(시리즈2) 쿠버네티스 클러스터에서 작업 유형 기반 오토스케일링 기준 선택과 성능 분석 (4) - HPA, Deployment, Service 설정 및 실험 수행
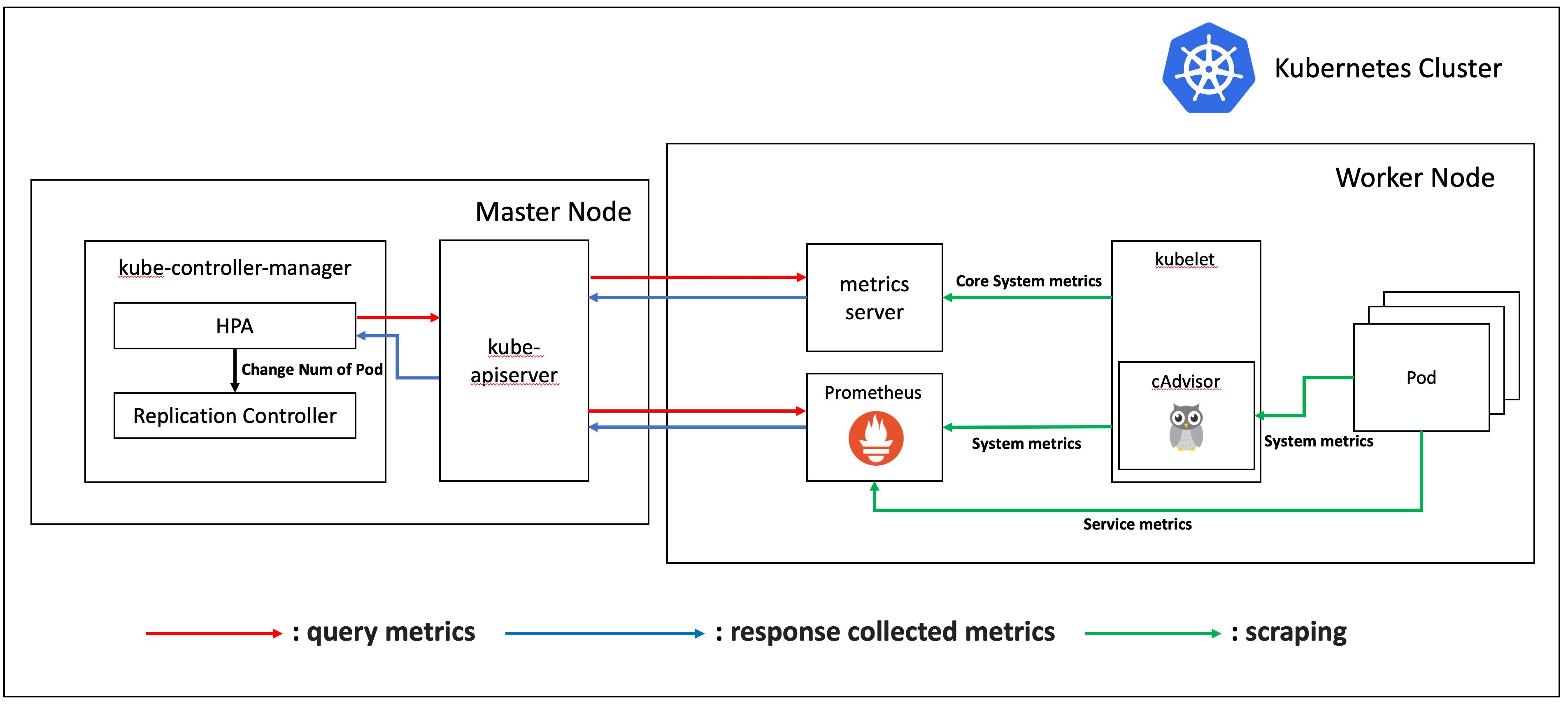
이번 글에서는 실제 실험 시나리오를 구상해보고, 시나리오에 따라 실험을 진행해 보겠습니다. 원래 순서라면 웹 서버 요청 툴에 대해 알아봐야 하지만, 파이썬으로 그래프 그린 것과 함께 묶어서 다음 글에서 정리하도록 하겠습니다.

실험 설계👨💻
서버 구성
서버는 node.js express를 이용해서 제작하였으며, GET 요청을 받으면 100,000번 난수들의 곱 연산을 수행하는 CPU 집약적 API와 GET 요청을 받으면 약 50MB 크기의 파일을 복사해서 저장하는 IO 집약적 API를 각각 구현하였습니다.
