MySQL
1.데이터와 정보
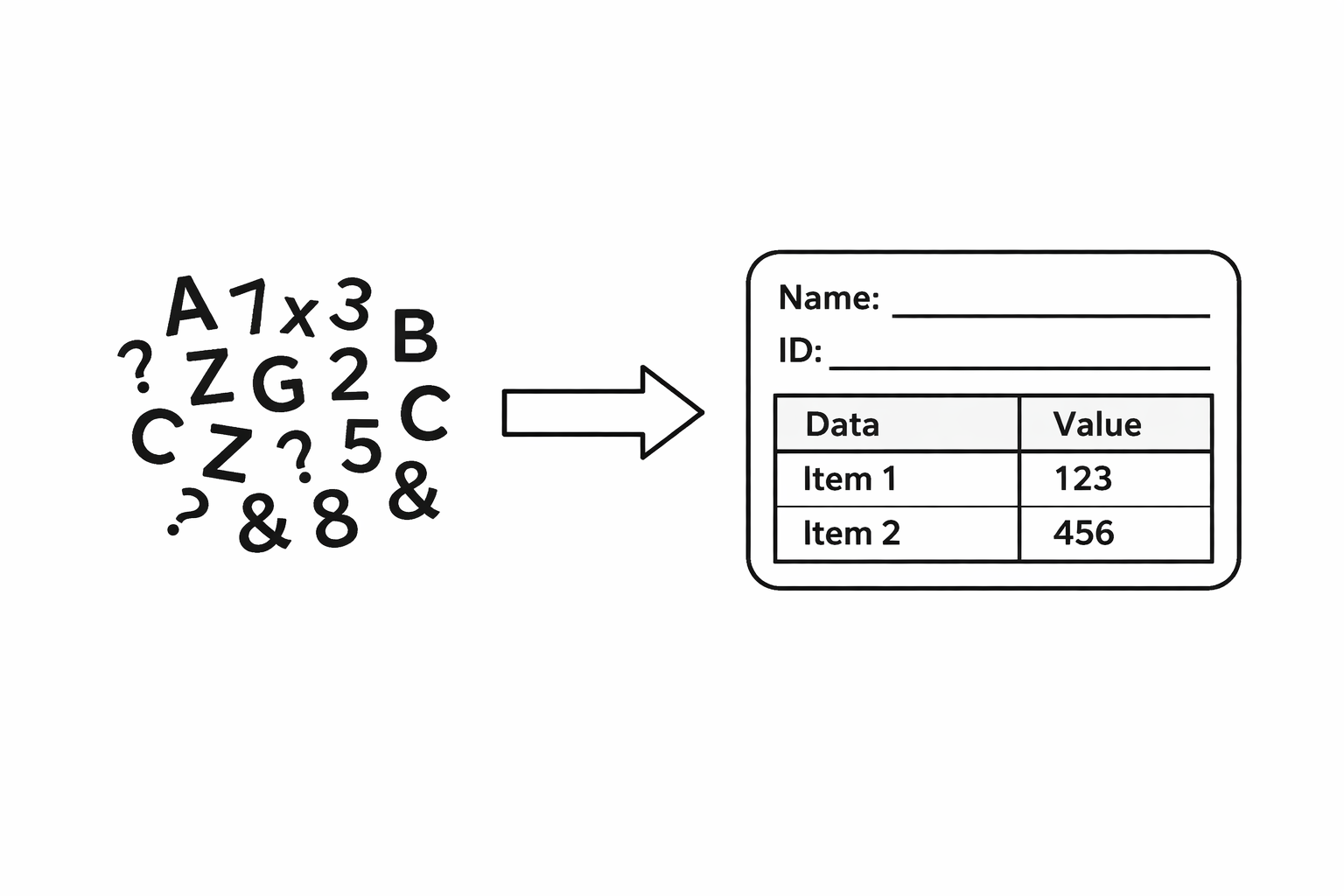
"데이터랑 정보가 다른 거야?" 처음 이 질문이 떠올랐을 때 그냥 같은 말 아닌가 싶었다. 그런데 이 둘의 차이가 생각보다 중요하고, 거기서 한 발 더 나아가면 우리가 데이터를 왜 다루는지까지 이어진다.데이터는 가공되지 않은 원재료다. 숫자, 문자, 날짜처럼 의미가 부
2.데이터베이스
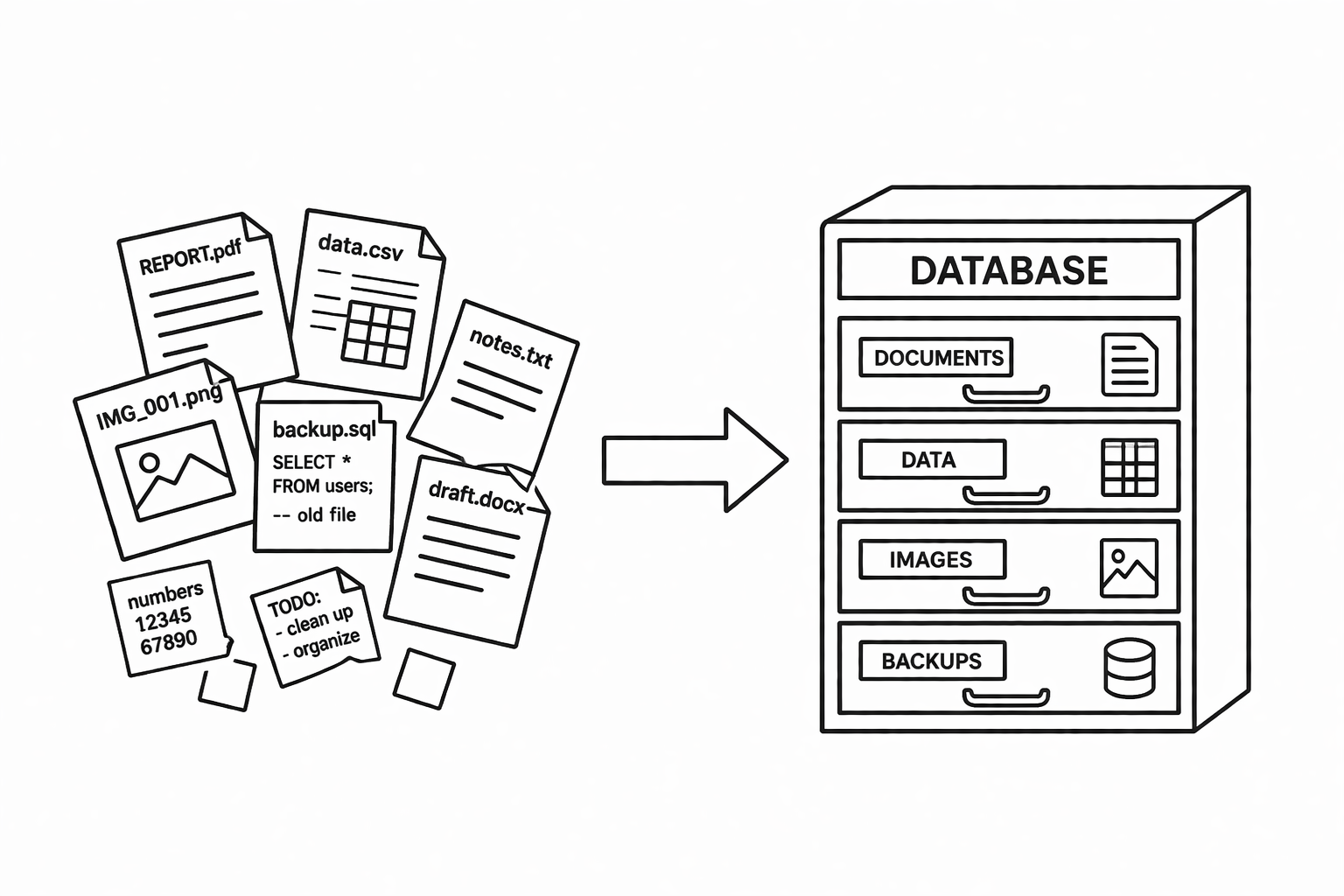
데이터를 그냥 파일에 저장하면 안 되나? 처음엔 이게 당연한 의문이다. 텍스트 파일이든 엑셀이든 저장은 되니까. 그런데 데이터가 쌓이기 시작하면 문제가 보인다.회원 정보를 텍스트 파일에 저장한다고 해보자.회원이 몇 명일 때는 괜찮다. 그런데 수천, 수만 명이 되면 이런
3.데이터베이스 설계 시나리오
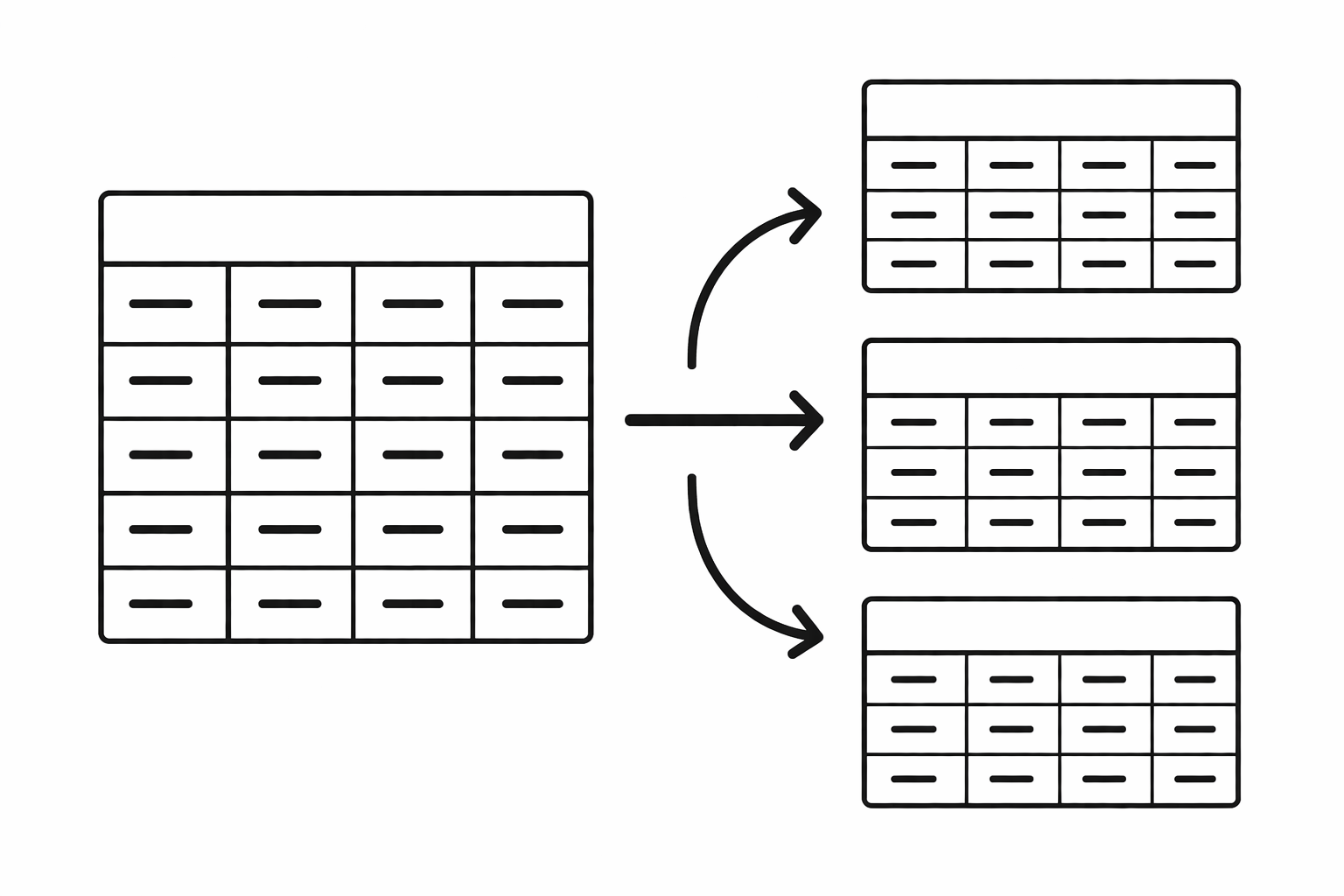
