운영체제 : 운영체제 과목의 개요

본 포스트는 학교 수업 강의내용을 단순 정리본 형태로 만든 내용입니다. 평소 포스트와 달리 다소 설명이 부실할 수 있음을 미리 알려드립니다 🙂
Memory
메모리는 컴퓨터 시스템에서 데이터를 저장하기 위한 장치이다.
데이터라는 것은 컴퓨터 시스템에서 동작하려면 0 아니면 1 을 의미하는 것이다. 즉, 2개의 구분가능한 상태의 정보를 말한다. 왜냐하면 이를 확장하면 문자(char)가 되고, 정수(Integer)가 되고, 실수(Float) 가 되기 때문입니다.
그래서 0과 1을 저장할 수 있으려면 0과 1을 구분할만한 state 를 정의해야하는데, 보통 회로적으로는 그게 전압이 될수도 있고, 또는 저항이 될수도 있다. 정리해보자면, 2개의 상태 값(state) 로 구분할 수만 있다면 0과 1로 저장할 수 있는것이다.
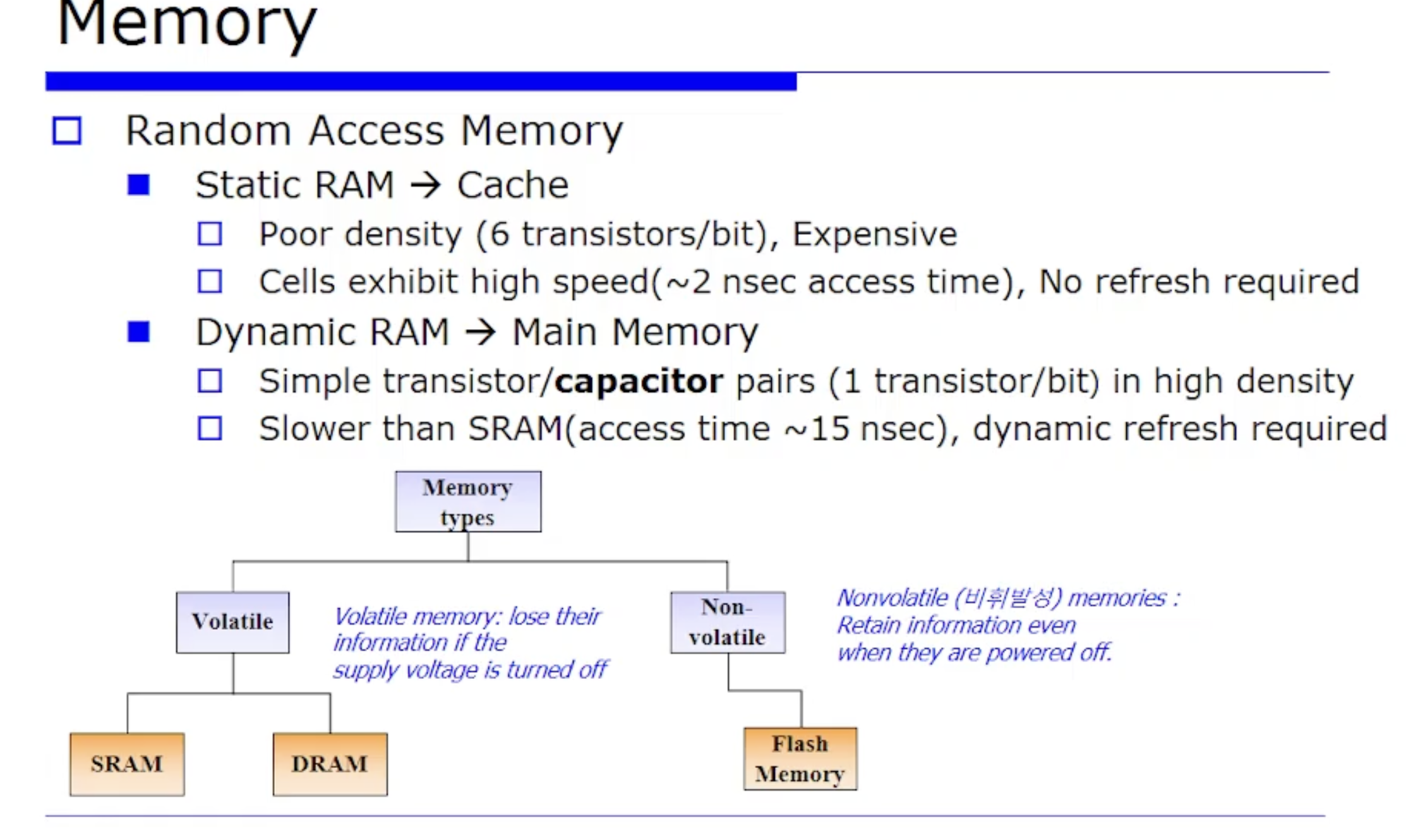
보통 우리가 프로그램을 실행하기 위한 메모리라는 것은 캐시도 될 수 있다. 우리 교재에서 설명하는 메모리라는 것은 정확히는 RAM(Random Access Memory) 이다. Random Access Memory 라는것은 어떤 특정 주소를 가지고 byte 단위의 주소를 접근 가능한 곳에서 정보를 유지하고, 사용자로부터 Call, Read, Write 연산이 가능한 장치를 말한다. 그래야지 Random Access 가 가능하겠죠.
우리가 논리회로때 배웠던 것은 1bit 기억소자인 Filp Flop 과 Latch 이다. 이 기억소자 안에는 트랜지스터로 구성된다.
SRAM, DRAM
정리하자면, 컴퓨터 시스템에서 주요 메모리로는 RAM으로써 2가지의 접근(SRAM, DRAM)이 있을수있는데, 역사적으로 DRAM 을 대용량의 메인 메모리로 진화했고, SRAM 은 캐시(cache) 에 사용되었다.
- SRAM, DRAM 의 공통점 : 전원이 나갔을때 데이터가 손실되는 휘발성(volatile) 장치이다.
휘발성이 아닌 비휘발성 장치를 사용해서 전원이 나가도 데이터를 보존하고 싶을경우, secondary device 라 할 수 있는 보조기억장치인 Flash Memory 를 사용한다.
Flash Memory
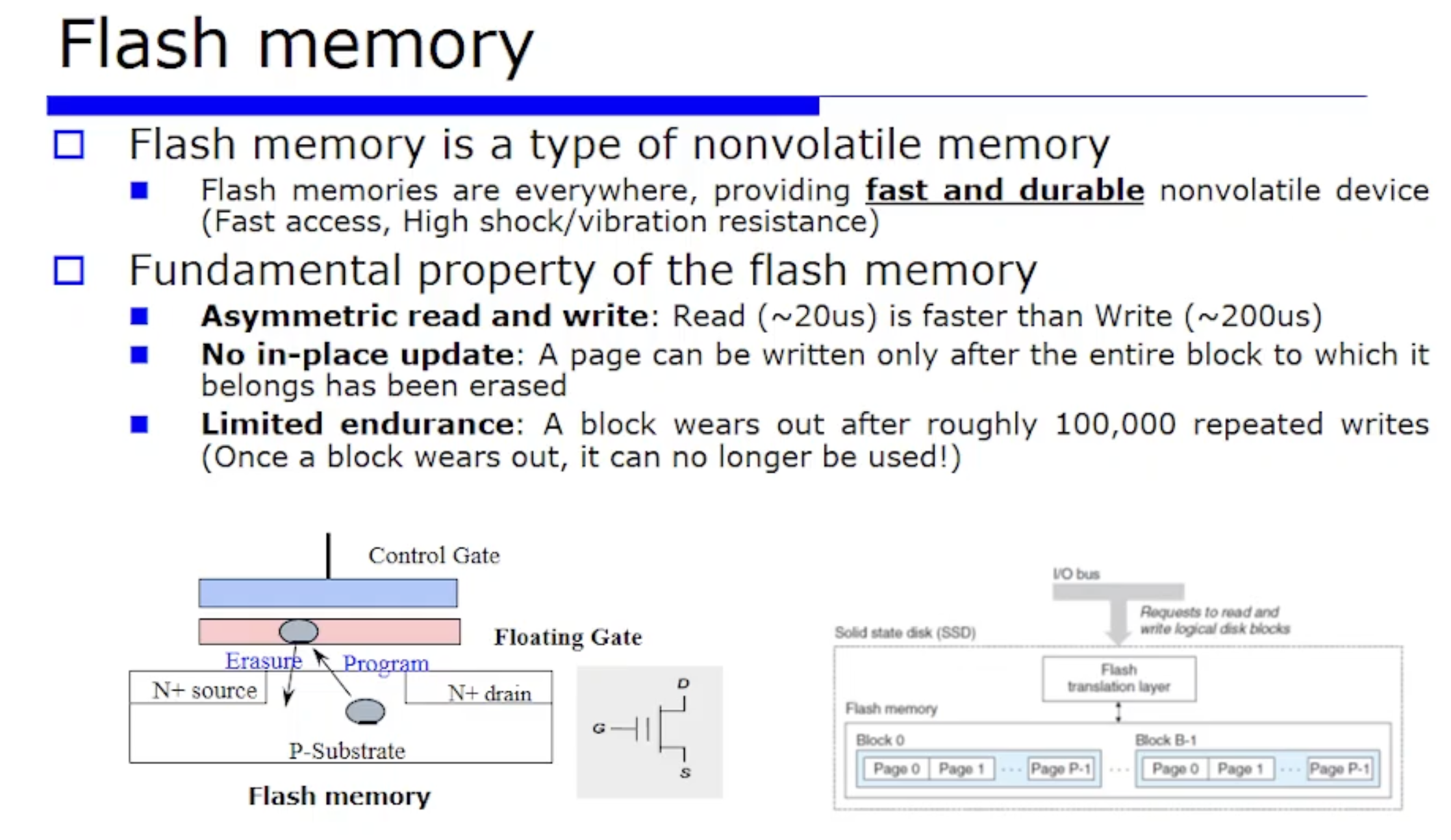
Flash Memory 는 다양한 장치로써 사용하고 있다. 전통적으로 OS 측면에서 secondary device 는 어떻게 발전해왔는지 생각해보자. 옛날에는 테이프 디바이스가 사용되었고, 그리고 최근에도 여전히 하드디스크 드라이브가 사용 되었다.
그런데 Flash Memory 를 하드디스크와의 상대적인 장단점을 비교해보면, 일단 첫번째로 빠르다는 장점이 있다.
