
이번에 하게 된 졸업 프로젝트에서 중요한 핵심 기술 중 하나인 NLP 부분을 맡게 되었다. 동화 데이터set에서 명사, 어근을 KoNLPy로 추출하고 "text rank"에 input으로 넣어 KoNLPy에서 추출한 단어 중 빈도 수, 맥락 면에서의 중요도를 고려하여 가중치가 설정된다.
이 부분에서 내가 맡은 부분은 KoNLPy에 동화 데이터set을 input으로 넣고 명사 및 어근만 추출해 내는 것!
KoNLPy란?
'한국어 정보처리를 위한 파이썬 패키지'
이렇게만 보면 감이 안 올 수 있는데 NLP에 대해 먼저 설명을 한다면 NLP란 Natural Language Processing 으로 우리 말로는 '자연어 처리'. 컴퓨터를 이용해서 사람의 자연어에서 의미있는 정보를 컴퓨터로 분석, 처리하는 기술이다.
우리가 흔히 아는 애플의 시리, 구글 번역기 등이 대표적인 자연어 처리 기술의 응용 사례이다.
KoNLPy는 한국어 텍스트를 이용하여 기초적인 NLP 작업을 수행하는데 도움을 주는 패키지이다. 우리 팀은 한글 동화를 대상으로 진행 중이므로 NLP 중 KoNLPy 패키지를 선택하게 되었다.
KoNLPy 사용해보기
사용하고 있는 OS에 따라 좀 다른데 나는 맥을 사용하고 있기 때문에 맥 버전으로 설명하려고 한다.
1. KoNLPy 설치하기
$ python3 -m pip install --upgrade pip
$ python3 -m pip install konlpy # Python 3.x별 거 없이 이 코드만 입력하면 설치가 된다.
..라고 생각했는데..
설치는 된다. 설치는 되는데.. 왜 vscode에서는 실행하려고 하면.. 이건 밑에 설명하겠다.
2. KoNLPy 사용하기
KoNLPy에는 품사 태깅을 하기 위한 옵션이 여러 개 있다. 이 옵션들은 모두 문구를 입력받아 태깅된 형태소를 출력하는 동일한 입출력 구조를 가진다.
1) Hannanum class
2) Kkma class
3) Komoran class
4) Mecab class (** 윈도우 지원 안됨!)
5) Okt class이 중에 Hannanum과 Kkma가 적절해보여서 둘 중 어떤 클래스가 성능면에서 뛰어난 지 알아보았다.
1) 로딩 시간: 사전 로딩을 포함하여 클래스를 로딩하는 시간.
- Kkma: 5.6988 secs
- Hannanum: 0.6591 secs
2) 실행시간: 10만 문자의 문서를 대상으로 각 클래스의 pos 메소드를 실행하는데 소요되는 시간.
- Kkma: 35.7163 secs
- Hannanum: 8.8251 secs사실 이건 내가 직접 해 본 것은 아니고 이미 성능 비교를 해줬길래 참고했다.
성능비교 참고 사이트
실제로 이 깃허브에 있는 코드로 직접 성능 비교를 해 볼 수 있다!
Hannanum과 Kkma 로딩 및 실행 시간 차이가 꽤 나서 Hannanum을 써야 할까 했는데 성능을 비교해보니 고민이 되었다.
- 띄어쓰기가 제대로 되지 않은 문구의 경우, 예를 들어 "아버지가방에들어가신다." 를 분석하게 해보았다.
