운영체제 : 프로세스 Switch

본 포스트는 학교 수업 강의내용을 단순 정리본 형태로 만든 내용입니다. 평소 포스트와 달리 다소 설명이 부실할 수 있음을 미리 알려드립니다 🙂
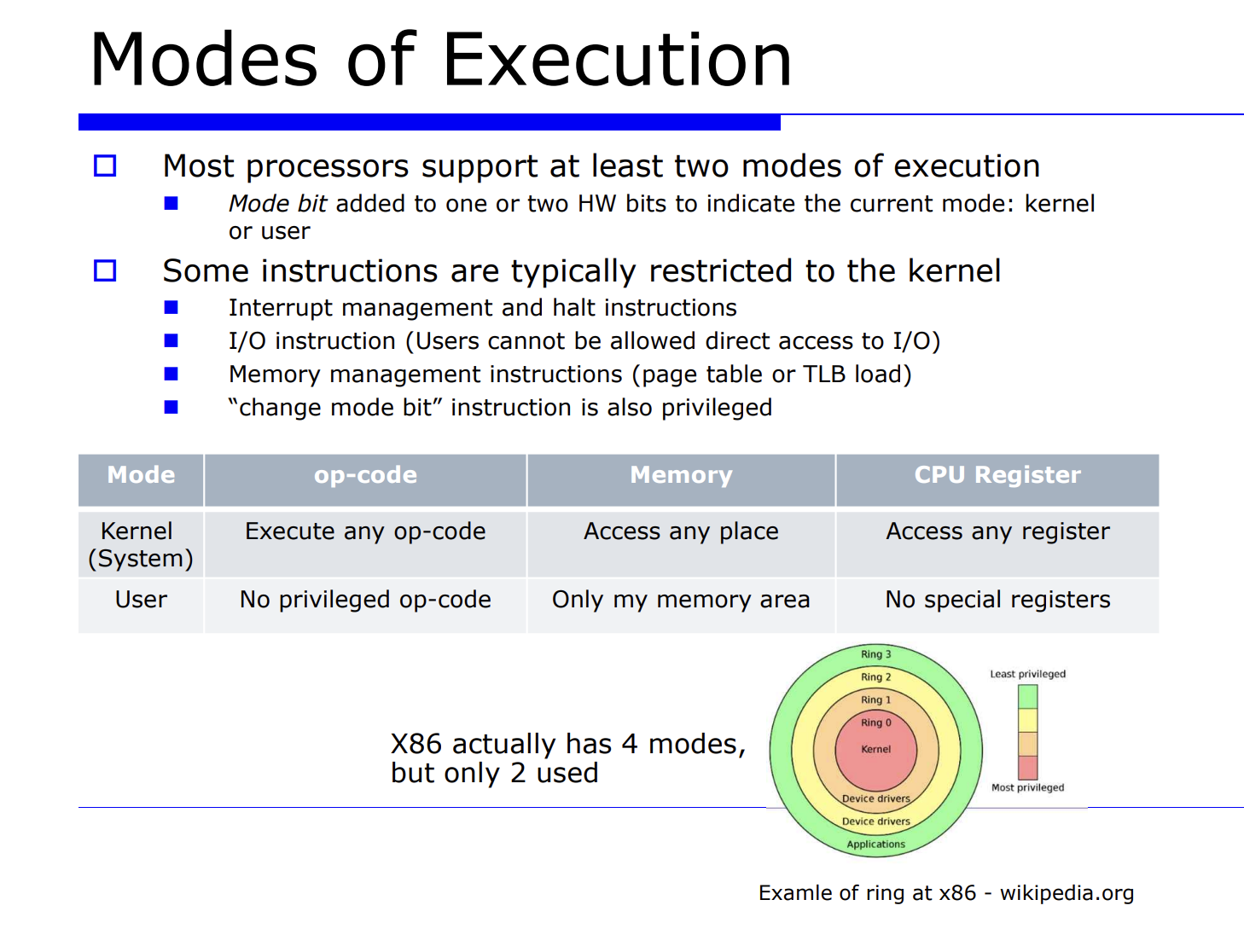
프로세스의 실행모드는 2가지로, 모드가 어떤것인지 저장하기 위한 1 bit 가 필요하다. 이 1bit 를 mode bit 라고한다. interrput flag 를 enable/disable 하는 특별한 명령어가 있다.
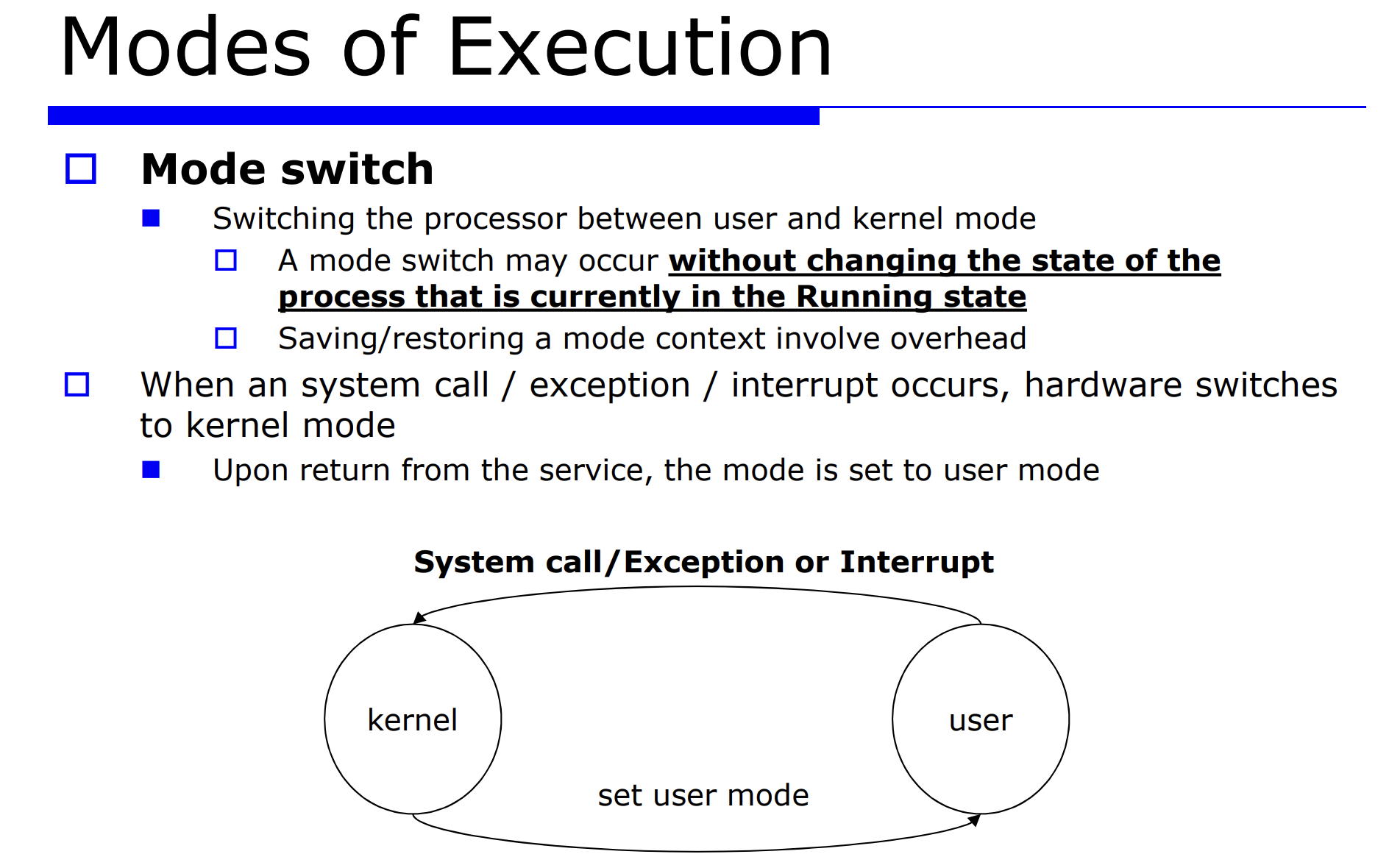
- mode swtich : 커널모드와 유저모드 사이에서 모드를 바꾸는 것
mode switch 에서 가장 중요한것은 다음과 같다.
- state : 현재 수행상태(state) 에 있는 프로세스
- 오버해드 : mode switch 로 인한 오버해드가 얼마나 발생할것인가
유저모드와 커널모드 사이에서 mode switch 가 발생하는 경우는 system call, exception, interrput 등이 발생했을 때다.

- interrput : 외부 디바이스들에 의해 발생하는 이벤트에 대한 처리 서비스
- exception : 어떤 프로그램이 수행하다가 에러 발생시 처리하기 위한 서비스

system call 과 interrput 와 exception 을 각각 따로 생각해보자.
- system call : 해당 프로세스가 요청한것이다. 따라서 그 프로세스와 연관이있다.
- exception : 해당 프로세스(프로그램) 수행중에 발행한 에러 코드에 대한 처리
- interrput : 반면 interrput 는 수행중인 해당 프로세스와 연관없을 수 있다.
process context : 이처럼 system call, exception 은 해당 프로세스와 연관있는 반면 interrput 는 연관이 없다. 즉, 커널로 들어오는 것은 system call 과 exception 2가지이다. 이 2가지가 커널로 들어오는 것과 연관이 있다. 즉 process context 는 커널이 프로세스를 대신해서 수행한다는 뜻을지닌다.
interrput : 반면 interrput 핸들러 서비스를 위해서 interrput context 로 구분하기 도 한다. 구분하는 이유는, interrput handling 을 하는데는 interrput 핸들링은 특성상 현재 수행중인 프로세스의 로직을 (time slice 를) 방해하고 있는 것이기 때문이다.
=> 따라서 interrput context 는 로직을 방해하기 때문에 최데한 빠르고 심플하게 처리되어야 한다.