테이블 하나에 다 넣으면 안 되나? 처음 데이터베이스를 접하면 이 질문이 자연스럽게 든다. 어차피 같은 DB 안에 있는 데이터인데, 굳이 여러 테이블로 쪼갤 이유가 있냐는 것이다.있다. 직접 보면 바로 납득이 된다.쇼핑몰을 만든다고 가정하자. 주문이 들어오면 이런 정보
4.DML(Data Manipulation Language)
DDL로 테이블 구조를 잡았다면, 이제 실제 데이터를 넣고 꺼내고 바꾸고 지우는 작업이 남는다. 이걸 담당하는 게 DML(Data Manipulation Language)이다.INSERT, SELECT, UPDATE, DELETE — 네 가지만 알면 된다.테이블에 새
5.DDL(Data Definition Language)
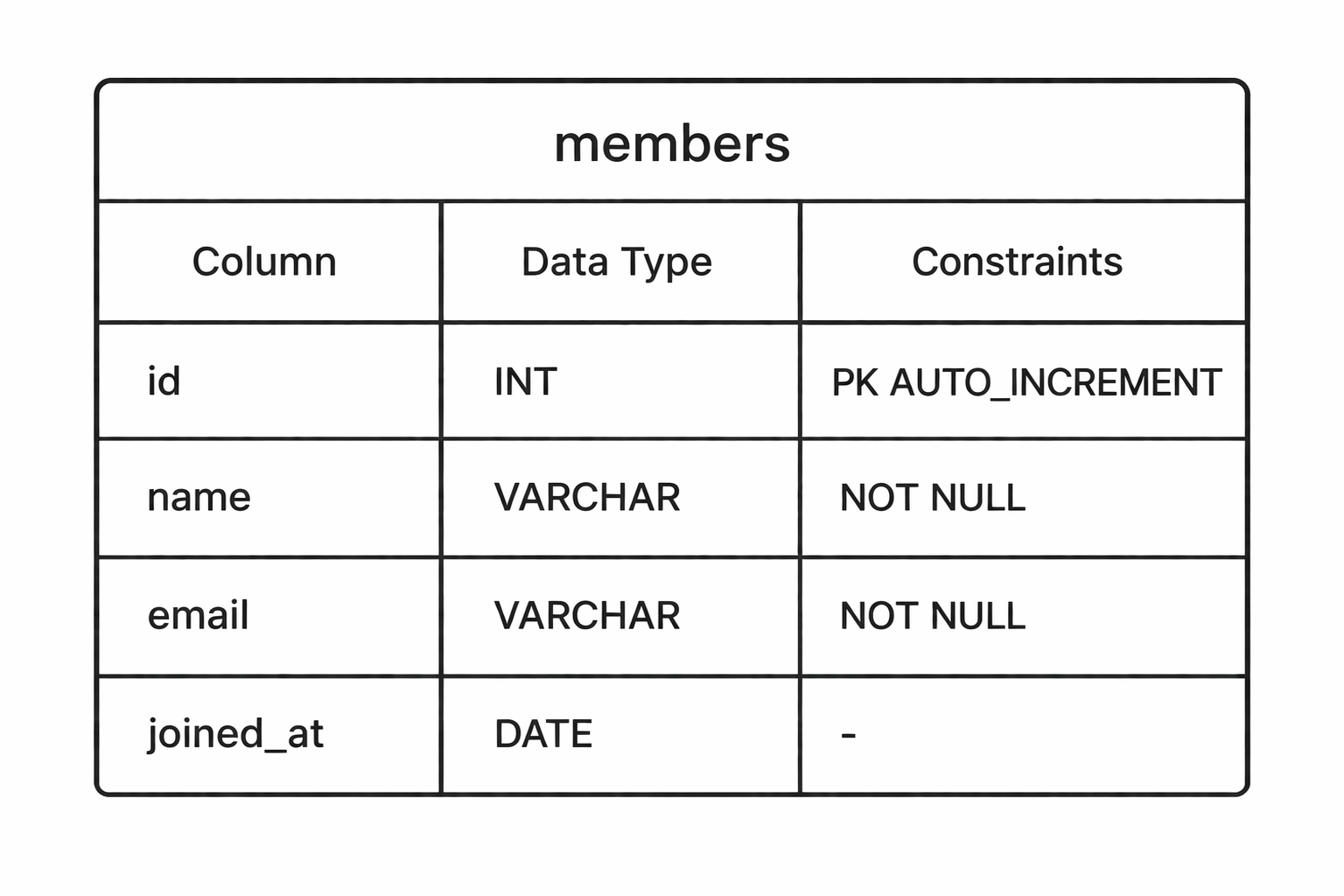
DDL — 테이블을 정의하는 명령어 SQL 명령어는 크게 세 가지로 나뉜다. 테이블 구조를 정의하는 DDL, 데이터를 다루는 DML, 권한을 관리하는 DCL. 이번 글은 그 첫 번째, DDL(Data Definition Language)이다. DDL은 데이터를 넣기
