(시리즈2) 쿠버네티스 클러스터에서 작업 유형 기반 오토스케일링 기준 선택과 성능 분석 (1) - 오토스케일링, 시스템 구성
쿠버네티스는 분산 시스템을 탄력적으로 실행하기 위한 프레임워크로서 그 핵심 역할 중 하나는 시스템 자원들의 메트릭 값을 모니터링하여 쿠버네티스 최소 자원 관리 단위인 파드 수를 자동으로 조절하는 오토스케일링 기능입니다. 하지만 쿠버네티스 기본 오토스케일러는 파드들의 CPU 평균 사용량을 오토스케일링 기준으로 삼고 있어 CPU를 많이 사용하지 않는 서비스의 경우 작업 특성에 맞춰 오토스케일링이 잘 되지 않는다는 문제가 있습니다.
이를 보완하기 위해 쿠버네티스 오토스케일러는 오토스케일링 기준을 바꿀 수 있는 사용자 정의 메트릭 기능을 제공합니다. 그 실효성을 평가하기 위해 쿠버네티스 클러스터에 CPU, IO 집약적인 웹 어플리케이션 API가 배포된 상황에서 오토스케일링 기준을 변경하며 실험을 수행해 보았습니다.

오토스케일링이란?
정의
쿠버네티스와 같은 컨테이너 오케스트레이션 툴은 시스템 사용량에 따라 동적으로 컨테이너의 숫자를 조절하는데, 이 기능을 오토스케일링이라 합니다. 따라서 오토스케일링 기능이 시스템 사용량을 잘 반영하지 못한다면 자원 부족으로 인해 사용자의 요청에 응답이 늦어지며, 심할 경우 SLA 위반으로 이어질 수 있습니다.
종류
출처 : cloudskew
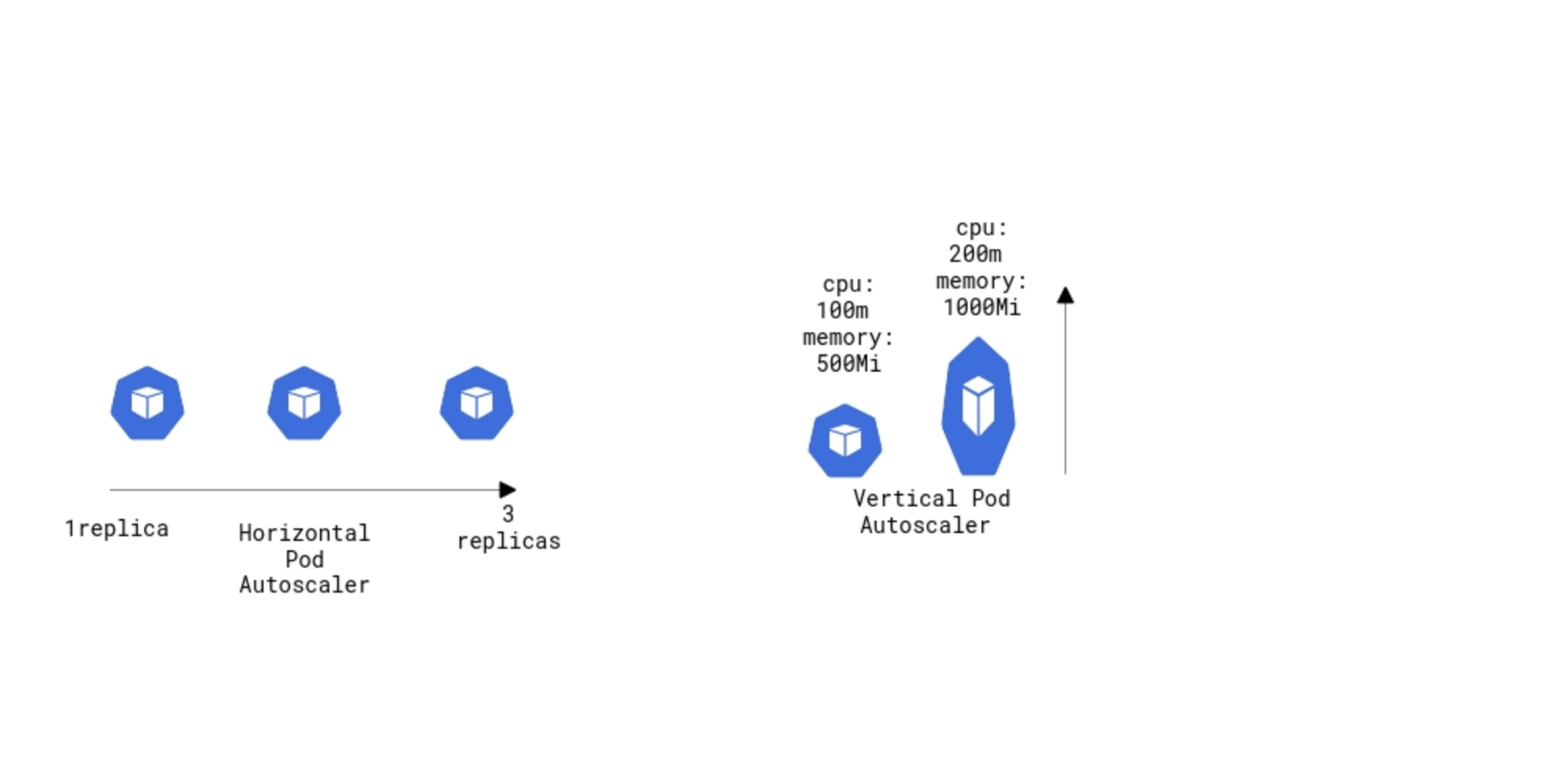
쿠버네티스에서 오토스케일링은 크게 HPA, VPA가 있습니다.
- HPA(Horizontal Pod Autoscaler) : 클러스터의 Pod 수를 조절하여 자원 할당량을 조절하는 방법입니다.
- VPA(Vertical Pod Autoscaler) : 기존 Pod에 CPU나 메모리를 재할당하여 자원 할당량을 조절하는 방법입니다. 자원 재 할당시 시스템을 재시작해야 하는 단점이 있습니다.
본 글에서는 HPA에 대해서만 알아보도록 하겠습니다.
쿠버네티스에서의 HPA