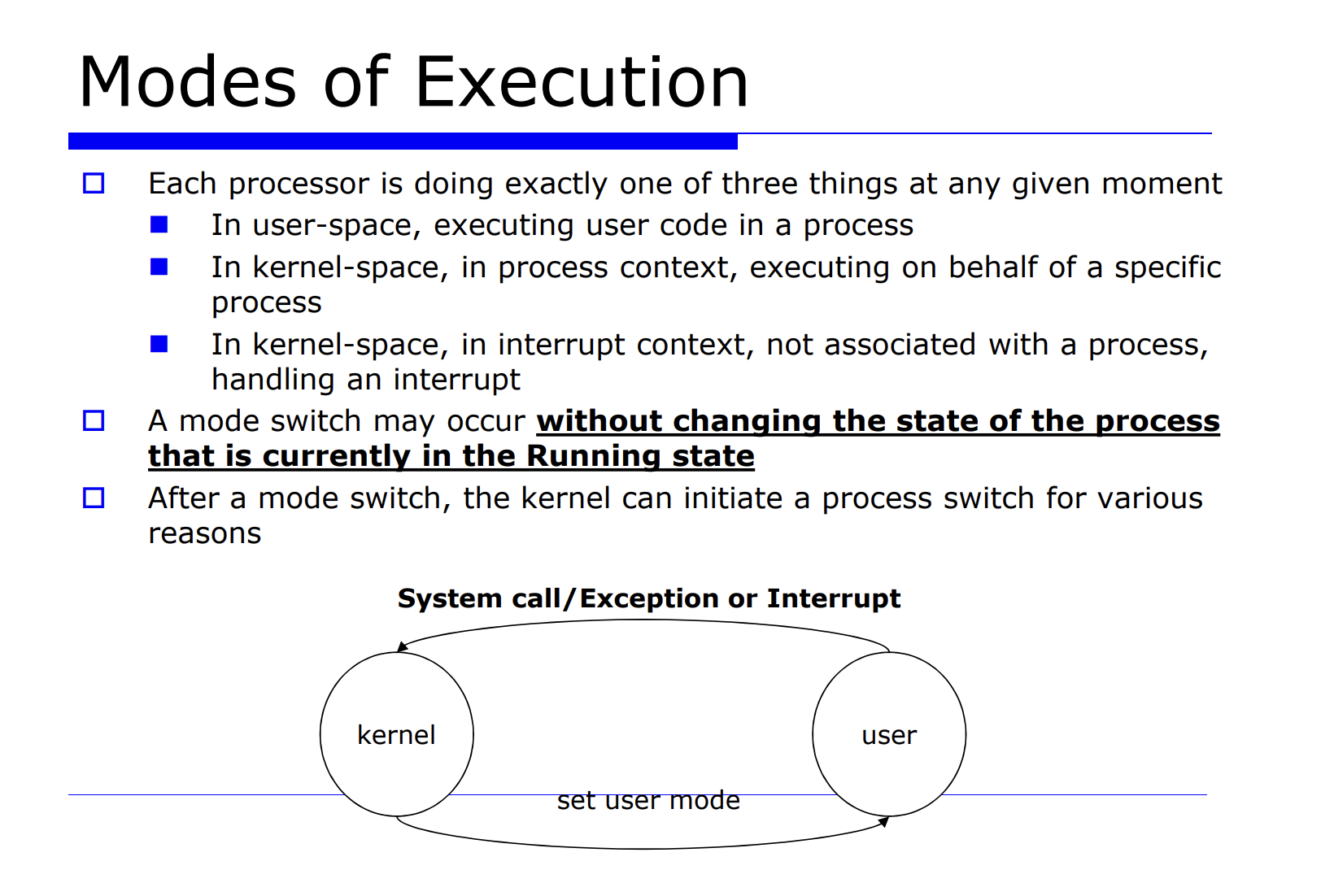
일반화시켜보자. 프로세스는 3가지의 경우를 가진다.
- user 공간(user space) 에서 유저 코드를 수행하는 상태
- kernal 공간에서 코드를 수행하는데, 그 코드가 process context 인 경우
- kernal 공간에서 코드를 수행하는데, 그 코드가 interrput context 인 경우
중요한 것은 mode switch 만으로는 프로세스의 상태(state) 가 바뀌지 않는다는 것이고, 그 다음 mode switch 이후에 다양한 원인에 의해 process switch 가 발생할 수 있다는 점이다.
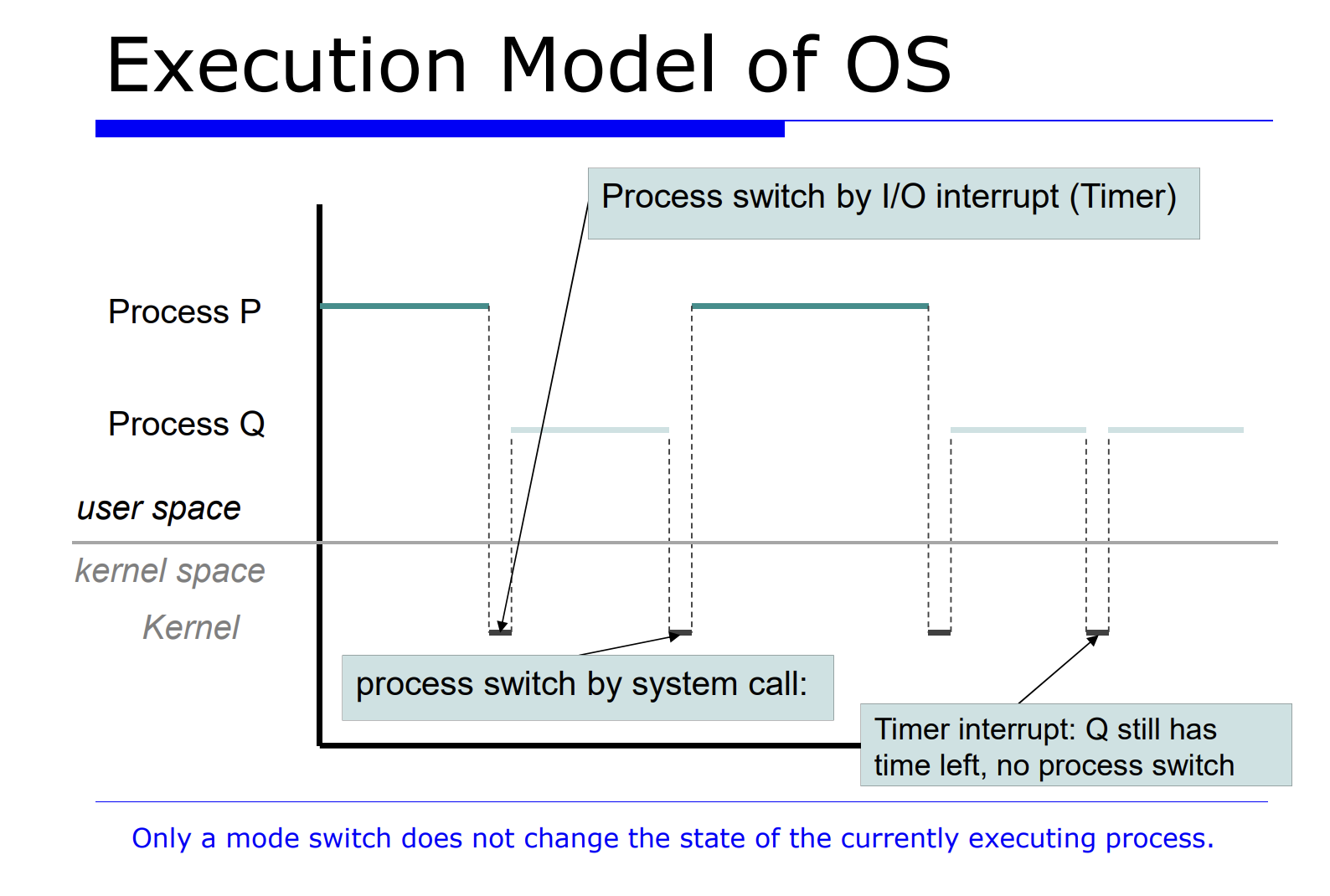
위 그림을 보면 프로그램 P 와 Q 가 있다. 이러한 상황에서, I/O Interrput 에 의해서 mode switch 가 발생했다.
위처럼 mode switch 가 발생해서 커널모드로 왔는데, 여전히 프로세스는 P 에 대한 커널 모드인것이다. 커널 모드로 와서 이후에 time slice 를 다 써버렸다면 process switch 에 대한 함수 호출이 발생한다.
process switch 가 되면 새로운 프로세스가 직전까지 수행한 진행상황부터 시작해서 다시 재개할 것이다.
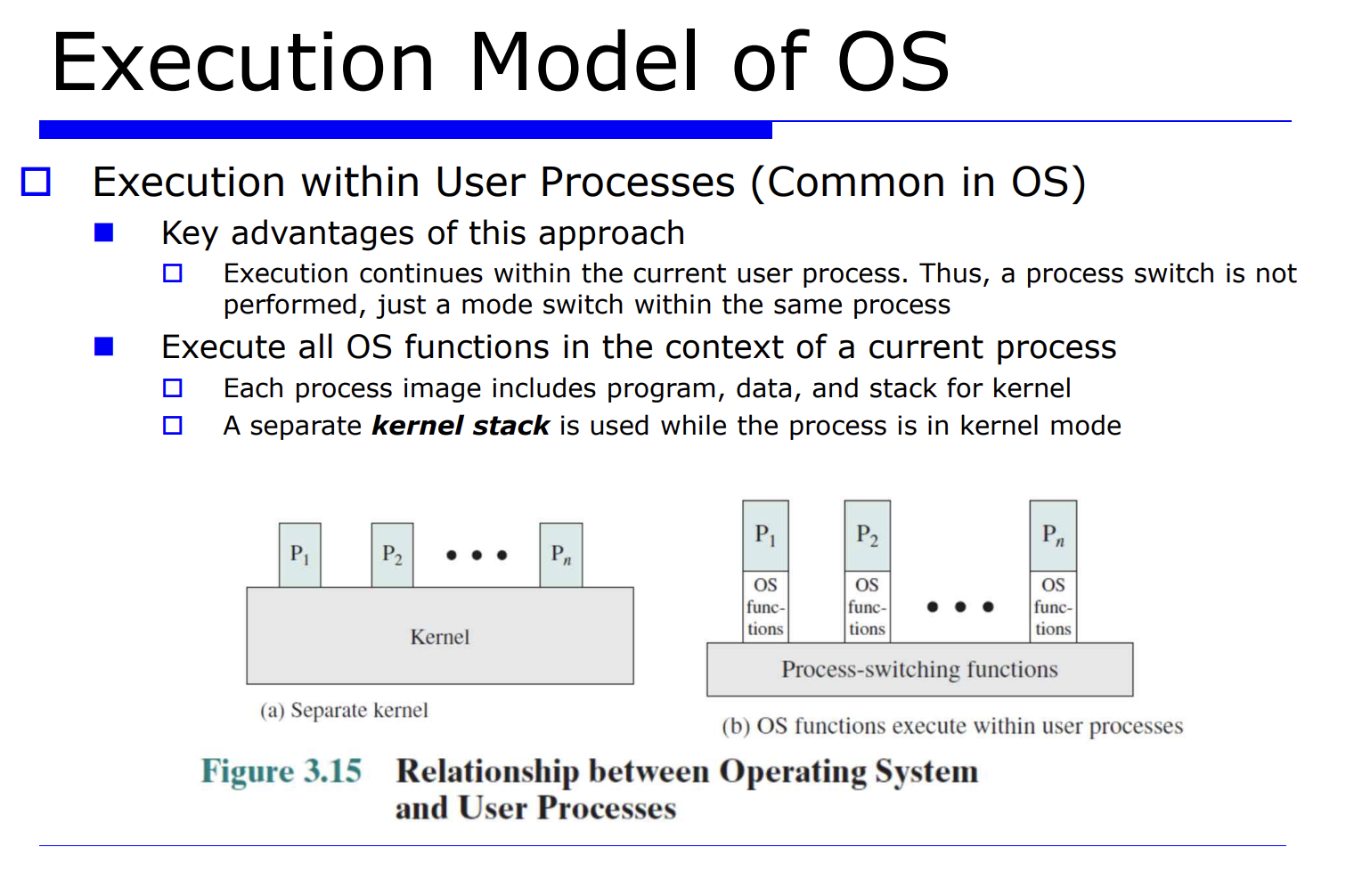
위 그림은 프로세스 사이의 관계를 보여주고있다. 이를 OS 의 실행 model 이라고 정의하고있다.
현대의 대부분의 OS 는 이러한 유저 프로세스 내에서 실행하는 model 을 가지고있다. 무슨 말이냐면 그림 (b)를 보자.
유저 프로그램 P1 이 수행하다가 어떤 이벤트(interrput, system call, exception) 등이 발생했을 때 커널 모드로간다. (mode switching 발생) 실행하다가 어떤 필요에 의해서 process switch 가 필요하다면, 커널 모드에서 다른 프로세스의 유저 모드로 switch 된다. (process switch)
만약에 system call 이나 interrput 같은거 발생하고 커널모드로 간후에 process switch 다시 기존에 수행하던 프로세스 P1 으로 되돌아온다.
