Proxy? 어떤 Proxy 인가?
프록시란 너무 범용적인 단어입니다. Spring Proxy, Proxy 패턴, Network Proxy 등에서 널리 사용되는 단어인데, 이번에 저희가 살펴볼 내용은 Network Proxy 입니다.
Proxy Server 가 없다면?
프록시 서버란 쉽게말해 "통신을 대신 처리하는 서버" 입니다. 클라이언트와 서버간의 중계 서버로, 통신을 대리 수행하는 서버입니다.
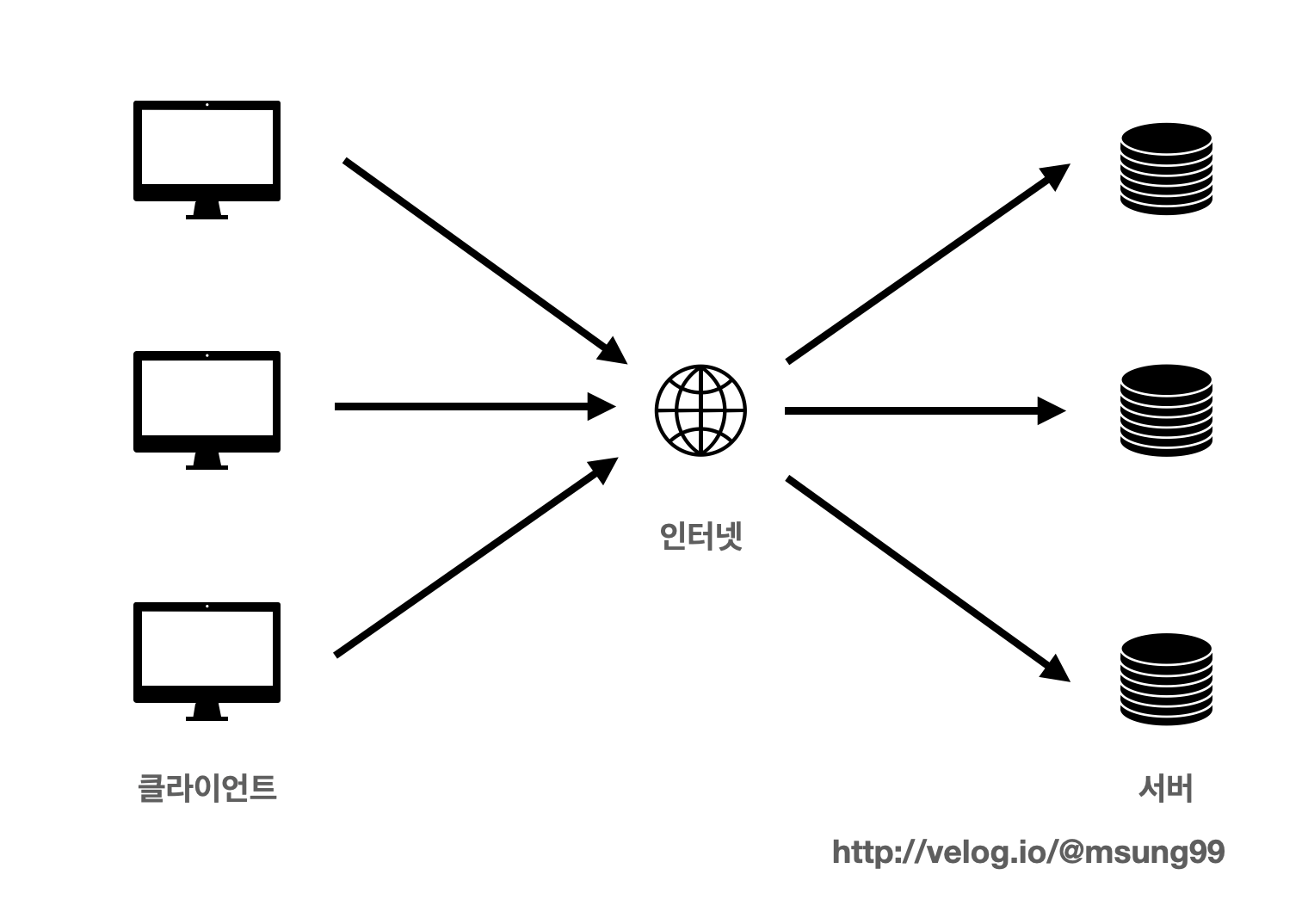
몰론 위와 같이 프록시 서버가 없이 클라이언트와 서버가 직접적으로 인터넷을 통해 통신은 가능합니다. 다만 이런 방식을 채택하면 클라이언트의 IP주소가 유출될 수 있다는 위험성이 존재합니다. (자세한 내용은 조금뒤에 설명드리겠습니다)
이 외에도 다양한 이유로 프록시 서버를 통해 클라이언트와 서버가 프록시 서버를 통해 간접적으로 통신하는데, 이들을 계속 알아봅시다.
정리) 프록시 서버 : 클라이언트와 서버간의 통신을 중계해서 대리 수행해주는 서버. 클라이언트와 서버는 직접적으로 통신하는 일을 방지할 수 있습니다.
Forward Proxy
프록시서버는 크게 Forward Proxy, Reverse Proxy 2종류로 나뉩니다.
