
1. 개요
스키마 모델링과 연관관계
작년부터 주요 프로젝트를 MongoDB로 개발해오면서 RDB 기반 스키마 모델링과 MongoDB 기반 스키마 모델링의 차이 때문에 많은 고민을 하고 있다.
MongoDB의 공식 문서에서 스키마 모델링 시 내장된 데이터(Embedded Data)와 참조(References) 2가지가 어떤 차이가 있고 어떤 상황에서 사용해야 하는지 자세히 설명하고 있는데, 일대다 또는 다대일 관계의 경우 내장된 데이터를 사용하면 상당히 편하게 사용할 수 있겠으나 연관관계가 있는 두 도큐먼트의 데이터가 별도로 보관이 되어야 하거나 백업이 필요한 경우라면 무작정 내장된 데이터 형식으로 쓰지 못하거나, 아니면 외부 도큐먼트 삭제 시 내장된 도큐먼트들을 백업하는 별도의 프로세스가 필요하다.
@Document
public class TestEntity {
@Id
private String id;
// TestEntity와 TestEmbeddedEntity가 일대다 연관관계일 경우 임베디드 방식을 사용
// TestEntity가 삭제될 경우 TestEmbeddedEntity도 같이 삭제된다
private List<TestEmbeddedEntity> embeddedEntities = new ArrayList<>();
...
}
// TestEntity 내에 내장될 엔티티
// 별도의 컬렉션이 아니라 TestEntity 컬렉션 내에 저장이 된다
public class TestEmbeddedEntity {
@Id
private String id;
...
}또는 두 데이터가 다대다 관계를 가지고 있다면 단순히 내장된 데이터를 사용하기가 어려운 만큼 참조를 사용하거나, 아니면 두 데이터를 참조할 수 있는 고유 필드를 통해 어플리케이션에서 직접 처리를 해야만 경우가 생기는데 첫번째 프로젝트는 대부분 내장된 데이터로 해결하였으나 이후의 프로젝트는 내장된 데이터를 적극적으로 사용할 수 없는 상황이 더 많아 고민이 더욱 깊어지게 되었다.
어떤 방법이 나은지 궁금하다
이야기가 길어졌는데 궁금한 것은 이것이다.
- @DBRef, @DocumentReference와 같이 도큐먼트 참조를 사용하여 일대다 또는 다대일 관계를 매핑하고 조회하는 것이 좋은지
- 아니면 지금껏 해왔던 방식대로 연관관계에 있는 도큐먼트 간에 참조를 할 수 있는 별도의 필드를 추가해 이를 통해 어플리케이션에서 두 도큐먼트를 쿼리하고 조합하는 방식이 좋은지
사실 대부분의 레퍼런스에서는 @DBRef, @DocumentReference 방식은 조회 성능 관련으로 자주 사용하지 않는 경우가 많아 보여서 후자의 방법으로 개발을 해왔었는데, 직접 적용은 해본 적이 없어서 얼마나 차이가 나고 복잡한지를 확인해보고 싶다.
2. @DBRef, @DocumentReference
개요
@DBRef는 Spring Data MongoDB에서 제공하는 어노테이션으로, 참조 관계를 나타낸다. JPA로 치자면 @ManyToOne, @OneToMany 등의 역할을 한다고 보면 된다.
@DBRef의 경우 기본적으로 참조되는 객체의 실제 데이터가 아니라 해당 객체가 저장된 컬렉션의 _id가 저장되며, 이를 통해 다른 객체와의 참조 관계를 유지할 수 있다.
@DocumentReference는 @DBRef와 목적은 동일하나, 저장되는 형식이 _id로 고정되는 것이 아니며, 도큐먼트 형식으로 저장이 된다. 이러한 형식은 @WritingConverter를 사용하여 매핑되는 형식을 지정할 수 있다.
사용 예시
도큐먼트에서 참조하려는 도큐먼트의 클래스를 필드로 선언하고 @DocumentReference 어노테이션을 지정한 후 바라보는 필드를 지정할 수 있다.
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Document(collection = "test_entity_b")
public class TestEntityB {
@Id
private String id;
@Indexed
private Long tid;
private String name;
@DocumentReference(lookup = "{'teid':?#{teid}}")
private List<TestEmbeddedEntityB> testEmbeddedEntitiesBs = new ArrayList<>();
...
}그리고 Spring의 Converter 인터페이스를 구현한 클래스를 만든 후 @WritingConverter 어노테이션을 지정하면서 참조가 되는 도큐먼트를 변환시킬 수 있다.
