운영체제 : 프로세스? 그게 뭐지?

본 포스트는 학교 수업 강의내용을 단순 정리본 형태로 만든 내용입니다. 평소 포스트와 달리 다소 설명이 부실할 수 있음을 미리 알려드립니다 🙂
프로세스

정의 : 실행중인 (또는 실행가능한) 프로그램
job, task 라는 표현 모두 프로세스와 동일한 의미이다.

또한 프로세스는 2개의 추상화된 정의가 있다. 하나는 자원 할당의 단위로써 테스크, 다른 하나는 실행단위로써의 쓰레드이다. (엄밀히는 프로세스의 하위 레벨이 쓰레드인데, 이 교재에서는 같은 단위로 보겠다는 것이다.)

프로그램과 프로세스의 차이에 대해 알아보자.
프로그램이란 디스크에 위치한, 바이너리로 구성된 명령어 집합의 실행가능한 파일이다.
해당 파일을 실행하면, 그 파일의 명령어와 데이터가 메모리로 올라와서 명령어가 수행될것이다. 이 명령어들이 실행되기 위해선 코드와 데이터만 있어서는 불가능하다. 이 외에도 procedure call 을 위해 스택이 필요하다.
프로세스 본질적으로 프로그램을 가지고 있기 때문에, 당연히 유저 레벨의 코드와, 그 코드와 연관된 데이터가 있으머, 스택이나 힙이 있다.
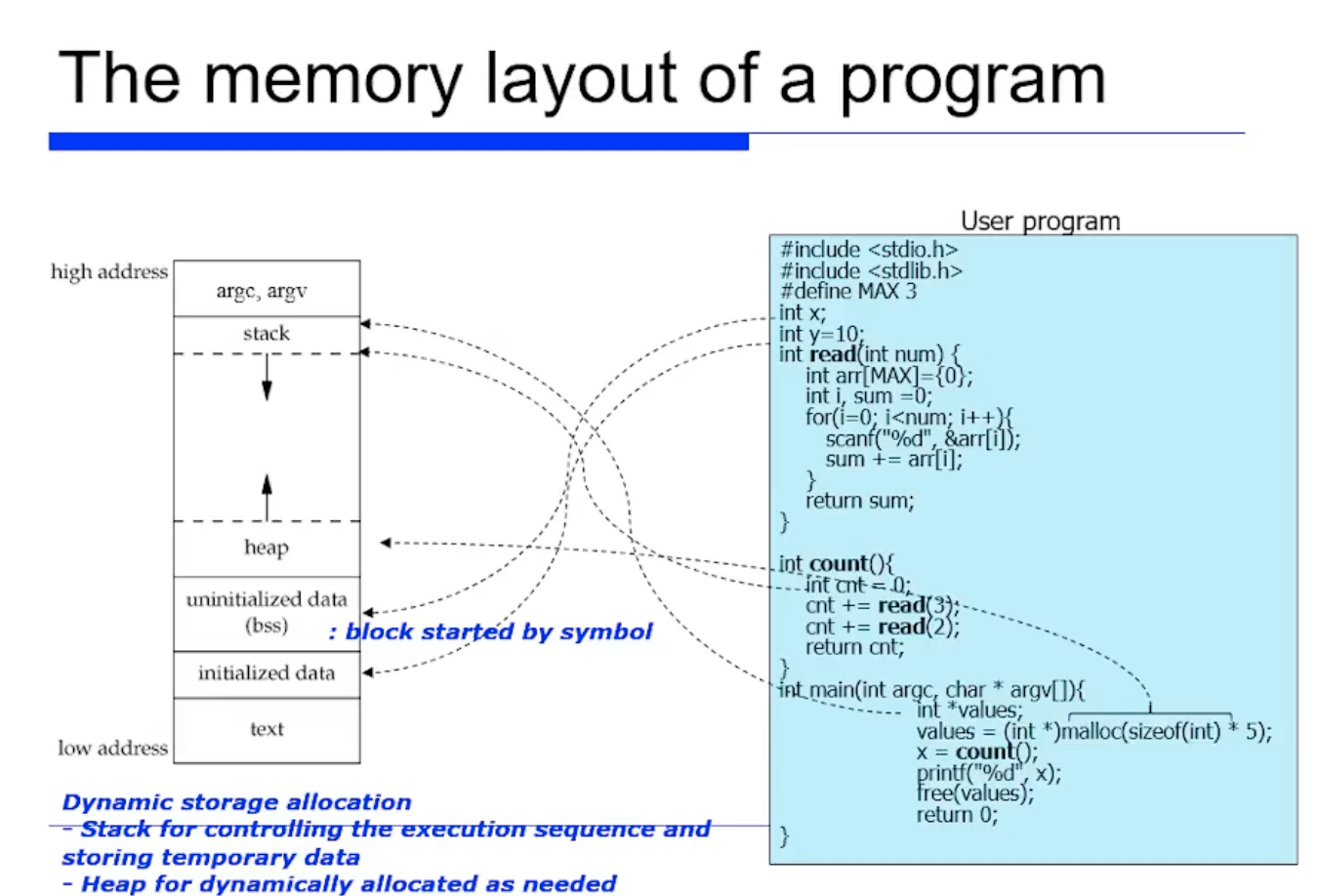
컴파일하면 실행파일이 만들어지고, 코드와 데이터로 구분될것이다.
- data : 스택의 data 영역에는 초기화된 전역변수들이 저장된다.
- bss : 반면 초기화되지 않은 변수들은 bss 에 저장된다.
- heap : malloc 와 같이 동적인 메모리를 저장
- stack : procedure call 명령어를 수 시 전달되는 파라미터, 해당 procedure 내에서 사용되는 지역변수, 함수의 return address 등을 저장
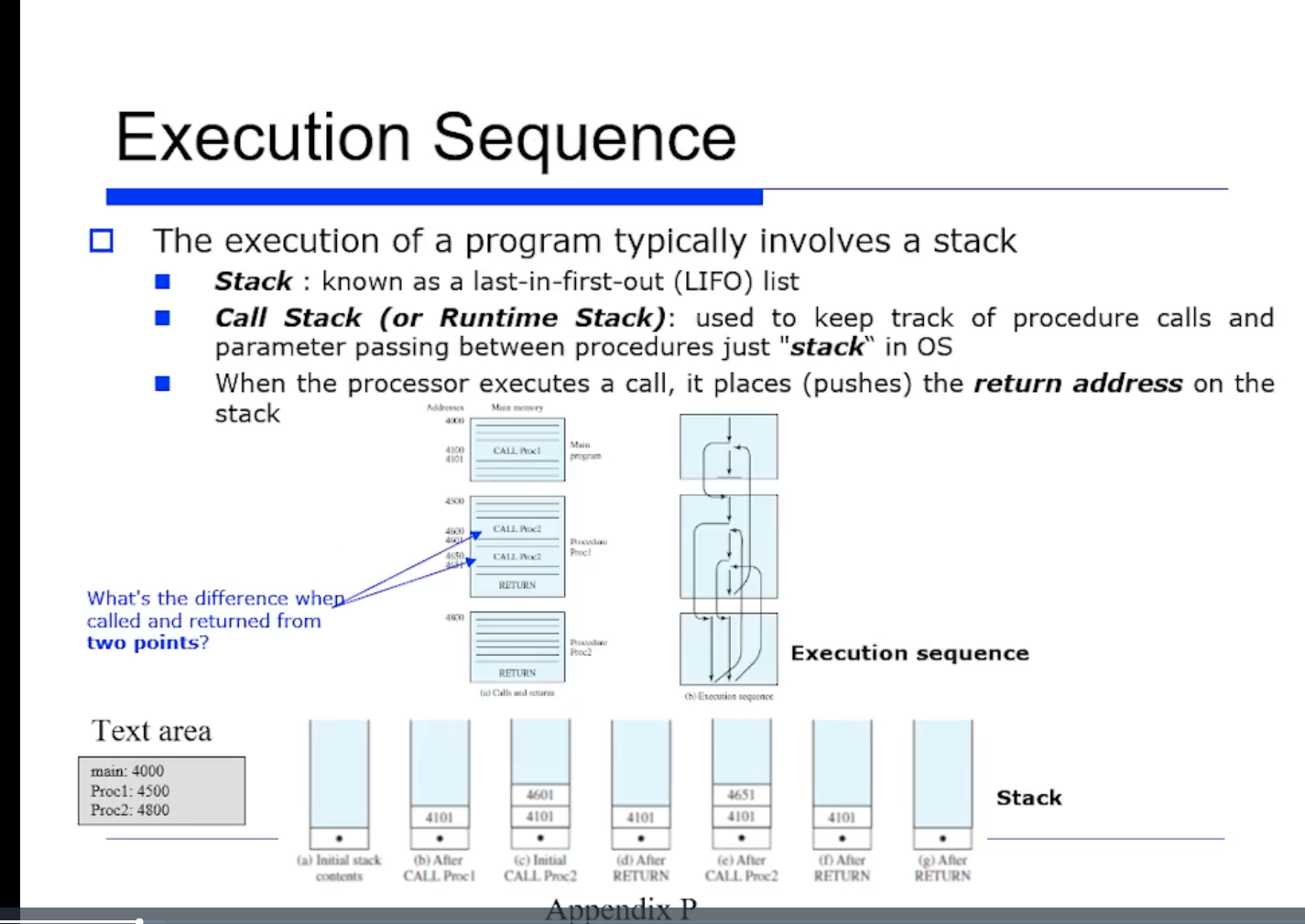
컴파일된 프로그램이 있을떄, 아래와 같이 main, proc1, proc2 가 있다고하자. main 은 4000번지 부터 시작되고, proc1 은 4500번지이고 proc2 는 4800 번지에 코드가 있다고하자.
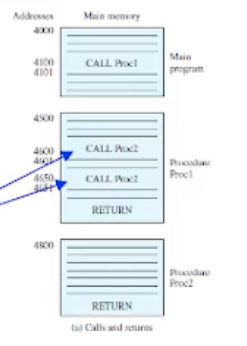
그러면 명령어들이 하나씩 차례대로 수행되다가, call 명령어를 만난경우를 생각해보자. call 명령어는 jump 명령어와 달리 procedure call 에 갔다가 반드시 다음에 온다는 약속을 한것이다.
