
sed

sed 's/hello/world/' input.txt > output.txt
=> s : sed 에서 제공하는 command, hello 라는 텍스트를 찾아서 world 라는 텍스트로 대체해라!
그리고 그 input의 결과를 output 으로 redirection 해라.
sed 's/hello/world/' < input.txt > output.txt
cat input.txt | sed 's/hello/world' > output.txtsed 문법
형태 : sed 범위 | -옵션 '[ line address ] command'
- 범위 : sed 에 input 으로 넘겨줄 범위값을 설정 (ex. seq 로 범위를 설정)
- 옵션 종류 : -n, -e, -E, -i, ...
- -e : 여러개의 명령어들을 연속해서 실행
- address line 이 명시되면, 해당 줄에 대해서만 명령어가 적용 및 실행된다.
- command(명령어) 는 딱 한 문자로 표현된다 ex) 명령어 종류 : p, i, d, s, r, w, c, ...
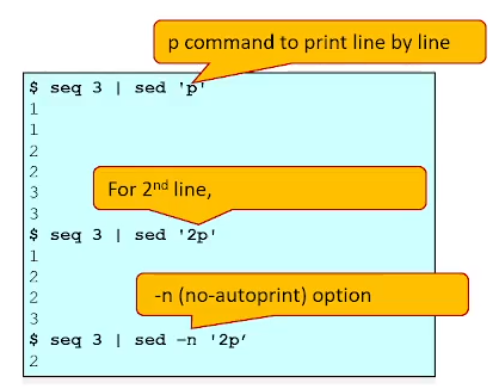
$ seq 3 | sed 'p'
=> seq 3 : 1~3 사이의 숫자가 출력
=> seq 3 | sed 'p' : seq 3 이라는 표준출력을 sed 의 표준입력으로 받겠다는 것
sed 의 표준입력으로 받아서 sed 구문안에 있는 명령어 p 에 대한 인풋값으로 부여해준다.
sed 'p' 에서 address 는 생략됨. => address 가 생략되었다는 것은 곧 명령어 p가 모든 줄에 한줄한줄 다 적용된다!
( 명령어 p : print 하는 명령어 )
=> sed 에 디폴트 출력이(auto print. 즉 자동출력) 있어서
명령어 p의 출력결과 + 디폴트 출력이 모두 일어나느라 1,2,3 이 각각 2번 출력된다.
$ seq 3 | sed '2p' : 2번째 줄에 대해서만 명령어 p를 살행
=> 2번째 줄에 대해서만 2라는 숫자가 2번 출력된다.
$ seq 3 | sed -n '2p' : "-n" 옵션 => auto print 기능을 제거
auto print 기능에 제거되어서, 2번째 줄에대해서 명령어 p의 출력 명령이 실행된다.