@WritingConverter
public class TestEmbeddedEntityBReferenceConverter implements Converter<TestEmbeddedEntityB, DocumentPointer<Document>> {
@Override
public DocumentPointer<Document> convert(TestEmbeddedEntityB source) {
return () -> new Document("teid", source.getTeid()).append("name", source.getName());
}
}여기서 TestEntityB의 실제 구조를 확인하면 다음과 같다.
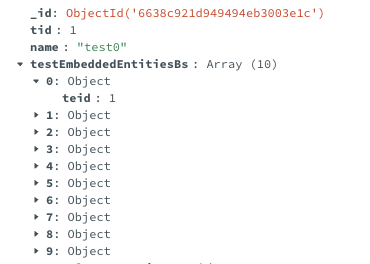
Spring Data JPA에서는 일대다 또는 일대일, 다대일 연관관계 매핑의 방법에 따라 어노테이션을 다르게 부착할 수 있지만 Spring Data MongoDB의 경우 @DocumentReference 어노테이션 하나로 처리가 가능하며, 참조하는 쪽에서 어노테이션을 붙이기만 하면 되기 때문에 단방향, 양방향 매핑도 어노테이션 하나로 처리할 수 있다.
이 부분은 Spring Data JPA를 다뤄본 사람들이라면 금방 적응할 수 있으리라 생각된다.
(만약 아니라면 뒤에 소개할 레퍼런스에 나온 Spring 공식 문서와 가이드를 참고하면 도움이 될 것이다.)
3. 예제 코드
@DocumentReference에 대한 소개를 마쳤으니 본격적으로 예제 코드와 함께 성능 및 용이성을 비교해보고자 한다.
상황은 다음과 같다.
- 테스트 엔티티 (A, B)는 각각 테스트 참조 엔티티와 일대일 양방향, 테스트 내장 엔티티 일대다, 다대일 양방향 연관관계를 가지고 있다.
- 테스트 엔티티는 10000개, 참조 엔티티는 10000개, 내장 엔티티는 100000개를 생성하며 내장 엔티티는 엔티티 1개 당 10개씩 연관관계가 맺어진다.
- 테스트 엔티티 A와 관련 엔티티들은
@DocumentReference를 사용하지 않고 연관관계를 가지고 있는 엔티티의 시퀀스 번호(tid, trid, teid)를 필드로 가지고 있으며, 어플리케이션에서는 연관관계가 있는 엔티티들을 통해 데이터를 반환해야 할 때 이 필드들을 통해 모든 도큐먼트들을 조회한 후 그룹핑하고 매핑한다. - 테스트 엔티티 B와 관련 엔티티들은
@DocumentReference를 사용하여 서로 참조하고 있으며, 어플리케이션에서는 연관관계가 있는 엔티티들을 통해 데이터를 반환해야 할 때 중심이 되는 도큐먼트만 조회한 후 매핑한다.
A 코드
엔티티
위에서 설명한대로 각 엔티티들은 참조하고 있는 엔티티의 시퀀스 번호를 필드로 가지고 있다.
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Document(collection = "test_entity_a")
public class TestEntityA {
@Id
private String id;
@Indexed
private Long tid;
private String name;
private List<Long> teid = new ArrayList<>();
@Indexed
private Long trid;
private TestEntityA(Long tid, String name) {
this.tid = tid;
this.name = name;
}
public static TestEntityA of(Long tid, String name) {
return new TestEntityA(tid, name);
}
public void addTeid(Long teid) {
this.teid.add(teid);
}
public void updateTrid(Long trid) {
this.trid = trid;
}
}
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Document(collection = "test_embedded_entity_a")
public class TestEmbeddedEntityA {
@Id
private String id;
@Indexed
private Long teid;
private String name;
@Indexed
private Long tid;
private TestEmbeddedEntityA(Long teid, Long tid, String name) {
this.teid = teid;
this.name = name;
this.tid = tid;
}
public static TestEmbeddedEntityA of(Long teid, Long tid, String name) {
return new TestEmbeddedEntityA(teid, tid, name);
}
}
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Document(collection = "test_reference_entity_a")
public class TestReferenceEntityA {
@Id
private String id;
@Indexed
private Long trid;
@Indexed
private Long tid;
private String name;
private TestReferenceEntityA(Long trid, Long tid, String name) {
this.trid = trid;
this.tid = tid;
this.name = name;
}
public static TestReferenceEntityA of(Long trid, Long tid, String name) {
return new TestReferenceEntityA(trid, tid, name);
}
public void updateName(String name) {
this.name = name;
}
}서비스
연관관계가 있는 엔티티끼리 그룹핑해야 할 경우 엔티티 내에 있는 참조하고 있는 엔티티의 시퀀스 번호를 활용하여 필요한 엔티티들을 조회한 후 Stream API 등으로 집계, 필터링을 하여 매핑한다.