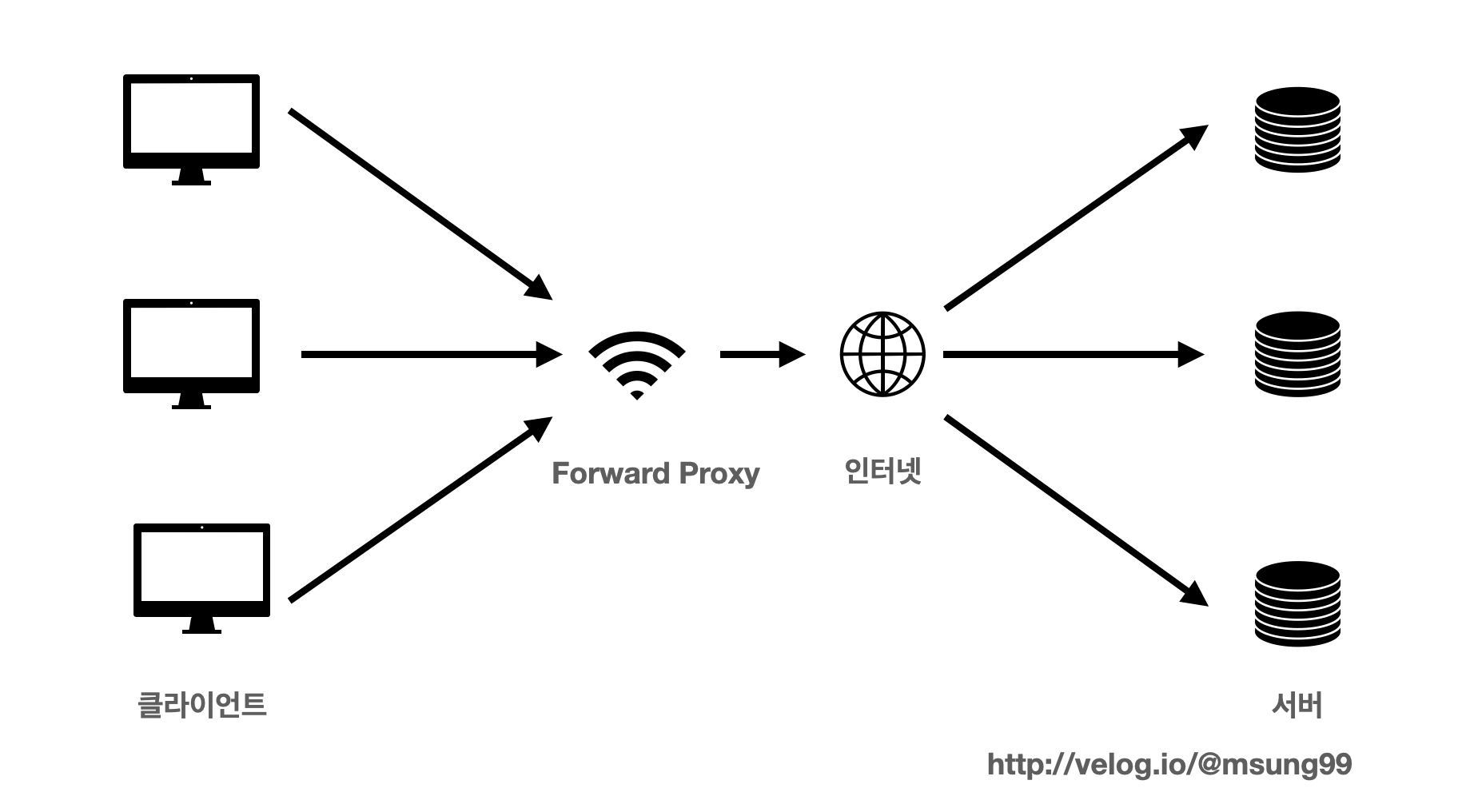
일반적으로 부르는 "프록시 서버" 는 Forward Proxy 를 의미합니다. 예를들어 아래처럼
- 프록시 서버를 설정하라!
- 외국에서 접속한 것처럼 테스트하도록 프록시 설정을 해주자!
- 개인정보를 빼돌린 해커 이모씨는 IP추적을 방지하도록 proxy 설정을 했다.
이런 표현들에서 사용하는 프록시라는 것이 Forward Proxy 입니다.
특징1: 캐싱
Forward Proxy 의 특징중 하나는 바로 캐싱입니다. 캐싱이란 자주 요청하는 결과 데이터를 캐시에 저장해놓고, 해당 데이터를 재요청하는 경우 서버에 재요청하지 않고 프록시 서버의 캐시에 저장해놓은 데이터를 리턴하는 방식 을 의미합니다.
예를들어 첫번째 클라이언트가 가요차트 1등 그룹이 누구인지 정보를 얻고싶어서, 서버에게 요청을 보냈다고 해봅시다.
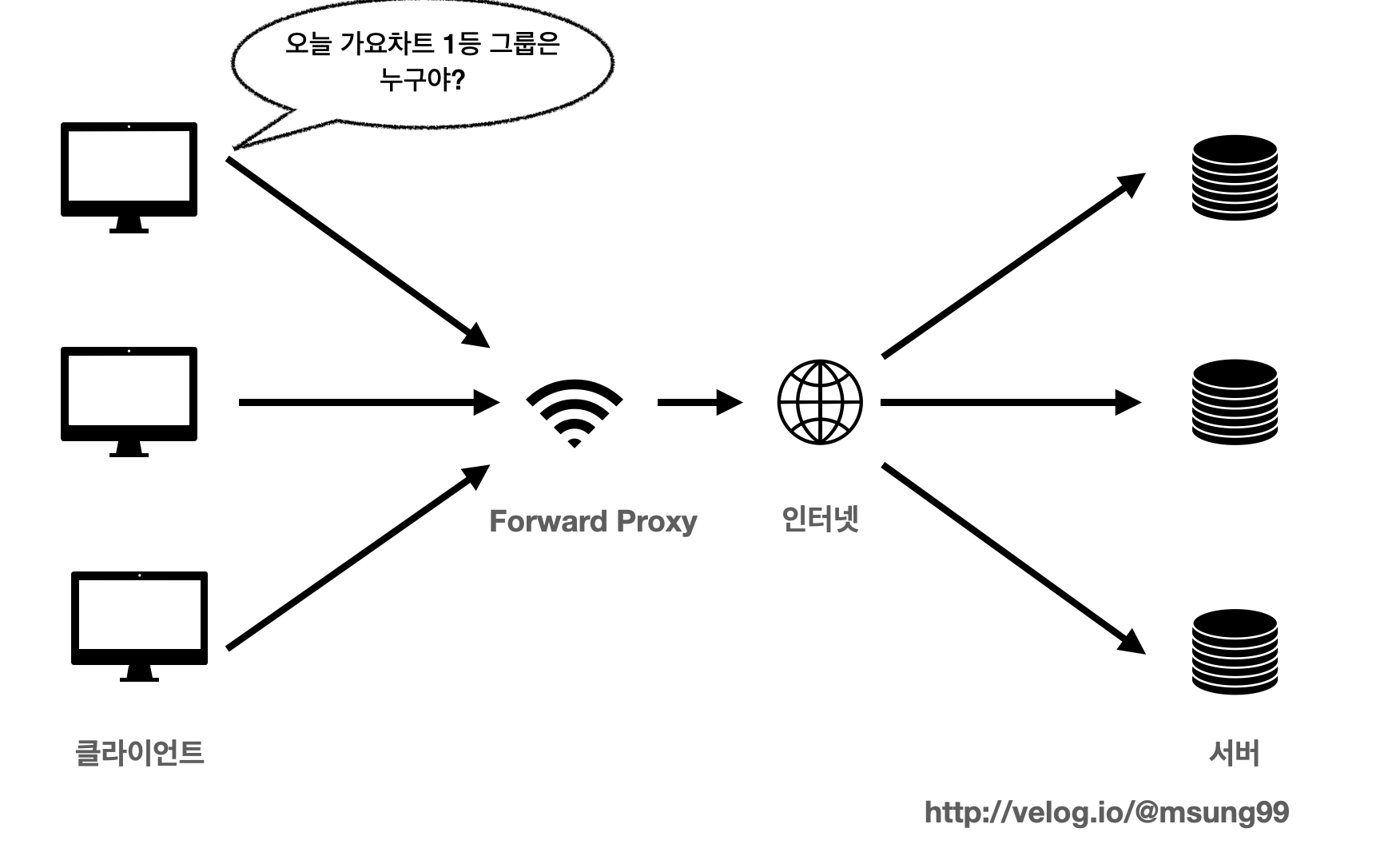
여러개의 서버중 가요차트 정보를 제공해주는 담당 서버는 클라이언트가 원하는 정보를 아래처럼 제공해주겠죠? Forward Proxy 서버와 인터넷을 통해 정보를 주고받을 겁니다.
