CUBRID란?
국내 유일의 오픈소스 DBMS다.
- 다양하게 쓰인다.
겁나 잘나간다 - 와! 이 모든 기능이 무료!
- 엔진의 소스 코드가 수정되면 소스를 까야하지만, 큐브리드 DBMS를 사용하도록 개발된 것들은 소스 코드를 공개하지 않아도 판매할 수 있다.
- 큐브리드 = 응용프로그램 + 브로커 + 데이터베이스 엔진
- 데이터베이스 엔진: 쿼리를 수행하고데이터베이스 볼륨을 저장.
- 브로커 : 응용프로그램의 연결 요청(to 데이터베이스)을 수행.
👉와! 브로커, 데이터베이스 여러개 쓸 수 있다!
- 브로커 : 응용프로그램의 연결 요청(to 데이터베이스)을 수행.
- 다양한 인터페이스(CCI, JDBC, PHP, ODBC, OLE DB) 제공.
jdbc👇
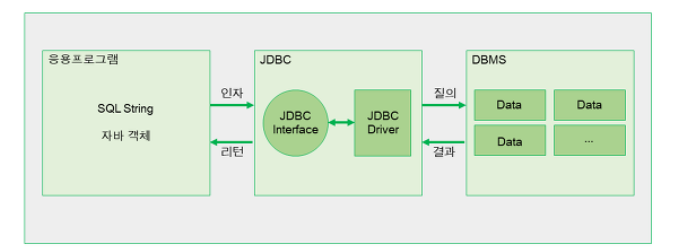
DBMS란?
근본 없이 널부러진 옷장 속에서 원하는 옷을 찾기란 실로 어려운 일이다. 고로 대량의(?)옷을 보관하고 관리하며 빠르게 꺼낼 수 있는 장치를 만들었다.(대충 보조 도구와 나만의 규칙으로 정리했다는 얘기)
데이터도 마찬가지다. 대량의 데이터를 적절하게 구성해서 저장, 관리하고 필요한 데이터를 빠르게 검색하는 장치가 DBMS이다.
ex. Oracle과 MySQL
>DBMS의 구조는?<
> DBMS가 나오기 전에는 데이터를 어떻게 관리했을까?<
[키워드 정리]
- 데이터: 어떤 사실을 나타낼 수 있는 값 + 그 값에 대한 설명
- 데이터베이스: 데이터의 집합
- 스키마: 데이터베이스에 있는 데이터들의 관계를 나타낸 것.
- 트랜잭션: 데이터베이스에서 하나의 작업을 수행하기 위해 필요한 연산(CRUD)들의 집합. 완벽한 일처리를 위해서 트랜잭션을 적절히 잘 나눠야겠죠?
CUBRID와 아이들 설치
[CUBRID 서버 + 인터페이스 드라이버 + 브로커]
- 윈도우와 리눅스용이 있다.
[큐브리드 GUI 도구- CUBRID 매니저]
- GUI관리 도구
- 질의 실
행뿐만 아니라 데이터베이스 추가, 백업, 복구 등 콘솔에서 수행하는 업무를 GUI로 수행할 수 있게 하는 도구.
- 질의 실
- 관리모드와 쿼리모드가 있다.
[큐브리드 GUI 도구- CUBRID MIGRATION 툴킷]
- 큐브리드 운영 중에 개발 데이터베이스 서버와 운영 데이터서버 사이의 데이터를 통합.
