
Manifest Android Interview 책을 읽고 Practical Questions 에 대한 답변을 작성해보고, 카테고리 내에 특정 개념에 대한 딥다이브 및 스터디 시간에 얘기 나누면 좋을 내용들을 적어보는 글입니다.
답변 정리는 LLM의 도움을 받았습니다.
Practical Questions
Q) 59. 장시간 실행되는 백그라운드 작업을 어떻게 관리하는가?
- 장시간 작업(예: 대용량 다운로드)은 포그라운드 서비스(Foreground Service)로 관리
- 앱이 종료되어도 작업 지속, 사용자에게 알림 제공 필수
- WorkManager는 주기적/지연 작업에 적합하지만, 즉시 실행 및 장시간 작업에는 포그라운드 서비스가 더 안정적
Q) Android 앱에서 원격 서버로부터 대용량 파일(수백 MB)을 다운로드하는 기능을 구현해야 합니다. 앱이 종료되더라도 다운로드가 계속되어야 하며, 성능과 네트워크 상태 측면에서 효율적이어야 합니다. WorkManager, 포그라운드 서비스, 또는 JobScheduler 중 어떤 백그라운드 실행 메커니즘을 선택하시겠습니까? 그리고 그 이유는 무엇입니까?
포그라운드 서비스 선택
이유:
- 앱 종료/백그라운드 상태에서도 작업 지속
- 다운로드 진행 상황을 알림으로 표시(필수)
- WorkManager/JobScheduler는 대용량 실시간 다운로드에는 부적합(지연, 제한, 중단 가능성)
- WorkManager는 재부팅 후 재시작 필요 시 보조적으로 사용 가능
Q) 60. JSON 형식을 객체로 어떻게 직렬화하는가?
Q1) API로부터 받은 JSON 응답을 Kotlin 데이터 클래스로 어떻게 역직렬화 하겠는가? Kotlin 우선 프로젝트를 위해 어떤 라이브러리를 선택하고, 그 이유는 무엇인가?
kotlinx.serialization 선택
이유:
-
코틀린 공식 지원 및 언어 친화성: kotlinx.serialization은 JetBrains에서 공식적으로 제공하며, Kotlin의 언어 특성과 기능(예: data class, default parameter, null-safety 등)을 완벽하게 지원
-
코틀린 데이터 클래스의 기본값, null-safety 지원: Gson, Moshi와 달리, 코틀린의 기본값(default value)이나 null-safety를 그대로 반영.
예를 들어, JSON에 없는 필드는 데이터 클래스에 지정된 기본값으로 자동 할당.
-> 이는 런타임 예외를 줄이고, 명확한 타입 안전성을 제공. -
컴파일 타임 코드 생성(Reflection 미사용): 런타임 리플렉션이 아닌 컴파일 타임에 직렬화/역직렬화 코드를 생성하므로, 성능이 우수하고, jar 크기와 시작 시간이 줄어듬. 이는 서버리스 환경이나 성능이 중요한 환경에서 큰 장점.
-
빌드 타임 타입 안전성: 컴파일 시점에 직렬화/역직렬화 로직이 생성되어, 런타임 오류 가능성이 줄어들고, 타입 안정성이 보장됨.
-
멀티플랫폼 지원: Kotlin/JVM, Kotlin/JS, Kotlin/Native 등 다양한 플랫폼에서 동일하게 사용할 수 있음
Q2) Kotlin 데이터 클래스에 정의되지 않은 누락되거나 추가 필드가 있는 JSON 객체를 역직렬화해야 하는 경우, 이 시나리오를 어떻게 처리하겠는가?
누락 필드:
- 데이터 클래스에 기본값 지정(예:
val name: String = "") - nullable 선언(예:
val name: String?)