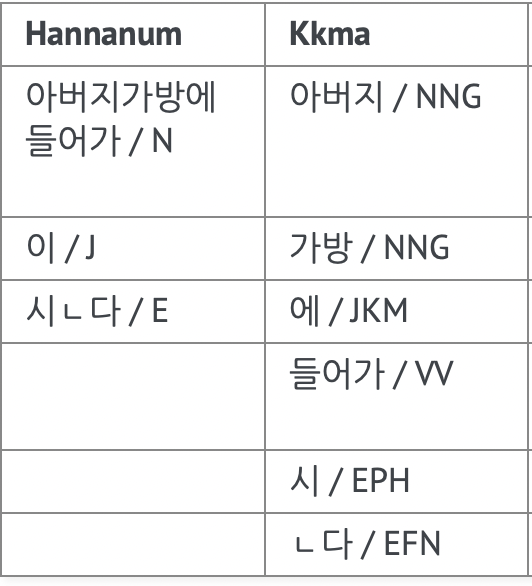
-> 둘 모두 완벽하진 않지만, Kkma가 보다 높은 정확도를 보인다.
- "하늘을 나는 자동차"에서 '나'는 '날다'의 어근에서 ㄹ이 탈락된 형태이다. 이를 분석할 수 있는 지를 보았다.
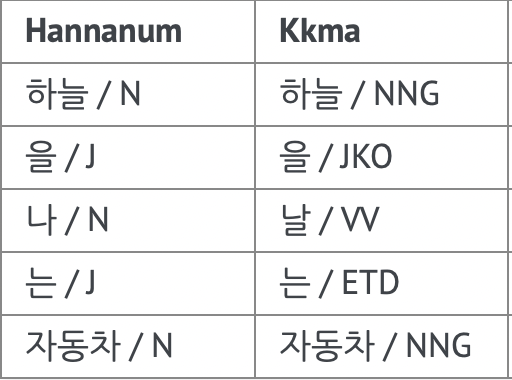
-> Hannanum의 경우 '나'를 명사로 분석했고 Kkma는 어근으로 분석한 것을 알 수 있다.
확실히 Kkma가 Hannanum 보다 형태소 분석 성능이 좋은 것을 알 수 있다.
각 클래스의 메소드에 대해 알아보았다.
두 품사 태깅 클래스 모두 코드가 비슷하다.
1) Hannanum
>>> from konlpy.tag import Hannanum
>>> hannanum = Hannanum()
>>> print(hannanum.morphs(u'롯데마트의 흑마늘 양념 치킨이 논란이 되고 있다.'))
>>> print(hannanum.nouns(u'다람쥐 헌 쳇바퀴에 타고파'))
>>> print(hannanum.pos(u'웃으면 더 행복합니다!'))- morphs 메소드의 경우
['롯데마트', '의', '흑마늘', '양념', '치킨', '이', '논란', '이', '되', '고', '있', '다', '.']
이렇게 단어를 분리해준다. - nouns 메소드의 경우
['다람쥐', '쳇바퀴', '타고파']
이렇게 명사만 출력한다. - pos 메소드는
[('웃', 'P'), ('으면', 'E'), ('더', 'M'), ('행복', 'N'), ('하', 'X'), ('ㅂ니다', 'E'), ('!', 'S')]
이런 식으로 형태소 별로 분리하고 해당 형태소와 함께 출력한다.
2) Kkma
>>> from konlpy.tag import Kkma
>>> kkma = Kkma()
>>> print(kkma.morphs(u'공부를 하면할수록 모르는게 많다는 것을 알게 됩니다.'))
>>> print(kkma.nouns(u'대학에서 DB, 통계학, 이산수학 등을 배웠지만...'))
>>> print(kkma.pos(u'다 까먹어버렸네요?ㅋㅋ'))
>>> print(kkma.sentences(u'그래도 계속 공부합니다. 재밌으니까!'))- morphs 메소드의 경우
['공부', '를', '하', '면', '하', 'ㄹ수록', '모르', '는', '것', '이', '많', '다는', '것', '을', '알', '게', '되', 'ㅂ니다', '.']