예를들어 위 그림처럼 4100 번지에서 CALL Proc1 명령어를 만난경우, 다음 주소인 4101 번지를 메모리의 스택 영역에다 저장해둔다. (스택에 push 가 일어남)
아무튼 proc1 을 call 하면 4500번지로 점프한다. 4500번지부터 시작헤서 명령어들을 또 차례대로 수행하다가 call proc2 를 만난다.
그러면 스택에 4601 번지 주소를 스택에 push 해두고 4800 번지로 가서 명령어를 수행한다. 쭉 명령어를 수행하다 return 명령어를 만나면 스택의 주소를 pop 하는 연산이 일어난다. 동시에 return 주소인 4601 번지로 복귀한다.
=> 이러한 procedure call 을 통해서 프로그램이 흐름을 갖게 되는 것이다. 스택의 LIFO 특징에 따라서 스택의 맨 위에있는 return 주소를 추출해서 그 주소로 복귀하고 스택에서 pop 시키는 방식이다.
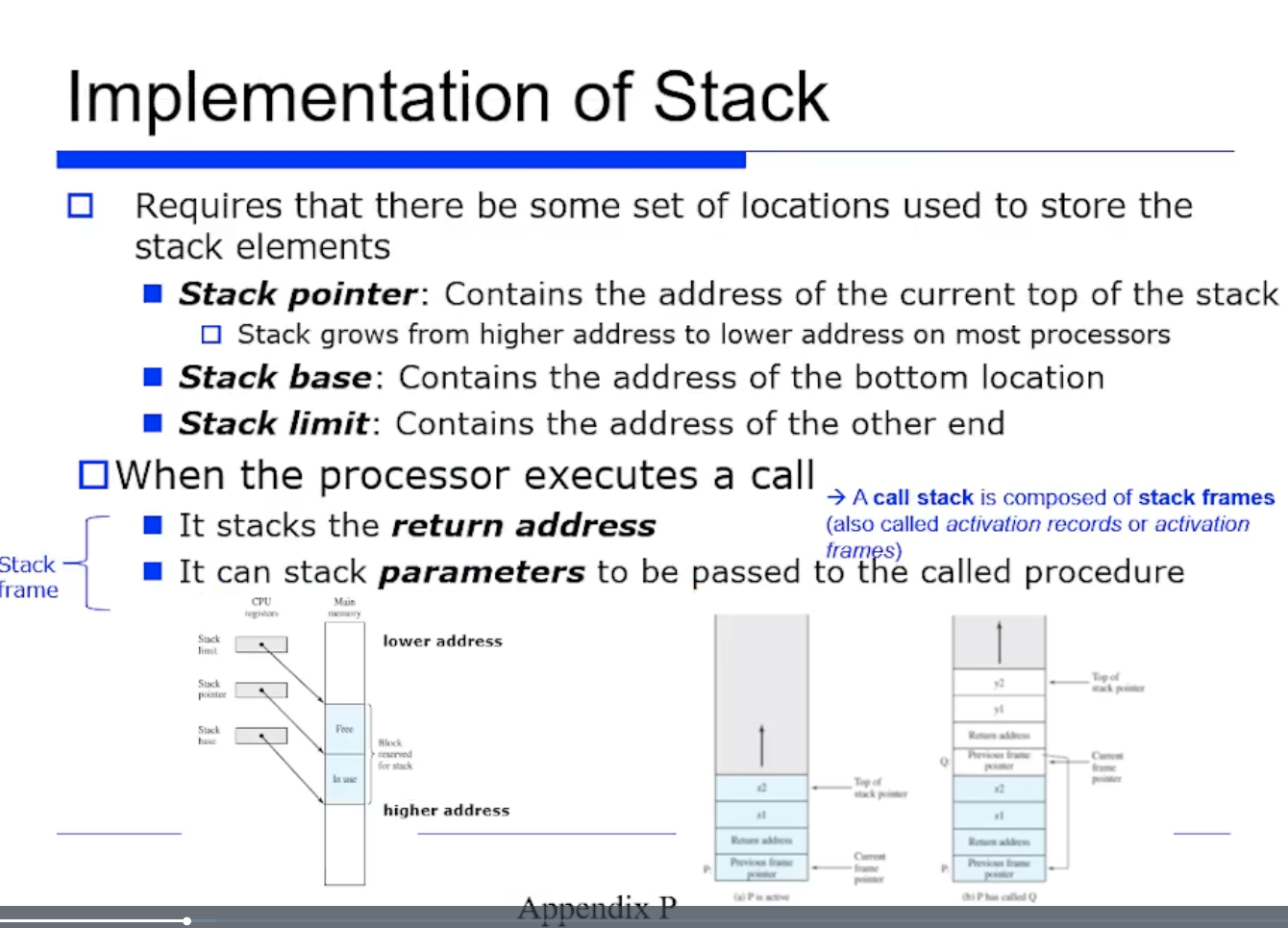
- stack pointer : 스택의 top 을 가리킴
- stack base : 스택의 맨 밑 바닥(bottom) 을 가리킴
- stack limit :
- 최근의 프로세스 대부분은 스택이 높은 곳에서 낮은 곳으로 return address 가 쌓이는 방식이다.
- 함수를 호출할때마다 procedure 단위에서 stack frame 이 생성된다. stack frame 의 집합을 스택이라 할 수 있다.
- procedure 마다 stack frame 의 크기가 다르다.

PCB 란 OS 가 그 프로세스를 관리하기 위해 필요한 정보의 집합이다. 이 정보에는 해당 프로세스를 관리하기 위한 모든 정보들이 들어있다.
- PCB 가 저장하는 정보들 : PID, State(상태 정보), Priority(여러 프로세스 중 실행 우선순위), context data
=> 이 중에서 context data 가 가장 중요하다. context data 는 이전에 time sharing system 에서 설명했었다. 여러 프로세스가 여러 자원을 함꼐 공유하는 구조, 즉 Multiple Process 를 지원하게 위해 존재한다.
-
수행중인 process 가 interrput 되고 나중에 다시 재개하려면, 그 중단됐을떄의 레지스터 정보, 즉 context data 를 save 하고 restore 할 수 있는 공간이 필요하다. 그 공간이 바로 PCB 이다.
=> interleaving, 즉 스캐줄러에 의해서 중단될 수 있을때 그 context 를 어딘가에 저장해야하는데, 그걸 제어하려면 당연히 저장할 공간을 미리 약속해야한다. 그게 바로 OS 에서 PCB 안에 저장되는 것이다.

이러한 PCB 는 어떻게 활용되는가?
OS 에서 프로세스를 fork 하면 가장 먼저 하는것이 PCB 를 받는것이다. PID 를 규정하고, 각 프로세스간의 부모-자식관계를 규정하는 등을 하는것이다.
Ready Queue, Waiting Queue, Suspend Queue 등 Queue 를 만들때 PCB 들을 링크드리스트 형태로 구현했다. 큐의 각 PCB 들은 포인터로써 연결된다.

OS 가 프로세스를 실행하고 관리하기 위해서 유저 프로그램(code), 데이터(data), 스택이 필요하다.
code 와 data 는 유저 프로그램의 요소이므로 당연히 필요하다. 또 실행하면서 프로세스가 스택을 사용하므로 스택도 필요하다. 이들은 유저 레벨 수준에서의 메모리에 있는 내용이다.
반면 그 프로세스가 스캐줄러에 의해서 중단되면, state 정보와 같은 레지스터 정보도 저장할 필요가 있다. 또한 그 프로세스의 상태 정보, priority (우선순위) 정보 등을 저장해두는 PCB 가 필요하다고 했었다.
- PCB 는 process descriptor 라고도 부른다.
=> process image, 즉 context (정확히는 system 레벨에서의 context) 란 유저 program + text + data + stack + PCB 로 구성된다.
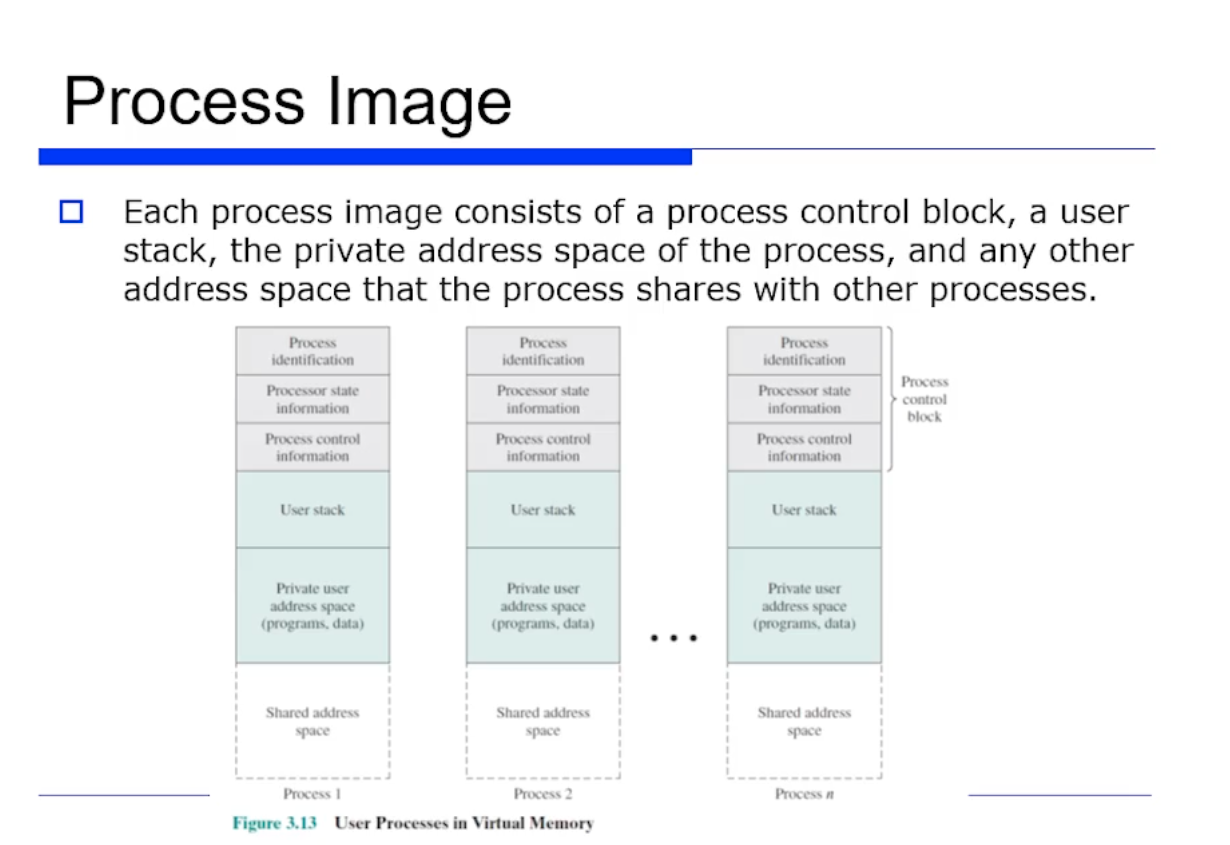
프로세스 입장에서 봤을때 virtual memory 에는 프로그램, code, data, stack 영역, PCB (Processor State + Context Data + Process 제어정보) 등의 정보가 들어있다.