그런데 이때 프록시 서버는 그냥 단순히 원하는 정보를 제공해주는 것이 아닙니다. 캐시에다가 가요차트 1등 그룹이 누구인지를 저장해놓는 것이죠.
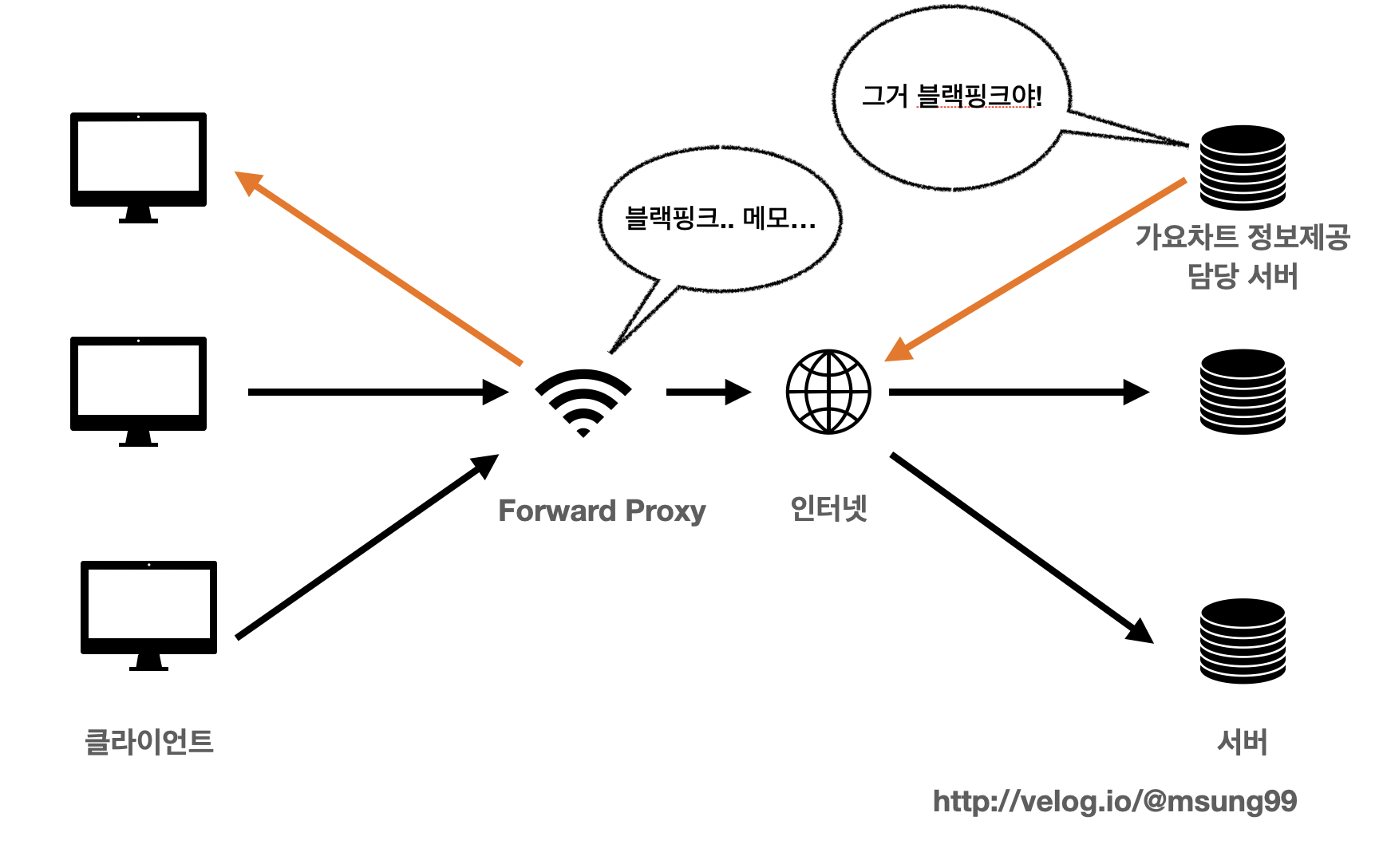
그러고 추후 여러 클라이언트들이 가요차트 1등 그룹이 누군지를 알고 싶을때 프록시 서버는 캐시에 저장해놓았던 데이터를 제공해주는 것입니다. 즉, 서버까지 귀찮게 도달하지 않더라도 캐시에 저장해놓은 데이터를 프록시 서버가 대신 제공해주는 것이죠.
