1. 문제 상황
개발 환경 노드가 일정 주기로 NotReady가 되기 시작했다
NHN Cloud의 NKS를 사용해서 개발 환경 쿠버네티스 클러스터를 구축한 뒤 Grafana로 노드별 메트릭을 확인하고 노드가 NotReady 상태가 되면 Alert이 Slack에 전달되게 세팅했었다.
그 뒤로 마이크로서비스가 배포되어 있는 노드에 문제가 생기는 경우가 종종 있었는데 주기를 확인해보니 3주~1달 간격으로 발생하고 있었고, 이전까지는 인프라 말고도 여러 영역에 걸쳐서 일이 많았다보니 신경을 쓰지 못했었던 것을 깨닫고 본격적으로 문제를 해결하기 위해 원인을 확인했다.
2. 원인 확인
노드에 메모리 누수가 발생하고 있었다
가장 먼저 NHN Cloud에서 제공하는 System Monitoring 기능으로 문제가 발생한 노드의 3개월간 데이터를 확인했다. 문제가 발생한 주기랑 동일하게 메모리가 계속해서 누적되고 메모리 프레셔가 발생하고 있었다.
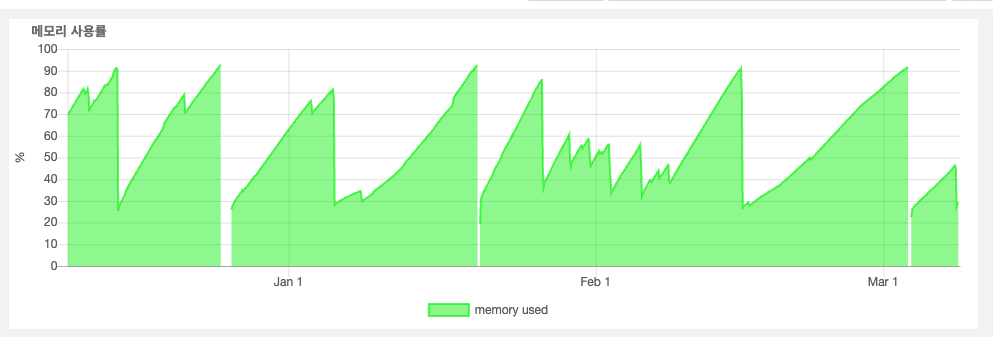