@Slf4j
@RequiredArgsConstructor
@Transactional(readOnly = true)
@Service
public class TestService {
private final TestFacadeRepository repository;
private final SequenceGenerator generator;
// 엔티티 A DTO 단건 조회
public TestEntityADTO getTestEntityA(Long tid) {
// 엔티티 A 단건 조회
TestEntityA entityA = repository.getTestEntityA(tid);
// 엔티티 A 연관 엔티티 단건 조회
TestReferenceEntityA referenceEntityA = repository.getTestReferenceEntityA(entityA.getTrid());
// 엔티티 A 내장 엔티티 목록 조회
List<TestEmbeddedEntityA> testEmbeddedEntityAs = repository.getTestEmbeddedEntitiesAs(tid);
// DTO 매핑 후 반환
return TestEntityADTO.fromEntity(entityA, testEmbeddedEntityAs, referenceEntityA);
}
// 엔티티 A DTO 페이지 조회
public Page<TestEntityADTO> getTestEntitiesAs(Pageable pageable) {
// 테스트 엔티티 A 페이지 조회
Page<TestEntityA> testEntities = repository.findAllTestEntitiesAs(pageable);
// 엔티티 A의 tid 리스트 생성
List<Long> targetTids = testEntities.stream().map(TestEntityA::getTid).toList();
// tid 필드가 tid 리스트에 포함되는 엔티티 A 참조 엔티티 목록 조회
List<TestReferenceEntityA> testReferenceEntities = repository.getTestReferenceEntitiesAsOfTestEntities(targetTids);
// trid(엔티티 A 참조 엔티티의 시퀀스 번호) : 엔티티 A 참조 엔티티 맵 생성
Map<Long, TestReferenceEntityA> testReferenceEntityAMap = testReferenceEntities.stream()
.collect(Collectors.toMap(TestReferenceEntityA::getTid, Function.identity()));
// tid 필드가 tid 리스트에 포함되는 엔티티 A 내장 엔티티 목록 조회
List<TestEmbeddedEntityA> testEmbeddedEntities = repository.getTestEmbeddedEntitiesAsOfTestEntitiesAs(targetTids);
// tid(엔티티 A의 시퀀스 번호) : 엔티티 A 내장 엔티티 리스트 맵 생성
Map<Long, List<TestEmbeddedEntityA>> testEmbeddedEntitiyAListMap = testEmbeddedEntities.stream()
.collect(Collectors.groupingBy(TestEmbeddedEntityA::getTid));
return testEntities.map(entityA -> {
TestReferenceEntityA testReferenceEntityA = testReferenceEntityAMap.get(entityA.getTid());
List<TestEmbeddedEntityA> testEmbeddedEntityAS = testEmbeddedEntitiyAListMap.get(entityA.getTid());
return TestEntityADTO.fromEntity(entityA, testEmbeddedEntityAS, testReferenceEntityA);
});
}
}DTO
연관관계가 있는 엔티티들을 모두 받아서 매핑한다.
@Getter
@Builder
public class TestEntityADTO {
private Long tid;
private String name;
private List<TestEmbeddedEntityADTO> embeddedEntityDTOS;
private TestReferenceEntityADTO referenceEntityDTO;
public static TestEntityADTO fromEntity(TestEntityA entityA, List<TestEmbeddedEntityA> testEmbeddedEntityAS,
TestReferenceEntityA testReferenceEntityA) {
return TestEntityADTO.builder()
.tid(entityA.getTid())
.name(entityA.getName())
.referenceEntityDTO(TestReferenceEntityADTO.fromEntity(testReferenceEntityA))
.embeddedEntityDTOS(testEmbeddedEntityAS.stream().map(TestEmbeddedEntityADTO::fromEntity).toList())
.build();
}
}B 코드
엔티티
위에서 설명했던 대로 필드 자체에 엔티티를 넣고 있으며 @DocumentReference로 참조를 하고 있다. 참조 시 lookup은 참조하고 있는 엔티티의 시퀀스 번호로 지정하였다.