6.DCL(Data Control Language)
DDL로 테이블을 만들고, DML로 데이터를 다뤘다면, 마지막으로 남은 건 "누가 이 데이터를 다룰 수 있는가"다. 이걸 관리하는 게 DCL(Data Control Language)이다.혼자 로컬에서 MySQL을 쓸 때는 이 개념이 크게 와닿지 않는다. 어차피 혼자 쓰
7.MySQL 데이터 타입
테이블을 만들 때 컬럼마다 타입을 지정해야 한다는 건 DDL에서 봤다. 그런데 막상 INT랑 BIGINT가 뭐가 다른지, VARCHAR랑 TEXT는 언제 구분해서 쓰는지 헷갈리기 시작한다. 이번 글에서 자주 쓰는 타입들을 정리한다.대부분은 INT로 충분하다. 사용자 I
8.INSERT 구문과 제약조건
테이블에 데이터를 넣는 건 INSERT 하나면 된다. 그런데 아무 값이나 다 들어가도 되는 건 아니다. 이름 없는 회원, 중복된 이메일, 음수 가격 — 이런 데이터가 쌓이기 시작하면 DB가 금방 엉망이 된다. 제약 조건(Constraint)은 처음부터 잘못된 데이터가
9.SELECT 와 WHERE
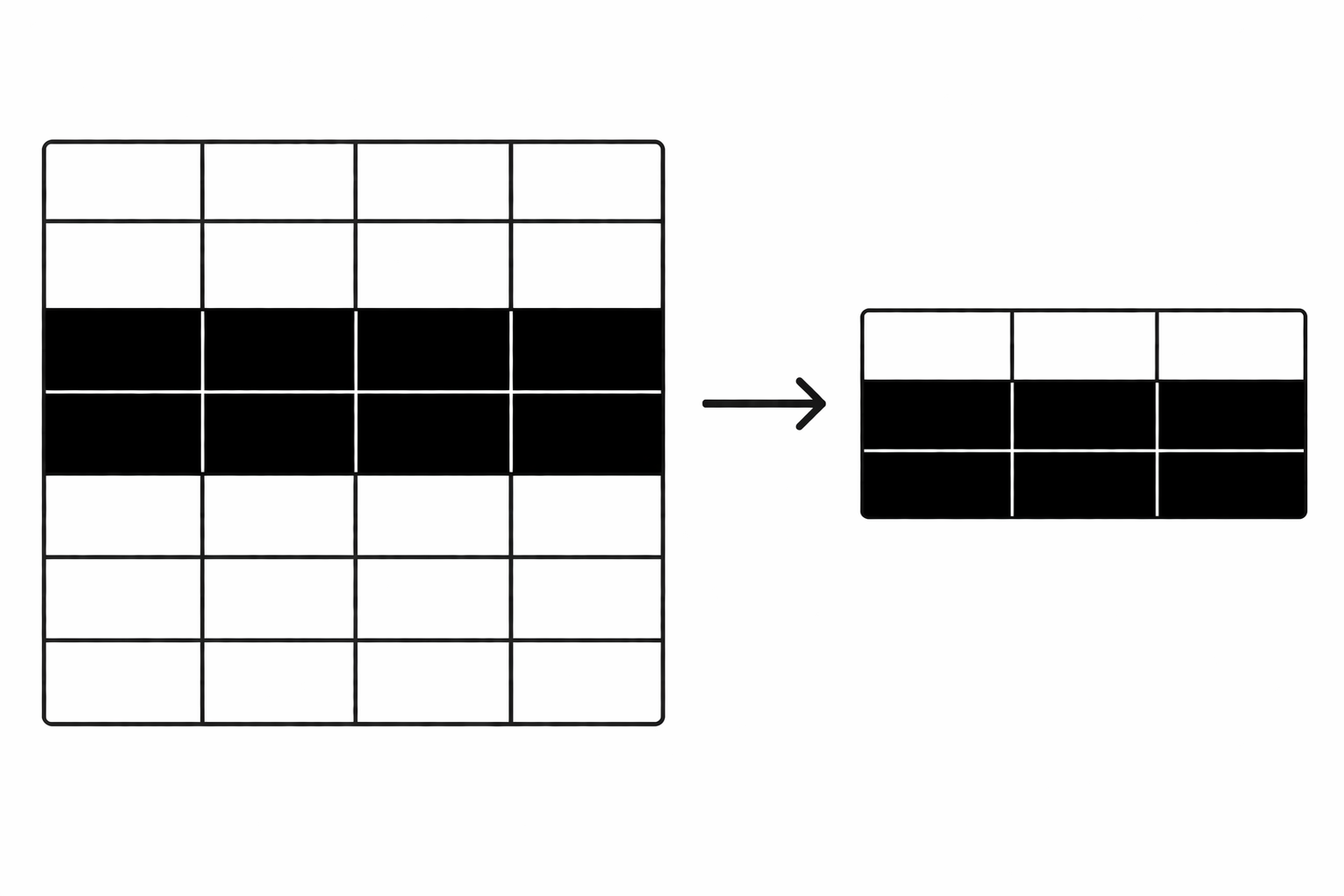
데이터를 넣었으면 꺼내야 한다. SQL에서 데이터를 조회할 때 쓰는 게 SELECT다. 단순히 전체를 가져오는 것부터 조건을 걸고 정렬하고 개수를 제한하는 것까지 — SELECT 하나에 옵션이 꽤 많다.\*는 모든 컬럼을 뜻한다. 컬럼이 많을 때는 필요한 것만 명시하는
10.Primary key, Unique, Foreign key
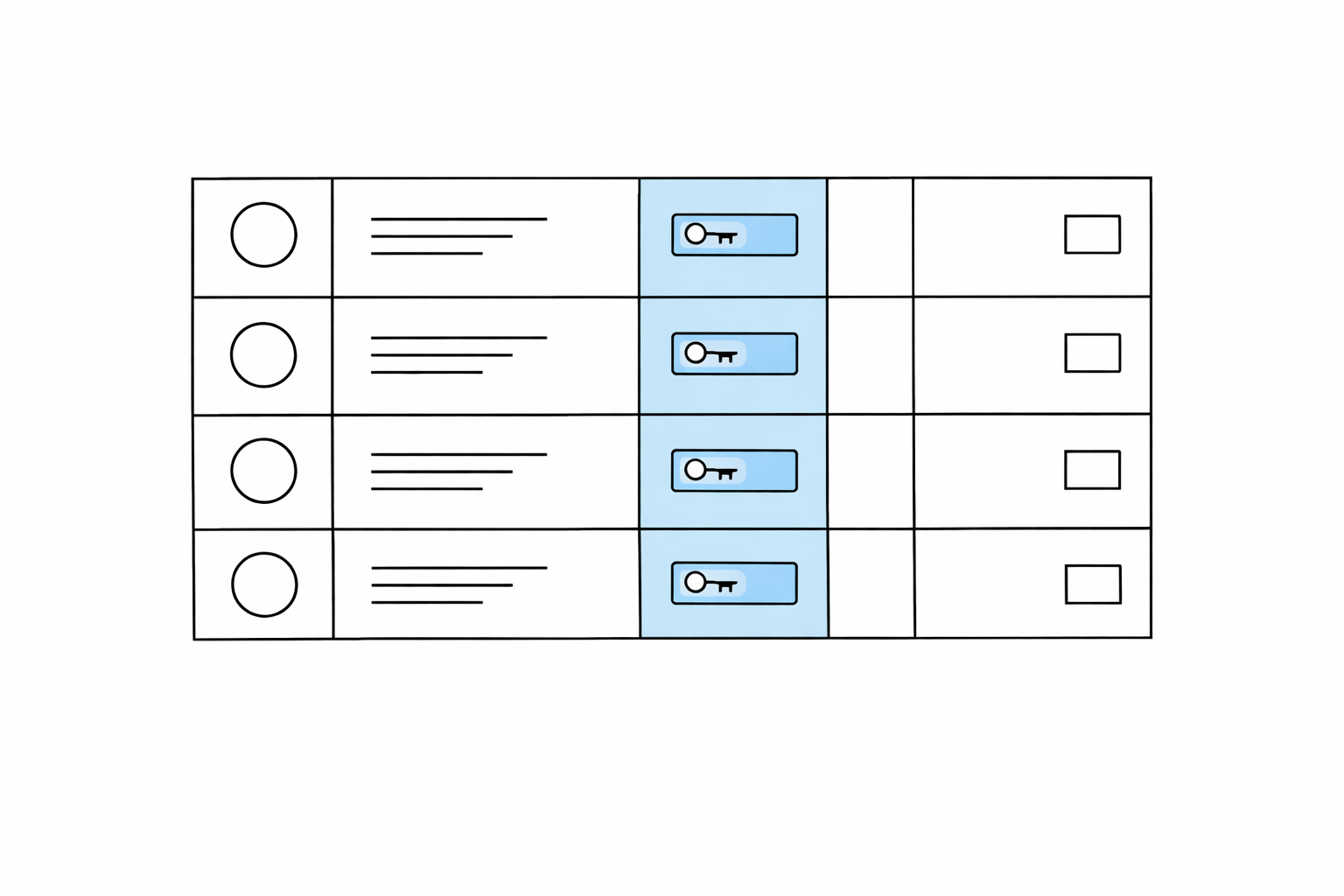
테이블을 처음 설계할 때 가장 자주 마주치는 세 가지 제약 조건이 있다. PRIMARY KEY, UNIQUE, FOREIGN KEY. 셋 다 "중복을 막는다"는 인상을 주는데, 역할이 미묘하게 다르다. 각각이 왜 존재하는지, 어떤 상황에서 쓰이는지를 구분해두면 테이블
