운영체제 : 멀티 프로그래밍과 스캐줄러 분화

본 포스트는 학교 수업 강의내용을 단순 정리본 형태로 만든 내용입니다. 평소 포스트와 달리 다소 설명이 부실할 수 있음을 미리 알려드립니다 🙂
Multiprogramming 환경에서 active 한 여러개의 job 들을 메모리에 올릴려다보니, 그 당시에 아주 큰 문제가 발생하게 된다. 대표적인 문제가 Relocation 문제와 Memory Protection 문제이다.
Relocation 문제는 그 작업이 항상 고정된 위치에 오는것이 아니라, 런타임에 그 주소가 동적으로 변할 수 있고 또는 디스크에 Swap out 했다가 그 주소도 변경될 수 있기 때문에 이 문제가 해결되어야한다.
또 Memory Protection 문제도 있다. 자기 영역이 아닌 다른 영역의 address 를 접근해서 잘못된 결과가 발생할 수 있는 것이다.
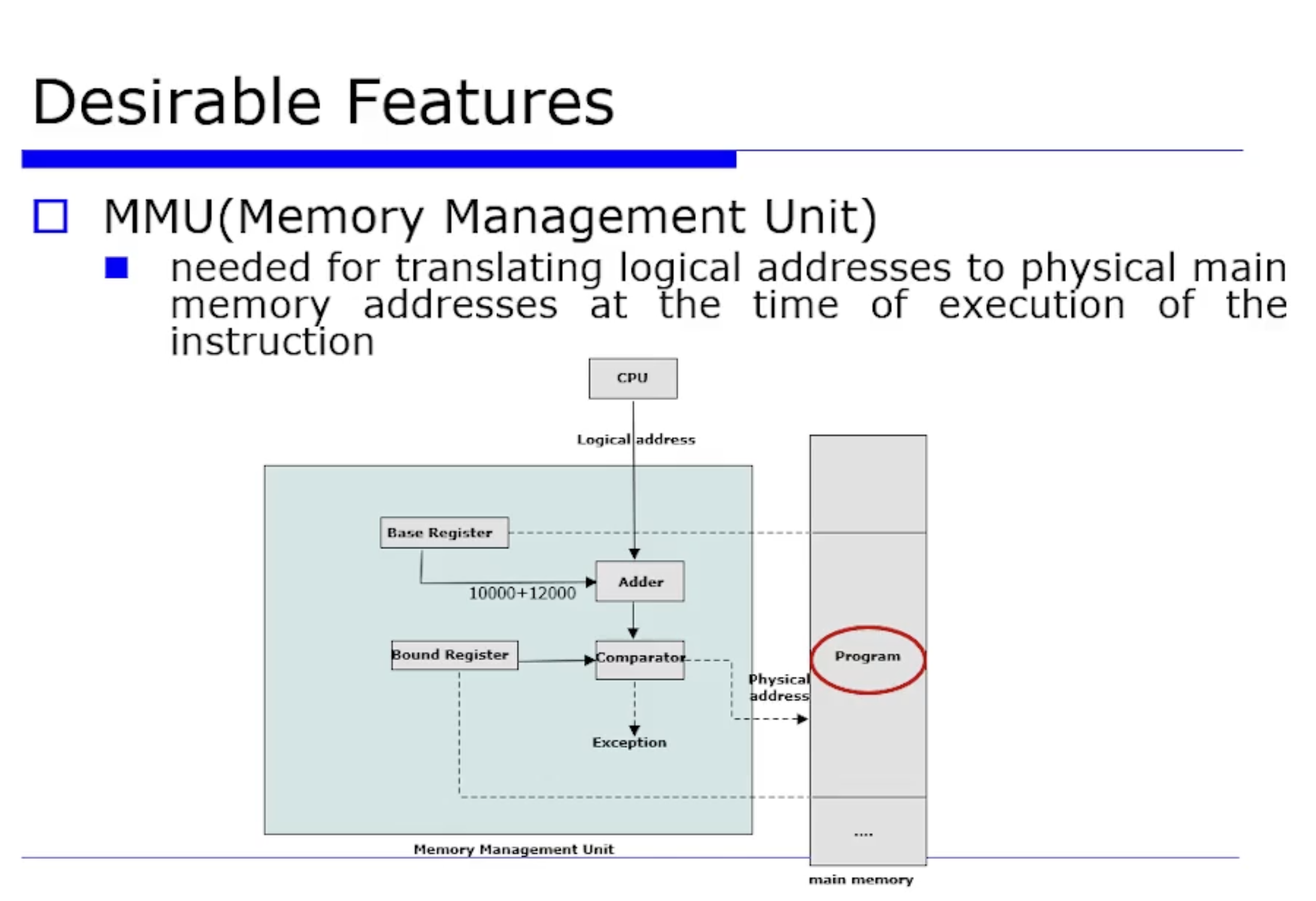
그래서 초기에 위와같은 address 의 개념이 세분화됐다. 논리적 주소와 물리적 주소로 세분화 된 것이다. 위 문제들을 해결하도록 등장한 것이 MMU 이다.
이 방식은 Base Register 를 통해 프로세스(job) 별로 시작주소를 유지하게 하는 것이다. 그리고 job 이 접근할 수 있는 범위(Bound) 도 Bound Register 에 저장(지정)해 놓는 것이다. 이 2가지를 보장하면 접근 가능한지, 예외인지 등을 확인해서 Reloccation 문제와 Memory Protection 문제를 해결할 수 있게된다.
이것이 현대적인 의미의 Dynamic Address Translation (동적 주소 변환) 이다. 이와 관련한 자세한 내용은 Virtual Memory 에서 다루겠다.

