추천 시스템의 평가 지표
비즈니스 / 서비스 관점
-
추천 시스템 적용으로 인한 매출, PV의 증가
-
새로운 추천 아이템으로 인한 유저의 CTR 상승
PV (Page View)
- 사람들이 홈페이지 및 사이트에 몇번의 페이지를 둘러봤는지에 대한 수치
ex. 10명이 방문하여 10개씩의 페이지를 둘러봤다면 PV는 100이 된다.(feat. SNS)
CTR (Click Through Rate)
-
광고가 노출되었을 때 얼마나 클릭을 했느냐라는 수치를 나타냄
-
일반적인 공식은 (클릭수/노출수)∗100
ex. 광고 100번 노출되었을 때 10번의 클릭이 일어났다면 CTR은 10%이다.
품질 관점
-
연관성(Relevance) : 추천된 아이템이 유저에게 관련이 있는지
-
다양성(Diversity) : 추천된 Top-K 아이템에 얼마나 다양한 아이템에 추천되는지
-
새로움(Novelty) : 얼마나 새로운 아이템이 추천되고 있는지
-
참신함(Serendipity) : 유저가 기대하지 못한 뜻밖의 아이템이 추천되는지
평가 과정
Offline Test
-
새로운 추천 모델을 검증하기 위해 가장 먼저 필요한 단계
-
유저로부터 이미 수집한 데이터를 Train/Valid/Test로 나누어 모델의 성능을 객관적인 지표로 평가
-
보통 Offline Test에서 좋은 성능을 보여야 Online 서빙에 투입되지만, 실제 서비스 상황에선 다양한 양상을 보임 (Serving Bias)
-
성능 지표: Precsion@K, Recalll@K, MAP, NDCG, Hit Rate, RMSE, MAE
논문이나 A/B Test에선 강조된 지표를 자주 사용한다.
Online A/B Test
-
Offline Test에서 검증된 가설이나 모델을 이용해 실제 추천 결과를 서빙하는 단계
-
추천 시스템 변경 전후의 성능을 비교하는건이 아닌, 동시에 대조군A과 실험군B의 성능을 평가함
대조군과 실험군의 환경은 동일해야 한다. -
실제 서비스를 통해 얻어지는 결과를 통해 최종 의사결정이 이뤄짐
-
성능 지표: 매출, PV, CTR 등의 비즈니스 / 서비스 지표
대부분 현업에서 의사결정을 위해 사용하는 최종 지표는 모델 성능(RMSE, NDCG 등)이 아닌 비즈니스/서비스 지표를 사용한다.
성능 지표
Precision/Recall
-
이진 분류 Binary Classification의 Metric으로 사용되는 지표
-
Precision: True라고 예측한 것들 중 실제 True인 비율
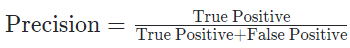
-
Recall: 전체 True 중 True라고 예측한 비율
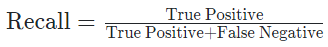
Precision/Recall@K
-
Precision@K: 우리가 추천한 K개 아이템 가운데 실제 유저가 관심있는 아이템의 비율