$ seq 10 | sed -n '4,6p'
=> 1~10사이의 숫자를 sed의 인풋으로 주고, 4~6 이라는 line address 를 넘겨줌
$ seq 10 | sed -n '2~3p'
=> 물결 "~" 은 step size 를 의미한다. 즉 2 에서 3을 더한 5와 , 또 5에서 3을 더한 8을 line address 로 넘겨줌
$ printf "%s\n" a b c | sed -n '/b/p'
=> 명령어 p 앞에 / / r가 왔다는 것은, regular expression 을 의미한다.
printf 문을 통해 a b c 가 출력이 되는데, b라는 단어를 가진 줄에 대해서 addressing 하는 것을 의미한다.
즉 b라는 단어를 가진 줄에 대해서만 명령어 p를 수행한다는 의미가 된다!명령어 종류
- a : append 기능 => 주어진 텍스트를 특정 줄에 추가
- c : replace 기능 => 주어진 텍스트를 특정 줄에 있는 텍스트로 대체(교체)
- i : insert 기능 => 주어진 텍스트를 특정 줄의 바로 앞에 삽입
- d : delete 기능 => 주어진 줄을 삭제
- e : separate 기능 => 명령어 구분 역할. -e 옵션을 두면서 명령어들을 연속으로 나열 및 사용가능
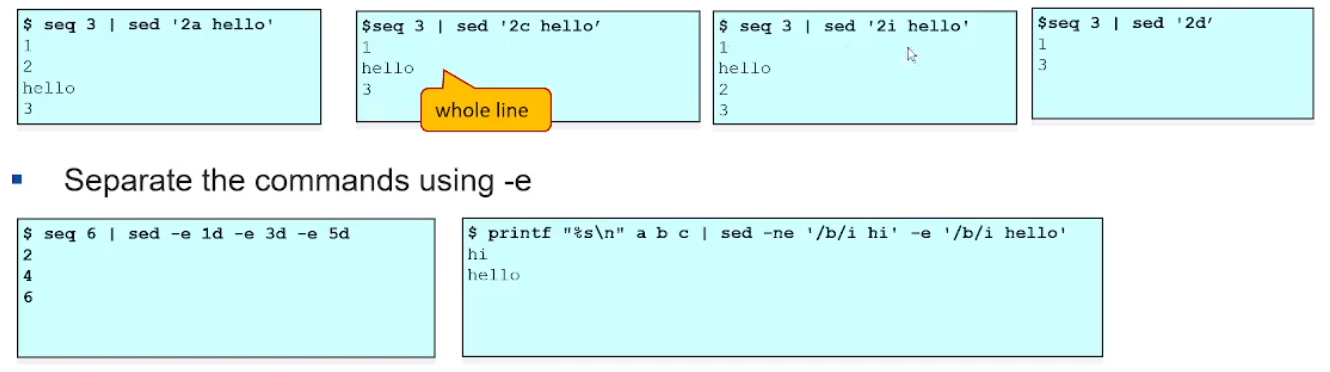
$ seq 3 | sed '2a hello' : "hello" 라는 텍스트를 2번째 줄에 append
$ seq 3 | sed '2c hello' : "hello" 라는 텍스트를 2번째 줄에 있는 텍스트와 교체
$ sed 5 | sed '2,4c hello' : "hello" 라는 텍스트를 2~4번째 줄에 있는 텍스트와 모두 교체
(=> 출력결과는 1 hello hello helllo 5 가 될 것이다.)
$ seq 3 | sed | sed '2i hello' : "hello" 라는 텍스트를 2번째 줄 바로 앞에 삽입
(즉, 인풋 hello 가 삽입되는 줄이 새롭게 2번쨰 줄이 되고 기존의 2번째 줄의 내용은 한줄 밀려서 3번째 줄로간다.)
$ seq 3 | sed '2d' : 2번째 줄을 삭제
$ sed 6 | sed -e ld -e 3d -e 5d : 1d, 3d, 5d 가 실행된다. 즉, 1번째 줄이 삭제되고, 3번째 줄이 삭제되고, 5번째 줄이 삭제된다.
$ printf "%s\n" a b c | sed -ne '/b/i hi' -e 'b/i hello'
=> -n 옵션과 -e 옵션을 동시에 사용가능. => '-ne' 로 표현됨명령어 's'
형태 : s/pattern/replacement(새롭게 대체할 문자열임!)/flags
- pattern 을 만족하는 부분 문자열들에 대해 다른 새로운 문자열로 대체한다.
- pattern 은 regular expression 으로써 부여된다.
- "-E", "-r" 옵션 : 기존의 basic한 regular expression 을 더 확장해서 확장적인 regular expression 을 제공하는 옵션기능
동작원리
- 명령어 s가 pattern 을 만족하는(일치하는) 문자열 줄들에 대해서 새로운 문자열로 대체한다.

