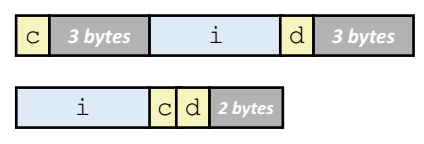
배열
- 스택에 쌓임
- 배열이름 : 포인터 (배열의 주소를 리턴해줌)
=> val + i : int형 배열 시작주소에 i바이트만큼 더한것
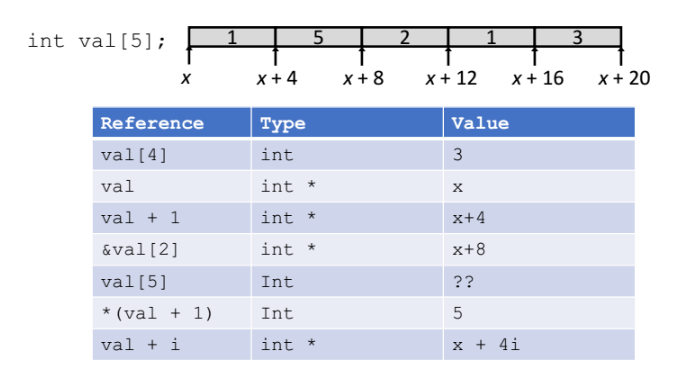
예제
rdi == z (배열의 시작주소)
rsi == digit (배열의 digit 번째 인덱스 번호)
movl(%rdi, %rsi, 4), %eax : 배열의 시작주소인 rdi 에서 digit x 4 바이트만큼 이동해서 (= 배열의 digit번째 원소에 접근해서) 그곳에 있는 값을 eax 에 담아서 리턴
예제
배열의 각 원소에 1을 더하는 함수이다.
현재 rax 가 인덱스 변수 i 역할을 하고있다.
cmpq src1, src2 : src1 에서 src2를 빼고 그 결과값을 기반으로 condition codes 들을 최신화
jbe : 음수가 아니면 실행 => jbe .L4 : 음수가 아니면 .L4 로 점프한다.
addl $1, (%rdi, %rax, 4) : 배열 시작주소(rdi = z) 에서 (4 x rax) 만큼 더한 주소값에 들어있는 값에다 1을 더해준다. 즉 배열 z에서 인덱스 rax 번째 주소에 1을 더한다!

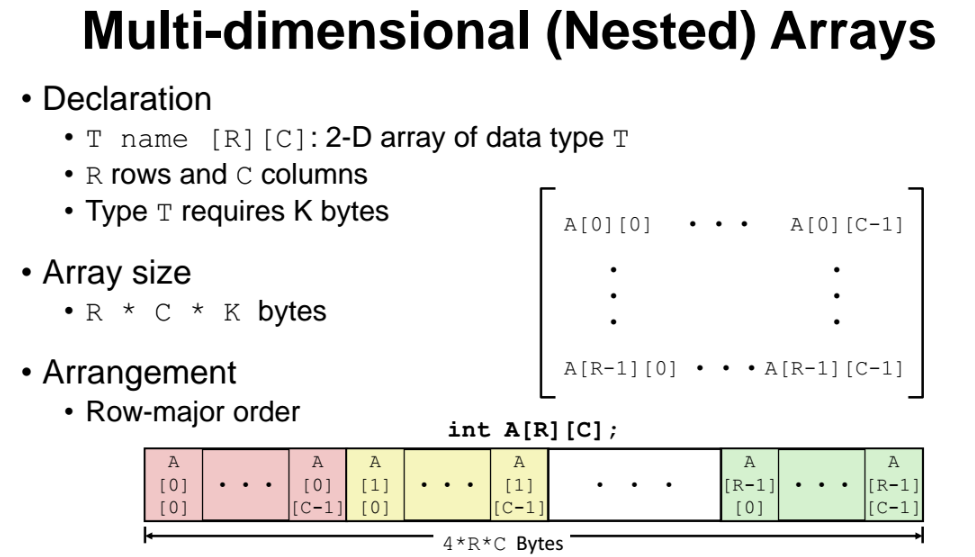
다차원 배열(Multi-dimensional(Nested) Array)
-
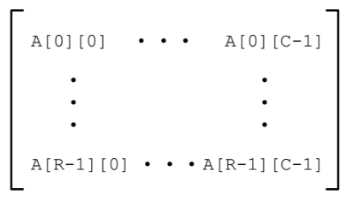
배열의 크기 : row x column x 타입크기(ex. int형 = 4)
-
저장방식 : row-major 구도로 저장
- row-major : 한 row 단위씩 이어서 저장하는것. 한 row 단위를 저장했다면 바로 뒤에 row 단위를 이어서 저장한다.(아래그림처럼 저장)

- column-major : 한 column 단위씩 이어서 저장. (아래그림처럼 저장)
예제
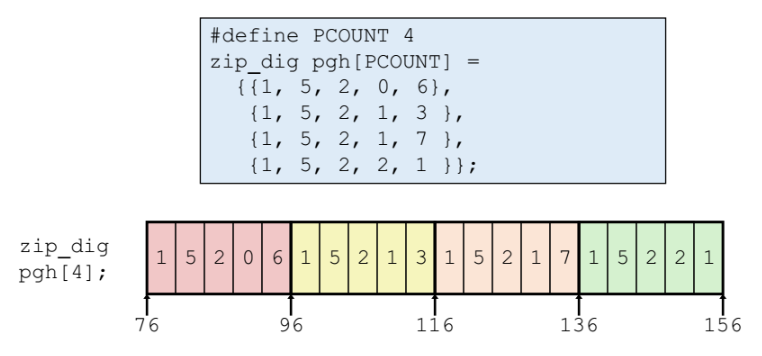
row 가 한줄한줄 들어간다.