-
Recall@K: 유저가 관심있는 전체 아이템 가운데 우리가 추천한 아이템의 비율
Example
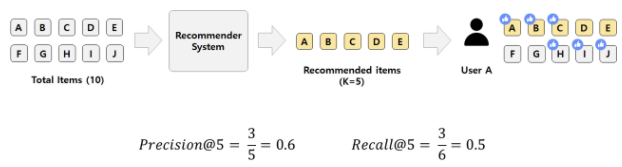
- 우리가 추천한 아이템 개수 : K = 5
- 추천한 아이템 중 유저가 관심있는 아이템 개수 : 3
- 유저가 관심있는 아이템의 전체 개수 : 6
→ Precision@5 = 2/5, Recall@5 = 3/6
Mean Average Precision@K
-
앞서 Precision@K, Recall@K는 모두 순서를 신경쓰지 않음
-
추천 시스템에서는 사용자가 관심을 더 많이 가질만한 아이템을 상위에 추천해주는 것이 매우 중요하며 이를 위해 성능 평가에 순서 개념을 도입한 것이 Mean Average Precision@K
-
Mean과 Average가 모두 평균이므로 혼란스러울 수 있으나 정확하게는 Average Precision의 Mean으로 해석
Average Precision@K
-
Precision@K와 다르게 연관성 있는 relevant한 아이템을 더 높은 순위에 추천할 경우 점수가 상승
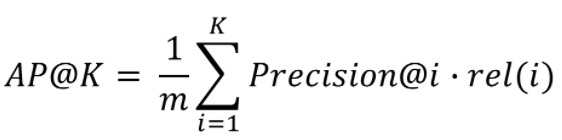
-
Precision@i : 추천한 아이템 개수 K중에서 해당 인덱스까지만 고려했을 때의 Precision 값
-
rel(i) : relevence를 나타내며 해당 아이템을 사용자가 좋아했는지 여부를 나타냄 (0 or 1)
-
m: 모든 아이템 중에서 사용자가 좋아한 아이템 수
-
Precision에 relevence를 곱해주는 이유는 정답 아이템이 추천 목록 중에서 딱 해당 순위에만 영향력을 주도록 하기 위함
정답이 1개 있다고 가정할 때, 똑같이 3개의 아이템을 추천했어도 정답을 첫 번째로 추천한 경우가 두번째, 또는 세번째에 추천한 것보다 AP 점수가 높아진다.
example
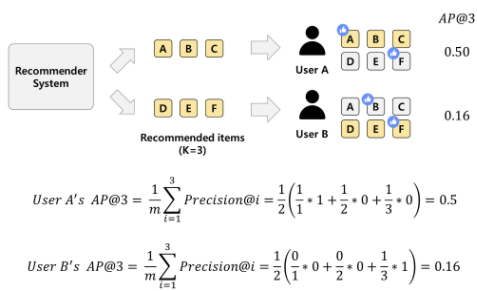
-
User A
- Precision@1 = 1/1, Precision@2 = 1/2, Precison@3 = 1/3
- rel(1) = 1, rel(2) = 0, rel(3) = 0
- m = 2
-
User B
- Precision@1 = 0/1, Precision@2 = 0/2, Precison@3 = 1/3
- rel(1) = 0, rel(2) = 0, rel(3) = 1
- m = 2
-
User A와 User B 둘 다 전체 아이템 중 2개를 좋아했고, 하나가 추천 목록에 포함
-
하지만 사용자가 좋아한 아이템의 추천 순서가 높았는지 낮았는지에 따라 AP값이 크게 차이남
-
User A는 첫번째에 맞췄기 때문에 User B에 비해 점수가 훨씬 높음
-
이와 같이 순서를 평가 지표에 반영한 것이 AP
Mean Average Precision@K (MAP@K)
-
