RDB / NoSQL
DB 와 RDBS의 차이점
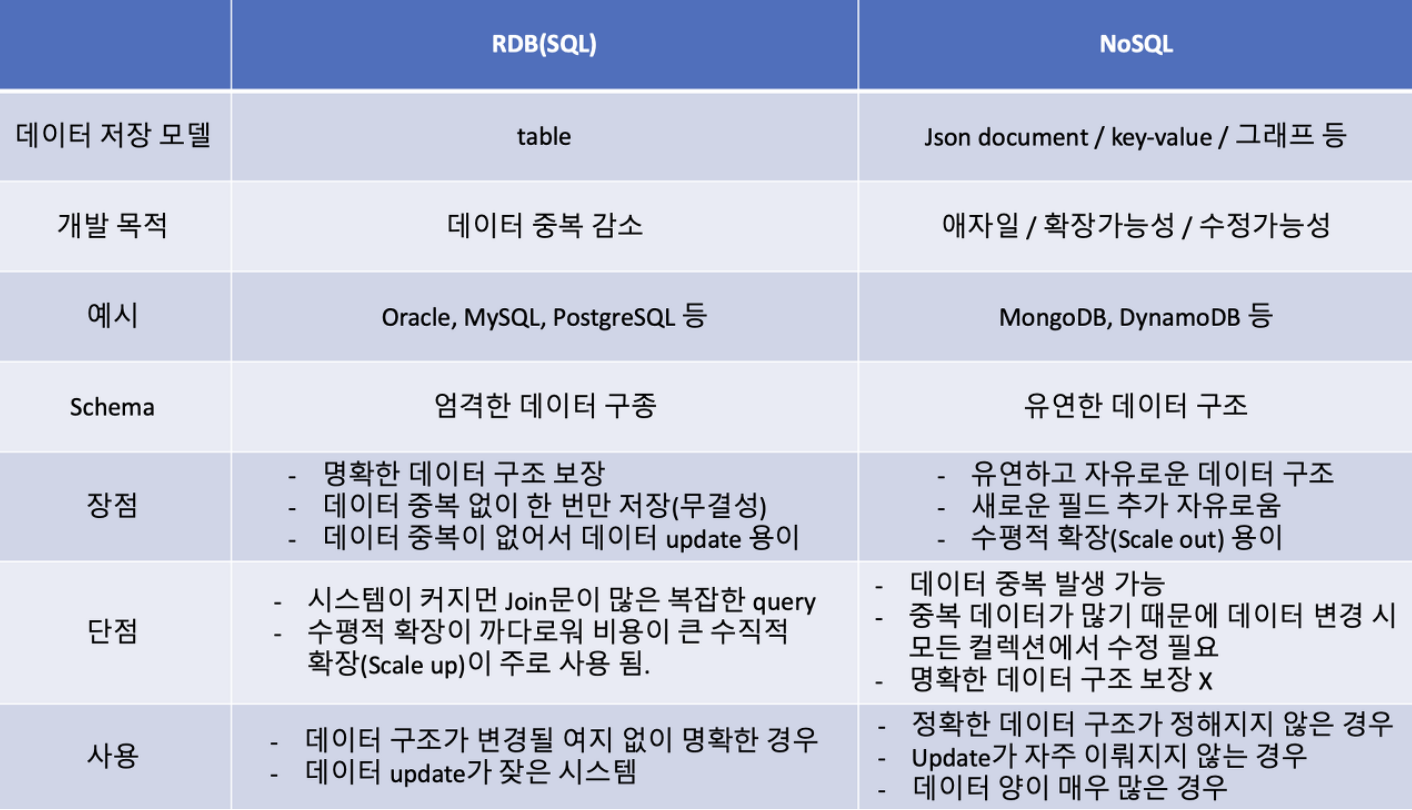
- 데이터 관리 분야에서는 서로 다른 개념!
DB
- 데이터베이스는 정리된 데이터의 모음. RDBMS 보다 상위 개념
- 진짜 찐 데이터 저장소 역할.
- 데이터를 관리하기 위한 도구나 기능이 본질적으로 포함되어 있지는 않다.
예시
- 문서, 키-값, 와이드 컬럼, 그래프 DB
RDB
-
관계형 모델을 사용하여 데이터를 저장하고 관리하는 특정 유형의 데이터베이스 관리 시스템(DBMS)
-
데이터는 테이블로 구성되며 관계를 통해 서로 연결됩니다.