추가 필드:
- 무시됨(데이터 클래스에 없는 필드는 자동 무시)
- 필요시
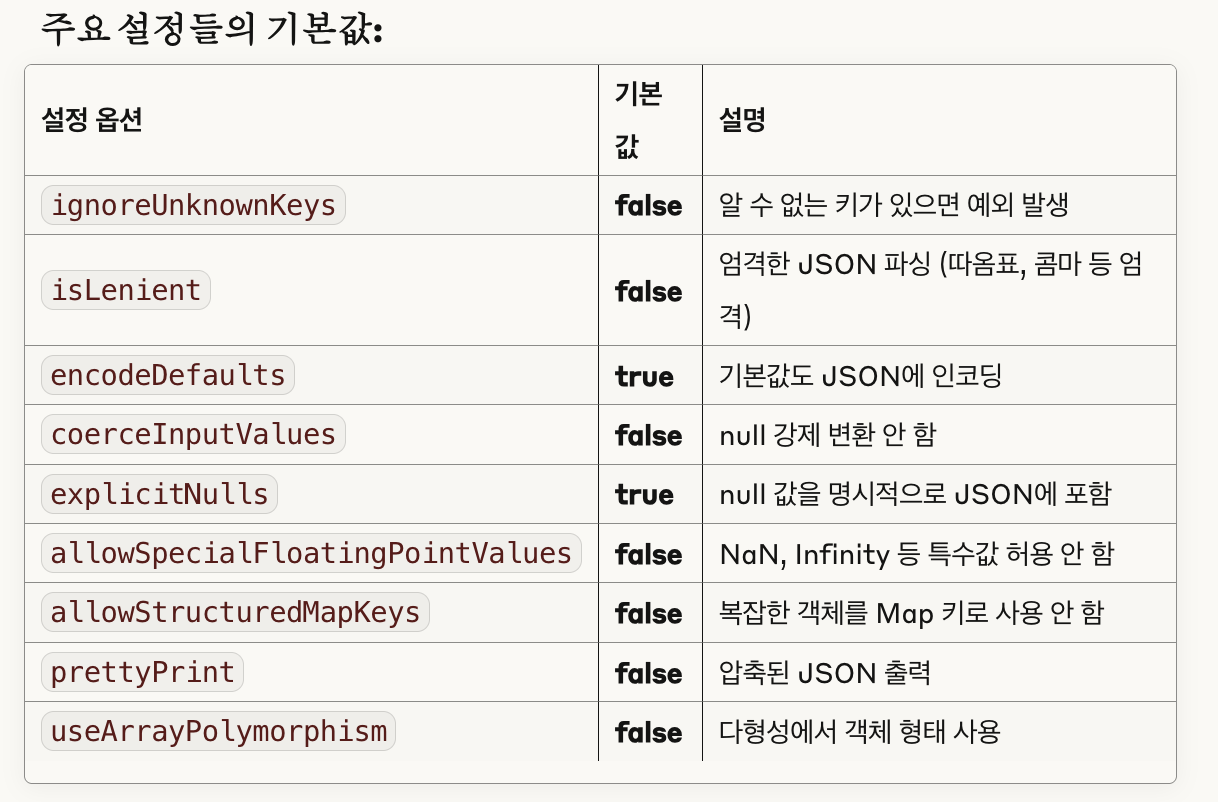
@SerialName,@JsonClass(generateAdapter = true)등으로 매핑 조절 - Json 설정을 통해 동작 제어
val lenientJson = Json {
ignoreUnknownKeys = true // 알 수 없는 키 무시 (기본값: false)
isLenient = true // 느슨한 파싱 허용
encodeDefaults = false // 기본값 인코딩 생략
coerceInputValues = true // null을 기본값으로 강제 변환
}
Q) 61. 데이터를 가져오기 위한 네트워크 요청을 어떻게 처리하고, 효율성과 신뢰성을 위해 어떤 라이브러리나 기술을 사용하는가?
효율적이고 신뢰성 높은 네트워크 요청 처리를 위해 Android에서는 Retrofit과 OkHttp, 그리고 Kotlin Coroutines를 조합하는 것이 표준적
Retrofit은 타입 안전성과 간결한 API 설계, OkHttp는 커넥션 풀링과 HTTP/2 지원 등으로 네트워크 효율을 높여주며, 코루틴은 비동기 처리를 간결하게 만듬.