모든 유저에 대한 Average Precision 값의 평균
→ 추천 시스템의 성능
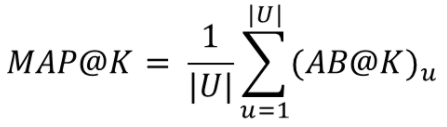
-
U : User 집합
-
|U| : 유저의 수
Example
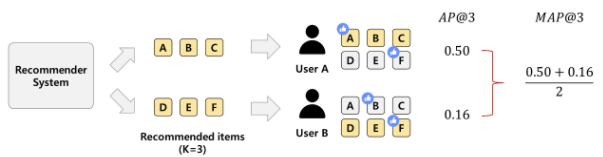
- MAP@K : User A와 User B의 AP@K 평균
NDCG@K (Normalized Discounted Cumulative Gain)
-
NDCG는 원래 검색 분야에서 등장한 지표이나 추천 시스템에도 많이 사용됨
-
위의 두 평가 지표와 마찬가지로 Top K개 아이템을 추천하는 경우, 추천 순서에 가중치를 두어 평가
-
NDCG@K값은 1에 가까울수록 좋음
-
MAP는 사용자가 선호한 아이템이 추천 리스트 중 어떤 순서에 포함되었는지 여부에 대해 1 or 0으로만 구분하지만, NDCG@K는 순서별로 가중치 값(관련도, relevance)을 다르게 적용하여 계산
Relevance
-
사용자가 특정 아이템과 얼마나 관련이 있는지를 나타내는 값
-
Relevance값은 정해진 것이 아니고 추천의 상황에 맞게 정해야 함
Example

-
User A의 아이템에 대한 Relevance
-
신발 추천인 경우 사용자가 해당 신발을 얼마나 클릭했는지의 클릭 여부(Binary) 등 다양한 방법으로 선정할 수 있음
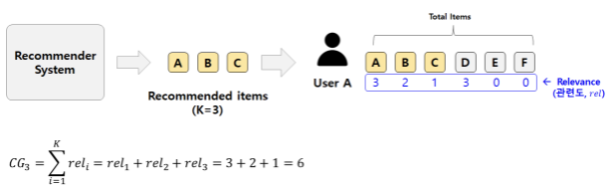
Cumulative Gain (CG)
- 추천한 아이템의 Relevance 합
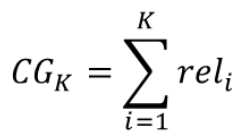
- 두 추천 모델이 순서에 관계없이 동일한 아이템 셋을 추천한 경우 두 모델의 CG는 같아짐
→순서를 고려하지 않은 값
Example
Discounted Cumulative Gain (DCG)
-
CG에 순서에 따른 할인 개념을 도입한 것
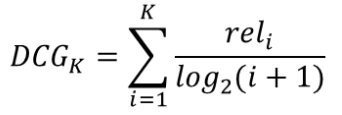
-
추천 아이템의 순서가 뒤에 있을수록 분모가 커짐으로써 전체 DCG에 영향을 적게 주도록 함
-
한계점: 사용자별로 추천 아이템의 수가 다른 경우 정확한 성능 평가가 어려움
Ex. 쇼핑몰에서 클릭한 신발 수가 5개인 사용자와 50개인 사용자에게 추천되는 아이템의 수는 다를 수밖에 없으며 추천 아이템의 수가 많아질수록 DCG값은 증가한다. -
정확한 평가를 위해서는 Scale을 맞출 필요가 있음 (정규화)
Example

Ideal DCG (IDCG)
- 최선의 추천을 했을 때 받는 DCG값
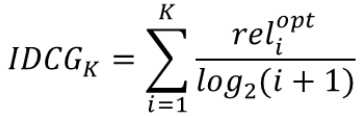
- IDCG는 모든 추천 아이템 조합 중에 최대 DCG값과 동일
Example
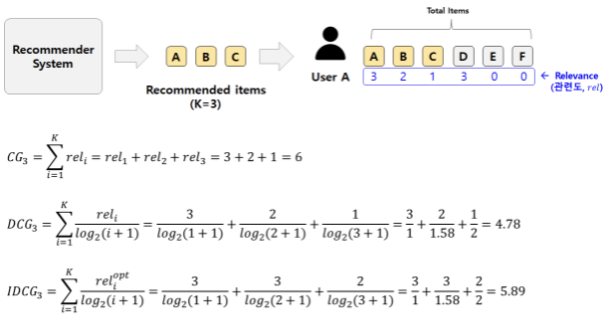
-