요청 횟수 구성
웹 부하테스트 도구 gatling을 이용하여 약 30분간 초당 요청횟수가 증감하는 상황이 반복되도록 부하 정도를 조절하였습니다. 첫째, 둘째 실험은 60,000개, 셋째 실험은 120,000개의 요청을 보냈습니다.
Auto Scaling 기준 설정
쿠버네티스 설정값 중 오토스케일링 관련하여 설정한 HPA의 파라미터 값은 다음 3가지가 있습니다.
- scrape interval : 매트릭을 수집하는 시간 간격
- horizontal-pod-autoscaler-downscale-delay : 새롭게 파드 갯수를 줄일때까지의 시간 간격
- horizontal-pod-autoscaler-upscale-delay : 새롭게 파드 개수를 늘릴때까지의 시간 간격
본 실험에서는 위 값들을 모두 1분으로 설정하였습니다.
또한 HPA의 스케일 아웃 이벤트 발생 설정값은 다음과 같습니다.
- (파드의 평균 CPU 사용량) cpu requests 100m, limits 200m, averageUtilization 80% : 파드당 기본 CPU할당 100m, 최대 200m으로 설정하고 사용량이 requests의 80%를 넘으면 스케일 아웃 발생
- (컨테이너들의 초당 평균 write byte 수) fs_writes averageValue 100000 : 컨테이너들의 초당 평균 write byte 수가 100KB를 넘으면 스케일 아웃 발생
시나리오
본 실험은 쿠버네티스 클러스터 상에서 CPU, IO 집약적인 두 개의 node.js REST API로 들어오는 요청 수가 변화하는 상황에서 실험을 진행합니다. 위 환경에서 오토스케일링 기준을 각각 파드들의 평균 CPU 사용량과 컨테이너들의 평균 write byte 수로 놓았을 때,
- HTTP 응답 상태 코드 200 OK를 받은 성공 응답과 그 외의 상태 코드를 받은 실패 응답 수
- 파드 수의 변화
- 응답 시간 측정을 통해 어플리케이션 작업 유형별로 오토스케일링 기준을 바꿨을 때
그 성능을 비교합니다.
3가지의 실험 유형은 다음과 같습니다.
- Case1. CPU 집약적인 API로만 요청이 들어오는 상황에서 오토스케일링 기준을 평균 CPU 사용량 또는 컨테이너들의 평균 write byte 수로 놓았을 때 성능 비교
- Case2. IO 집약적인 API로만 요청이 들어오는 상황에서 오토스케일링 기준을 평균 CPU 사용량 또는 컨테이너들의 평균 write byte 수로 놓았을 때 성능 비교
- Case3. CPU 집약적인 API와 IO 집약적인 API 요청이 골고루 들어오는 상황에서 오토스케일링 기준을 기본 설정인 평균 CPU 사용량 또는 평균 CPU 사용량과 컨테이너들의 평균 write byte 수 둘 다 놓았을 때 성능 비교
yaml 파일 정의📜
Deployment, Service
apiVersion: apps/v1
kind: Deployment
metadata:
