지난내용복습
벡터 : 배열의 확장 개념 / 배열처럼 인덱스로 접근 가능 / 배열로 구현
-
insert, erase : 전부 하나씩 밀어야하기 때문에 O(n)
=> 해결방법 : circular array 로 구현할 경우 맨 앞의 원소에 대한 insert, erase 가 O(1) 이 걸린다 ( 하지만 이것도 맨 앞이 아니라면 O(n)이 걸린다 ) -
사용 공간 : O(N) 이 사용됨 ( N : 처음 지정한 배열의 크기 )
(주의할 것! N 과 n 은 다르므로 구분짓자. ) -
더블링 stategy 로 벡터를 구현시 Amotized Analysis 를 통해 O(1) 이 걸린다.
-
몰론 벡터를 배열말고도 링크드 리스트로도 구현 가능.
Position ADT
자료구조 안에서 하나의 오브젝트가 어디에 있는지 "위치"를 추상화 해놓은 개념 ( 임의의 자료구조의 '주소'를 모델링한 개념 )
내부적으로 어떻게 구현되어 있는지 상관하지 않고(신경쓸 필요x), 외부에서 해당 자료구조에서 원하는 위치에 대해 access
Postition ADT 가 구현된 것 : 포인터 변수, 이터레이터 변수 등등
-
어느 객체가 어디에 있다는 것은 구현을 어떻게 했는가에 따라서 실제로 어디있는지 달리진다.
- 맨앞의 원소의 position은 배열로 구현했다면 인덱스 0일 것이다
- 링크드리스트로 구현해서 데이터를 저장했다면 실제 주소값은 어딨는지 몰라도 head 라는 노드형 포인터가 그 맨앞 원소의 position을 가리키고 있다
- 내부적으로 어떻게 구현되있느냐에 따라서, 실제로 맨앞 객체의 위치(position)이 저장되는 방법이 다르겠지만 우리는 외부에서 첫번째 맨앞 객체라고만 부른다.
-
iterator : 맨앞과 맨뒤의 원소를 가리키는 방법이 구현된 변수
( 자료구조 범위에서 벗어나는 내용임 )iterator 는 내부적으로 자료구조가 어떻게, 어떤걸로 구현되어서 어떤 방법으로 position을 access 할수있는지 상관하지 않고 맨앞과 맨뒤에 원소의 position에 access 할수있는 변수다.
- ex ) 외부에서 우리가 어떤 자료구조의 첫번쨰 position 을 access 한다고 하면, 내부적으로 배열로 구현이 되어있을 경우 인덱스를 이용해서 그 position에 해당하는 객체에 access 하는 방법으로 구현되어 있을 것이다.
- ex) 마찬가지로 외부에서 어떤 position 을 access하는 경우 링크드리스트로 구현되어 있다면, 포인터를 이용해서 access 하는 방법으로 구현되어 있을 것이다.
-
p.element( ) : 유일한 메서드인 element 메서드는 주어진 위치에 해당하는 값을 리턴해줌 ( c++에서 *p 연산자와 동일한 기능 )
- p가 position을 나타내는 변수라면, 예를들어 iterator의 begin() 과 같은 것. 맨 앞 위치의 element 를 리턴하도록 하는것.
- ex) 배열로 구현된 경우 맨 앞 위치의 요소를 리턴해라 하면 return A[0]; 로 구현되지만, 밖에서는 신경쓸 필요x. 어떻게 내부적으로 구현되었든 간에 맨 앞 위치의 element 값을 가져옴
→ list adt를 배우기 위한 기초 개념이라고 생각하자!
List ADT
position(위치)를 기반으로 데이터를 access 하는 추상 자료형
외부에서는 해당 자료구조를 position 이라는 개념으로 호출하지만, 내부적으로는 인덱스, 노드형 포인터, .. 등등으로 구현된 자료구조에 알맞게 position 이 변환되서 탐색,삽입 삭제들의 연산을 할수있다(access할수있다).
따라서 특정 원소의 위치가 어딨는지 알려주는 변수인 iterator 를 외부에서 활용하면 리스트의 내부 안에서의 데이터의 위치를 찾아내고, 그 데이터에 대해 insert, erase 등의 연산을 할 수가있다!
(이때 iterator는 맨 앞과 맨 뒤의 원소가 대해서만 어딨는지 알려줄 수 있다.)
- 배열의 일반화가 벡터이듯이, 리스트는 더블리 링크드 리스트를 일반화 해놓은것
일반 링크드 리스트와 다른 점 : Node의 data에 해당하는 부분이 Position으로 되어있음
즉, 특정 데이터의 주소가 연결된 것이 바로 List 이다. → a sequence of positions storing arbitrary object
- 리스트는 데이터를 쭉 나열한 것이므로, 위치의 개념만 알고 있으면 됨.
