정규화와 역정규화: 데이터베이스 설계의 핵심
데이터베이스 설계에서 정규화와 역정규화는 중요한 개념입니다. 이 글에서는 이 두 가지 개념의 목적과 원리를 다루고, 각 기법이 어떻게 실제 환경에서 활용되는지 설명하겠습니다. 또한, 실제 데이터베이스 성능 테스트를 통해 정규화와 역정규화의 성능 차이를 살펴보겠습니다.
1. 정규화
💡 중복 데이터를 줄이고, 데이터의 무결성을 유지하기 위해 데이터를 체계적으로 분리하는 프로세스
1.1 목적
- 중복 최소화: 데이터베이스 크기 감소
- 데이터 무결성 유지: 수정 시 다른 곳에 영향 없음
- 이상 현상 방지: CRUD 작업의 비효율성 제거
1.2 1NF, 2NF, 3NF
1NF
-
각 컬럼이 원자 값을 가짐
-
잘못된 테이블 (1NF가 아님):
학생 ID 이름 과목 1 홍길동 수학, 영어 -
1NF로 변환:
학생 ID 이름 과목 1 홍길동 수학 1 홍길동 영어
2NF
-
1NF를 만족하면서 부분 함수 종속성 제거
-
예시: 학생이 다수의 과목을 수강할 때
잘못된 테이블 (1NF 상태):
학생 ID 과목 이름 1 수학 홍길동 1 영어 홍길동 2NF로 변환:
학생 테이블:
학생 ID 이름 1 홍길동 수강 과목 테이블:
학생 ID 과목 1 수학 1 영어
- 즉, 2NF는 A<-(-B , C)->D 인 경우에 A<-B, (B,C)-> D와 같이 분리 하는 것을 의미하는 것입니다.
3NF
-
Transitive Dependency 제거
-
잘못된 테이블 (2NF 상태):
학생 ID 이름 학과 학과 위치 1 홍길동 컴퓨터공학과 2층 -
3NF로 변환:
학생 테이블:
학생 ID 이름 학과 ID 1 홍길동 101 학과 테이블:
학과 ID 학과 학과 위치 101 컴퓨터공학과 2층 -
즉 3NF는 A->B->C인 테이블 상황을 A->B와 B->C로 분리하는 것을 의미합니다.
그렇다면 이러한 테이블의 정규화가 항상 효율적인 결과를 가져오는 것일까요??
2. 역정규화(반정규화)
💡 Denormalization attempts to improve read performance at the expense of some write performance. Redundant copies of the data are written in multiple tables to avoid expensive joins.
https://github.com/donnemartin/system-design-primer#denormalization
2.1 Denormalization?
위의 system-design-primer의 git에는 여러 대규모 시스템을 구축하는 방법론을 다루고 있습니다. 이 중 denormalization 파트를 인용하겠습니다.
Once data becomes distributed with techniques such as federation and sharding,
managing joins across data centers further increases complexity.
Denormalization might circumvent the need for such complex joins.
- 이 이야기의 핵심은 데이터가 페더레이션이나 샤딩 같은 기술로 분산되면, 데이터 센터 간의 조인 관리가 더 복잡해진다는 것입니다.
- 이때 역정규화(Denormalization)는 이러한 복잡한 조인의 필요성을 줄이는 방법으로 활용됩니다.
- 즉, Denormalization을 통해 궁극적으로 조인에 들어가는 비용을 줄이는 기법입니다.
그렇다면 실제 조인에 들어가는 비용은 얼마나 될까요?