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Document(collection = "test_entity_b")
public class TestEntityB {
@Id
private String id;
@Indexed
private Long tid;
private String name;
@DocumentReference(lookup = "{'teid':?#{teid}}")
private List<TestEmbeddedEntityB> testEmbeddedEntitiesBs = new ArrayList<>();
@DocumentReference(lookup = "{'trid':?#{trid}}")
private TestReferenceEntityB testReferenceEntityB;
private TestEntityB(Long tid, String name) {
this.tid = tid;
this.name = name;
}
public static TestEntityB of(Long tid, String name) {
return new TestEntityB(tid, name);
}
public void updateTestReferenceEntityB(TestReferenceEntityB testReferenceEntityB) {
this.testReferenceEntityB = testReferenceEntityB;
testReferenceEntityB.updateTestEntityB(this);
}
public void addTestEmbeddedEntityB(TestEmbeddedEntityB testEmbeddedEntityB) {
this.testEmbeddedEntitiesBs.add(testEmbeddedEntityB);
testEmbeddedEntityB.updateTestEntityB(this);
}
}
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Document(collection = "test_embedded_entity_b")
public class TestEmbeddedEntityB {
@Id
private String id;
@Indexed
private Long teid;
private String name;
@DocumentReference(lookup = "{'tid':?#{tid}}")
private TestEntityB testEntityB;
private TestEmbeddedEntityB(Long teid, String name) {
this.teid = teid;
this.name = name;
}
public static TestEmbeddedEntityB of(Long teid, String name) {
return new TestEmbeddedEntityB(teid, name);
}
public void updateTestEntityB(TestEntityB testEntityB) {
this.testEntityB = testEntityB;
}
}
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Document(collection = "test_reference_entity_b")
public class TestReferenceEntityB {
@Id
private String id;
@Indexed
private Long trid;
private String name;
@DocumentReference(lookup = "{'tid':?#{tid}}")
private TestEntityB testEntityB;
private TestReferenceEntityB(Long trid, String name) {
this.trid = trid;
this.name = name;
}
public static TestReferenceEntityB of(Long trid, String name) {
return new TestReferenceEntityB(trid, name);
}
public void updateTestEntityB(TestEntityB testEntityB) {
this.testEntityB = testEntityB;
}
public void updateName(String name) {
this.name = name;
}
}컨버터
엔티티가 생성되는 단계에서 활용되는 컨버터를 작성한다. 공식 문서 예제에서는 단순 필드와 도큐먼트 2가지 방식을 사용했는데, 여기서는 도큐먼트를 사용하였다.
@WritingConverter
public class TestEntityBReferenceConverter implements Converter<TestEntityB, DocumentPointer<Document>> {
@Override
public DocumentPointer<Document> convert(TestEntityB source) {
return () -> new Document("tid", source.getTid()).append("name", source.getName());
}
}
@WritingConverter
public class TestEmbeddedEntityBReferenceConverter implements Converter<TestEmbeddedEntityB, DocumentPointer<Document>> {
@Override
public DocumentPointer<Document> convert(TestEmbeddedEntityB source) {
return () -> new Document("teid", source.getTeid()).append("name", source.getName());
}
}
@WritingConverter
public class TestReferenceEntityBReferenceConverter implements Converter<TestReferenceEntityB, DocumentPointer<Document>> {
@Override
public DocumentPointer<Document> convert(TestReferenceEntityB source) {
return () -> new Document("trid", source.getTrid()).append("name", source.getName());
}
}서비스
A의 사례와는 달리 조회하려고 하는 중심 엔티티인 엔티티 B만 쿼리해서 DTO로 매핑하면 되기 때문에 코드가 훨씬 간결해졌다.
@Slf4j
@RequiredArgsConstructor
@Transactional(readOnly = true)
@Service
public class TestService {
...
// 엔티티 B DTO 단건 조회
public TestEntityBDTO getTestEntityB(Long tid) {
TestEntityB entityB = repository.getTestEntityB(tid);
return TestEntityBDTO.fromEntity(entityB);
}
// 엔티티 B DTO 페이지 조회
public Page<TestEntityBDTO> getTestEntitiesBs(Pageable pageable) {
Page<TestEntityB> testEntities = repository.findAllTestEntitiesBs(pageable);
return testEntities.map(TestEntityBDTO::fromEntity);
}
}DTO
조회 대상이 되는 엔티티 B만으로 연관관계가 있는 엔티티들도 같이 DTO로 매핑하며 이 때 일대일 관계인 참조 엔티티가 null인 경우 null로 매핑하도록 처리하고 있다.