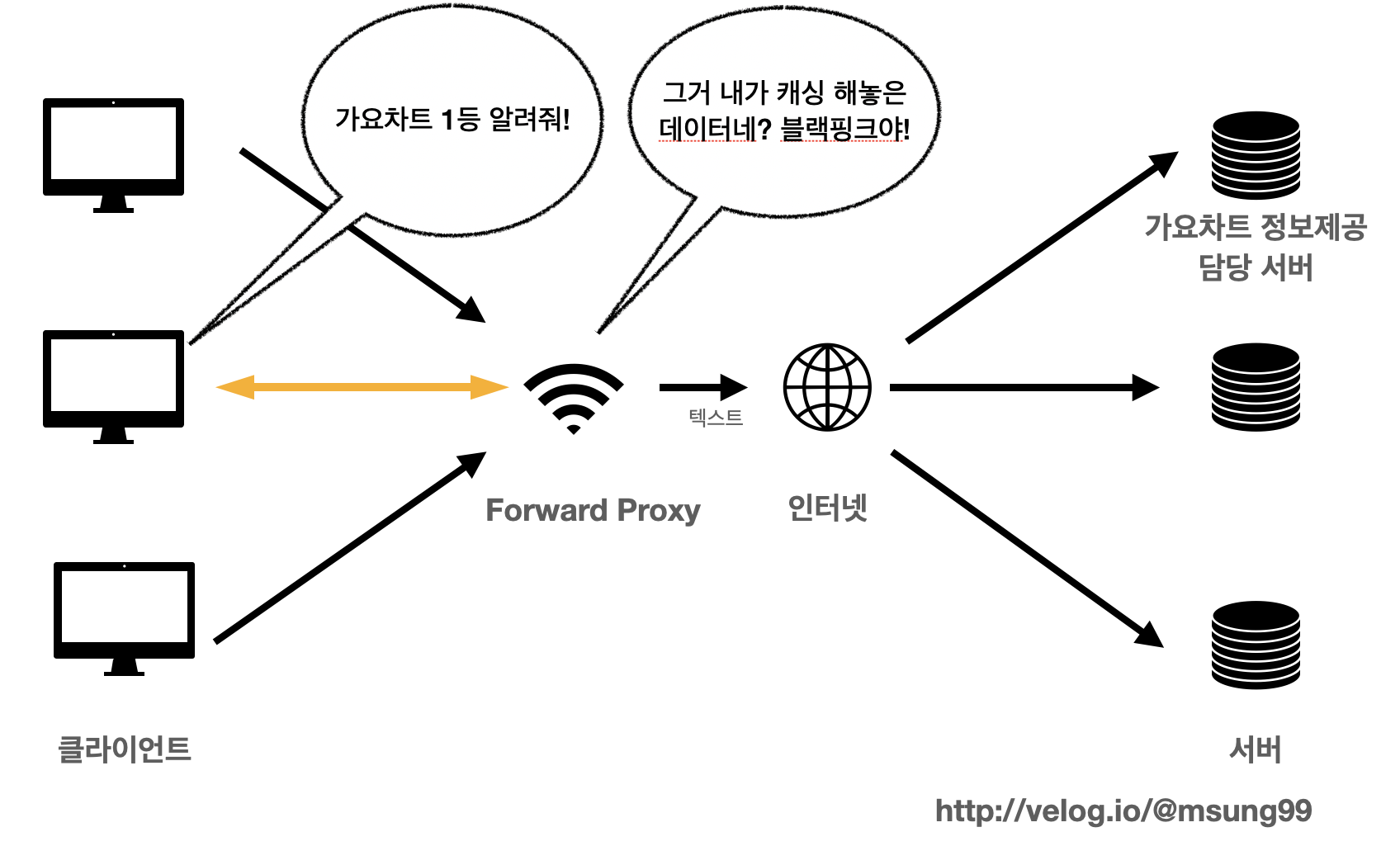
이러한 캐싱의 특징으로 얻을 수 있는 장점은 다음과 같습니다.
- 1) 전송 시간절약
- 2) 불필요한 외부 전송을 하지 않아도 된다.
- 3) 외부 요청이 감소한다 : 네트워크 병목현상 감지
인터넷, 서버를 통하지 않기 떄문에 전송 시간이 절약됩니다. 또한 불필요한 외부 전송을 하지 않아도 되고 외부 요청이 감소됨으로써 네트워크 병목현상을 방지할 수 있습니다.
특징2: 익명성
다음으로는 익명성이라는 특징이 있습니다. 익명성을 지닌다는 것은 클라이언트가 보낸 요청을 감춘다는 의미입니다.
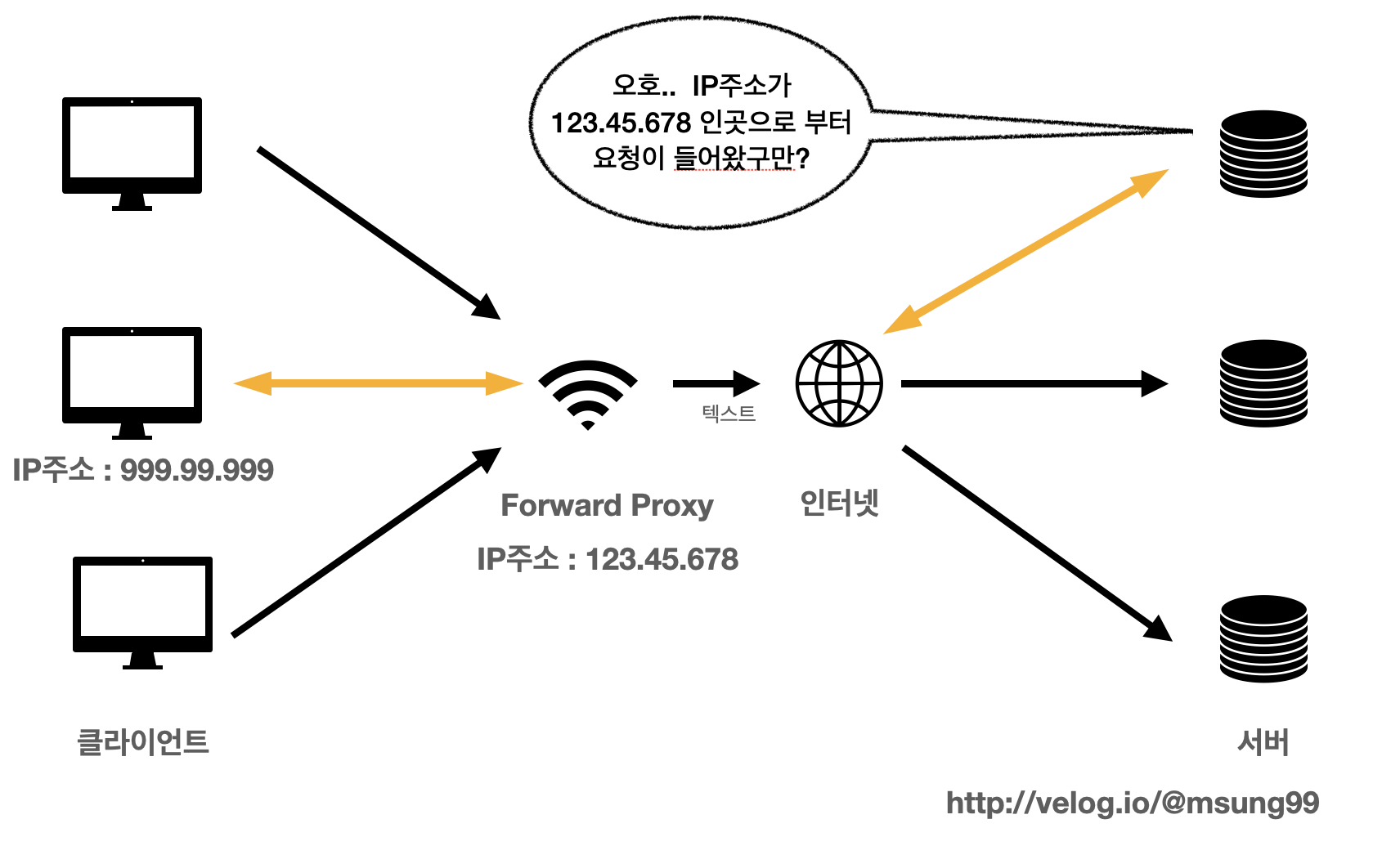
클라이언트가 서버로 직접 호출할때는 저희(클라이언트)의 IP주소, 장비 정보, OS정보등을 그대로 서버에게 전달해야합니다.