커넥션 풀링:
네트워크 요청 시 매번 새로운 연결을 생성하는 대신, 미리 만들어진 연결(커넥션)을 재사용하는 기술
- 새로운 연결을 생성하는 오버헤드를 줄여, 요청 지연(latency)을 크게 감소시킴
- 여러 HTTP 요청이 병렬로 발생할 때도 이미 열려 있는 연결을 재사용하여 효율성을 높임
- OkHttp와 같은 클라이언트 라이브러리는 내부적으로 커넥션 풀을 관리하며, 사용이 끝난 연결은 닫지 않고 풀에 반환하여 다음 요청에서 재사용
- 커넥션 풀링을 사용하면 평균 응답 시간이 최대 5배까지 빨라질 수 있음
HTTP/2:
HTTP/2는 HTTP/1.1의 한계를 극복하고 네트워크 효율성을 극대화하기 위해 도입된 프로토콜
-
멀티플렉싱(Multiplexing):
하나의 연결(TCP 커넥션)에서 여러 요청과 응답을 동시에 주고받을 수 있음
HTTP/1.1처럼 요청이 순차적으로 처리되어 병목이 생기는 현상을 제거 -
바이너리 프레이밍(Binary Framing):
데이터를 바이너리로 전송해 파싱 속도와 신뢰성을 높임 -
헤더 압축(Header Compression):
반복적으로 전송되는 HTTP 헤더를 압축해 네트워크 트래픽을 줄이고, 성능을 개선 -
서버 푸시(Server Push):
클라이언트가 요청하기 전에 서버가 미리 필요한 리소스를 전송할 수 있어, 리소스 로딩 속도가 빨라짐 -
스트림 우선순위(Stream Prioritization):
중요한 리소스를 먼저 받을 수 있도록 요청의 우선순위를 지정할 수 있음 -
지속적 연결(Persistent TCP Connection):
페이지가 열려 있는 동안 TCP 연결을 계속 유지해, 여러 리소스 요청을 빠르게 처리 -
보안(Encryption):
HTTP/2는 TLS(암호화)를 기본적으로 지원하여 데이터의 안전한 전송을 보장
Q1) 앱이 여러 개의 동시 API 요청을 하고 UI를 업데이트하기 전에 결과를 결합해야 한다. Retrofit과 코루틴을 사용하여 이를 효율적으로 달성하는 방법은 무엇인가?
동시(병렬) API 요청을 효율적으로 처리하고, 모든 결과를 결합한 후 UI를 업데이트하려면 다음과 같이 구현할 수 있음.
1. CoroutineScope(예: ViewModelScope)에서 launch
2. async 블록으로 각 API 요청을 병렬 실행
3. awaitAll로 모든 결과를 한 번에 수집
4. 결과 결합 후 UI 업데이트
viewModelScope.launch {
val deferred1 = async { api.getUserInfo() }
val deferred2 = async { api.getPosts() }
val deferred3 = async { api.getComments() }
// 모든 요청이 끝날 때까지 대기, 실패 시 예외 발생
val results = awaitAll(deferred1, deferred2, deferred3)
// results는 [userInfo, posts, comments] 형태
// 결과 결합 및 UI 업데이트
updateUi(results[0], results[1], results[2])
}- async는 각 요청을 별도 스레드에서 병렬 실행
- awaitAll은 모든 요청이 끝날 때까지 기다렸다가 결과 리스트를 반환. 하나라도 실패하면 즉시 예외가 발생.
- UI 업데이트는 모든 데이터가 준비된 후 한 번에 처리할 수 있음.
-> 이 방식은 메인스레드 블로킹 없이, 여러 API 요청을 동시에 빠르게 처리하고, 결과를 안전하게 결합할 수 있어 효율적
Q2) API 호출 실패시 어떻게 처리하고 재시도 메커니즘을 구현하겠는가?
API 호출 실패 시 신뢰성을 높이려면, 체계적인 에러 처리와 재시도 로직이 필요
에러 처리:
- Retrofit + 코루틴에서는 try-catch로 네트워크 예외, HTTP 예외 등을 포착할 수 있음.