-
데이터 조작 및 쿼리에 SQL을 사용
-
ACID 규정 준수: RDBMS는 일반적으로 안정적인 트랜잭션 처리를 위해 ACID(원자성, 일관성, 격리성, 내구성) 속성을 보장합니다
예시
- MySQL, PostgreSQL, Oracle Database
모든 RDBMS는 데이터베이스이지만 모든 데이터베이스가 RDBMS는 아닙니다.
RDBMS
스키마란?
- 데이터베이스의 구조적 설계. 일종의 골격!
RDB의 스키마
-
데이터가 구성되는 방식과 데이터 간의 관계를 정의한다.
-
RDB에서 스키마는 데이터베이스 내의 데이터 구성을 지시하는 프레임워크 역할을 합니다.
예시
- Ex) 테이블 이름, 필드, 데이터 유형, 엔티티 간의 관계(외래키) 등 논리적 제약조건 지정
데이터 개체(Entity), 속성(Attribute), 관계(Relationship)
그러면 ERD와 똑같은거 아냐??
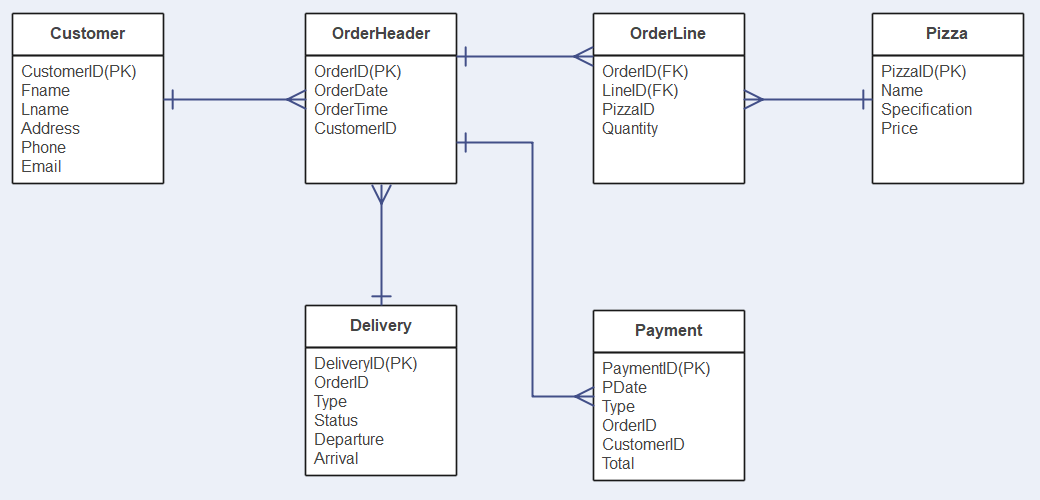
-
스키마는 디자인을 실제로 구현한 것. 상세 아키텍쳐 계획.
-
ERD는 이러한 스키마를 지도처럼 시각화해서 표현한것!
SQL
-
DBMS에서 데이터를 관리하고 조작하기 위해 특별히 고안된 표준 프로그래밍 언어
-
관계형 데이터베이스에 저장된 데이터에 대해 다양한 작업을 수행하는 데 사용!
-
RDB 와 연결해 사용자 및 애플리케이션 과 데이터베이스 중간에서 상호작용한다.
예시
- SELECT, 새 데이터 삽입(INSERT), 기존 데이터 업데이트(UPDATE), 데이터 삭제(DELETE), 데이터베이스 구조 수정(CREATE, ALTER, DROP) 등
정리
- 관계형 데이터베이스 환경에서는 데이터베이스가 데이터 자체를 저장
- 스키마가 이 데이터의 구조와 조직을 정의하며,
- SQL은 스키마에 정의된 규칙과 구조에 따라 데이터베이스 내의 데이터를 상호 작용, 조작 및 관리하는 데 사용됩니다.
NoSQL
No? vs Not only?
No
- "NoSQL"이라는 용어는 원래 "No SQL"을 의미
- 이는 전통적인 관계형 DBMS에서 벗어나는 움직임을 반영하기 위함이었음.
Not Only
-
그러나 시간이 지나면서 "NoSQL"에 대한 해석은 "Not only SQL"이라는 의미로 발전
-
이는 NoSQL 데이터베이스가 SQL 기반 시스템의 '대안'으로 개발되었지만 반드시 이를 완전히 대체할 의도는 아니라는 점을 인정하기때문!