[CUBRID 쿼리 브라우저]
- GUI쿼리 도구
프로세스들 of CUBRID
이 두 그림을 같이 보면 뽝 이해가 가지
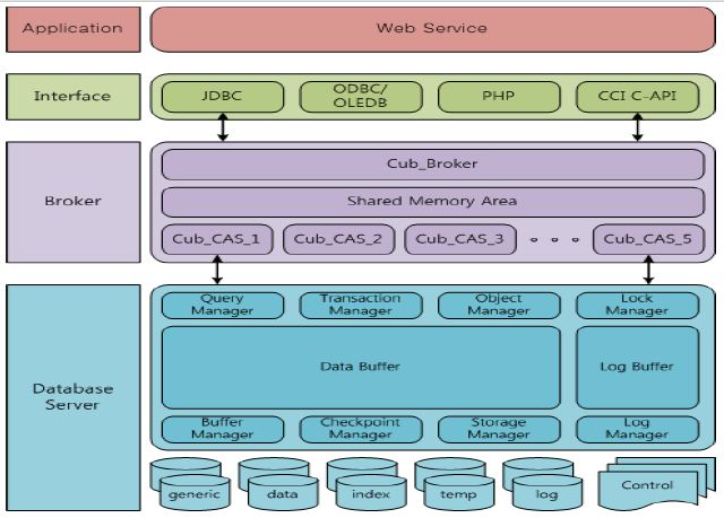
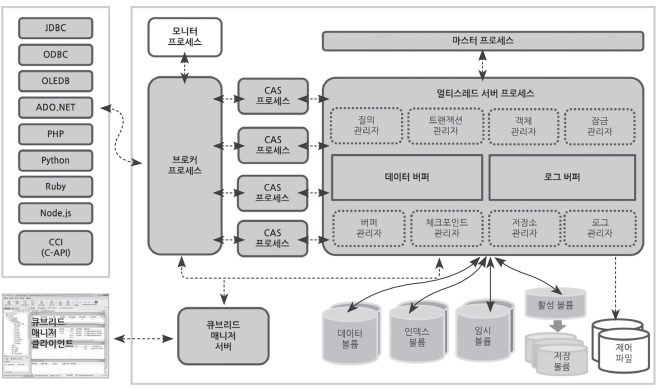
[master process]
ps -ef |grep cub_master- 큐브리드 서비스를 구동하면 하나의 cub_master서비스가 돌아간다.
- client(jdbc, odbc, php...)와 database server프로세스 사이를 연결하는 프로세스
- In detail, CAS프로세스와 database server프로세스 사이를 연결하기도 하고, 큐브리드를 전반적으로 운영하는 프로세스임.
[database server process]
ps -ef |grep cub_server- 이 친구는 항상 특정 데이터베이스와 일대일로 대응된다.
👉 장비 하나에 디비 여러개 돌릴 때, 디비 하나 고장나도 다른 디비들은 살아있음. - 데이터베이스 파일과 로그 파일에 직접 접근해 사용자 요청을 처리하는 프로세스
[Broker process]
ps -ef |grep cub_broker- client와 CAS프로세스 사이를 연결하는 프로세스.
- cubrid_broker.conf 파일에서 필요한 개수 만큼 설정.
- CAS 프로세스들의 상태를 모니터링하고 관리한다.
[CAS process]
ps -ef |grep cub_cas- client와 연결이 종료될 때까지 쿼리 요청을 처리하는 프로세스.
- 브로커로부터 연결 요청을 받으면, 마스터 프로세스에게 일 시킬 데이터베이스 서버 프로세스를 알려달라고 한 후, 그 친구 일이 끝날 때 까지 연결을 유지한다.
응용프로그램과 서버의 연결 과정
1. 응용프로그램이 브로커 프로세스에 연결을 요청하면 브로커 프로세스는 CAS 프로세스를 할당한다.
2. 응용프로그램과 CAS 프로세스가 연결된다.
3. CAS 프로세스가 마스터 프로세스에 연결을 요청하면 마스터 프로세스는 서버 프로세스에 연결한다.
4. 💖응용프로그램 – CAS 프로세스 – 서버 프로세스💖 연결이 완료된다.
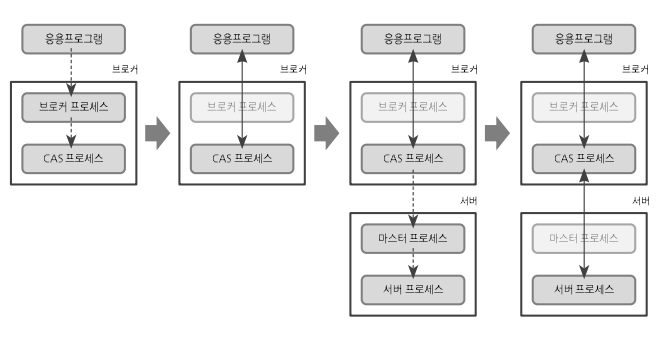
프로세스 of CUBRID MANAGER
[CUBRID MANAGER process]
ps -ef |grep cub_cmserver
CUBRID 껏다켜기 신공
[서비스 껐다 켜기]
cubrid service start/stop
👉마스터 프로세스, 서버 프로세스, 브로커 프로세스, 매니저 프로세스 순서대로 실행됨.- 마스터 프로세스는 디폴트로 실행되니까 브로커 프로세스만
service명령어로 껏다 켜고 싶으면cubrid.conf파일에서service=server,broker,manager👉service=broker바꾸셈.