$ echo "apple %-= banana."
=> 그냥 평범한 출력문
$ echo "apple %-= banana." | sed -E 's/a/X'
=> "-E" 옵션 : 기존의 basic한 regular expression 을 더 확장해서 확장적인 regular expression 을 제공하는 옵션기능
=> 's/a/X' : "s"는 명령어 s이고,
"a" 는 pattern 으로써, 이렇게 단순히 char 문자가 오면 특별한 의미 및 기능이 없이
주어진 문자열 "apple %-= banana" 에서 a 라는 문자를 찾아서 새로운 문자열(문자)인 "X" 로 대체하는 것이다.
$ echo "apple %-= banana." | sed -E 's/a/X/2'
=> 바로 위 코드에서 flag 인 2가 추가된 형태. 바로 위 코드처럼 flag 가 없는경우는
주어진 문자열 "apple %-= banana" 에서 a를 찾을떄 a가 굉장히 많은데 가장 앞에있는 a를 X로 대체하는 코드이다.
반면, 현재 코드처럼 flag 에 2가 부여되면 2번째 a를 X로 대체한다!
$ echo "apple %-= banana." | sed -E 's/a/X/g'
=> flag 로 'g' (= global) 를 부여하면 'g'lobal 하게 모든 문자 a에 대해서 X로 대체함.
$ cat input | sed -E 's/([^ ]*), ([^ ]*)/\2 \1/g'
=> ([^ ]*), ([^ ]*) : regular expression 부분 (pattern 부분) 으로,
swap 기능을 가지고 있다. 첫번째 ([^ ]*) 에는 1이, 두번째 ([^ ]*) 에는 1이 할당된다.
$ cat input | sed -E "s/$old/$new/g"
=> $old, $new 와 같은 쉘 변수에도 새로운 문자열로 대체하는 replacement 작업이 적용가능하다!
Sed 의 regular expression
- 슬래쉬 2개 '/ / ' 사이에서 regular expression (pattern) 을 표현하면 된다.
- ex) $ cat text | sed -n '/hello/p' => regular expression인 "hello" 를 슬래쉬 2개 사이에서 표현함.
-
"-E" 또는 "-r" 옵션은 regular expression 을 사용하겠다고 명시적으로 표시하는 것
-
regular expression 안에서 슬래시 2개 사이에 넣을 수 있는 특수 문자들
-
^ : 라인(줄)의 시작을 의미
-
$ : 라인(줄)의 끝을 의미
=> cf) sed 에서 $ 나 ^ 등을 특수문자가 아닌 그냥 평범한 문자들을 찾고 replacement 하고 싶은경우는 역슬래쉬를 통해서 escape 시켜줘야 한다.
(regular expression 안에서 /$ 나 /^ 와 같은 형태로 선언해서 평범한 문자로 인식시키면 된다!)
-
$ cat text | sed -n '/hello/p'
=> text stream 표준출력으로써, hello 라는 문자열을 찾아서 해당 줄에 대해 명령어 p를 수행(해당 줄을 출력)
cf) 명령어 "grep hello" 를 실행하는것과 동일하는 기능이 된다!
$ cat text | sed -En '/hello/p'
=> 옵션 "-E" 을 부여함으로싸 regular expression 을 사용하겠다고 명시적으로 선언한 것이다.
몰론 이 옵션을 명시안해도 regular expression 을 표현 가능하지만,
어떤 special character (ex. / \ $ . [] () ^ * + ? 등등) 을 사용하게 될때만큼은 반드시
옵션을 명시해야지 정상적으로 인식을 한다!와일드카드, anchor
와일드카드

^ : 라인(줄)의 시작을 의미
$ : 라인의 끝을 의미
. : 단일문자를 의미
\s : 공백문자와 tab 을 의미
\b : 단어(word) 의 양 끝의 경계를 의미
\< : 단어의 양 끝 경계중 앞에있는 시작경계를 의미
\> : 단어의 양 끝 경계중 앞에있는 끝경계를 의미
\w : word character 를 의미 => word character 에는 문자, 숫자, 언더스크어 문자들이 해당한다.
/W : non-word character 를 의미 => word character 에 속하지 않는 문자들이 이에 해당한다.예제
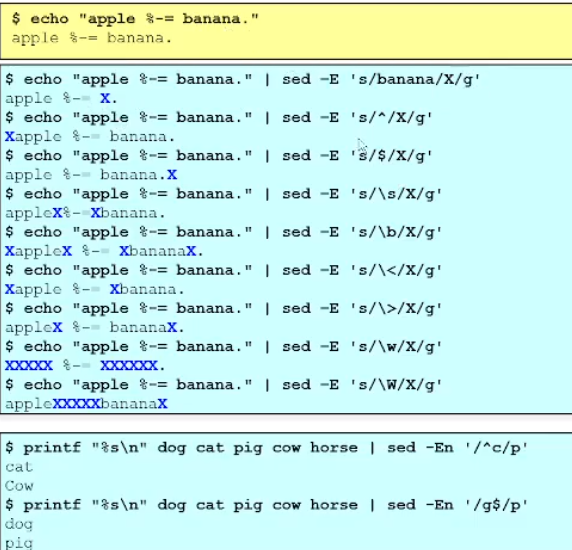
$ echo "apple %-= banana." | sed -E 's/^/X/g'
=> 문자열에서 맨 시작문자를 X로 대체한다는 의미
("apple %-= banana." 가 "Xpple %-= banana." 로써 출력결과가 바뀜!)
--------
$ echo "apple %-= banana." | sed -E 's/\b/X/g'
=> 각 단어의 경계를 X로 대체한다. 즉, 단어 apple 과 banana 경계를 X 로 대체해서
"XappleX %-= XbananaX" 가 되는것을 볼 수 있다. (cf. "%-=" 는 단어가 아닌 기호이다!)
--------
$ echo "apple %-= banana." | sed -E 's/\W/X/g'
=> non-word character 를이 X로 대체되었다.
--------
$ printf "%s\n" dog cat pig cow horse | sed -En '/^c/p'
=> ^c 라는 pattern 을 만족하는 라인에 대해서만 명령어 p를 수행해라!
^ 는 라인의 시작을 의미하는 와일드카드이므로, c로 시작하는 라인에 대해서 명령어 p를 수행하라는 의미가 된다.
---------
$ printf "%s\n" dog cat pig cow horse | sed -En '/g$/p'
=> 라인의 끝 문자가 g 인 라인들에 대해서 명령어 p를 수행하라!Group and Quantifiers
- 여러가지 표현들을 그룹화시켜서 pattern 을 표현할 수 있다.