만일 Forward Proxy 를 사용한다면 저희 클라이언트가 요청했지만 마치 Forward Proxy 가 요청을 한 것처럼 서버들에게 Forward Proxy 의 정보들을 전달해 줄 수 있습니다.
-
즉, 클라이언트의 IP주소 같은 정보를 서버에 직접 제공하지 않고, 대신 Forward Proxy 의 정보를 제공하는 것이죠. 이게 익명성입니다.
-
서버는 응답받은 요청을 누가 보냈는지 알지 못하게 됩니다.
예를들어 서버가 받은 요청 IP 는 곧 proxy IP 입니다. (서버가 받은 요청 IP = proxy IP)
Reverse Proxy
Reverse Proxy 는 Forward Proxy 과 거의 유사하나, 큰 차이점을 뽑자면 Forward Proxy 와 달리 인터넷-서버 사이에 위치하고 있다는 점입니다.
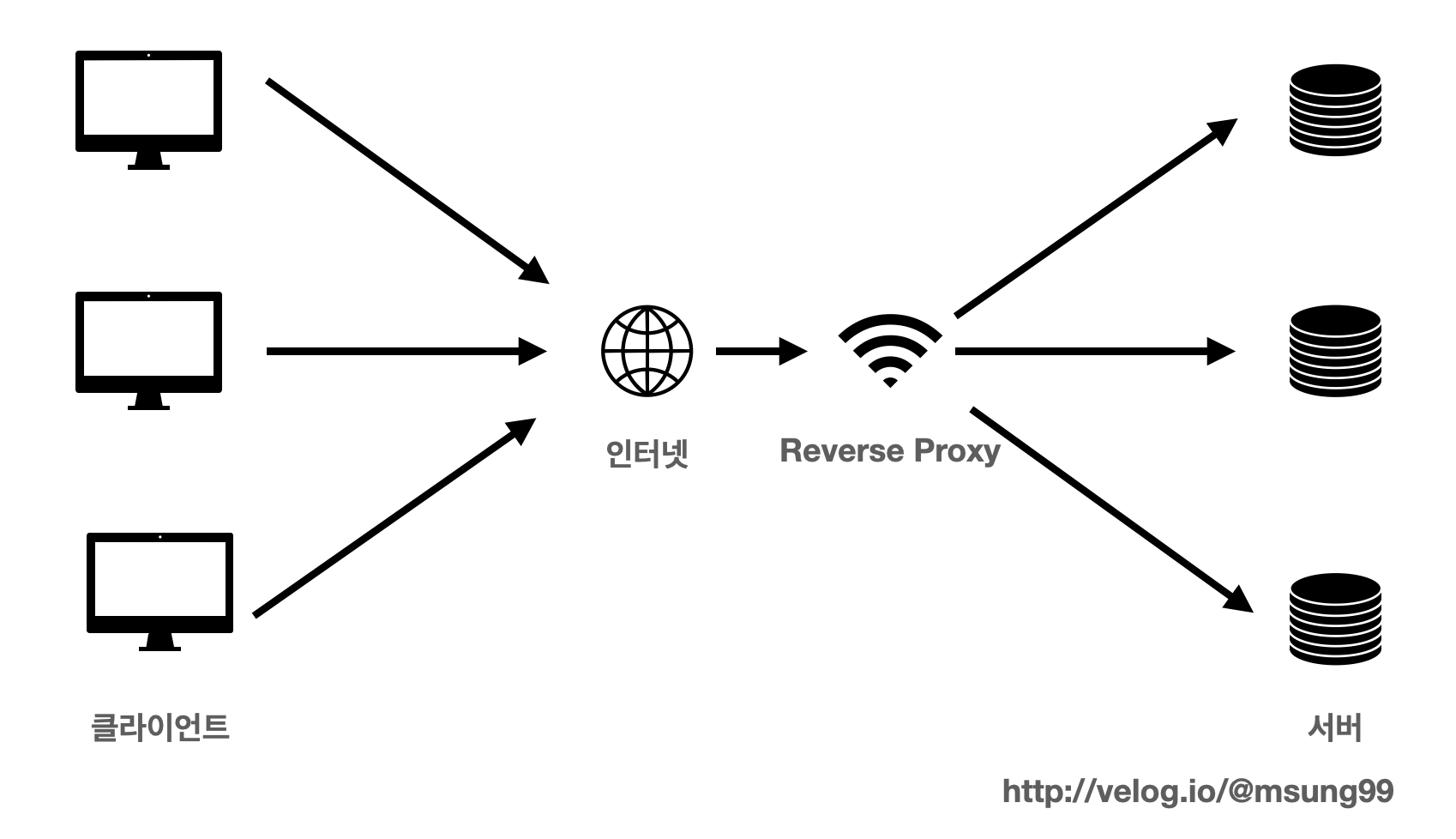
이들의 특징도 간단히 알아봅시다.
특징1 : 캐싱
Forward Proxy 와 동일하게 캐싱이 가능합니다. 그로 인해 얻어내는 장점도 동일하죠. 캐싱이 무엇인지는 앞서 살펴봤으니 자세한 설명은 생략하겠습니다!
특징2: 보안
다음 특징은 보안적이다 라는 것입니다. 서버의 정보를 클라이언트로부터 숨길 수 있다는 점입니다.