반면 그림 (a) 는 OS 의 초기 모델이였다. 즉 프로세스 P1, P2, .. 를 수행하다가 아예 커널모드로 넘어가버리는 것이다.
=> 현재 OS 의 장점을 정리해보자면, 현재 유저 프로세스 내에서 필요한 경우 process switch 가 발생하고, 필요없다면 기존 유저 프로세스를 다시 실행하는 유연함이 있다는 것이다. (불필요한 mode switch 가 발생하지 않는다)
=> 스택 : 어떤 프로그램 A 를 수행하다가 B 로 넘어가기 위해 A 에 대한것을 스택에 저장하는 방식이다.
- 유저 모드를 위한 스택이 필요하고, 커널 모드를 위한 스택이 필요하다. 즉, 각 프로세스마다 2개의 프로세스(유저 프로세스, 커널 프로세스) 가 필요하다.
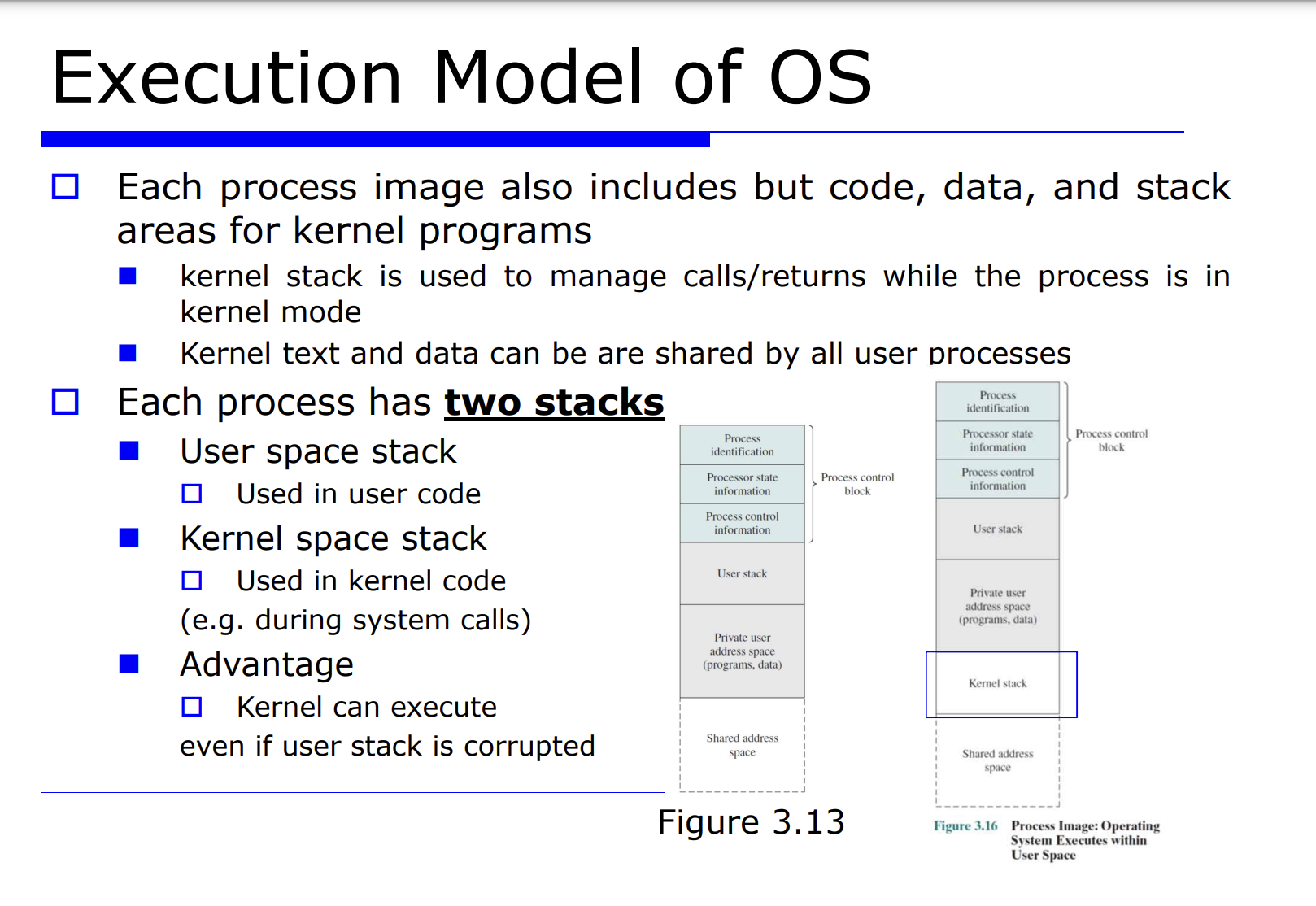
프로세스를 위한 code, data, stack 이 필요하다. 그리고 각 프로세스는 2개의 스택(유저 코드를 수행하기 위한 스택, 커널 코드를 수행하기 위한 스택) 이 필요하다.

언제 switch 가 발생하는지 알아보자.
Process Switch
Process Switch 란 실행하는 프로세스가 바뀌는것이다. 이는 커널모드로mode switch 된 후에 다른 프로세스로 바뀌는것이다.
Interrput
Interrput 가 발생하면 그를 기다리는 block 상태인 프로세스가 있을것이다. 그러면 그 interrput 핸들러에서는 ready state 로 바꾼다. 그를 ready queue 에 반영할것이다. 그런데 그 코드가 우선순위가 높다면, 어떤 스캐줄링 정책에의해서 즉각적으로 현재 수행중인 프로세스를 중단 및 자원을 빼앗고 ready state 인 우선순위가 높은 프로세스를 수행시킬 수 있을 것이다. 이럴때 process switch 가 발생할 수 있다.
- 대표적인 예 : time interrput -> time interrput 로 외부 interrput 로 온것인데, time slice 를 다 사용했다면 현재 수행중인 프로세스를 ready state 로 바꿔주는 상황
Exception
현재 수행중인 프로세스가 어떤 예외를 만나면 해당 프로세스는 exited state 로 바뀐다. 또 다른 프로세스로 전환되는 process switch 가 발생한다.
system call
read, write 와 같은 system call 연산으로 인해 현재 프로세스가 더 이상 진행되지 않는 blocked 상태로 바뀔 수 있다. 즉 현재 프로세스는 더 이상 진행못하니까 다른 프로세스를 running state 로 바꾸는 process switch 가 발생하는 것이다.
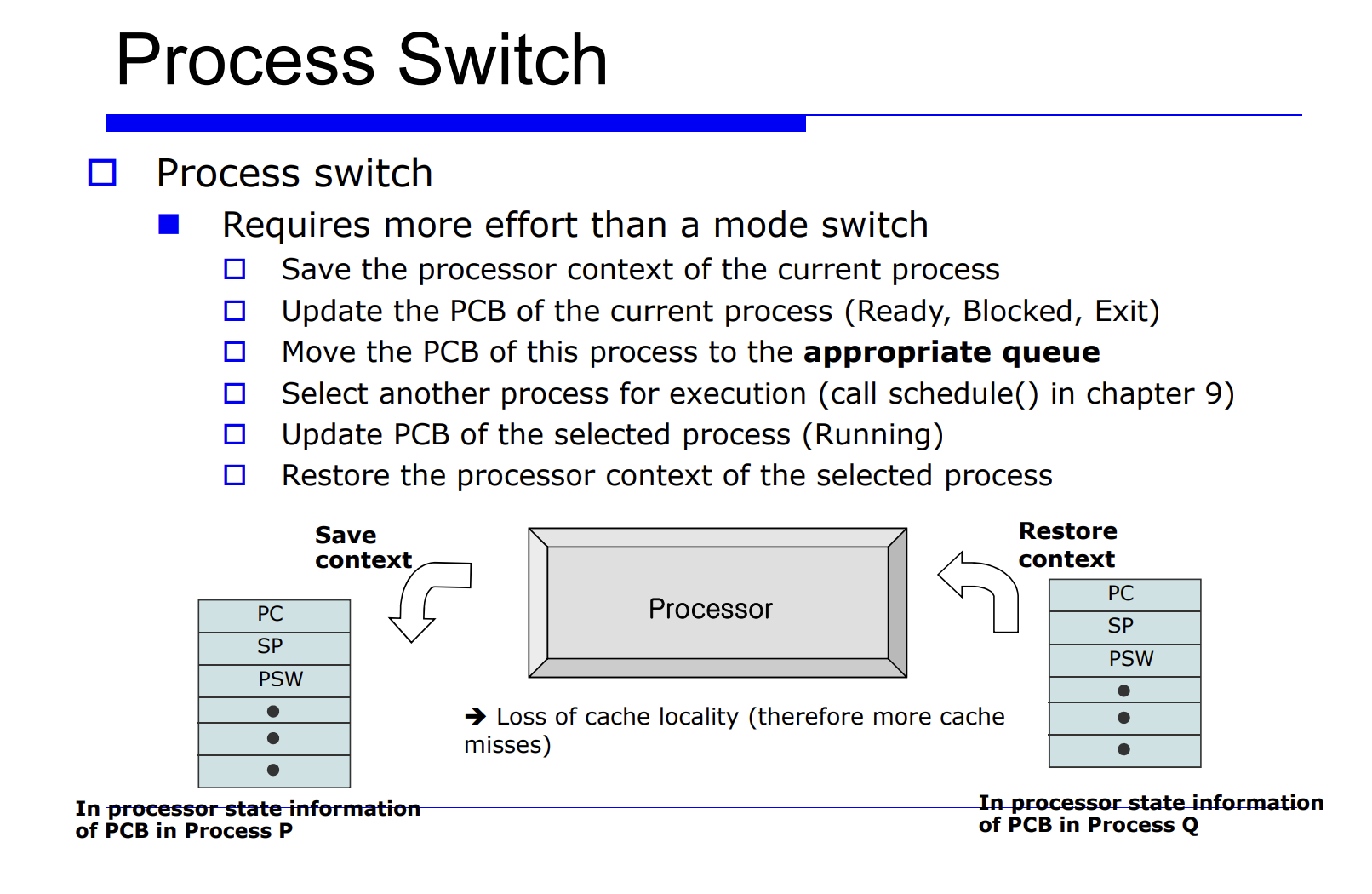
proceess switch 라는 것은 비용이 많이 발생한다(오버해드가 높다).
proceess switch 과정을 나열해보자.
current process 를 다녀온다. 이때 current process 를 running state 일것이다.
- 이게 만약 timer interrput 에 의해 중단된다면 ready state 로 바뀔 확률이 높다.
- 반면 이게 만약 system call 로 I/O Request 를 했다면 blocked state 가 될것이다.
- 또 만약 이게 exception 으로 process switch 를 유발한다면 exited state 로 바뀔 확률이 높다.
스캐줄링은 프로세스가 증가함에 따라서 실행시간이 증가할 수 있다. 즉 스캐줄러는 오버해드를 가질 수있다.