위 정의대로라면 오토스케일링을 할 기준(메트릭)을 뭘로 정할 것이냐에 대한 의문이 들 것입니다. 현재 기본 쿠버네티스 오토스케일러는 CPU 평균 사용량만을 오토스케일링 기준으로 삼고 있어 자원 이용률 향상, SLA 충족 등을 위해서 어플리케이션 특성 및 상황에 맞는 오토스케일링 기법을 적용해야 한다는 필요성이 꾸준히 제기되고 있습니다.
쿠버네티스 Horizontal Pod Autoscaler(HPA) 최신 버전에서는 오토스케일링 기준을 사용자 정의 메트릭으로 설정하는 기능을 제공하며, 사용자 정의 메트릭을 수집하는 대표적인 오픈소스로 프로메테우스가 있습니다.
메트릭의 정의와 그 종류
메트릭이란 시스템에서 수집할 수 있는 모든 종류의 지표를 말합니다. 쿠버네티스는 이 메트릭을 이용해서 오토스케일링 지표로 삼거나 운영자가 상태를 모니터링할 수 있도록 제공합니다. 그 종류에는 크게 시스템 메트릭과 서비스 메트릭이 있습니다.
- system metrics : 노드나 컨테이너의 CPU, 메모리 사용량 같은 시스템 관련 메트릭
- 코어 메트릭 : 쿠버네티스 내부 컴포넌트들이 사용하는 메트릭(HPA, kubectl top)
- 비코어 메트릭 : 쿠버네티스가 직접 사용하지 않는 다른 시스템 메트릭
- service metrics : 애플리케이션을 모니터링할 때 필요한 메트릭
- 쿠버네티스 인프라용 컨테이너에서 수집하는 메트릭 : 클러스터를 관리할 때 참고해서 사용할 수 있음 ( 웹 서버 응답 시간, 500에러 갯수 등)
- 사용자 애플리케이션에서 수집하는 메트릭
쿠버네티스 메트릭 관련 컴포넌트
metrics-server
metrics-server 는 쿠버네티스 클러스터 각 노드에 설치된 kublet을 통해서 노드나 컨테이너의 CPU나 메모리 사용량 같은 코어 시스템 메트릭을 수집합니다. kubeadm을 이용한 클러스터 구성시 default로 제공되지는 않지만, kubernetes-sigs(special interest groups) 에서 제공하며 사실상 오토스케일링 기본 모듈입니다.
kubernetes-sigs/metrics-server
cadvisor
cAdvisor란 쿠버네티스에서 사용하는 기본적인 모니터링 에이전트로 모든 노드에 설치되서 노드에 대한 정보와 포드 (컨테이너) 에 대한 지표를 수집합니다.