11.인덱스(Index)
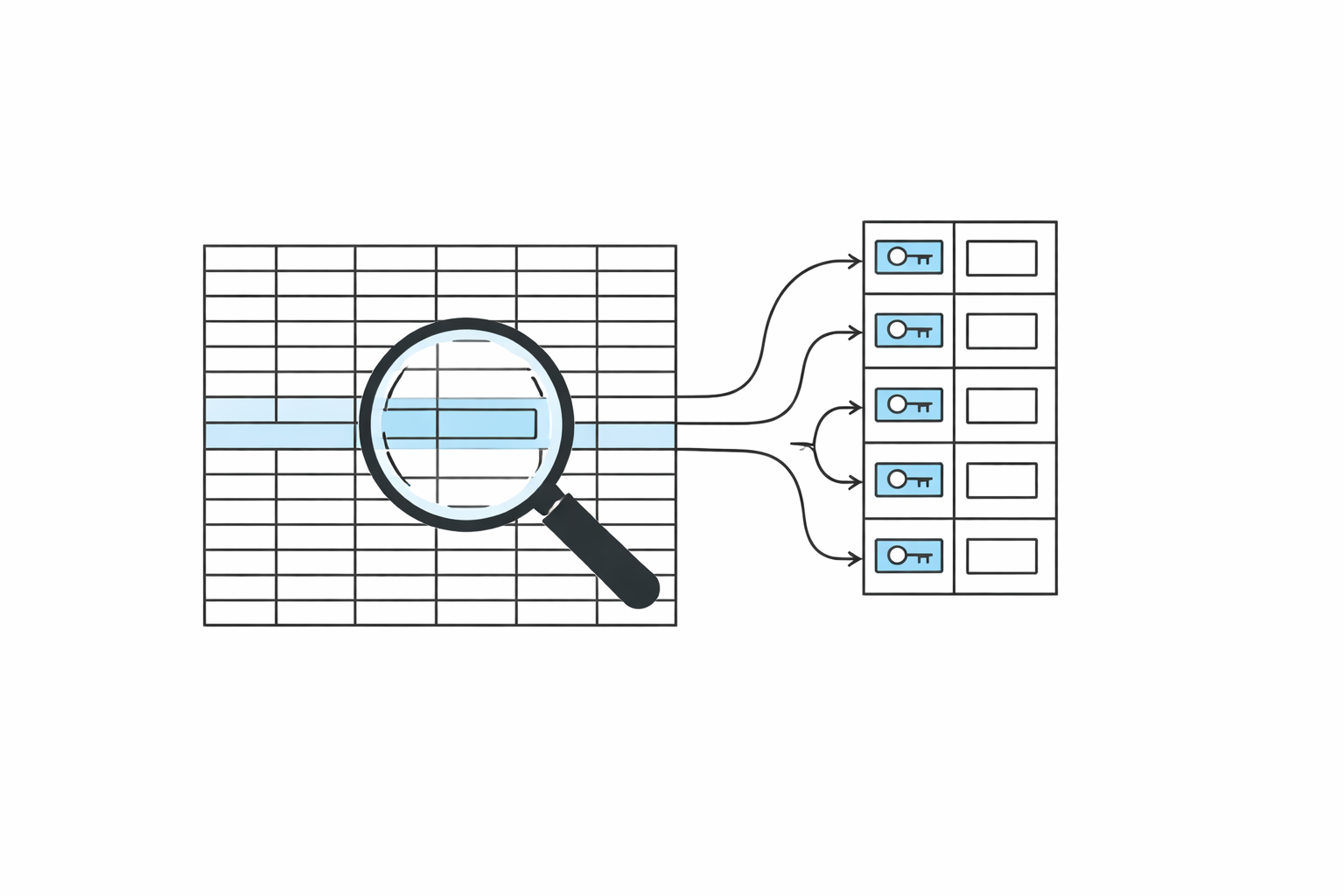
행이 수십만 건 쌓인 테이블에서 특정 이메일을 조회한다고 생각해보자. DB는 기본적으로 첫 번째 행부터 마지막 행까지 전부 훑어본다. 데이터가 많을수록 느려지는 건 당연하다. 인덱스(Index)는 이 문제를 해결하기 위해 존재한다.책 뒤에 붙어 있는 색인을 떠올리면 쉽
12.관계 차수
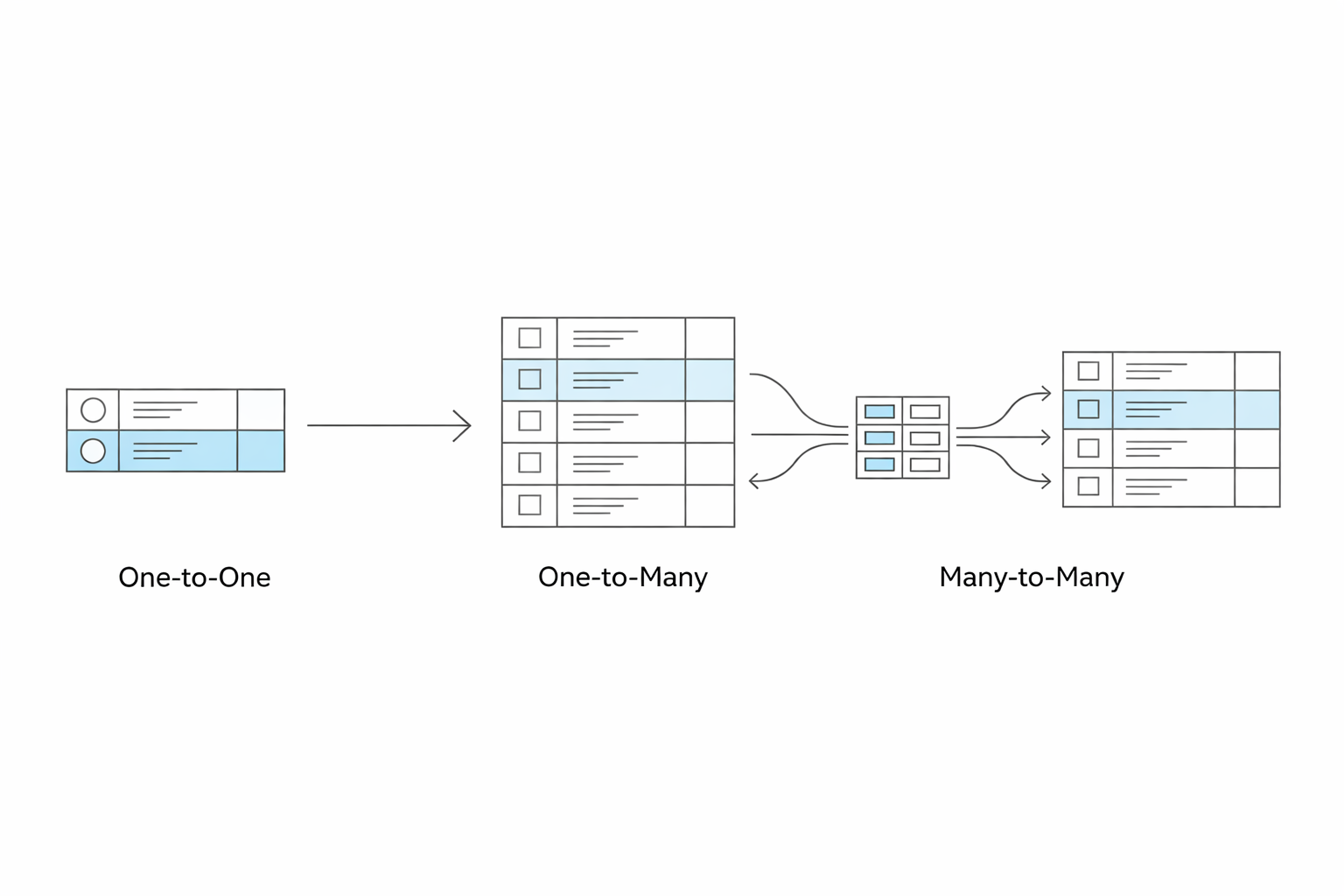
테이블을 나눴으면 이제 나눈 테이블들이 서로 어떻게 연결되는지를 따져야 한다. "한 회원이 주문을 몇 개나 할 수 있나?", "한 주문에 상품이 몇 개 들어갈 수 있나?" — 이런 질문이 바로 관계 차수(Cardinality)다. 테이블 간의 관계를 수량 관점에서 정의
13.ERD 다이어그램
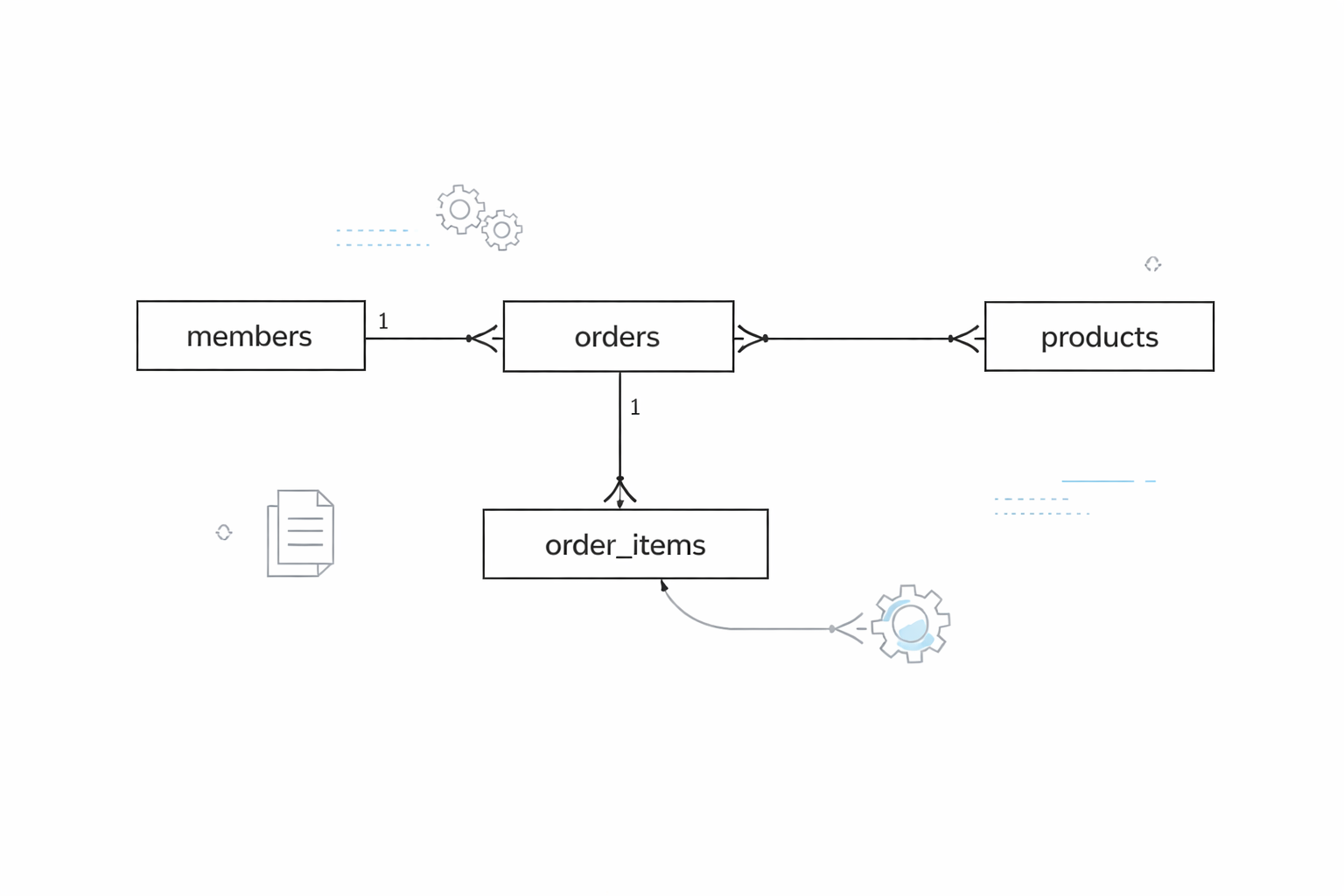