@Getter
@Builder
public class TestEntityBDTO {
private Long tid;
private String name;
private List<TestEmbeddedEntityBDTO> embeddedEntityDTOS;
private TestReferenceEntityBDTO referenceEntityDTO;
public static TestEntityBDTO fromEntity(TestEntityB entityB) {
TestReferenceEntityB referenceEntityB = entityB.getTestReferenceEntityB();
return TestEntityBDTO.builder()
.tid(entityB.getTid())
.name(entityB.getName())
.referenceEntityDTO(referenceEntityB != null ? TestReferenceEntityBDTO.fromEntity(referenceEntityB) : null)
.embeddedEntityDTOS(entityB.getTestEmbeddedEntitiesBs().stream().map(TestEmbeddedEntityBDTO::fromEntity).toList())
.build();
}
}4. 조회 성능 비교
조회는 크게 단건 조회와 페이지 조회를 하였다.
조회 대상은 테스트 엔티티의 DTO이며, 이 DTO는 테스트 엔티티와 연관되어 있는 참조, 내장 엔티티도 같이 DTO로 매핑하여 필드로 두고 있다.
Apache JMeter를 사용하여 조회에 대한 부하 테스트를 진행하여 평균값을 구해본다.
(1초에 50번, 총 100번 반복)
A의 경우
단건 조회
평균 121ms로 측정되었다.

페이지 조회 (사이즈를 100으로 했을 경우)
엔티티 A, 엔티티 A 참조 엔티티 각각 100개와 엔티티 A 내장 엔티티 1000개를 조회하게 된다.
평균 157ms로 측정되며 단건 조회와 큰 차이가 나지 않는다.

B의 경우
단건 조회
평균 116ms로 측정되었으며, A보다 살짝 빠르지만 유의미한 차이는 아닌 것 같다.

페이지 조회 (사이즈를 100으로 했을 경우)
마찬가지로 엔티티 B, 엔티티 B 참조 엔티티 각각 100개와 엔티티 B 내장 엔티티 1000개를 조회하게 된다.
평균 1200ms로 측정되며 A보다 확연히 느려진 것을 알 수 있다.

사실 전체 조회가 아닌 페이지 조회로 테스트를 하게 된 계기도 전체 조회를 할 경우 B에서는 몇분이 지나도 조회가 되지 않았기 때문이었다.
참고로 A의 경우 전체 조회(엔티티 A, 엔티티 A 참조 엔티티 10000개와 엔티티 A 내장 엔티티 100000개) 를 한 번만 요청할 경우 평균 1000ms 내외, 동일하게 부하를 걸 경우 11000ms 내외로 측정이 되었다.
5. 저장 / 수정 / 삭제 시의 용이성 비교
저장
엔티티 A, 엔티티 B 모두 연관되는 엔티티를 저장해야 할 때 (예를 들어 참조 엔티티를 저장해야 할 때) 저장되는 엔티티, 연관되는 엔티티 모두 save()를 해야 한다.
...
// 엔티티 A 참조 엔티티를 저장할 때
@Transactional
public void saveTestReferenceEntityA(Long tid, TestReferenceEntityARequestDTO dto) {
TestEntityA entityA = repository.getTestEntityA(tid);
Long trid = generator.generateSequence(SequenceName.TEST_REFERENCE_ENTITY_A.toString());
TestReferenceEntityA referenceEntityA = dto.toEntity(dto, trid, tid);
// 엔티티 A의 참조 엔티티의 시퀀스 번호를 업데이트
entityA.updateTrid(trid);
// 엔티티 A, 엔티티 A 참조 엔티티 모두 save()
repository.saveTestEntityA(entityA);
repository.saveTestReferenceEntityA(referenceEntityA);
}
// 엔티티 B 참조 엔티티를 저장할 때
@Transactional
public void saveTestReferenceEntityB(Long tid, TestReferenceEntityBRequestDTO dto) {
TestEntityB entityB = repository.getTestEntityB(tid);
Long trid = generator.generateSequence(SequenceName.TEST_REFERENCE_ENTITY_B.toString());
TestReferenceEntityB referenceEntityB = dto.toEntity(dto, trid);
// 엔티티 B의 참조 엔티티를 업데이트
entityB.updateTestReferenceEntityB(referenceEntityB);
// 엔티티 B, 엔티티 B 참조 엔티티 모두 save()
repository.saveTestEntityB(entityB);
repository.saveTestReferenceEntityB(referenceEntityB);
}만약 MongoRepository가 아닌 MongoOperations을 활용하여 원자적 업데이트를 위해 findAndModify()를 써야 할 경우, A는 단순히 시퀀스 번호만 수정해주면 되겠지만 B는 어떻게 해야할 지... (방법은 있겠지만 잘 떠오르지는 않는다)
수정
엔티티 A, 엔티티 B 모두 연관되는 엔티티가 업데이트되더라도 엔티티 A, B에 대해서는 크게 업데이트를 해야 하는 부분은 없다.