- Kotlin의
ResultAPI를 활용하면 성공/실패 상태를 명확하게 관리할 수 있음
재시도 메커니즘 (Exponential Backoff):
- 네트워크 불안정 등 일시적 오류에 대해 재시도(특히 지수적 백오프)를 적용하면 신뢰성이 높아짐
- 코루틴에서는
retry연산자(Flow 사용 시) 또는 직접 반복문 + delay로 구현할 수 있음
suspend fun <T> retryWithBackoff(
times: Int = 3,
initialDelay: Long = 1000,
maxDelay: Long = 8000,
factor: Double = 2.0,
block: suspend () -> T
): T {
var currentDelay = initialDelay
repeat(times - 1) {
try {
return block()
} catch (e: IOException) {
// 네트워크 오류만 재시도
}
delay(currentDelay)
currentDelay = (currentDelay * factor).toLong().coerceAtMost(maxDelay)
}
return block() // 마지막 시도
}- 이 함수는 지정 횟수만큼 재시도하며, 실패할 때마다 대기 시간을 지수적으로 늘림
- 실제 API 호출 시
retryWithBackoff { api.getData() }처럼 사용
Q) 62. 대용량 데이터셋 로딩 시 페이징 시스템이 왜 필수적인지, 그리고 RecyclerView와 함께 어떻게 구현할 수 있는지 설명하라.
대용량 데이터셋을 한 번에 모두 로드하면 앱의 메모리 사용량이 급증하고, UI가 느려지거나 심지어 앱이 강제 종료될 수 있음. 페이징 시스템은 데이터를 필요한 만큼만(즉, “페이지” 단위로) 불러오게 하여 네트워크, 메모리, CPU 자원을 효율적으로 사용하게 해줌. Android Jetpack의 Paging 라이브러리는 이러한 페이징을 쉽게 구현할 수 있도록 지원하며, RecyclerView와 자연스럽게 연동됨
Q1) 앱이 API에서 대용량 데이터셋을 가져와 RecyclerView에 표시한다. 원활한 스크롤을 보장하고 메모리 사용량을 줄이기 위해 효율적인 페이징 시스템을 어떻게 구현하겠는가?
효율적인 페이징 시스템 구현 방법 (RecyclerView + Paging):
- Paging 라이브러리 사용: Android Jetpack의 Paging 라이브러리를 활용하면, 대용량 데이터셋을 네트워크 또는 로컬에서 페이지 단위로 불러오고, RecyclerView에 효율적으로 표시할 수 있음.
- PagingSource 구현: API에서 데이터를 페이지 단위로 받아오는 로직을 PagingSource로 구현.
- ViewModel에서 PagingData 스트림 생성: ViewModel에서 PagingData를 Flow 또는 LiveData로 생성.
- PagingDataAdapter 연결: PagingDataAdapter를 구현하여 RecyclerView에 연결하면, 사용자가 스크롤할 때마다 자동으로 다음 페이지를 로드하고, 메모리에 필요한 데이터만 유지.
- 자동 로드 및 캐싱: Paging 라이브러리는 데이터 중복 요청 방지, 인-메모리 캐싱, 에러 처리, 새로고침 및 재시도 등 다양한 기능을 내장하고 있음
예시코드:
val adapter = UserPagingAdapter()
recyclerView.adapter = adapter
lifecycleScope.launch {
viewModel.pagingDataFlow.collectLatest { pagingData ->
adapter.submitData(pagingData)
}
}Q2) RecyclerView와 함께 수동 페이징 시스템을 구현할 때 어떤 문제가 발생할 수 있으며, 원활한 사용자 경험을 제공하기 위해 이러한 문제를 어떻게 완화할 수 있겠는가?