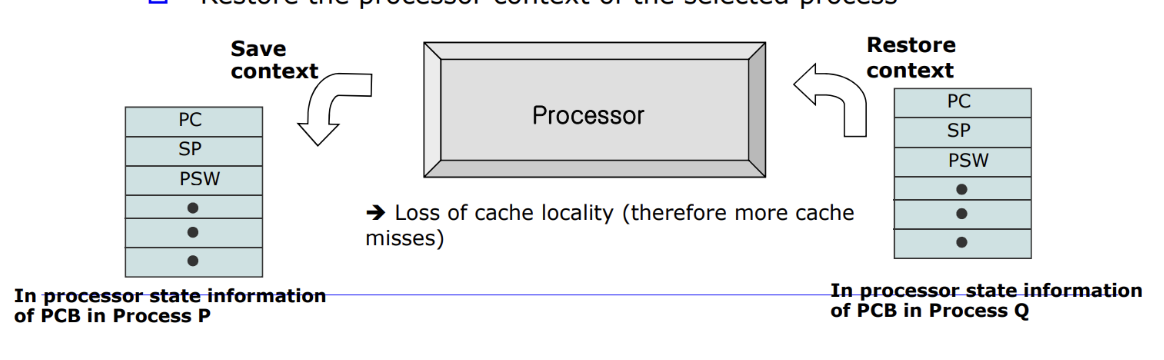
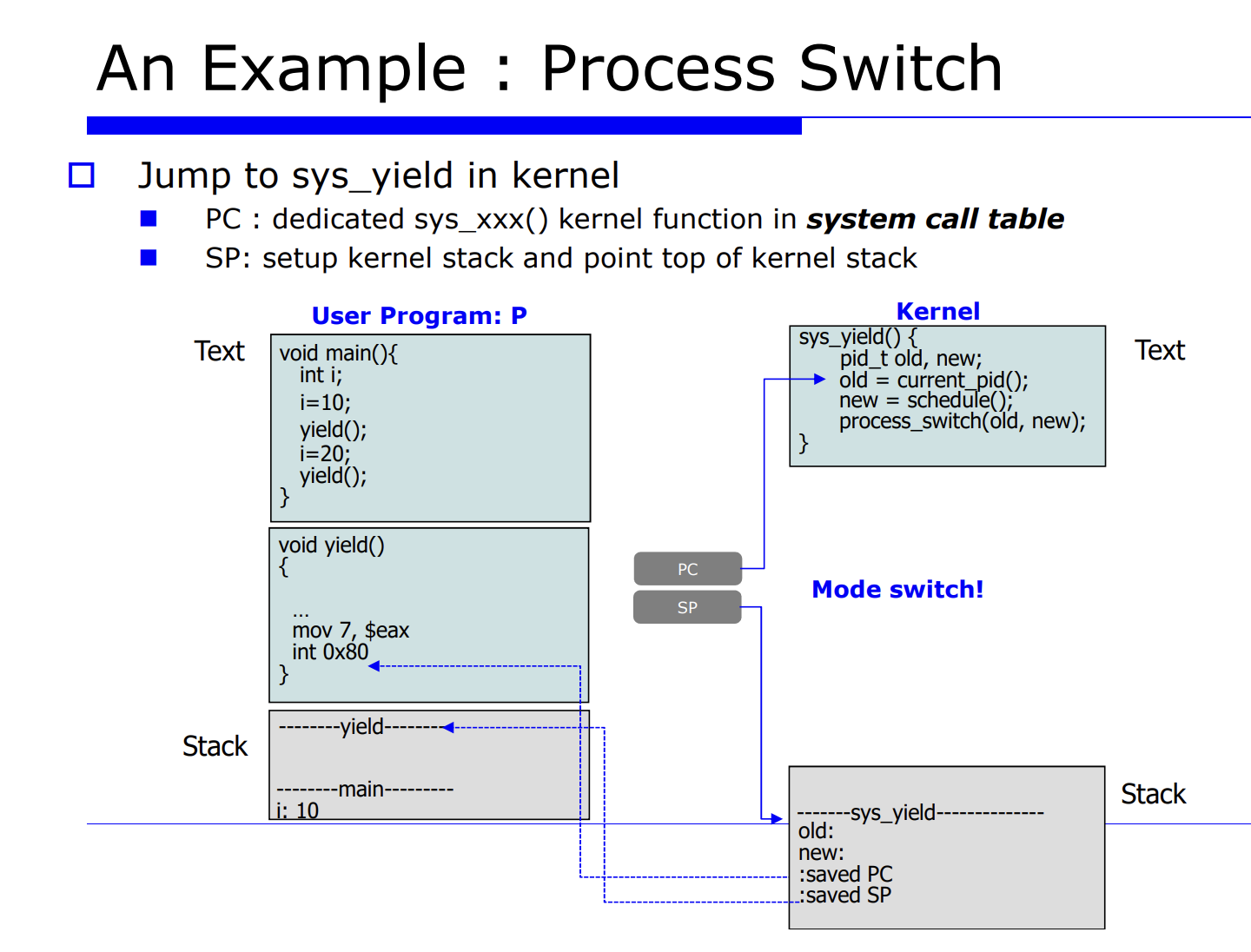
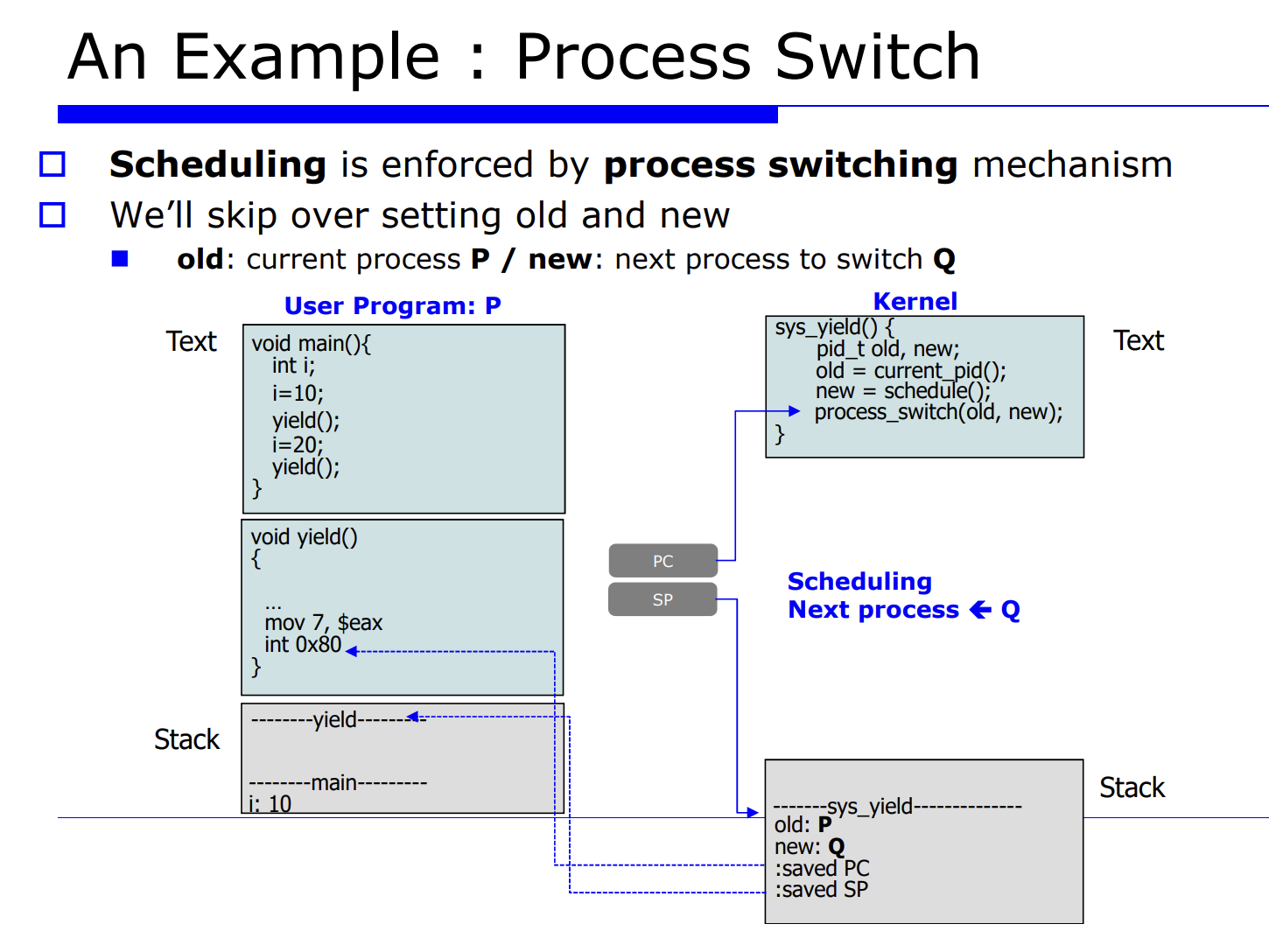
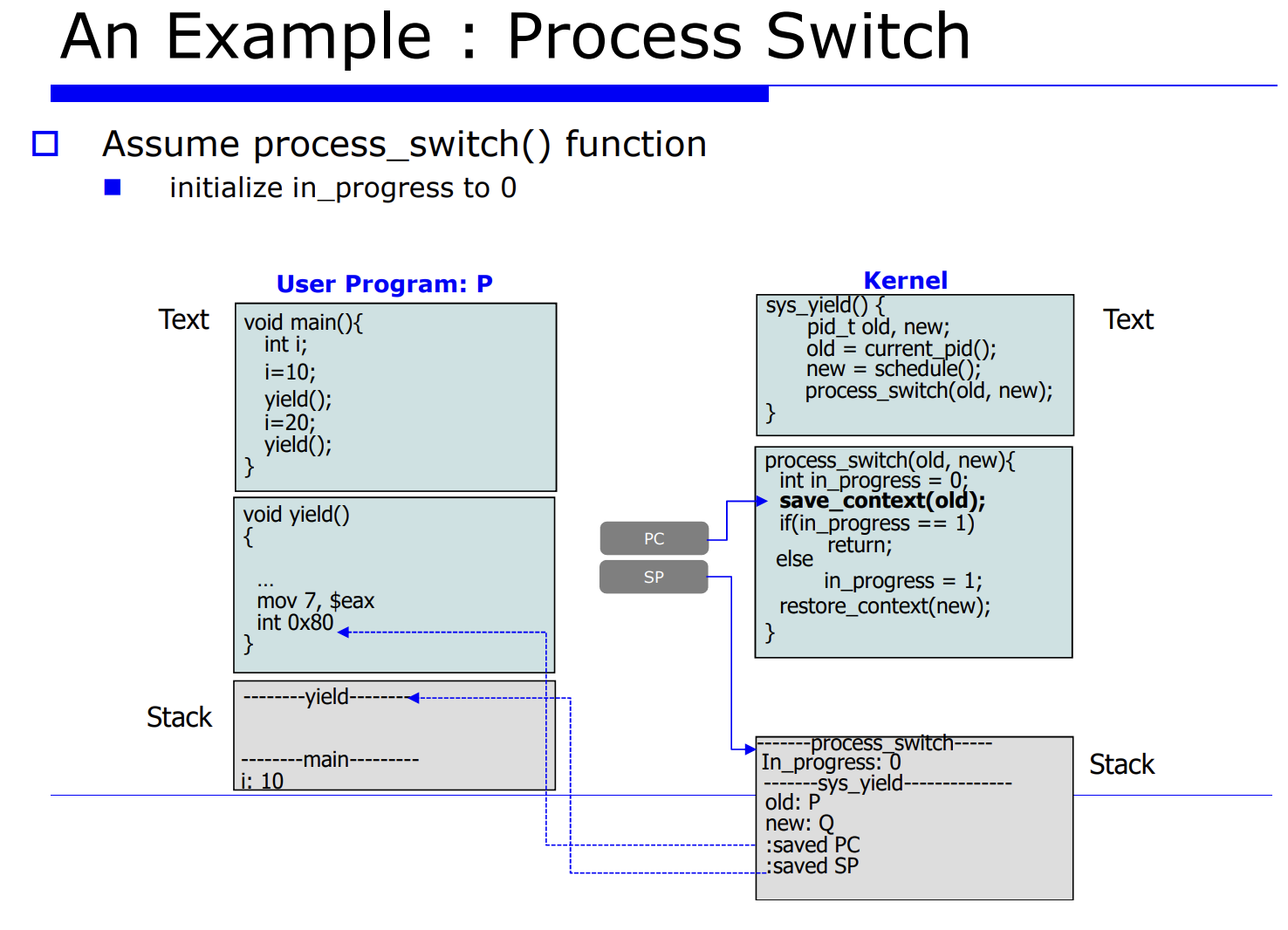
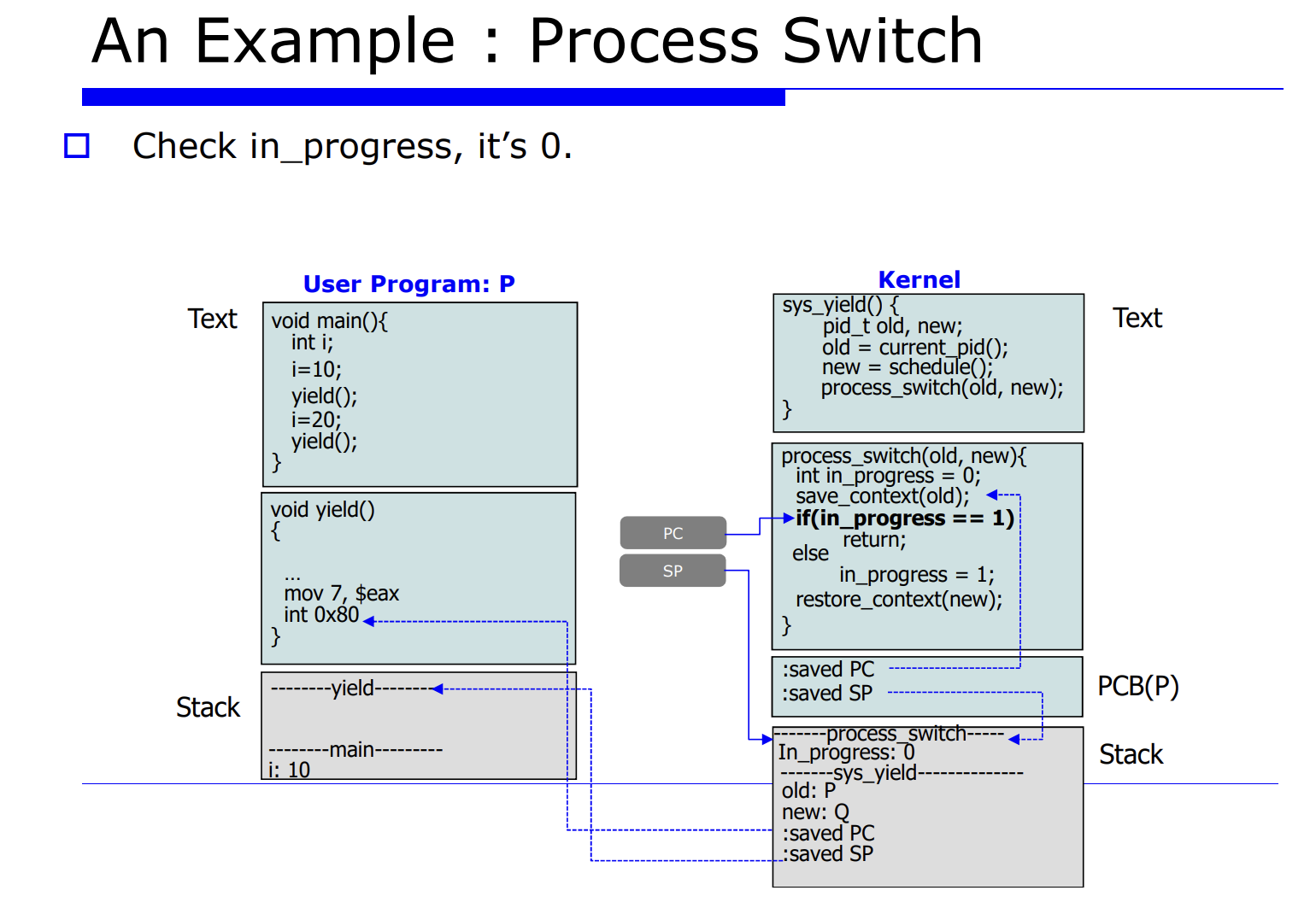
