SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
Computer Vision
Abstract & Key Attribution
contrast learning에서, (1) composition of data augmentation, (2) learnable non-linear transformation between representation and contrastive loss (i.e. FC and ReLU layer), (3) larger batch sizes and more training step을 도입하면 simple framework (e.g. ResNet)으로도 높은 performance를 얻을 수 있다
Introduction
contrast learning: self-supervised learning 기법 중 하나로, image에 다른 augmentation을 적용하고 similarity를 높이는 방향으로 학습하는 기법
Methods
Contrastive Learning Framework
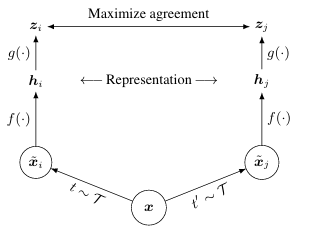
: family of augmentations
: augmented image
: base encoder network, 저자들은 ResNet 사용
: representation
: learnable non-linear NN
Constrastive loss
: Normalized Temperature-Scaled Cross Entropy
: consine similarity
positive pair의 similarity를 높이고, negative pair의 similarity를 낮추도록 학습
Global batch normalization
ResNet은 BN layer를 사용함 but contrastive learning에서는 mini-batch에서 positive pair가 동일한 device에서 계산되므로 model이 BN layer를 악용하여 representation 학습을 저해할 가능성이 존재함
global batch에 대해 batch normalization을 적용하여 이를 막음
Results
Composition of data augmentation
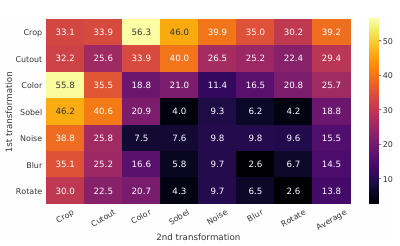
data augmentation은 다음과 같이 나눌 수 있음:
- spatial: cropping, resizing, fliping, cutout
- appearance: color distortion, Gaussian blur
저자들은 individual augmentation보다 composition of augmentations이 더 높은 performance를 관찰했고, 특히 cropping + color distortion이 가장 높은 performance를 나타냄을 관찰함
cropping + color distortion이 높은 성능을 내는 이유?
이미지는 비슷한 color distribution을 공유하기 때문
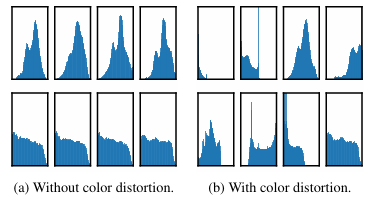
아래 그림에서, color distortion을 적용하지 않을 경우 동일 이미지의 다른 부분을 crop하더라도 color distribution이 비슷해 model이 이를 통해 의도하지 않은 쉬운 방법으로 representation을 학습함
Effect of other design choices
다음의 design choices는 contrast learning에 효과적임
- stronger augmentation; even dangerous level to supervised learning
- bigger model
- non-linear layer before contrastive loss
- NT-Xent
- larger batch sizes and longer training
마지막으로, 다양한 datasets에 대한 performance table은 다음과 같음
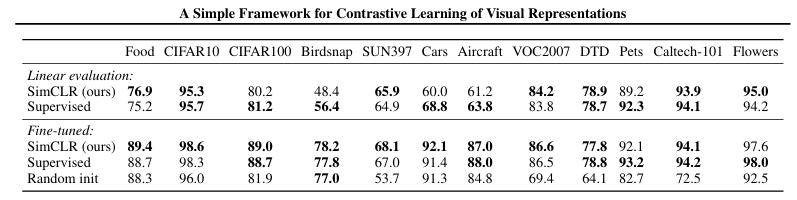
" Comparison of transfer learning performance of our self-supervised approach with supervised baselines across 12 natural image classificationdatasets, for ResNet-50 (4) models pretrained on ImageNet." 대부분의 datasets에서 SimCLR이 supervised baseline models보다 높거나 비슷한 performance을 보여주고, fine-tune할 경우 더 우세한 performance를 보여줌
Summary & Questions
data augmentation + simple architecture = powerful!
간단하면서도 직관적인 model architecture로도 supervised learning과 비슷한 performance를 보일 수 있다는 점에서 contrastive learning의 가능성을 보여주는 논문이었던 것 같음
BN이 어떻게 작동하는지 한 번 더 확인해봐야 할 것 같음