수동 페이징 구현 시 발생할 수 있는 주요 문제점:
- 중복 요청 및 데이터 누락: 스크롤 이벤트와 네트워크 요청 타이밍이 어긋나면 같은 페이지를 여러 번 요청하거나, 일부 데이터가 누락될 수 있음
- 에러 및 재시도 처리 미흡: 네트워크 오류 발생 시 사용자에게 적절히 알리거나 재시도 로직을 구현하지 않으면 UX가 저하됨
- 로딩 상태 관리의 복잡성: 로딩 중, 에러, 빈 데이터 등 다양한 상태를 직접 관리해야 하므로 코드가 복잡해지고 버그가 발생하기 쉬움
- 메모리 관리 어려움: 불필요하게 많은 데이터를 한 번에 메모리에 올릴 수 있어, OutOfMemory 오류 위험이 커짐
- 스크롤 위치 관리: 데이터가 갱신될 때 스크롤 위치가 튀거나, 사용자가 보고 있던 위치를 잃어버릴 수 있음
원활한 사용자 경험을 위한 완화 방안:
- 중복 요청 방지: 요청 중 상태 플래그를 두어, 동일한 페이지가 중복 요청되지 않도록 제어
- 에러 및 재시도 UI 제공: 로딩 실패 시 Snackbar, Toast, 별도의 에러 뷰 등을 통해 사용자에게 안내하고, 재시도 버튼을 제공
- 로딩/빈 상태 UI 관리: 로딩 중에는 ProgressBar, 데이터가 없을 때는 Empty View 등 상태별로 적절한 UI를 제공
- DiffUtil 활용: 데이터 변경 시 전체 리스트를 갱신하지 않고, 변경된 부분만 효율적으로 업데이트하여 스크롤 위치 유지 및 성능을 높임
- 적절한 데이터 캐싱: 이미 불러온 데이터는 메모리나 로컬에 캐싱하여, 불필요한 네트워크 요청을 줄임
- 스크롤 위치 보존: 데이터가 갱신될 때 RecyclerView의 scrollToPosition 등을 활용해 사용자의 위치를 최대한 보존
-> Jetpack Paging 라이브러리를 사용하면 이러한 문제를 대부분 자동으로 관리해주므로, 복잡한 수동 페이징 구현 대신 공식 라이브러리 활용을 권장
Q) 63. 네트워크에서 이미지를 가져와 렌더링하는 방법은?
Q) 앱이 원활한 스크롤을 보장하면서 RecyclerView에서 원격 서버에서 고해상도 이미지를 로드하고 표시해야 한다. 어떤 이미지 로딩 라이브러리를 선택하고, UI 지연을 방지하기 위해 성능을 어떻게 최적화하겠는가?
coil을 선택
이유:
- Kotlin 및 코루틴 친화적: Kotlin 언어와 코루틴에 최적화되어 비동기 이미지 로딩이 간결하고 안전하게 구현됨
- 효율적 캐싱: 메모리와 디스크 캐시를 자동으로 관리해, 동일 이미지의 중복 다운로드를 방지하고 스크롤 시 빠른 재표시가 가능
- 백그라운드 처리: 이미지 다운로드·디코딩이 우선순위가 낮은 백그라운드 스레드에서 이루어져 UI 스레드가 차단되지 않음
- 간편한 API:
ImageView.load(url)한 줄로 비동기 이미지 로딩, 플레이스홀더·에러 이미지 지정, 크기 조정, 변환 등이 가능 - 확장성: 바인딩 어댑터, 커스텀 디코더, 프리로딩 등 다양한 확장 기능을 지원
UI 지연 방지 및 성능 최적화 방법:
- 적절한 이미지 크기 요청: 서버에서 실제 표시 크기에 맞는 이미지를 받아오도록 쿼리 파라미터 또는 Coil의
size()옵션 사용 - 캐싱 전략 활용: Coil의 기본 메모리/디스크 캐시 활용, 필요시 커스텀 캐시 정책 적용
- 에러 및 로딩 상태 UI 제공: placeholder, error 이미지로 사용자 경험 개선
- 프리로딩/스레드 튜닝: 스크롤 예측 프리로딩, ImageLoader의 스레드 풀 크기 조절 등 고급 최적화 가능
- 메모리 관리: 대용량 이미지의 경우 썸네일 사용, 필요시 이미지 압축·리사이즈
Q) 64. 데이터를 로컬에 어떻게 저장하고 유지하는가?
Q) 오프라인 접근을 위해 네트워크 API에서 대용량 JSON 응답을 저장해야 하는 시나리오에서, 어떤 로컬 저장 메커니즘을 사용하고, 그 이유는 무엇인가?