name: k8shpatest-for-default
namespace: k8shpatest
spec:
replicas: 1
selector:
matchLabels:
app: k8shpatest-for-default
template:
metadata:
labels:
app: k8shpatest-for-default
annotations:
prometheus.io/scrape: "true"
spec:
containers:
- name: k8shpatest-for-default
image: zesow/k8shpatest:v8.1
resources:
limits:
cpu: 100m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: k8shpatest-for-default
namespace: k8shpatest
spec:
type: NodePort
selector:
app: k8shpatest-for-default
ports:
- port: 3000
targetPort: 3000
nodePort: 30001HPA
CPU 기준 Scaling
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: k8shpatest-for-default
namespace: k8shpatest
spec:
maxReplicas: 20
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: k8shpatest-for-default
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80IO 기준 Scaling
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: k8shpatest-for-iointensive
namespace: k8shpatest
spec:
maxReplicas: 20
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: k8shpatest-for-iointensive
metrics:
- type: Pods
pods:
metric:
name: fs_writes
target:
type: AverageValue
averageValue: "100000"실험 결과🏌️♂️
Case1. CPU 집약적인 API로만 요청이 들어오는 상황에서 오토스케일링 기준을 평균 CPU 사용량 또는 컨테이너들의 평균 write byte 수로 놓았을 때 성능 비교
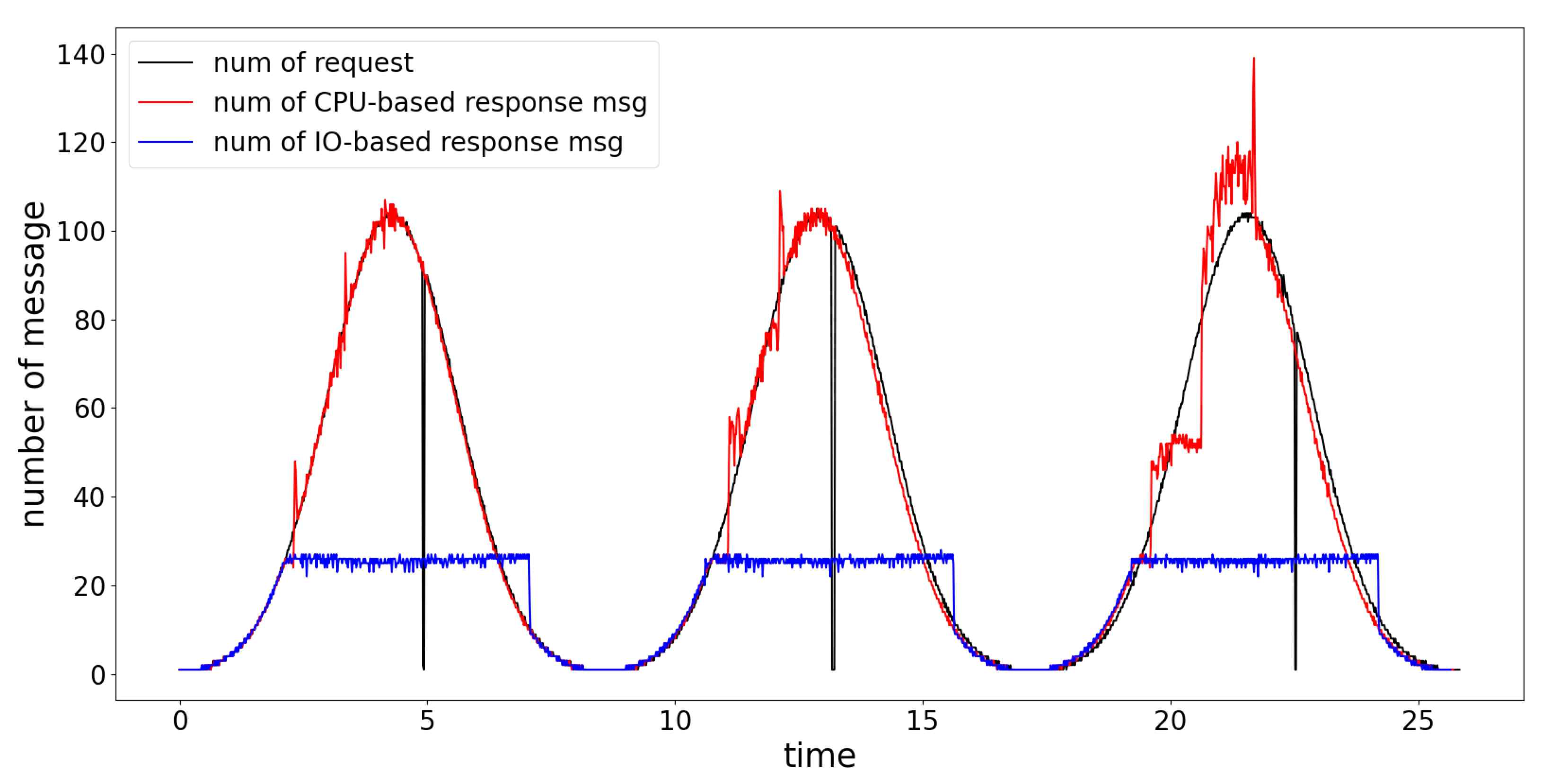
위 그림은 CPU 집약적인 API로만 요청이 집중되는 상황에서 오토스케일링 기준을 파드들의 평균 CPU 사용량 또는 컨테이너들의 평균 write byte 수로 놓았을 때, 시간에 따른 요청 수와 HTTP 응답 상태 코드 200 OK를 받은 성공 응답 수를 나타낸 그래프입니다.