다차원배열 접근(access) 방식
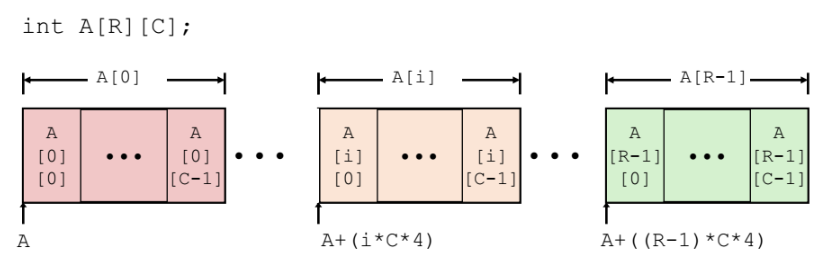
i행 j열의 원소에 접근하고 싶은경우
과정1) row 계산
A + i * ( C * K )
(i : K: 배열타입 크기. int형의 경우 4)배열의 시작주소 A에서 시작해서
C * K 는 row 한줄의 사이즈(크기)이다.
과정2)
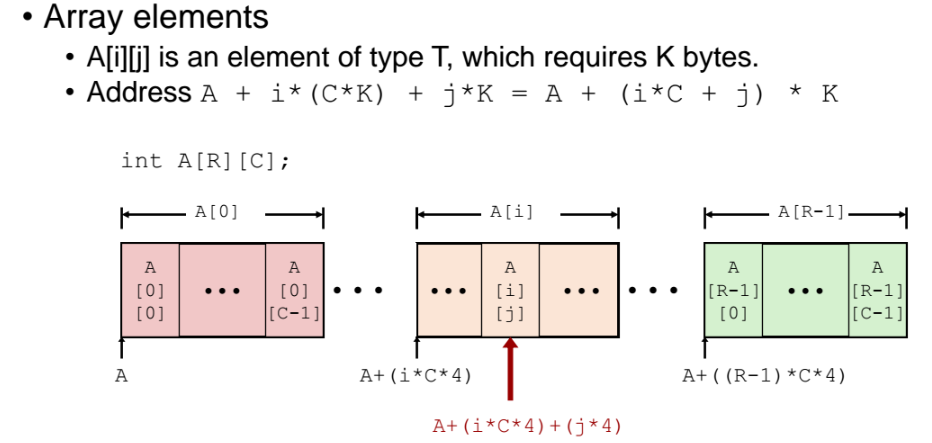
앞서 구해낸 row 값 (= A + i x ( C x K)) 에다 j * K 를 하면 끝이다!
예제 - row 구해내기

rdi == 인덱스 번호
leaqq(%rdi, %rdi, 4), %rax : row 한줄의 크기가 원소 5개로 이루어져있고, 이는 곧 20바이트 크기라는 소리가 된다.