=> 점점 NoSQL 데이터베이스는 다양한 데이터 모델(예: 키-값, 문서, 열 계열, 그래프)을 제공하며
- 기존 SQL 데이터베이스가 덜 효율적일 수 있는 특정 사용 사례를 처리하도록 설계되는 중이다
NoSQL 스키마
스키마 유연성
- 시스템 자체에 의해 엄격하게 적용되지 않고 애플리케이션 수준에서 정의 및 관리할 수 있는 유연하거나 동적인 스키마
Ex) 전체 데이터베이스 구조를 수정하지 않고도 데이터 형식을 쉽게 변경가능
-
ACID, Transaction 등을 지원하지 않는다.(아닌경우도 있다! ex 몽고Db)
-
NoSQL 데이터베이스를 사용하면 유연하고 동적 스키마로 작업할 수 있습니다
-
구조를 미리 정의할 필요 없이 데이터를 저장하고 검색할 수 있습니다.
예시
문서 지향(예: MongoDB)
-
각 문서는 서로 다른 구조를 가질 수 있지만 일반적으로 JSON형식
-
각 '문서'는 고유한 구조를 가질 수 있습니다. 예를 들어, 한 문서에는 동일한 컬렉션(RDBMS의 테이블과 유사)에 있는 다른 문서와 완전히 다른 데이터 필드가 포함될 수 있습니다.
키-값 저장소(예: Redis)
- 데이터는 연관된 값이 있는 키로 저장
- 값의 구조가 데이터베이스 시스템에 의해 적용되지 않는 가장 간단한 형식입니다.
import redis
redis_client.lpush('fruits', 'apple')
redis_client.lpush('fruits', 'banana')
# 키-값 쌍의 모음인 해시를 사용 (파이썬 딕셔너리 느낌)
redis_client.hset('user:1000', 'name', 'Alice')
redis_client.hset('user:1000', 'age', 30)
열(컬럼) 저장소(예: Cassandra)
-
대용량 데이터를 관리하기 위해서 설계된 시스템.
-
구조가 정의되어있긴 하지만, 기존 SQL 데이터베이스보다 더 유연
-
데이터는 계열로 그룹화된 열에 저장됩니다. 열은 행마다 다를 수 있습니다.
코드 예시
import com.datastax.oss.driver.api.core.CqlSession;
import com.datastax.oss.driver.api.core.CqlSessionBuilder;
import com.datastax.oss.driver.api.core.cql.ResultSet;
import com.datastax.oss.driver.api.core.cql.Row;
public class CassandraExample {
public static void main(String[] args) {
// Create a session with Cassandra
try (CqlSession session = new CqlSessionBuilder().build()) {
// Create a keyspace
String createKeyspace = "CREATE KEYSPACE IF NOT EXISTS mykeyspace WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};";
session.execute(createKeyspace);
// Create a table
String createTable = "CREATE TABLE IF NOT EXISTS mykeyspace.users (id UUID PRIMARY KEY, name text, email text);";
session.execute(createTable);
// Insert data into the table
String insertData = "INSERT INTO mykeyspace.users (id, name, email) VALUES (uuid(), 'John Doe', 'john.doe@example.com');";
session.execute(insertData);
// Retrieve data from the table
ResultSet resultSet = session.execute("SELECT * FROM mykeyspace.users;");
for (Row row : resultSet) {
System.out.println("User: " + row.getUuid("id") + ", " + row.getString("name") + ", " + row.getString("email"));
}
}
}
}
그래프 데이터베이스(예: Neo4j)
-
노드, 에지, 속성이 있는 그래프 구조를 사용하여 데이터를 표현하고 저장
-
관계형 스키마에 비해 더 유동적!
-
데이터베이스는 다양한 데이터 모델(예: 키-값, 문서, 열 패밀리, 그래프)을 제공하며 일반적으로 보다 유연한 스키마를 허용
import org.neo4j.driver.AuthTokens;
try (Session session = driver.session()) {
// Write transactions
String createQuery = "CREATE (a:Person {name: 'Alice', age: 22})-[:KNOWS]->(b:Person {name: 'Bob', age: 25})";
try (Transaction tx = session.beginTransaction()) {
tx.run(createQuery);
tx.commit();
}
// Read transactions
String readQuery = "MATCH (a:Person)-[:KNOWS]->(b:Person) RETURN a.name, b.name";
try (Transaction tx = session.beginTransaction()) {
Result result = tx.run(readQuery);
while (result.hasNext()) {
var record = result.next();
System.out.println(record.get("a.name").asString() + " knows " + record.get("b.name").asString());
}
tx.commit();
}
}
}NoSQL 의 SQL
-
SQL(구조적 쿼리 언어)을 사용하지 않습니다.