여기서 당황했던 점은 문제가 발생한 노드 내의 마이크로서비스의 메트릭을 Grafana로 주기적으로 확인하고 있었는데 정작 메트릭을 확인해보면 메모리가 누수되는 부분이 딱히 관찰이 되지 않았다는 점이다. 내가 모르는 영역에서 메모리 누수가 발생하고 있었던 것이다.
Grafana로 Pod별 메트릭을 확인해보니
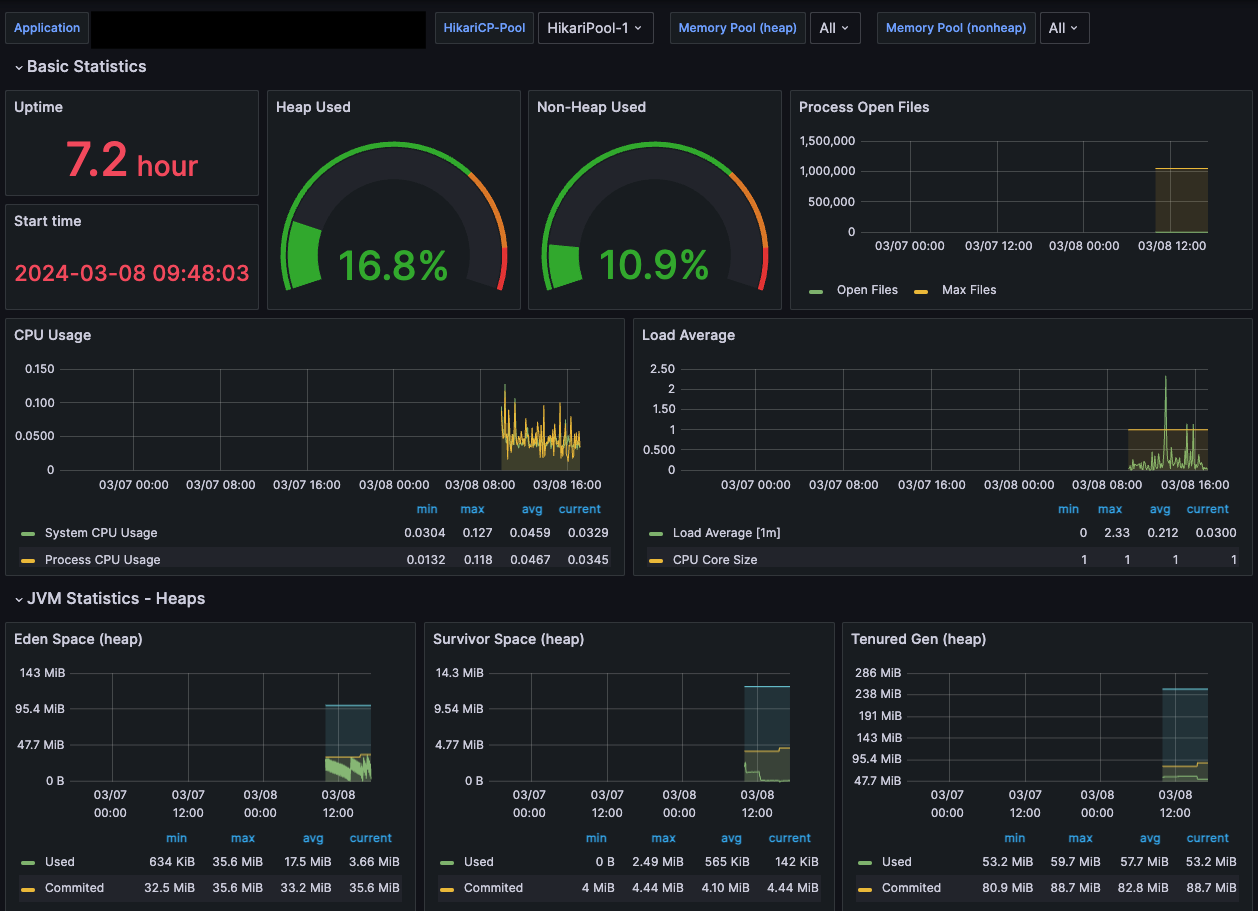
Pod별 메트릭을 확인해보니 Flask, Spring Boot 기반 마이크로서비스 Pod 중 Spring Boot 기반에서만 메모리 누수가 발생하고 있었다.
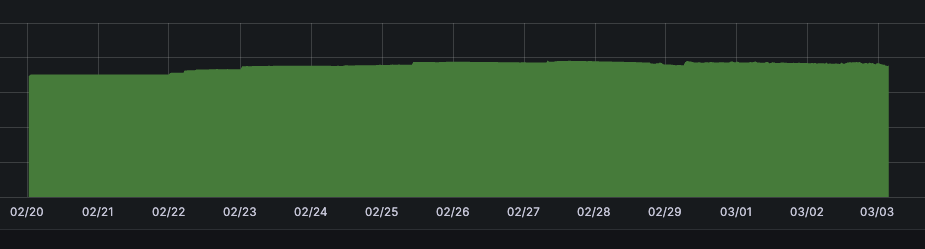
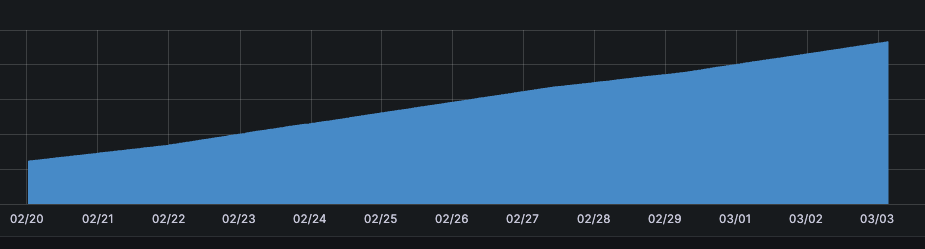
하지만 위에서 이야기했던 것처럼 마이크로서비스 메트릭을 Grafana 대시보드로 주기적으로 관찰했지만 힙 영역을 비롯하여 딱히 문제가 되는 점이 관찰되지 않았기에 어디서 누수가 발생하고 있는지 바로 와닿지 않았다
메모리 덤프를 하고 분석을 해보았는데
문제가 발생하는 마이크로서비스 Pod 중 하나의 내부로 접근하여 메모리 덤프 파일을 생성한 후 끄집어 낸 뒤 Eclipse Memory Analyzer를 사용해보았다.