즉, 내 앞과 뒤에 누가 있는지만 알고 데이터를 저장하는 방법.
(before / after relation )
=> 링크드 리스트를 생각해보면 5번째 데이터는 4번째와 6번째로 갈 수 있다.
4번째, 6번째 객체들의 정보를 5번째 객체가 가지고 있다.
기능
-
size(), empty()
-
begin(), end()
=> 리스트는 iterator를 활용해 2가지 함수를 지원.
- begin() : 리스트의 시작 주소 리턴
- end() : 리스트의 마지막 주소 "다음 주소" 리턴
-
insert(p,e), erase(p) : p => position p에다 e를 삽입, 삭제
- 이터레이터가 position 위치의 역할을 한다. (즉, p라는 위치를 주고 그곳에다 삽입 또는 삭제 하는 연산이다. 외부에서 메소드를 position p를 주면서 호출하면 만일 내부에서는 더블리 링크드 리스트로 구현된 경우 p가 가리키는 실제 위치로 바꿔서 그 위치의 Node 를 지워버린다. )
-
insertFront(e), insertBack(e) : 그 리스트의 특정한 위치(맨앞, 맨뒤) 에 e를 삽입
- 맨앞, 맨뒤의 위치인 경우 위치 정보 p를 줄필요가 없다. begin(), end() 가리키는 곳으로 위치를 알 수 있기 때문
- eraseFront(), eraseBack() : 그 리스트의 특정한 위치(맨앞, 맨뒤)의 데이터를 삭제
- 구성요소 : 컨테이너, 알고리즘, iterator
- 컨테이너 : 실제 데이터들을 저장하는 담는 자료구조
- 알고리즘 : 그것들을 활용할 수 있도록 구현된 함수
- iterator : 그 자료구조에 들어있는 데이터(object) 들을 차례대로 알고리즘 함수로 access 하도록 지원해주는 개념
반복자(iterator)
📢 List에서 사용되는 중요한 개념이 바로 반복자(Iterators) 이다.
반복자는 컨테이너 원소의 position 리턴하므로 포인터와 동일한 역할을 한다.
때문에 반복자는 컨테이너에 저장된 원소에 접근하기 위한 도구로 사용된다.
ex. 반복자를 통해 접근하려는 원소의 주소를 알아내어 이를 이용해 연산을 수행하곤 한다.
리스트에서 반복자는 begin(), end() 함수를 통해 초기화된다.
이때 유의할 것은 end() 함수를 통해 리턴되는 것이
마지막 원소의 주소가 아닌 마지막 원소의 다음번 주소라는 것이다.
즉, end() 멤버 함수를 통해 얻어지는 반복자는 결과적으로 아무 의미가 없는 것을 가리키고 있는 것이며,
이 반복자가 가리키는 것을 참조하면 예상치 못한 오류가 발생하게 된다.
(이는 일반적인 컨테이너들에 다 해당되는 특징임)
Q. 왜 end() 함수는 마지막 원소의 다음 주소를 리턴하는 것인가?
위 구조는 half open range [begin, end) 로 정의되곤 하는데, 이는 다양한 오류를 핸들링하기 쉬우며
empty 일때 begin() = end() 를 가능하게 한다는 점 등에서 많은 장점이 있다.
더블리 링크드 리스트
- list ADT 를 자연스럽게 구현하게 해줌
- head, tail 노드 존재
head -> prev = NULL
tail -> next = NULLInsertion (삽입연산)

- insert(p, x) 구현하기 : p라는 위치 앞에다가 데이터 x를 삽입하기
=> p : 위치, x : 삽입할 데이터- 더블리 링크드 리스트로 구현되어 있기 때문에 p값은 주소값이 된다.
동작 원리
- 외부에서 position을 가지고, 즉 이터레이터를 가지고 access 한다.
- 외부에서 바로 알수 있는 position은 (이터레이터는)
begin() 과 end() 밖에없다. - 다른 임의의 위치를 알고 싶다면 이터레이터로 begin 부터 따라가면서
특정 위치를 찾아낼 수 있다. - 예를들어 특정 위치인 5번째 위치를 찾아낸 경우, 더블리 링크드로 구현된 내부에서는 5번째 위치의 주소값으로 변환을 통해 진행할 수 있다.