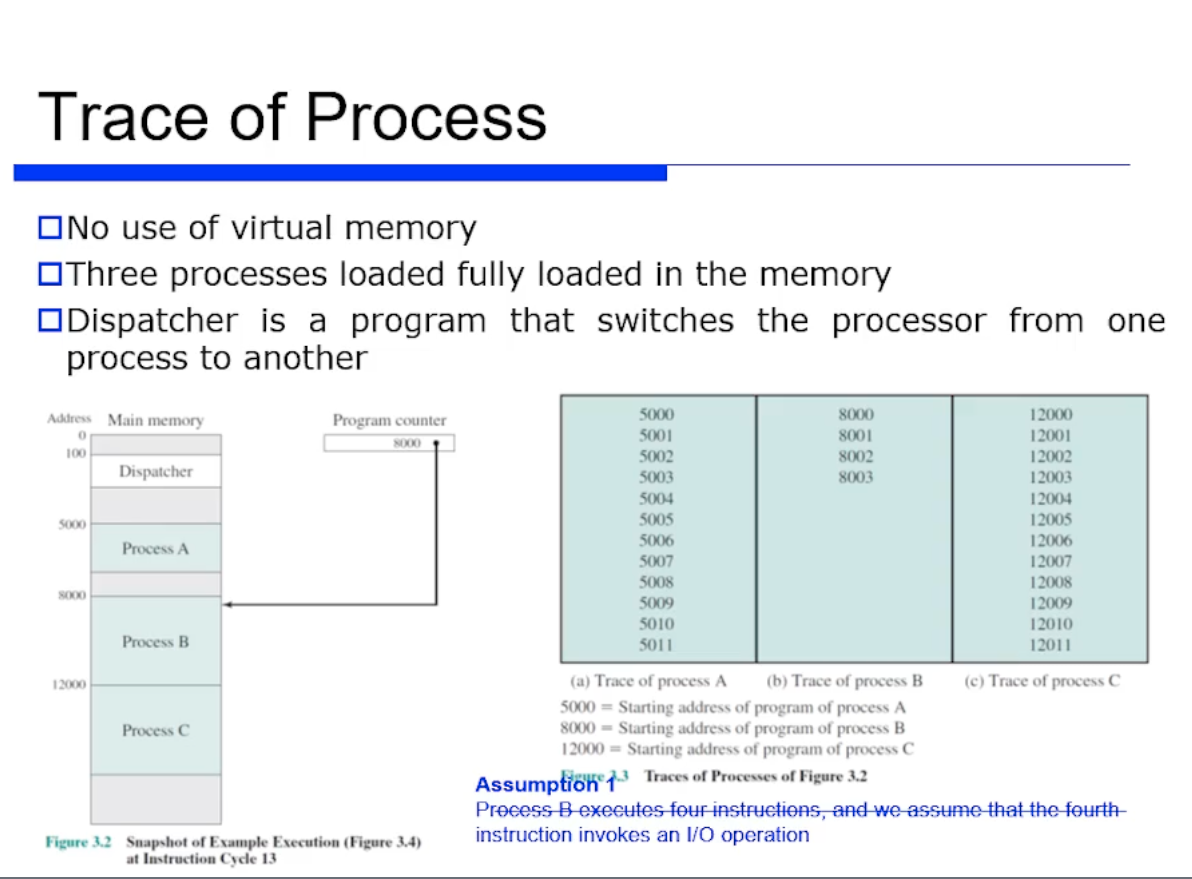
프로세스가 어떻게 실행되는지 시뮬레이션을 한번 돌려보자. 그 전에 가정을 몇가지 해보자.
-
가정1. virtual memory 를 사용하고 있지 않는다.
=> virtual memory 는 분산/부분 적재를 수행하는데, 이러한 적재가 없다는것이다. -
가정2. 3개의 프로세스가 메모리에 fully 하게 모두 올라온다.
=> 앞서 가상 메모리가 없다가정했으므로, 분산/부분 적재가 없어서 그렇다. -
가정3. Dispatcher (= 쉽게말해 OS 커널 영역이다.) 를 번역해보면 "내보낸다" 는 뜻인데, 스캐줄러라고 보면된다. 즉 Dispatcher 란 커널 영역에 있는 스캐줄 함수라고 이해하면된다.
프로세스 A, B, C 의 코드는 5000번지 부터 시작해서 프로세스들의 명령어들이 쭉 나열되어있다라고 생각하면된다.

그리고 가정하기를, 프로세스 B 의 8003번에 있는 4번째 명령어를 수행하면 I/O 연산을 요청한다고 되어있다. 이는 뭘 의미하냐면, I/O 연산을 수행하면 프로세스 B는 무언가 더 수행하지 못하고 이벤트가 올때까지 waiting 해야한다는 것이다.
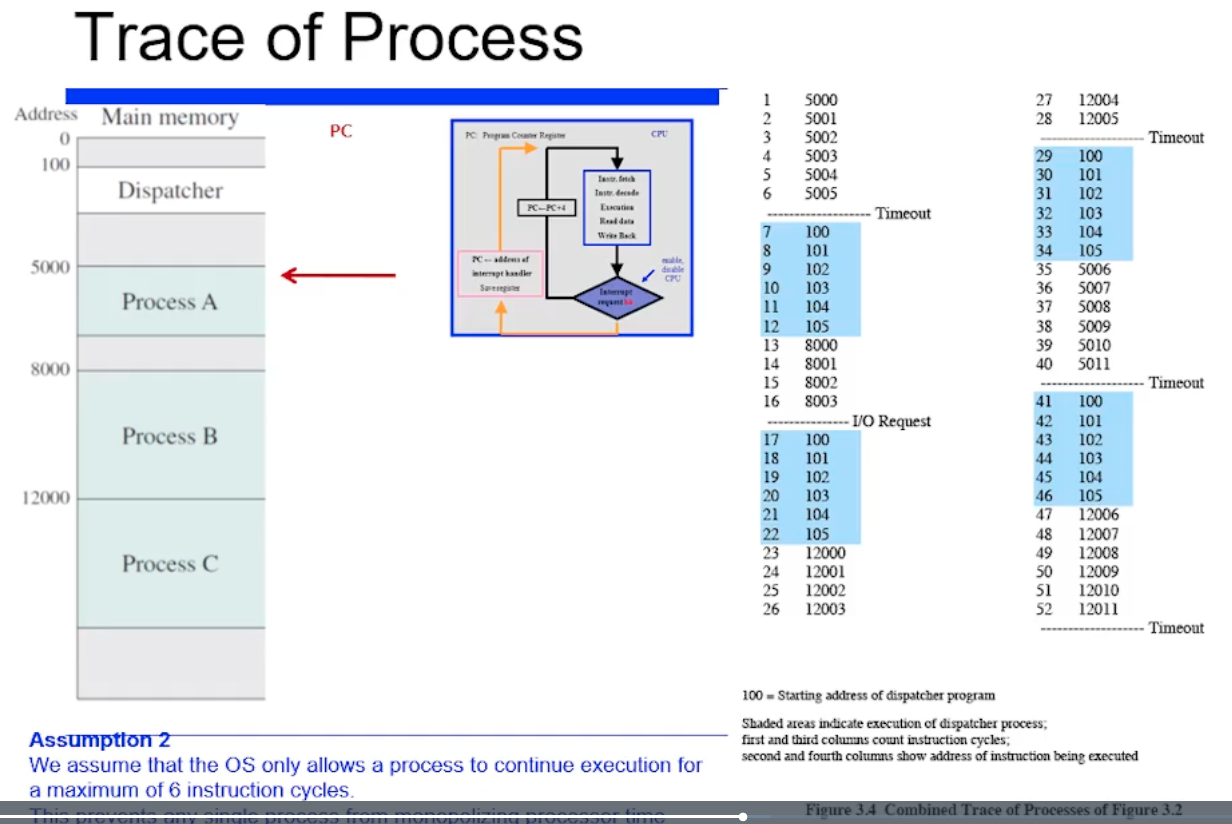
위 예제를 시뮬리이션 돌려보면서 자세히 이해해보자.
PC 가 프로세스 A 의 5000번지를 가리키고 있다고해보자.

또 2번째 가정을 하고있는데, time sharing 에서 time slice 가 6개의 명령어 사이클만 수행하고 timeout 된다고 가정하고있다.