대용량 JSON 데이터를 오프라인 접근을 위해 로컬에 저장해야 하는 경우, Android에서는 Room 데이터베이스를 사용하는 것이 가장 권장됨
Room 데이터베이스를 선택하는 이유:
- 대용량 데이터 처리에 최적화: Room은 SQLite 기반의 ORM 라이브러리로, 수천~수만 건의 데이터도 효율적으로 저장·조회할 수 있음. 단순 파일 저장이나 SharedPreferences는 대용량 데이터 처리에 부적합하며, 메모리/성능 이슈가 발생할 수 있음
- 구조화된 쿼리 및 인덱싱: Room을 사용하면 원하는 조건으로 데이터를 빠르게 검색·정렬할 수 있고, 인덱싱을 통한 조회 성능 최적화가 가능
- 데이터 무결성 및 타입 안전성: 엔티티(Entity)와 DAO(Data Access Object) 구조를 통해 데이터 무결성과 타입 안전성이 보장됨
- LiveData/Flow 연동: Room은 LiveData, Flow 등과 쉽게 연동되어, 데이터 변경 시 UI에 자동 반영이 가능합니다
- 오프라인 캐싱 및 동기화: 네트워크 연결이 끊겼을 때도 Room에 저장된 데이터를 즉시 사용할 수 있어, 오프라인 퍼스트 경험을 제공
대안: 파일 시스템에 JSON 저장
- FileOutputStream 등으로 직접 JSON 파일 저장: 대용량 JSON을 단일 파일로 저장할 수 있지만, 부분 조회나 조건 검색이 어렵고, 데이터 일부만 갱신할 때 비효율적
- 청크 단위 분할 저장: 파일을 여러 조각으로 나눠 비동기 저장하면 메모리 과부하를 줄일 수 있으나, 데이터 일관성·관리 측면에서 Room보다 복잡
Q) 65. 오프라인 우선 기능을 어떻게 처리하는가?
Q1) 네트워크를 사용할 수 없을 때 원활한 사용자 경험을 보장하기 위해 Android 애플리케이션에서 오프라인 우선 기능을 어떻게 설계하겠는가?
오프라인 우선(Offline-first) 앱은 네트워크 연결이 없어도 핵심 기능이 정상적으로 동작하도록 설계되어야 함. 이를 위해 다음과 같은 전략을 적용:
- 로컬 데이터 우선 사용: 앱은 서버 데이터 요청 전, 항상 Room 등 로컬 데이터베이스에 저장된 데이터를 우선적으로 조회·표시. 네트워크 연결이 복구되면 서버에서 최신 데이터를 받아와 로컬 데이터와 동기화.
- 네트워크 상태 감지:
ConnectivityManager등으로 네트워크 연결 상태를 실시간 감지하고, 오프라인일 때는 자동으로 로컬 데이터만 사용하도록 전환. - 데이터 캐싱 및 저장소 패턴: Repository 패턴을 적용하여, 데이터 소스(로컬/원격) 선택 및 데이터 스트림을 관리. Flow, LiveData 등 반응형 API를 활용하면 데이터 변경이 UI에 자동 반영.
- 오프라인 작업 큐: 오프라인 상태에서 발생한 데이터 변경(쓰기, 수정, 삭제 등)은 큐에 저장해두고, 온라인 상태가 되면 서버와 자동 동기화.
- 사용자 경험 개선: 오프라인 상태임을 명확히 안내하고, 캐시된 데이터로도 앱이 자연스럽게 동작하도록 UI/UX를 설계. 예를 들어, 로딩 인디케이터, 오프라인 배지, 동기화 진행상태 표시 등을 제공
Q2) 로컬 Room 데이터베이스 변경 사항을 원격 서버와 동기화하기 위해 어떤 전략을 사용하고, 로컬 및 원격 데이터가 둘 다 수정된 경우 충돌 해결을 어떻게 처리하겠는가?