leaq pgh(, %rax, 4) : pgh 배열의 시작주소에서 20 x rdi, 즉 20 x 인덱스번호 만큼 이동하여 그곳에 있는 값을 rax 에 담아서 리턴
예제 - row에 이어서 column 까지 구해내서 접근하기
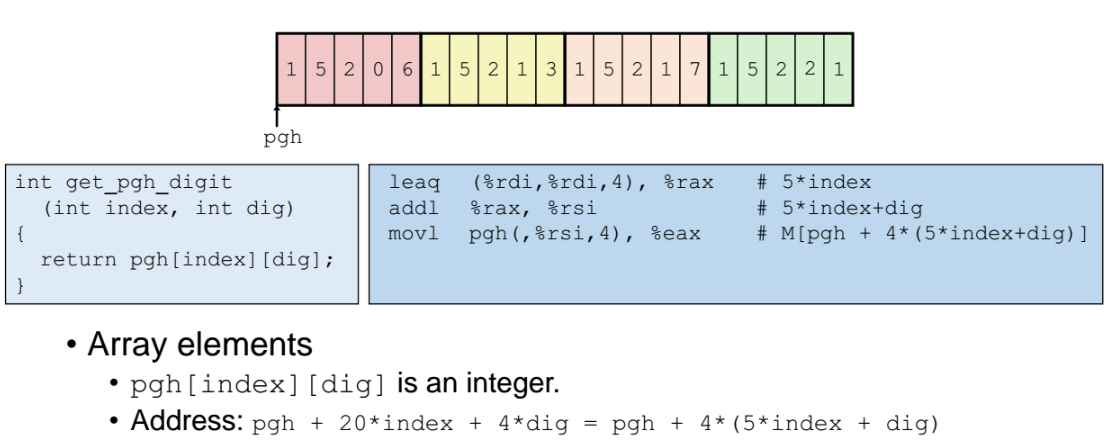
- index == row 값
- dig == column 값
Multi-Level
-
앞서 살펴본 배열은 Nested array 라고 부르지만, 지금 살펴볼 배열의 형태는 Multi-level array 라고 부른다.
-
차이점 : row만 contigeous(이어지는) 형태이고, column 은 끊어진 형태이다.
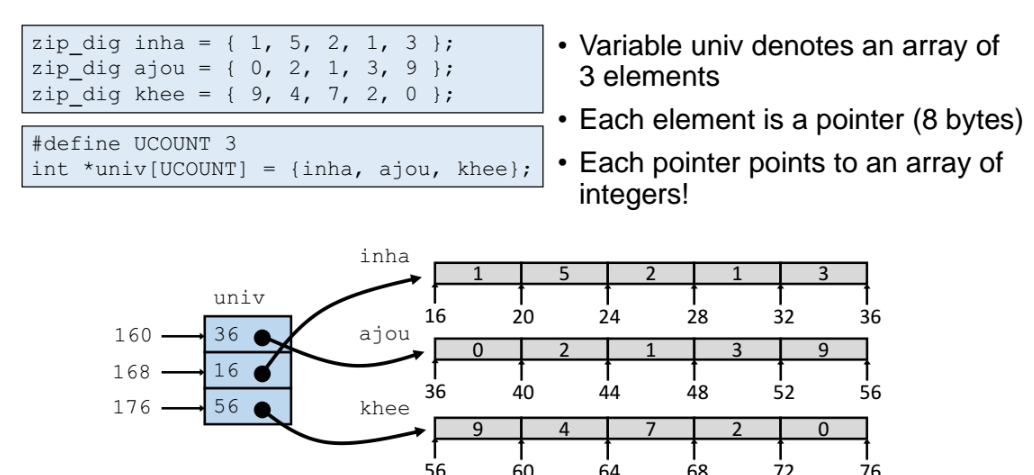
인덱스 access 방식
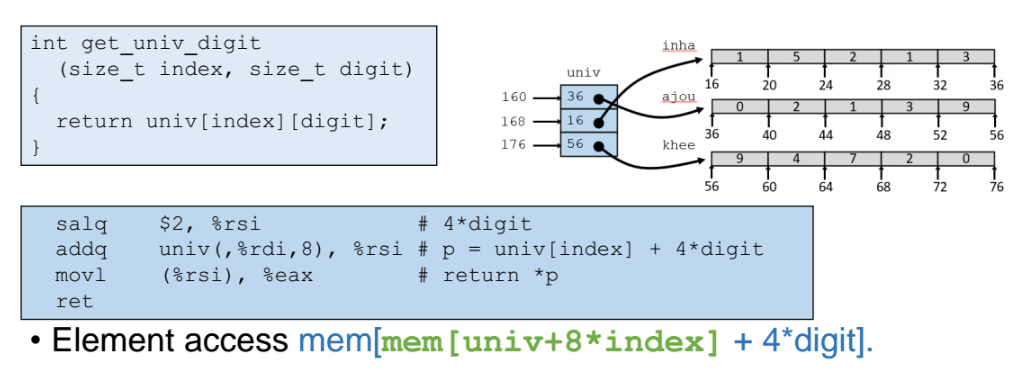
-
rdi : 행 번호
-
rsi : 열 번호 => 열번호에 대해 좌측 쉬프트 연산 2번을 한다. 즉 열번호에 4를 곱해준다.
-
row 찾기 : rdi 에 8을 곱한것을 배열의 시작주소 univ 에 더해준다.