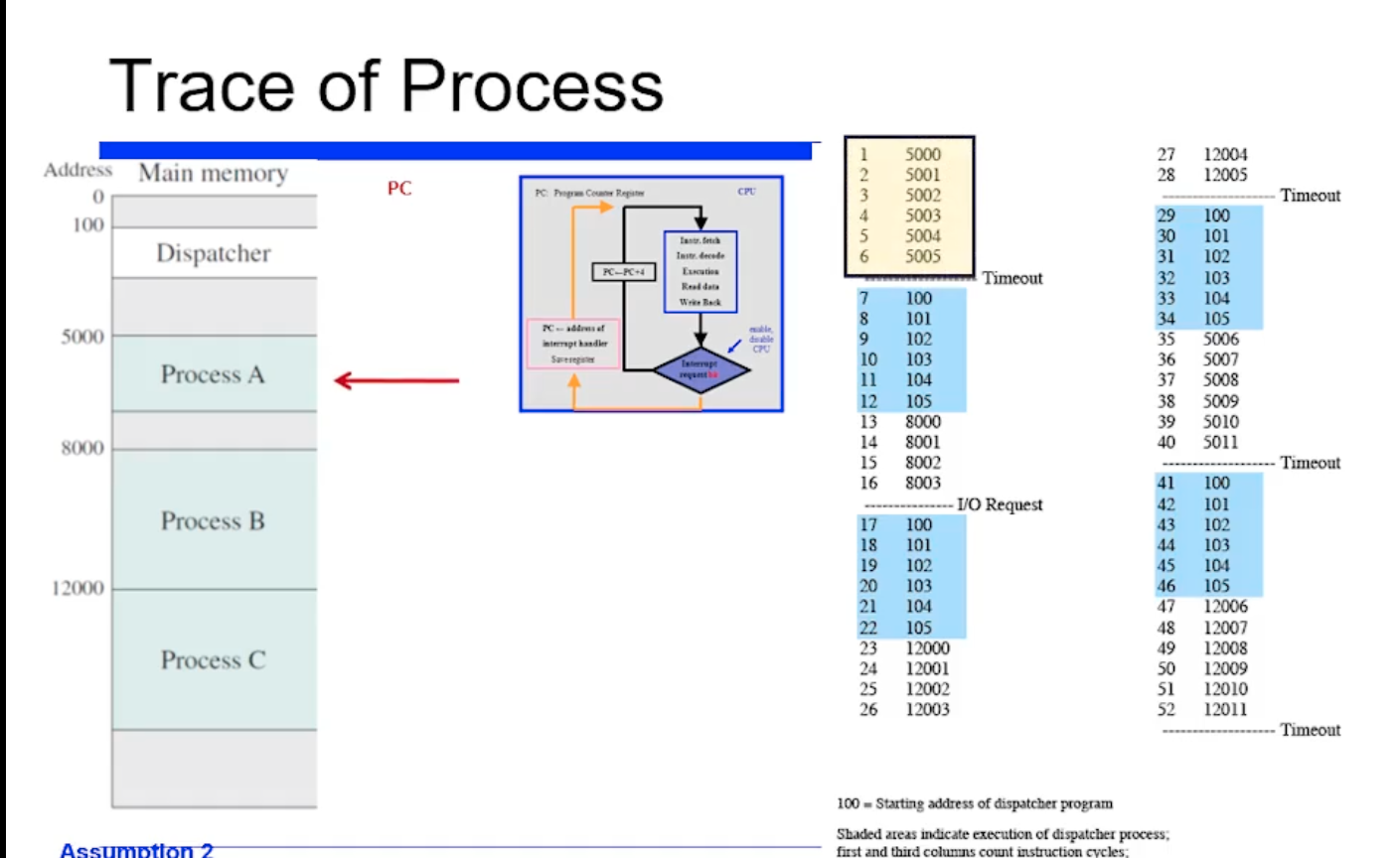
아무튼 이 프로세스 A를 5000번지부터 시작해서 5005번지 까지 수행하다가 timeout이 왔다. timeout 이 걸렸다는 것은, timer interrput 가 와서 time slice 을 사용했다고 인식하고 스캐줄링을 두른다.
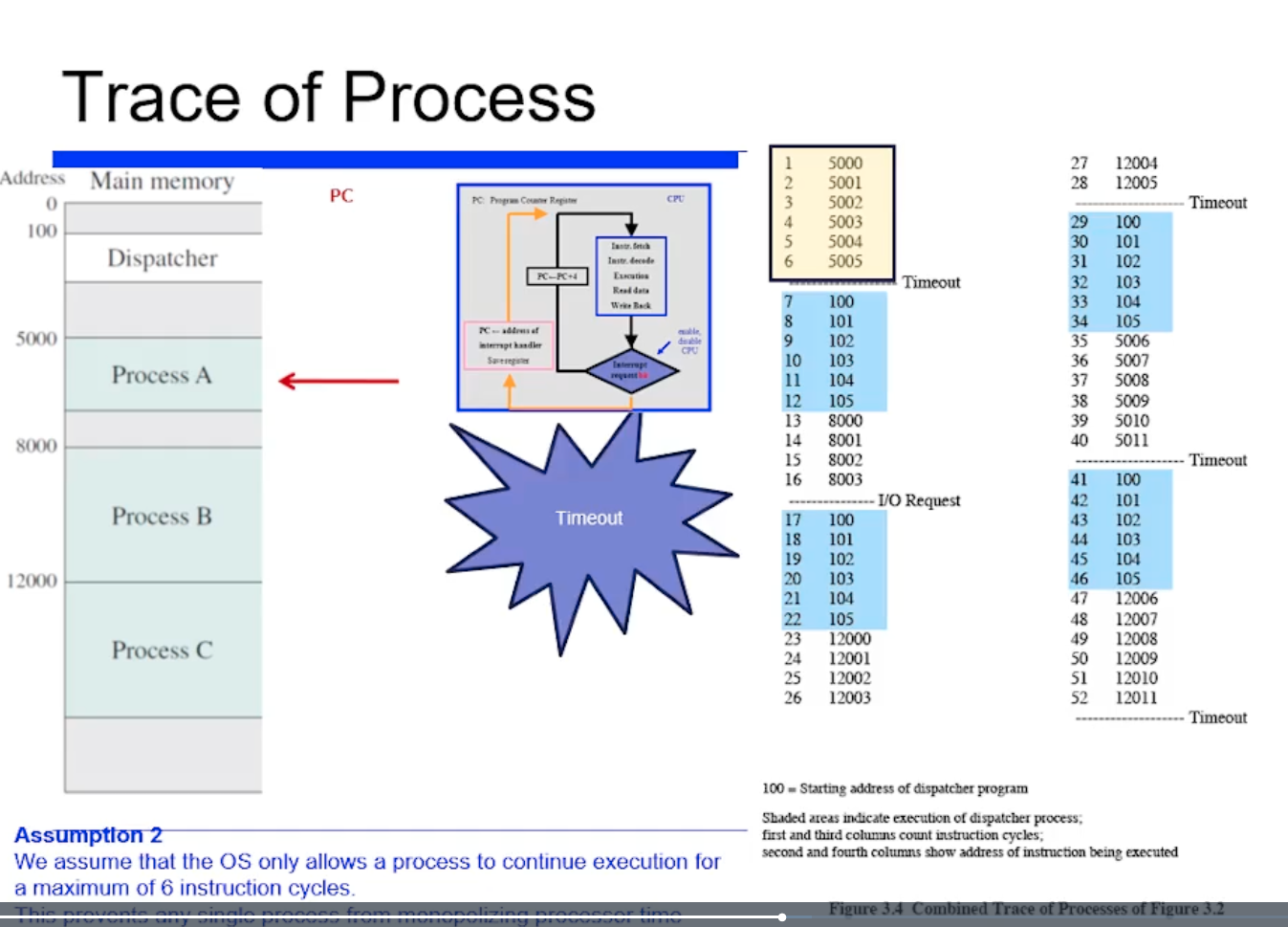
timeout 되면 스캐줄링을 두르는데, process B 를 다음 프로세스로 선택한것이다.
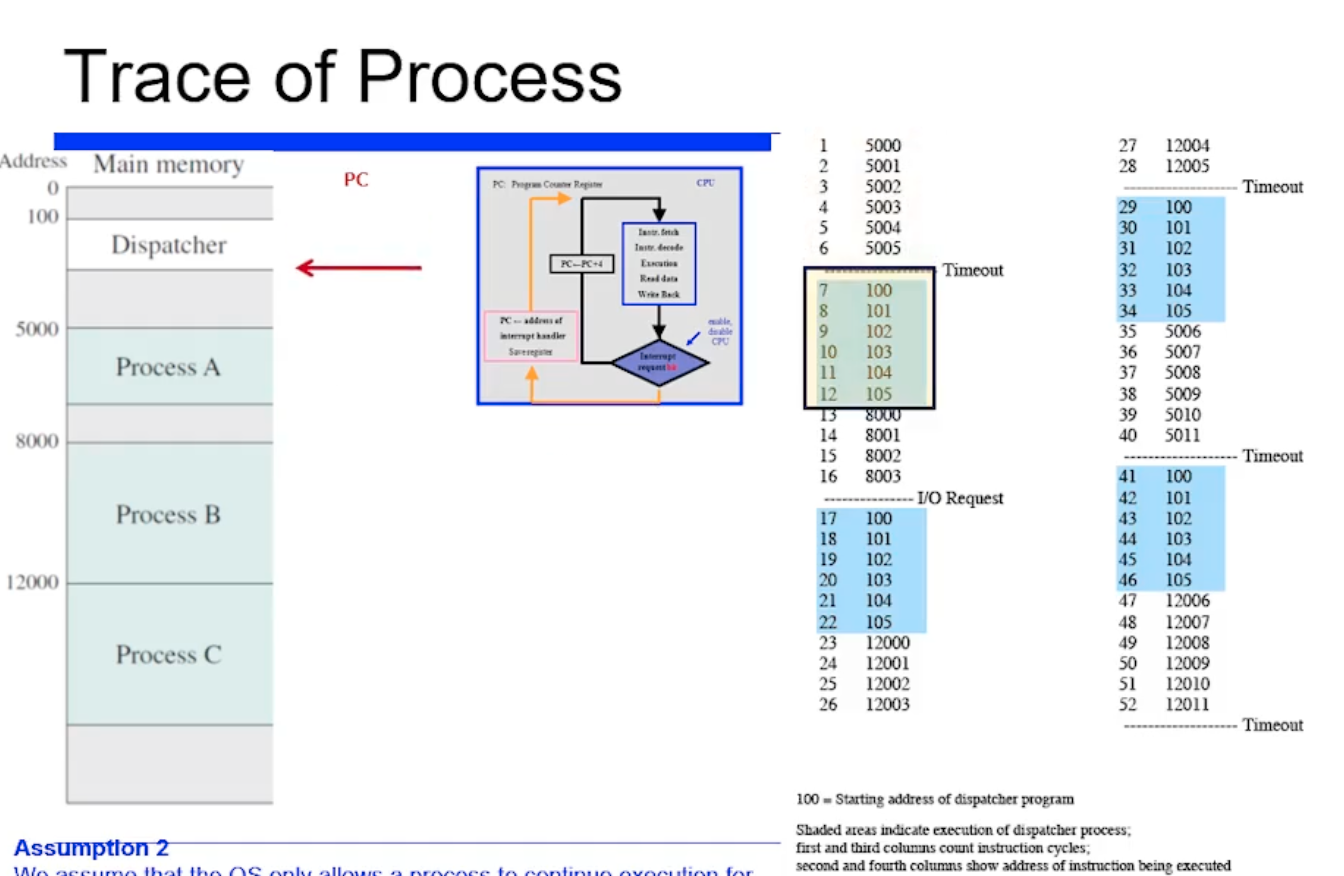
