
문제
문제 설명
[본 문제는 정확성과 효율성 테스트 각각 점수가 있는 문제입니다.]
친구들로부터 천재 프로그래머로 불리는 "프로도"는 음악을 하는 친구로부터 자신이 좋아하는 노래 가사에 사용된 단어들 중에 특정 키워드가 몇 개 포함되어 있는지 궁금하니 프로그램으로 개발해 달라는 제안을 받았습니다.그 제안 사항 중, 키워드는 와일드카드 문자중 하나인 '?'가 포함된 패턴 형태의 문자열을 뜻합니다. 와일드카드 문자인 '?'는 글자 하나를 의미하며, 어떤 문자에도 매치된다고 가정합니다. 예를 들어 "fro??"는 "frodo", "front", "frost" 등에 매치되지만 "frame", "frozen"에는 매치되지 않습니다.
가사에 사용된 모든 단어들이 담긴 배열 words와 찾고자 하는 키워드가 담긴 배열 queries가 주어질 때, 각 키워드 별로 매치된 단어가 몇 개인지 순서대로 배열에 담아 반환하도록 solution 함수를 완성해 주세요.
제한 사항
- 가사 단어 제한사항
words의 길이(가사 단어의 개수)는 2 이상 100,000 이하입니다.- 각 가사 단어의 길이는 1 이상 10,000 이하로 빈 문자열인 경우는 없습니다.
- 전체 가사 단어 길이의 합은 2 이상 1,000,000 이하입니다.
- 가사에 동일 단어가 여러 번 나올 경우 중복을 제거하고
words에는 하나로만 제공됩니다. - 각 가사 단어는 오직 알파벳 소문자로만 구성되어 있으며, 특수문자나 숫자는 포함하지 않는 것으로 가정합니다.
- 검색 키워드 제한사항
queries의 길이(검색 키워드 개수)는 2 이상 100,000 이하입니다.- 각 검색 키워드의 길이는 1 이상 10,000 이하로 빈 문자열인 경우는 없습니다.
- 전체 검색 키워드 길이의 합은 2 이상 1,000,000 이하입니다.
- 검색 키워드는 중복될 수도 있습니다.
- 각 검색 키워드는 오직 알파벳 소문자와 와일드카드 문자인
'?'로만 구성되어 있으며, 특수문자나 숫자는 포함하지 않는 것으로 가정합니다. - 검색 키워드는 와일드카드 문자인
'?'가 하나 이상 포함돼 있으며,'?'는 각 검색 키워드의 접두사 아니면 접미사 중 하나로만 주어집니다.- 예를 들어
"??odo","fro??","?????"는 가능한 키워드입니다. - 반면에
"frodo"('?'가 없음),"fr?do"('?'가 중간에 있음),"?ro??"('?'가 양쪽에 있음)는 불가능한 키워드입니다.
- 예를 들어
입출력 예
| words | queries | result |
|---|---|---|
| ["frodo", "front", "frost", "frozen", "frame", "kakao"] | ["fro??", "????o", "fr???", "fro???", "pro?"] | [3, 2, 4, 1, 0] |
입출력 예 설명
"fro??"는"frodo","front","frost"에 매치되므로 3입니다."????o"는"frodo","kakao"에 매치되므로 2입니다."fr???"는"frodo","front","frost","frame"에 매치되므로 4입니다."fro???"는"frozen"에 매치되므로 1입니다."pro?"는 매치되는 가사 단어가 없으므로 0 입니다.
아이디어
- 정규 표현식으로 접근해 봐야겠다
- import re 사용 → 벌써부터 효율성 검사 걱정됨
- 하지만 이진 탐색은 뭐 어떻게…?
제출 코드
import re
def solution(words, queries):
answer = []
for query in queries:
cnt = 0
q_len = len(query)
query = query.replace('?', '.')