(포인터는 4바이트가 아닌 8바이트이므로 4가 아닌 8을 곱해줌. 8을 사용해서 인덱싱 해야한다. ) -
column 찾기 : 앞서 열번호에 4를 곱한 결과를 방금구한 row 값에다 더해준다.
nested array 와 multi-level array 비교
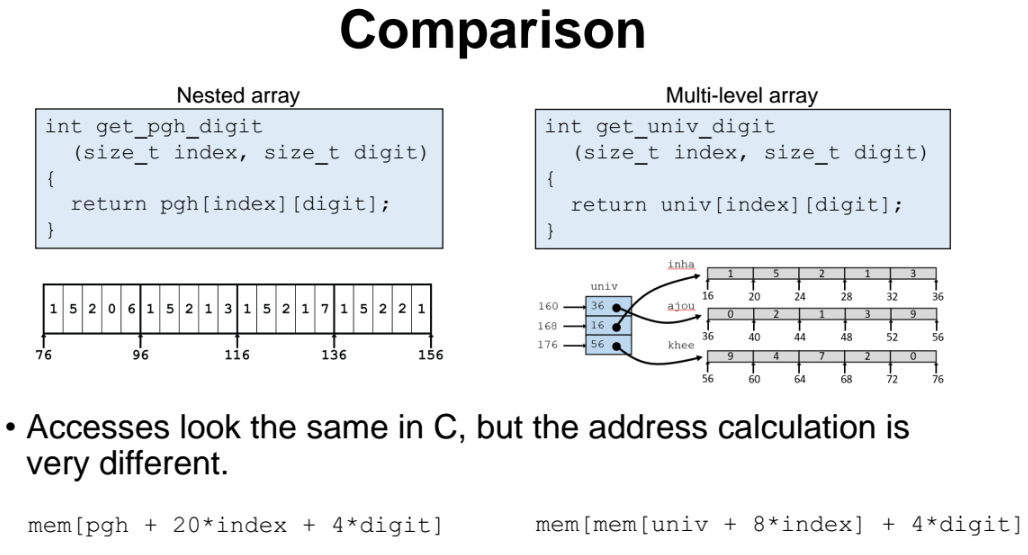
- rdi == index (행 번호)
- rsi == digit (열 번호)
우선 이 방식은 nest array 의 계산방식과 달리, 서로 메모리가 끊어져있어서 계산을 크게 2번에 나눠서 주소를 계산하고 메모리에 접근 해야한다.
=> 첫번쨰로 포인터로 원하는 row 단위에 접근하는 먼저 계산을 하고,
그 다음으로 해당 row 단위에서 어떤 원소에 접근해야하는지(열) 을 계산을 해줘야한다.
N X N 행렬

- 앞서 살펴본 two-dimensional array 인데, 사이즈가 구현 방법에 따라서 고정되어있을수도 있고, 아닐수도 있다.
1) Fixed Dimensions
- N x N 행렬일때 N 값을 그냥 받아와서 access 하면 끝!
2) variable dimensions, explicit
- 앞서 살펴본 multi-level array 로, 끊어져있는 구조.
3
예제

- 6으로 크기가 고정

Structure (Struct 구조체)