- 마스터 프로세스는 디폴트로 실행되니까 브로커 프로세스만
[서버 프로세스 껏다 켜기]
cubrid server start/stop [데이터베이스 이름]- 요즘 작업하는 데이터베이스 매번 시작하기 귀찮으면
cubrid.conf파일에서server=요즘, 작업하는, 디비들넣으면 서비스 시작할 때 자동으로 켜짐.(ㄱㅇㄷ)
- 요즘 작업하는 데이터베이스 매번 시작하기 귀찮으면
- 바아로 쿼리문 날리고 싶다면
csql -u dba [데이터베이스 이름]
[브로커 프로세스 껏다 켜기]
cubrid broker start/stop
👉 이 명령어로cubrid_broker.conf파일에 설정한 브로커들을 전부 켠(start) 다음에cubrid broker off/on [상태를 끄/켜고 싶은 브로커 이름]형식으로 세부 조정을 하다가stop으로 샷다 내린다.
[매니저 프로세스 껏다 켜기]
cubrid manster start/stop
데이터베이스
[데이터베이스 볼륨]
- (= 데이터가 저장될 공간)
- 저장 형태에 따라 세가지로 구분됨.
- 영구적인 볼륨: 한 번 생성되면 데이터베이스가 삭제되기 전까지 유지되는 볼륨
👉 용도에 따라 4가지로 구분됨.
1. 범용 볼륨: 일반적으로 사용하는 볼륨. 스키마, 인덱스, 데이터를 저장한다.
볼륨 생성 명령(cubrid createdb)을 실행할 때 볼륨 타입을 지정하지 않으면 범용 볼륨으로 생성된다.
2. 데이터 볼륨: 데이터를 저장하기 위한 공간.
3. 인덱스 볼륨: 인덱스를 저장하기 위한 공간.
4. 임시 볼륨: 질의 처리 및 정렬을 수행할 때 중간 결과 및 최종 결과를 임시로 저장하는 공간.이 공간이 모두 소진되면 일시적인 볼륨을 사용한다. 일시적인 볼륨은 데이터베이스를 재시작하면 삭제되지만 임시 볼륨은 영구 볼륨
이므로 데이터베이스를 정지해도 유지된다. - 일시적인 볼륨: 데이터베이스 운영 중 필요한 중간 결과를 일시적으로 저장하기 위해 사용되는 볼륨
- 백업 볼륨: 데이터베이스의 백업 시점의 스냅숏으로, 데이터베이스 백업 시 생성되는 볼륨이다
[데이터베이스 생성]
$ cd $CUBRID_DATABASES
$ mkdir testdb
$ cd testdb
$ cubrid createdb testdb ko_KR.utf8
Creating database with 512.0M size using locale ko_KR.utf8. The total amount of disk space
needed is 1.5G.- 이와 같이 testdb를 생성한 상태에서 데이터베이스 볼륨 파일을 확인해보면 다음과 같다.
$ ls
디렉터리: C:\CUBRID\testdb
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2021-11-08 오전 3:17 lob
-a---- 2021-11-08 오전 3:17 536870912 testdb
-a---- 2021-11-08 오전 3:17 65 testdb_keys
-a---- 2021-11-08 오전 3:17 536870912 testdb_lgar_t
-a---- 2021-11-08 오전 3:17 536870912 testdb_lgat
-a---- 2021-11-08 오전 3:17 172 testdb_lginf
-a---- 2021-11-08 오전 3:17 173 testdb_vinf- testdb: 데이터베이스의 데이터와 인덱스 정보를 저장하는 볼륨. 카탈로그 테이블 정보가 포함돼 있다.