또 하드디스크는 외부 충격(ex. 차량 내부의 블랙박스가 충격받는 경우) 에 약하다. 충격을 받으면 데이터가 손상될 수 있다는 특징이 있으나, Flash Memory 는 전자장치로써 외부 충격에 강하다. 따라서 요즘 대부분의 장치(ex.핸드폰)은 Flash Memory 로 구성되어 있다. SSD 같은 것들도 모두 Flash Memory 기반의 장치이다.
Flash Memory 의 3가지 특성
-
Read 연산이 Write 연산보다 더 빠르다
-
in-place update (제자리 업데이트) 가 안된다 : in-place update 란 하드디스크 드라이브에서 내가 특정 sector 에 데이터를 write 할때, write 된 어떤 값이 있으면 바로 그 제자리에서 값이 업데이트 되는 것을 의미한다. 반대로 Flash Memory 의 경우 그 블록 메모리 단위에서 write 된 데이터가 있으면 raise 하고나서 다시 써야하는 어떠한 제약들이 있다. 즉, 이미 write 했던 데이터가 있다면 그 자리에서 바로 write 를 연속적으로 할 수 없다는 것이다. 따라서 다른 자리에 데이터를 write 하거나, 또는 기존 데이터를 삭제하고 그 자리에 새로운 데이터를 write 하는 방식으로 진행해야한다.
-
제한된 연산 횟수 : 특정 블록 단위에 대해 제약된 연산수가 정해져있다. 10만번 이상 쓰기연산을 진행시 해당 블럭은 더이상 연산을 받아들이지 못한다. 이를 해결하기 위해선 여러 블록에 연산을 골구로 분포시키는 알고리즘이 필요하다.
Hard Disk Drive (HDD)

또 secondary device 를 볼때 non-volatile device 로써 하드디스크 드라이브를 가장 많이 생각한다.
어떤 방향을 지정하고 전류를 흘려주면 N극 또는 S극으로, 즉 2개의 구분 가능한 상태를 만들어내는 방식으로 동작한다. N극이면 0으로, S극이면 1로 한다. 전원이 나가면 이미 자성체에 자기화가 되었기 때문에 그 데이터를 유지하는 일반적인 non-volatile device 로써 다양한 형태로 활용되고 있다.
SSD

SSD 는 아까 살펴본 Flash Memory 기반의 스토리지(저장소)이다.
전통적으로 운영체제는 HDD 에 초점을 맞추어 진화했다고 말했었다. 그런데 새로운 기술이 도입되었다.
아까 Flash Memory 의 특징은 말했듯이 Read & Write 의 비대칭성이 있고, in-place update 가 안되고, 제한된 연산 횟수가 있다고 했었다. 제한된 연산 횟수를 극복하기 위해서 알고리즘을 사용한다고 했었다.
따라서 인터페이스는 다를 수 밖에없다. 우리가 하드디스크를 Read, Write 하듯이 SSD 를 Read, Write 한다면 무조건 성능 저하가 발생할것이다. 따라서 마치 conventional disk 를 접근하는 것 같은 인터페이스로 통합되게 설계가 될 것이다. 이런 하드디스크뿐만 아니라 이런 Flash Memory 또한 기술이 필요한것이다.
그래서 아까 언급한 Flash Memory 의 특성들을 감추면서 동시에 하드디스크 드라이브의 functionality 를 가져가려고 하는 소프트웨어 계층을 FTL (Flash Translation Layer) 라고한다.
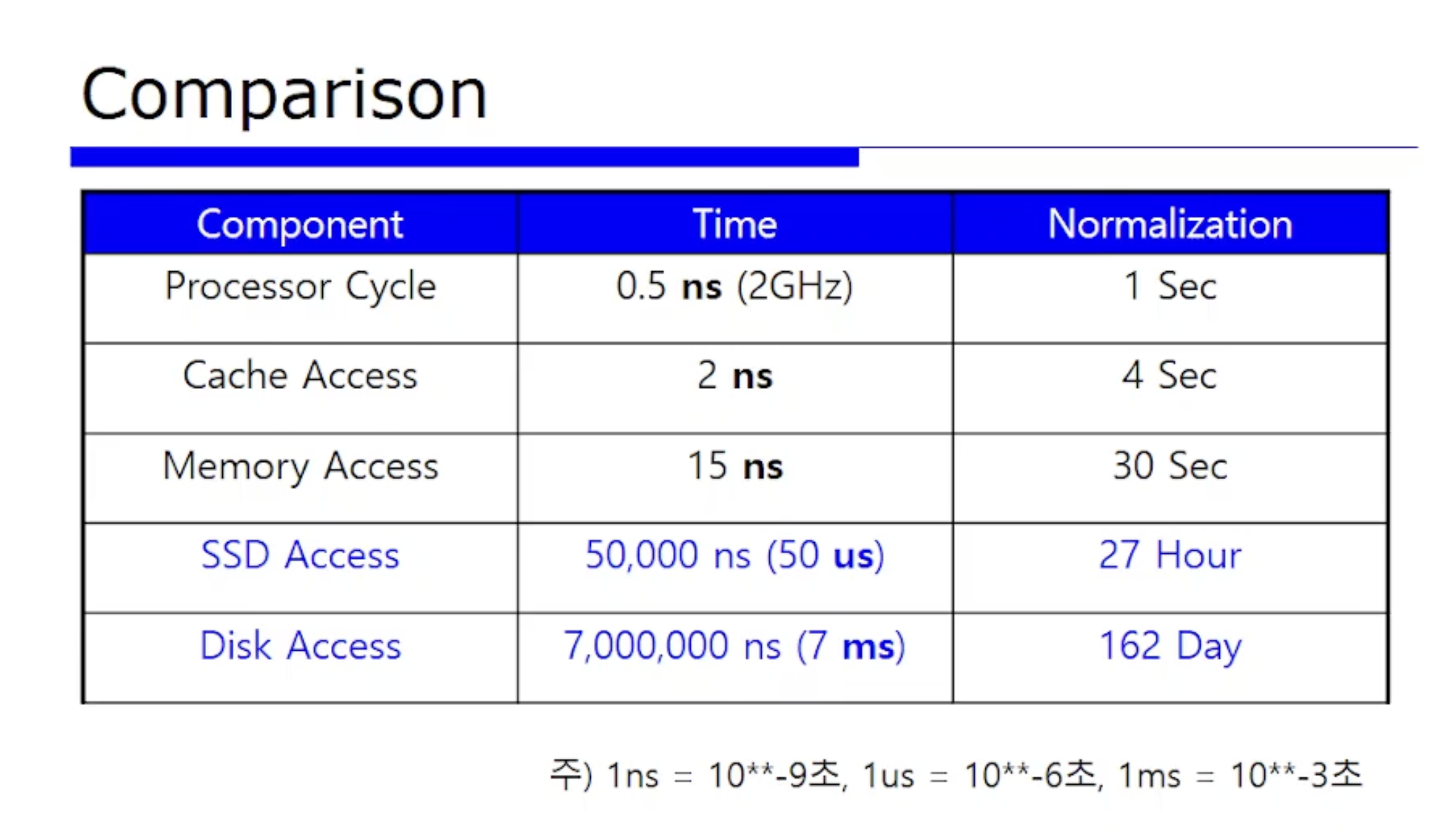
위 숫자들 외울필요x. 그냥 단순한 예시임
Processor Registers

우선 Processor (처리기) 입장에서는, CPU 아래에는 다양한 종류의 레지스터들이 있고, ALU 가 있고, 캐시가 있습니다. 이 캐시는 아까봤던 SRAM 이라고 보면되고, 또는 Filp Flop 의 집합으로 봐도된다. 그들이 모인게 레지스터이고, SRAM 이기 떄문이다.
다양한 레지스터가 있고, 각 레지스터들을 다양한 종류의 레지스터로 분류해볼 수 있다. 가장 쉽게 분류할 수 있는 분류기준은, 가장 일반적인 레지스터라 말할 수 있는 범용 목적의 레지스터가 있고, 또는 특수 목적의 레지스터로 분류할 수 있다.
범용 목적의 레지스터의 목적은 다양한 목적이 있을수있지만 외부의 메모리나 디바이스에 접근할때 이러한 메모리 레퍼런스를 메모리 접근 엑세스를 최소한의 방향으로 진화가 될 것이다. 그를 위해서 레지스터가 진화되고, 그리고 그 레지스터의 방향을 다양한 목적으로 가져서 컴파일러나 최적화하는데 사용된다.
그래서 이러한 범용 목적의 레지스터는 보통 이름이 R1, R2, R3, ... 로 이름을 짓거나 또는 A, B, C, D, .. 이런식으로 이름이 네이밍된다.
또 만약 ALU 에서 계산한 결과물들을 다시 메모리에 쓰면 시간이 너무 오래걸릴것이다. 따라서 메모리 대신에 레지스터에 저장해놓는다.
Processor Registers

특수 목적의 레지스터의 종류는 여러가지가 있을 수 있다. 이 슬라이드 에서는 핵심적인 레지스터들에 대해 소개하고있다. 그들에 대해 소개해보곘다.
Program Counter
다음에 수행할 명령어의 주소를 저장(fetch) 하는 레지스터
Instruction register (명령어 레지스터)
만약 fetch (임시저장) 를 하게되면, 예를들어 1000번지 주소에 있는 명령어를 어딘가로 가져와서 저장해놓고 실행한다. 이때 가져올 대상이 바로 IR 레지스터이다.
최근에 fetch 된 명령어들을 저장하는 레지스터라고 할 수 있다.
Program Status word (PSW)
프로그램 상태 레지스터. 프로그램 처리기(CPU) 의 상태정보가 이러한 flag 들의 집합 형태로 있는 레지스터이다.
예를들어서 한 단어가 32비트라면, 32가지의 어떤 bit 단위로써 다양한 상태(state)를 저장할 수 있는 레지스터이다.
이 PSW 레지스터는 Condition Code 로써 활용될 수도 있고, 또는 Interrupt flag (Interrupt mask 라고도 부름) 로 사용되거나 privilege level 로써 활용될 수 있다. 이들은 뭘까?
Condition Code
예를들어 if 문이 있을때 결과값으로 0 또는 1 과 같은 잡다한 상태정보를 가지고있고, 이 정보는 jump 를 할때 활용된다. 이렇게 산술, 논리연산에 대한 정보들을 Condition Code 라고 한다.