- 배열과달리 다양한 타입(int, float, double, ... ) 등을 저장할 수 있다.
- 각 원소가 타입과 사이즈가 다를 수 있다.
- 구조체 안에 변수 및 배열을 선언한 순서대로 메모리에 배치한다.
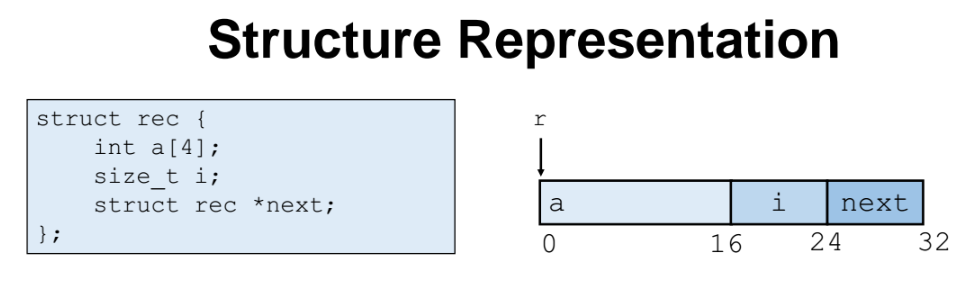
예제
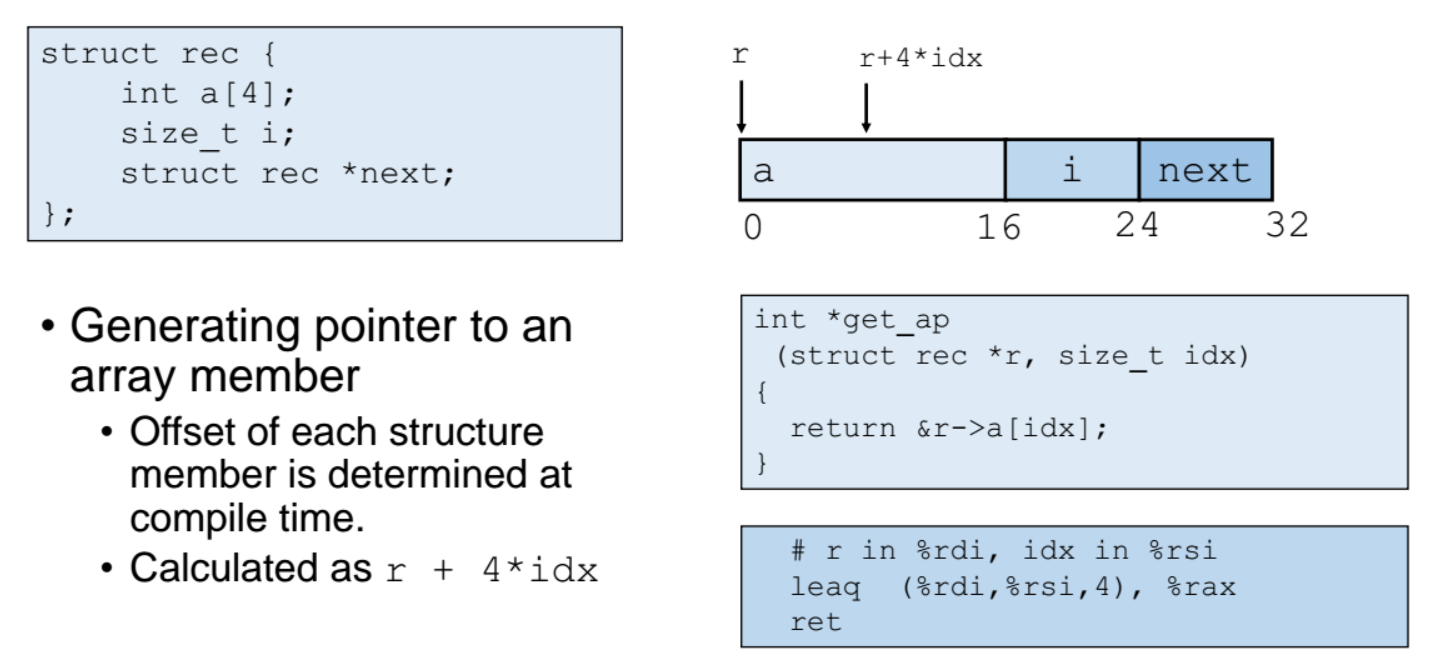
구조체(r) 안에 있는 배열(a) 원소의 특정 인덱스(idx)를 access 하고 싶은 경우
(=> return &r->a[idx]; )
r == rdi, idx == rsi
배열 a의 시작주소(rdi) + 4 x (rsi) == 배열 a의 idx(= rsi) 번째 인덱스의 값을 추출해낸다.
구조체안의 배열원소
-
구조체안에 배열이 들어가있어도, 앞서 배운 배열의 구조와 다르지 않고 동일하다.
-
위 예제에서 배열 a가 가장 먼저 선언되어 있는데, 구조체 rec의 시작주소가 곧 배열 a의 시작주소가 되기도 하다 (시작주소가 같음)
-
어셈블리에서는 구조체의 3개의 원소(a, i, *next) 가 연속적으로 저장되어 있을뿐이고, 같은 구조체로 묶여있는지를 신경쓰지 않는다.
-
access 방법은 그림에서 보듯이 구조체 "시작주소 + 4 x 인덱스번호" 형태로 진행하면 된다.