query = re.compile(query)
for word in words:
if len(word) != q_len:
continue
if query.match(word) != None:
cnt += 1
answer.append(cnt)
return answer- 효율성 미통과
참고 코드
def solution(words, queries):
head, head_rev = {}, {}
wc = []
def add(head, word):
node = head
for w in word:
if w not in node:
node[w] = {}
node = node[w]
if 'len' not in node:
node['len'] = [len_word]
else:
node['len'].append(len_word)
node['end'] = True
for word in words:
len_word = len(word)
add(head, word)
add(head_rev, word[::-1])
wc.append(len_word)
def search(head, querie):
count = 0
node = head
for q in querie:
if q == '?':
return node['len'].count(len_qu)
elif q not in node:
break
node = node[q]
return count
li = []
for querie in queries:
len_qu = len(querie)
if querie[0] == '?':
if querie[-1] == '?':
li.append(wc.count(len_qu))
else:
li.append(search(head_rev, querie[::-1]))
else:
li.append(search(head, querie))
return li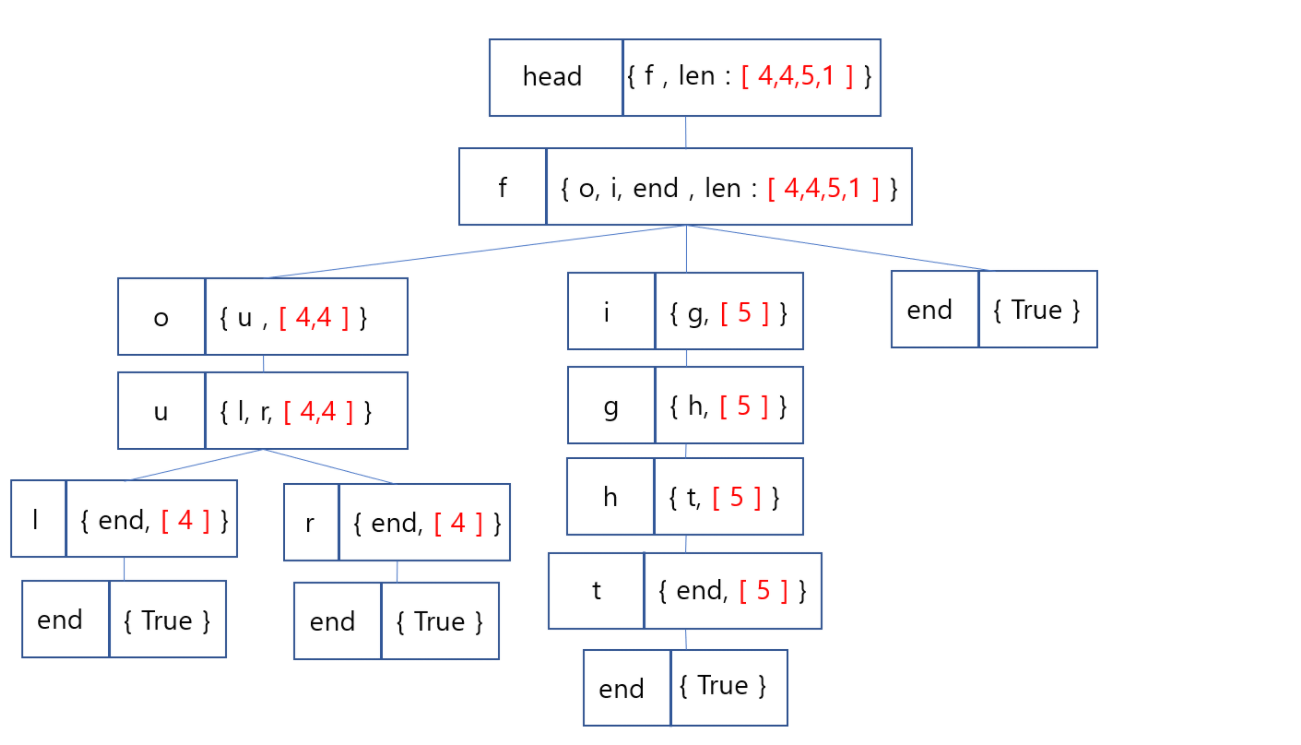
- add
- trie 구조에 위와 같은 그림 형태로 저장
- f로 시작하는 단어 중 길이가 4, 4, 5, 1인 단어가 하나씩 존재한다는 말
- fo로 시작하는 단어 중 길이가 4, 4인 단어가 하나씩 존재한다는 말
- search
- queries에서 하나씩 꺼낸 query의 알파벳 하나하나를 순회
- 알파벳이 물음표가 아니고 (아직 일치해야 할 부분이 남아 있고) 노드에 없지 않다면 (찾기가 끝나지 않았다면)
return node['len'].count(len_qu)해당 노드까지 일치한 단어들 중 query와 길이가 동일한 단어들을 카운트하여 반환
- ???abc를 처리하는 방법
- cba??? 로 뒤집어서 search를 돌리면 됨
- cba??? 로 뒤집어서 검색하려면 검색하는 단어들인 word들도 모두 뒤집어서 저장돼 있어야 함
- 따라서 뒤집혀서 저장돼 있는 자료 구조인 rev_trie 필요
모범 풀이
def solution(words, queries):
head, head_rev = {}, {}
wc = []
def add(head, word):
node = head
for w in word:
if w not in node:
node[w] = {}
node = node[w]
if 'len' not in node:
node['len'] = [len_word]
else:
node['len'].append(len_word)
node['end'] = True
for word in words:
len_word = len(word)
add(head, word)
add(head_rev, word[::-1])
wc.append(len_word)
def search(head, querie):
count = 0
node = head
for q in querie:
if q == '?':
return node['len'].count(len_qu)
elif q not in node:
break
node = node[q]
return count
li = []