# pod 내에 접근
kubectl exec --stdin --tty <pod 이름> -n <pod 네임스페이스> -- /bin/bash
# JVM 내 프로세스 ID 확인
jps
# 메모리 덤프
jmap -dump:live,format=b,file=<덤프 파일 이름>.bin <프로세스 ID>
# exit 후 마스터 노드에서 pod 내 덤프 파일 복사하기
kubectl cp <pod 네임스페이스>/<pod 이름>:/usr/src/<덤프 파일 이름>.bin /<마스터 노드 경로>/<덤프 파일 이름>.bin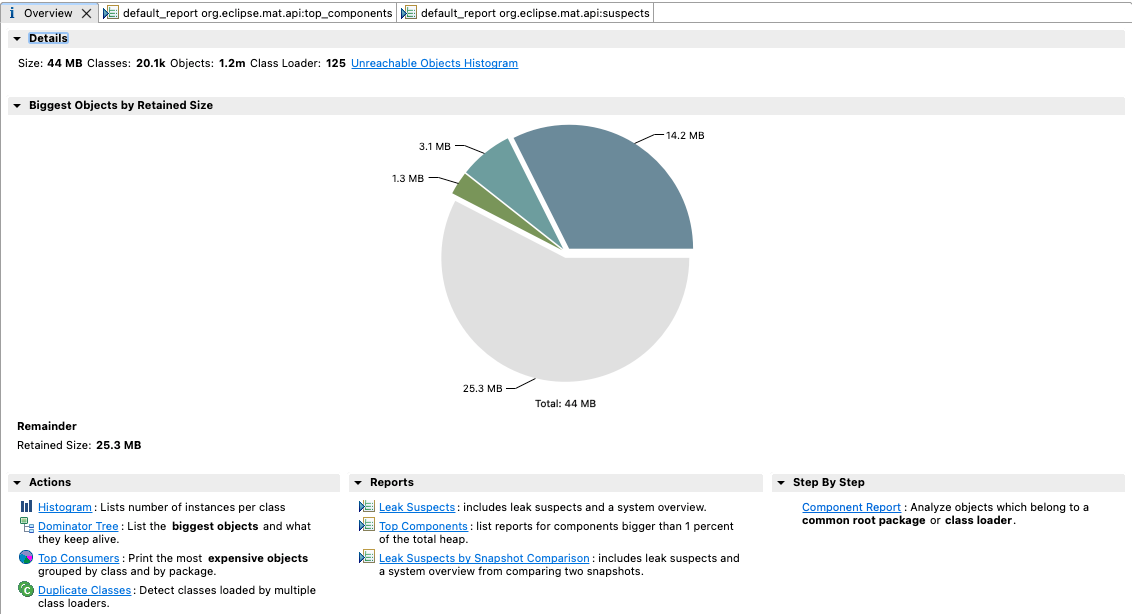
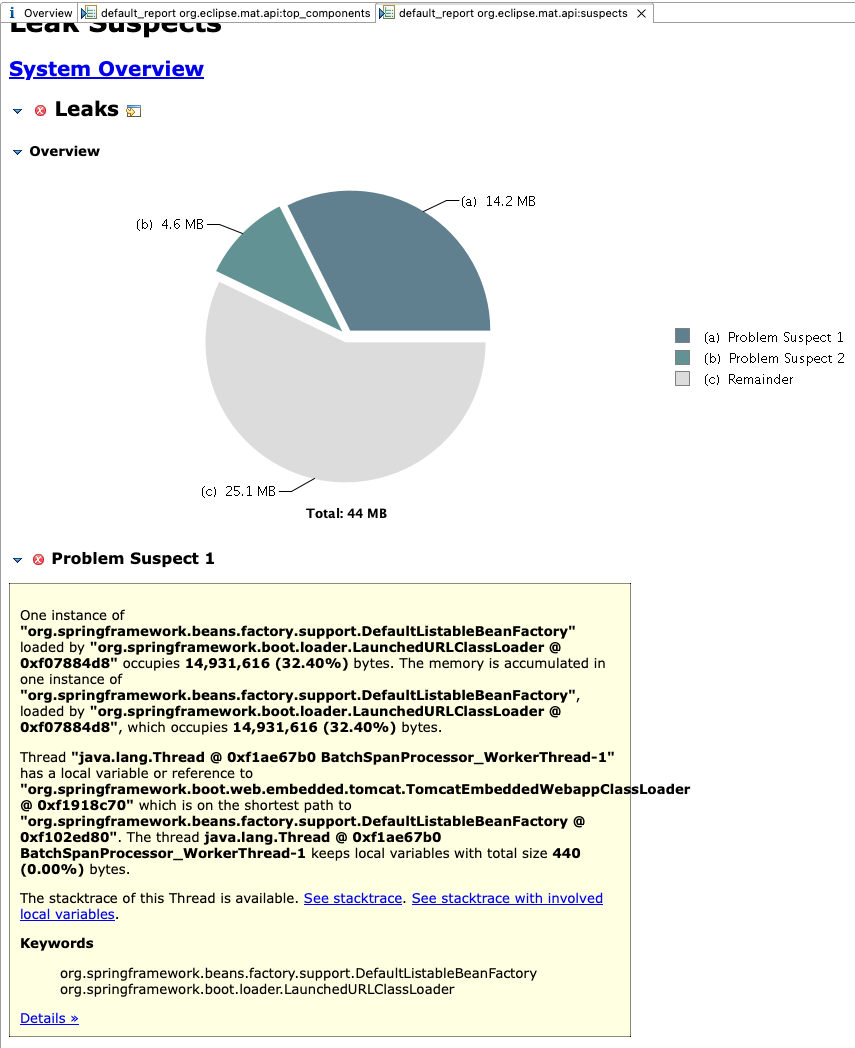
Reports에서 Leak Suspects를 체크하였는데 BatchSpanProcessor에서 메모리 누수가 발생할 우려가 있다는 분석 결과가 나왔으나 실제 사이즈는 400 byte로 굉장히 미미한 편이었다. (찾아보니 OpenTelemtry, Micrometer 관련 설정의 이슈로 추측된다. 마침 마이크로서비스 모두 Jaeger에 분산 추적 정보를 넘기기 위해 OpenTelemetry 관련 설정을 해둔 참이었다.)
메모리 덤프를 하고도 특별한 문제점을 확인하지 못했고 Grafana 대시보드에서 관찰되는 메트릭으로도 특별한 문제점을 찾지 못해 일단 마이크로서비스 자체에는 문제가 없다고 판단하여 또 다른 대시보드를 확인하였다.
Fluentbit를 확인해보니