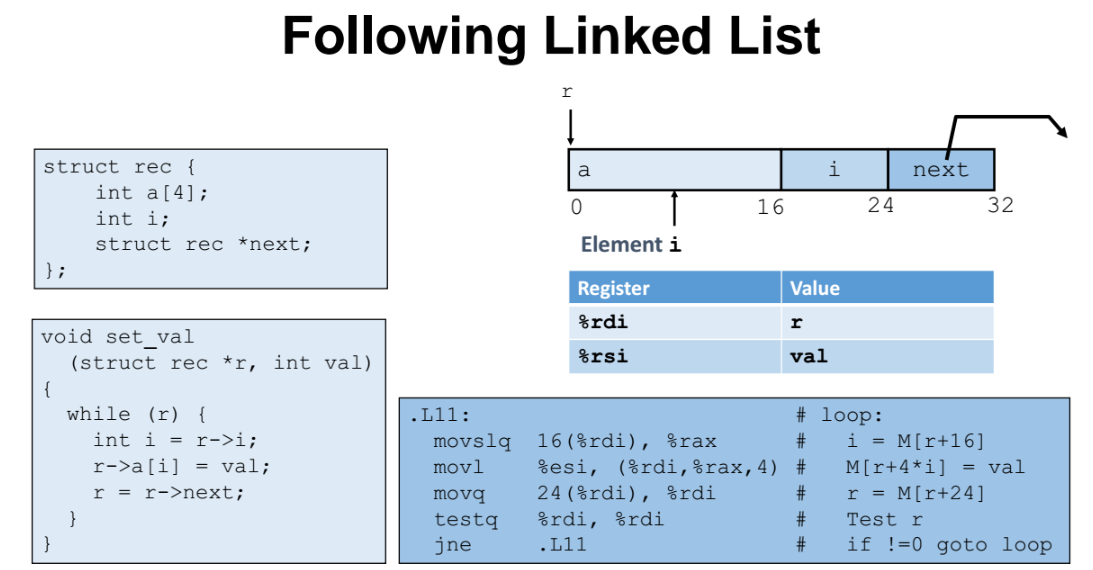
링크드리스트 형태

- 구조체 원소중에 "struct rec *next" 보면 알수있듯이 같은 타입을 가리키는 링크드리스트이다.

-
while 문을 돌면서 "r = r->next" 를 보면 알수있듯이 링크드리스트 구조를 만들어준다.
-
rdi : 구조체 시작주소 (즉, 포인터)
-
rax : 인덱스 값
16(%rdi, %rax) : r 에다 16을 더해주고 rax 에 넣는다. (기존 r 에는 배열의 시작주소가 저장되어 있어서, 배열 시작주소 + 16 바이트 만큼 이동해서 그곳에 있는 값을 추출해내서 rax 에 넣는것이다 )
movl %esi, (%rdi, %rax, 4) : 4 x 인덱스값 + 구조체 시작주소 rdi에 더해준 해당 주소값 공간에 rsi (esi) 의 값을 넣어준다.
movq 24(%rdi), %rdi : 기존에 rdi 포인터가 가리키고 있던 주소에서 24 바이트만큼을 이동시켜서 가리키게 한다. 24 만큼을 더하면 메모리상에서 다음 구조체의 시작주소를 가리키게 되는 것이다.
=> 이렇게 링크드리스트 구조를 구현할 수 있다!
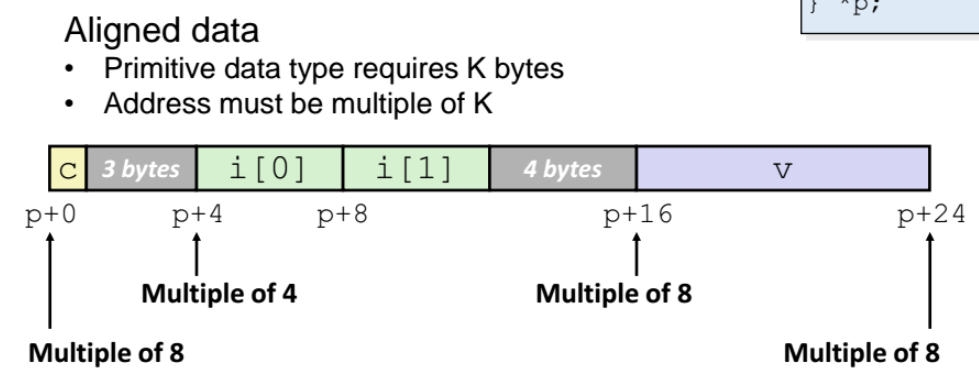
structure & Alignment
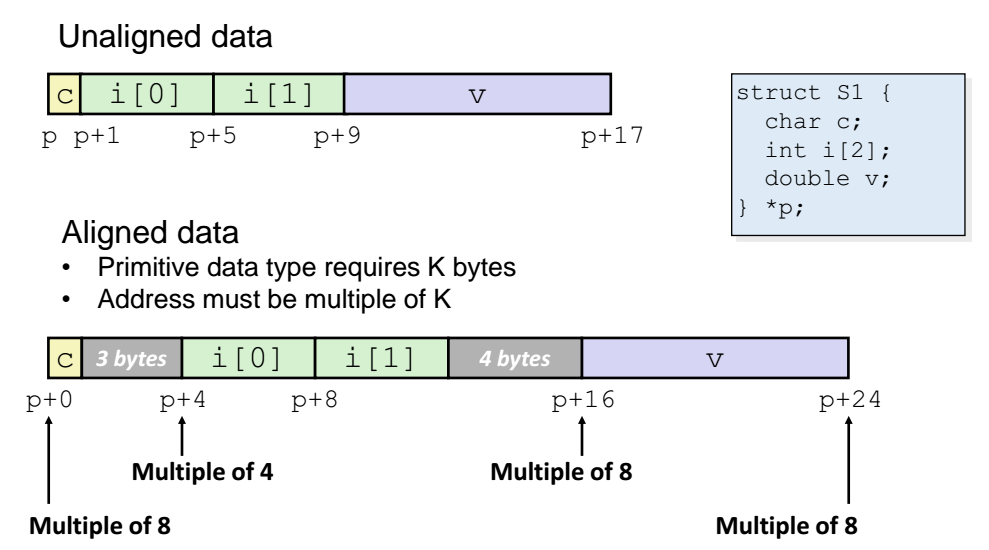
- 위 구조체는 1 + 8 + 8 = 17바이트를 사용하는데, 컴파일러가 17바이트라는 게 2의 보수(2,4,8,16,32,...) 가 아니라서 마음에 안든다고 아래처럼 바꿔버린다.