삭제
엔티티 A, 엔티티 B 모두 연관되는 엔티티가 삭제될 경우 매핑된 시퀀스 번호나 엔티티 자체를 업데이트해줘야 한다.
// 엔티티 A 참조 엔티티를 삭제할 때
@Transactional
public void deleteTestReferenceEntityA(Long tid, Long trid) {
// 연관되어 있는 엔티티 A 조회
TestEntityA entityA = repository.getTestEntityA(tid);
// 엔티티 A 참조 엔티티 삭제
repository.deleteTestReferenceEntityA(trid);
// 엔티티 A의 참조 엔티티 시퀀스 번호 null 처리 후 save()
entityA.updateTrid(null);
repository.saveTestEntityA(entityA);
}
// 엔티티 B 참조 엔티티를 삭제할 때
@Transactional
public void deleteTestReferenceEntityB(Long tid, Long trid) {
// 연관되어 있는 엔티티 B 조회
TestEntityB entityB = repository.getTestEntityB(tid);
// 엔티티 B 참조 엔티티 삭제
repository.deleteTestReferenceEntityB(trid);
// 엔티티 B의 참조 엔티티 null 처리 후 save()
entityB.deleteTestReferenceEntityB();
repository.saveTestEntityB(entityB);
}사실 CUD 작업에 있어서도 @DocumentReference를 사용할 때와 그러지 않을 때의 큰 차이가 없어서 용이성 관련으로 이렇다할 이점은 없었던 것 같다.
6. 개인적인 결론
@DocumentReference를 사용할 경우 사실상 Spring Data JPA에서 사용하던 연관관계 매핑과 동일하게 처리를 할 수 있어서 조회 시에는 코드도 간결해지고 비즈니스 로직 처리가 간단해지긴 하지만 조회해야 하는 도큐먼트가 많아질수록 조회 성능이 급격히 낮아지는 것을 확인했다.
Spring 공식 문서에서는 @DocumentReference로 연결된 도큐먼트들을 조회할 때 어플리케이션 메모리 내에 대량으로 로드하고 최선의 노력으로 순서를 복원한다고 하는데 어노테이션 설정 부에 사용한 $lookup 의 경우 성능 문제가 발생할 수 있다고 하는 것을 보면 이러한 이유로 조회해야 할 도큐먼트에 비례하여 조회 성능이 나빠지는 것 같다. (공식 문서에서는 인덱스를 적용하면 조회 성능이 개선될 수 있다고는 하나, 위의 코드를 보면 $lookup 으로 바라보고 있는 필드들을 이미 인덱스로 선언했다...)
또한 조회를 제외한 나머지 CUD 처리의 경우 편의성 면에서 이렇다 할 차이가 없었기 때문에 대량으로 조회할 일이 없다는 것이 확실한 도큐먼트 / 엔티티가 아니고서는 @DocumentReference를 사용할 일은 없을 것 같다.
다만 @DocumentReference의 사용을 고려해도 좋은 케이스가 없는 것은 아니므로 추후 이러한 케이스가 생긴다면 한 번 적용해볼 생각은 있다. 테스트로 설계한 엔티티의 구조가 잘못되었을 가능성도 있으니.
마지막으로 이전까지는 막연하게 참조 방식보다는 어플리케이션에서 조인하는 것이 좋다는 이야기를 많이 들어서 그렇게 사용했었지만 직접 테스트를 해보면서 어플리케이션 조인과 참조 방식이 성능면, 용이성 면에서 어떤 차이가 있는지 확인하는 시간이 된 것 같다. 이번 테스트를 토대로 평소에 의문점을 가지고 있던 부분을 실제로 테스트를 해보면서 인사이트를 체득하는 방식으로 깊게 공부해야 할 것 같다.
Reference
https://docs.spring.io/spring-data/mongodb/reference/mongodb/mapping/document-references.html
https://spring.io/blog/2021/11/29/spring-data-mongodb-relation-modelling