예시에서 가장 이상적인 경우는 Relevance가 높은 순서대로 A(3), D(3), B(2) 3개를 추천하는 것
-
A, D, B를 추천했을 때, DCG값은 5.89
Normailzed DCG (NDCG)
- DCG의 한계점을 보완하기 위해 DCG에 정규화를 적용한 것으로 DCG를 IDCG로 나눔
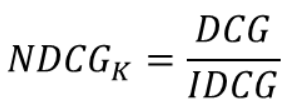
Example
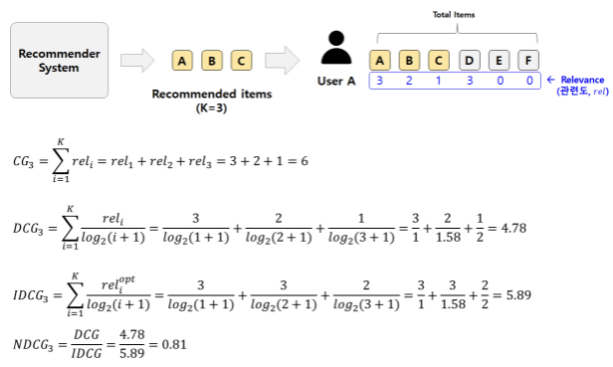
Result
-
NDCG@K는 가장 이상적인 추천 조합 대비 현재 모델의 추천 리스트가 얼마나 좋은지를 나타내는 지표
-
정규화를 함으로써 NDCG는 0~1사이의 값을 가지게 됨
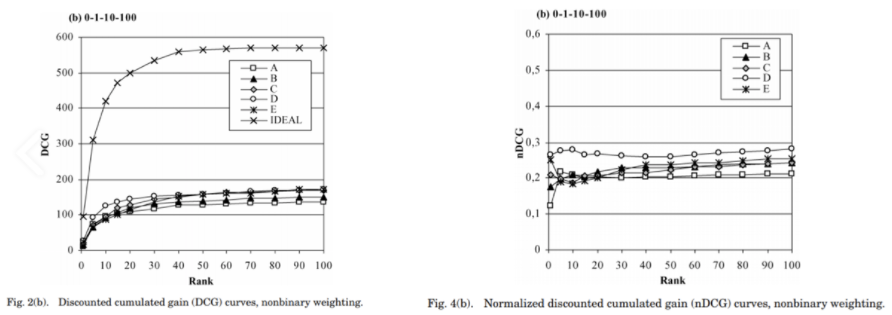
-
다음은 K(x축, Rank)가 증가함에 따라, DCG과 NDCG가 어떻게 달라지는지 나타낸 그래프
-
좌측 그래프는 서로 다른 추천 모델(A~E, Ideal)의 DCG값이고, 우측은 NDCG값을 나타냄
-
DCG는 K가 증가함에 따라 지속적으로 증가하는 반면, NDCG는 어느정도 K에 독립적이어서 어떤 K가 적절한지 판단이 가능
-
NDCG가 작은 스케일을 가지기 때문에 비교가 더 용이
Hit Rate@K
- 전체 사용자 수 대비 적중한 사용자 수를 의미 (적중률)
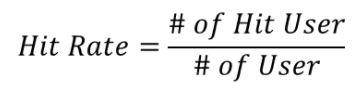
- Hit Rate는 아래 4가지 단계로 구할 수 있음
-
사용자가 선호한 아이템 중 1개를 제외 (Leave-One-Out Cross-Validation)
-
나머지 아이템들로 추천 시스템을 학습
-
사용자별로 K개의 아이템 추천, 앞서 제외한 아이템이 포함되면 Hit
-
전체 사용자 수 대비 Hit한 사용자 수 비율, Hit Rate가 됨
Example

MAE & RMSE (평점)
- 앞서 소개한 성능 지표와 달리 '평점 예측'에 대한 평가 방법
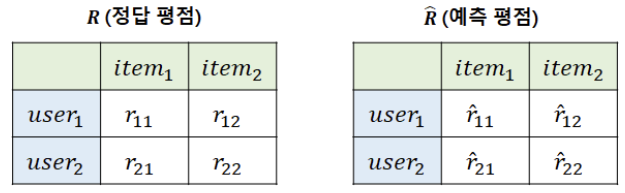
- 사용자별 아이템에 대한 정답 평점과 예측 평점이 있을 때 두 평점 간 차이를 바탕으로 성능을 평가하는 방법
MAE (Mean Absoulute Error)
-
정답 평점과 예측 평점 간 절대 오차에 대해서 평균을 낸 것
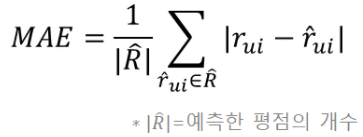
-
장점: 직관적이고 해석이 용이함
-
단점: 오차가 큰 이상치에 쉽게 영향을 받음
RMSE (Root Mean Square Error)
-
오차 제곱의 평균을 내고 루트를 취한 것

-
MSE(Mean Sqaured Error)는 제곱으로 인해 단위가 커지므로 루트를 씌워 실제 예측값과 유사한 단위를 가지도록 만듬
-
MSE는 제곱을 하기 때문에, 1미만인 오차는 더 작아지고 그 이상의 잔차는 더 크게 반영되므로 오차의 왜곡현상이 발생하는데 루트를 통해서 이를 완화
Reference