for querie in queries:
len_qu = len(querie)
if querie[0] == '?':
if querie[-1] == '?':
li.append(wc.count(len_qu))
else:
li.append(search(head_rev, querie[::-1]))
else:
li.append(search(head, querie))
return li
추가 사항
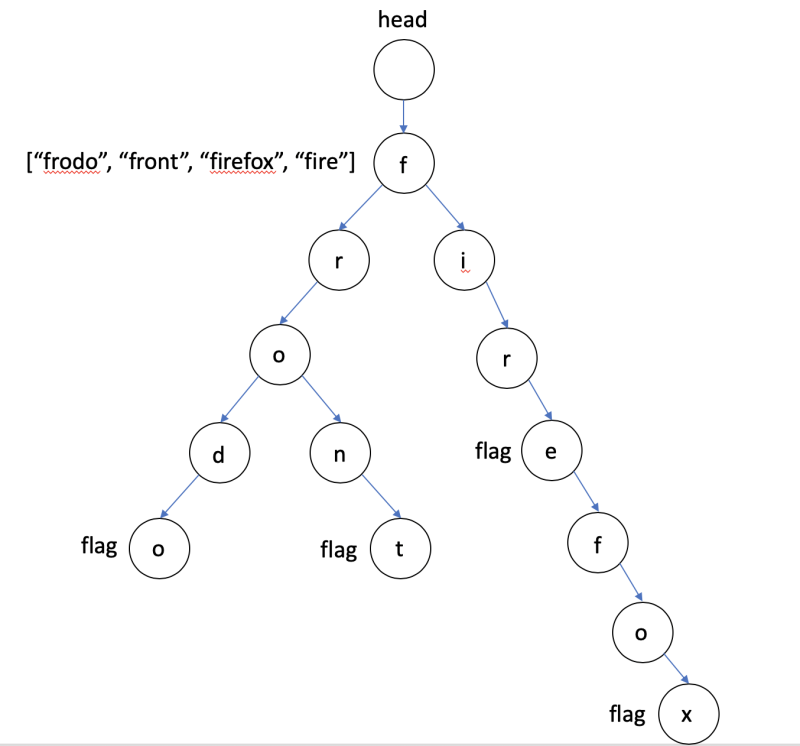
- Trie 알고리즘
-
입력되는 문자열을 tree 형식으로 만들어 빠르게 문자열 검색이 가능한 자료 구조
-
보통 문자열이 존재하는지 확인하기 위해서는 O(n) 시간 소요
-
Trie 알고리즘 사용하면 O(m) 소요 (m은 문자열의 길이)
-
문자열을 검색하는 문제에서 입력되는 문자열이 많을 경우 자주 사용
-
노드를 이용한 tree 형태로 이루어져 있음
-
문자열의 끝을 알리는 flag가 존재
-
- Node 구현
-
key: 값으로 입력될 문자
-
data: 문자열의 종료를 알리는 flag
-
children: 자식 노드 저장
class Node(object): def __init__(self, key, data=None): self.key = key self.data = data self.children = {}
-
- Trie 구현
class Trie: def __init__(self): self.head = Node(None) def insert(self, string): current_node = self.head for char in string: if char not in current_node.children: current_node.children[char] = Node(char) current_node = current_node.children[char] current_node.data = string def search(self, string): current_node = self.head for char in string: if char in current_node.children: current_node = current_node.children[char] else: return False if current_node.data: return True else: return False def starts_with(self, prefix): current_node = self.head words = [] for p in prefix: if p in current_node.children: current_node = current_node.children[p] else: return None current_node = [current_node] next_node = [] while True: for node in current_node: if node.data: words.append(node.data) next_node.extend(list(node.children.values())) if len(next_node) != 0: current_node = next_node next_node = [] else: break return words- head를 빈노드로 설정
- insert 함수
- 트리를 생성하기 위한 함수
- 입력된 문자열의 문자를 하나씩 children에 확인 후 저장하고 문자열을 다 돌면 마지막 노드의 data에 문자열을 저장
- search 함수
- 문자열이 존재하는지에 대한 여부를 리턴하는 함수
- 문자열을 하나씩 돌면서 확인 후 마지막 노드가 data가 존재한다면 True를, 그렇지 않거나 애초에 children에 존재하지 않는다면 False를 리턴
- starts_with 함수
- prefix단어로 시작하는 단어를 찾고 배열로 리턴하는 함수
- prefix단어까지 tree를 순회 한 이후 그다음부터 data가 존재하는 것들만 배열에 저장
