matrix[y][x + 1],
matrix[y + 1][x + 1]
};
Arrays.sort(four);
return four[2];
}
// 재귀 호출
else {
int half = n / 2;
int [] four = new int[] {
pooling(half, x, y),
pooling(half, x + half, y),
pooling(half, x, y + half),
pooling(half, x + half, y + half)
};
Arrays.sort(four);
return four[2];
}
}
public static void main(String[] args) throws IOException {
System.out.println(new two17829().solution());
}
}별 찍기 - 10
문제
재귀적인 패턴으로 별을 찍어 보자. N이 3의 거듭제곱(3, 9, 27, ...)이라고 할 때, 크기 N의 패턴은 N×N 정사각형 모양이다.
크기 3의 패턴은 가운데에 공백이 있고, 가운데를 제외한 모든 칸에 별이 하나씩 있는 패턴이다.
***
* *
***N이 3보다 클 경우, 크기 N의 패턴은 공백으로 채워진 가운데의 (N/3)×(N/3) 정사각형을 크기 N/3의 패턴으로 둘러싼 형태이다. 예를 들어 크기 27의 패턴은 예제 출력 1과 같다.
입력
첫째 줄에 N이 주어진다. N은 3의 거듭제곱이다. 즉 어떤 정수 k에 대해 N=3k이며, 이때 1 ≤ k < 8이다.
출력
첫째 줄부터 N번째 줄까지 별을 출력한다.
예제 입력 1
27
코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
// https://www.acmicpc.net/problem/2447
public class five2447 {
private char[][] starboard;
public void solution() throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(reader.readLine());
starboard = new char[n][n];
for (char[] row: starboard) {
Arrays.fill(row, ' ');
}
setStar(n, 0, 0);
StringBuilder drawStar = new StringBuilder();
for (int i = 0; i < n; i++) {
drawStar.append(starboard[i]).append('\n');
}
System.out.println(drawStar.toString());
}
public void setStar(int n, int x, int y) {
// n = 3이라면 실제로 별을 그리기 시작
if (n == 3) {
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
// 가운데면 스킵
if (i == 1 && j == 1) continue;
// 아니라면 별 그리기
starboard[y + i][x + j] = '*';
}
}
}
// n = 3일 때까지 재귀 호출
else {
int offset = n / 3;
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
// 가운데 사각형이면 굳이 재귀호출 안해도 된다.
if (i == 1 && j == 1) continue;
setStar(offset, x + offset * i, y + offset * j);
}
}
}
}
public static void main(String[] args) throws IOException {
new five2447().solution();
}
}Heap
Heap
Heap은 특수한 형태의 완전 이진 트리이다. 완전 이진 트리의 어떤 노드 C와 부모 노드 P가 있을 때, C의 값보다 P의 값이 항상 크거나 C의 값보다 P의 값이 항상 작을 때 이 트리를 힙이라고 부른다. 다양한 요소를 가지고 있는 집합에 대하여 가장 큰 값이나 가장 작은 값을 찾기 용이하다. 따라서 우선순위 큐를 만드는 데 유용하게 사용된다. 힙은 정렬을 위한 자료 구조가 아니라 최대/최소를 위한 자료 구조라고 보는 것이 더욱 적합하다. 완전 이진 트리가 아니라면 힙이 아니다.
힙의 삽입 연산 → ReHeapUp / SiftUp
- 제일 오른쪽 아래에 원소를 삽입한다.
- 새로 삽입한 원소를 부모 노드와 비교한다.
- 힙의 조건을 만족시키지 못하는 경우 교환해서 위치를 찾아 준다.
- 새로 추가한 원소가 루트 원소가 되거나 힙의 조건을 만족시킬 때까지 반복한다.
삽입 순서에 따라 힙의 모양이 달라질 수 있다.
일단 삽입을 한다.