- 형태1 : 표현1 | 표현2
ex) abc|def : "abc" 와 일치하거나 "def" 와 일치하는 라인 또는 문자열을 찾는다.
- 형태2: (표현)
=> brace expression 을 사용하며 그룹화 시키는 방법이다.
ex) fos(abc|def)* : "fosabs" 와 일치하거나 "fosdef" 와 일치하는 라인 또는 문자열을 찾는데,
형태2 에서 특수문자 종류

* : 해당 문자(또는 문자열) 포함하는 문자열 또는 라인을 찾는다는 의미
해당 문자(또는 문자열)을 아무것도 포함하지 않는것도 포함해서 찾는다!
ex1) "abc*" : 문자 c 를 하나 이상이라도 포함하고 있는 라인 또는 문자열을 포함하는 문자열을 찾는다. => "abc", "abcc", "abcde" 등에 매칭된다.
이때 c를 포함하지 않는 라인 또는 문자열로 찾아낸다. 즉, ab 를 하나 이상이라도 포함하는 라인 또는 문자열을 찾아낸다! => "abc", "abcd", "abccc" 등이 매칭된다.
ex2) "fos(abc|def)*" : 문자열 "abc" 또는 "def" 중에서 하나 이상이라도 포함하고 있는 라인 또는 문자열을 찾는다.
(또는 abc, def 중에 아무것도 포함하지 않는 라인 또는 문자열도 찾아낸다)
=> "ab", "abc", "abcc", "abccc", "d", "def", "defff", ... 등이 이에 매칭될 것이다.
(이떄 "ab" 와 "d" 는 아무 문자열도 포함하지 않지만, 이들도 * 찾아낸다!)
ex3) ".*" : 점 "." 는 와일드카드로써 아무 단일문자를 의미하는 것이므로, 아무 단일문자를 포함하는 문자열 또는 라인을 찾는다.
(또한 아무 단일문자도 포함하지 않는 문자열 또는 라인을 찾는다.)
=> 즉, 모든 문자열들이 이에 매칭될 것이다 (이때 빈 문자열도 포함!)
-----------------------------------------------------
+ : * 에서 조금만 조건이 바뀜. 별표 * 가 해당 문자(또는 문자열) 중에 아무것도 포함하지 않는 문자열 또는 라인들도 포함해서 찾는다면,
+ 는 이 조건이 제외되었다. 즉, 해당 문자(또는 문자열)을 포함하는 문자열 또는 라인만 찾는다!
ex) "abc+" : "abc", "abcdef", "abccc" 등에 해당된다. "ab" 와 같은 것들은 "abc" 를 포함하지 않으므로 결과적으로 매칭되지 않는다.
-----------------------------------------------------
? : 해당 문자열이 없거나 딱 한번만 포함하는 문자열 또는 라인을 찾는다는 의미
ex) "abc?" : "ab" 와 "abc" 등이 매칭된다.
-----------------------------------------------------
{i, j} : 해당 문자열이 i ~ j 번 사이로 반복되는 문자열 또는 라인을 찾는다는 의미
ex) (abc){2, 4} 은 "abcabc", "abcabcabc", "abcabcabcabc" 등이 매칭된다.
예제