프로메테우스
Prometheus는 SoundCloud에서 만든 오픈소스로 Prometheus는 모니터링과 알림 시스템을 제공하는 툴킷입니다. 여기서 수집한 메트릭은 모니터링 뿐만 아니라 오토스케일링 메트릭으로 사용할 수 있고, 본 실험에서는 그 방법을 이용해 볼 것입니다.
prometheus/prometheus
그래서 실험에서 선택할 메트릭은?🤔
본 실험은 쿠버네티스 클러스터 상에서 CPU, IO 집약적인 두 개의 node.js REST API로 들어오는 요청 수가 변화하는 상황에서 실험을 진행할 것입니다. 위 환경에서 오토스케일링 기준 메트릭을 각각 파드들의 평균 CPU 사용량과 컨테이너들의 평균 write byte 수로 놓고, 어플리케이션 작업 유형별로 오토스케일링 기준을 바꿨을 때 그 성능을 비교할 예정입니다.
시스템 구성
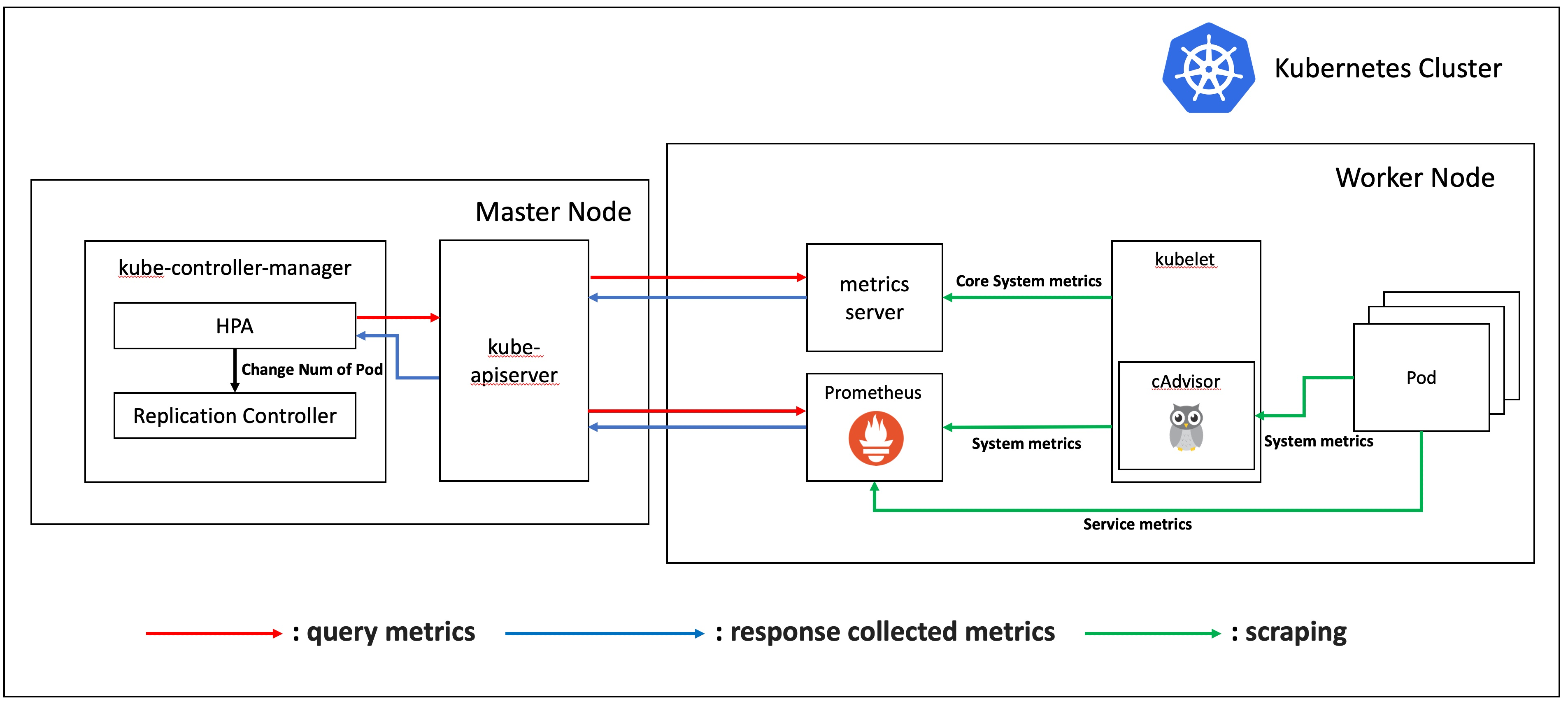
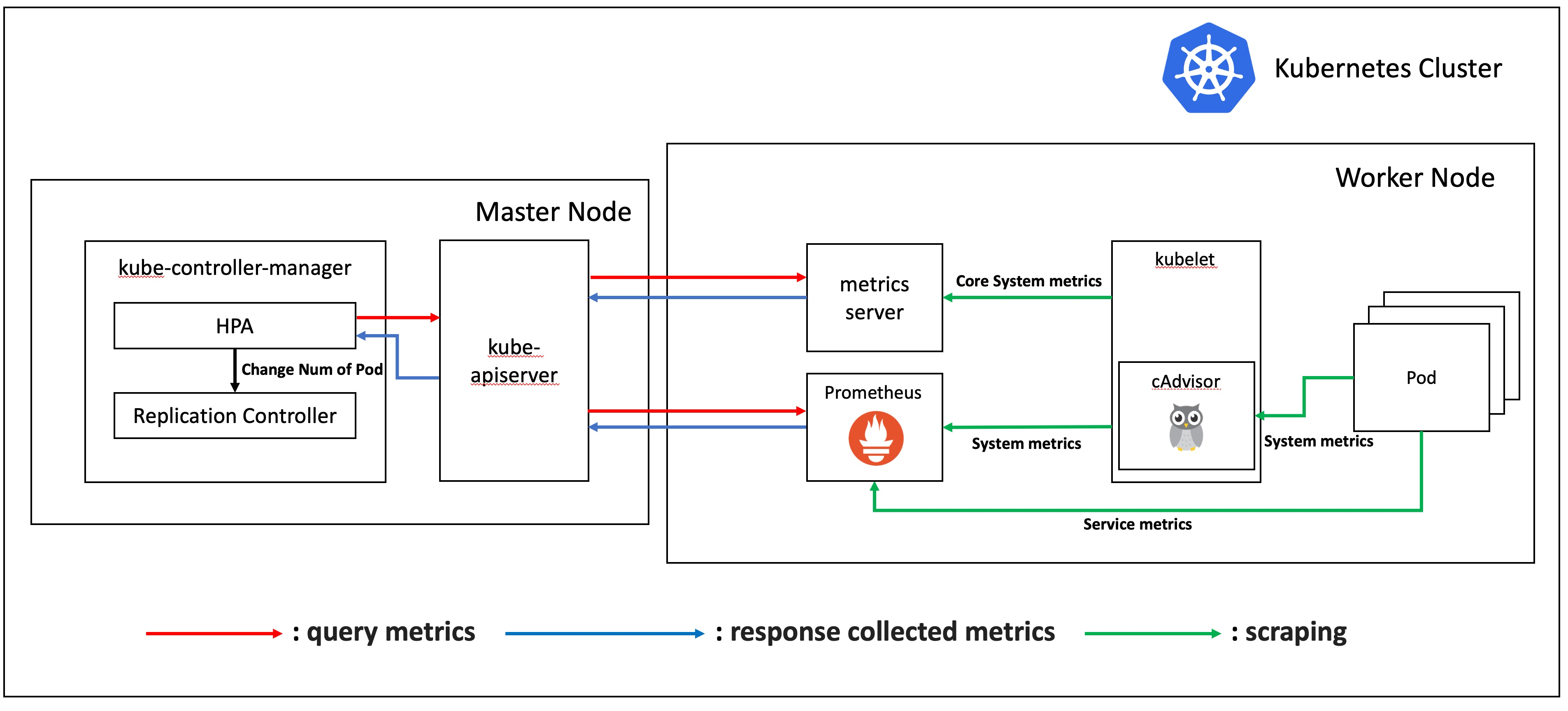
구성한 쿠버네티스 클러스터의 구성도는 위 그림과 같습니다. worker 노드가 하나 더 있으나 내부 구조는 동일하기에 표현하지 않았습니다. 위 그림의 구성 요소를 간단히 설명드리면 다음과 같습니다. (이해의 편의를 위해 prometheus-adapter와 metrics aggregator 등의 몇몇 모듈을 제외한 점 참고 부탁드립니다.)