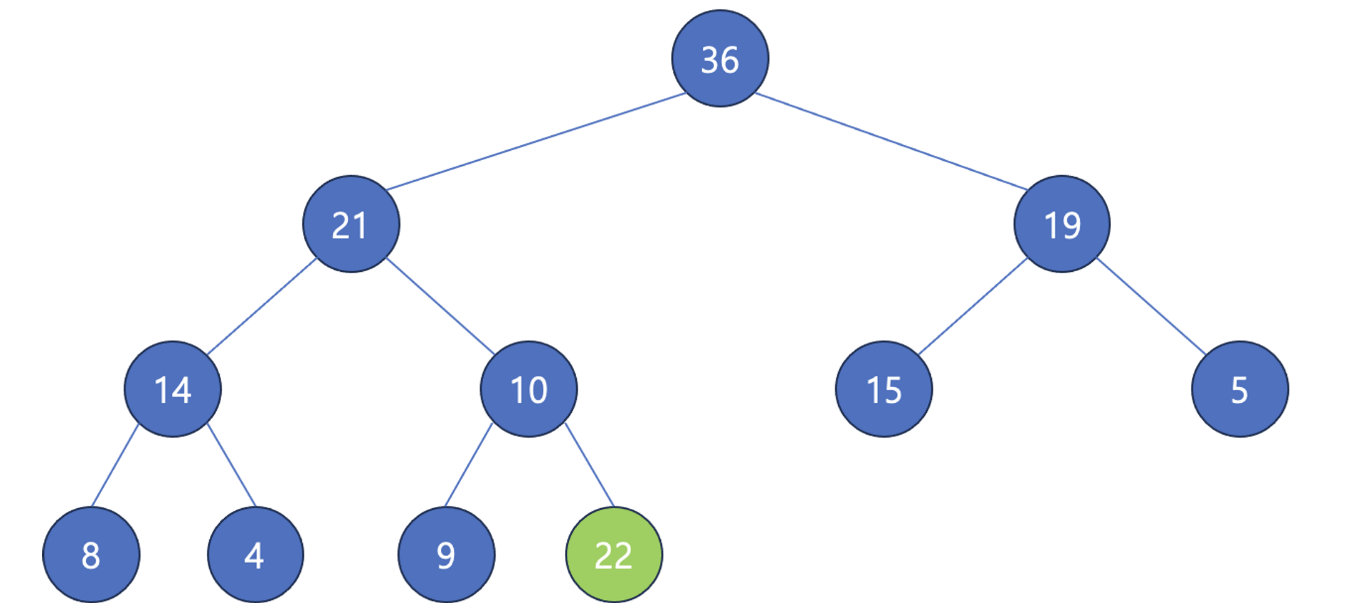
이후 부모 노드와 비교해서 조건을 만족시키지 않으면 위치를 변경한다.
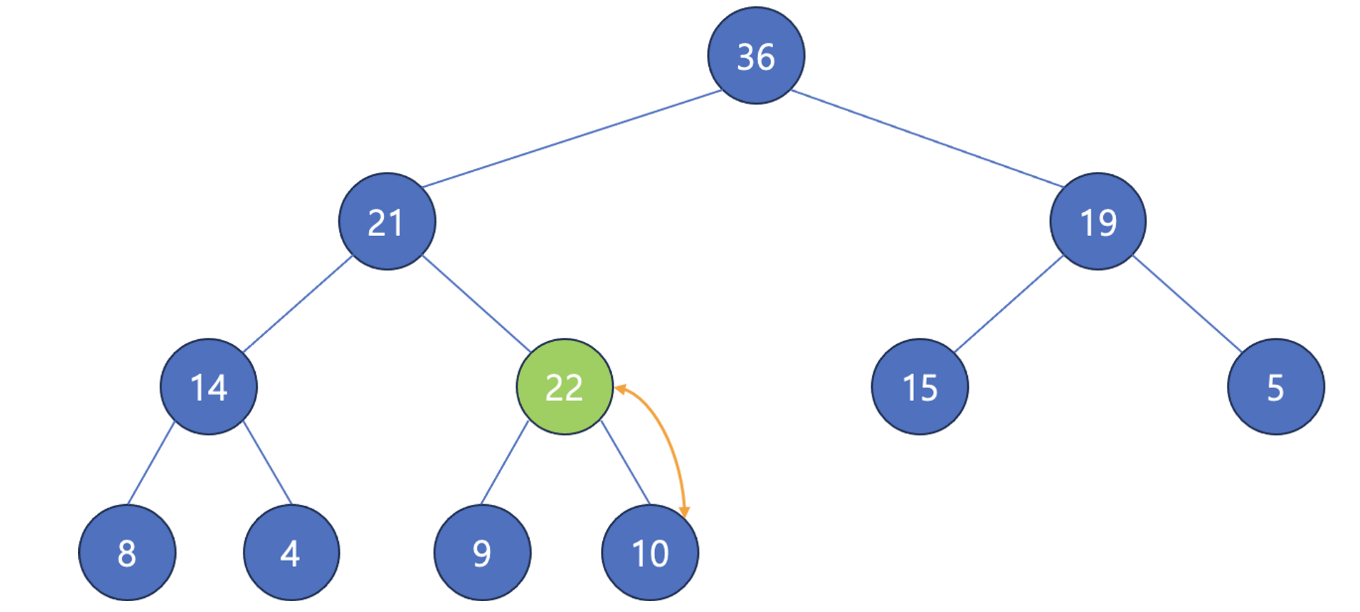
힙 조건을 만족할 때까지 위 과정을 반복한다.