파드들의 평균 CPU 사용량 기준일 때는 최대 성공 응답 수가 104까지 가는 반면, 컨테이너들의 평균 write byte 수 기준일 때는 최대 성공 응답 수가 26을 넘지 못하였습니다. 총 60,000회의 요청 중 CPU 기준은 59,950회, IO기준은 26,560회의 성공 응답을 받아 약 2.26배 차이를 보였다. 또한 최대 파드 수 또한 각각 10개, 1개로 확인되었습니다.
이는 CPU 집약적인 작업에서 write 작업은 전혀 없기 때문에 큰 차이가 벌어진 것으로 해석됩니다.
Case2. IO 집약적인 API로만 요청이 들어오는 상황에서 오토스케일링 기준을 평균 CPU 사용량 또는 컨테이너들의 평균 write byte 수로 놓았을 때 성능 비교
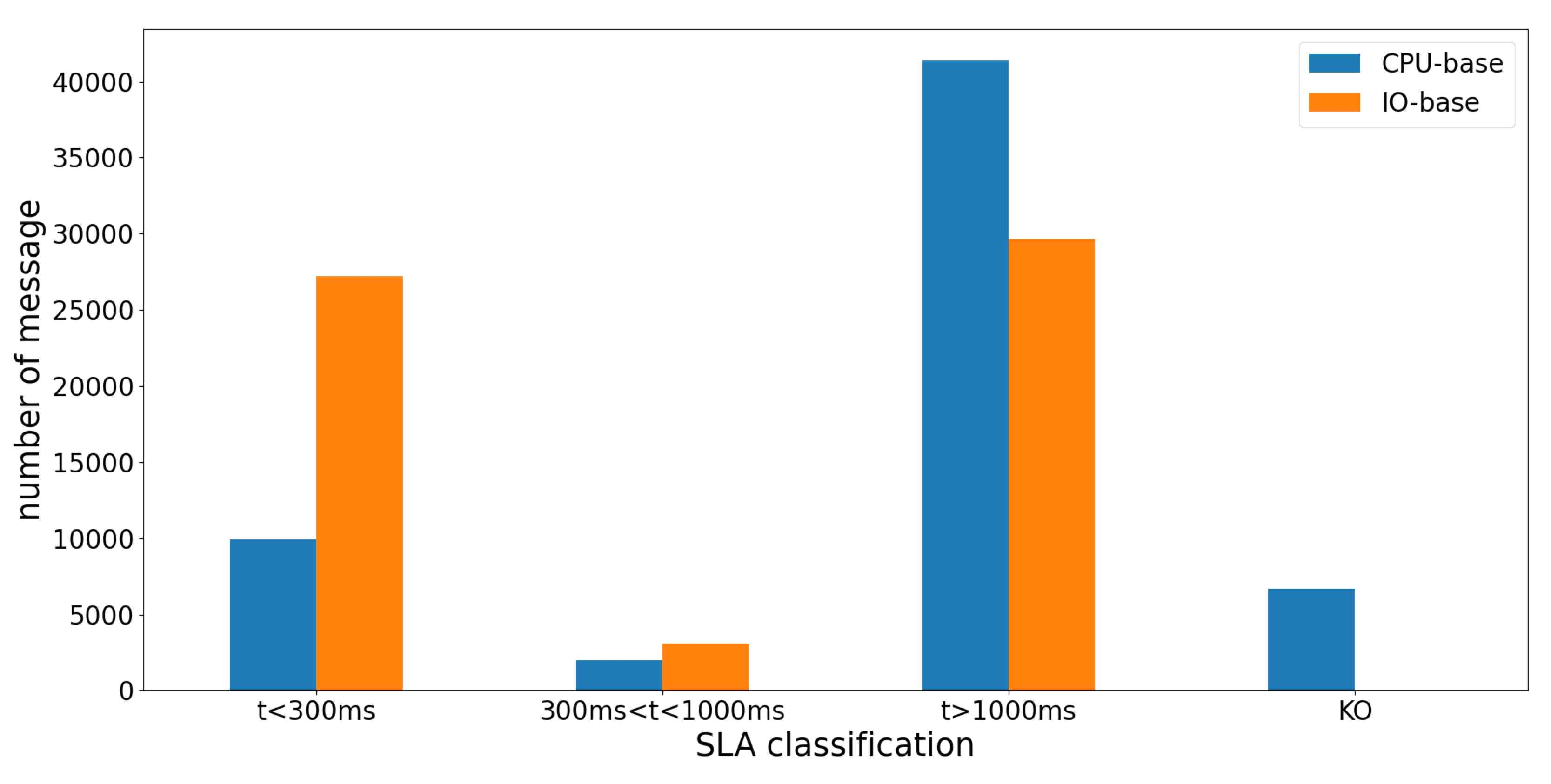
위 그림은 IO 집약적인 API로만 요청이 집중되는 상황에서 오토스케일링 기준을 파드들의 평균 CPU 사용량 또는 컨테이너들의 평균 write byte 수로 놓았을 때, 응답 시간이 각각 300ms 이하, 300~1000ms, 1000ms 이상 걸려서 HTTP 응답 상태 코드 200 OK를 받은 성공 응답 수와 그 외 응답 상태 코드를 받은 응답 수를 나타낸 표입니다.