2.2 배달의 민족의 역정규화 도입 사례
https://www.youtube.com/watch?v=704qQs6KoUk
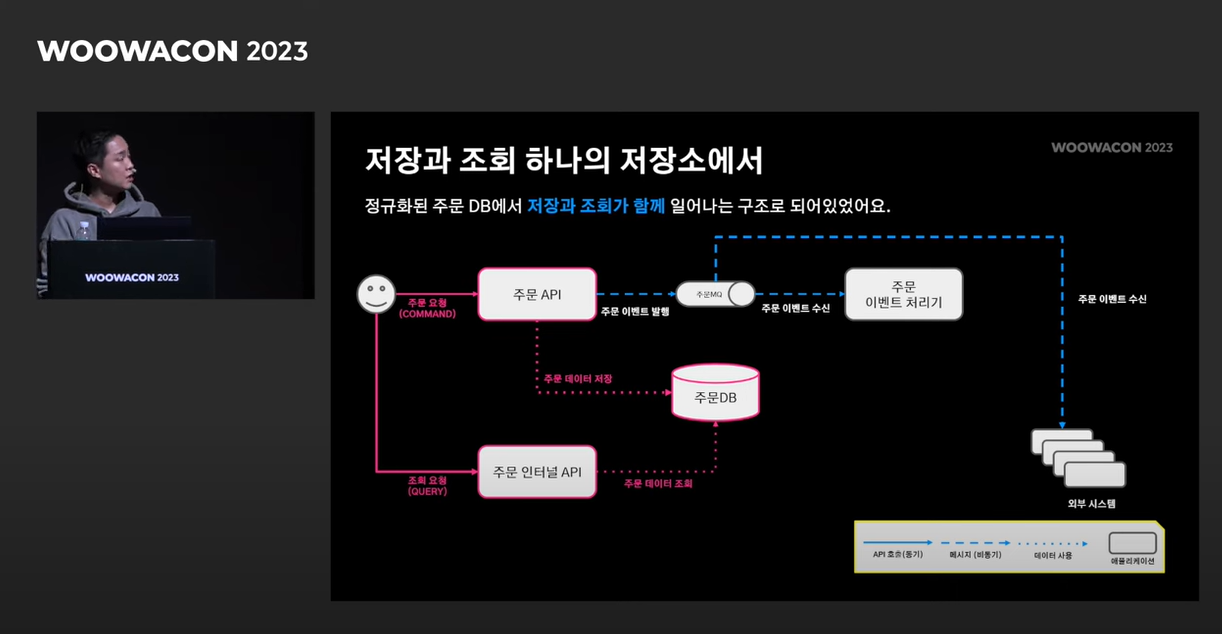
-
배민 같은 경우 위처럼 기존에는 주문 DB에서 데이터를 저장하고 조회하는 작업을 동시에 수행하였습니다.
-
그런데 사용자에게 주문 내역을 보여주어야할 때, db에서 조회해야하는 정보는 무수히 많으며, 이와 관련한 테이블 또한 무수히 많았다고 합니다.
-
조회시 무수히 많은 테이블을 조인연산을 필요로 했고, 이는 성능 저하로 이어지게 되었다고 합니다.
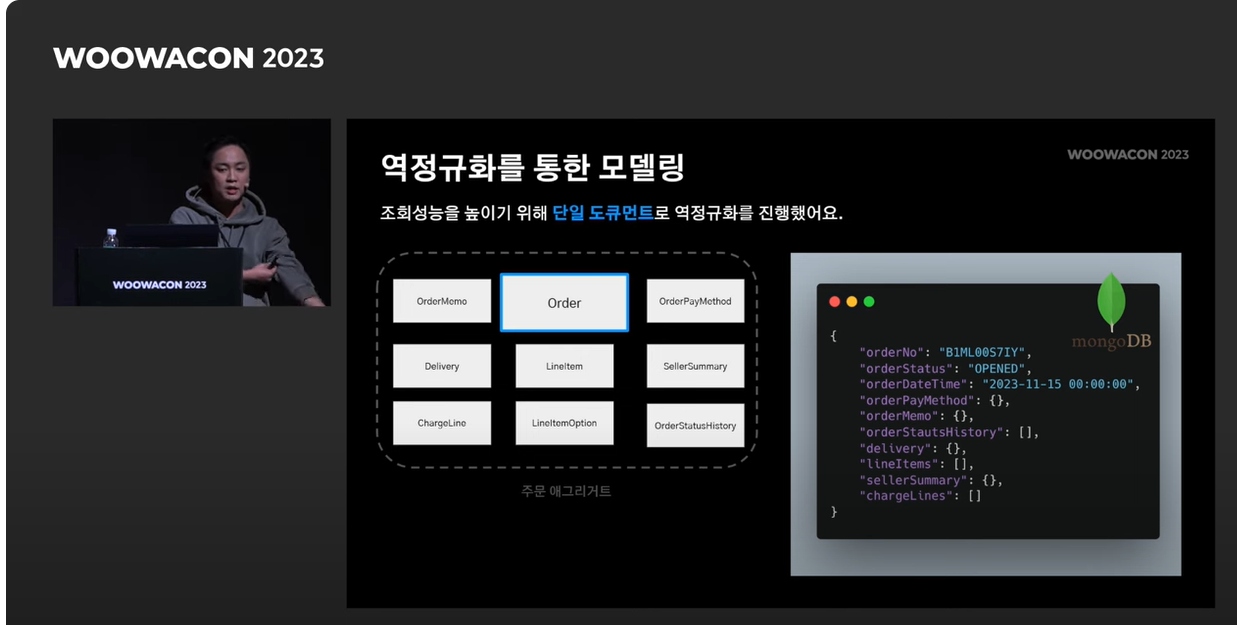
-
배달의 민족은 읽기 전용 MongoDB를 사용해 성능 저하 문제 해결하였다고 합니다.