변경 사항 추적 및 동기화:
- 로컬 데이터 변경(삽입, 수정, 삭제 등)은 별도의 동기화 큐(예: 테이블 또는 메모리 큐)에 기록
- 네트워크가 연결되면 큐에 쌓인 작업을 서버에 순차적으로 전송해 동기화
- 서버에서 변경된 데이터도 주기적으로 내려받아 로컬 데이터와 병합
충돌 해결(Conflict Resolution):
- 타임스탬프 기반 우선순위: 각 레코드에 마지막 수정 시각을 저장하고, 동기화 시점에 더 최신인 데이터를 우선 반영
- 최종 승자 정책(Last Write Wins, LWW): 서버와 클라이언트 모두에서 가장 최근에 수정된 데이터를 남김
- 사용자 개입: 중요한 데이터의 경우, 충돌 시 사용자에게 선택지를 제공해 직접 해결하도록 할 수 있음
- 자동 병합: 단순한 필드(예: 숫자, 카운터 등)는 자동 병합 로직을 적용할 수 있음
동기화 실패/재시도 처리:
- 동기화 중 네트워크 오류가 발생하면, 실패한 작업을 큐에 남겨두고, 네트워크가 복구되면 자동 재시도 수행
- 동기화 상태와 에러를 사용자에게 명확히 안내해 신뢰성을 높임
Q) 66. 초기 데이터 로딩을 위한 작업을 어디에서 시작하나요? LaunchedEffect vs. ViewModel.init()
Q1) Jetpack Compose에서 ViewModel의 init 블록과 LaunchedEffect의 장단점은 무엇이며, 언제 어떤 접근 방식을 선택하겠는가? 다른 대안을 선호한다면, 그것은 무엇인가?
ViewModel.init:
장점: 데이터 로딩이 ViewModel 생성과 동시에 이뤄져 UI와 분리
단점: ViewModel 생성 시점에 부수효과 발생(테스트·디버깅 어려움)
LaunchedEffect:
장점: Composition 진입 시점에 맞춰 데이터 로딩
단점: Composition이 재실행될 때마다 재호출 위험
Lazy Observation
장점: 데이터가 실제로 구독(관찰)될 때만 로딩 시작
단점: 구현 복잡도 증가 가능
공식 문서 및 커뮤니티에서는 ViewModel의 init 블록에서 초기 데이터를 로드하는 것이 일반적이지만, 이는 라이프사이클 불일치, 예기치 않은 부수효과 등으로 인해 최근에는 권장되지 않는 패턴으로 간주되고 있음
LaunchedEffect는 Composition 진입 시점에 맞춰 동작하지만, 키 관리가 미흡하면 불필요하게 여러 번 실행될 수 있어 주의가 필요
Ian Lake(구글 Android Toolkit 팀) 등 전문가들은 두 방식 모두 부수효과(side-effect) 관리에 취약하므로, 실제로 데이터를 구독하는 시점에만 로딩이 시작되는 lazy observation (예: cold Flow, LiveData 구독) 방식을 권장
대안:
-
Cold Flow/Lazy Observation: Flow, LiveData 등 cold stream을 ViewModel에서 제공하고, Composable에서 collectAsState 등으로 구독할 때 데이터 로딩이 시작되도록 설계
-
Navigation Graph 범위 ViewModel: 화면 단위가 아닌 네비게이션 그래프 범위로 ViewModel을 관리하면, 데이터 로딩과 UI 라이프사이클을 더 잘 맞출 수 있음
Q2) 지연 관찰과 cold flows를 사용하는 것이 ViewModel.init() 또는 LaunchedEffect에 비해 초기 데이터를 로드할 때 효율성을 어떻게 향상시키는가? 이 접근 방식이 유익한 예시 시나리오를 제공하라.