-
컴파일러는 컴파일 단계에서 구조체를 저장할 떄 사이즈를 확인한다.
-
시작주소를 자기 사이즈의 배수가 되도록 바꾼다.
-
int 타입이므로 컴파일러가 기본적으로 4의 배수인 주소에다가 원소를 저장하고 싶어한다. 기존에 p + 1 인 주소를 4의 배수가 되도록 p + 4 에다가 옮겨버린다.
-
그렇게 int 형 원소를 2개 넣고나면 (p + 4) + ( 4 x 2) = p + 12 가 되는데, double 형은 8바이트 이다. 12는 8의 배수가 아니므로 컴파일러가 또 불편러라서... p + 12 에서 4 를 더한 p + 16 에 해당 double 타입 원소를 밀어넣는다.
-
이렇게 컴파일러가 불편러라서 원소들을 계속 밀어내는 방식을 패딩(padding) 이라고 한다.
- 이렇게 되면 중간중간에 빈공간이 생기게 될 것이다.
컴파일러는 구조체의 원소들들을 메모리에 할당시에 그대로 할당 순서 그대로 메모리에 할당하지, 순서를 바꾸지 않는다고 했었다. 메모리 공간이 낭비되더라도 그냥 원소를 밀어내면서 원소들을 본인의 배수가 맞춰서 할당하는 방식은 structure alignment (구조체 조정) 라고 한다.
structure alignment 원리
- 하드웨어 특성상 메모리에 access 할때 4바이트 단위 또는 8바이트 단위로 access 하기 때문에 이러한 단위를 맞춰서 원소를 할당하지 않으면 나중에 access 할때 복잡하고 접근이 어려워진다! 이 때문에 컴파일러가 이따구로 원소 할당하는거임
1바이트 : char
2바이트 : short
4바이트 : int, float
8바이트 : double, long, char *, ...
16바이트 : long double
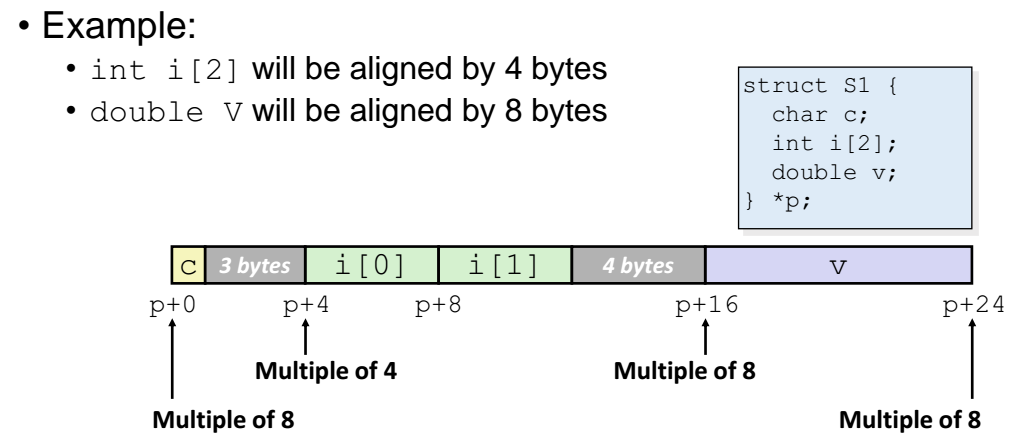
예제
-
int 가 4바이트이므로 시작주소가 4의 배수인곳에 할당
-
double 은 8바이트이므로 시작주소가 8의 배수인곳에 할당
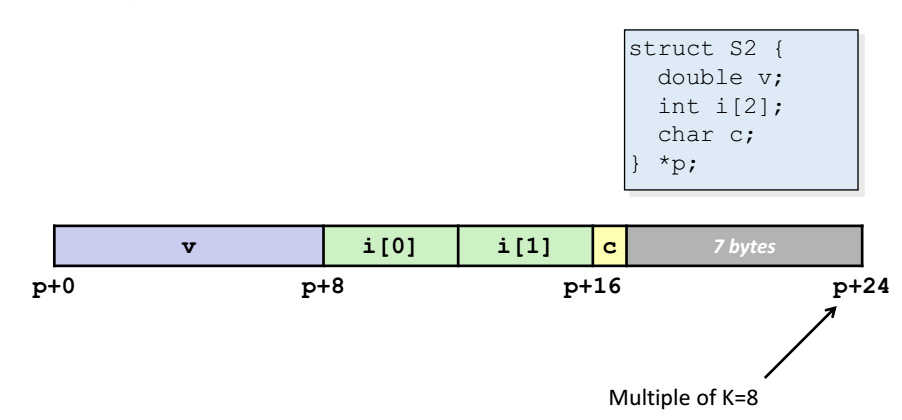
- 앞서 시작주소는 각자의 본인의 타입의 배수가 되어야한다고 했었다.