이렇게 단어를 분리해준다. - nouns 메소드는
['대학', '통계학', '이산', '이산수학', '수학', '등']
이렇게 명사만 출력한다. - pos 메소드는
[('다', 'MAG'), ('까먹', 'VV'), ('어', 'ECD'), ('버리', 'VXV'), ('었', 'EPT'), ('네요', 'EFN'), ('?', 'SF'), ('ㅋㅋ', 'EMO')]
이렇게 형태소 별로 분리하고 해당 형태소와 함께 출력한다. - sentences 메소드의 경우
['그래도 계속 공부합니다.', '재밌으니까!']
이렇게 문장 별로 분리하여 출력한다.
매우 간단하다.
우리 팀의 경우 새로운 장면을 만들어내기 위해 다양한 단어가 필요한 것이므로 '었', '는', 'ㅂ니다' 등 어미, 조사 같은 것들은 제외하고, 명사나 어근만을 추출해야 하기 때문에 pos 메소드에서 파라미터를 조정하여 원하는 결과만을 출력하고자 했다.
from konlpy.tag import Kkma
kkma = Kkma()
words = kkma.pos(u'이것은 예시입니다. 생각보다 쉽다. 블로그를 쓰는 것은 조금 어렵다. 나는 노래를 듣는다.', flatten=True, join=True)
words = [w for w in words if ('/NNG' in w or '/VV' in w or '/VA' in w)] # NNG와 VV, VA 형태소인 것만 출력
print(words)**Hannanum의 경우 kkma 대신 hannanum 이라고 쓰면 된다.
원하는 문장을 넣고, flatten과 join 파라미터 값을 수정해주었다.
- flatten의 default 값은 True로 어절마다 끊기지 않고 결과 값이 한 줄로 쭉 출력된다. False로 값을 바꾸면 어절마다 줄이 바뀌어 출력된다.
- join의 default 값은 False로 분리된 문장과 해당 형태소가 따로 출력이 된다. True로 값을 바꾸면 분리된 문장과 해당 형태소가 같이 출력된다.
우리 팀의 경우 정제된 명사와 어근을 "text rank"에 input으로 넣어줘야 하기 때문에 팀원의 요청대로 분리된 문장과 해당 형태소가 같이 출력이 되도록 설정해줬다. 따라서 위의 코드를 실행해보면
['예시/NNG', '생각/NNG', '쉽/VA', '블/VV', '로그/NNG', '쓰/VV', '어렵/VA', '노래/NNG', '듣/VV']가 출력이 된다.
원하는 output 형태대로 메소드를 사용하고 해당 메소드에서 파라미터를 조정해서 결과를 얻으면 된다.
사실 코드는 정말 간단한데 이게 vscode에서 설치를 하고 실행을 하려고 하면 '~~모듈이 설치가 안되어있다' 부터 해서 '[Errno 0] JVM DLL not found' 이런 에러도 발생한다. 하도 에러가 많이 발생해서 일단 KoNLPy를 검증하기 위해 colab에서 코드를 실행해봤는데 코랩에서는 아무런 문제 없이 아~주 잘된다.ㅠㅠ
코랩에서 실행 할 때는
$ python3 -m pip install --upgrade pip
$ python3 -m pip install konlpy # Python 3.x이 부분을 그냥
pip install konlpy으로만 하면 되고 나머지는 위에 설명한대로 적으면 된다.
사실 동화 데이터 set에서 명사와 어근으로 정제하는 과정이라 굳이 vscode를 이용하지 않아도 되긴 할 것 같지만 그래도 vscode에서 실행하는 과정에서 발생하는 오류, 해결 방법, 과정도 블로그에 작성할 예정이다. 무엇이 문제인건지, m1이라 그런건지(라고 믿고 싶음..) 후에 작성하겠다.
생각보다 kkma가 시간이 많이 걸려서 성능이 조금 떨어져도 hannanum을 사용해야 할 지, 시간이 조금 더 걸려도 kkma를 사용해야 할 지에 대해서는 팀원들과 논의를 거친 후 결정을 할 것 같다.

잘 읽었어요~ 김현수교수