예시를 보자.
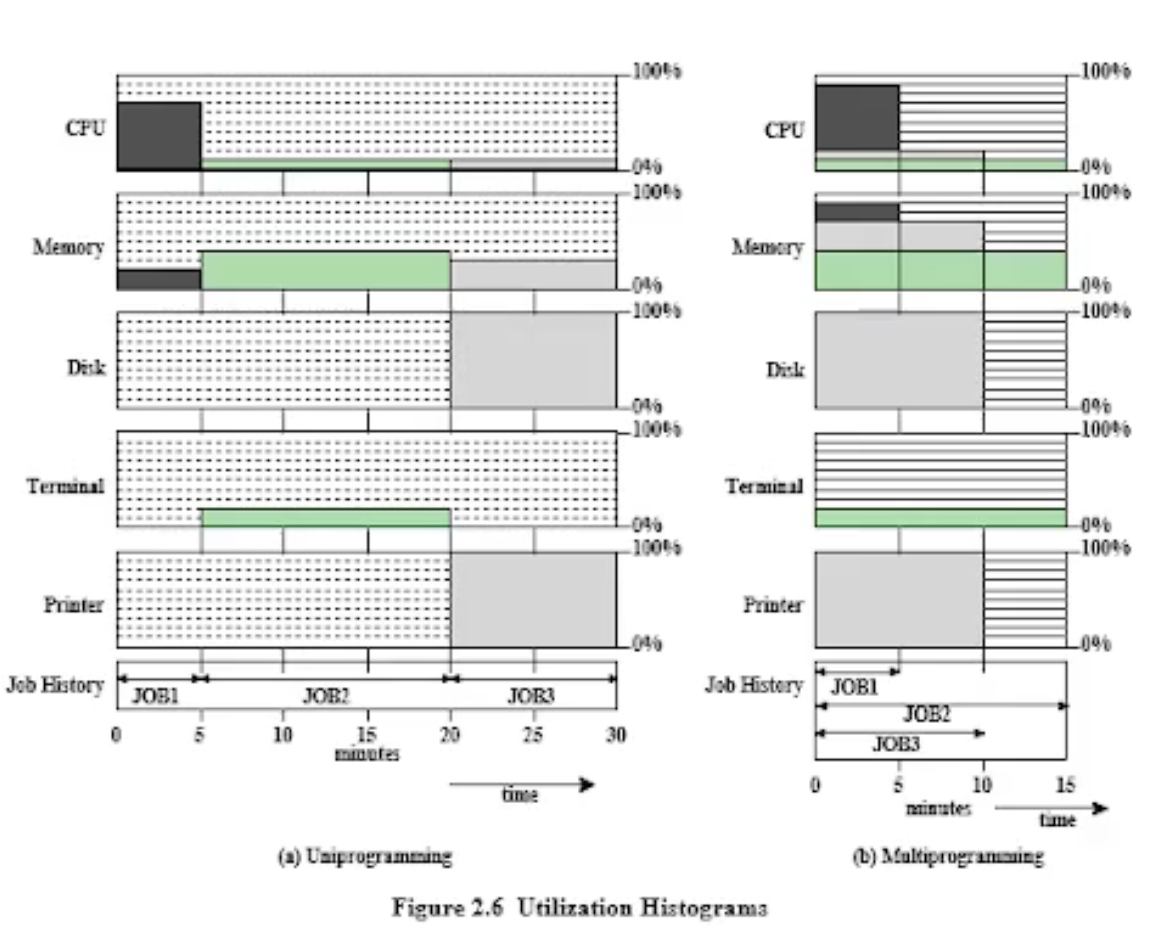
우선 위 그림은 Uniprogramming 을 했을 때에 비해 Multiprogramming 을 했을때 성능상 결과가 더 좋아짐을 보여주고있다.

이 예제에서는 프로세스(job)가 3개가 있다고 가정한다. CPU 가 각 job 에 대해 70%, 10%, 10% 만큼 사용한다고 가정한다. 이 퍼센트가 뭘 의미하냐면, 프로세스를 나누는 기준중에 CPU 를 많이쓰는 프로세스가 있고, I/O 작업을 많이 쓰는 프로새스가 있다. 그래서 CPU 를 많이쓰는 job(프로세스) 을 CPU Bounded Job 이라고하며, 또 I/O 작업을 많이쓰는 네트워크 job 들은 I/O Bound 프로세스라고한다.
job1 이 있는데, 이 놈은 계산이 상대적으로 많은 CPU Bound job 이라는 것이고, 반면 job2 와 job3 는 CPU 보다는 I/O 작업이 많은 (CPU 는 10퍼센트만 쓰는) I/O Bound job 이라는 것이다.
그 다음, 자원이라는 것은 CPU Memory I/O 이니까 Memory 는 250M 이다.

job1 은 수행시간이 5분정도 걸린다고 가정하고, job2 와 job3 는 수행시간이 15분, 10분 걸린다고 가정했다.
그리고 각 job 에서 Memory, Disk, Temrminal, Printer 와 같은 I/O 디바이스들을 사용하는지의 여부를 나타냈다. 작가는 이 표를 통해 뭘 말하고 싶은걸까?
각 job 들이 병행성의 특성을 띠면서 MultiProgramming 이 가능하려면 배타적으로 사용한다. 표를보면 동시간에 job3 만 디스크를 사용하고 있다. 또 terminal (터미널) 은 동시간애데 job2 만 사용하고있다. 즉, 이 표는 동시에 수행가능하다라는 병행성의 특징을 보여주고 싶은 것이다.
위와 같은 가정들로 Uniprogramming 을 했을때 시스템의 전반적인 utilitzation 이나 성능 향상이 어떻게 되며 달라지게 되는지 알아보자.
UniProgramming 에서의 CPU utilization
우리가 MultiProgramming 을 하는 기본적인 목적은 시스템의 utilitzation 을 극대화하기 위해 도입된 것이다. 따라서 Uniprogramming 일때의 프로세서의 utilization 은 곧 CPU 의 사용률(utilization) 이라고 이해하면 된다.