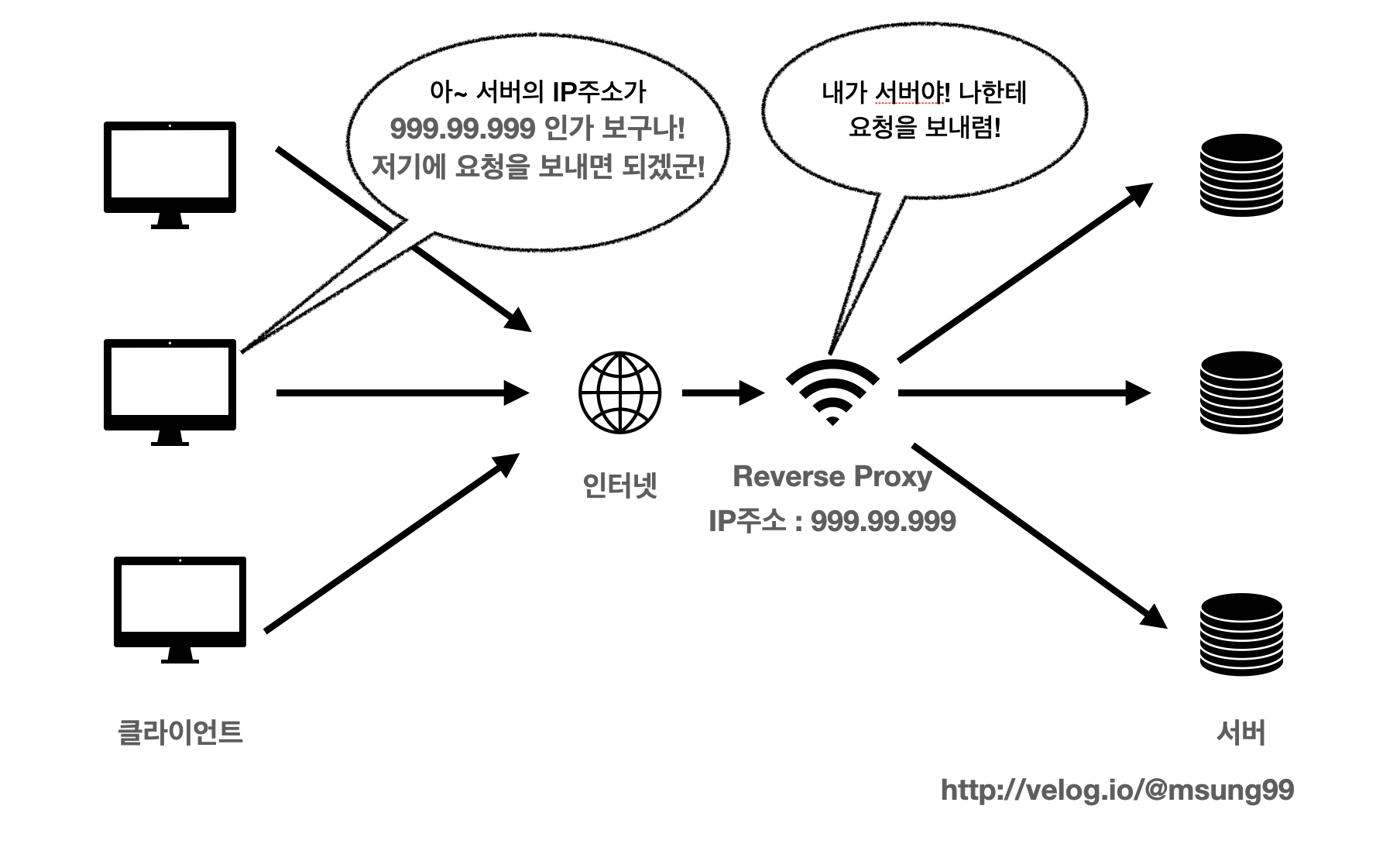
클라이언트는 요청을 할때 어떤 서버에 요청을 하는지, 또 해당 서버의 정보는 무엇인지 직접 알지 못합니다. 대신 클라이언트 입장에서 서버인 Reverse Proxy 에게 요청을 전달합니다.
클라이언트들은 Reverse Proxy 를 실제 서버라고 생각하고 요청을 합니다. 따라서 실제 서버들의 IP는 클라이언트로부터 안전하게 보호됩니다.
정리해보자면 아래와 같습니다.
- 클라이언트는 reverse proxy 를 실제 서버라고 생각하고 요청한다.
- 실제 서버의 IP가 유출되지 않는다.
특징3: 로드밸런싱
다음으로 로드밸런싱이 가능하다는 점입니다. 로드밸런싱은 상황에 따라서 할지말지를 결정해야합니다. (하는 경우도 있고, 하지 않는 경우도 있습니다. 선택적임)
- 로드밸런싱이란 무엇일까요? 이것도 무엇인지 알아봅시다.
로드밸런싱
로드밸런싱(Load Balancing) 이란 쉽게 말하면 부하분산입니다. 해야할 작업 및 요청을 적절히 분배시켜서 서버의 부하를 분산시키는 것입니다.
