
프로세스 생성의 목적
-
같은 프로그램의 처리를 여러 개의 프로세스가 나눠서 처리한다.
-
전혀 다른 프로그램을 생성한다.
위의 생성 목적에
fork()와execve()함수를 사용한다. 시스템 내부에서는clone()과execve()시스템 콜을 호출한다.
fork()
'같은 프로그램의 처리를 여러 개의 프로세스가 나눠서 처리한다.' 에는 fork() 함수만 사용한다.
fork() 함수를 실행하면 실행한 프로세스와 함꼐 새로운 프로세스가 1개 생성된다.
- 생선 전의 프로세스를 부모 프로세스(parent process)
- 새롭게 생성된 프로세스를 자식 프로세스(child process)
프로세스 생성하는 순서
- 자식 프로세스용 메모리 영역을 작성하고 거기에 부모 프로세스의 메모리를 복사한다.
fork()함수의 리턴값이 각기 다른 것을 이용하여 부모 프로세스와 자식 프로세스가 서로 다른 코드를 실행하도록 분가한다.
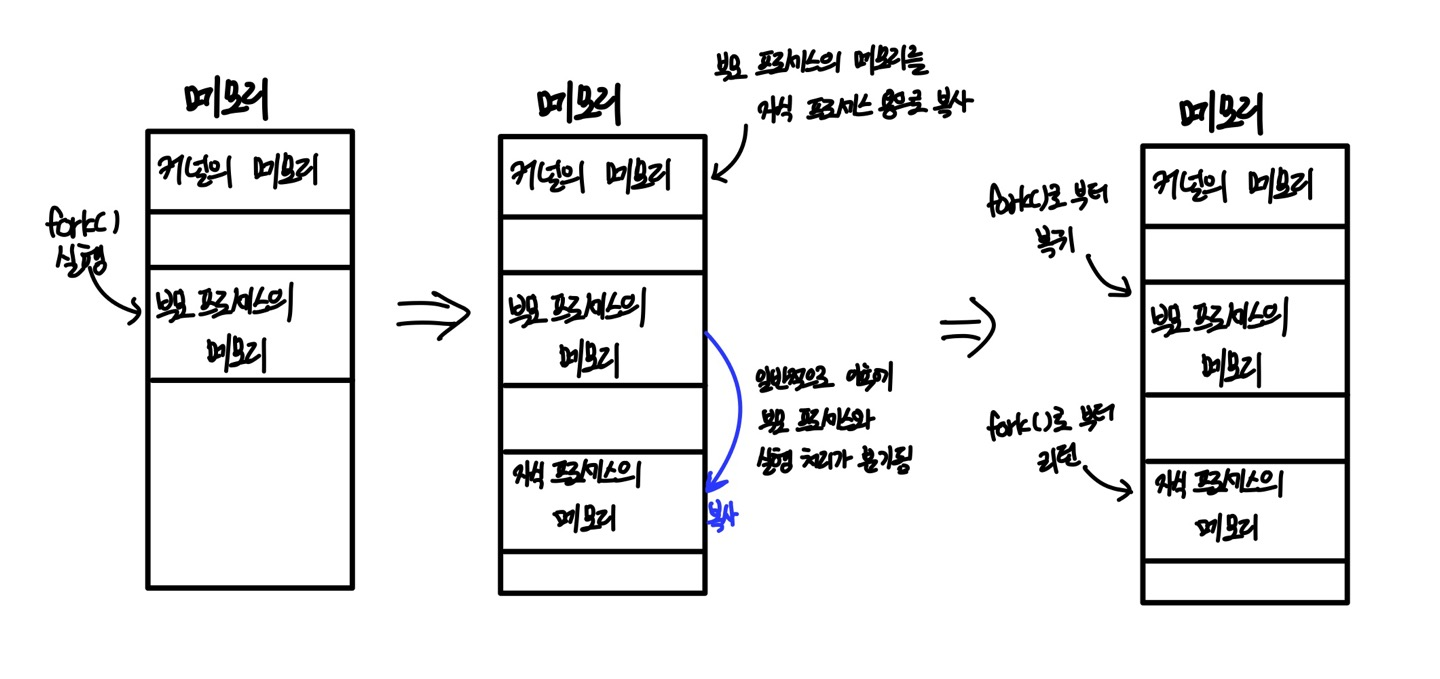
프로세스가 생성되는 과정
- 프로세스를 새로 만든다.
- 부모 프로세스는 자신의 프로세스 ID와 자식 프로세스의 ID를 출력한 뒤 종료한다.
fork() 함수를 리턴할 때 부모 프로세스는 자식 프로세스의 프로세스 ID를, 자식 프로세스는 0을 리턴한다. 이를 이용하여 부모 프로세스와 자식 프로세스의 처리를 나눠서 실행한다.
코드로 실험
fork.c
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <err.h>
static void child()
{
printf("child: %d.\n", getpid());
exit(EXIT_SUCCESS);
}
static void parent(pid_t pic_c){
printf("parent: %d, child of parent: %d\n", getpid(), pic_c);
exit(EXIT_SUCCESS);
}
int main(void)
{
pid_t ret;
ret = fork();
if(ret==-1)
err(EXIT_FAILURE, "fork() failed");
if(ret==0){
child();
}
else{
parent(ret);
}`ㅏ
err(EXIT_FAILURE, "shouldn't reach here");
}실행 결과