테이블이 세 개, 네 개 넘어가면 말로 설명하기가 힘들어진다. "회원 테이블이 주문 테이블과 연결되고, 주문 테이블은 상품 테이블과 중간 테이블을 통해 연결되고..." — 듣는 사람도, 말하는 사람도 금방 헷갈린다. ERD(Entity-Relationship Diagr
14.JOIN
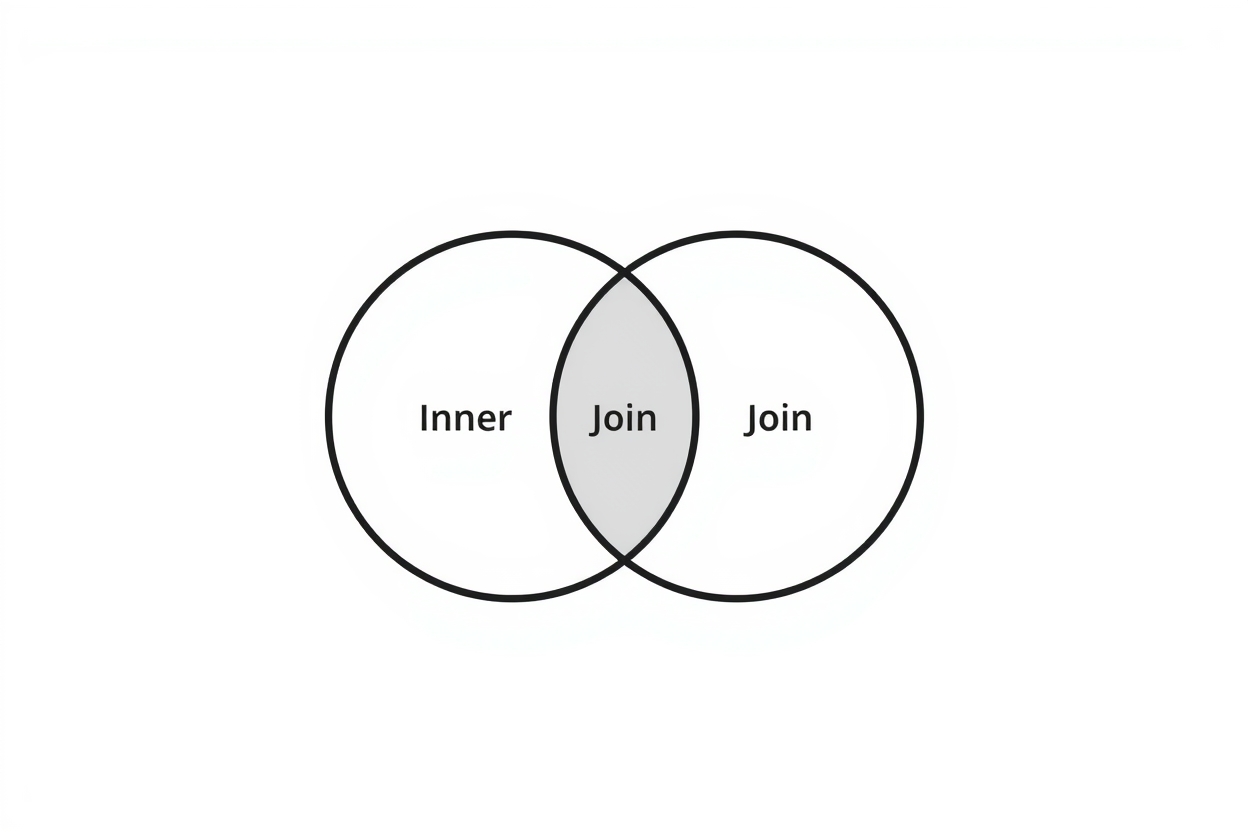
테이블을 잘 나눠뒀는데, 막상 데이터를 꺼내려고 하면 문제가 생긴다. 주문 목록을 보고 싶은데 주문 테이블엔 member_id만 있고 이름은 없다. 회원 이름까지 같이 보려면 두 테이블을 합쳐서 조회해야 한다. 이때 쓰는 게 JOIN이다.설명에 사용할 테이블과 데이터를
15.alias (별칭)
JOIN을 쓰다 보면 자연스럽게 테이블 이름 뒤에 짧은 글자를 붙이게 된다. 위 코드에서 members m, orders o가 바로 별칭(Alias)이다. 컬럼과 테이블 모두에 붙일 수 있고, 쿼리를 훨씬 읽기 쉽게 만들어준다.조회 결과에서 컬럼 이름을 바꿔서 보여준다
16.트랜잭션 (Transaction)
