페이징 기능
보통 게시판 구현에서 많이 사용하는 페이징 기능은 크게 다음과 같은 요소로 구성된다
- 한 페이지 당 몇 개의 자료를 담을지 (size)
- 조회하려는 페이지가 몇 번째 페이지인지 (page)
- 조회하려는 자료가 전체 몇 페이지로 구성되어 있는지 (totalPages)
- 해당 페이지에 다음 페이지가 존재하는지 (hasNext 또는 last)
- 자료를 정렬하는 기준 필드와 방법 (sorted, ASC 또는 DESC)
여기서 RDBMS, NoSQL을 가리지 않고 기본적으로 페이징 시 사용되는 쿼리들은 skip(), limit()이며 한 size와 page를 기준으로 skip(), limit()를 하여 조회하려는 페이지의 첫번째 자료 이전까지의 자료를 전부 skip하고, 그 페이지의 마지막 자료까지 조회를 limit()로 제한하는 방식으로 처리된다.
Spring Data 프로젝트에서는
Spring Data 프로젝트에서는 이를 쉽게 구현할 수 있게 Page 자료형을 제공하고 있으며 쿼리 파라미터로 페이징에 필요한 요소들을 담은 Pageable을 전달하면 Page 자료형으로 객체를 전달받을 수 있다.
// 예시 : List로 반환
List<TestEntity> findByAll();
// 예시 : Page로 반환
Page<TestEntity> findByAll(Pageable pageable);
그리고 이러한 Page 자료형을 DTO 등으로 매핑해서 REST API로 조회해보면 다음과 같은 형태가 된다. 여기서 페이징 조건은 파라미터로 page, size 등을 전달할 수 있다.
@RequiredArgsConstructor
@RestController
public class TestController {
private final TestEntityRepository repository;
@GetMapping("/test")
public Page<TestEntityDTO> findAll(@PageableDefault Pageable pageable) {
Page<TestEntity> entities = repository.findAll(pageable);
return entities.map(TestEntityDTO::fromEntity);
}
}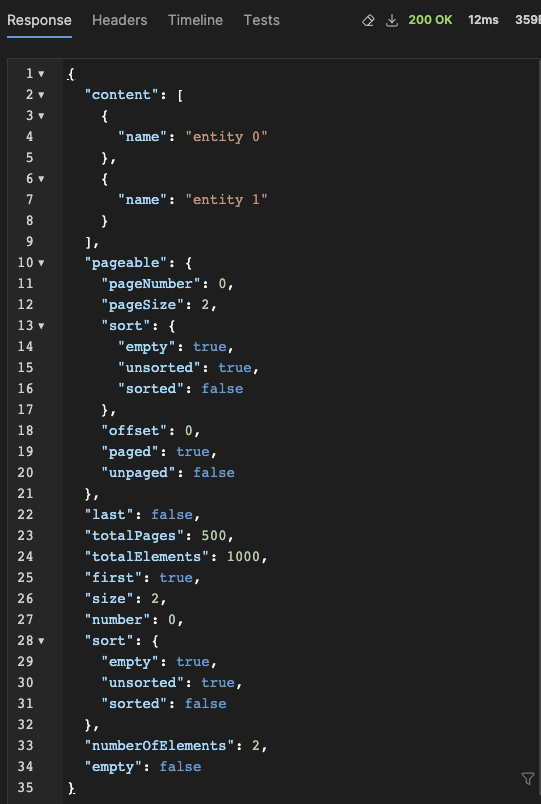
위의 예시에서는 page를 0으로 (주의 : Pageable에서 첫번째 페이지는 1이 아닌 0이다) size를 2로 전달했을 때의 응답이며 content에는 조회된 엔티티를 DTO로 매핑한 것들이 담기고 그 위 pageable과 페이지 관련 정보 필드가 담겨있는 것을 볼 수 있다.

참고로 totalPages, totalElements를 계산하기 위해선 결국 페이징을 처리하지 않은 검색 대상의 엔티티 수를 계산해야 하기 때문에 count() 쿼리가 추가로 들어가며 debug log 상에서도 executing count로 찍히는 것을 볼 수 있다.
프론트엔드 측에서 페이지네이션을 할 때 totalPages, totalElements가 필요한 경우라면 Page 기본 구현을 그대로 사용해도 되겠으나, 그렇지 않은 경우라면 조금의 성능 향상을 위해서 count를 제외하고 skip, limit만 사용하는 쿼리 메서드를 구현하는 것이 좋을 듯 하다.
그 밖에도 사용자 측으로 페이징 조건을 받을 때 정렬 조건 필드와 정렬 방식도 지정이 가능하지만 생략하였다.
Spring Data 프로젝트의 Page 기능은 상당히 간편해서 이전부터 많이 써왔기 때문에 어려운 부분은 없다.
MongoEngine에서는?
새로 진행 중인 프로젝트가 Flask + MongoEngine 기반인데 Spring Data의 Page, Pageable과 같은 기능이 없기 때문에 직접 Flask에서 파라미터를 받고 MongoEngine에서 skip(), limit()를 사용하는 방식으로 진행했다.
(공식 문서에서는 skip, limit 외에 object 내에 배열 분할을 사용하는 방법을 권장하고 있긴 하다)
@app.route('/test', methods=['GET'])
def test():
page = int(request.args.get('page', 1))
size = int(request.args.get('size', 10))
skip = (page - 1) * size
limit = size
# skip, limit를 사용
result = TestEntity.objects().skip(skip).limit(limit)
# 배열 분할을 사용
# result = TestEntity.objects[skip:skip+limit]
total_elements = TestEntity.objects().count()
schema = TestEntityDTO(many=True)
return jsonify(content=schema.dump(result),
total_pages=total_elements / size,
total_elements=total_elements)Spring Data의 Pageable과의 차이점이라면 Page를 0부터 받느냐 1부터 받느냐 사용자의 구현에 따라 마음대로 할 수 있다는 점? 파라미터 이름도 바꿀 수 있고. (사실 동일하게 맞추고 싶다면 skip 부분의 처리를 바꾸면 그만이지만...)
정렬 기능도 request.args로 정렬이 될 대상, 정렬 기준을 받아서 order_by()에 적용하면 된다.
페이징 자체는 사실 실제 구현 원리만 알면 크게 어려운 것은 없기 때문에 빠르게 구현할 수 있었다.
다만 페이지 정보에 대해 별다른 작업을 하지 않아도 되는 Page와는 다르게 jsonify 등으로 응답을 반환할 때 유틸 클래스 등을 써서 페이지 정보를 같이 반환하게끔 처리를 해줘야 하는 번거로움이 있다.