utilitzation 이라는 것은, 처음에 어떻게 사용하고 있냐고 가정하고 시뮬레이션 했냐면 처음에는 job1 을 수행한다. 앞선 가정에 따라서 job1 은 5분동안 수행하고 CPU 를 70% 를 사용한다. (위 그림에서 한칸이 10%임!) 그리고 그림에서 5분~20분 시간대를 보면 job2 가 15분동안 CPU 의 10% 를 사용하고 있는 모습을 볼 수 있다.
마지막으로는 job3 가 10분동안 10% 를 사용하는 모습을 볼 수 있다.
이럴때 평균 utitlization 을 어떻게구할까?
총 시간인 30분중에서 5분은 5/30 = 1/6 이다. 즉 job1 에 대한 utilization 을 먼저 계산해보자면 1/6 x 70% = 70/6 이다. 그리고 평균값을 구하도록 job2 와 job3 에 대한것도 구해보면,
- job2 의 utilization = 3/6(= 15/30) x 10% = 30/6 %
- job3 의 utilization = 2/6(= 10/30) x 10% = 20/6 %
이렇게 된다. 이들을 다 더해보자. 분모를 6으로 통일해서 더해보면 (70+30+20)/6 = 120/6 = 20% 이다.
MultiProgramming 에서의 CPU utilization

이어서 MultiProgramming 에서의 utilization 도 구해보자. 이 또한 앞서 했던것처럼 평균값을 구해내면된다. 예는 15분만에 끝낼수있다. 시뮬레이션을 해보면, job1 을 수행하는 동안에 70% 만 CPU 를 사용하니까 30 % 가 남고는다. 이때 CPU 자원이 30% 가 남기 떄문에 job1 과 job2 를 실행할 수 있다.
그러면 job 들이 동시에 수행을 시작해서 job1 - job3 - job2 순으로 수행이 끝날것이다. 이러한 상황일때 utilization 을 구해보자. 초기에 job1, job2, job3 의 CPU utilization 을 모두 더해보면 70 + 10 + 10 = 90 % 으로, 100% 가 초과하지 않기 떄문에 모든 job 들을 동시에 수행할 수 있다.
따라서 다음과 같이 utilization 이 계산된다. 총 15분안에서 일어나는 utilization 을 각각 구해보면,
- 초기 5분동안은 (70 + 10 + 10) / 3 = 90/3 %
- 중간 5분동안은 (10 + 10) / 3 = 20/3 %
- 마지막 5분동안은 10 / 3 = 10/3 %
이렇게 된다. 다 더해보면 (90 + 20 + 10) / 3 = 120/3 = 40 % 가 나온다. 즉 utilization 이 40 % 이나 된다. 아까 구했던 UniProgramming 의 CPU utilization 은 20 % 인걸보면, 무려 utilization 이 2배나 증가했다.
디스크 utilization
UniProgramming 에서의 디스크 utilization
그 다음으로 아까 말했듯이 utilization 이라는 것은 CPU 말고도 I/O 단위 에서도 utilization 을 계산할 수 있다. 예를들면 여러 I/O 중에서 디스크의 utilization 을 구해보자.

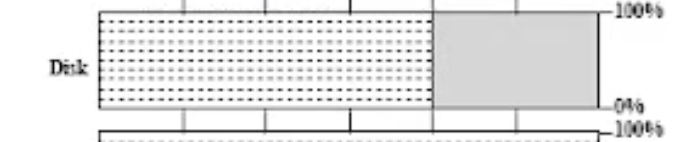
디크스는 job 3 만 쓰고있다. job 3 가 디스크를 10분 동안 쓴다고 가정하면, 아래 그림의 회색 부분처럼 디스크는 이 타이밍에만 사용한다고 색칠되어있다. 그렇다면 utilization 은 아래 그림을 보면 직관적으로 알 수 있듯이 회색 부분이 1/3 을 차지하므로, 1/3 이다. (전체 6칸중에 2칸만 사용하고 있으니깐).
따라서 UniProgramming 에서의 디스크의 utilization 은 33 % 이다.
=> 정직하게 계산해보면, job3가 디스크를 10분쓰고, 전체 시간은
MultiProgramming 에서의 디스크 utilization
반면에 MultiProgramming 에서 디스크는, 우선 전체 시간을 15분으로 봐야할것이다. job3 는 수행시간이 10분이라고 가정했으므로, 따라서 10/15 = 2/3 = 67% 가 된다.

throughput (처리량)
위와 같은 상황에서 throughput(처리량) 은 어떻게될까? 처리량은 "단위시간당 처리된 job 의 수" 이 정도로 정의했었다. UniProgramming 의 경우 30분만에 job3 을 3개 끝냈다. 만약 단위시간을 1시간으로 잡는다면 1시간당 6개를 끝낼 수 있는것이다. 이게 바로 UniProgramming 에서의 처리량(throughput) 이다.
반면 MultiProgramming 은 15분당 3개를 끝냈으므로, 처리량을 계산해보면 단위시간인 1시간당 12개를 끝낼 수 있는 것이다.
ResponseTime (응답시간)
ResponseTime 은 보통 응답시간을 의미한다. 이는 교재마다 정의가 조금 다른데, 우선 submission 하고 (요청 보내고) 최초의 응답이 올때까지의 시간으로 계산된다. 또는 submission 하고 그 작업이 완전히 끝날때까지의 시간, 즉 turn around 시간으로 계산하기도 한다.
UniProgramming 의 ResponseTime