-
kube-controller-manager : 컨트롤러 각각을 실행하는 컴포넌트
- HPA : 주기적으로 실행하면서 설정된 HPA의 상태를 확인하는 컴포넌트
- Replication Controller : 주기적으로 실행하면서 지정된 수의 파드 레플리카가 실행 중임을 보장하는 컴포넌트
-
metrics server : 각 노드에 설치된 kublet을 통해서 노드나 컨테이너의 CPU나 메모리 사용량 같은 코어 시스템 메트릭을 수집한다.
-
prometheus : 프로메테우스는 메트릭 기반의 오픈소스 모니터링 시스템이다.
-
kubelet : 클러스터 안 모든 노드에서 실행되면서, 파드 컨테이너들의 실행을 직접 관리함.
-
pod : 쿠버네티스에서 컨테이너를 관리하는 최소 단위. 여러 개의 컨테이너로 구성될 수 있음
HPA는 주기적으로 kube-apiserver에 metric을 요청하고, kube-apiserver는 메트릭 수집 장치에서 해당 요청을 조회합니다. 메트릭 수집 장치(metrics-server, prometheus) 는 일정 간격마다 메트릭을 수집해 보관하고 있으므로 언제나 조회가 가능합니다. 현재 메트릭을 반환받은 HPA는 desired state와 비교하고, scale-out 이 필요하다고 판단될 시 replication controller 에게 pod 갯수를 변경하라는 지시를 보냅니다.
이 때 kube-apiserver는 metrics-server와 prometheus 두 개의 모듈에서 데이터를 받는 것을 보실 수 있습니다. 이 두 개의 파이프라인을 리소스 메트릭 파이프라인(Resource Metrics Pipeline)과 완전한 메트릭 파이프라인(Full Metrics Pipeline) 이라고 합니다.
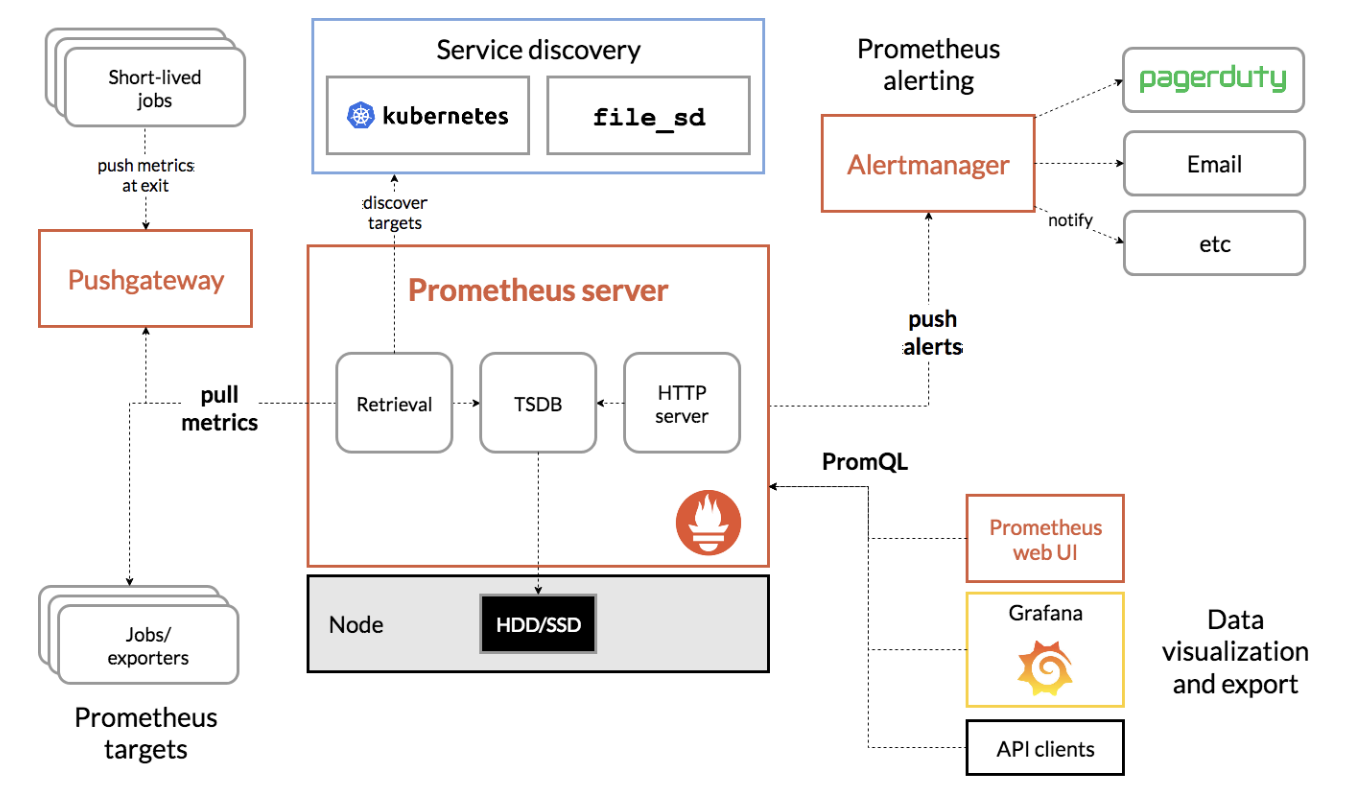