힙의 삭제 연산 → ReHeapDown
- 힙의 루트 원소를 제거한다.
- 루트 원소의 위치에 힙의 마지막 원소를 배치한다.
- 루트 원소와 자식 원소들을 비교한다.
- 힙의 조건을 만족시키지 못하게 배치된 경우 서로 교환한다.
- 만일 둘 다 조건을 만족시키지 못하는 경우 만족시킬 수 있는 더 크거나 작은 값과 교환한다.
- 교환이 일어났다면 다시 자식 노드들과 비교한다.
루트 노드를 삭제한다.
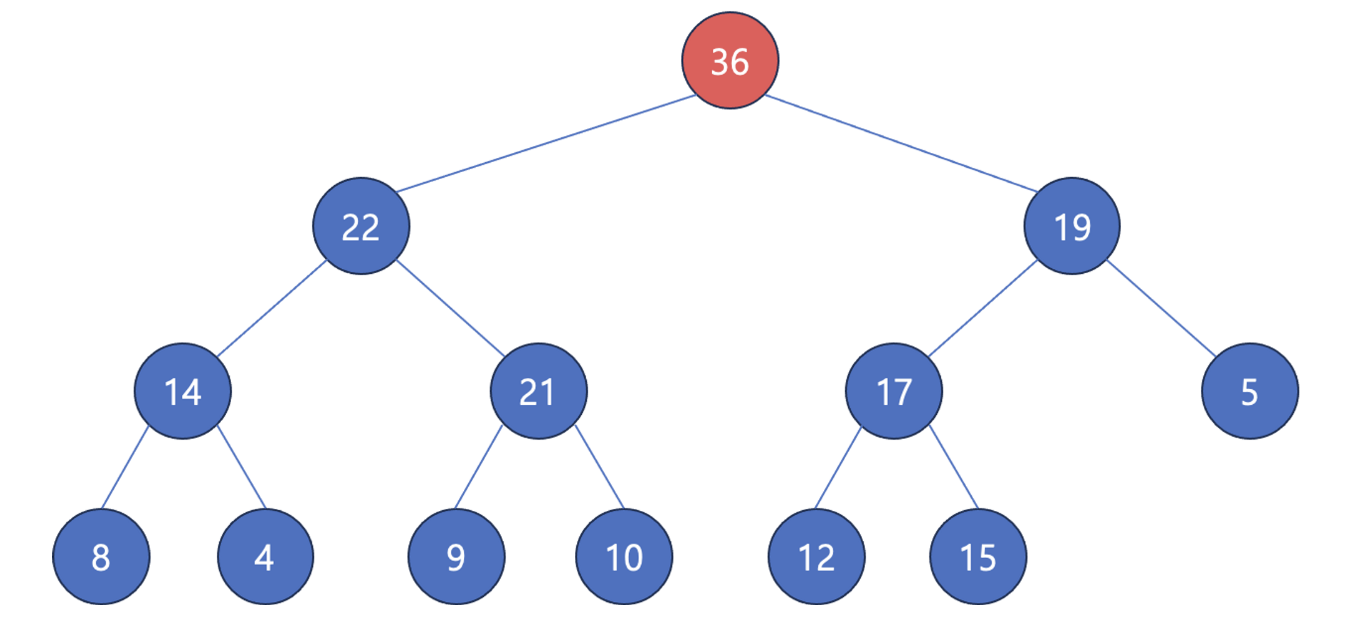
가장 마지막 노드를 루트로 설정한다.

자식 노드와 교환을 통해 자리를 찾아 간다.