즉 timeout 걸렸으므로, 위처럼 스캐줄링으로 Dispatcher 코드를 수행하고
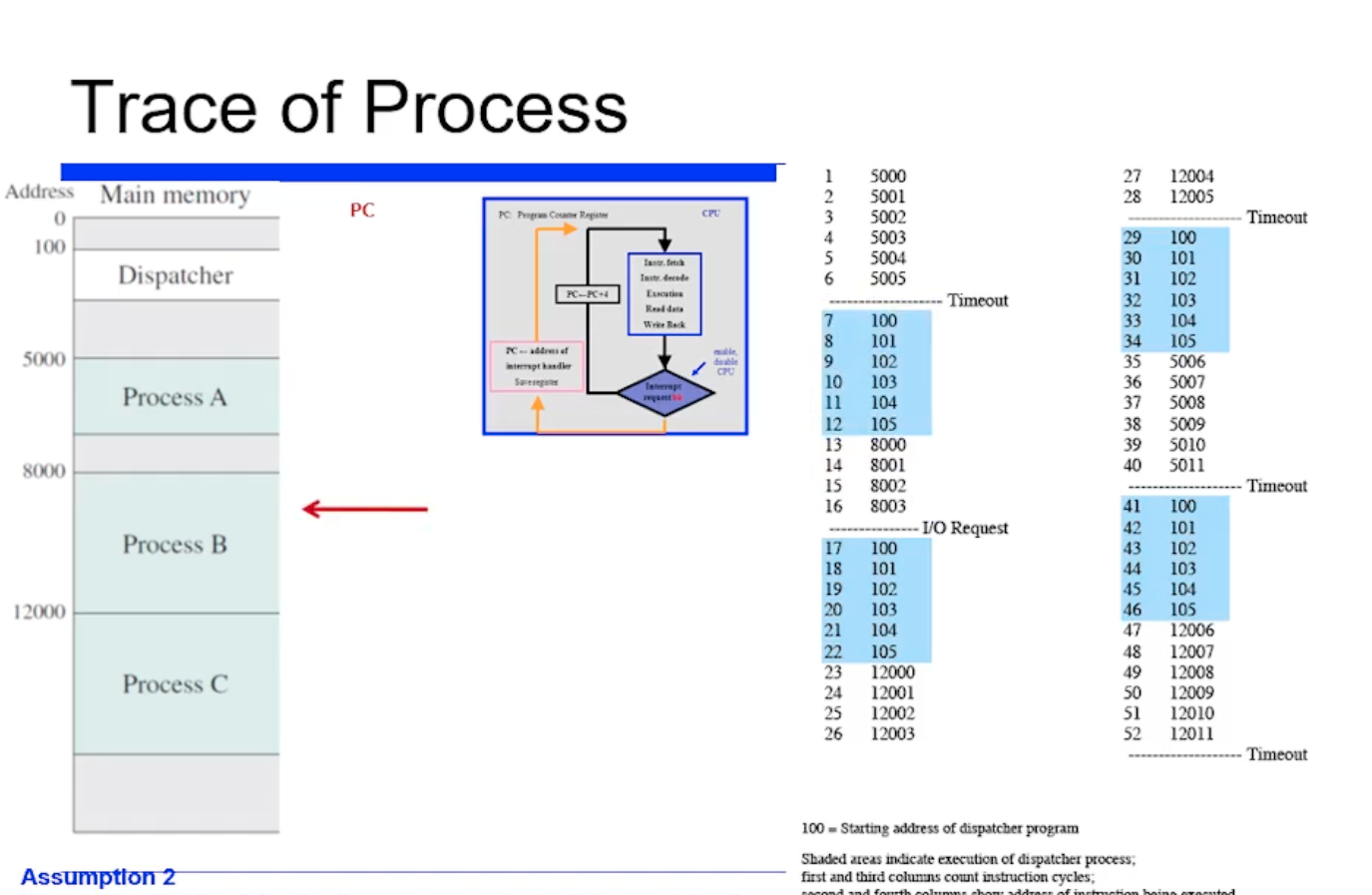
다음 프로세스로 B 를 선택한 상황이다.
=> 여기까지 내용을 정리하면, 프로세스 A 가 수행되다가 timeout 되고 100번지에부터 커널코드가 수행되고 B 가 선택되서 8000번지가 수행된것이다.
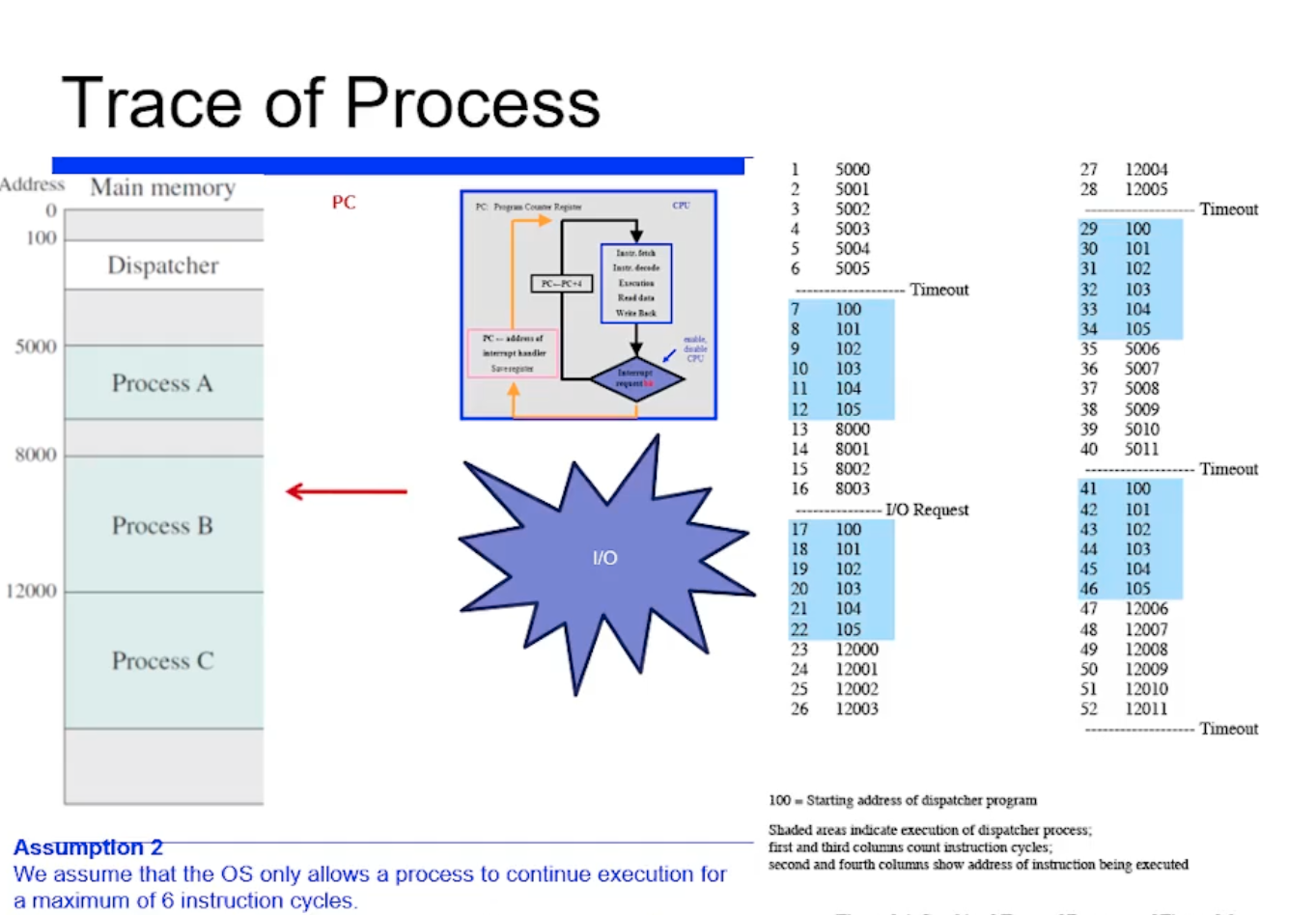
그 다음으로 프로세스 B 의 8003번에 있는 4번째 명령어를 수행하면 I/O 연산을 요청한다고 가정했었다. 그렇다면 synchoronous I/O 같은 경우에는 더 이상 진행되지 않을것이다.