Cold Flow(지연 관찰)란?:
Flow, LiveData 등 cold stream은 실제로 구독(collect)되는 시점에만 데이터 로딩(네트워크, DB 등)이 시작됨
즉, ViewModel이 생성되어도 아무도 데이터를 구독하지 않으면, 불필요한 네트워크/DB 작업이 발생하지 않음
효율성 향상 이유:
- 불필요한 작업 방지: 화면이 실제로 표시되지 않거나, 여러 번 재구성될 때마다 중복 데이터 로딩이 발생하지 않음
- 라이프사이클 일치: Composable이 화면에 나타나고 collectAsState 등으로 구독이 시작될 때만 데이터 로딩
- 테스트·유지보수 용이: side-effect가 명확하게 관리되고, 불필요한 초기화 코드가 줄어듦
유익한 예시 시나리오:
- 탭/네비게이션 화면: 여러 탭 중 사용자가 실제로 진입한 탭만 데이터 로딩 필요할 때
- 다이얼로그/바텀시트: ViewModel은 미리 생성되지만, 실제로 다이얼로그가 표시될 때만 데이터 로딩이 필요할 때
- 리스트 상세 화면: 리스트에서 상세로 이동할 때만 상세 데이터 로딩이 필요할 때
예시 코드:
// ViewModel
val userData: Flow<User> = flow {
emit(api.getUser())
}.stateIn(viewModelScope, SharingStarted.WhileSubscribed(5_000), null)
// Composable
val user by viewModel.userData.collectAsStateWithLifecycle()Composable에서 collectAsStateWithLifecycle()가 실행될 때만 Flow가 시작되어 네트워크 요청이 발생
스터디 언급
1. Retrofit vs Ktor

Retrofit/OkHttp와의 차이점 요약
-
간편함/생산성:
Retrofit은 어노테이션 기반으로 API 정의가 쉽고, 일반적인 REST API 연동에 매우 빠르게 적용할 수 있음
반면, Ktor는 더 많은 자유도와 커스터마이즈가 가능하지만, DSL과 코루틴에 대한 이해가 필요해 진입장벽이 다소 높을 수 있음 -
복잡한 네트워크 요구사항:
고도의 커스터마이즈, 멀티플랫폼 지원, 실시간 통신(예:WebSocket) 등 복잡한 네트워크 계층이 필요한 경우 Ktor가 더 적합
단순한 REST API 연동, 빠른 개발에는 Retrofit이 여전히 강점을 가짐
결론
- 선택 기준:
단순/빠른 REST API 연동 → Retrofit
멀티플랫폼 지원, 고도화된 커스터마이즈, 비동기/동시성 극대화 → Ktor
Retrofit과 Ktor의 WebSocket(소켓통신) 구현 비교
Ktor를 사용한 WebSocket 통신 구현이 Retrofit보다 훨씬 쉽고 자연스러움
Retrofit의 한계
- Retrofit은 본질적으로 REST API(HTTP/HTTPS 기반의 요청/응답) 통신을 위해 설계된 라이브러리
- Retrofit 자체에는 WebSocket 지원 기능이 내장되어 있지 않음
- OkHttp가 WebSocket을 지원하지만, Retrofit과의 통합이 공식적으로 제공되지 않으므로, WebSocket을 쓰려면 OkHttp의 하위 레벨 API를 직접 사용해야 함
- 결과적으로, Retrofit 기반 프로젝트에서 WebSocket을 쓰려면 Retrofit과 별개로 OkHttp의 WebSocket API를 직접 다루거나, 추가적인 래퍼 코드를 작성해야 하므로 번거롭고 일관성이 떨어짐
Ktor의 장점
- Ktor는 HTTP뿐만 아니라 WebSocket 프로토콜을 클라이언트와 서버 모두에서 공식적으로 지원
- Ktor Client에서는
ktor-client-websockets플러그인만 추가하면 손쉽게 WebSocket 세션을 열고, 메시지를 주고받을 수 있음 - 코루틴 기반 API로 비동기 메시지 송수신, 연결 유지(ping/pong), 프레임 크기, 직렬화 등 다양한 옵션을 간단하게 설정할 수 있음
- 코드 예시와 공식 문서가 잘 갖추어져 있어, 실시간 통신이 필요한 앱에서 빠르고 일관성 있게 구현할 수 있음
https://ktor.io/docs/client-websockets.html
https://ktor.io/docs/client-websockets.html
2. Paging3 with LazyColumn
Jetpack Compose에서 Paging LoadStateFooter를 구현 하는 방법
3. Load Initial Data
reference)
The ONLY Correct Way to Load Initial Data In Your Android App?
Loading Initial Data in LaunchedEffect vs. ViewModel
Loading Initial Data on Android Part 2: Clear All Your Doubts
위의 skydoves 님 글 번역글
[Android] 초기 데이터 로드 : LaunchedEffect vs ViewModel
[Android] 초기 데이터 로드 2 : 의문점 해소하기