Binary Max Heap
insert 연산
// 삽입 연산
public void insert(int item) {
heap[size] = item;
// TODO 비교하며 끌어올리기
reHeapUp(size);
size++;
}
// index에 존재하는 원소를 자신의 부모와 비교해서
// heap의 조건을 만족시키도록 교환을 반복적으로 진행하는 함수
private void reHeapUp(int index) {
while (index > 0) {
int parentIndex = (index - 1) / 2;
// 힙의 조건 만족
if (heap[index] <= heap[parentIndex]) break;
// 아니면 교환
int temp = heap[index];
heap[index] = heap[parentIndex];
heap[parentIndex] = temp;
index = parentIndex;
}
}remove 연산
// 삭제 연산
public int remove() {
// 루트 노드 제거
int root = heap[0];
// 마지막 자식 할당
heap[0] = heap[size - 1];
size--;
// TODO 아래로 끌어내리기
reHeapDown(0);
return root;
}
private void reHeapDown(int index) {
while(index < size) {
int leftChild = index * 2 + 1;
int rightChild = index * 2 + 2;
int maxIndex = index;
// 왼쪽 자식이 존재하며 왼쪽 자식이 현재 루트보다 클 때
if (leftChild < size && heap[leftChild] > heap[maxIndex]) {
maxIndex = leftChild;
}
// 오른쪽이 제일 크다면 갱신되었을 것
if (rightChild < size && heap[rightChild] > heap[maxIndex]) {
maxIndex = rightChild;
}
// 부모 인덱스가 제일 큰 경우는 힙 만족이라 조건
if (maxIndex == index) break;
int temp = heap[index];
heap[index] = heap[maxIndex];
heap[maxIndex] = temp;
index = maxIndex;
}
}전체 코드
public class BinaryMaxHeap {
private int[] heap;
private int size;
public BinaryMaxHeap() {
heap = new int[32];
size = 0;
}
// 삽입 연산
public void insert(int item) {
heap[size] = item;
// TODO 비교하며 끌어올리기
reHeapUp(size);
size++;
}
// index에 존재하는 원소를 자신의 부모와 비교해서
// heap의 조건을 만족시키도록 교환을 반복적으로 진행하는 함수
private void reHeapUp(int index) {
while (index > 0) {
int parentIndex = (index - 1) / 2;
// 힙의 조건 만족
if (heap[index] <= heap[parentIndex]) break;
// 아니면 교환
int temp = heap[index];
heap[index] = heap[parentIndex];
heap[parentIndex] = temp;
index = parentIndex;
}
}
// 삭제 연산
public int remove() {
// 루트 노드 제거
int root = heap[0];
// 마지막 자식 할당
heap[0] = heap[size - 1];
size--;
// TODO 아래로 끌어내리기
reHeapDown(0);
return root;
}
private void reHeapDown(int index) {
while(index < size) {
int leftChild = index * 2 + 1;
int rightChild = index * 2 + 2;
int maxIndex = index;
// 왼쪽 자식이 존재하며 왼쪽 자식이 현재 루트보다 클 때
if (leftChild < size && heap[leftChild] > heap[maxIndex]) {
maxIndex = leftChild;
}
// 오른쪽이 제일 크다면 갱신되었을 것
if (rightChild < size && heap[rightChild] > heap[maxIndex]) {
maxIndex = rightChild;
}
// 부모 인덱스가 제일 큰 경우는 힙 만족이라 조건
if (maxIndex == index) break;
int temp = heap[index];
heap[index] = heap[maxIndex];
heap[maxIndex] = temp;
index = maxIndex;
}
}
public static void main(String[] args) {
BinaryMaxHeap binaryMaxHeap = new BinaryMaxHeap();
for (int i = 0; i < 32; i++) {
binaryMaxHeap.insert(i);
}
for (int i = 0; i < 32; i++) {
System.out.println(binaryMaxHeap.remove());
}
}
}min Heap을 사용하고 싶다면 PriorityQueue 라이브러리를 사용하면 되고, max Heap을 사용하고 싶다면 collenction.reverseOrder()를 사용하면 된다.
PriorityQueue<Integer> minHeap = new PriorityQueue<>();
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(Collections.reverseOrder());Spring AMQP
Message Broker
서비스가 발전하면서 기능이 많아지면 하나의 서버에서 모든 것을 처리하지 않는 방향을 인증해 볼 수 있다. 인증만 담당하는 서버를 따로 만들거나 서비스 사용 이력을 검색 가능한 형태로 기록하거나 채팅만 담당하는 등 기능을 분리할 수 있다. 이럴 경우 서로 상호 소통을 해야 하는 상황이 발생한다.