-
동적이며 종종 스키마가 없는 데이터 모델을 통해 더 많은 유연성을 제공!
-
특정 데이터 모델에 맞는 다양한 쿼리 언어를 제공
- 위에서 말한것 처럼, 문서 중심(JSON), 키-값 저장소, 열 군 저장소(CQL- 카산드라 언어), 그래프 데이터베이스(Neo4j 용 Cypher)
NoSQL이 유리한 경우, 불리한 경우는 언제일까?
NoSQL 의 장점
데이터 모델링의 유연성
- 정형, 반정형, 비정형 데이터를 모두 처리할 수 있습니다.
=> 다양한 데이터 유형을 처리하거나 빠르게 진화하는 데이터 모델을 다루는 애플리케이션에 적합!
확장성
- 일반적으로 여러 서버에 걸쳐 분산 및 수평 확장을 사용하여 확장하도록 설계되었습니다.
=> 이는 대규모 애플리케이션과 빅 데이터 요구에 이상적!
성능
- 데이터 모델이 더 단순하고 트랜잭션이 엄격하지 않기 때문에 더 나은 성능을 제공할 수 있습니다.
=> 특정 작업, 특히 대량의 데이터를 처리하거나 단순한 읽기/쓰기 작업을 처리할 때 유리!
다양한 데이터 모델
- 최적화된 다양한 데이터베이스 유형(키-값, 문서, 열-계열, 그래프)을 포함
=> 애플리케이션의 특정 요구사항에 맞는 더 많은 선택지를 제공!
NoSQL 의 단점
표준화 부족
- SQL과 달리, 다양한 NoSQL 데이터베이스에는 표준 쿼리 언어나 통일된 인터페이스가 없습니다.
=> 이로 인해 학습이 어렵고, 상호 운용성에 문제가 생길 수 있습니다.
일관성
- 많은 NoSQL 데이터베이스는 성능과 확장성을 위해 ACID(원자성, 일관성, 격리성, 내구성) 을 포기했다
=> 데이터 일관성이 중요한 애플리케이션에는 적합하지 않을 수 있습니다.
정리
NoSQL을 사용해야 할 때
- 구조가 거의 또는 전혀 없는 대량의 데이터를 처리하거나
- 높은 성능과 확장성을 보장해야 하거나
- 데이터 모델이 빠르게 진화하는 경우.
몽고 DB
장점
- 문서 중심 저장으로 유연성을 제공 => 반정형 데이터 저장
추천용도
- 스키마가 진화하는 애플리케이션, 특히 콘텐츠 관리 시스템
- 전자 상거래 애플리케이션, 모바일 앱과 같이 시간이 지남에 따라 데이터 구조가 변경되는 서비스
레디스
장점
- 메모리 내 데이터 저장으로 인해 속도가 매우 빠릅니다.
- 고성능과 짧은 대기 시간이 필요한 시나리오에 적합합니다.
추천용도
- 캐싱, 세션 관리, 게시/구독 시스템 및 실시간 분석에 가장 적합!
카산드라
장점
- 단일 장애점 없이 고성능을 제공 => 수많은 분산된 서버 전체 간의 대용량의 데이터를 관리
- 쓰기 작업이 많은 로드에 탁월하며 수평 확장을 위한 강력한 지원을 제공합니다.
추천용도
- IoT, 웹 분석, 시계열 데이터 등 성능 저하 없이 확장성과 고가용성이 필요한 애플리케이션에 적합합니다.
Neo4j
장점
- 그래프 기반 모델을 사용하여 복잡한 데이터 네트워크를 저장하고 쿼리하는 데 최적화되어 있습니다.
추천 용도
- 소셜 네트워크, 사기 탐지 시스템, 추천 엔진과 같이 상호 연결된 데이터의 효율적인 표현과 쿼리가 필요한 애플리케이션에 적합
RDBMS를 사용해야 할 때
- 애플리케이션에 복잡한 트랜잭션과 쿼리
- 엄격한 데이터 무결성
- 안정적이고 구조화된 데이터 모델이 필요한 경우.