Interrupt
그리고 다음 시간에 배우겠지만, Interrupt 라는 것은 활성화 또는 비활성화 할 수 있다.
privilege level
또는 privilege level 이라고해서 프로그램 CPU 가 제공하는 2가지 모드가 있는데, 유저모드인지 커널모드인지를 제공한다. 유저모드인 경우 접근이 제한되는것들이 있고, 커널모드는 모든지 접근이 가능하다. 이러한 privilege (특권) 을 설정할 수 있고, 이 설정값을 0 또는 1로 저장한다.
Memory address register / Memory buffer register
처리기(Processor) 입장에서도 어떻게 보면 메모리도 외부에 있는 장치가 될 것이다. 어떤 메모리에 접근하기 위한 인터페이스가 필요한것이다. 그래서 실질적으로 우리 교재에는 간단히 시스템 버스라고 되어있지만, 그 내부는 address bus, data bus, control bus 등으로 세부적으로 나누어져있다.
추상화해서 어떤 디바이스에다 1000번지에 있는 데이터를 제공해달라고하면, 그러면 MAR에 1000번지를 입력하면 인터페이스에서 MBR을 통해 데이터를 전달받는 것이다. MBR이 "1000번지에는 어떤 데이터가 있어~" 라고 결과값을 리턴해준다.
=> 정리 : MAR은 현재 메모리로부터 fetch 한 주소가 저장되어 있는 레지스터이고, 그 결과로써 데이터가 저장되는 곳을 MBR 이라고한다.
ISA

- 명령어 집합 구조(Instruction Set Architecture)
- 명령어와 machine 의 state 를 정의한다. 이때 machine 의 state 는 레지스터와 메모리로 구성된다.
- ISA 는 인터페이스이다. 프로그래머 관점에서 볼 수 있는 최하위의 API이다. 명령어에 대한 set, instruction 과 그것에 따르는 해당 머신의 state 를 규정하고있다.
=> 이게 무슨 말인가? : 컴퓨터 시스템은 굉장히 복잡한 머신이다. 따라서 우리가 컴퓨터 내부를 온전히 다 이해하기란 쉽지않다. 그래서 추상화시켜서 이 컴퓨터 시스템의 연산으로써 명령어를 보유하고있고, 그 연산,즉 명령어에 따라서 machine state 가 어떻게 바뀔것인지에 대한 명세가 필요한것이다. 그게 ISA 마다 다른 것이다.
Instruction Format

그러면 이제 명령어(Instruction) 이 무엇인지 알아보자. 직전에 알아본 ISA 에서 Instruction Set (명령어 집합) 이 무엇인지 알려면 당연히 명령어가 어떤 종류가 있고 어떻게 정의되어 있는지 살펴봐야한다.
명령어는 가변길이(길이가 변함) 일수도 있고, 반대로 길이가 고정되어 있을수도 있다. 여기서는 길이가 고정되어 있는 어떤 가상의 머신을 가정하면서 설명하고있다.
명령어의 구성요소는 크게 2가지이다. 하나는 Opcode (명령어 코드) 이고, 디른 하나는 Operands (피연산자) 이다. Operands 는 보통 명령어를 수행하기위한 입출력으로써 사용될 수 있는 주소를 뜻한다.

예시를 보자. 한 명령어가 위처럼 16bit 라고 가정하면, Opcode 로는 4bit 를 쓰고 나머지 12비트는 피연산자로써 사용하겠다라는 것이다. 피연산자는 보통 주소(address)가 올 수 있고, 상수도 올 수 있다. 또한 아키텍처별로 이 피연산자가 1개가 있을수도있고, 2개 또는 3개가 일수도있다. Opcode 가 4비트를 쓴다면 나올 수 있는 Opcode 의 종류는 2^4 = 16가지이다. 즉 16가지의 Opcode 가 존재하겠구나(더하기, 빼기, 곱하기, ... 등의 연산이 16가지) 라고 이해하면된다. 또 address 주소의 길이는 12비트이구나 라는것도 유추해볼 수 있다. 그러고 아키텍처 측면에서는 소프트웨어 개발자가 주소가 12비트 체계라는 것을 인지하고 주소값 구성이 좀 부족하겠는데? 또는 넉넉하겠다 라고 생각해볼 수 있는 것이다.

우리 교재에서는 Opcode, Opcode 의 길이나 포맷등을 정의해놓지않았다. 우리 교재에서는 Opcode 종류의 일부로써 3가지로 설명하고있다. 만약에 Opcode 가 0001 이라면 16진수로 1이다. 즉 Opcode 가 1이면 메모리로부터
가져와서(Load) AC (이때 AC 란 범용 레지스터 종류중 하나임) 에다, 즉 범용 레지스터에다 적재하라는 뜻이다.
또는 0010인 경우 레지스터에 있는 것을 메모리에 저장하라는 뜻이된다. 이때 정확히 어디에 저장할것인지에 대한 정보가 인자로써 들어올 수 있다.
0101인 경우 어떤 메모리에 있는 값을 현재 레지스터에 저장되어 있는 기존값에다 더하라는 뜻. 예를들어 기존레지스터에 3이 저장되어있고, 메모리에서 새롭게 읽어온 값이 2라면, 레지스터의 값은 3+2 = 5 로 최신화된다.
Instruction Fetch
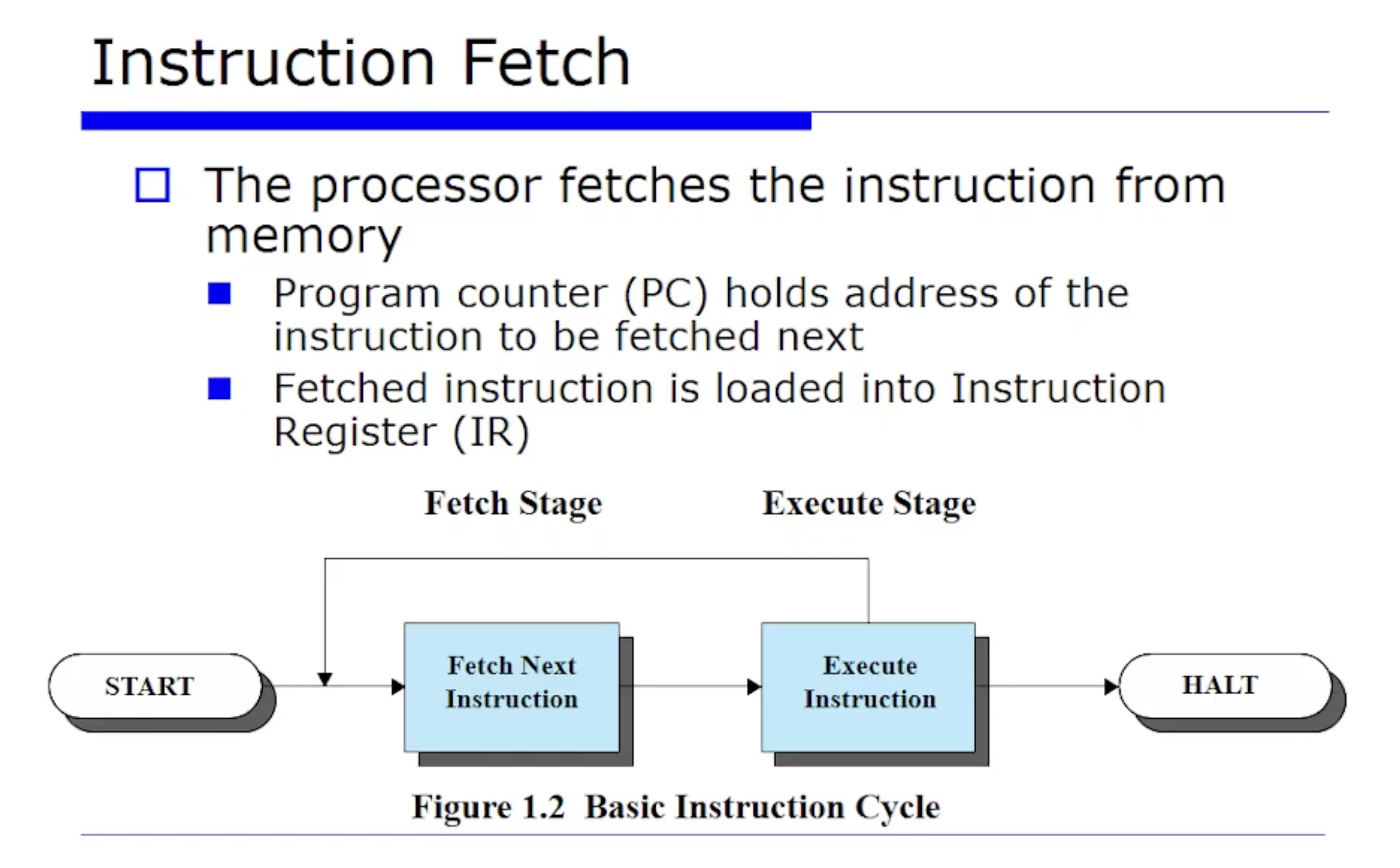
다음으로 명령어(Instruction) 이 어떻게 수행되는지 가장 심플하게 단계를 나누어보자면 fetch + execute 이렇게 두 단계로 구성된다.
- fetch : PC 에는 다음에 수행할 명령어의 주소가 저장되어있을텐데, PC에서 명령어를 꺼내서 IR 레지스터에 저장하는 것이다. 즉 PC 에는 fetch 할 주소가 있는것이고, fetch 를 하고나면 결과물 명령어가 IR 에 저장되는 메커니즘이다.

그러고 당연히 fetch 에 성공하고나면 실행(execute)을 해야할것이다. execute 를 하려면 당연히 디코드(Decode) 라는 것을 해야한다. 왜냐하면 fetch 해서 명령어들을 보고나면 그 명령어들이 뭔지를 알고(분석하고) 실행을 해야할것이다.
그래서 그 fetch 한 명령어에 0~3까지, 즉 4비트를 정의했다면 16가지의 Decode 값이 나올 수 있을것이다.
우리 교재에서 설명하고 있는것은 Opcode 에 대한 얘기를 하고있다. 현재 컴퓨터 시스템의 여러가지 종류가 있을텐데, Opcode 는 그 종류에 따라 4가지 타입으로 분류할 수 있다. 그 종류로는 Data Processing, Control, Processor-memory, Processor-I/O 가 있다.