HTTP 요청을 보내면 Request (METHOD + url) + Header + Body로 구성된다. 이때 HTTP를 사용하면 요청을 보낸 후에 응답이 올 때까지 서버의 수행이 중단된다. 여러 서버에 동시에 정보를 전달하기 어렵고 어떤 특정 서버를 지정해서 요청을 보내야 하기 때문에 결합성이 증가한다.
대신 Message Broker라는 소프트웨어를 사용해 메시지의 전달을 위임할 수 있다. 서버는 메시지를 Message Broker에 한 시점에 맡기고, 메시지 대상자는 처리 가능한 시점에 Message Broker에서 메시지를 꺼내는 것이다.
Message Broker를 사용하면 서버와 서버 사이에 비동기 통신이 가능해진다. 응답이 돌아올 때까지 기다리지 않아도 된다는 것이다. 서버간의 결합성을 감소시키고 확장성을 확보한다.
RabbitMQ
AMQP 통신을 기반으로 여러 소프트웨어간 메시지를 주고받게 해 주는 대중적인 Message Broker이다.
CloudAMQP - Queue starts here.
위 사이트에서 로그인을 진행해 준다. 이후 새로운 팀을 만들어 준다. 이후 만들어진 팀에서 아직 개발 단계기 때문에 새로운 인스턴스를 만들어 준다.
지역까지 설정해 주면 인스턴스가 생성된다.
Job Queue
메시지를 주고받는 방식을 정의한 디자인 패턴의 일종이다. 한 서버에서는 처리해야 하는 작업을 만들어 Queue에 적재한다. 처리하는 기능을 갖춘 소프트웨어가 Queue에서 순차적으로 작업을 처리한다. 작업을 만든 서버는 작업을 어떻게 진행되는지 살펴볼 필요가 없이 순서만 정해 주면 된다.
lombok, JPA, RabbitMQ가 있는 consumer 프로젝트와 lombok, JPA, Web, RabbitMQ가 있는 producer 프로젝트 두 개를 준비해 준다.
Producer
producer 폴더를 열고 의존성을 추가해 준다.
// sqlite
implementation 'org.xerial:sqlite-jdbc:3.41.2.2'
runtimeOnly 'org.hibernate.orm:hibernate-community-dialects:6.2.4.Final'
// gson
implementation 'com.google.code.gson:gson:2.9.0'이후 yaml 파일도 설정해 준다.
spring:
rabbitmq:
**username: username
password: password**
host: dingo.rmq.cloudamqp.com
virtual-host: username
datasource:
url: jdbc:sqlite:db.sqlite
driver-class-name: org.sqlite.JDBC
username: sa
password: password
jpa:
hibernate:
ddl-auto: create
database-platform: org.hibernate.community.dialect.SQLiteDialect
show-sql: true이때 username과 password는 rabbit 사이트에서 볼 수 있다. 이후 JobEntity와 JobRepository를 만들어 준다.
import jakarta.persistence.*;
import lombok.Data;
@Data
@Entity
@Table(name = "jobs")
public class JobEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// 작업을 식별하기 위한 ID -> UUID
private String jobId;
// 작업의 상태를 저장하기 위한 status
// IDLE: 아직 처리 전
// PROCESSING: 어떤 Consumer에 의해 작업이 처리되기 시작
// DONE: 작업 처리 끝
private String status;
// 인코딩이 끝난 영상이 위치할 곳 가정
private String resultPath;
}import java.util.Optional;
public interface JobRepository extends JpaRepository<JobEntity, Long> {
Optional<JobEntity> findByJobId(String jobId);
}이후 총 4개의 dto를 만든다.
import lombok.AllArgsConstructor;
import lombok.Data;
@Data
@AllArgsConstructor
// Producer가 발생시킬 Job을 정의한 DTO
public class JobPayload {
private String jobId;
private String filename;
private String path;
}import lombok.Data;
@Data
// 사용자가 인코딩 요청을 보내는 DTO
public class JobRequest {
private String filename;
}import com.example.producer.jpa.JobEntity;
import lombok.Data;
@Data
// 사용자에게 요청 처리 상태를 알리기 위한 DTO
public class JobStatus {
private String jobId;
private String status;
private String resultPath;
public static JobStatus fromEntity(JobEntity jobEntity) {
JobStatus jobStatus = new JobStatus();
jobStatus.setJobId(jobEntity.getJobId());
jobStatus.setStatus(jobEntity.getStatus());
jobStatus.setResultPath(jobEntity.getResultPath());
return jobStatus;
}
}import lombok.AllArgsConstructor;
import lombok.Data;
@Data
@AllArgsConstructor
// 사용자에게 요청의 처리 상태를 확인할 수 있는
// jobId를 반환하는 용도의 DTO
public class JobTicket {
private String jobId;
}ProduceConfig를 만들어서 큐를 생성한 뒤 작업을 생성한다.