리소스 메트릭 파이프라인은 쿠버네티스의 컴포넌트가 활용하는 메트릭의 흐름입니다. 쿠버네티스는 수집된 정보를 kubectl top 명령으로 노출해주고, 스케일링이 설정되어 있다면 자동 스케일링(Autoscaling)에 활용합니다. [그림 6]은 metrics-server를 통해 수집된 모니터링 정보를 메모리에 저장하고 API 서버를 통해 노출해 kubectl top, scheduler, HPA와 같은 오브젝트에서 사용된다는 것을 나타냅니다. 쿠버네티스의 일부 기능은 Metric Server의 정보를 사용합니다.
다만, 이러한 정보는 순간의 정보를 가지고 있고, 다양한 정보를 수집하지 않으며, 장시간 저장하지 않습니다. 이로 인해 두 번째 흐름인 완전한 메트릭 파이프라인이 필요합니다. 이는 기본 메트릭뿐만 아니라 다양한 메트릭을 수집하고, 이를 스토리지에 저장합니다. 완전한 메트릭 파이프라인 자체는 쿠버네티스에서 직접적으로 관여하지 않으며, CNCF 프로젝트 중 하나인 프로메테우스를 활용할 수 있습니다. 프로메테우스를 활용한 경우의 흐름은 아래 그림과 같으며, 프로메테우스를 통해 서비스 디스커버리(Service discovery), 메트릭 수집(Retrieval) 및 시계열 데이터베이스(TSDB, Time Series Database)를 통한 저장, 쿼리 엔진을 통한 PromQL 사용과 Alertmanager를 통한 통보가 가능합니다[1].
다음 글에서는 HPA를 테스트할 REST API 어플리케이션을 구성해보고 과부하를 주기 위한 툴 gatling에 대해 알아보도록 하겠습니다.
잘못된 부분이 있는 경우 댓글로 남겨주시면 적극 반영하겠습니다! 감사합니다.

참고문헌
[1] https://www.samsungsds.com/kr/insights/kubernetes_monitoring.html