- Data Processing : 산술, 논리 연산과 관련된 명령어
- Control : 여기서의 Control 이란 Flow Control 이다.
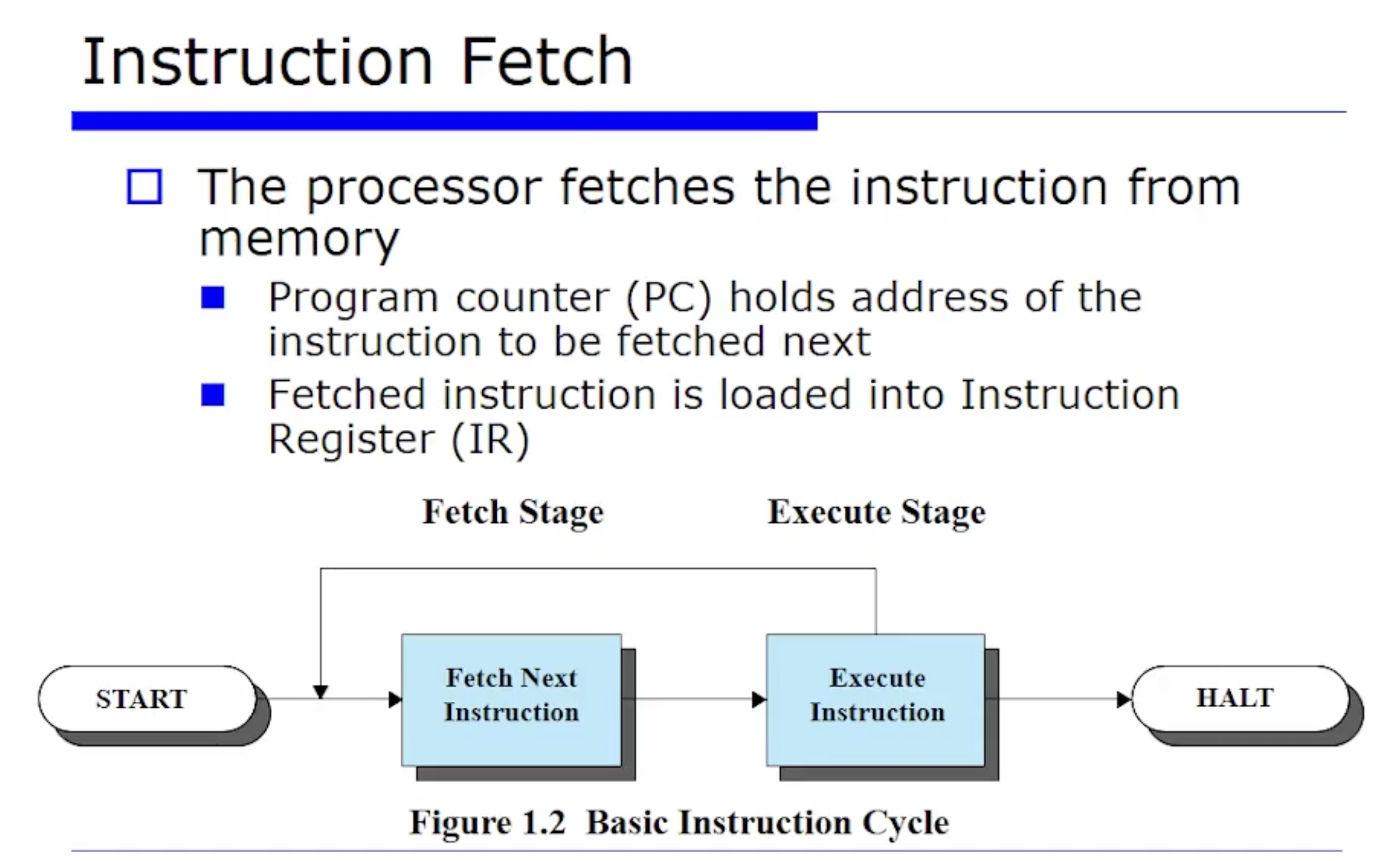
우리가 위 그림의 2단계에서 보면, 명령어를 fetch 하고 실행하는 이 과정을 다시 반복하는 모습을 보인다. 이는 PC 가 자동으로 다음 명령어 주소를 가리키기 때문에 가능한것이다. 그러면 fetch 되면 다음 명령어가 순차적으로 차례에 맞게 fetch 되고 실행될것이다. 하지만 실제 프로그램은 이렇게 돌아가지 않는다. 갑자기 jump 도 할것이고, if문이나 while 문으로 인해 control 이 바뀌게 된다.
그렇다면 이 control 에서 지원하는 명령어가 뭐냐있냐면, 무조건적인 jump 명령어도 있고 또는 조건적인 Jump 명령어도 지원해준다. 또는 call 명령어도 있을것이다.
-
Processor-memory : 처리기(processor)와 메모리간의 통신을 위해 사용되는 명령어(ex. 아까 살펴봤던 Load 명령어(메모리에 있는것을 레지스터로 Load 해오는 명령어), Store 등 )
-
Processor-I/O : 프로세스와 모듈 디바이스간의 I/O 통신을 위한 In 명령어, Out 명령어
Instruction Cycle
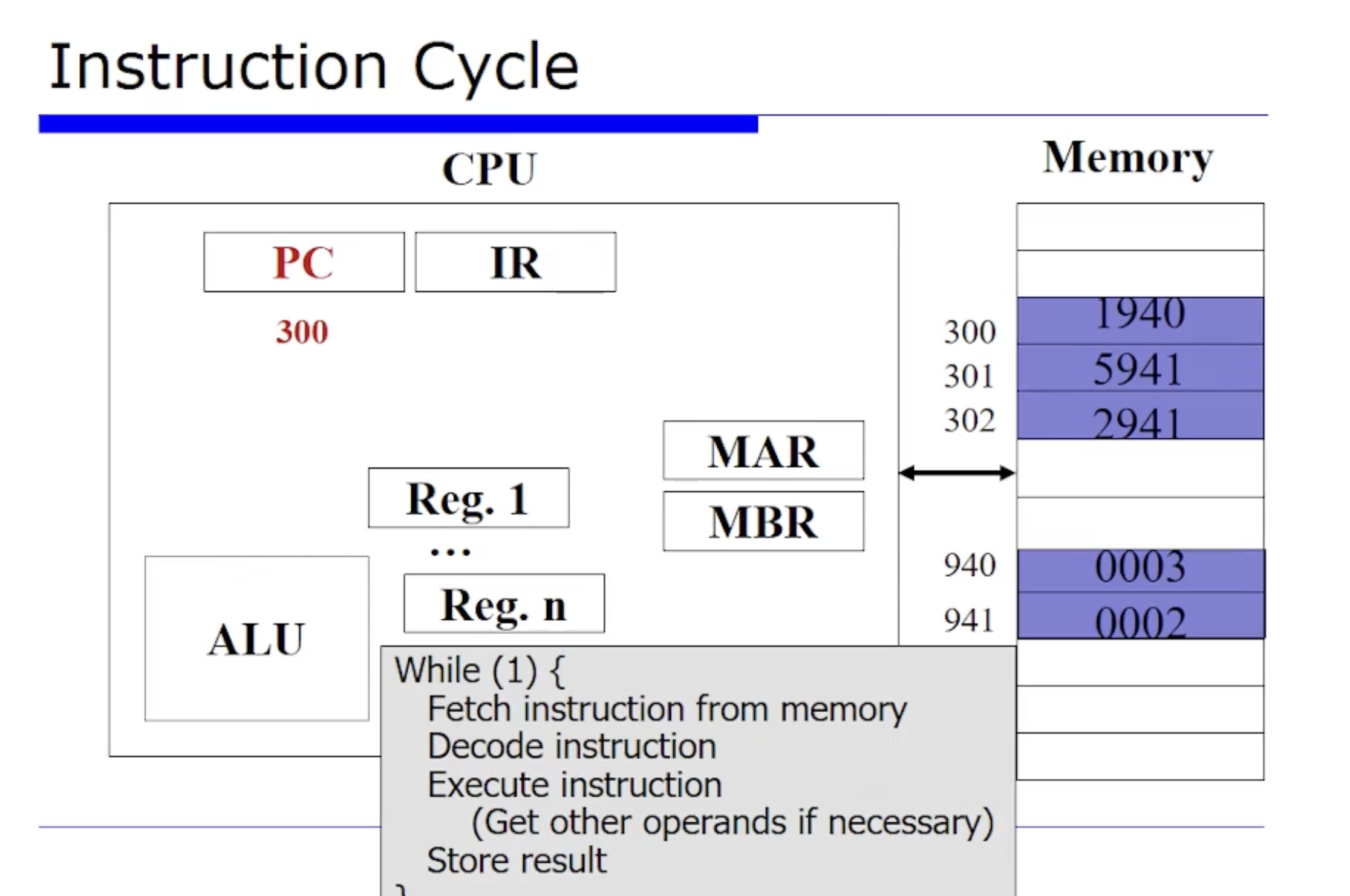
먼저 CPU 의 한 명령어가 어떠한 사이클을 돌며, 해당 사이클이 끝났을 떄 다른 하나의 명령어가 수행하고 machine 의 state 를 바꿀것이다. 운영체제의 관점에서 machine 의 state 는 레지스터와 메모리가 어떻게 바뀌는지에 따라 변하게된다. 이때 레지스터와 메모리의 어떤 부분이 어떻게 변화되는지 자세하게 알아보자.

CPU 는 쉽게보면 위처럼 while 문을 돌면서 명령어들을 메모리로부터 fetch 해오고 decode execution 을 한다. 필요하다면 메모리에 또 접근하는 방식으로하고, 한 명령어가 끝나면 또 다른 명령어에 대해 이 과정을 반복한다. 이런 메커니즘을 반복하는 단순한 기계가 CPU 이다.