여기서는 2번째의 정의인 turn around 시간을 기준으로 설명하겠다. UniProgramming 의 ResponseTime 을 구해보자.
job1 은 submission 되고 끝날때까지 5분 걸렸다. job2 은 submission 되고 끝날때까지 20분 걸렸다. 몰론 15분이 걸렸지만 5분의 대기시간이 존재하므로, 20분으로 보는게 맞다. job3 는 30분이 되어야 끝나게 된다. 평균을 내려보면,
- (5분 + 20분 + 30분) / 3 = 55/3 = 약 18분
=> 따라서 응답시간은 약 18분이다.
MultiProgramming 의 ResponseTime
MultiProgramming 으로 넘어와서 계산해보자. job1 은 5분 걸리고, job2 는 15분, job3 는 10분 걸린다.
평균 내보면 (5 + 10 + 15) / 3 = 10분이다.
정리
이렇듯이 MultiProgramming 을 사용하면 utilization 측면이나, throughput, Response Time 측면에서 모두 많이 개선됨을 알 수 있다.
이렇게 MultiProgramming 을 도입해서 성능이 많이 개선됐음을 눈으로 봤다. 성능이 좋아지면서 동시에 반도체의 트랜지스터 가격이 싸지면서 비용도 내려갔다.
그러나 이 당시의 문제는 또 뭐냐면, 한번 submission 하면 실행중인 job 이 사용자가 수행중인 작업과 소통할 수 없다는것이다.
MultiProgramming 을 처음 도입할시 프로세스의 utilization 을 최대한 높이는것이 목표였는데, 이제는 ResponseTime 을 최소화하는 것이 더 중요시되었다.
그런데 아쉽게도 어떤 한 부분에 대해 최적화를 시키면, 다른 부분에 대한 최적화는 기대하지 못한다. 즉 ResponseTime 에 대한 성능 최적화를 진행하면, utilization 에 대한 성능이 다소 떨어질 수 있게된다.
정리하자면, 이 시기는 ResponseTime 에 대한 성능 최적화 및 요구사항이 많아지게 된 시기이다. 이에따라 job control language 가 등장하게 되었고, 현대 시대에 이르러서는 우리가 터미널에서 사용하고 있는 명령어들로 소통하는게 더 중요해졌다. 그래야 더 생산적이기 때문이다.
Time Slice
그런데 UniProcessor 라고 가정했을때 CPU 라는 자원의 특성상 쪼개서 줄 수 없다. 그래서 당연히 시간단위에서 배분하는 고민을 했다. 따라서 초창기에 200ms 단위로 시간 할당량(시간 단위)을 정해놓았다. 그러한 시간단위를 time slice 라고한다.