@Configuration
public class ProducerConfig {
@Bean
public Queue queue() {
return new Queue(
"boot.amqp.worker-queue",
true,
false,
true)
}
}들어가는 인자들은 다음과 같다.
name: Producer와 Consumer가 같은 Queue (같은 우체통)을 사용하기 위해 작성하는 식별자durable: Producer인 서버가 종료된 뒤에도 Queue가 유지될지exclusive: 지금 이 서버만 큐를 사용할 수 있는지autoDelete: 사용되고 있지 않은 큐를 자동으로 삭제할 것인지
이후 ProduceService를 구현한다.
import com.example.producer.dto.JobPayload;
import com.example.producer.dto.JobTicket;
import com.example.producer.jpa.JobEntity;
import com.example.producer.jpa.JobRepository;
import com.google.gson.Gson;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.stereotype.Service;
import java.util.UUID;
@Slf4j
@Service
@RequiredArgsConstructor
public class ProducerServices {
// RabbitMQ에 메시지를 적재하기 위한 서비스
private final RabbitTemplate rabbitTemplate;
private final JobRepository jobRepository;
private final Queue jobQueue;
private final Gson gson;
// filename을 인자로 받고
// filename을 바탕으로 JSON으로 직렬화된 작업 정보를
// Queue에 적재한 뒤
// 사용자에게 JobTicket을 반환하는 메소드
public JobTicket senrd(String filename) {
// jobId 발행
String jobId = UUID.randomUUID().toString();
JobTicket jobTicket = new JobTicket(jobId);
// jobPayload 생성 (Consumer에서 확인)
JobPayload jobPayload = new JobPayload(
jobId,
filename,
String.format("/media/user-uploads/raw/%s", filename)
);
// jobEntity로 작업 내역 입력 기록
JobEntity jobEntity = new JobEntity();
jobEntity.setJobId(jobId);
jobEntity.setStatus("IDLE");
jobRepository.save(jobEntity);
// Message Broker에게 메시지 전달
rabbitTemplate.convertAndSend(
// Queue의 이름
jobQueue.getName(),
// 메시지로 보낼 문자열
gson.toJson(jobPayload)
);
// 사용자에게 추후 확인용 JwbTicket 전달
log.info("Send job: {}", jobTicket.getJobId());
return jobTicket;
}
}Consumer
Consumer 프로젝트에서 가장 중요한 것은 ddl-auto: none으로 설정해 줘야 한다는 것이다. 사용자 쪽에서는 수정만 가능하도록 하는 것이다.
이후 ProducerConfig와 같이 ConsumerConfig를 만들어 Queue를 정의해 주고, RabbitMQ의 Queue에 적재되는 메시지를 받아서 처리하는 Consumer Service도 만든다.
@Slf4j
@Service
// 이 클래스는 RabbitMQ의 Queue에 적재되는 메시지를 받아서 처리하기 위함
@RabbitListener
@RequiredArgsConstructor
public class ConsumerService {
private final JobRepository jobRepository;
private final Gson gson;
@RabbitHandler
// message에 Queue에 담겼던 문자열 전달
public void receive(String message) throws InterruptedException {
// 역직렬화
JobPayload newJob = gson.fromJson(message, JobPayload.class);
String jobId = newJob.getJobId();
log.info("Received Job: {}", jobId);
// Entity 검색
Optional<JobEntity> optionalJob = jobRepository.findByJobId(jobId);
// TODO 예외처리를 해 줘야 마땅하나 잠시 생략
JobEntity jobEntity = optionalJob.get();
// 요청을 처리 상태로 업데이트
jobEntity.setStatus("PROCESSING");
jobEntity = jobRepository.save(jobEntity);
log.info("Start Processing Job: {}", jobId);
// 처리하는데 시간이 걸린다고 치자
TimeUnit.SECONDS.sleep(5);
jobEntity.setStatus("DONE");
jobEntity.setResultPath(
String.format("/media/user-uploaded/processed/%s", newJob.getFilename())
);
jobRepository.save(jobEntity);
log.info("Finished Job: {}", jobId);
}
}