$ printf "%s\n" dog cat pig cow horse | sed -En '/^(c|d)/p'
=> c 또는 d 로 시작하는 문자열을 출력
$ printf "%s\n" dog cat pig cow horse | sed -En '/ca*/p'
=> a를 포함하거나 포함하지 않는 문자열 또는 라인을 찾아서 출력.
즉 a를 포함하지 않는 문자열인 "c", "cbb", "cold" 등이 매칭되며,
ca를 포함하는 문자열인 "ca", "caa","caa" ,"carr" 등이 매칭된다.
$ printf "%s\n" dog cat pig cow horse | sed -En '/co?w/p'
=> 문자 o가 없거나 있는 것들 탐색. 즉, "cow", "cw" 등에 매칭된다.
$ printf "%s\n" gogle google gogogle | sed -rn '/(go){2,}/p'
=> "go" 라는 것이 최소 2번이상 반복되는 문자열들을 찾아낸다.
Character Set (문자 집합)
형태

- 형태1 : [ charset ]
- char set 에 있는 문자중 어떤거 하나라도 포함하면 매칭되는 것
- ex1) [aeiou] : 문자 a,e,i,o,u 중에 하나라도 포함하는 것과 매칭
- ex2) [bc]at : "bat" 와 "cat" 과 매칭됨.
- 형태2 : [ char1 - char2 ]
- charset 의 범위를 지정하는 것
- ex) [a-z0-9] : a~z 사이의 문자 또는 0~9 사이의 숫자를 하나라도 포함하는 것과 매칭
- cf) 이와 같은 형태에서 "-" 의 특수기능을 제거하고 - 를 그냥 평범한 문자로 인식시키고 싶다면 역슬래쉬를 사용해서 "/-" 와 같은 형태를 만들자!
- 형태3 : [ ^charset ]
- charset 의 부정(^) 으로, charset 에 포함되지 않는 문자들을 하나라도 포함하면 매칭되는 것
- [^abc] : 문자 a,b,c 를 포함하지 않는 것과 매칭
- cf) "^" 가 밖에있으면 anchor 로써 역할을 수행하기 때문에 주의하자!
특수문자

[+\-]?[0-9]+
=> 문자 + 또는 - 중에 아무거나 문자 하나를 포함하고 0~9 사이의 숫자중에 아무 숫자를 1번 이상 포함한 문자열과 매칭
=> 이때 특수한 기능을 가진 "-" 는 역슬래쉬를 앞에 붙임으로써 그 기능이 제거되고 평범한 문자가 되었다.
$[0-9]{3}-[0-9]{3}-[0-9]{4}
=> 0~9 사이의 아무 숫자가 3번 오고, 0~9 사이의 아무 숫자가 3번 오고, 0~9 사이의 아무 숫자가 4번 오는 문자열과 매칭
$[\w|\W]\s {2}
=> word 문자 또는 non-word 문자가 나오고 나서 공백문자(\s) 가 2번 나오는 것들과 매칭예제

- 왼쪽 그림처럼 stat 으로 나오는 정보들중에 괄호가 포함된 정보들만 매칭하고 뽑아내고 싶은 상황일때, 오른쪽 그림처럼 regular expression 을 사용하자.
\([^\)]*\)
해석 순서
1. \( : "(" 의 특수한 기능제거
2. ^ : charset 에서 부정의 기능
3. \) : ")" 의 특수한 기능제거
4. *
5. \) : ")" 의 특수한 기능제거
=> 여는괄호 "\(" 로 시작해서 괄호가 아닌 것들 "^\)" 이 0번이상 나오고 닫는괄호 "\)" 로 끝나는 문자열들을 찾아낸다.
( => 여기서 괄호가 아닌 것들 "^\)" 이란 괄호안에 포함된 평범한 문자 및 숫자를 의미할것이다! )Back-references and SubExpressions (레퍼런스(참조)하는 방법)
-
Back-references 도 regular expression command 이다.
-
처음에 매칭된 파트를 재활용해서 레퍼런싱할 떄 사용할 수 있다.
-
레퍼런싱할 대상을 괄호 "( )" 로써 감싸면 레퍼런싱이 가능해진다. (그룹을 레퍼런싱 하는것)
-
Back-references 는 역슬래쉬와 단일 숫자의 조합으로 수행된다. (ex. '\1', '\2')
예제1
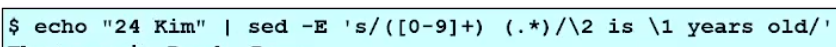
- 출력결과 : Kim is 24 years old
예제2

블로그 이전했습니다 🙂 : https://haon.blog