=> 애플리케이션 단위로, 즉 job 단위로 time slice 를 정해놓고 배분하는 방식으로 진화했다. 이러한 그 당시의 시스템을 Time Sharing System 이라한다.
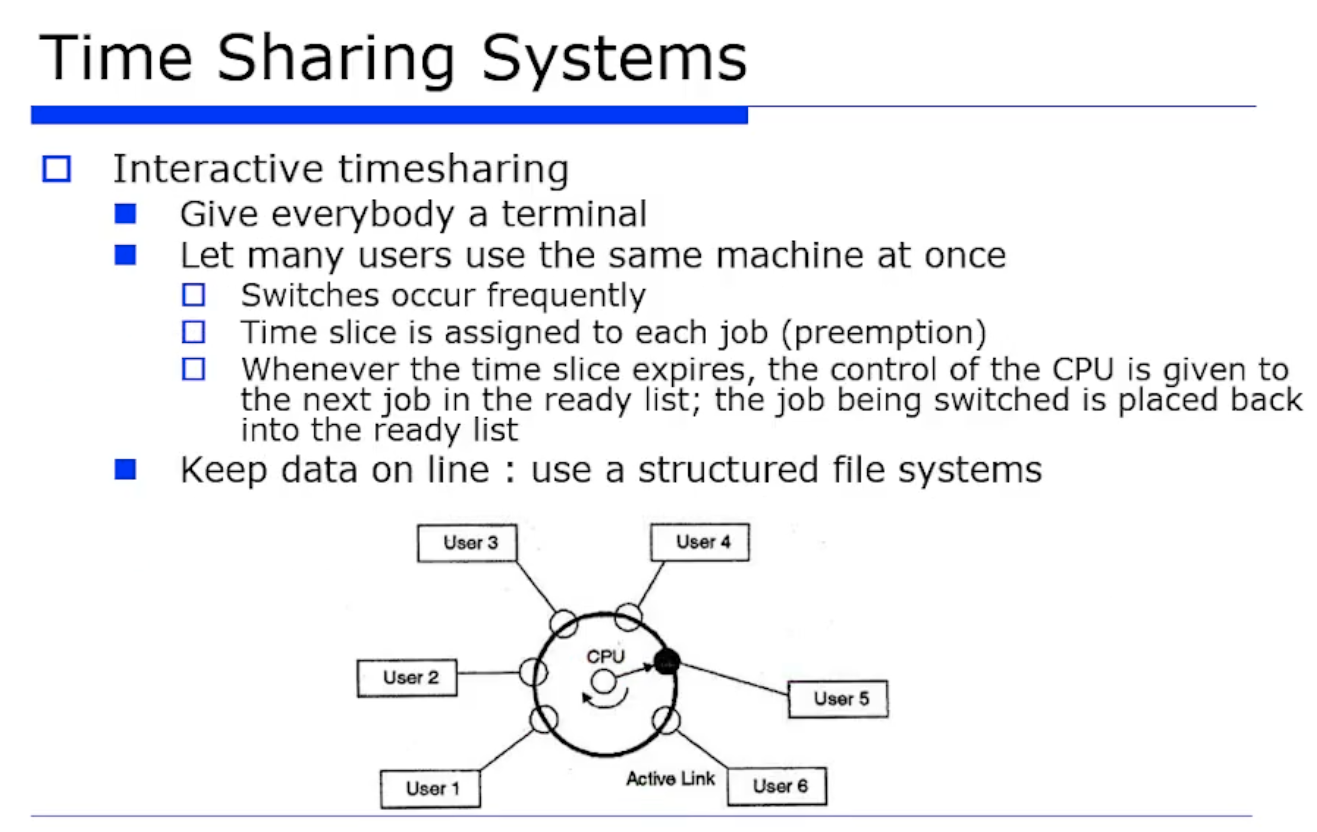
중앙에 메인 서버를 정해놓고 Multiple 한 job 말고도 이제는 Multiple 한 유저도 지원하게된다. 그래서 사용자들이 터미널 형태로 연결이된다.
(이때 주의할점은 우리가 현재 쓰고있는 소프트웨어적인 터미널이 아니라, 하드웨어적인 터미널이다!)
그래서 터미널들이 다 주어지고, 터미널이 터미널 컨트롤러를 통해서 메인 서버에 연결되고, 나는 마치 내 PC 인것 마냥 사용하는 방식이다. 그런데 메인 서버의 OS 는 Time Sharing 을 통해서, CPU 를 time slice 를 통해서 배분해가는 방식으로 지원하게 된다.
Process Switching
이떄 OS 의 중요한 개념들이 등장했다.
일단 각 유저들에게 터미널이 주어졌고, 그 터미널을 통해서 실제 CPU 를 사용하는것은 한번씩 돌아가면서 쓰는것이다. 이렇다는 것은 곧 OS 에서 작업 스위칭(work switching) 을 지원해야한다는 의미가 된다. 현대적인 표현으로는 Process Switching 이 되겠다.
preemption
Process1 이 수행하다가 time slice 가 만료되면 Process2 가 수행하는 것이다.
=> OS 가 타이머를 통해서 특정 프로세스가 time slice 를 다 썼는지(만료되었는지) 보고, 다 쓴경우 중단 시키는것이다. 이렇게 중단 시키고 자원을 회수해서 프로세스1 에서 프로세스2 로 전달되는 과정이 발생하는데, 그 회수하는 과정을 preemption 이라고한다. 즉 어떤 자원(여기서는 CPU) 을 OS 가 회수하는 것이다.
그리고 다른 작업들이 있을텐데, 다른 작업들은 기다릴 대기장소가 필요하다. 작업을 진행할 준비가 된 프로세스들이 모여있는 곳을 Ready list 라고한다. 또 Ready List 에서 가장 적절한 프로세스를 선택하는 작업을 스캐줄링 이라하고, 그 프로세스를 선택해서 주는것이다. 그런데 여기서 라운드 로빈이기 때문에, 여기서는 그냥 다음 프로세스를 선택해서 준 것이다.
- 이것이 바로 초기의 time sharing system 이다.
문제점
이때 나온 문제점은 이 시스템의 여러 유저들이 마치 본인의 PC 인것으로 착각하는것이다. 그래서 개인적인 사생활 정보를 저장하기 시작한다. 이로인해 보안성을 강화하기 위한 개인 및 그룹별 파일시스템이 등장 및 진화하게된다.