구현
-
new 로 할당받은 position을 q 라고 하자. (q는 새로 할당받는 노드형 포인터)
-
insertion 의 수도코드
(q : 노드 p의 앞에다 삽입할 새로운 노드 q => node* q = new node;)
q.data <- x
q.prev <- p.prev
q.next <- p
q.prev.next <- q
q.prev <- q
n <- n + 1find and insert VS insert
insertion 의 시간복잡도 : O(1)
수도코드 다시 표현
(위의 수도코드는 교수님 설명 코드이고, 이 수도코드는 ppt에 적혀있는 코드임)
"u <-> p" 인 링크드리스트에 데이터 e를 가지는 새로운 노드 v를 추가해서
"u <-> v <-> p" 가 되게 하는 상황
Algorithm insert(p, e): {insert e before p}
Create a new node v // O(1)
v -> element = e // O(1)
u = p -> prev // O(1)
v -> next = p; p -> prev = v {link in v before p} // O(1)
v -> prev = u; u -> next = v {link in v after u} // O(1)상세 설명
insert : 이미 주어진 위치에다 데이터를 삽입
find and insert : 어떤 특정 위치를 일일이 노가다로 찾아내서 데이터를 그곳에 삽입
비유)
insert : 100번지 집 앞에다 데이터를 넣어라
find and insert : 홍길동이 사는 집을 찾아서 그 집 앞에다 데이터를 넣어라
-
우리가 하고 있는 것은 insert 이다.
-
insert 는 어떤 특정 위치(주어진 위치 p)의 앞에다가 데이터를 삽입하는 것인지, 특정 위치를 찾아내서 데이터를 삽입하는 함수가 아니다.
( find and insert 였다면 O(1) 가 아닌 O(n) 이였을 것이다. ) -
p라는 위치가 주어지지 않았다면 find and insert 방식으로 진행한다.
즉, 맨 앞에서 부터 원하는 지점까지 도달할때 까지( = 원하는 데이터를 가지는 노드를 찾을 때까지) find를 해야하므로 O(n) 이 걸린다.
=> ex) find and insert 방식으로 "홍길동" 데이터를 가지는 노드 찾고, 그 노드 앞에다 새로운 노드 "안녕" 삽입하기
-
노드형 포인터 tmp 를 하나 만들고,
-
head 에서 부터 tmp = tmp->next; 연산을 계속 반복문으로 진행하면서
-
tmp의 데이터가 "홍길동" 일때 까지 반복문을 돈다. 결국 tmp의 데이터가 홍길동이 될때 break 가 되고 홍길동 노드를 찾은 것이다.
-
홍길동 노드의 주소를 tmp 가 저장하고 있게 된다.
-
그러면 tmp의 prev 가 그 앞의 노드고, tmp 의 prev와 tmp 사이에 새로운 노드를(이때 노드의 데이터 값은 "안녕") 삽입하면 된다.
-
이 경우는 최악의 경우 O(n)이 걸린다.
=> 여기서 우리가 배우는 insert 연산은 이러한 find and insert 연산과 다르다!!
erase
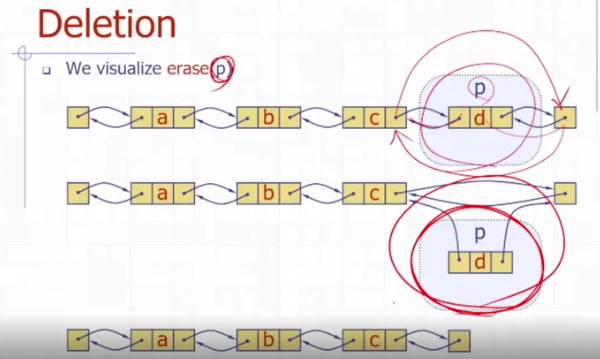
-
erase(p) 구현하기
-
O(1)
더블리 링크드 리스트에서 position를줬을 때 그 position 앞에 새로운 노드를 insert 하거나 그 주소에 있는 것을 delete 하는 것은 모두 O(1) 이 걸린다.
-
마찬가지로 find and erase 연산이라면 최악의 경우 O(n) 이 걸린다.
교수님 설명 수도코드
p.prev.next = p.next
p.next.prev = p.prev
delete p ( 또는 free p )
n = n - 1ppt 수도코드
u <-> p <-> v 인 링크드리스트에서 p를 삭제시키고
u <-> v 인 상태로 만드는 삭제 연산이다.
Algorithm erase(p):
u = p -> prev // O(1)
v = p -> next // O(1)
u -> next = v {linking out p} // O(1)
v -> prev = u // O(1)Performance
-
공간 : O(n) 사용
- 리스트의 각각의 position 이 O(1)의 공간( =객체+ 위치. position을 포인터로 따졌을 때는 포인터 객체 + 주소값)을 차지하므로, n개의 element 가 있다면 O(n) 의 공간을 차지한다.
-
List ADT : 리스트의 모든 연산은 O(1) 이 걸린다.