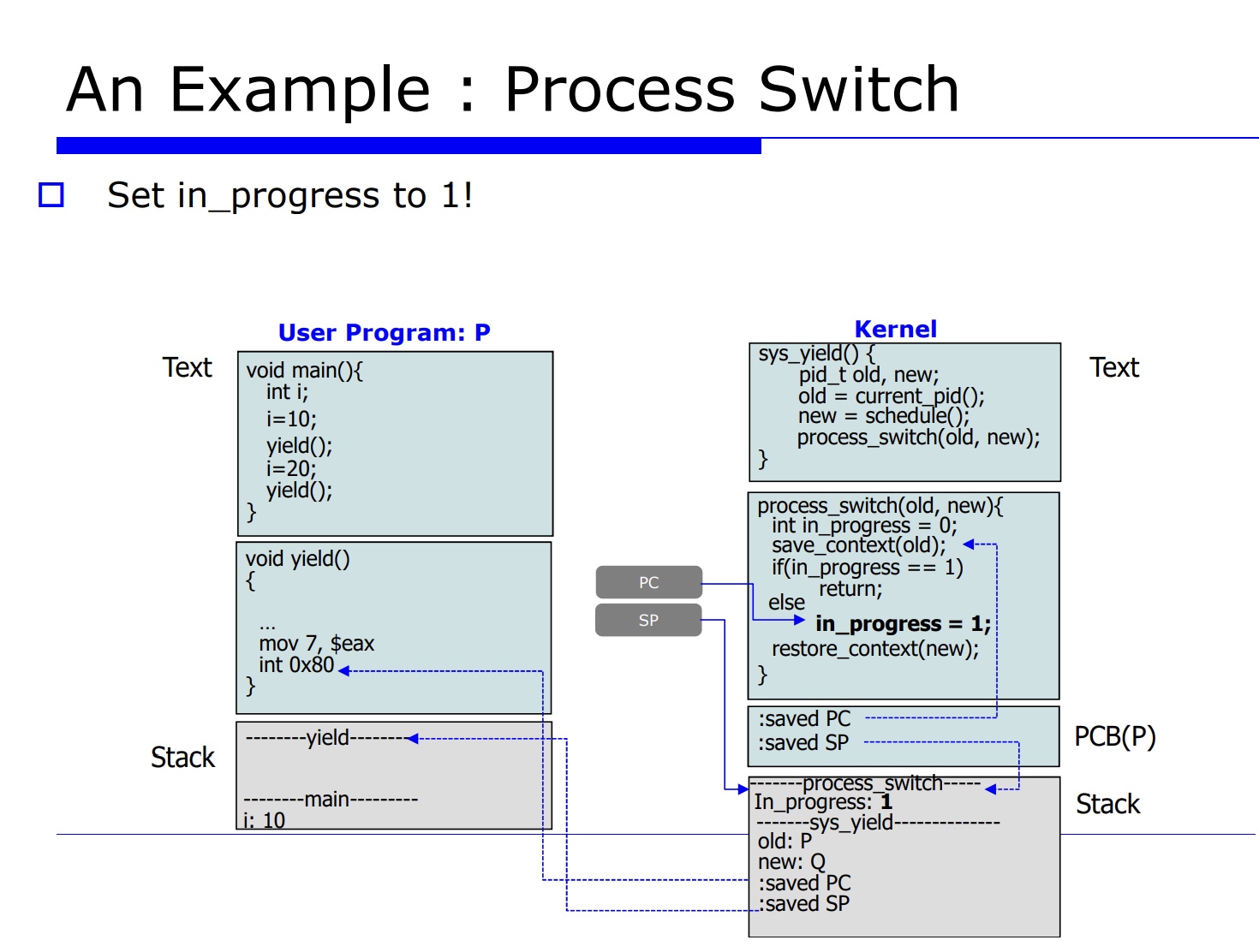
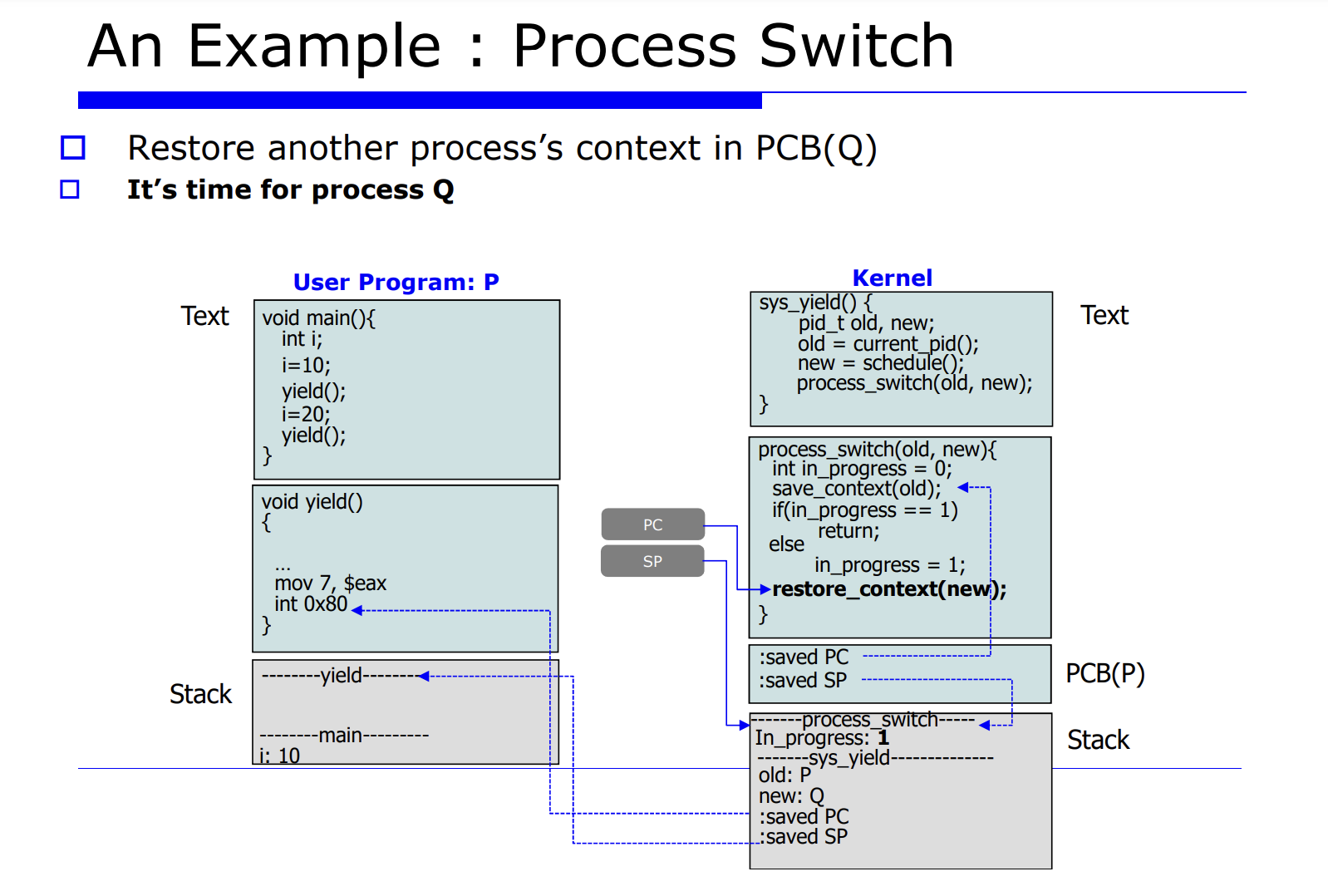
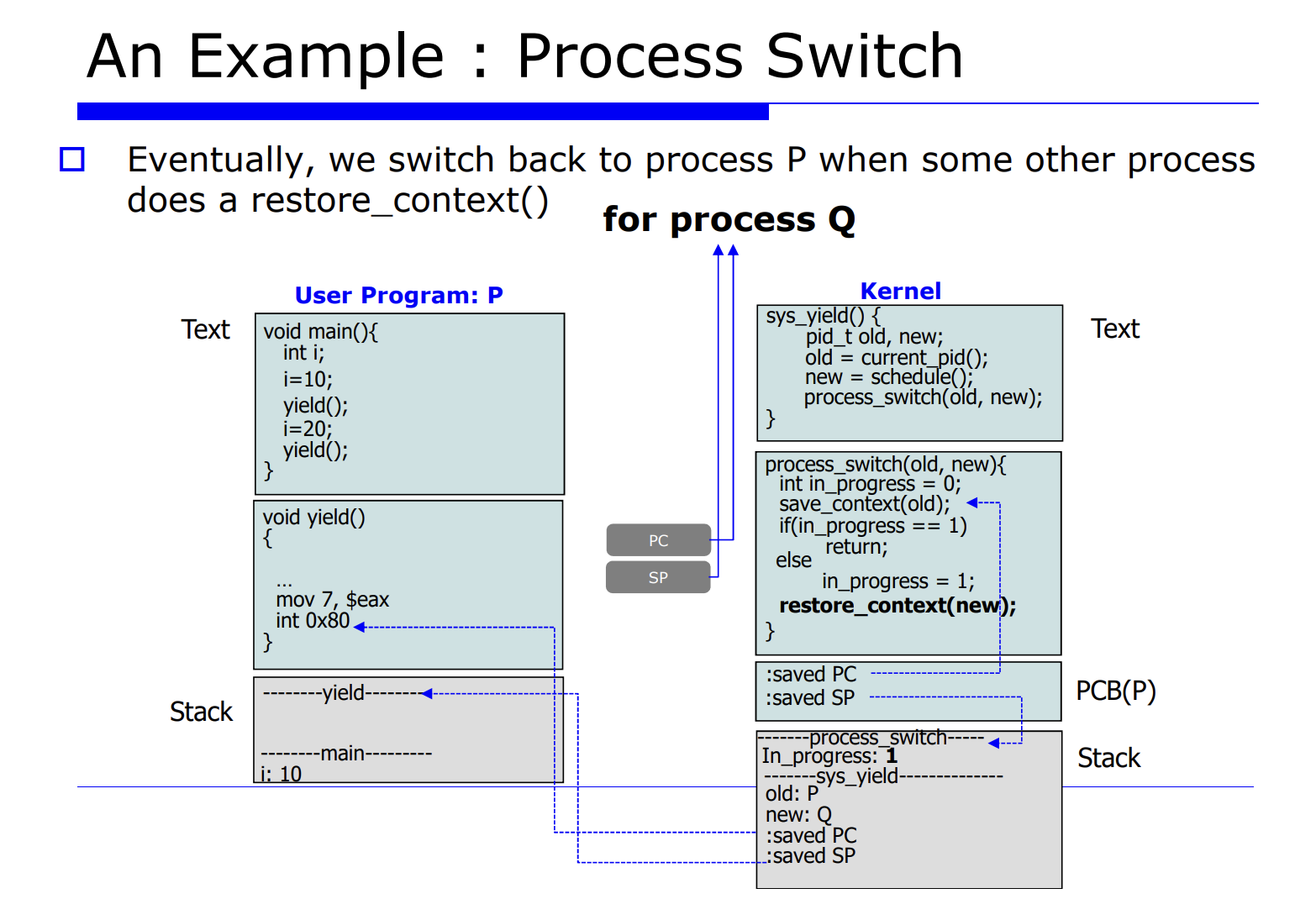
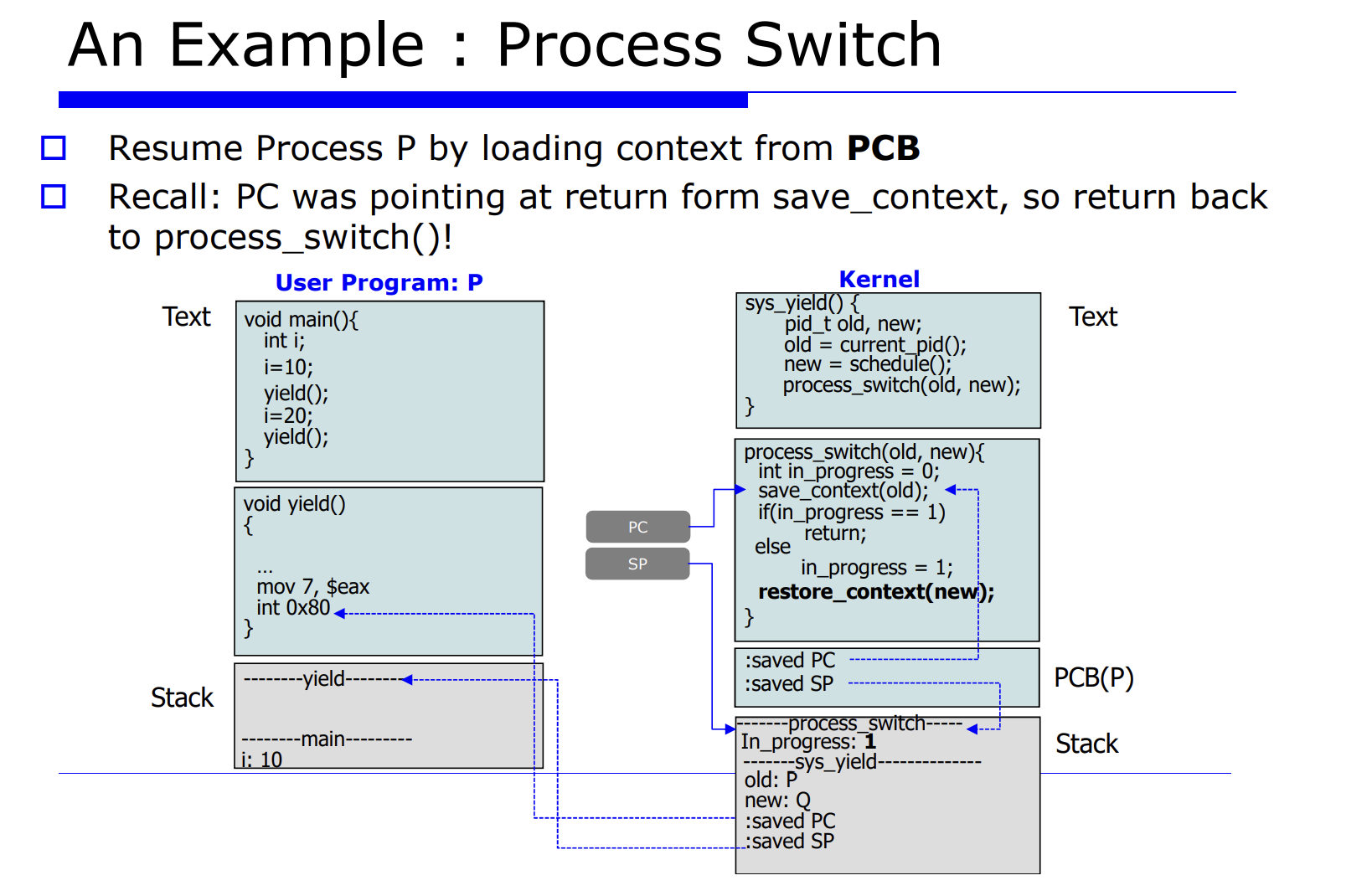
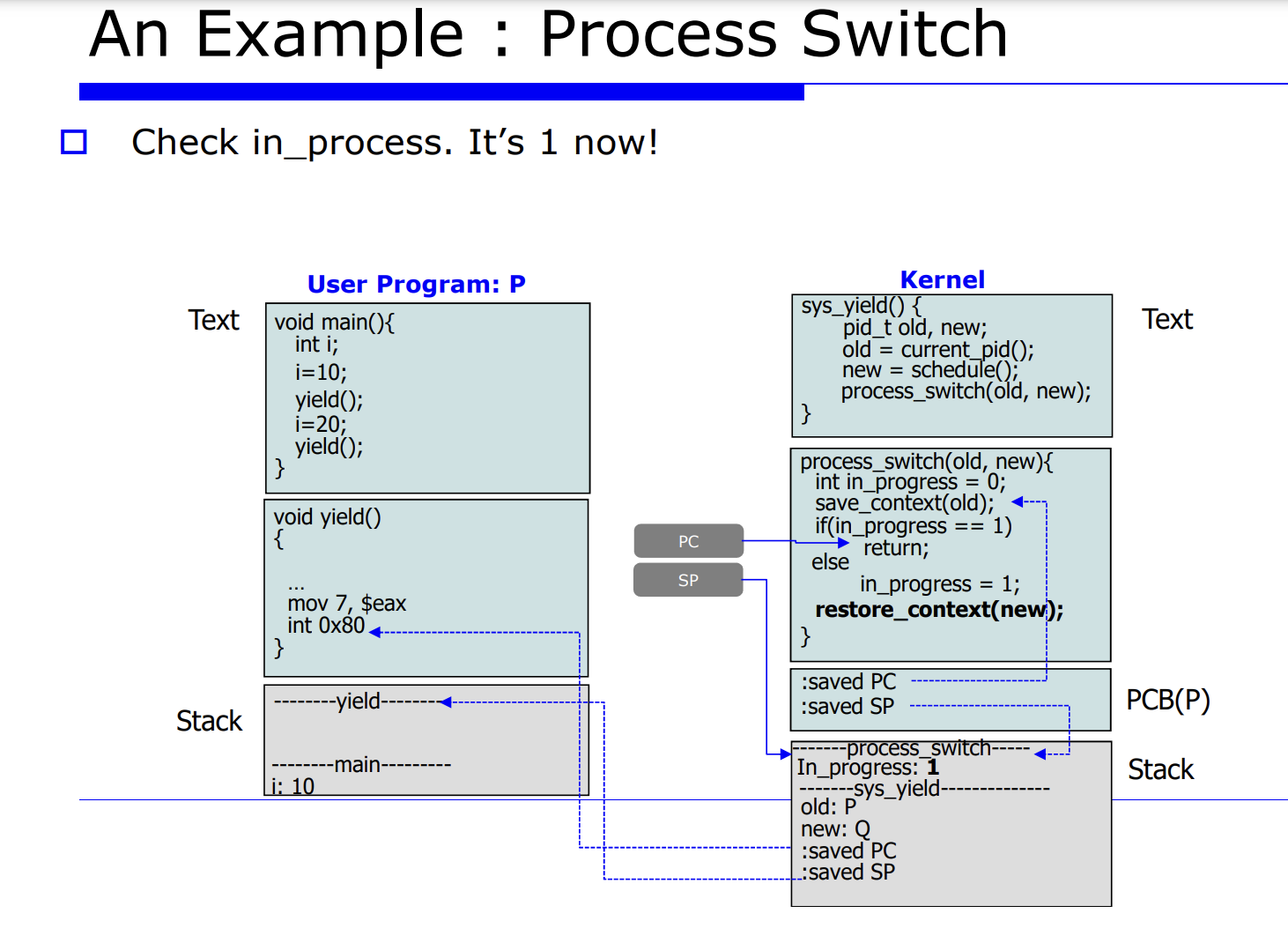
프로세스 Q 에서 P 로 process switch 를 유발시킨다는 것은 레지스터 정보를 업데이트 해주는것이고, 그를 context data 라고한다. 그리고 그를 PCB(process control block) 에 저장한다고 했었다. 그러면 그 놈을 셋팅하기전에 하드웨어에 있는 레지스터 정보를 프로세스 P, Q 에 대한 메모리의 PCB 안에다 save 해야한다. 이 과정을 process switch 라고한다.