Time Sharing System 은 CTSS 로 시작헤서, 70년에 UNIX 가 등장하고, 이것은 리눅스, 윈도우, 맥 OS 등 모든 OS 들의 탑제된다.

Time slice 와 Preemption 에 대해 더 자세히 알아보자.
위 그림처럼 프로세스(job) A 와 B 가 있다고하자. 각 job 의 수행시간은 6초, 2초 이다. 기존에는(Time sharing 이 아닐때는) A 를 다 수행하고 B 가 수행되는 방식이였다. Time slice 를 1초라 가정하자.

Time Slice 로 OS 에서 얼만큼으로 잡는가도 중요한 사항이다. 아무튼 그냥 1초라 가정하면, A를 수행하고
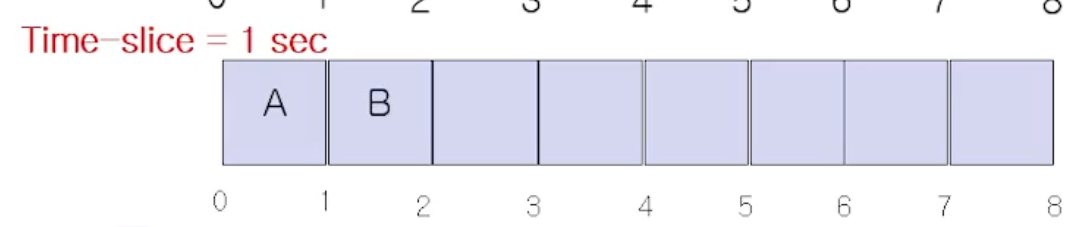
OS 시스템 타이머를 보면서 time slice 를 다썼는지 preemption 한다. 그러고 다시 B 를 수행시킨다. 지금 가정한것은 Ready list 에 있는 A, B 만 있다고 가정한것이고, I/O 작업은 없고 CPU 작업만 있다고 가정한 예시이다.
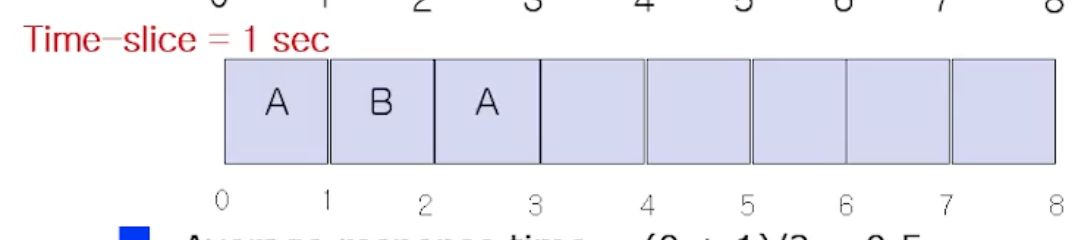
그러고 B가 다 끝나지 않았음에도 불구하고 A 가 다시 수행된다.
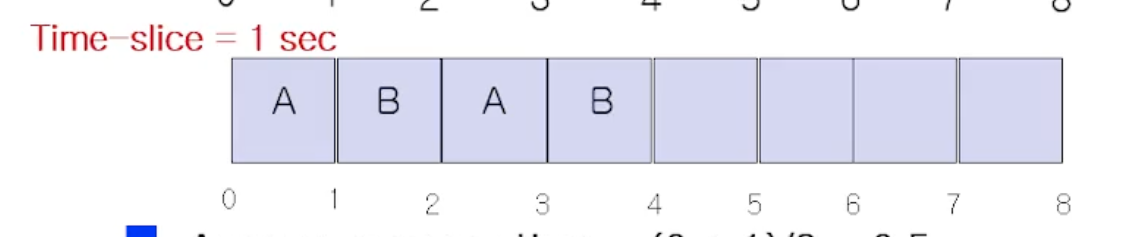
그러고 B 가 또 수행된다.
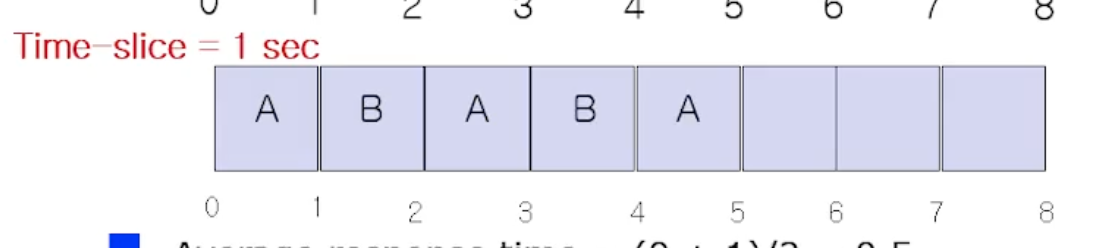
그 다음 A 가 수행되는데, 앞선 가정에따르면 B는 2초만 수행한다 했으니깐 이제 다 마치고 종료되었다.

따라서 앞으로 계속 A 만 수행된다.
Time Sharing 의 목적이 응답시간을 최소화하는 것 이였으므로, 이렇게 Time Sharing 이 동작했을때 응답시간이 줄어드는가를 보여주는 예제였다.
응답시간을 첫번째 반응이 올때까지의 시간이라고 하면, job A 는 시작하자마자 반응이왔다. 따라서 A 의 응답시간은 0이다. 반면 B 는 1초의 대기시간을 가진후 시작했다. 따라서 1초다.
따라서 평균 응답시간은 (1+2) / 2 = 0.5 초이다.
반면에 turnaround time 도 비슷하긴 하지만, turnaround time 을 시스템이 submission 되고 종료될때까지라고 하면, 8초후에 끝났으므로 job A 의 turnaround time 은 8초이다. B 는 4초일때 끝났으니까 4초이다.
따라서 평균 turnaround time 은 (8 + 4) / 2 = 6 초이다.
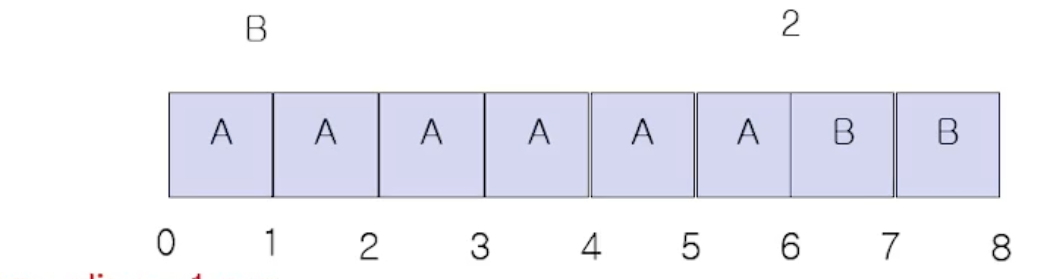
위 그림하고도 비교해보자. 즉 위 그림은 time sharing 이 아닐때이다. 위 처럼 실행했을때는 평균 응답시간이 (0+6) / 2 = 3 이다.
또 평균 turnaround time 은 (6 + 8) / 2= 7초이다.
이렇듯 job A 와 B 모두 time slice 가 적용되니 응답속도, turnaround 시간 모두 성능이 향상되었다.

프로세스 도임
이렇게 time sharing 이 진행되는 Unix 시스템이 만들어면서 프로세스라는 개념이 도입되면서 프로세스의 구조가 만들어졌다.
스캐줄링 도입
그리고 스캐줄링이 등장했다. job 이 수행되고나서 ready list 에 여러개의 작업 후보들이 있을것이다. Ready list 에서 무조건 다음에 저장되어있는것만 선택하는게 아니라, 내가 어떤것을 선택하는가에 따라서 성능이 달라진다. 그래서 스캐줄링이 등장함
동기화 : synchornization
그리고 동기화 이슈가 등장하게된다. 어떤 프로그램이 수행하다가 중단되고 다른 프로그램이 수행할때 예상치못한 문제점들이 많이 등장하게된다.
Memory Management
active 한 작업들을 메모리에 올린다고 했는데, 물리적 메모리의 양은 고정되어있고, 프로그램은 더 클수도있고, 또 MultiProgramming 의 정도롤 얼마나 더 높일것인가에 따라서 성능이 달라진다.
Resource Protection