마이크로서비스 Pod에는 사이드카로 로그 수집을 위한 Fluentbit를 같이 배포하고 있었는데, Pod 대시보드에서는 마이크로서비스 컨테이너와 Fluentbit가 하나로 합쳐서 노출이 되고 있던 걸 보고 아차 싶어서 다른 대시보드를 확인했는데...

확인해보니 문제가 발생하고 있던 마이크로서비스들 모두 마이크로서비스가 아닌, Fluentbit에서 메모리 누수가 발생하고 있었다. 그런데 희한한 점은 Flask, Spring Boot를 가리지 않고 모든 Fluentbit의 설정이 동일했었는데 왜 Spring Boot 기반 마이크로서비스에서만 문제가 있냐는 것이었는데 혹시나 싶어서 ArgoCD를 통해 Fluentbit의 로그를 확인했더니
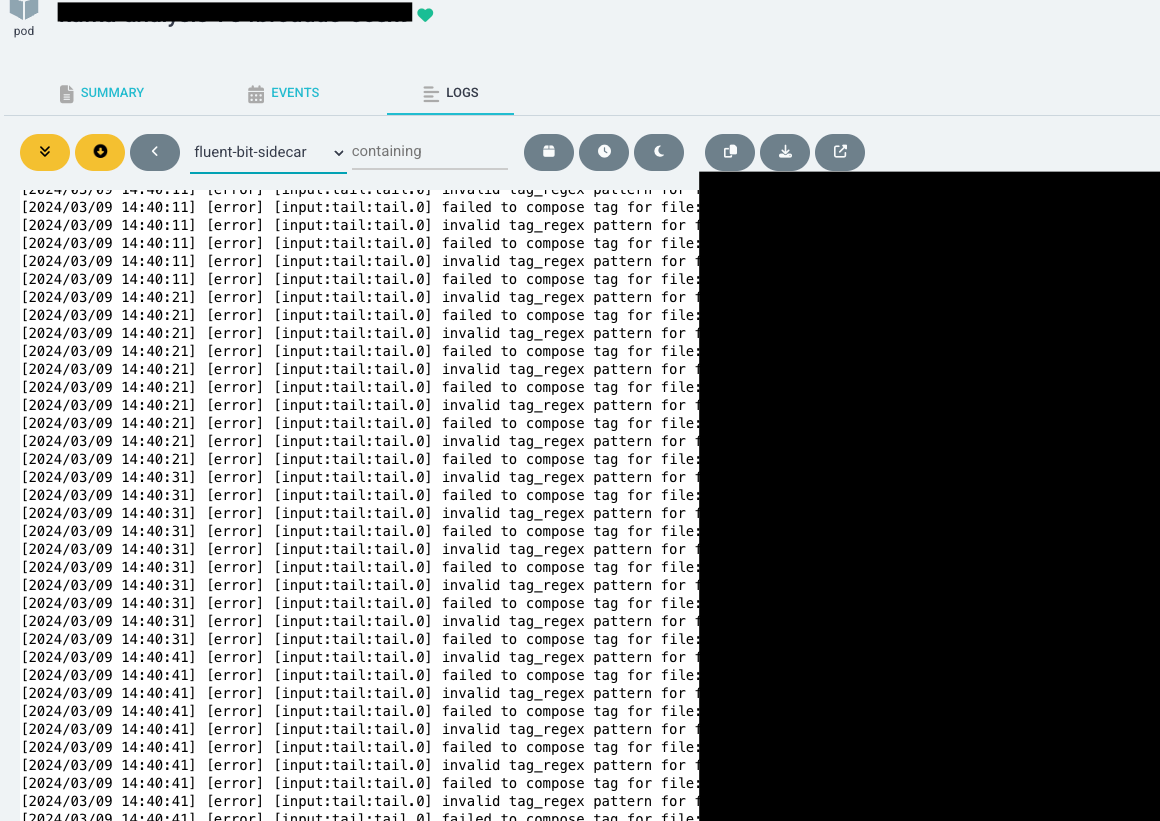
알고 보니 INPUT 단계의 Tag_Regex 부분 정규식 오류로 파일을 제대로 파싱하지 못하고 있었고 이에 대한 에러 로그와 함께 메모리가 계속 누적되고 있었던 것이었다...
정작 Fluentbit에서 Tag_Regex에서 오류가 있었음에도 다른 단계에서 정상적으로 파싱을 진행했고, 이를 Fluentd로 넘겨주어 결과만 놓고 보면 로그는 정상적으로 Elasticsearch에 적재되고 있었기 때문에 이러한 에러가 발생하고 있는지 모르고 있었다. (심지어 Fluentbit 내부의 로그 설정을 debug로 해놨었기 때문에 저 에러 로그 말고도 무수한 로그가 있었어서 저 에러 로그가 묻히고 있었다.)