아무튼 여기서는 프로그램이 실행될 떄 어떠한 프로그램이 위처럼 메모리에 올라와있다고 가정하고있다. 이것은 우리 교재에서 말하고 있는 가상의 머신이고,
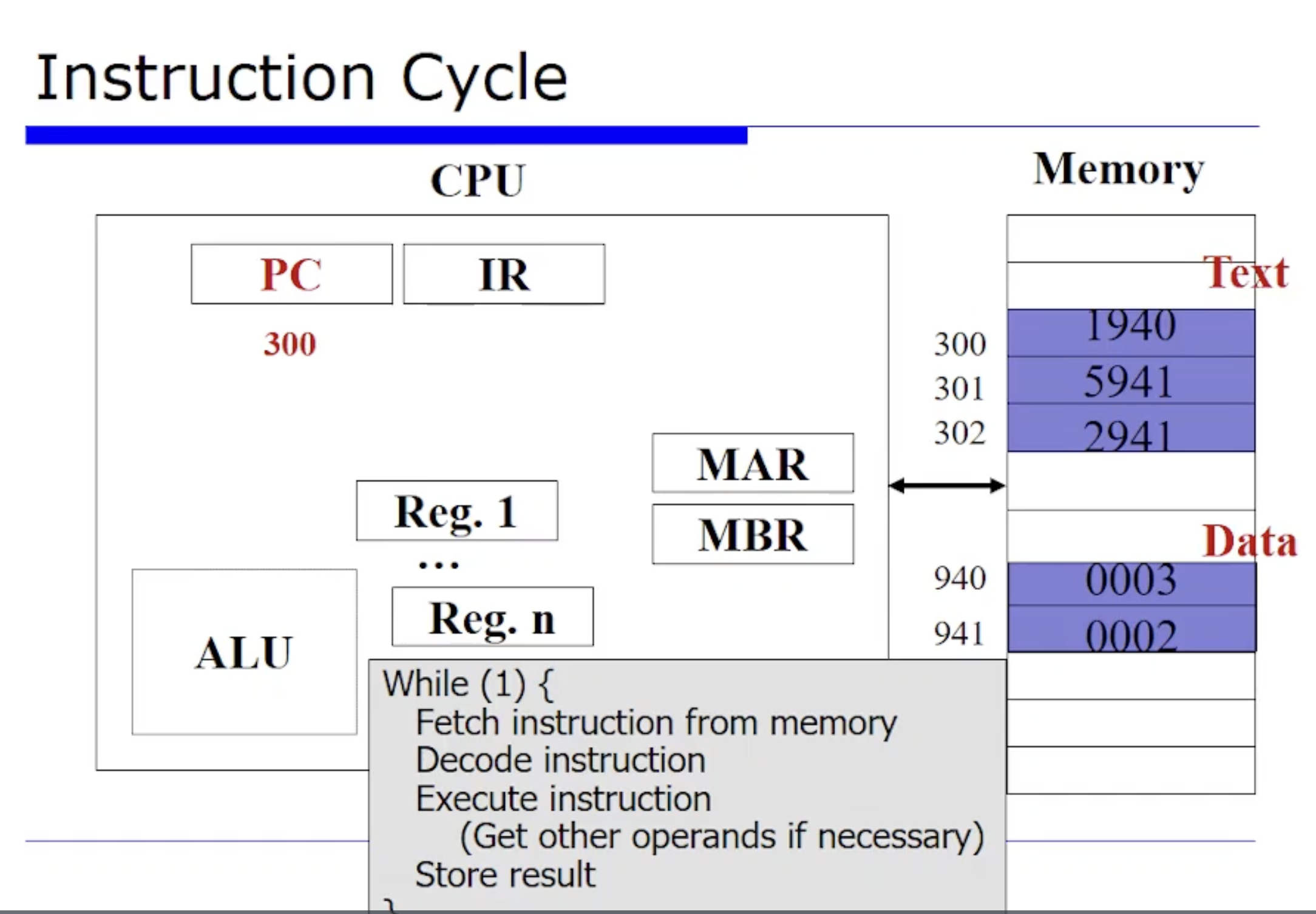
또 위 그림에서

이들은 명령어와 데이터인데, 우리가 후반부에서 프로세스를 공부하면서 Segment 를 공부할텐데, 이런 명령어들이 올라가있는 곳을 Text Segment, 데이터가 올라기있는 곳을 Data Segment 라고한다. (일단 알고만 있자!)
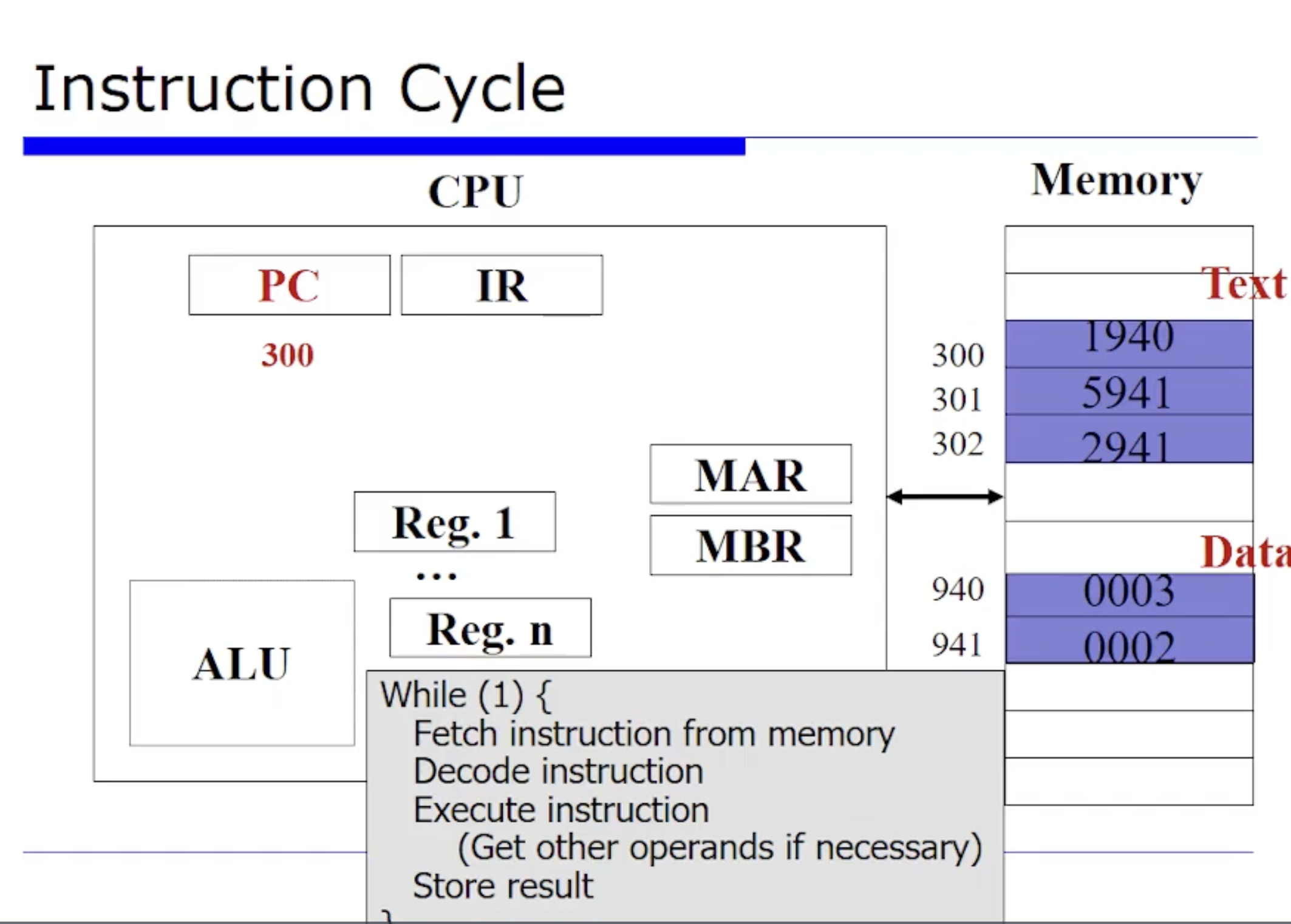
아무튼 CPU 는 여기에 있는 명령어들을 하나씩 하나씩 fetch 해서 반복적으로 실행(execute) 하는 기계인것이고, 그 과정에서 우리가 배운 범용 레지스터와 특수 목적의 레지스터가 어떻게 관여했는지를 한번 유기적으로 살펴보자는 것이다.
PC 가 현재 300을 가리키고 있다는 것은 이 프로그램은 현재 300번지에서 수행할 사례(?) 라는 것이다. 300번지에서 이 명령어를 fetch 해야한다.
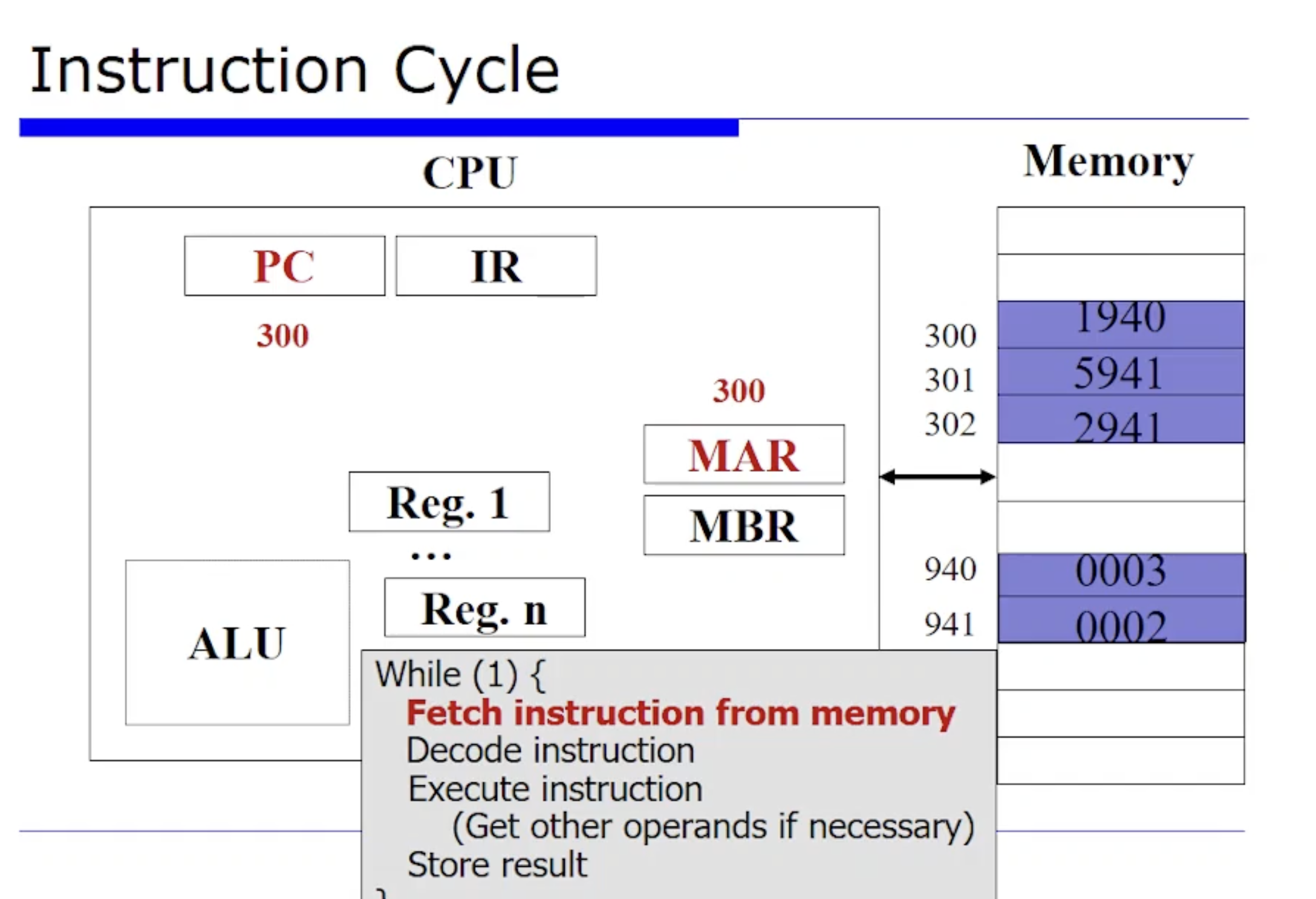
이때 메모리에 I/O 을 수행할 인터페이스로써 MAR, MBR 레지스터가 관여할 수 있다. 그래서 300번지 메모리에 요청을하고, 그러면 300번지에 있는 1940 값 데이터가 MBR 에 저장이된다.