프로세스란 실행중인 프로그램, 또는 실행가능한 프로그램을 뜻한다.
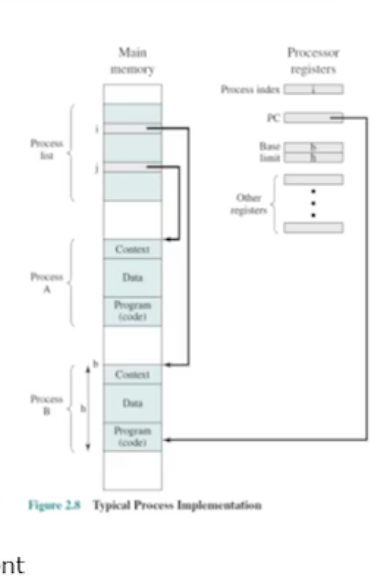
이러한 각 프로세스가 메모리상에는 프로세스 리스트 형태로 있는다. 프로세스 리스트에서 각 프로세스에 대한 정보가 필요한데, 앞선 정의처럼 프로세스란 실행중인 또는 실행가능한 프로그램이라 했으므로 메모리에 위치해있어야한다. 또 실행 가능하려면 원래의 프로그램 코드와 관련된 데이터가 메모리에 올라가있어야한다.
프로세스 구성요소
따라서 필연적으로 프로세스에는 코드와 데이터가 있다. 또 OS 에게 관리받기 위해서 필요한 메타데이터도 보유하고있다. 메타데이터에는 ID 와 매핑정보등이 해당된다. 그리고 이 메타데이터는 Execution Context 라고한다.
이때 Context 라는것은 OS 가 그 프로세스를 관리하고 제어하기 위한 내부 데이터를 정의를했다. 대표적인게 바로 레지스터 정보다.
추가적으로 넓은의미에서 Context 에는 PID, Priority 등도 해당된다. 해당 프로세스에 대한 상태정보를 나타낼 수 있는 값들 말이다!
register context
레지스터 정보란, 특정 프로그램이 수행하다가 time-sharing 을 하다가 선점될수도 있다고 했었다. 즉 스캐줄러에 의해서 중단될 수도 있다. 어떤 A 라는 job 이 열심히 레지스터를 사용하고 있는데 스캐줄러에 의해서 갑자기 중단될 경우 바로 업데이트하면 안된다. 그러면 A 를 메모리에 저장해야한다. 그걸 그 당시에는 context 라고 했었고 특히 context 내부에서 레지스터 정보를 Register Context 라고한다.

스캐줄러의 분화
이렇듯 프로세스를 실행하고 time sharing 기반의 어떤 핸들링을 하기 위해 위와 같은 구조의 프로세스가 필요하다. 이제 스캐줄러의 분화가 일어난다.(스캐줄러가 세분화된 종류로 구분됨) 초기의 simple batch system 시기에는 단순히 submission 이 가능한지 아닌지만 보는 스캐줄링 이였다면,

이제는 2가지의 스캐줄링으로 나뉘었다. 바로 Long term queue 와 Short term queue 이다. 시스템 단위의 submission 이 가능한가 아닌가의 정보를 Long term queue 에 저장하고, Short term queue 에는 CPU 단위에서 어떤 리스트에 있는 여러개의 프로세스들 중에서 어떤 프로세스에 CPU 를 할당할것인가에 대한 실질적인 CPU 스캐줄링이 필요하다는 것이다. 그게 바로 Short term 스캐줄러이다. (뭔 소리지?)
- 이에 대한 내용은 나중에 더 자세히 설명한다!
여러개의 OS 가 queue 를 갖게 되었고, 스캐줄링 방식 및 스캐줄러도 다양해졌다. (메모리 스캐줄링, 네트워크 스캐줄링, I/O 스캐줄링 등)
스캐줄링 정책의 분화
그리고 이 스캐줄링의 정책도 다양하게 분화했다. 이 당시에 최적화의 타겟을 어떤것으로 하는가에 따라서 성능이 달라짐을 확인헀다.
- Fairness : 공평성(공정성). 얼마나 CPU 리소스를 공평하게 분배할것인가
- Efficiency : thoroughput, response time 을 최적화하는 전략이 나올 수 있다. 또한 공평성을 지키다보면 효율성이 떨어질 수 밖에없다. (공평성과 효율성은 반비례한다)
- Differential responsiveness : 차별화된 응답성.

time sharing 하면서 프로세스들이 interleaving 할 수 있다. interleaving 이란 프로그램이 수행하다가 스캐줄러에 의해 선점당하고 다른 프로그램이 수행되다가 그 놈도 선점당하는 방식이다. 즉 프로그램이 실행되고 있는 중간에 명령어가 끼어드는 것이다.
=> 쉽게말해, 프로그램 A 를 실행하다가 프로그램 B 가 동시에 실행되면서 B 의 명령어가 A 에게 개입해서 프로그램의 정확도를 떨어뜨리는 것이다.
- race condition, deadlock 이 발생할 수 있다.