MySQL
장점
- 강력한 ACID 규정 준수 및 강력한 생태계
추천용도
- 웹 애플리케이션, 전자 상거래 플랫폼 및 온라인 거래 처리 시스템
포스트그레SQL
장점
- 저장 프로시저, 뷰, 트리거 및 정교한 잠금과 같은 고급 기능을 지원
추천용도
- 금융 시스템, 지리공간 데이터베이스, 엔터프라이즈급 애플리케이션과 같이 복잡한 쿼리, 정교한 데이터 유형 및 데이터 무결성이 필요한 애플리케이션에 이상적
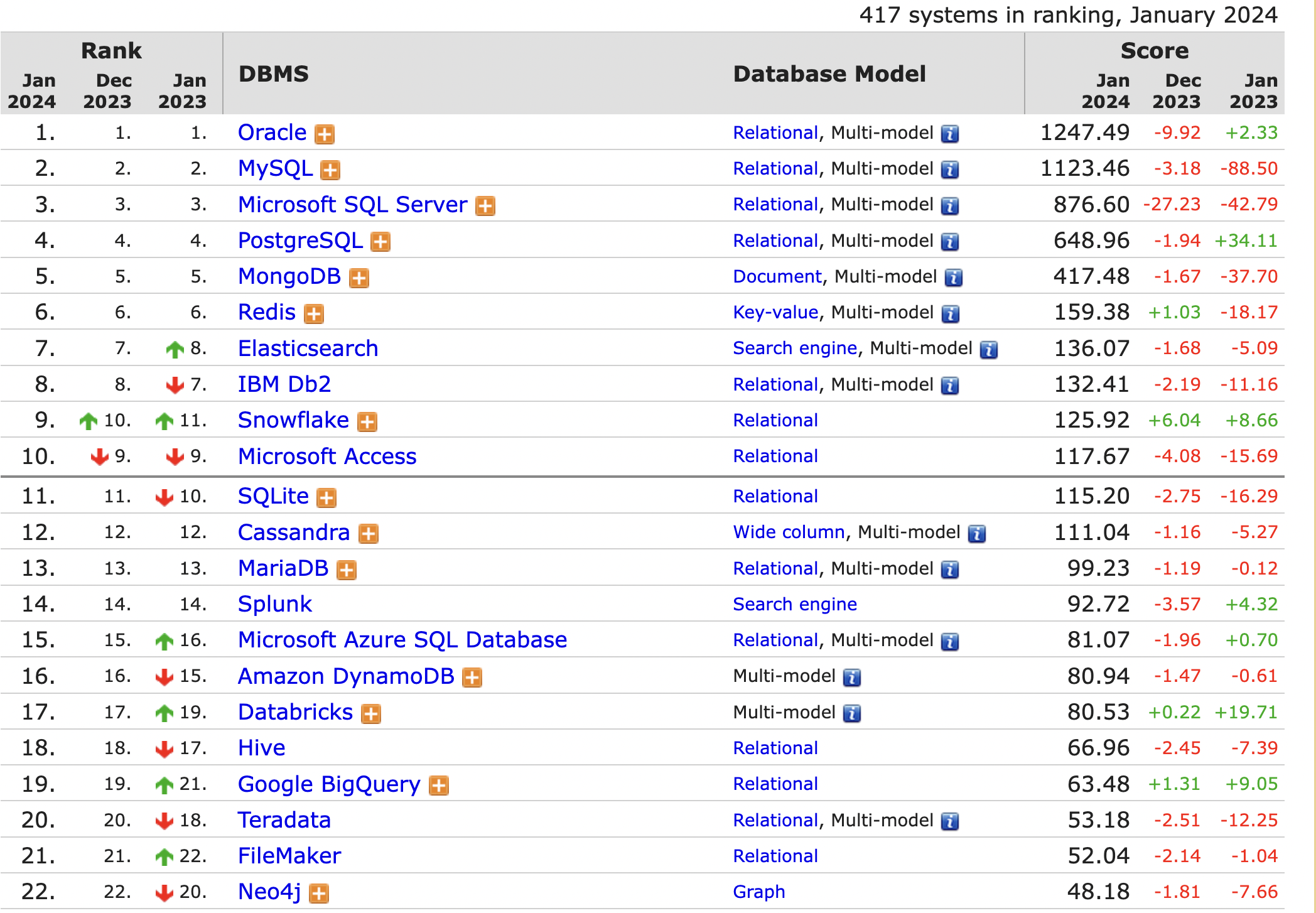
2024 1월기준 전세계 DB 인기도 랭킹 순위
https://db-engines.com/en/ranking