-
MongoDb를 적용한 workflow는 다음과 같습니다.
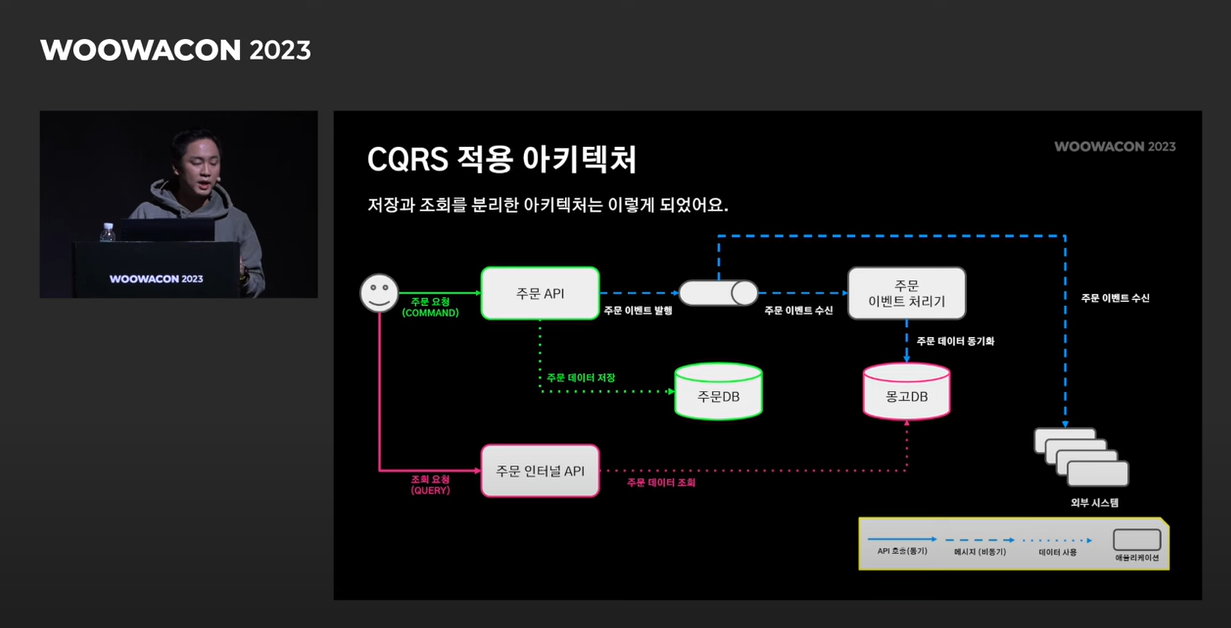
3. CS 관점에서의 JOIN 비용
https://www.oreilly.com/library/view/mongodb-applied-design/9781449340056/ch01.html#FIG1
- 보편적인 데이터베이스는 데이터를 디스크에 저장합니다.
- DBMS는 적절한 데이터를 디스크에서 읽어와 데이터를 보여주는 형태입니다.
- 따라서 join도 디스크의 접근 관점에서 볼 수 있습니다.