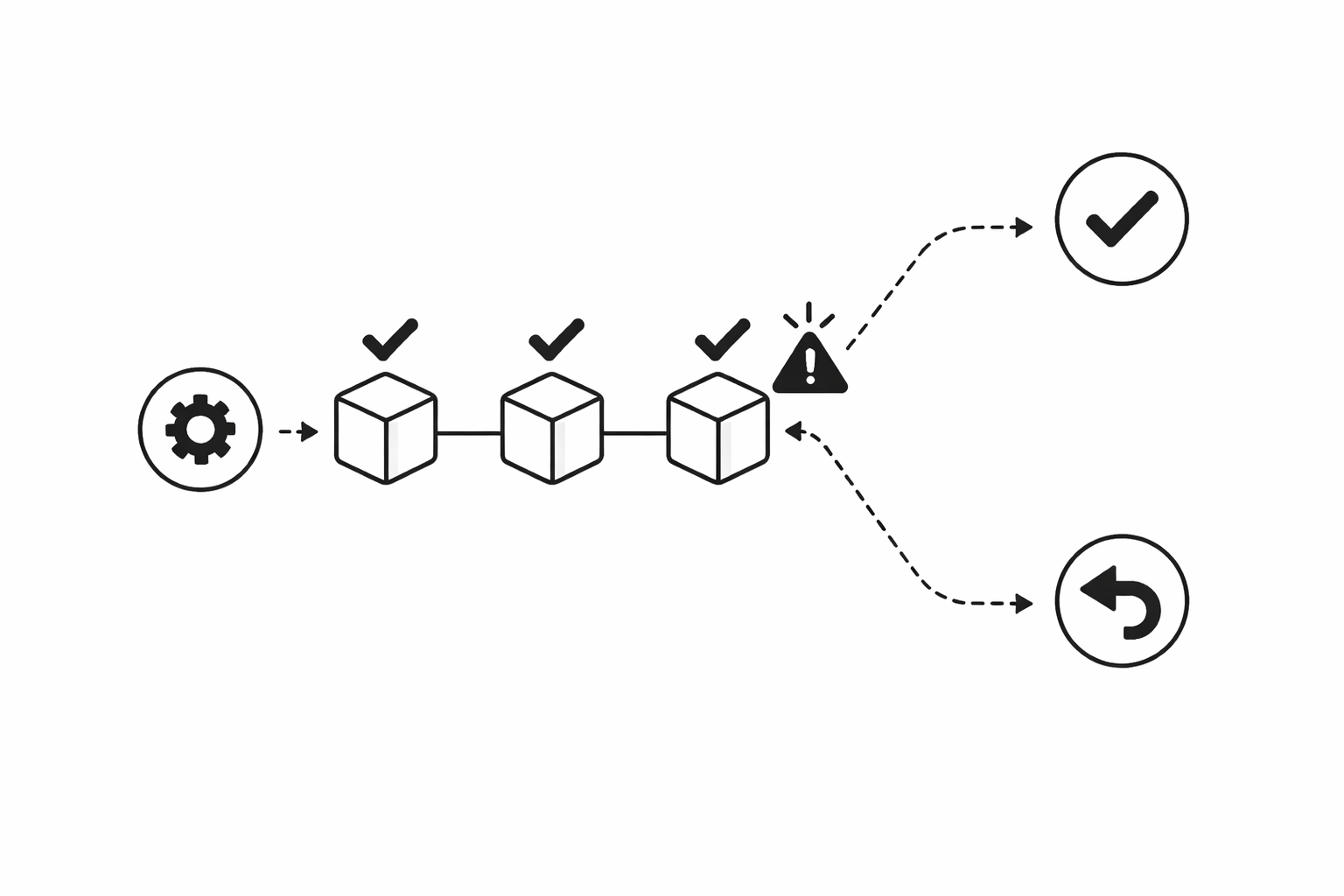
계좌 이체를 생각해보자. A가 B에게 10만 원을 보내는 과정은 두 단계다.A 계좌에서 10만 원 차감B 계좌에 10만 원 추가그런데 1번은 성공했는데 2번 도중에 서버가 꺼지면 어떻게 될까. A의 돈은 빠져나갔는데 B에게는 입금이 안 된다. 이런 상황을 막기 위해 존
17.자주 쓰는 MySQL 함수

SQL을 쓰다 보면 단순히 데이터를 꺼내는 것 이상이 필요해진다. 이름을 대문자로 바꾸거나, 날짜 차이를 계산하거나, 소수점을 정리하거나. 이런 처리를 쿼리 안에서 바로 할 수 있게 해주는 것이 내장 함수다.자주 쓰는 것들만 추렸다.여러 문자열을 이어 붙인다.문자열의
18.GROUP BY, HAVING
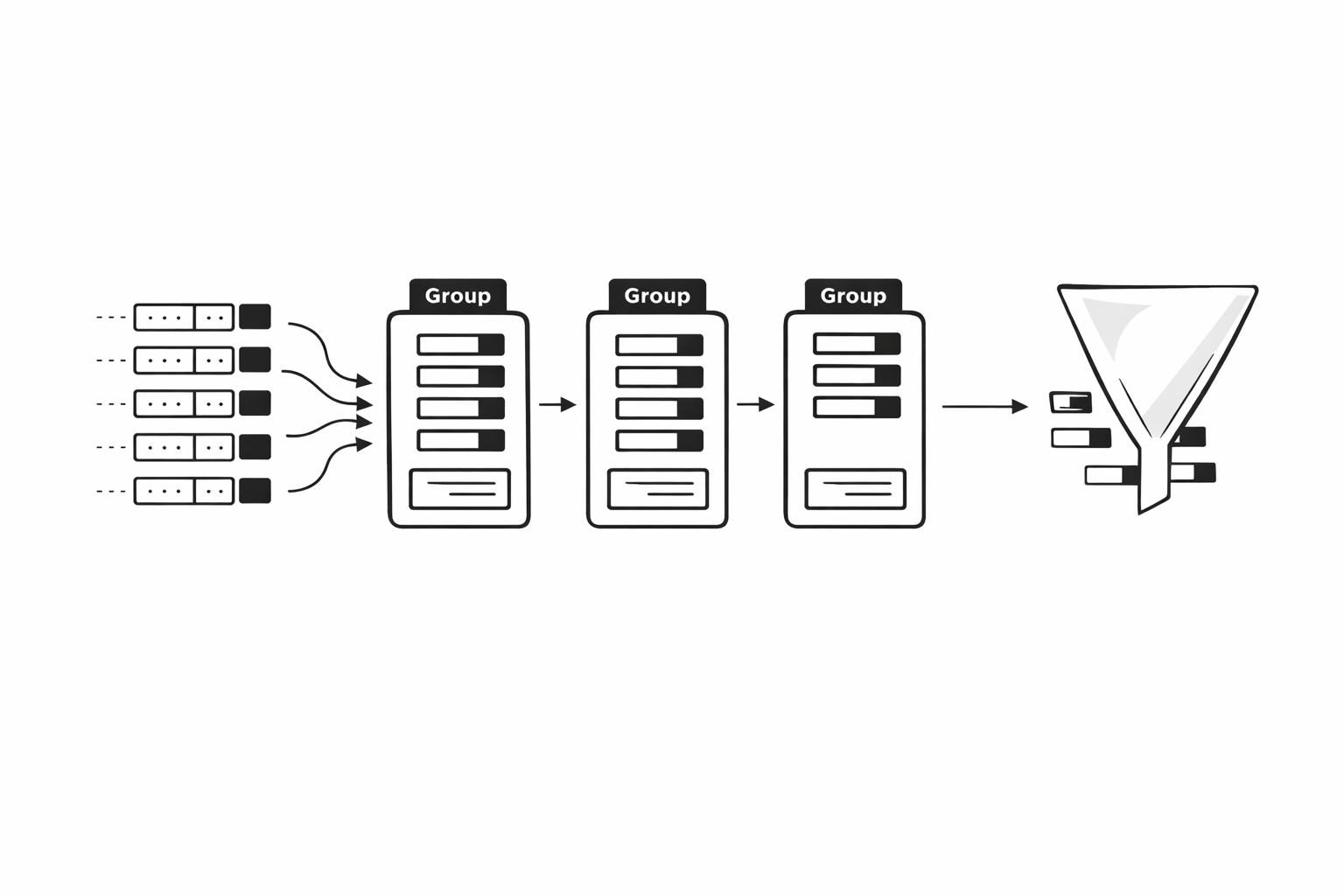