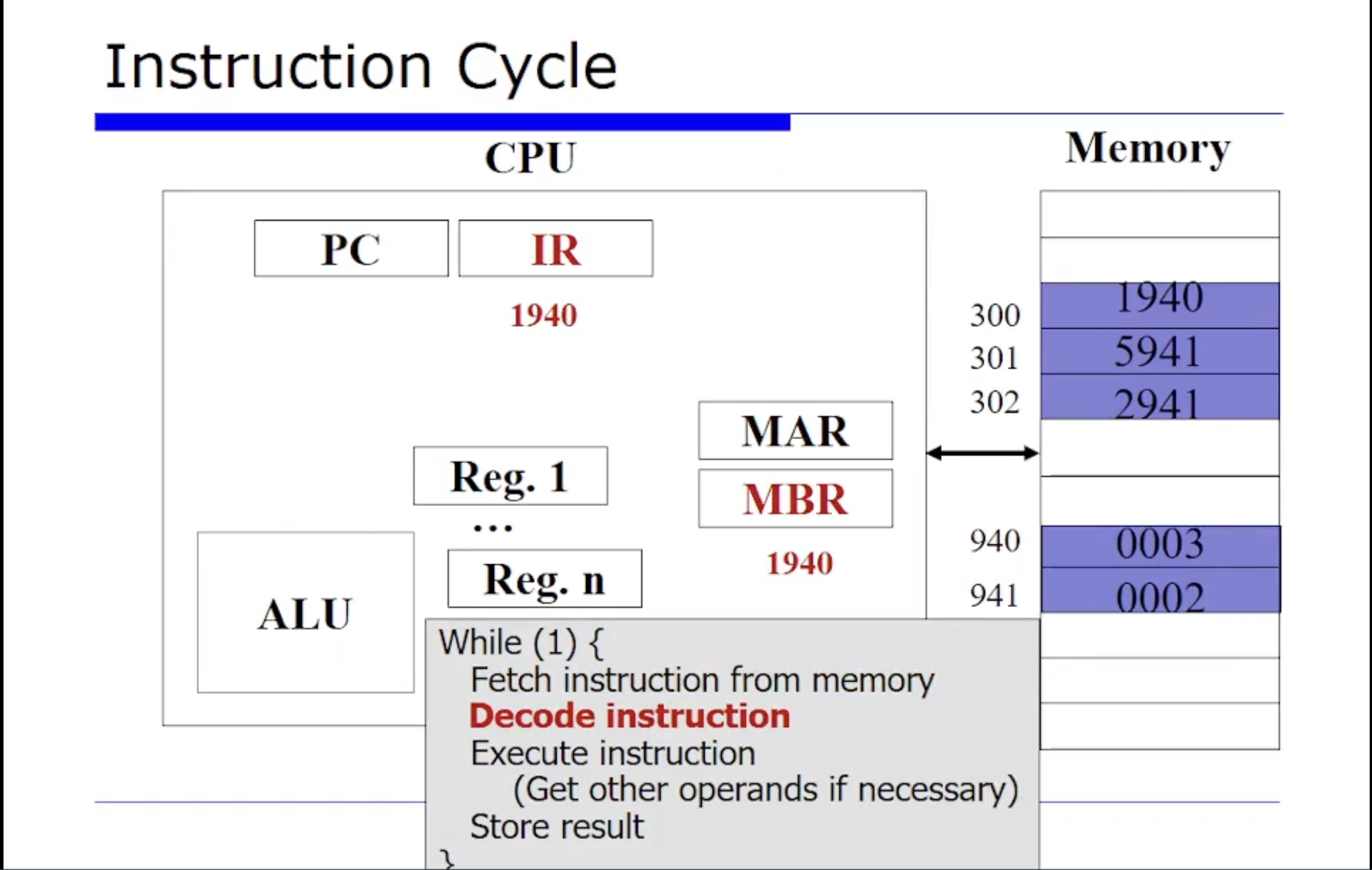
그리고 최종적으로 이 데이터는 명령어 레지스터(IR) 에 1940 이 오게된다. 여기까지가 바로 fetch 단계이다.
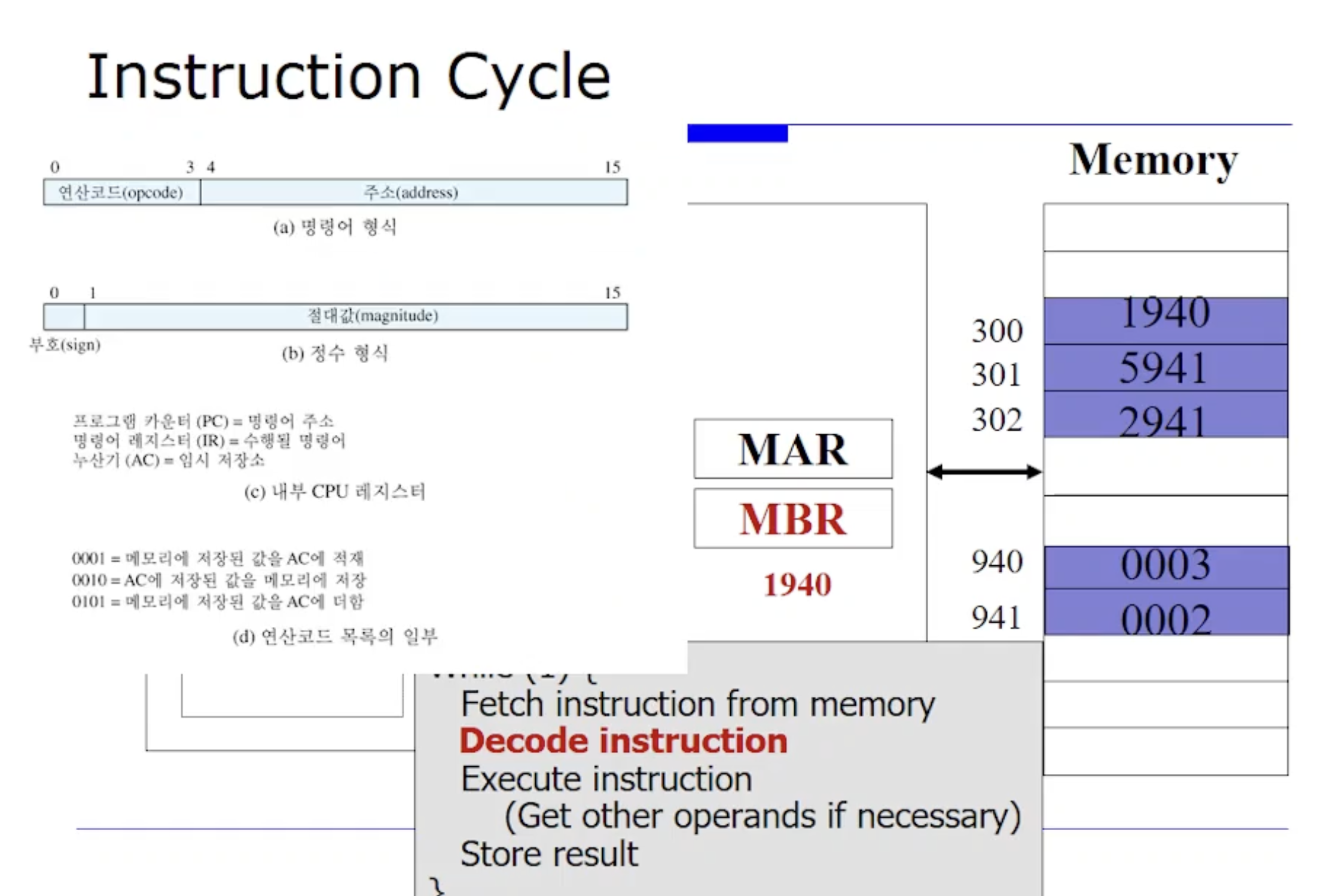
그 다음으로 execution 단계로 간다. execution 하기 위해서는 먼저 1940 이 IR 레지스터에 있는데, 이를 디코드(decode) 해야한다. 그러면 Opcode 와 Operand 로 구분해야하는데, 얘는 한 word 가 16비트라고 가정하고 있는데 16진수로 바라봐보자. 16진수는 한 자리가 4비트이다. 그러니까 16진수에서 1940 중에 Opcode 값이 1이다. 그리고 Operand 는 16진수에서 나머지 3자리를 차지하는 940 이다.
이때 Opcode 값인 1은 아까 가상의 머신에서 가정한것에 따르면, 메모리에 저장된 값을 AC 에 적제하는것이였다. 즉 Opcode 1은 Load 연산이다. 정리하자면, 940번지에서 값을 Load 해오는 것이다.