메모리 공간 부족 이슈를 해결하도록 virtual memory 개념이 등장했다.
이는 Paging 기법에 기반해서 발전했다.
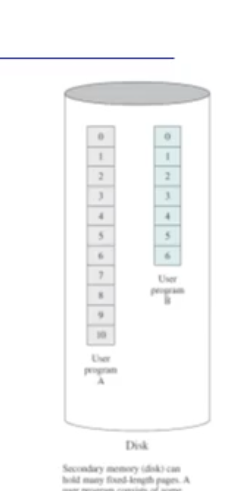
Paging
프로그램이 초기에는 디스크에 있었다. 또 Paging 이란 프로그램을 Paging 이라는 단위의 고정크기 조각으로 나눈것이다.
초기에는 프로그램이 메모리에 다 올라와서 실행했었다. 즉 메모리가 이러면 공간이 부족해진다. 이를 극복하도록 필요한 것들만 메모리에 올리자는 아이디어가 나왔고, 메모리에 올릴떄는 한 프로그램을 여러개의 Paging 조각으로 나누어서 여러 곳에 분산 적재했다. 또 이 분산적재는 부분적재로 진화해서 더 많은 프로그램(프로세스)를 메모리에 적제시키도록했다.
또 실제 메모리 물리적 공간보다 더 많은양을 적제할 수 있게되었다. 실제 메모리 크기는 3MB 이더라도 10MB 짜리 프로그램을 수행할 수 있도록하는 가상 메모리 공간을 만드는 것이다.
Page Fault
이떄 부분적재를 했다는 것은, 아직도 디스크에 Page 단위 데이터가 남아있다는 것이다. 따라서 MMU 가 변한다. address translation 할때 실제 물리 메모리만 관여한게 아니라, 실제로는 메모리에 없을수도 있다는것이다. 디스크에 있을수도 있는것임
만약에 4번 Page 에 있는 100번째 offset 에 접근하려는 경우, 실제 메모리에 없다면 빨리 디스크에서 올려줘야한다. 이게 바로 Page Fault 이다.

다양한 Multi job (프로세스) 들이 I/O 작업을 직접 수행하면 문제가 발생할 수 있기 때문에, 시스템 자원을 보호하도록 2가지 모드(유저모드, 커널모드)가 도입되었다.
사용자가 어떤 OS 시스템 콜을 통해서 자원을 접근할 수 있도록하는 서비스라고 보면 된다.
system call 이란 유저모드에서 커널모드로 넘어가게 하는것이다.(그리고 이러한 system call 은 모드 전환(mode switching) 이 일어난다는 것이다.

다시 정리해보자. system call 이란 프로세스가 커널 서비스를 요청하는 것을 의미한다. system call 의 목적은 시스템 자원을 보호하기 위함이다.

또 system call 은 여러 OS 종류마다 잘 정의해뒀다.
또 system call 은 일반 사용자들이 사용하기에 난이도가 어렵기 때문에, 라이브러리 형태로써 scanf(), printf() 와 같은것으로 대신헤서 사용하게 한다.
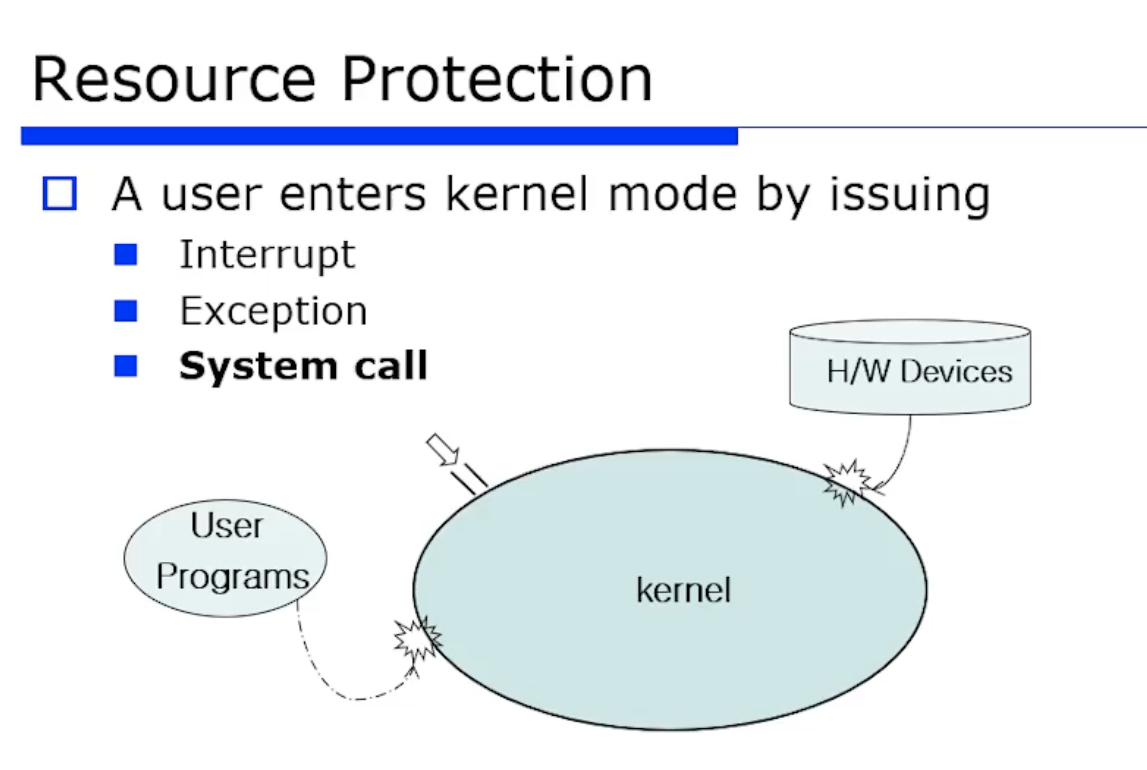
앞선 내용을 정리해보자. 커널에 진입하는 방법은 3가지가 있다.
- Interrput : 외부에서 interrput 가 발생했을 때 커널 모드로 mode switching 이 일어난다.
- excepion : 그 프로그램이 수행하다가 예외가 터지면 커널 모드로 mode switching 이 일어난다.
- system call : 시스템 콜도 커널 모드로 진입하는 방식이다.

실제 유저 프로그램에서 I/O 를 접근하는게 아니라, 요청만 하고 파라미터를 전달하는데, register 를 통해서 전달한다. 메모리의 시작주소를 register 로 전달해서 block 덩어리를 보낼수도 있고, 또는 파라미터가 굉장히 길다면 스택을 사용할수도있다.