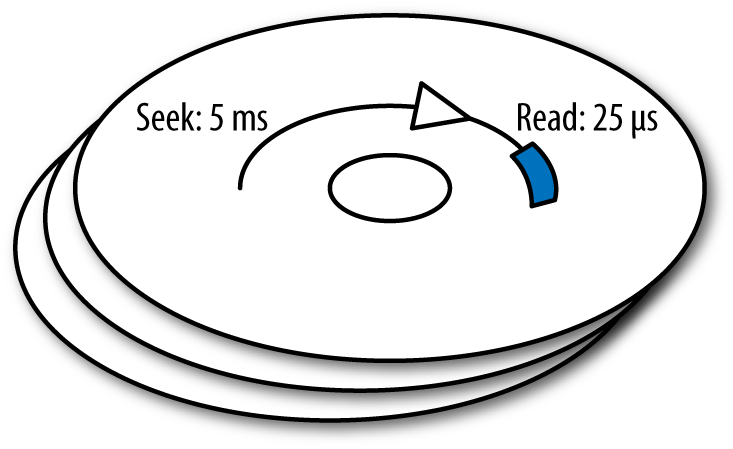
mongodb-applied-design의 내용을 인용하겠습니다.The seek takes well over 99% of the time spent reading a row.
When it comes to disk access, random seeks are the enemy.
The reason why this is so important in this context is because JOINs typically require random seeks.
-
디스크에서 읽는데 전체 걸리는 시간 중 탐색시간이 제일 오래 걸립니다.(99%)
-
JOIN 연산은 여러 테이블에서 데이터를 결합해야 하므로, 디스크에서 여러 위치로 이동해야 하는 random seek 이 많이 발생하게 됩니다.
-
random seek의 반대로 순차 접근이 있는데 순차 접근은 디스크의 데이터를 연속된 순서로 읽기 때문에, 디스크 헤드가 한 번의 이동으로 여러 데이터를 처리할 수 있어 훨씬 빠릅니다.
-
random seek 는 여러 위치로 헤드를 이동시키는 과정이 자주 발생하는 반면, 순차 접근은 디스크의 연속된 데이터 블록을 읽기 때문에 물리적인 헤드 이동이 거의 없거나 최소화됩니다.
결과적으로 순차 접근은 탐색 시간 및 성능 면에서 더 효율적입니다. -
이러한 random seek가 많이발생 하므로 결국 오버헤드가 발생하는 경우가 존재하며,결과적으로 성능은 떨어지게 됩니다.
4. MySQL 환경에서의 쿼리 성능 테스트
4.1 테스트 시나리오
1:N 관계에서 정규화된 테이블과 역정규화된 테이블 간의 쿼리 성능을 비교했습니다. 데이터셋의 크기 및 테이블의 갯수 에 따라 성능 차이가 발생하는지를 측정했습니다.
4.2 데이터 10개일 때
- 데이터가 10개인 student와 student와 student_id로 1:N 매핑 되어 있는 60개의 데이터를 가지는 subject테이블이 있습니다.
- 또한 이 두 개의 테이블을 합쳐 둔 student_subject_combined를 생성합니다.
- name=Jack Turner가 듣는 subject_name을 구한다고 해봅시다.
SHOW PROFILES;를 이용.

데이터 셋이 얼마 안돼서 그런가 0.00041725 0.00047800로 약소한 차이가 안납니다.
4.3 데이터 100개 및 3개의 테이블 관계
- 학교(School), 반(Class), 학생(Student) 테이블 1:N 관계입니다.
- 이 세 테이블을 합친 테이블을 combined_info라고합니다
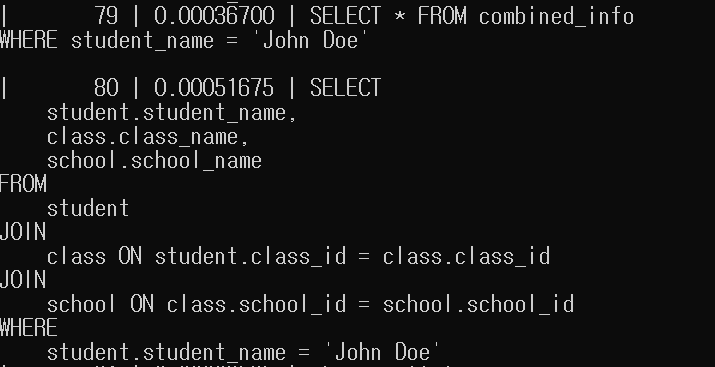
- 시간이 0.00036700 0.00051675로 위보다는 차이가 많이 남을 알 수 있습니다.