로드밸런서란 여러대의 서버가 분산(나누어) 처리할 수 있도록 요청을 나누어주는 서비스다.
로드밸런싱의 등장배경
저희는 왜 로드밸런싱을 써야하며? 이것은 왜 Reverse Proxy 에서 활용되는 것일까요?
예를들어 최대 10명의 요청을 동시간대에 처리가능한 서버를 구축하고 배포했다고 가정해봅시다.
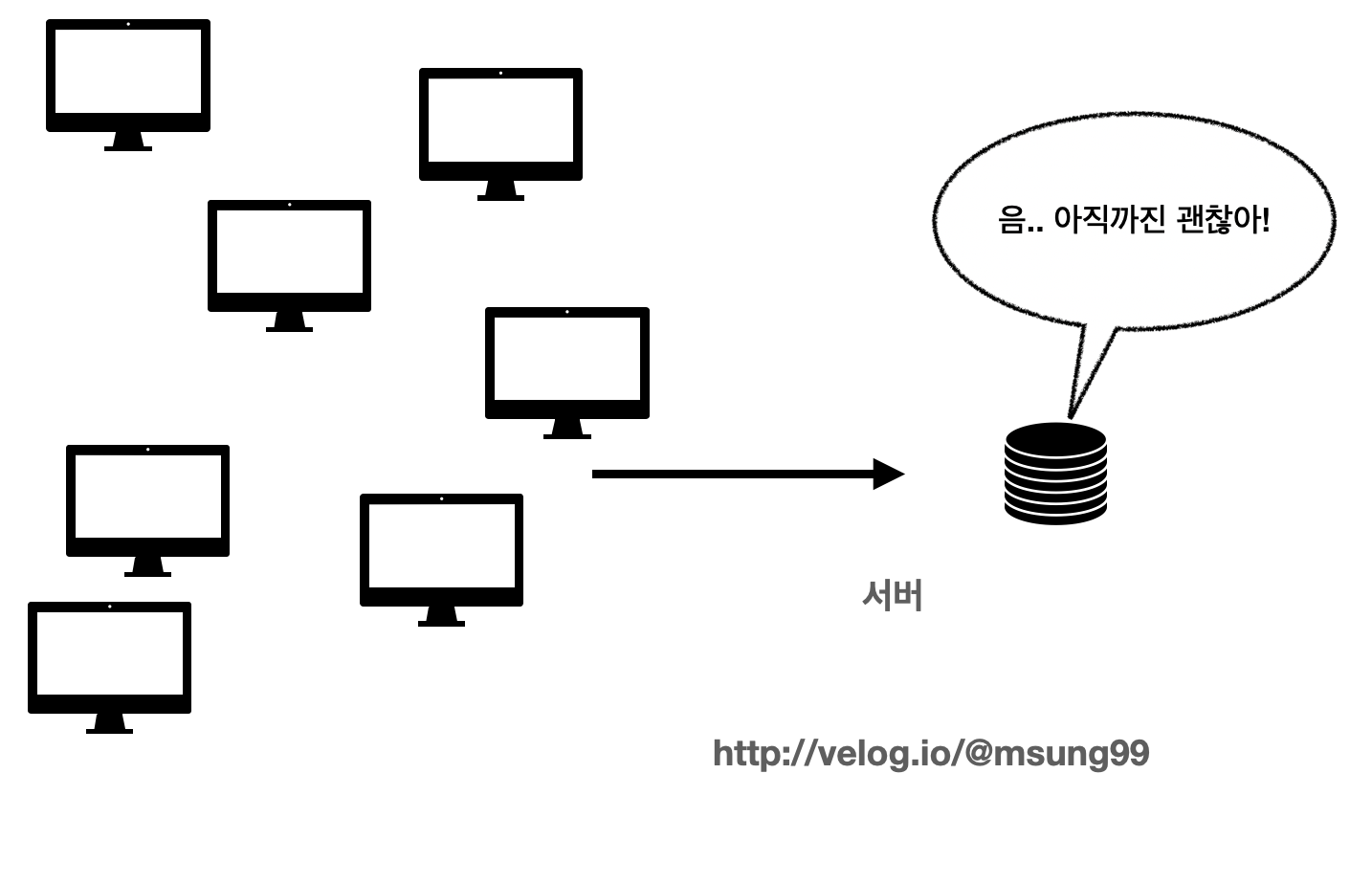
그런데 서비스 사용자가 많아져서 10명이 넘어가는 사람들이 요청을 보내는 경우가 발생한다면, 서버에 부여하는 부하가 커질겁니다. 과부하가 걸리는 것이죠.
- 이에따라 서버의 성능을 향상시켜서 문제는 임시적으로 해결 가능합니다. CPU 성능을 개선하고, 메모리도 넣어서 성능을 좋게 만들어서 해결하는 것이죠.
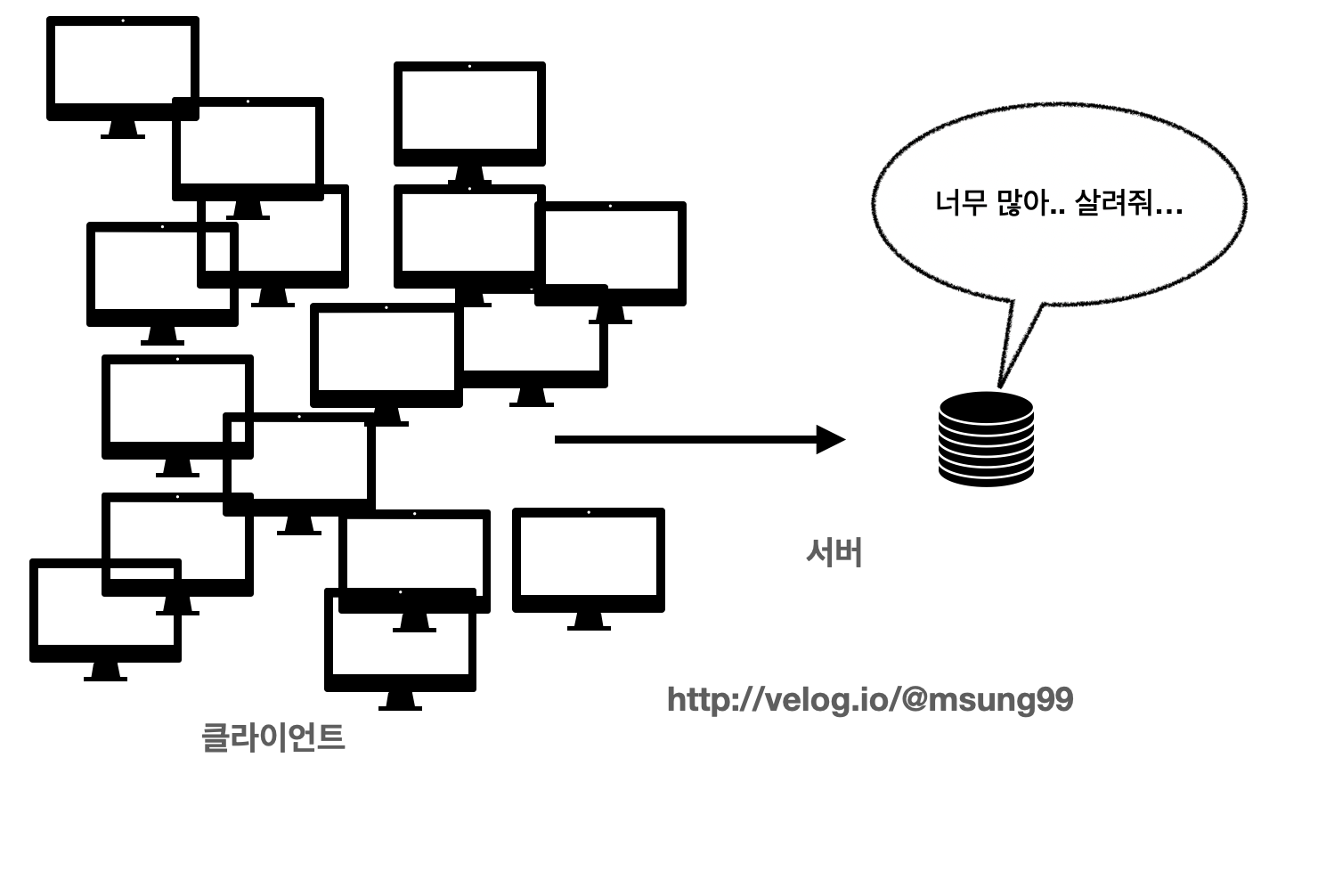
- 그러나 사용자가 100만명이 넘어가면 어떨까요? 그때는 메모리에 꽃을 수 있는 소켓도 한정적입니다. 이떄 바로 로드밸런서를 적용하여, 서버를 1대가 아닌 100대로 늘리고 클라이언트로 부터 오는 각 요청을 골구로 서버들에 분산시켜주는 것이죠.