300ms 이내에 온 응답의 숫자를 살펴보면, 오토스케일링 기준이 컨테이너들의 평균 write byte 수일 때는 27,221회인 반면 파드의 평균 CPU 사용량에서는 9,938회로 약 2.74배 차이를 보였습니다. 반면 성공 응답 수 자체는 총 60,000회의 요청 중 CPU기준은 53,307회, IO 기준은 59,985회의 성공 응답을 받아 아주 큰 차이는 보이지 않았습니다.
이는 IO 집약적인 작업에서도 CPU는 사용되기 때문에 파드수가 증가하여 첫 번째 실험만큼 큰 차이가 나진 않은 것으로 해석됩니다.
Case3. CPU 집약적인 API와 IO 집약적인 API 요청이 골고루 들어오는 상황에서 오토스케일링 기준을 기본 설정인 평균 CPU 사용량 또는 평균 CPU 사용량과 컨테이너들의 평균 write byte 수 둘 다 놓았을 때 성능 비교
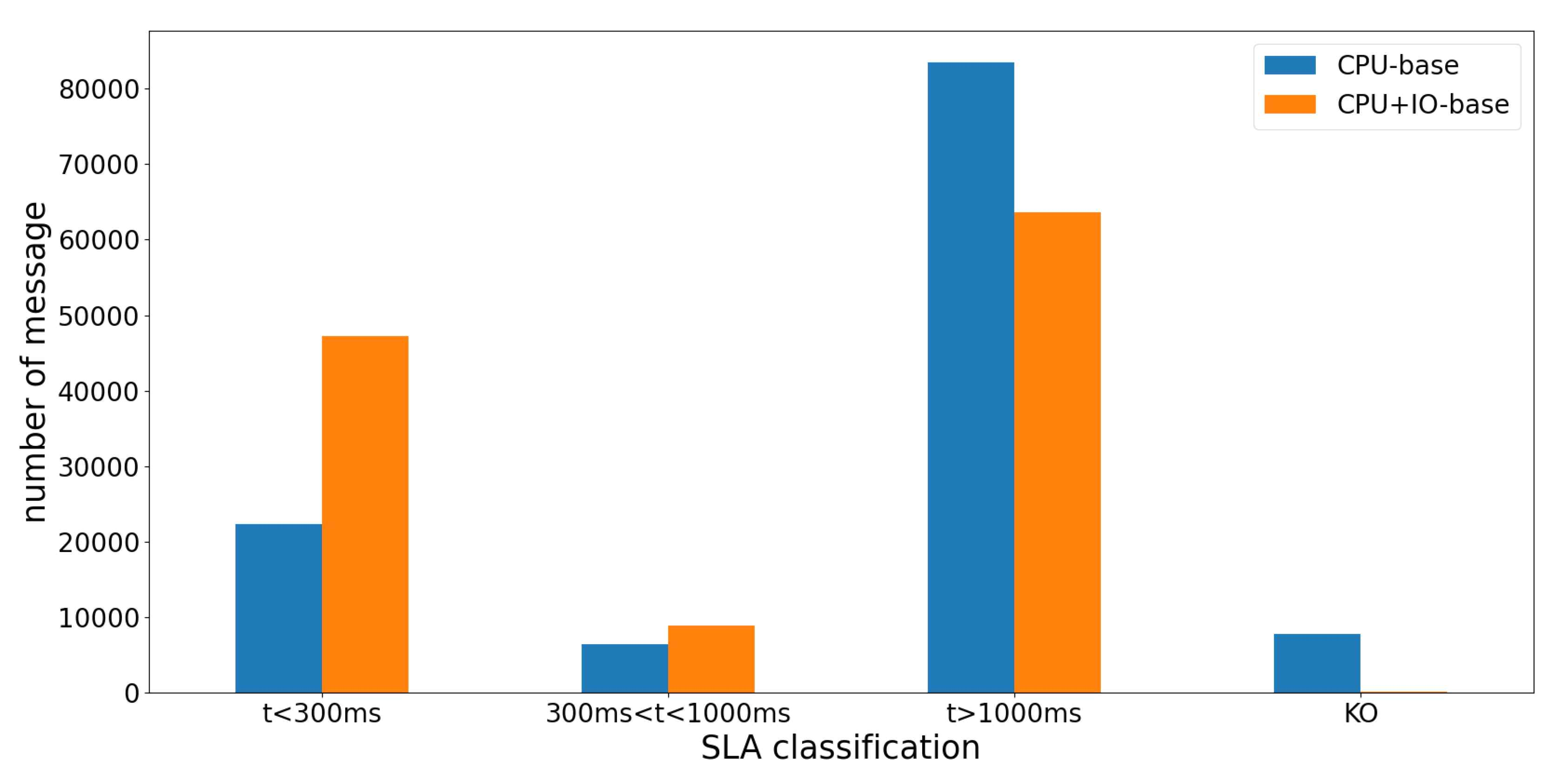
위 그림은 CPU 집약적인 API와 IO 집약적인 API 요청이 골고루 들어오는 상황에서 오토스케일링 기준을 파드들의 평균 CPU 사용량만 놓았을 때 또는 파드들의 평균 CPU 사용량과 컨테이너들의 평균 write byte 수를 둘 다 놓았을 때, 응답 시간이 각각 300ms 이하, 300~1000ms, 1000ms 이상 걸려서 HTTP 응답 상태 코드 200 OK를 받은 성공 응답 수와 그 외 응답 상태 코드를 받은 응답 수를 나타낸 표입니다.
300ms 이내에 온 응답의 숫자를 살펴보면 오토스케일링 기준으로 파드들의 평균 CPU 사용량과 컨테이너들의 평균 write byte 수를 둘 다 놓았을 때는 47,267회인 반면 파드의 평균 CPU 사용량만 놓은 경우에는 22,310회로 약 2.12배 차이를 보였습니다.