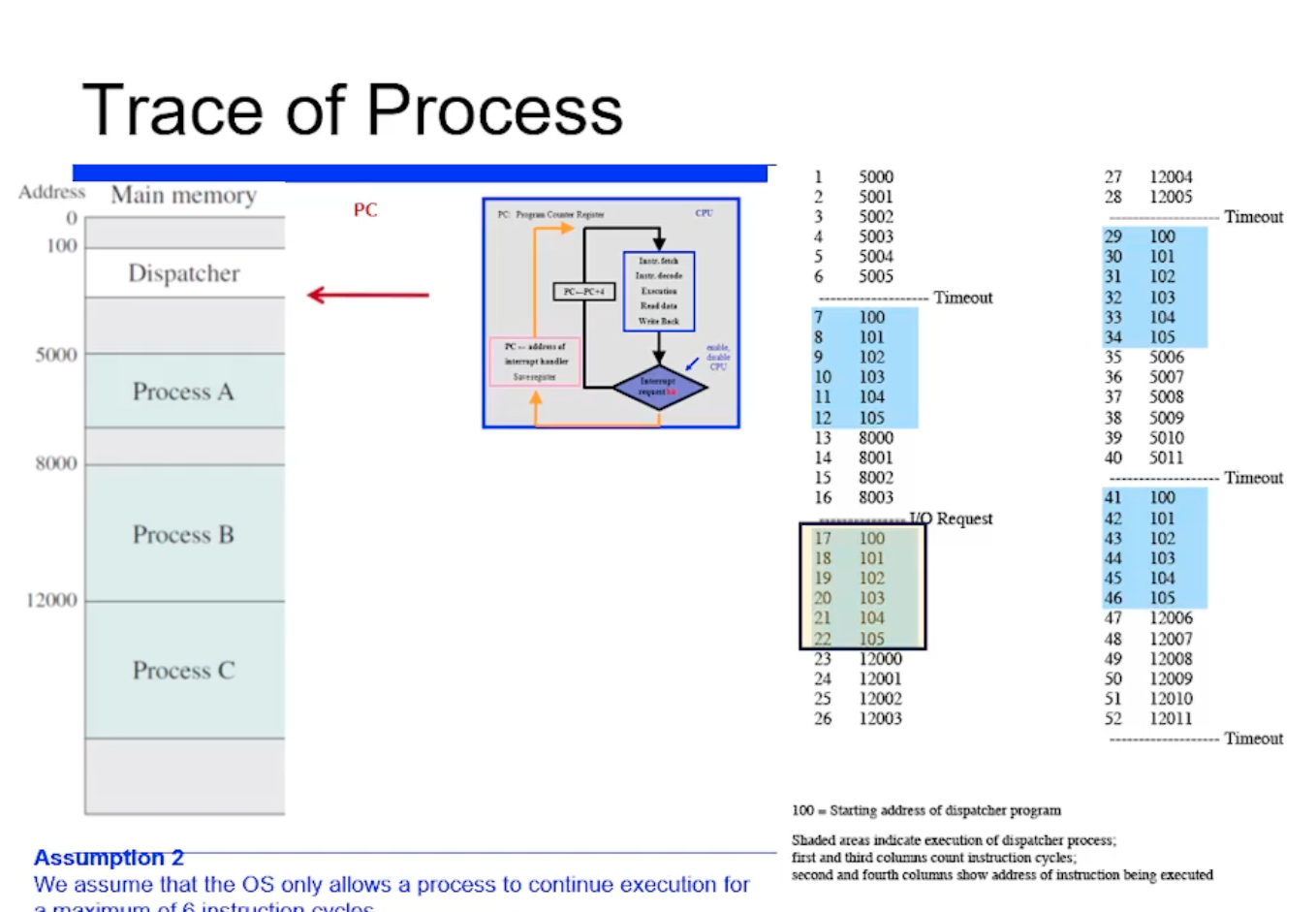
그러면 커널 Dispatcher 코드가 또 호출된다.
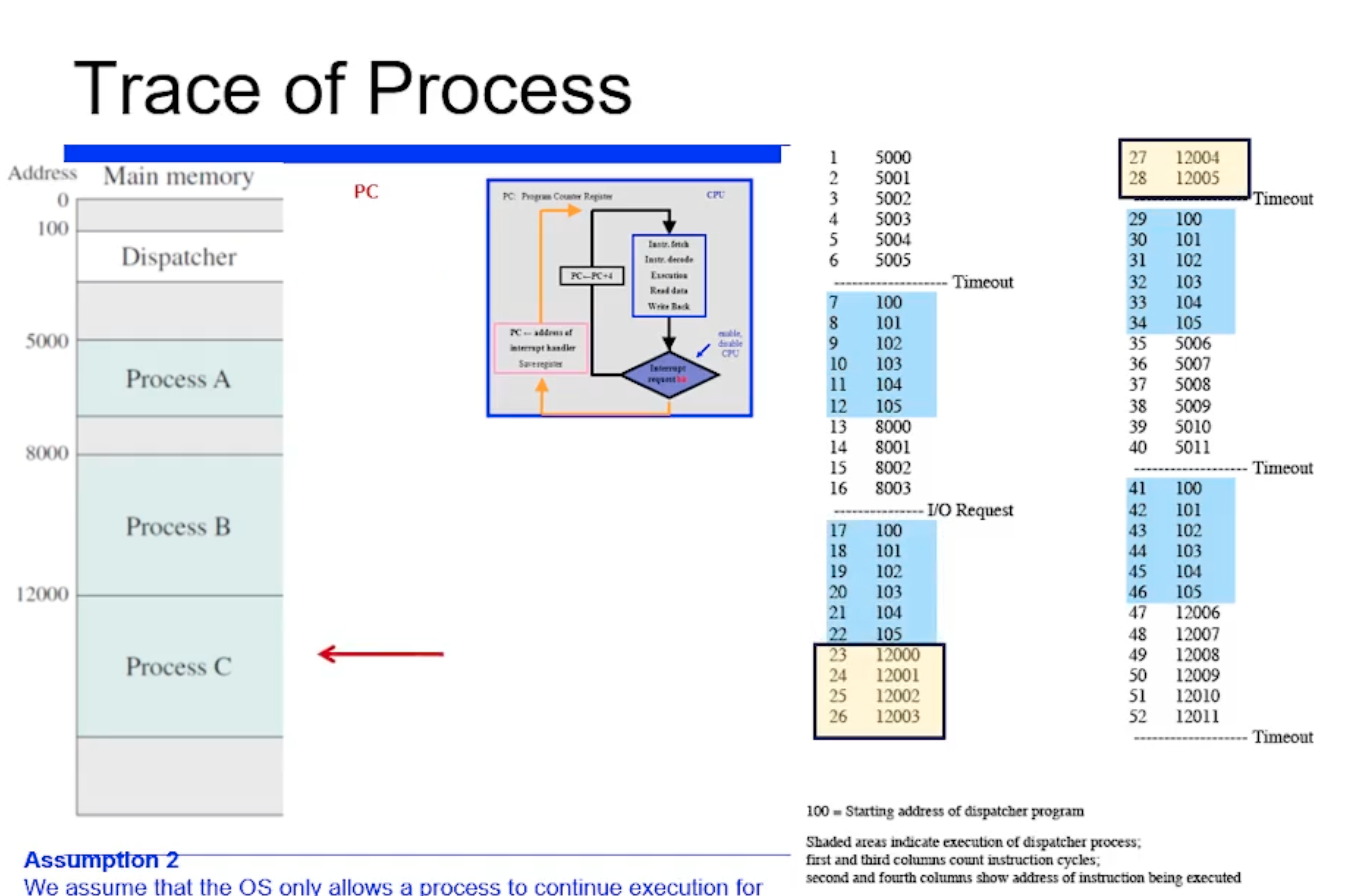
Reqeust 를 하면 보통 커널 모드로 가서 필요에 따라서 스캐줄링이 일어날 수 있는것이다.
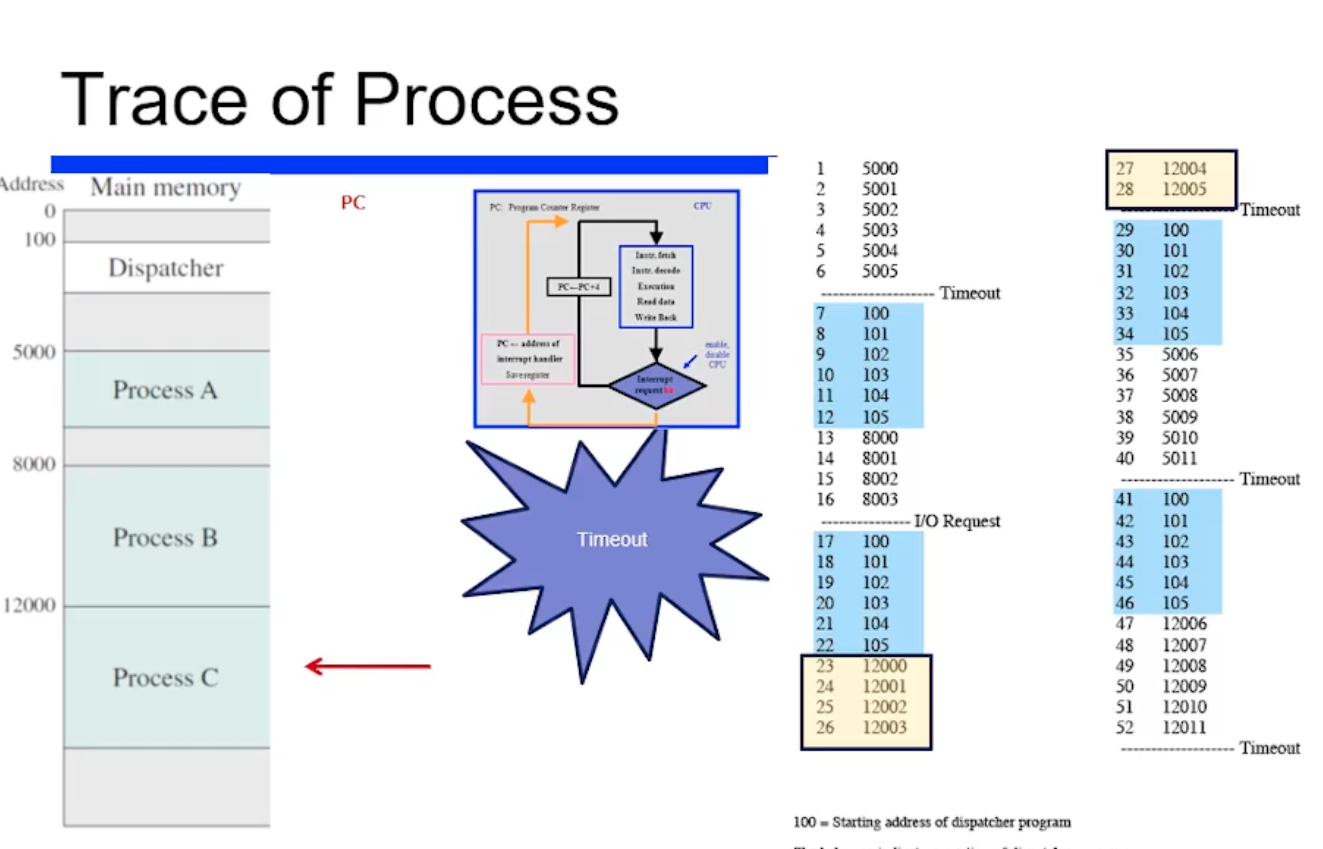
또 프로세스 C 를 수행하다가 timeout 나면 또 커널로 간다.