COUNT, SUM, AVG 같은 집계 함수는 전체 데이터를 하나로 요약한다. 그런데 "전체 주문 수"가 아니라 "회원별 주문 수"가 필요하다면? 데이터를 특정 기준으로 묶어서 각 그룹마다 집계해야 한다. 이때 쓰는 게 GROUP BY다.GROUP BY member_i
19.DISTINCT
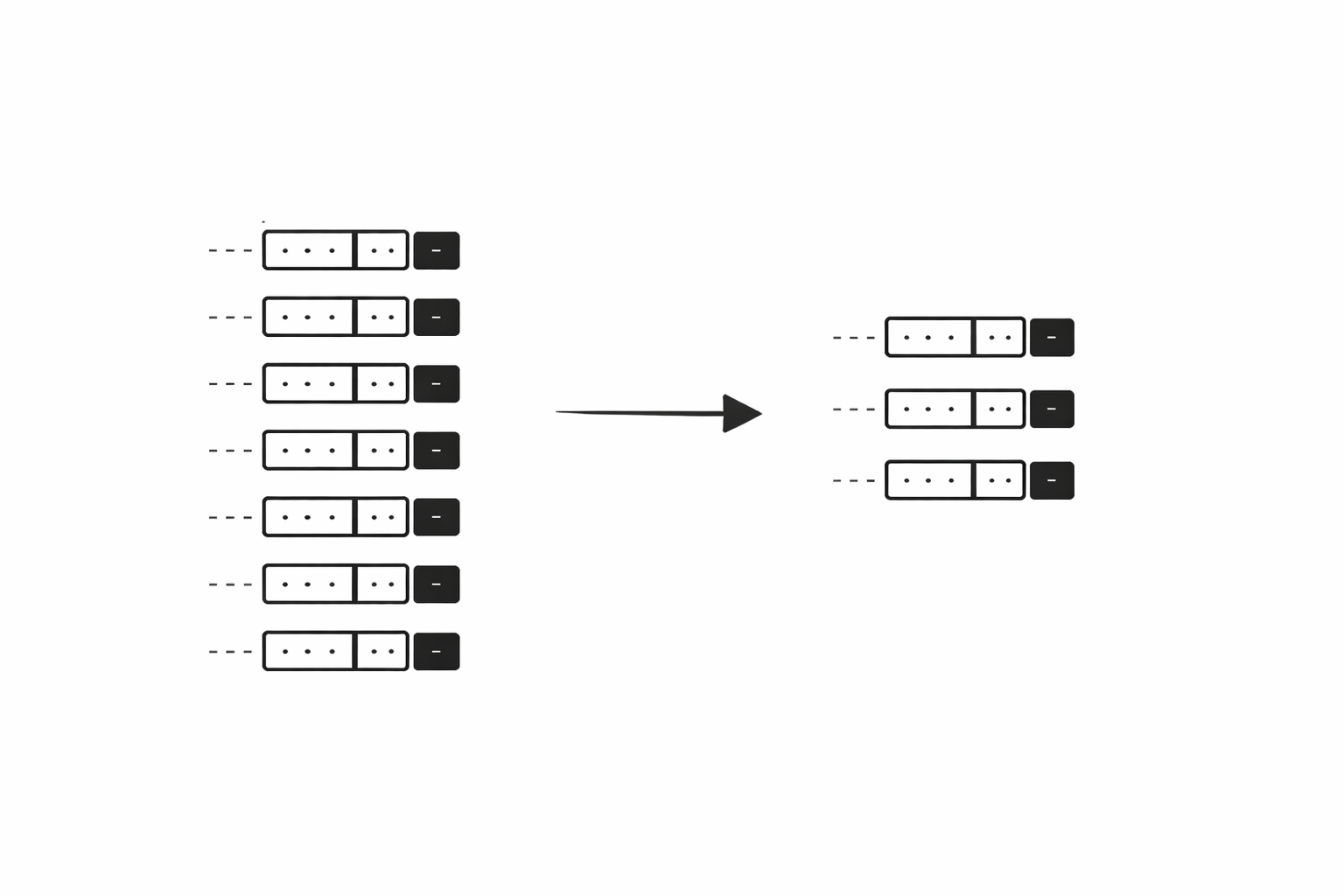
같은 회원이 여러 번 주문하면 member_id가 중복으로 나온다. 여기서 "몇 명이 주문했는지"가 궁금한 거라면 중복을 없애야 한다. DISTINCT는 조회 결과에서 중복된 행을 제거한다.SELECT 바로 뒤에 DISTINCT를 붙이면 된다. 중복된 값은 한 번만 나
20.SQL 쿼리 실행 순서
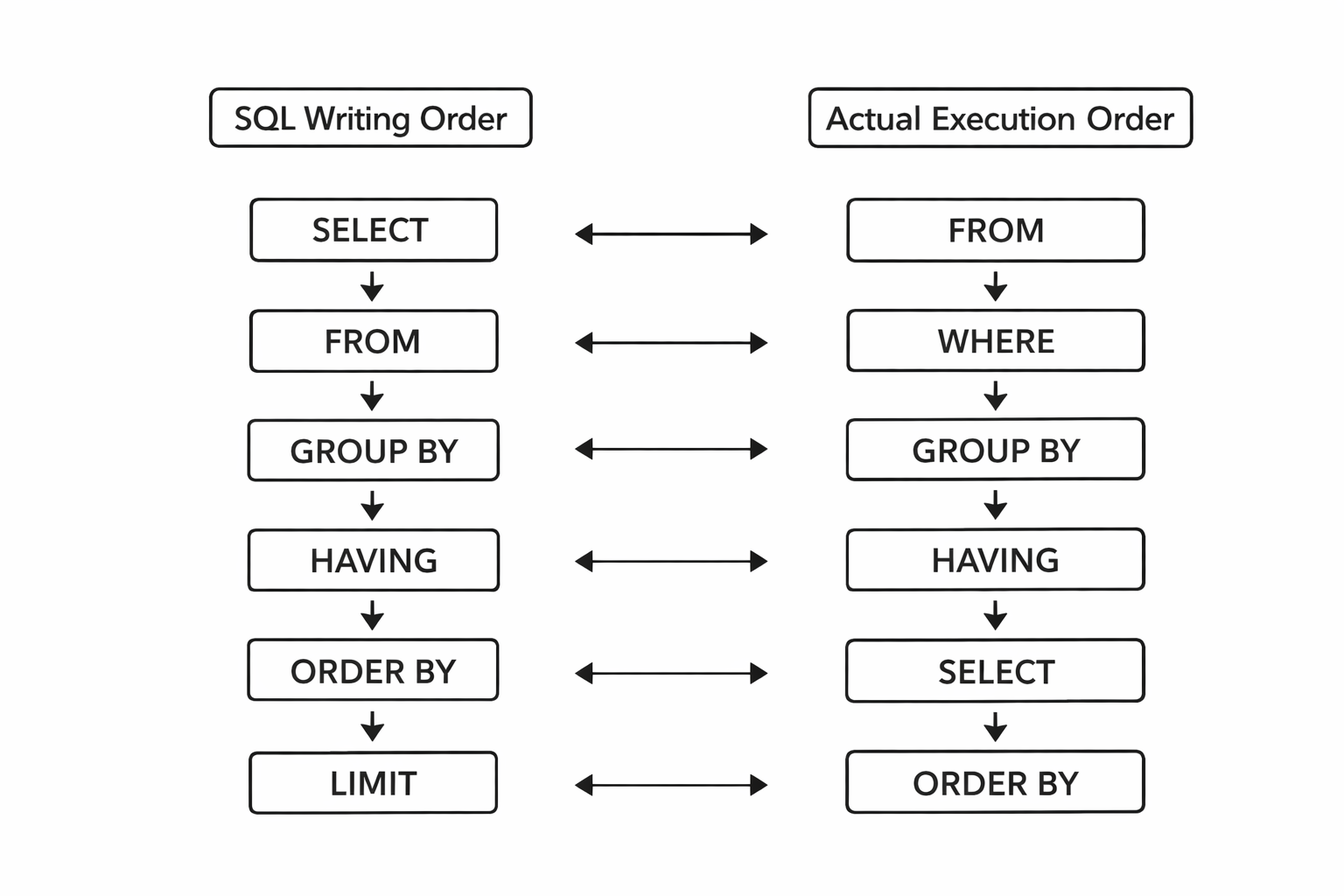
SQL을 처음 배울 때 한 번쯤 이런 의문이 생긴다. SELECT가 제일 앞에 있는데 왜 WHERE에서는 SELECT에서 정한 별칭을 못 쓰지? HAVING은 WHERE랑 뭐가 다른 거지? 이 의문들은 SQL이 작성 순서대로 실행되지 않는다는 걸 알면 한 번에 풀린다.