- testdb_lgar_t: 보관 로그 파일을 저장하기 전에 사용되는 임시 파일. 활성 로그 파일이 가득 차면 보관 로그 파일이
생성되는데, 보관 로그 파일은 데이터베이스의 백업 또는 복구 시 사용된다. HA 구성 시 데이터 복제에도 보관 로그
파일이 사용된다. 이 예에서는 보관 로그 파일이 아직 생성되지 않은 상태다. - testdb_lgat: 활성 로그 파일. 진행 중인 트랜잭션 정보를 저장한다.
- testdb_lginf: 로그 파일의 정보를 저장하는 파일.
- testdb_vinf: 볼륨 파일의 정보를 저장하는 파일.
[데이터베이스 볼륨 추가]
$ cubrid addvoldb -S -p data -n testdb_DATA01 --db-volume-size=512M testdb
$ cubrid addvoldb -S -p data -n testdb_DATA02 --db-volume-size=512M testdb
$ cubrid addvoldb -S -p index -n testdb_INDEX01 --db-volume-size=512M testdb
$ cubrid addvoldb -S -p temp -n testdb_TEMP01 --db-volume-size=512M testdbPS C:\CUBRID\testdb> ls
디렉터리: C:\CUBRID\testdb
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2021-11-08 오전 3:17 lob
-a---- 2021-11-08 오전 3:25 536870912 testdb
-a---- 2021-11-08 오전 3:24 536870912 testdb_DATA01
-a---- 2021-11-08 오전 3:25 536870912 testdb_DATA02
-a---- 2021-11-08 오전 3:25 536870912 testdb_INDEX01
-a---- 2021-11-08 오전 3:17 65 testdb_keys
-a---- 2021-11-08 오전 3:25 536870912 testdb_lgar_t
-a---- 2021-11-08 오전 3:25 536870912 testdb_lgat
-a---- 2021-11-08 오전 3:17 172 testdb_lginf
-a---- 2021-11-08 오전 3:25 536870912 testdb_TEMP01
-a---- 2021-11-08 오전 3:25 322 testdb_vinf볼륨 사용량 확인
- 해당 서버 프로세스를 켜고
PS C:\CUBRID\testdb> cubrid server start testdb ++ cubrid server start: success
- 볼륨 사용량을 확인한다.
cubrid spacedb -p testdb
큐브리드 설정
conf폴더에 설정 파일들 있음.
[큐브리드 서버 설정]
cubrid.conf에 설정.
크게 네 부분으로 구분돼 있으며, 각 부분에서 설정하는 파라미터는 다음과 같다.
- [service]: 큐브리드 서비스 시작에 관련된 파라미터.
- [common]: 전체 데이터베이스에 공통으로 관련된 파라미터.
- [@{데이터베이스 이름}]: 각 데이터베이스에 개별적으로 적용되는 파라미터.
- [standalone]: cubrid 유틸리티가 독립 모드(stand-alone, --SA-mode)로 구동할 때 사용되는 파라미터.
cubrid 유틸리티란 cubrid로 시작하는 명령의 집합을 말한다
(예: cubrid createdb, cubrid loaddb, cubrid backupdb 등)
cubrid.conf
[service]
service=server,broker,manager
server=testdb
[common]
data_buffer_size=512M
log_buffer_size=4M
sort_buffer_size=2M
max_clients=100
cubrid_port_id=1523
db_volume_size=512M
log_volume_size=512M
log_max_archives=0
[standalone]
sort_buffer_size=256M- data_buffer_size: 캐싱되는 데이터 버퍼의 크기. 이 값이 클수록 캐싱되는 데이터가 많아지므로 디스크 I/O 비용을 줄일 수 있지만, 너무 크면 시스템 메모리가 과도하게 점유돼 운영체제에 의해 스와핑이 발생할 수 있다.
- log_buffer_size: 로그 버퍼의 크기.
- sort_buffer_size: 정렬을 수행하는 질의에서 사용하는 버퍼의 크기. 정렬을 요청하는 클라이언트마다 정렬 버퍼가 할당되며, 정렬이 완료되면 해제된다. 인덱스를 생성하는 경우 정렬 버퍼가 많이 필요하므로 정렬 버퍼를 늘리는 것이 좋지만 데이터베이스 운영 중에는 불필요하게 많은 메모리를 점유할 수 있으므로 다시 줄이는 것이 좋다.