자세한 순서를 나열해보면 아래와 같다.

- 2.현재 프로세스들의 PCB 를 업데이트한다.
- 3.적절한 큐에다 PCB 를 insert 한다.
- 4.schedule() 함수가 호출되면서 next process 를 선택한다.
- 5.다음에 수행할 next process 가 선택된다.
- 6.restore 한다.
=> 무엇보다 중요한것은, process switch 가 발생하면 캐시(cache) 에 대한 성능저하가 발생한다. 정확히는 cache 의 공간적 locality 에 대한 손실이 발생한다. 어떤 프로세스가 수행하면서 그 프로세스의 캐시의 공간적인 최적화가 이루어진것이다. 즉, 캐시에는 현재 수행중인 프로세스에 대한 데이터들이 캐시에 최적화가 잘 되어있을텐데, process switch 가 일어나서 다른 프로세스로 바뀐다면 hit rate 가 급격히 떨어지고 성능 저하가 발생할것이다.
스캐줄러는 호출한다는 표현은 곧 스캐줄 함수를 호출한다는 것이다.
이 함수는 Ready state 에 있는 프로세스들 중에서 가장 좋은것 하나를 찾는것이다. (이에대한 자세한 설명은 다음 수업시간에 설명!)
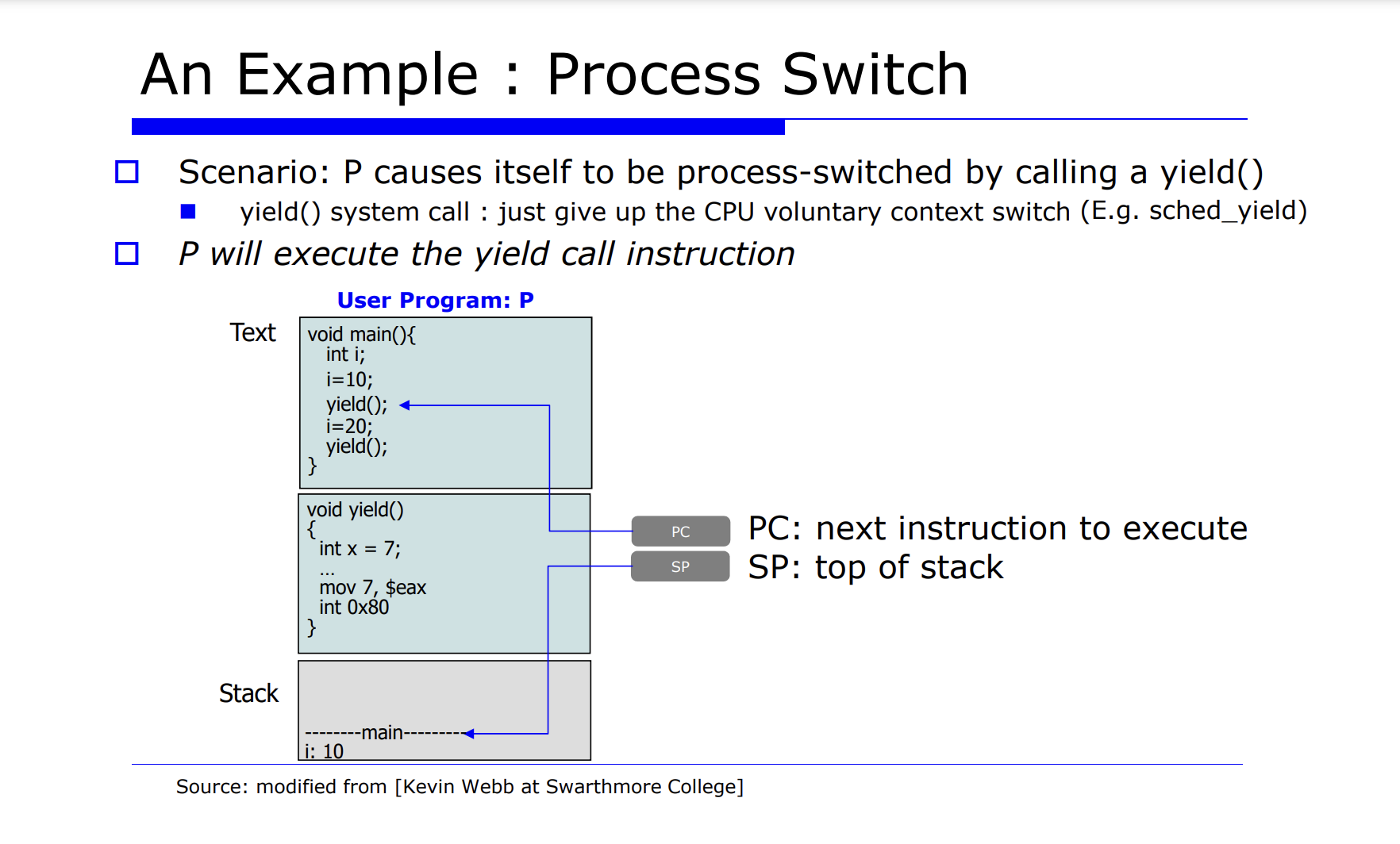
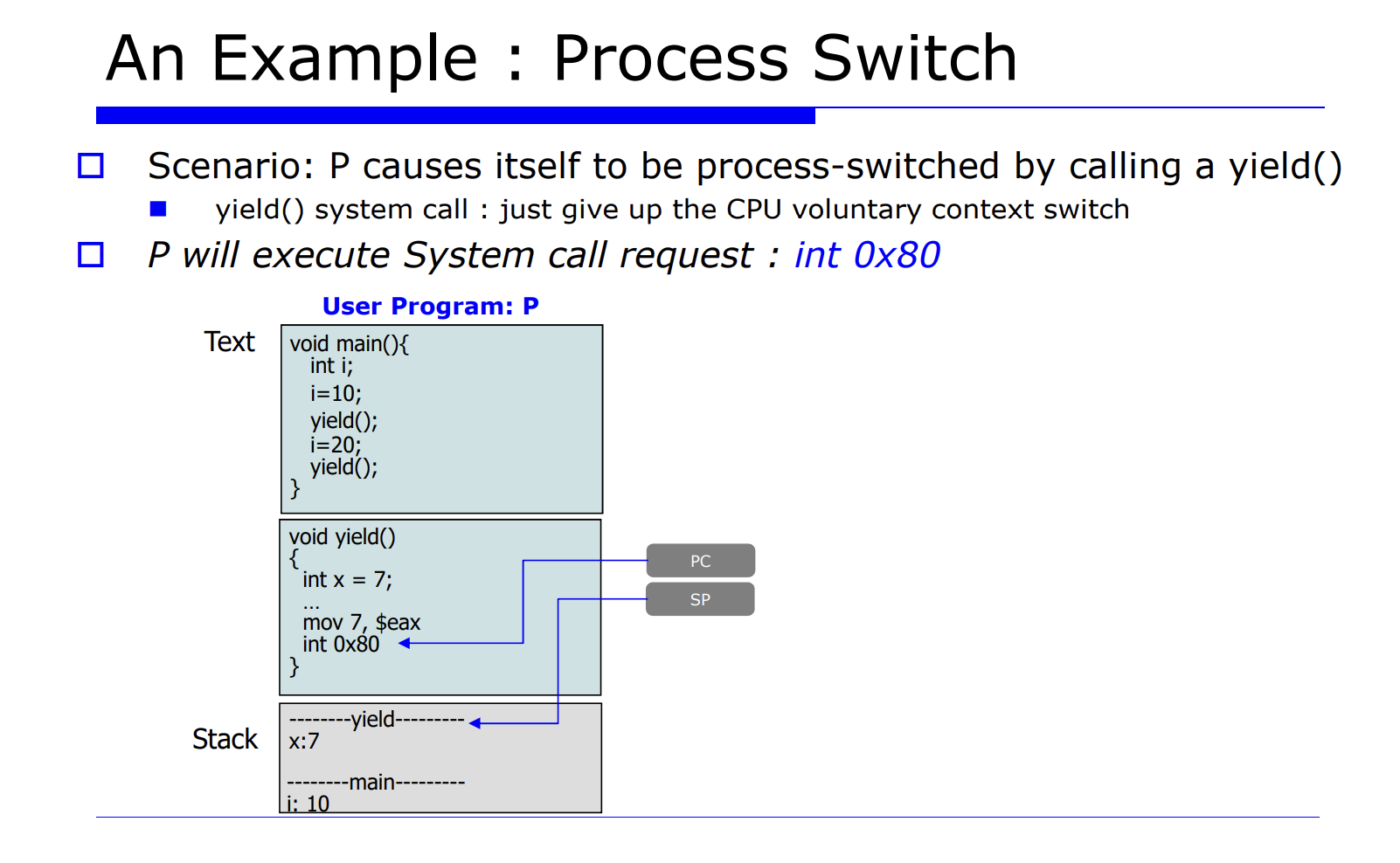
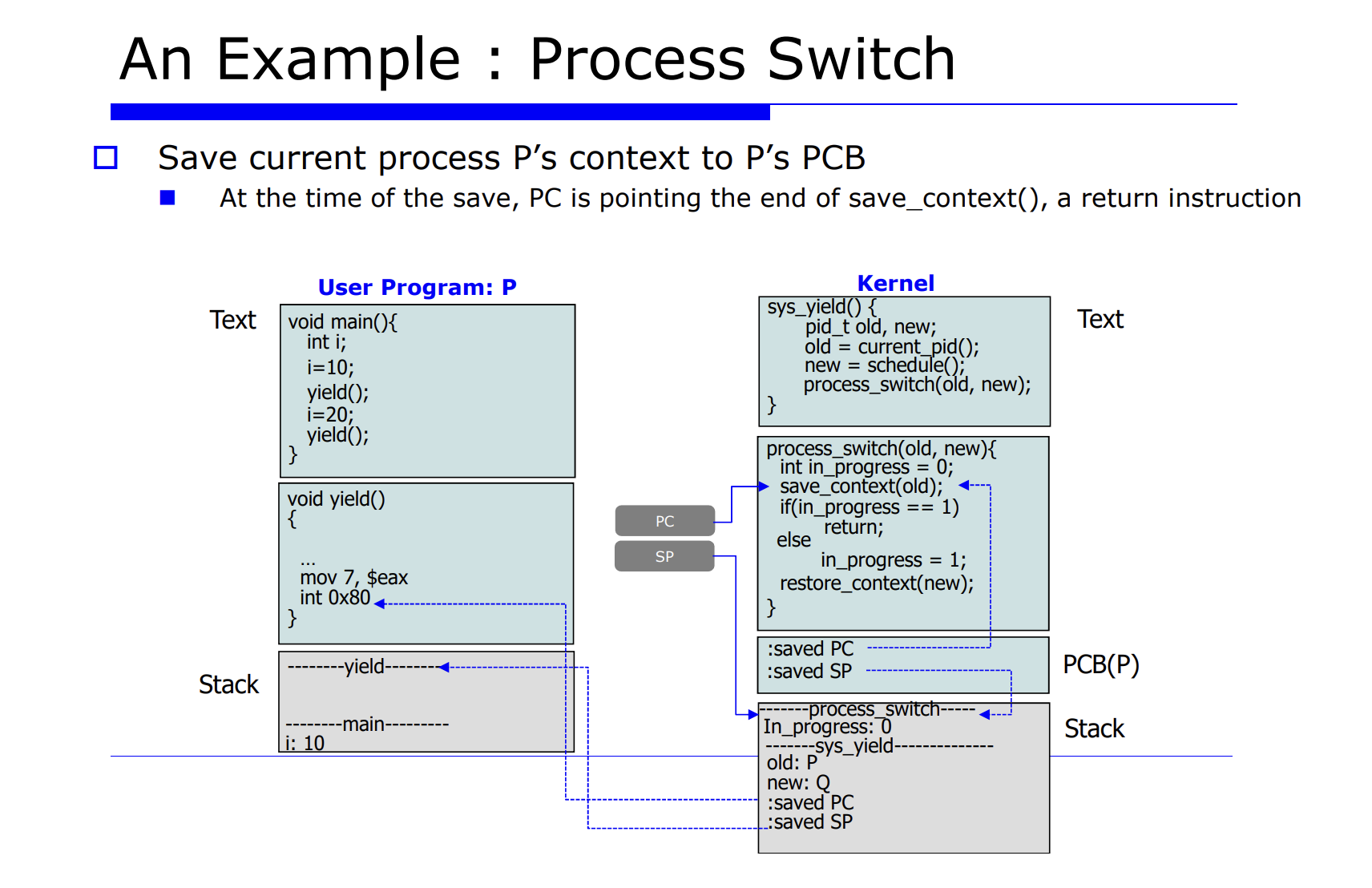
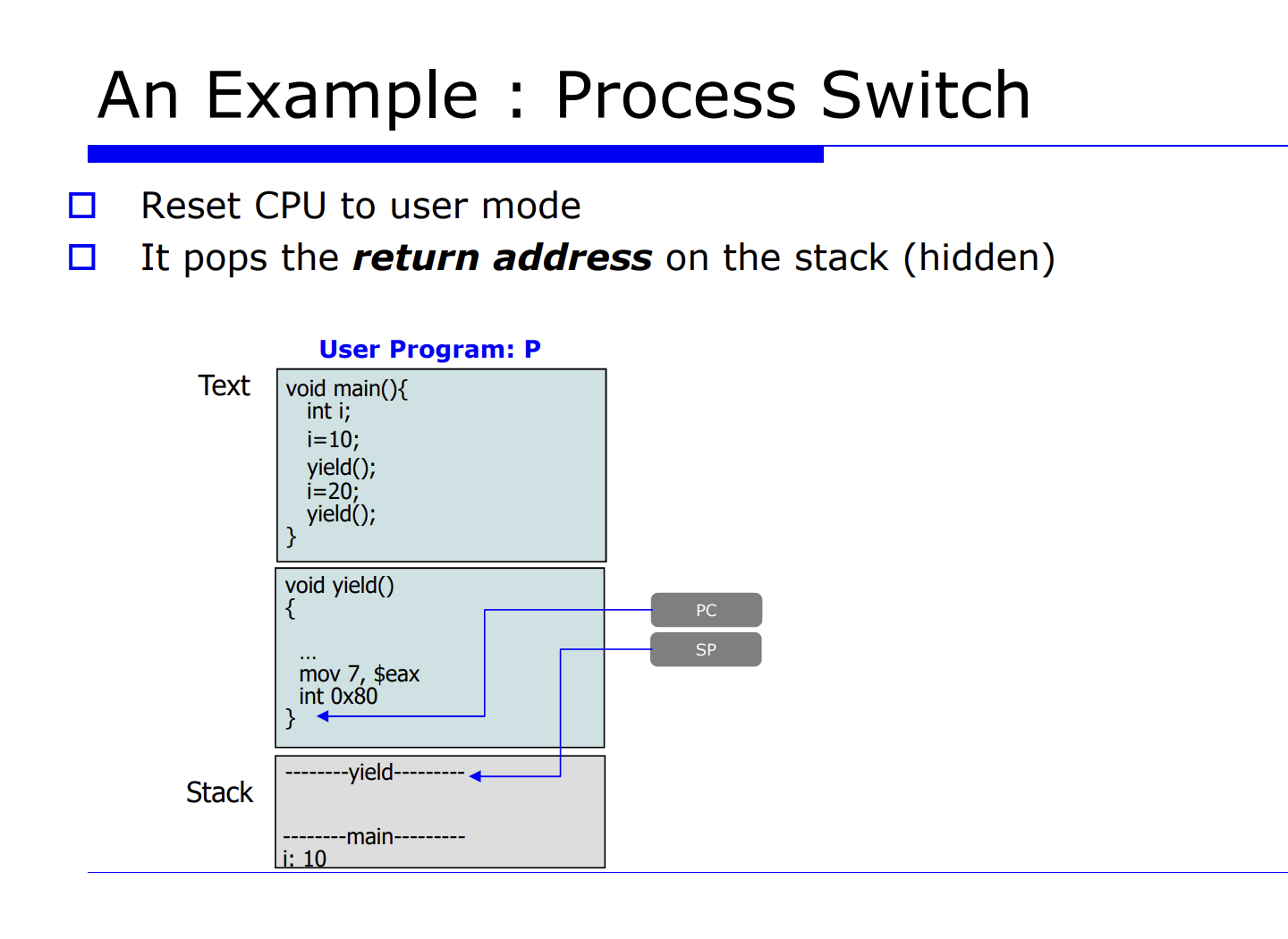
지금까지 배운것을 예시를 살펴보며 정리해보자.
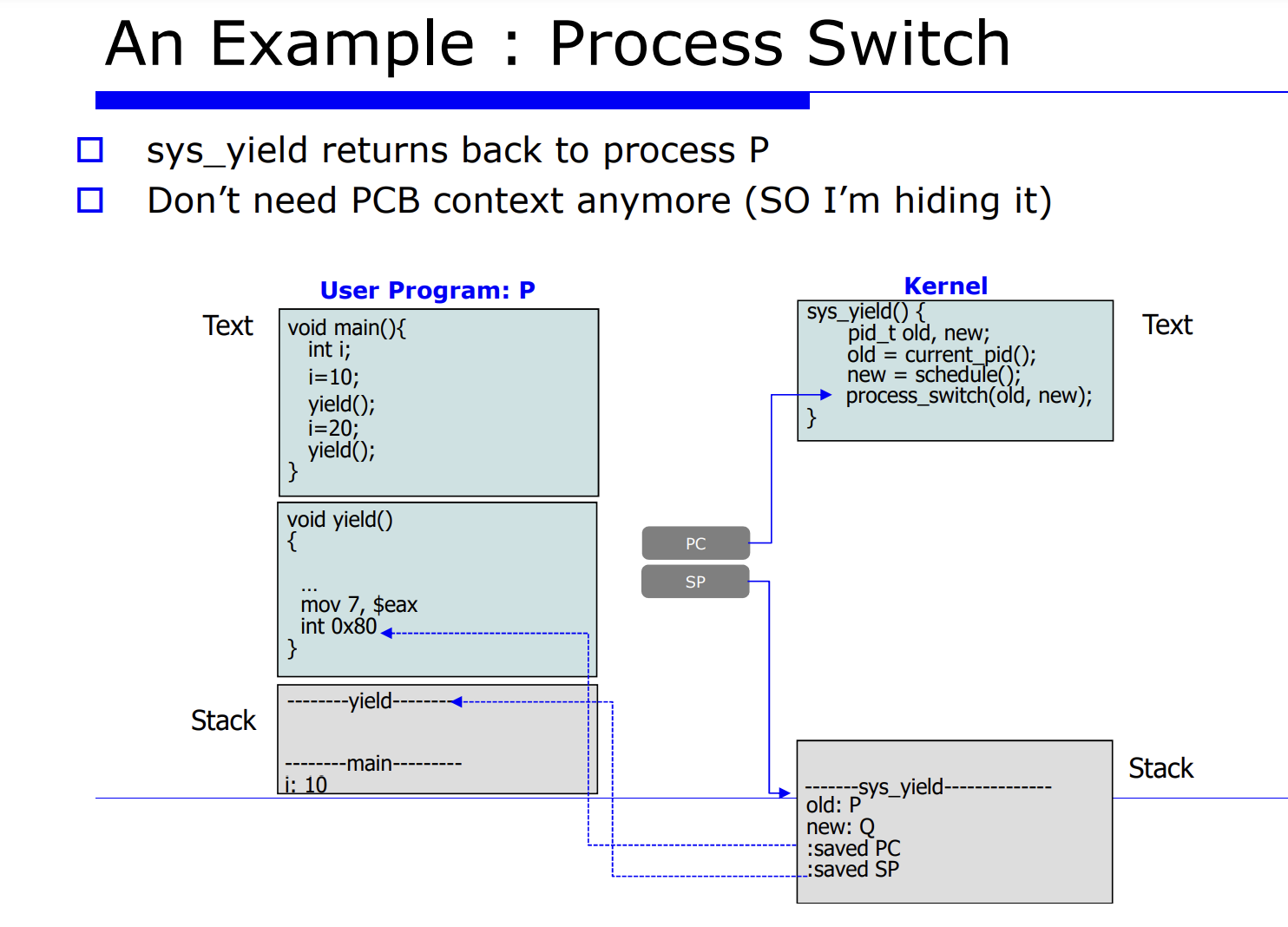
P 라는 유저 프로그램이 어떤 시스템 함수를 call 할것이다. 이때 main 함수안에 yield() 함수는 리눅스 시스템 함수로, process switch 를 유발하는 함수다. 다른 말로 표현하면, 자발적으로 CPU 를 통해 다른 프로세스에게 실행을 양보하는 것이다.
즉, process switch 를 자발적으로 유발하는 system call 함수를 호출한다.
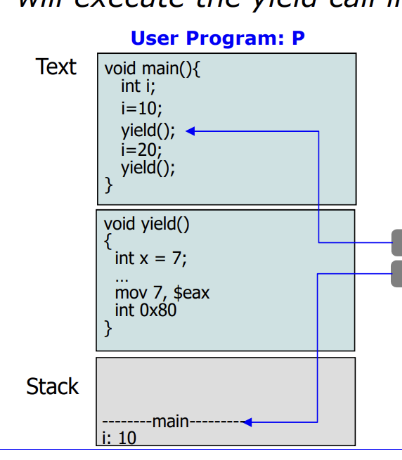
PC 는 다음에 수행할 명령어의 주소가 코드상에 위치해있는 있는것이다.