이는 다른 성격의 요청이 같이 들어올 때 오토스케일링 기준을 다양화하는 것이 더 빠른 응답을 줄 수 있다는 것을 보여줍니다.
결론👩🦱
본 실험에서는 서버 어플리케이션의 CPU, IO 집약적 API로 들어오는 다양한 요청 상황에서 쿠버네티스 오토스케일링 기준을 바꿔가며 성능 및 자원 할당 차이를 관찰 및 분석하였습니다.
첫 번째, 두 번째 실험 결과로 오토스케일링 기준을 CPU 집약적인 API 호출이 집중되는 환경에서는 파드의 평균 CPU 사용량을, IO 집약적인 API 호출이 집중되는 환경에서는 컨테이너들의 평균 write byte 수를 기준으로 하는 것이 요청 수의 변화에 따라 자원을 잘 할당해 주는 것을 확인할 수 있었습니다. 또한 세 번째 실험인 CPU, IO 집약적인 API 호출이 섞여 들어오는 상황에서는 파드의 평균 CPU 사용량과 컨테이너들의 평균 write byte 수를 둘 다 기준으로 할 때 더 자원을 적절히 할당해 주었습니다.
이를 통해 운영되는 서비스의 특징, 요청 부하 패턴 및 API 호출 빈도 등을 분석하여 상황에 맞는 오토스케일링 기준을 설정하는 것이 적절한 자원 사용과 성능 확보에 유리할 수 있다는 결론을 내렸습니다.
다음에는 시리즈 마지막 글로, 웹 서버 부하테스트 툴 gatling 을 이용해 실험을 진행하고, 여기서 나온 log 데이터를 전처리해 파이썬 matplotlib 로 그래프를 그린 내용을 정리하겠습니다. 잘못된 부분이나 의견이 있으신 경우 댓글로 남겨주시면 적극 반영하겠습니다! 감사합니다.