- 이거 말고도 끝주소에 대해서도 처리할게 있다.
끝 주소는 구조체의 원소들을 중에 타입이 가장 큰 타입의 배수가 되어야한다.
끝 주소는 구조체의 원소들을 중에 타입이 가장 큰 타입의 배수가 되어야한다.
=> 위 예제에서는 8바이트가 가장 크다. 이떄 모든 원소를 메모리에 다 할당하면
p + 17 이 되는데, 17은 8의 배수가 아니다. 따라서 p + 17 이 아닌 p + 24 가 끝주소가 되도록 설정한다.
( p + 17 부터 p + 24 사이의 숫자는 빈 상태로 둔다! )
예제
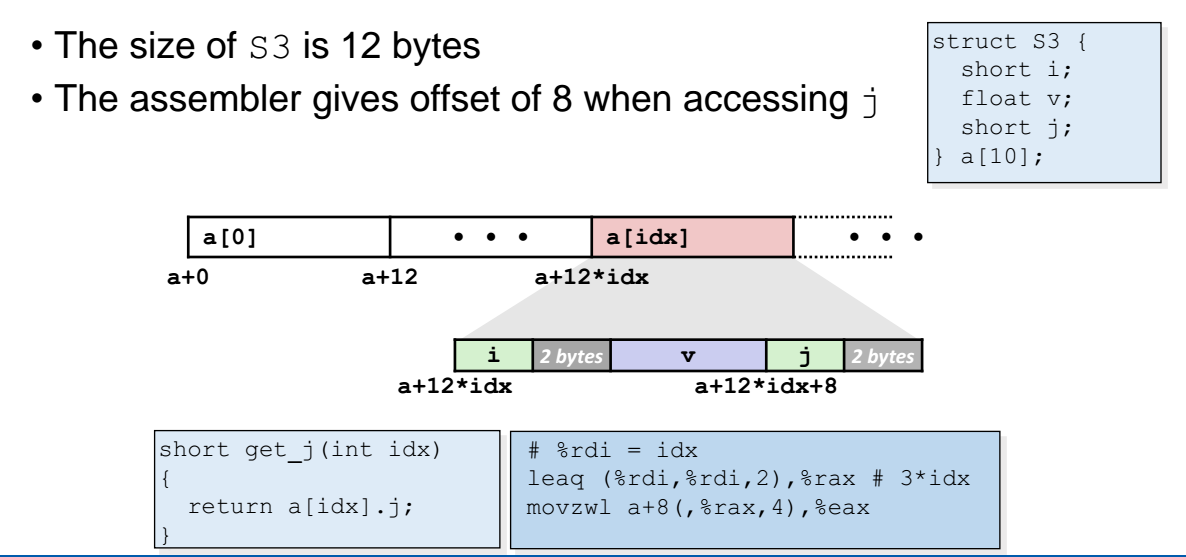
- padding 이 있을떄는 곱셈에 유의하자!
구조체 s3 의 사이즈는 8바이트가 아닌, 12바이트가 나온다!
padding 으로 낭비되는 공간 절약하는 방법
- 가장 큰 타입의 데이터를 구조체에서 가장 먼저 선언하자!
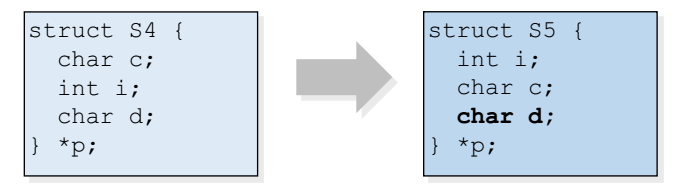
구조체 s4 를 s5 과 같이 큰 타입을 먼저 선언하면 공간이 아래 그림처럼 절약되는 모습을 볼 수 있다.