정리해보자. 프로세스 A 수행하다가 - 커널 수행하다가 - 프로세스B 수행하다가 - 커널 수행하다가 - 프로세스 C 수행하다가 - 커널 수행하다가 - 아까 5005번지에 끝났으니까 5006번지 부터 다시 수행하는 interleaving 이 일어나게된다. 그런데 프로세스 A 입장에서보면 concurrent 하게 계속 수행되는 것처럼 보인다.
=> 이렇게 유저모드와 커널모드를 계속 왔다갔다 하는 mode switching 이 일어난다.

Process Switch (프로세스 교환)은 mode switch 를 선행하고 있는것이다. 이 disptacher 가 커널 모드에서 일어나기 때문이다.
아무튼 mode switch 가 발생되어야지(선행되어야지) process switch 가 발생하게 되는 것이다.
그런데 항상 mode switch 가 있다고해서 process switch 가 있는것은 아니다. 즉 커널모드로 갔다고해서 항상 process switch 가 일어나는것이 아니다. 따라서 process switch 보다 mode switch 의 발생비율이 더 높다.
그렇다면 process switch 는 언제 발생하는가?
time interrput
process switch 발생 주 원인은 timeout, I/O Request 이다. process switch 는 timeout interrput (clock interrput 라고도 부름) 에 의해서 발생한다.
다시 정리해보면, interrput 에 의해서 mode switch 는 항상 발생하는 것이고 process switch 까지 이어질 수도 있는것이다.
이러한 timeout interrput 말고도 Disk 에 요청을 했는데 그 결과가 오는 interrput 가 올 수 있다. 이 프로세스는 요청했을때 block 상태로 그 이벤트를 기다리고 있게된다. 그런데 이 프로세스가 우선순위가 높은 프로세스일때, 지금 응답이와서 내가 기다리는데 이벤트가 온 경우, state 가 Ready state 로 바뀐다.
그러면 우선순위가 높은 프로세스라면 스캐줄러가 바로 즉시 스캐줄링(process switch)을 한다. 이 시나리오에서는 interrput 에 의해서 timer interrput 가 아닌 일반적인 interrput 에 의해서 process switch 가 발생할 수 있다.
또 2번째 예시는 바로 I/O Request 이였다. I/O 요청을 보낸다, I/O 리소스를 사용한다 와 같은 것들은 system call 이다. 우리가 system call 을 하면 많이 기다려야한다. synchornous I/O 인 경우 process switch 가 발생할 수 있다.
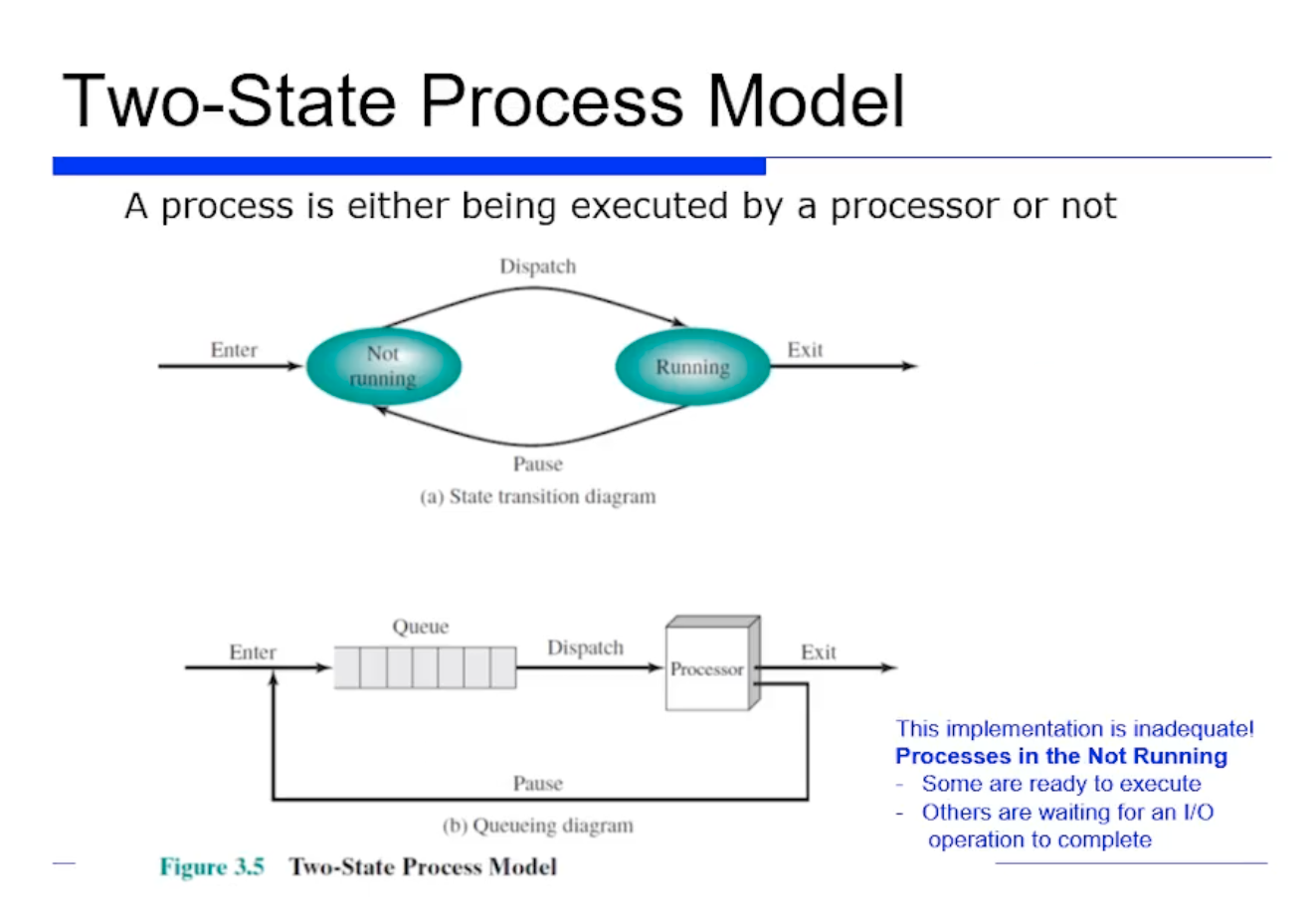
프로세스는 2가지 상태로 나눌 수 있다. CPU 를 활용해서 수행중인 상태인 running state 와, CPU 를 활용하지 않는 not running state 가 있다.
프로세스가 n개, 프로세서의 수가 m개 있다고 가정해보자. 그러면 우리는 MultiProgramming 을 가정하고 있기 때문에, 프로세스의 수가 더 많다. (n > m)
예를들어 n=1000, m=1 이라고 가정해보자. 그러면 running state 인 프로세스는 딱 1개일 것이고, not running state 는 999개 일것이다.
만약에 프로세스를 구현한다면 당연히 Queue 가 필요하다. Queue 는 OS 가 프로세스들을 제어하기위한 구조로써, Running State 와 Not Running State 에 있는 프로세스들을 PCB 로 연결하는 구조로 구현되어있다. => 이들을 Ready List 라고 부른다.
스캐줄러가 스캐줄링할떄, 즉 process switch 가 필요한 적절한 시점에 이 Queue 를 본 다음에 Dispatcher 가 not running state 인 프로세스를 하나 선택 하는것이다. not running state 는 running state 로 바뀌게 되고, 기존에 있는 프로세스는 not running state 로 바꾸는 방식으로 구현하면 된다.
그런데 이렇게 구현하면 문제가 있다. not running state 인 프로세스에는 바로 CPU 를 제공해줬을때 수행가능한 프로세스가 있는 반면에, 아직도 I/O 연산을 기다리는 프로세스도 있을 수 있다. 그러면 그 프로세스는 CPU 를 줘봤자 수행 못한다.
(utilization 이 내려감)
이를 해결하도록, not running state 를 2개로 쪼갠다. 즉 ready state 와 block state 로 쪼개는것이다.
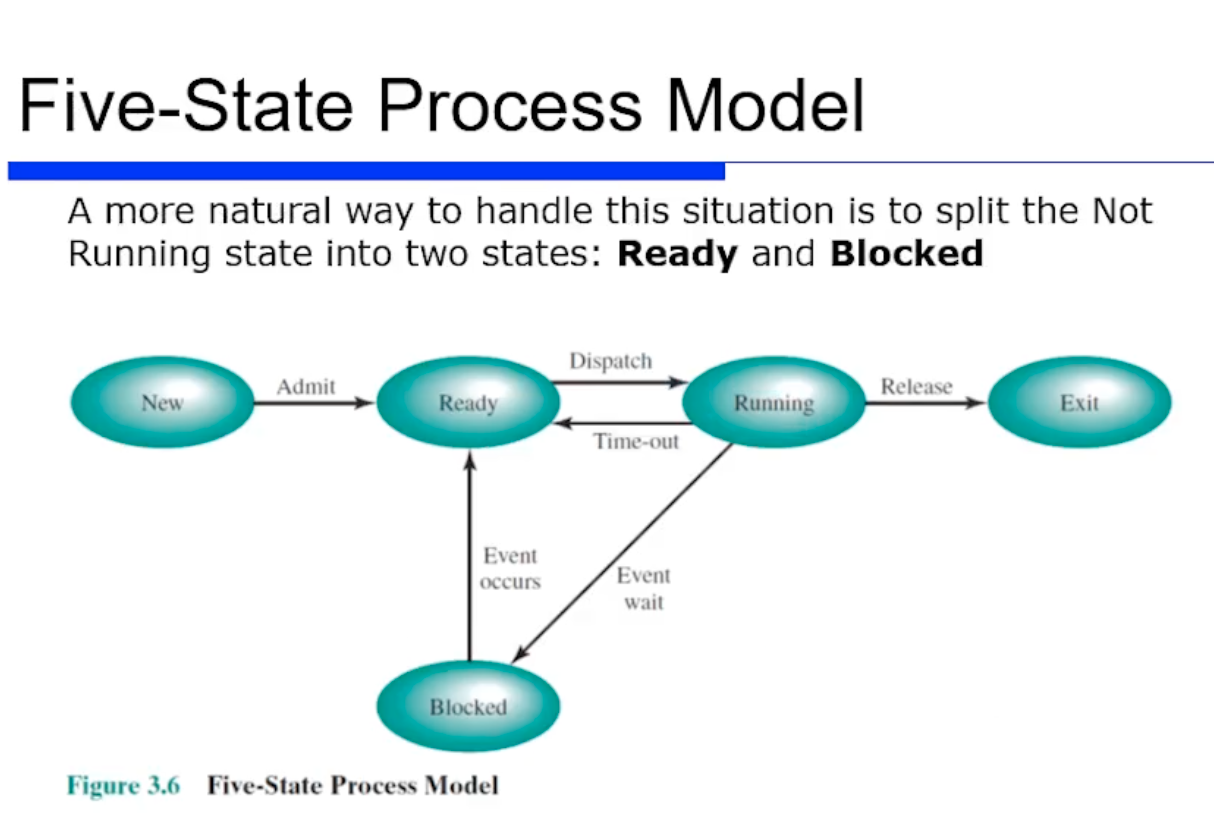
그래서 등장한것이 바로 Five State 프로세스 모델이다. 이 모델은 보듯이 not running state 를 위처럼 ready state 와 block state 2개로 구분했고, 추가적으로 new 와 exit state 를 추가했다. 그래서 이렇게 총 5가지의 state 가 존재한다.