이 결과로 프로세스 ID가 7076인 프로스세가 분기 실행되어 부모 프로세스에게 프로세스 ID 7077번의 자식 프로세스가 생성되었다는 점과 fork() 함수 실행 뒤에 두 프로세스의 처리가 분기되어 실행되고 있음을 알 수 있다.
execve()
전혀 다른 프로그램을 생성할 때에는 execve() 함수를 사용한다.
커널이 각각의 프로세스를 실행되기까지의 흐름
1. 실행 파일을 읽은 다음 프로세스의 메모리 맵에 필요한 정보를 읽어 들인다.
2. 현재 프로세스의 메모리를 새로운 프로세스의 데이터로 덮어쓰인다.
3. 새로운 프로세스의 첫 번째 명령부터 실행한다.
전혀 다른 프로그램을 생성하는 경우 프로세스의 수가 증가하는 것이 아니라 기존의 프로세스를 별로의 프로세스로 변경하는 방식으로 수행된다.
별도의 프로그램 생성 순서
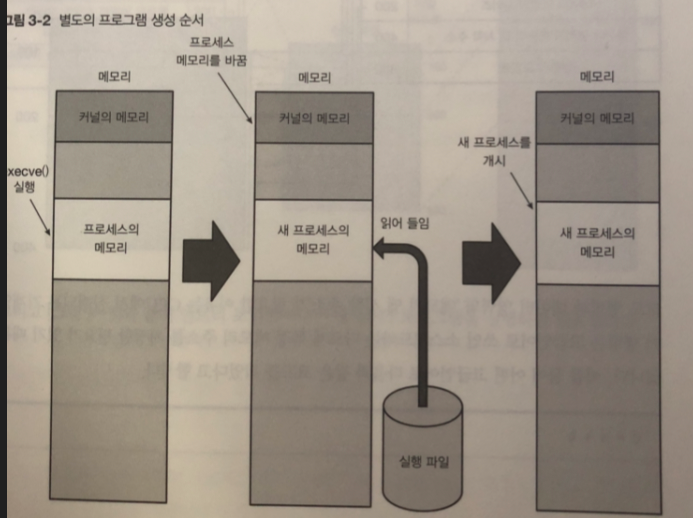
전체 순서를 구체적으로 살펴본다. 일단, 실행 파일을 읽고 프로세스의 메모리 맵에 필요한 정보를 읽어 들인다. 실행 파일은 프로세스의 실행 중에 사용하는 코드와 데이터 이외에도 다음과 같은 필요하다
- 코드를 포함한 데이터 영역의 파일상 오프셋, 사이즈, 메모리 맵 시작 주소
- 코드 외의 변수 등에서의 데이터 영역에 대한 정보(오프셋, 사이즈. 메모리 맵 시작 주소)
- 최초로 실행할 명령의 메모리 주소(엔트리 포인트)
엔트리 포인트(entry point) 또는 진입점은 제어가 운영 체제에서 컴퓨터 프로그램으로 이동하는 것을 말하며, 프로세서는 프로그램이나 코드에 진입해서 실행을 시작하는 것이다.
리눅스의 실행 파일은 단순한 것이 아니라 ELF(Executabke and Linkable Format)라는 형식을 사용한다. ELF 형식의 각종 정보는 readelf 명령어로 자세히 살펴 볼 수 있다.
-h 옵션을 지정하면 시작 주소를 얻을 수 있다.
readelf -h /bin/sleep

이 프로그램의 엔트리 포인트는 0x2b90이다
-S를 통해서는 데이터 영역의 파일상의 오프셋, 사이즈, 메모리 맵 시작 주소를 얻을 수 있다.
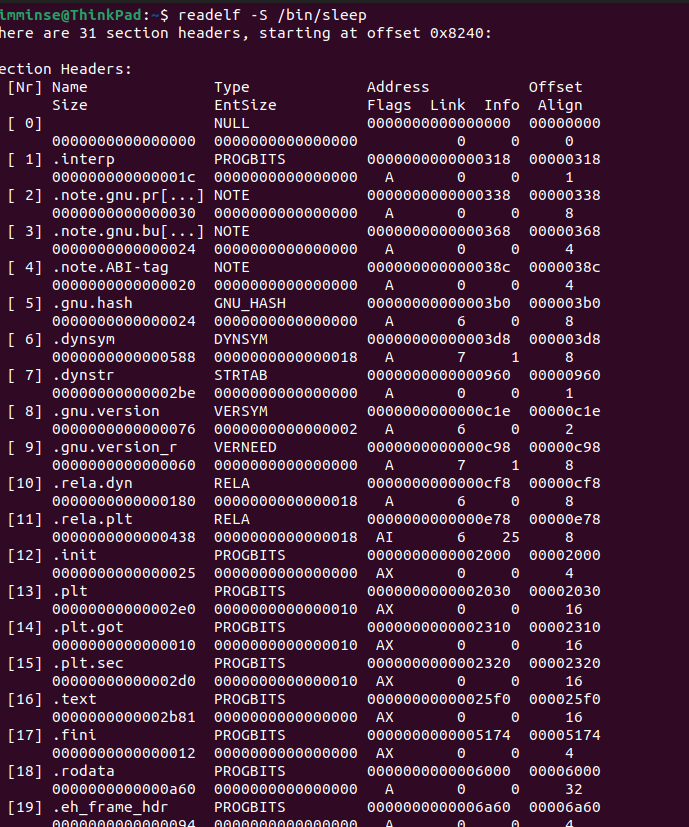
이해 해야하는 사항
- 출력된 내용은 두 줄이 하나의 정보 세트이다.
- 수치는 전부 16진수이다.
- 세트 중 첫줄의 두 번째 필드가
.text이면 코드 영역의 정보를.data면 데이터 영역의 정보를 의미한다. - 세트의 매모리 맵 시작 주소, 파일상의 오프셋, 사이즈를 통해 위치를 알 수 있다.
프로그램 실행 시에 작성된 프로세스 메모리 맵은 /proc/pid/maps 파일을 통해 알 수 있다.



이 글을 보고 리눅스 개발자가 되기로 마음 먹었습니다.