4.4 데이터 50개 및 5개의 테이블 관계
- 학교(School), 반(Class), 학생(Student), 수업(Course), 성적(Grade) 테이블 1:N 관계입니다.
- 이 세 테이블을 합친 테이블을 combined_info
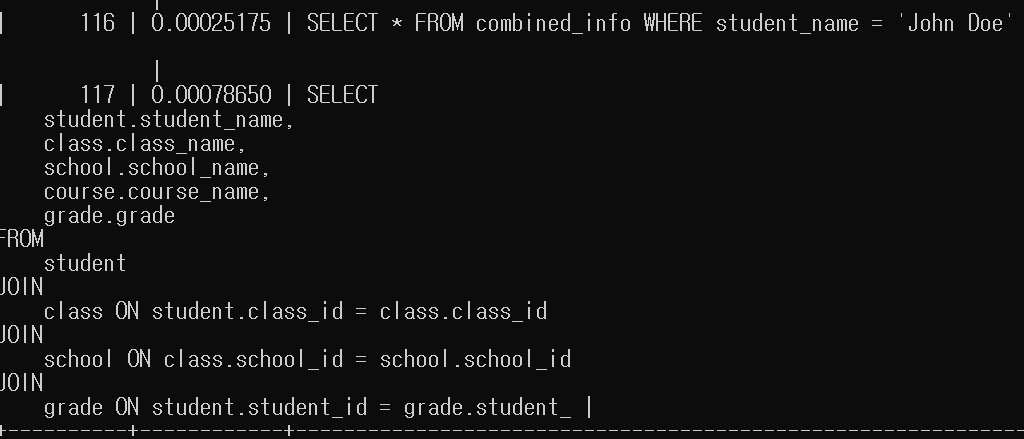
- JOIN으로 조회시 0.00078650, 합쳐진 테이블(combined_info)로 조회시에는 0.00025175로 성능 차이 큰 것을 확인 할 수 있습니다.
4.5 테스트 전체 결과
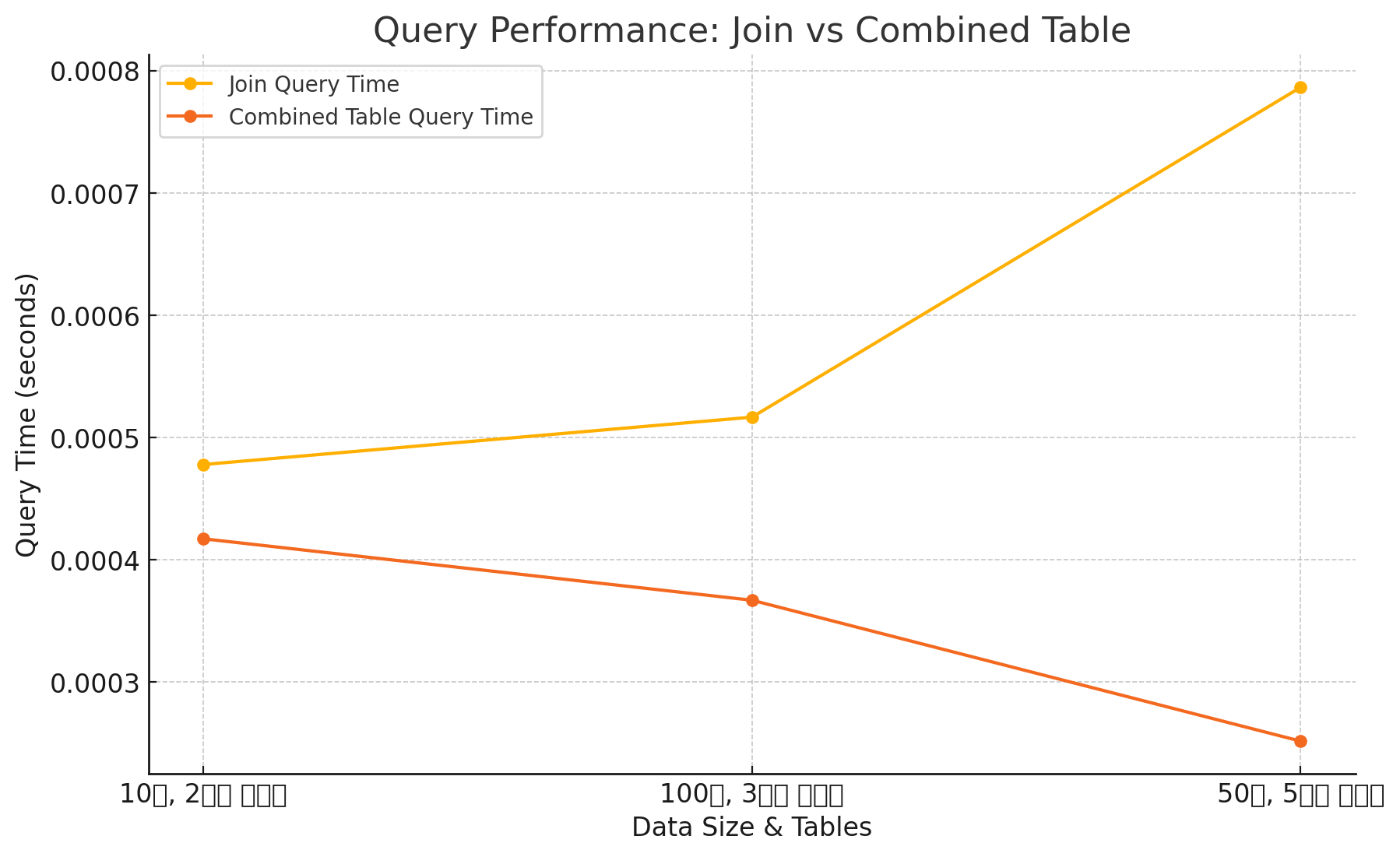
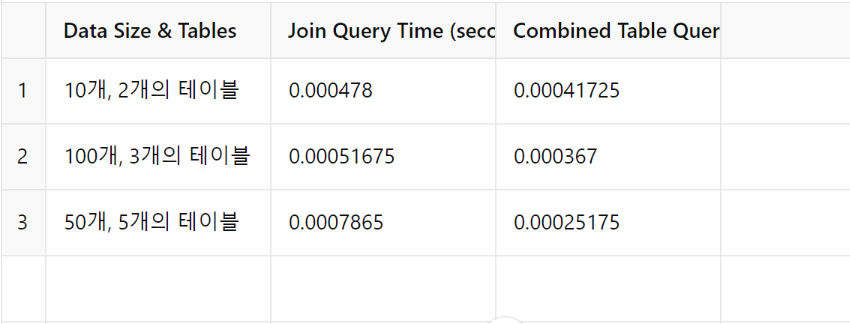
위의 그래프와 도표를 통해 조인 쿼리와 합쳐진 테이블 쿼리의 성능 차이를 확인할 수 있습니다.
-
데이터 크기가 커질수록 조인 쿼리 시간이 점점 더 길어지는 반면, 합쳐진 테이블을 사용하는 경우 쿼리 시간이 더 짧게 유지됩니다.
-
이를 통해 데이터 크기와 테이블 수가 증가할 때, 역정규화된 테이블을 사용하는 것이 성능 향상에 유리하다는 것을 알 수 있습니다.
결론
정규화는 데이터의 중복을 최소화하고 데이터 무결성을 유지하는 데 중요한 기법입니다. 하지만 조인 연산의 성능 저하 문제를 해결하기 위해, 상황에 따라 역정규화가 필요할 수 있습니다. 또한 위의 테스트 결과에 따라서 많은 테이블을 join하여 사용할 때는 역정규화가 성능 향상에 더욱 기여할 수 있음을 알 수 있습니다. 실제 데이터베이스 설계 및 데이터베이스를 선택함에 있어서, join의 성능 저하부분을 고려해야함을 어느정도는 알게 되었습니다.
이 글을 통해 정규화와 역정규화의 개념을 이해하고, 실제 시스템 설계에서의 적용 방법을 학습할 수 있었습니다.