new state
new state 란 프로세스를 fork 하면 가장 먼저 OS 가 PCB 를 만든다고 했었는데, 최종적으로 ready state 로 만들기 직전까지의 state 를 의미한다. 이렇게 ready state 직전까지는 PCB 같은 것들이 완벽하지 않으니까, 스캐줄러의 대상이 아니다. 그러니까 fork 하면 new state 상태로 시작하게된다.
new state 인 프로세스가 어느정도 준비가 되면 ready state 가 되고, ready state 상태로 있다가 Dispatcher 의 스캐줄링 대상이 되면 running state 로 전환된다.
running state 로 전환후 실행하다가 특정 프로세스가 혼자서 독점을 방지하기 위해 timeout 될수도있다. timeout 되면 다시 ready state 로 바뀌게 된다. 반면 시간을 줘도 I/O Request 를 수용하지 못하는 경우 Blocked 상태 (waiting 상태 라고도 부름) 가 된다.

- new state : OS 에서 아직 Ready state 가 안된것
- ready state : 기회가 주어지면 바로 수행할 준비가 되어있는 프로새스
- running state : 수행중인 상태
- blocked (또는 waiting) state : I/O 연산(이벤트)을 기다리고 있는 상태
- exit : 종료 상태
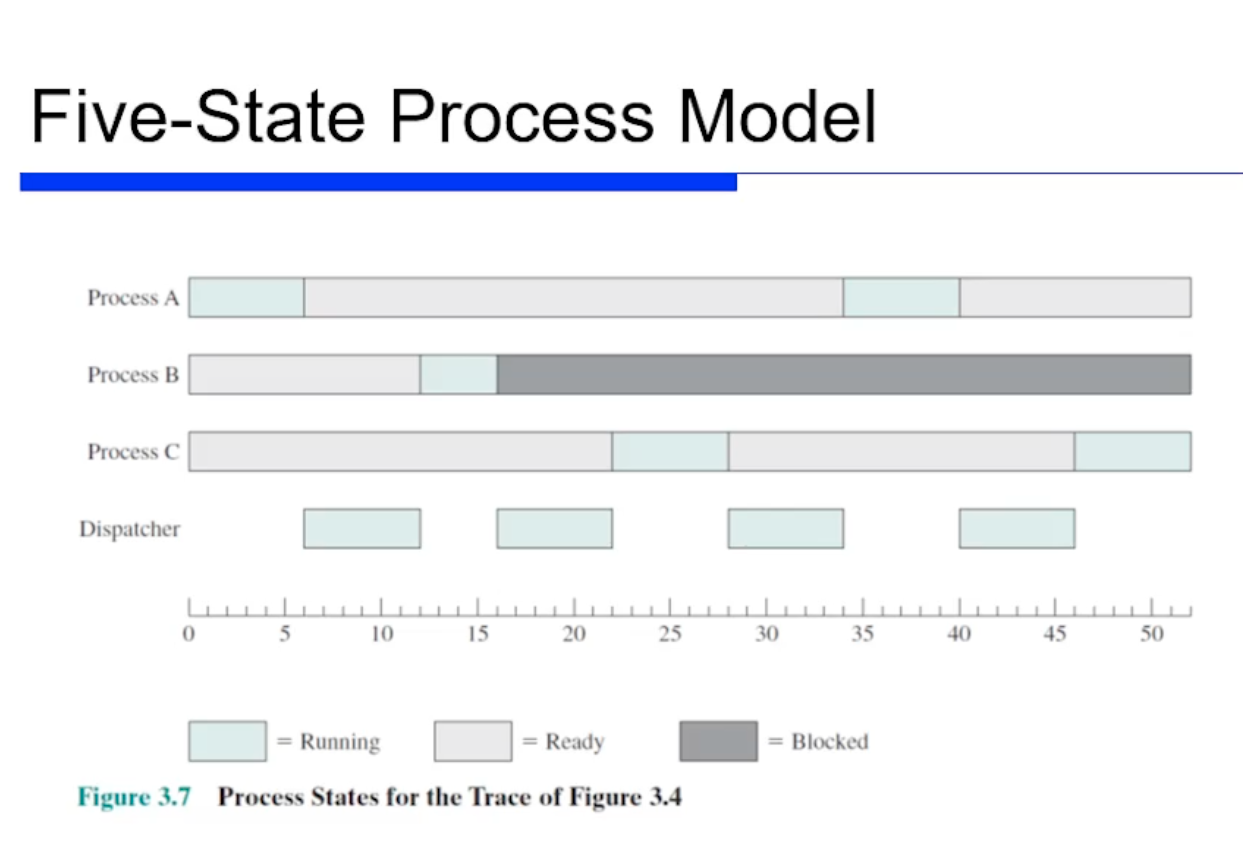
위 그림은 시간에 따른 프로세스별 state 를 나타낸것이다.
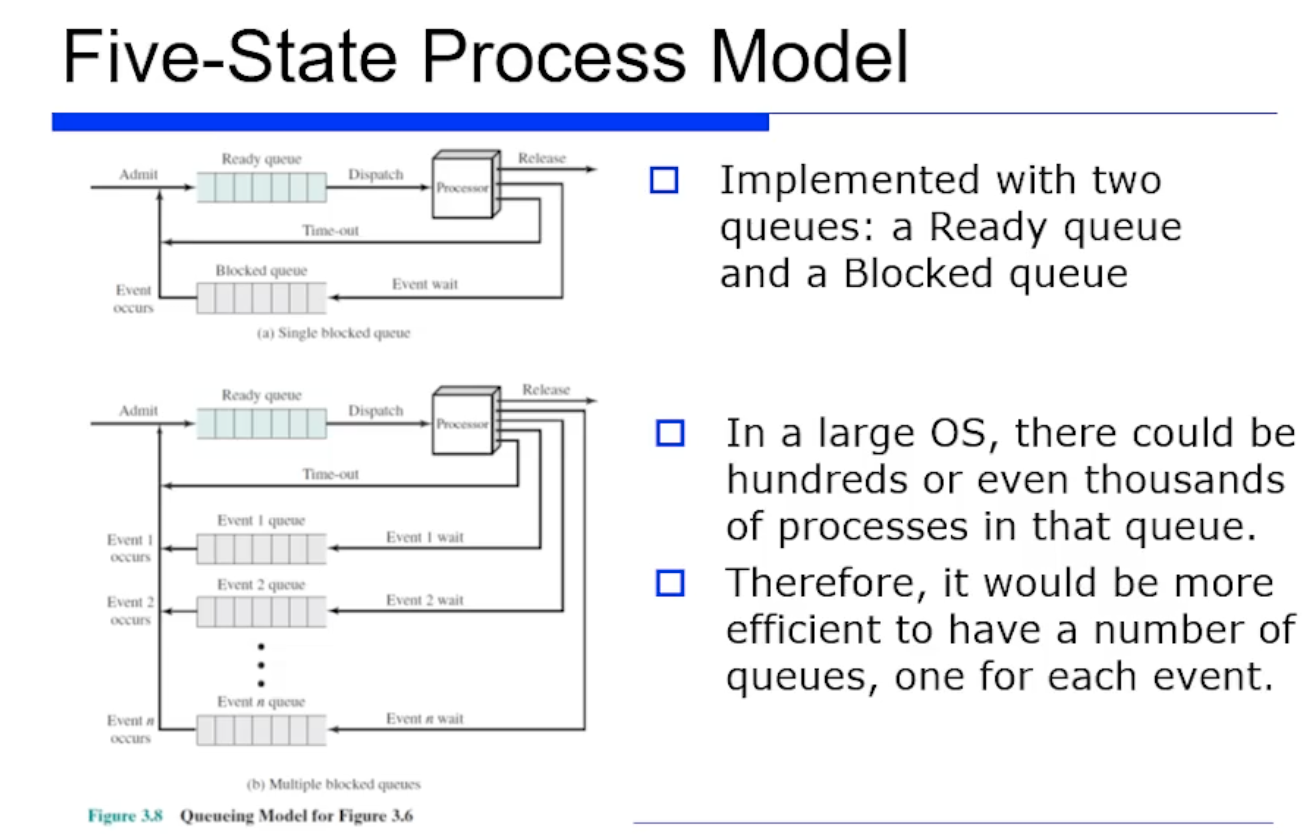
five state 프로세스 모델을 구현하기 위해선 2가지의 큐가 필요하다. Ready queue 와 Blocked queue 이다.
만약 프로세스가 timeout 된 경우 ready queue 로 가야하고, I/O Request 를 했다면 기다리는 대기장소인 Blocked queue 로 간다.
큰 큐모의 OS 에서는 프로세스가 엄청 많고, blocked 된 프로세스들도 많아지게 될 것이고 이들을 큐에 저장할텐데, 어떤 이벤트가 어떤 프로세스에 대한것인지 찾는것은 굉장히 오래 걸리기 때문에 이벤트 종류별로 여러개의 큐(Multiple Queue)에다 분류해놓는다.