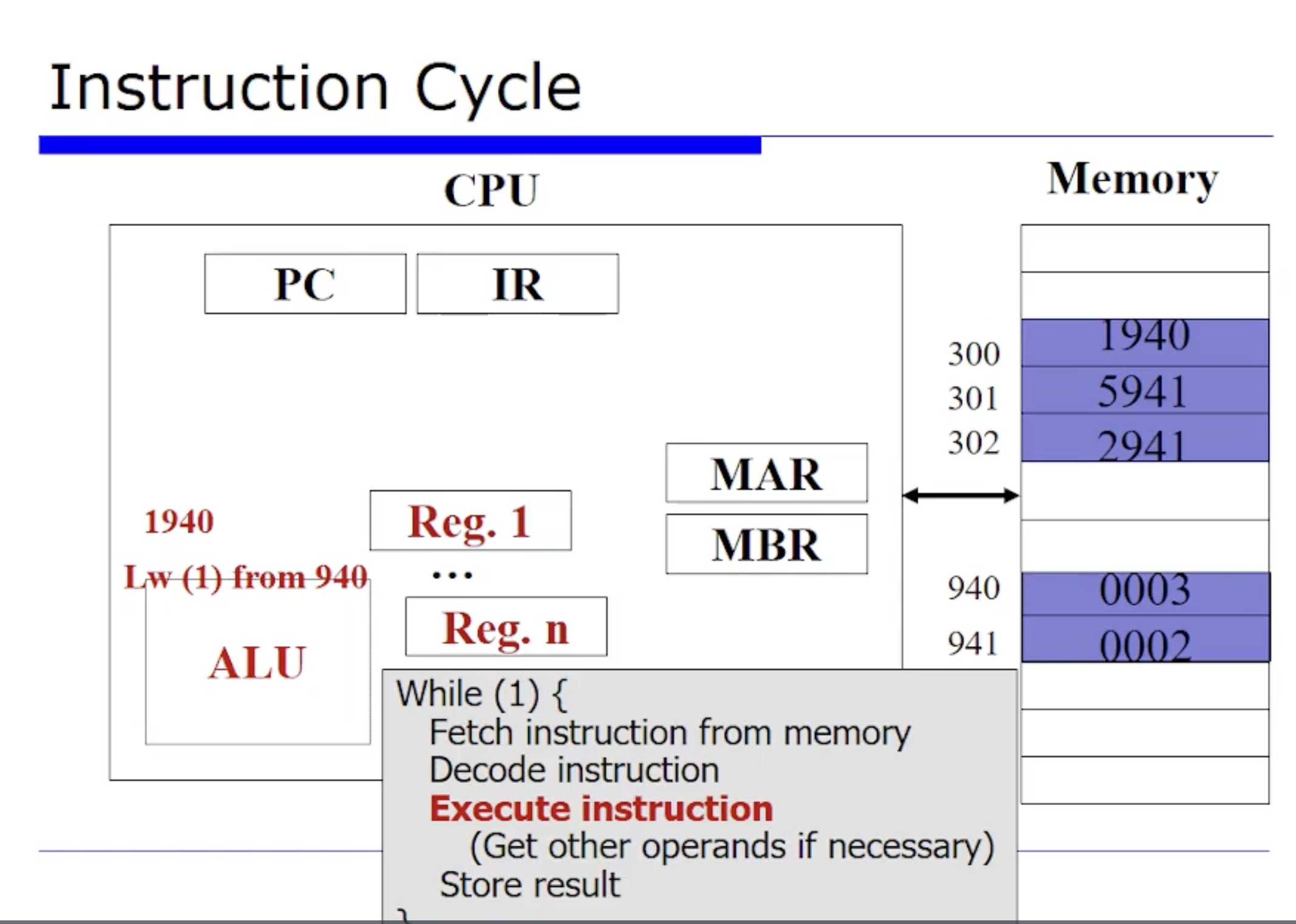
그러면 Load 연산을 진행하기 위해 메모리에 먼저 요청을 보내야한다. 그러면 메모리의 940번지 데이터를 읽어와야한다.
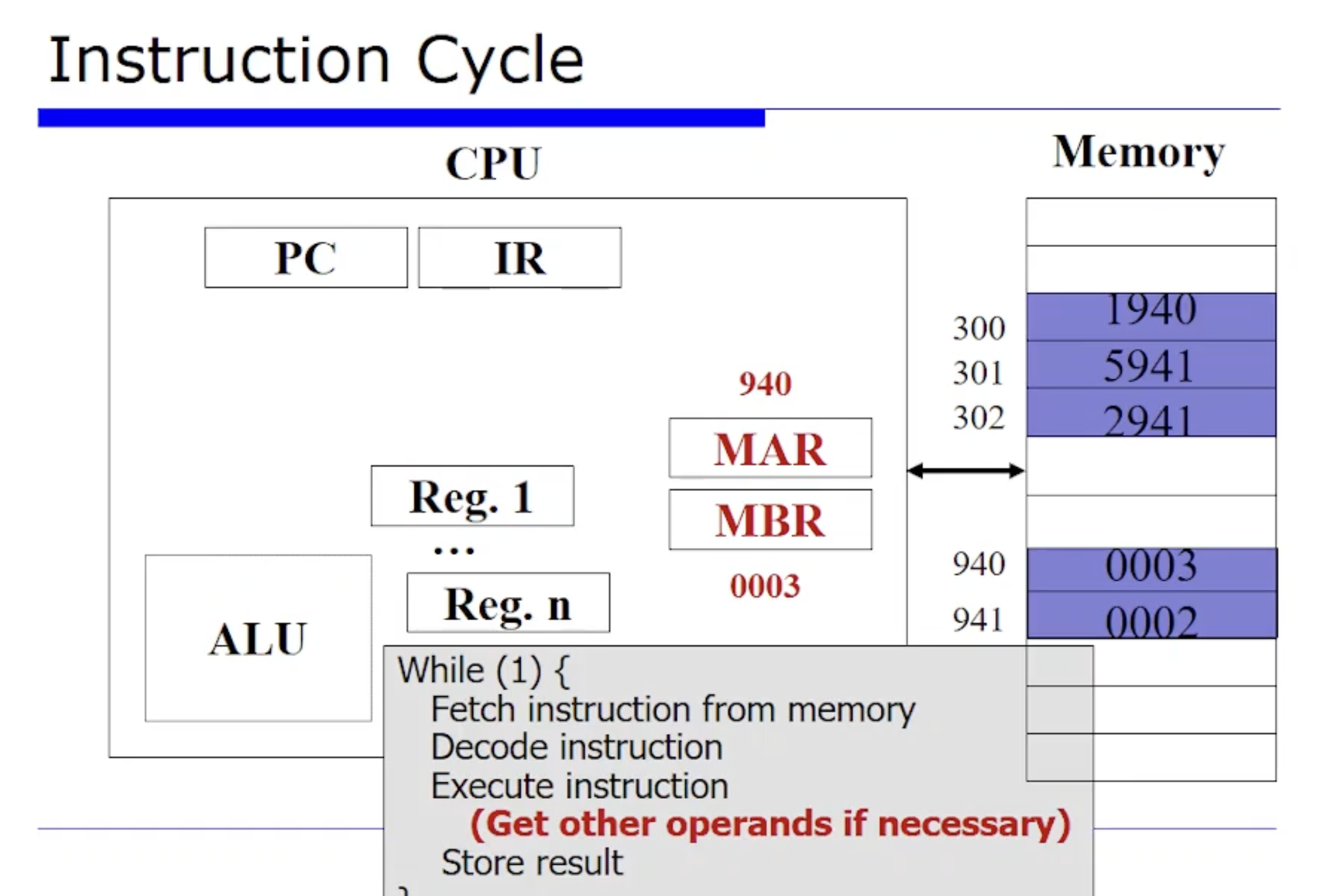
이 때문에 MAR 에 940 을 저장하게된다. (MAR은 현재 메모리로부터 fetch 한 주소가 저장되어 있는 레지스터라고 했었다.) 그리고 메모리에 저장되어 있는 3이라는 값이 MBR 에 저장될것이다.
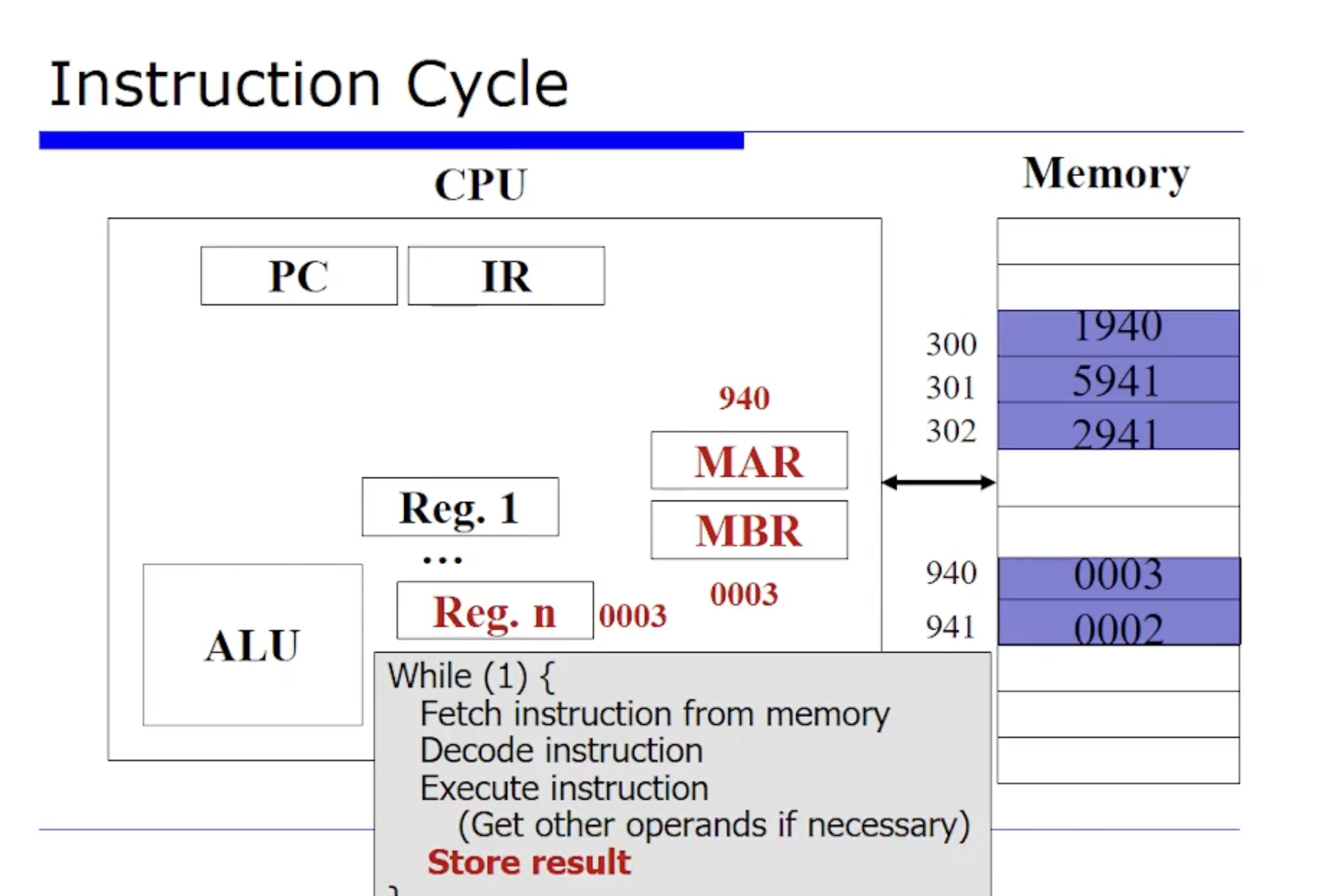
그래서 최종적으로 AC 레지스터 어딘가에 3 이라는 값이 저장이 될 것이다.