3. 대응
문제가 되던 Tag_Regex 부분의 정규식을 변경하였고 재배포를 진행하였다.

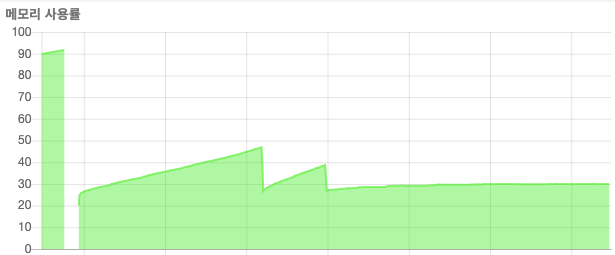
예상대로 더 이상 메모리 누수는 발생하지 않았고 Fluentbit의 메모리도 일정 수준으로 유지가 되고 있었다. (물론 노드 전체 메모리 상태를 볼 경우 조금씩 미미하게 메모리가 쌓이고 줄어들고를 반복하고 있는 상황이지만 추가적인 메모리 덤프나 노드 리소스 관찰 등으로 계속해서 지켜볼 계획이다)
4. 느낀점
처음으로 겪어보는 메모리 누수 문제였기 때문에 많은 자료들을 찾아봤는데 누수가 발생하는 원인이 워낙 다양했다보니 어떻게 해결해야하는지보다는 어느 영역에서 문제가 발생하고 있는지를 찾는 것이 중요했다.
사실 Grafana 대시보드를 볼 때 Pod 내부의 컨테이너의 리소스까지 같이 볼 수 있는 것이 있었는데 이를 놓치지 않았다면 더 빨리 문제를 확인할 수 있지 않았을까 하는 아쉬움이 있다.
그래도 이런 삽질이 있었기 때문에 메모리 덤프도 해보고 이것저것 찾아보게 되는 계기가 되었다.
그리고 가장 다행인 점은 운영 환경으로 넘어가기 전에 이런 문제를 찾았다는 것...
물론 운영 환경은 개발 환경보다 더 변수가 많기 때문에 무수한 이유로 메모리 누수를 비롯해 많은 이슈가 발생하겠지만 어플리케이션 개발이 아닌 어플리케이션, 인프라 운영 / 관리 시 문제가 발생했을 때 어떻게 접근해야 하는지 조금이라도 맛보기를 해봐서 다행인 것 같다.