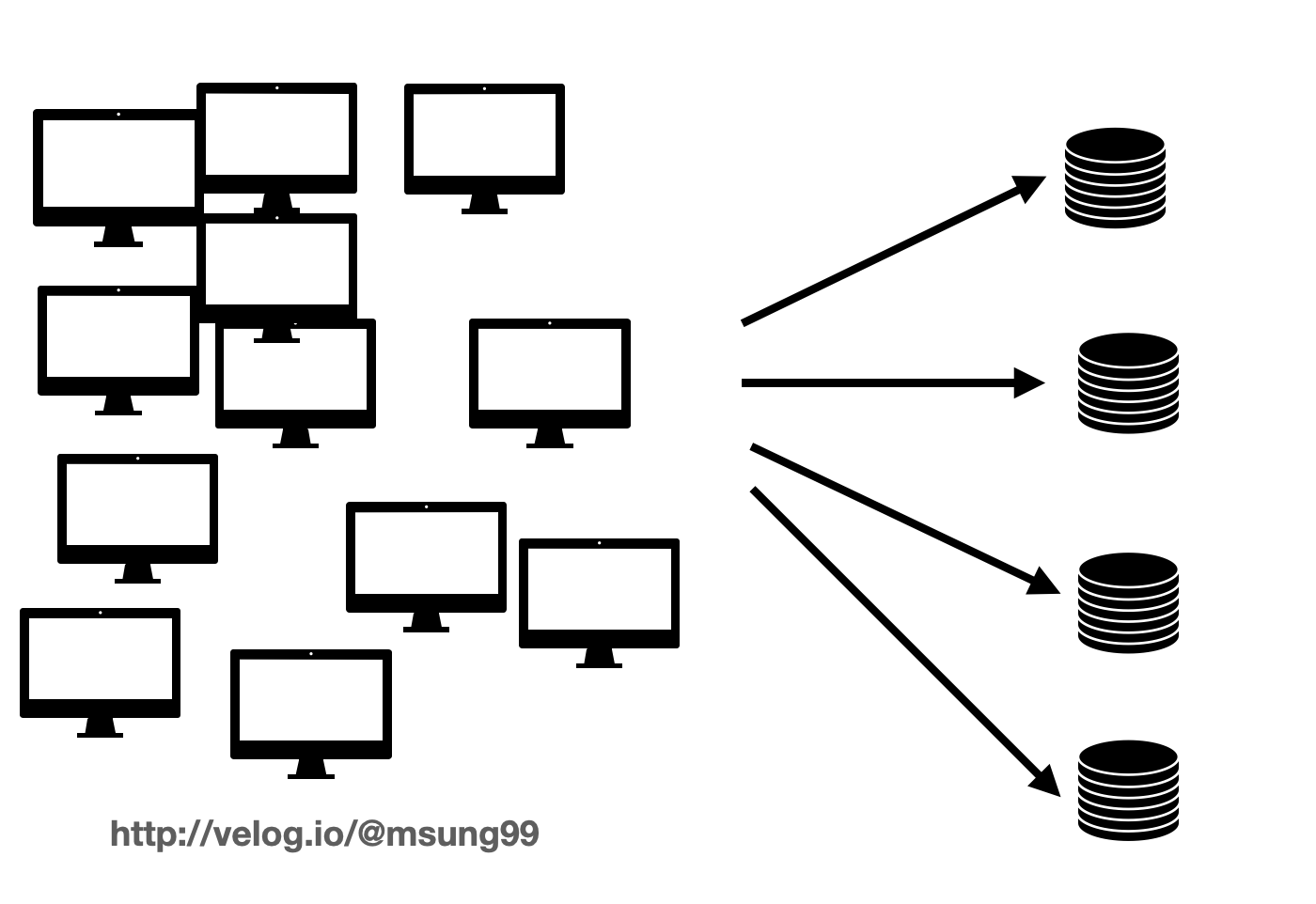
로드밸런싱의 특징과 장점
앞서 로드밸런싱을 알아봤는데, 특징을 정리하고 추가적인 장점을 나열해보자면 다음과 같습니다.
🤔 많은 트래픽을 어떻게 대처할까?
- Scale up: 기존 서버의 성능을 높인다 (비용도 같이 올라간다)
- Scale out: 여러 대의 서버를 두어 트래픽을 분산시킨다.(물리적 or 논리적)
여기서 저는 비용적인 부분을 생각해 논리적인 Scale out 방식을 생각했습니다.
Scale out을 하기 위해서 무조건 해야 하는 일이 로드밸런싱입니다!
트래픽을 감당하는 장점 이외의 장점 : 무중단 배포
로드밸런싱을 통해 무중단 서비스와 배포가 가능해집니다.
- 서버는 갑자기 다운될 수도 있고, 배포를 하게되면 서버가 다운이됩니다. 인프라를 한번이라도 경험하신 분들은 다 아실겁니다.
- 당연스럽게도 여러 대의 서버로 나누게 되면 하나의 서버가 다운되어도 실제 클라이언트는 알 수 없습니다.
로드밸런싱의 종류
1. 하드웨어에서의 로드밸런싱
로드밸런서의 종류는 네트워크 계층의 7 Layer 를 기준으로 나누어져있다고 합니다. 저희는 이중에 L4, L7 정도만 알고 넘어갑시다.
L4 : Transport Layer, 그러니까 IP와 Port 레벨에서 로드 밸런싱하는 것
ex) 예를들어 http: //msung99.velog.io 에 접근시 서버 A와 B로 로드 밸런싱을 해주는것이다.(나눠줌)
어떤 사이트로 들어갔을 때 우리가 80번 포트로 접근을 하게되죠. 이를 그냥 서버 A와 B로 요청을 고르게 나눠주는 것이다. 이게바로 L4 로드밸런서입니다.
L7 : 어플리케이션 레벨에서 로드밸런싱을 하는것이다.
ex) 예를들어 http: //msung99.velog.io 에 접근시 "http: //msung99.velog.io" URL의 뒤에다 무엇을 붙이는가에 따라서, 혹은 Query Param 에 따라서 그 애플리케이션을 요청하는 방법에 따라서 어떤 서버로 로드밸런싱을 할지 결정하는게 L7이다.
2. 소프트웨어에서의 로드밸런싱 : Reverse Proxy
이 방식은 기본적으로 Reverse Proxy 를 기반으로 동작합니다.
Reverse Proxy 는 로드밸런싱만을 위해 개발된 프로그램이 아니기 때문에 기본적인 로드밸런싱의 기능만이 있지만 그만큼 비용적으로 저렴하고 구축이 쉽다는 장점이 있다.
- Reverse Proxy 의 로드밸런싱은 Nginx, HAProxy 등으로 기능 구현이 가능합니다. 이들은 추후 포스팅으로 조만간 다루어볼까 합니다.
.

좋은글 잘보고갑니다 👍👍