결론적으로, 우리가 어떤 메모리로부터 명령어 사이클이 발생할 때 memory bus 를 한번만 타는게 아니라, 2~3번 탈수도 있는 것이다. 명령어를 fetch 하고 Load 하는 과정을 여러번하면서 memory bus 를 탈수있다.
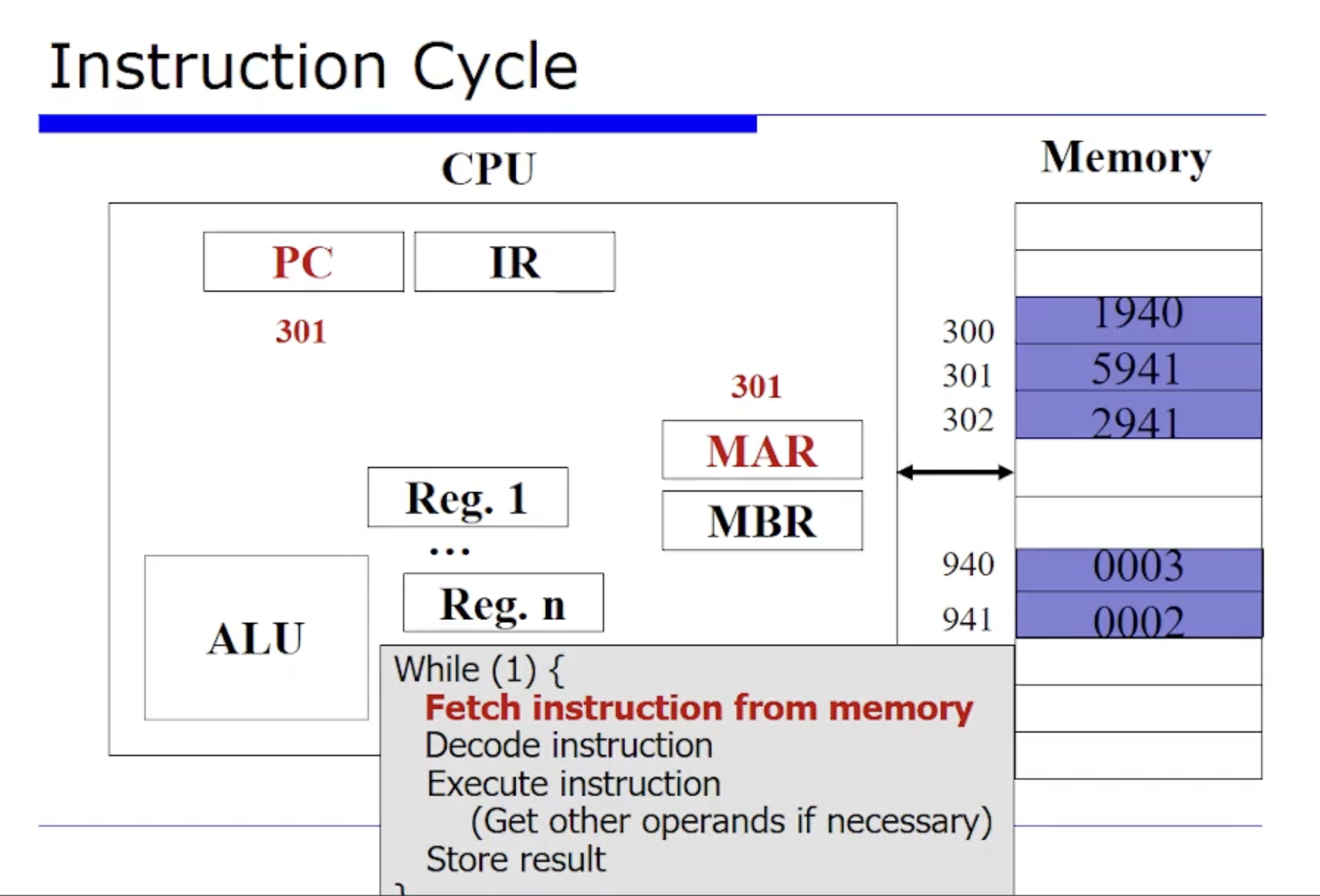
그리고나서 하드웨어적으로 그 이전의 PC 는 자동으로 알아서 그 다음에 수행할 명령어로 업데이트된다. 위와 같이 PC 가 301로 업데이트되었다. 301번지 이므로 메모리에서 fetch 를 해와야한다. 그래서 메모리를 접근하기 위해서 MAR 에 301을 요청하고, 그러면 301번지의 값인 5941 이 MBR 에 읽혀올것이다. 그리고 최정적으로 IR 레지스터에 올것이다.
이떄 5941 를 디코드(decode) 해야한다. 5941를 4비트인 16진수로 변환했을때 우선 5는 메모리에 저장된 값을 AC 에 더하는 연산이였다. 즉 5941 에서 941 번지에 있는 값이 2이므로, 기존에 AC 에 있는값이 3이있었으므로 3+2 = 5 로 AC 레지스터의 state를 업데이트한다.
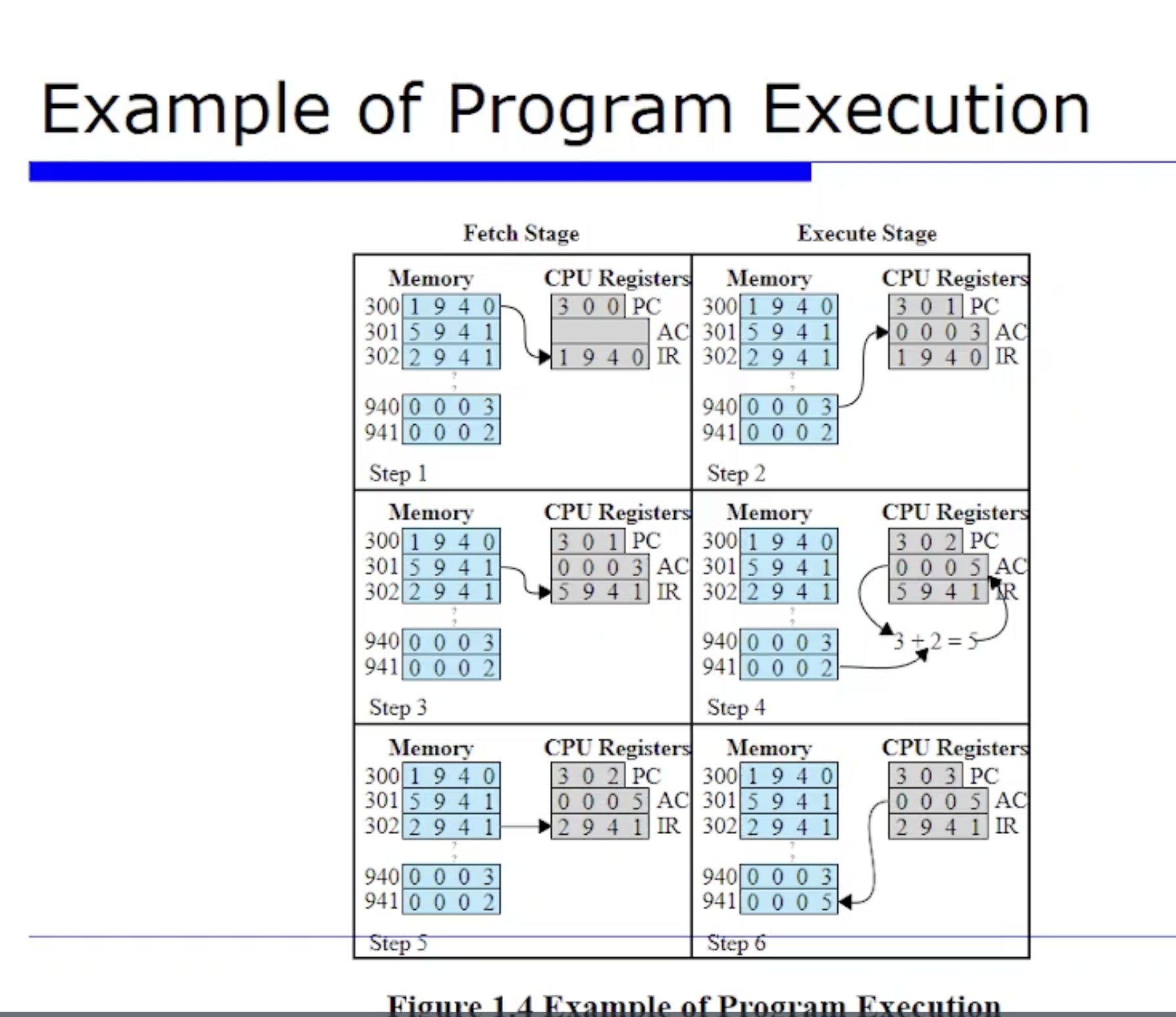
위 명령어 수행 과정들의 전 과정들은 이 그림으로 요약된다.
.