- max_clients: 큐브리드 서버 프로세스에 접속 가능한 클라이언트의 최대 개수. 여기서 클라이언트란 브로커의 CAS, CSQL, HA 복제 관련 프로세스, cubrid 유틸리티를 의미한다. 따라서 사용하려는 응용프로그램의 최대 개수보다 크게 설정해야 한다.
참고
리눅스에서는 프로세스 하나당 오픈할 수 있는 파일 디스크립터 개수의 최댓값(ulimit –n)을 max_clients 파라미
터의 값보다 크게 설정해야 한다. - cubrid_port_id: 큐브리드 마스터 프로세스가 사용하는 포트 번호.
이 포트는 큐브리드 마스터 프로세스와 브로커 프로세스가 통신할 때 사용하는 포트다.
응용프로그램은 CAS 프로세스와 통신하므로 응용프로그램에서 사용하는 포트는 cubrid_broker.conf 파일의 BROKER_PORT 파라미터로 설정한다. - log_max_archives: 보관 로그의 최대 개수.
특정 시점으로 복구하려면 해당 시점이 보관 로그에 보존돼야 하므로 이 값을 크게 설정해야 한다. 그 외의 경우에는 설정을 바꾸지 않아도 된다.
[브로커 설정]
cubrid_broker.conf
[broker]
MASTER_SHM_ID =30001
ADMIN_LOG_FILE =log/broker/cubrid_broker.log
[%query_editor]
SERVICE =ON
BROKER_PORT =30000
MIN_NUM_APPL_SERVER =5
MAX_NUM_APPL_SERVER =40
APPL_SERVER_SHM_ID =30000
LOG_DIR =log/broker/sql_log
ERROR_LOG_DIR =log/broker/error_log
SQL_LOG =ON
TIME_TO_KILL =120
SESSION_TIMEOUT =300
KEEP_CONNECTION =AUTO
[%BROKER1]
SERVICE =ON
BROKER_PORT =33000
MIN_NUM_APPL_SERVER =5
MAX_NUM_APPL_SERVER =40
APPL_SERVER_SHM_ID =33000
LOG_DIR =log/broker/sql_log
ERROR_LOG_DIR =log/broker/error_log
SQL_LOG =ON
TIME_TO_KILL =120
SESSION_TIMEOUT =300
KEEP_CONNECTION =AUTO[broker] 아래에 정의된 파라미터는 모든 브로커에 공통으로 적용되는 파라미터
- SERVICE: 해당 브로커의 구동 여부. ON이면 구동하고, OFF이면 구동하지 않는다.
- BROKER_PORT: 해당 브로커에서 사용하는 포트 번호
- MIN_NUM_APPL_SERVER: 해당 브로커에서 구동되는 CAS 프로세스의 최소 개수. 브로커가 처음 구동될 때 이
개수만큼의 CAS 프로세스를 구동한다. 기본값은 5다. - MAXNUM_APPL_SERVER: 해당 브로커에서 구동되는 CAS 프로세스의 최대 개수. MIN_NUM_APPL
SERVER 파라미터로 지정한 개수보다 많은 연결 요청이 오면 CAS 프로세스 개수를 늘리며, 최대 개수를 초과하면
먼저 진행 중인 트랜잭션이 종료될 때까지 기다렸다가 CAS 프로세스를 할당한다. 기본값은 40이다.
😎그럼 초과하면 프로세스 계속 늘리는건가? - APPL_SERVER_MAX_SIZE: 해당 CAS 프로세스가 사용하는 메모리 공간의 최대 크기를 지정
동작 방식
이때 사용하는 메모리의 기준은 cubrid broker
status 명령의 결과로 출력되는 PSIZE 값이다. CAS 프로세스의 PSIZE 값이 설정된 값을 초과하면 진행
중이던 트랜잭션을 모두 수행한 후 해당 CAS 프로세스를 재시작한다. 리눅스에서 기본값은 0이며, 이 경
우 CAS 프로세스의 PSIZE 값이 초기 구동 시 PSIZE 값의 두 배가 되면 해당 CAS 프로세스를 재시작한
다. 예를 들어, 초기 구동 시 PSIZE 값이 50MB라면 이 값이 100MB가 될 때 진행 중이던 트랜잭션을 모두
수행한 후 CAS 프로세스를 재시작한다.