-
Postition ADT : Position을 주고 그곳에 access 하는 것은 O(1) 이 걸린다.
- p.element() : O(1) => position 가 "위치"라는 개념이지만, 여기서는 대게 "포인터, 즉 주소(address)" 이다. 따라서 그냥 주소라고 생각하고, p.element() 라는 것은 곧 주소값을 주고 access 하라는 것이다. 해당 주소의 element 를 리턴해줘 라는 의미이므로 주소값을 알고이으므로 O(1)이다.
position 을 그냥 포인터, 즉 주소(address) 라고 생각하자!
이전에 배운 싱글리 리스트
싱글리 링크드 리스트는 insert 할 특정위치(position) (=insert할 특정주소) 가 주어졌다고 한들, 그 뒤에다 insert 하는건 O(1) 일지 몰라도 그 앞에다 insert 하는것은 O(n) 이 걸린다 => position이 주어져도 find and insert 가 진행된다.
싱글리/더블리 링크드 리스트 모두 특정 위치(position) ( = insert할 특정 주소)가 주어지면 insert 연산이 O(1)이 된다.
특정 위치가 주어지지 않으면 그 특정 위치를 찾는 과정이 포함되기 때문에 O(n) 이 걸린다.
-
이전에 다루었던 싱글리 리스트는 position 값이 주어지지 않고,
head 와 tail 밖에 주어지지 않았다. -
head 와 tail 은 유일하게 position이 주어졌기 때문에 head 와 tail 에 insert하는 연산은 O(1) 이다.
-
다만, 싱글리 리스트에서 tail에 대한 delete 연산은 그 앞에 직전노드를 못찾기 때문에 O(n)이 걸린다.
-
더블리 리스트처럼 tail의 앞 노드를 찾는 방법이 있다면 delete/insert 연산이 O(1) 이 걸린다.
-
심지어 싱글리 리스트도 임의의 위치의 다음에다 insert 하는 것은 O(1)이 걸린다.
그러나 임의의 위치 앞에다 insert 하는 것은 O(n)이 걸린다. (그 앞 위치를 바로 못찾으니까)
-
이전의 싱글리 링크드 리스트는 insert는 특정 위치를 찾는 과정을 포함하기 때문에 O(n) 이지만,
여기서는 특정 위치 찾는 과정이 제외되었기 때문에 O(1) 이다. -
head와 tail 에 insert 하는 연산은 O(1) 이다.
-
다만 tail 바로 앞 노드에 대한 insert 와 delete 는 tail 바로 앞의 위치를 못찾기 때문에 O(n) 이 걸린다. (싱글리 리스트는 prev 를 가지고 있지 않기때문)
=> 더블리 링크드 리스트는 tail 바로 앞 노드를 알고 있기 때문에 insert 와 delete 가 O(1) 이 걸린다!
정리
- 임의의 위치에 대한 정보 p 가 주어지는 경우(insert/delete 연산)
-
싱글리 링크드 리스트 insert/delete => p앞에 insert/delete 하는 경우 : O(n)
- 그 앞 위치를 바로 못찾기 때문. position이 주어진다고한들, 맨앞에서부터 찾아와야함(find and insert가 되버림)
-
싱글리 링크드 리스트 insert/delete => p뒤에 insert/delete 하는 경우 : O(1)
-
더블리 링크드 리스트 insert/delete => p앞에 insert/delete 하는 경우 : O(1)
-
더블리 링크드 리스트 insert/delete => p뒤에 insert/delete 하는 경우 : O(1)
- 임의의 위치에 대한 정보가 주어지지 않는 경우 (find and insert/delete 연산)
임의의 위치(position) (=insert 또는 delete할 주소) 가 없는 경우는, 그래도 유일하게 head 와 tail 이라는 position만을 보유하고 있다.
-
싱글리 링크드 리스트 중간 어떤 위치에 대한 insert / delete : O(n)
-
싱글리 리스트 head 또는 head 뒤에 insert : O(1)
-
싱글리 리스트 tail 에 insert : O(1) => append() 메소드임
- head와 tail에 대한 position을 알고있기 때문
-
싱글리 리스트 tail 을 delete : O(n)
- tail의 앞의 위치에 대해 바로 못찾기 때문
- 이래서 싱글리 리스트의 tail을 delete 하는 연산이 비효율적이라고 했던것!
-
싱글리 링크드 리스트 tail 바로 앞에 insert / delete : O(n)
- 마찬가지로 그 앞의 위치에 대해 못찾기 때문
- 더블리 링크드 리스트 tail 앞 노드에 대한 insert / delete : O(1)
- 그 앞 위치에 대한 정보를 prev 로 가지고 있기 때문
