레디스 (Redis)란
레디스는 Remote Dictionary Server의 약자로서, 키-값 구조의 데이터를 메모리에 저장하고 관리하기 위한 데이터베이스 관리 시스템이다.
서버가 1대라면 로컬변수에 저장하면 간단하지만, 서버가 여러대인 경우 Consistency 문제가 발생하기 때문에 레디스 서버를 따로 두는 경우가 많다.
특징은 다음과 같다.
빠른 데이터 접근 속도
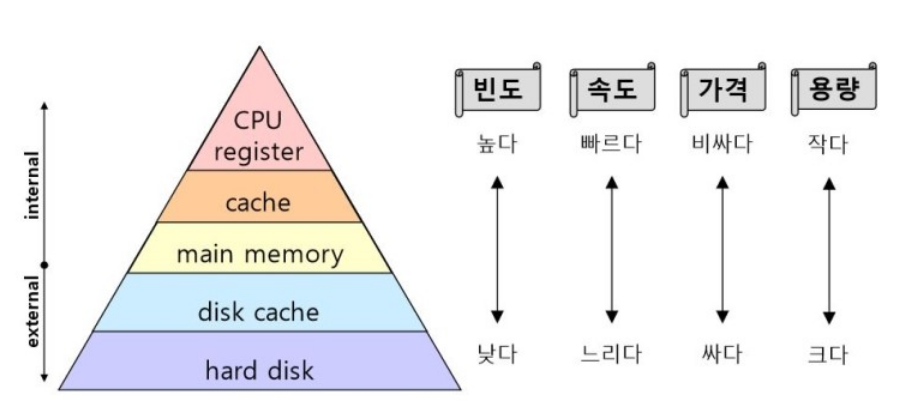
메모리에 저장하기 때문에 디스크에 저장하는 데이터베이스보다 더 빠른 속도로 데이터에 접근이 가능하다.
다양한 자료구조 지원
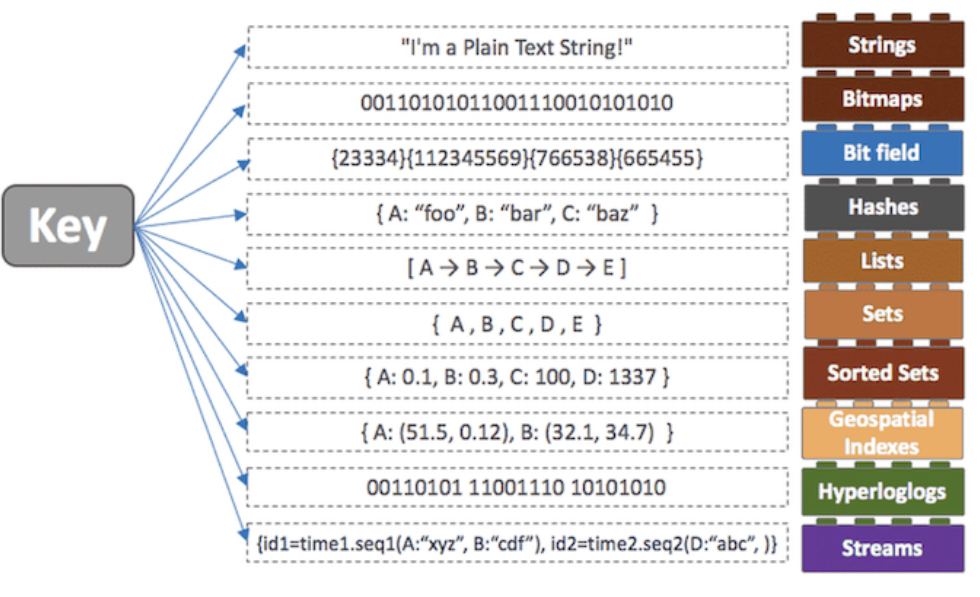
레디스가 다른 In-Memory 데이터베이스와 가장 큰차이점은 다양한 자료구조를 지원한다는 것이다. 레디스는 아래의 자료구조들을 Key-Value 형태로 저장한다.
따라서 다양한 방식으로 데이터를 활용할 수 있다.
ex) sortedSet을 사용하여 랭킹 저장
데이터 영속화
레디스는 데이터를 디스크에 저장하여, 영속화 시키는 기능을 갖고 있기에 메모리에 저장된 데이터가 휘발성으로 사라져 버릴 거라는 걱정을 안해도 된다.
-
Snapshot: 정기적으로 데이터베이스의 내용을 디스크에 쓴다. 만약
레디스를 재기동하면 이 파일부터 데이터를 불러와 복원시킨다. 디스크에 언제 저장할 것인지 설정할 수 있다.단, 이 때 스냅샷을
SAVE하는 시점에서 모든 명령어 수행이 제한되게 된다. 따라서 이런 문제를 막고자 백그라운드에서 스냅샷을 뜨는BGSAVE옵션이 존재한다.BGSAVE를 수행할 때는 자식 프로세스를 하나 생성하여 스냅샷을 수행하기 때문에 메모리가 현재 사용량의 2배가 될 수 있음을 인지해야 한다. -
Append Only File:
Snapshot은 데이터가 유실될 가능성이 존재한다.AOF에서는 명령이 실행될 때 마다 명령어들을 파일에 기록하여 데이터 손실을 방지한다. 다양한AOF옵션이 존재하니 아래 블로그 글을 읽어보는 것을 추천한다!
AOF 참고하면 좋은 곳
부하 분산
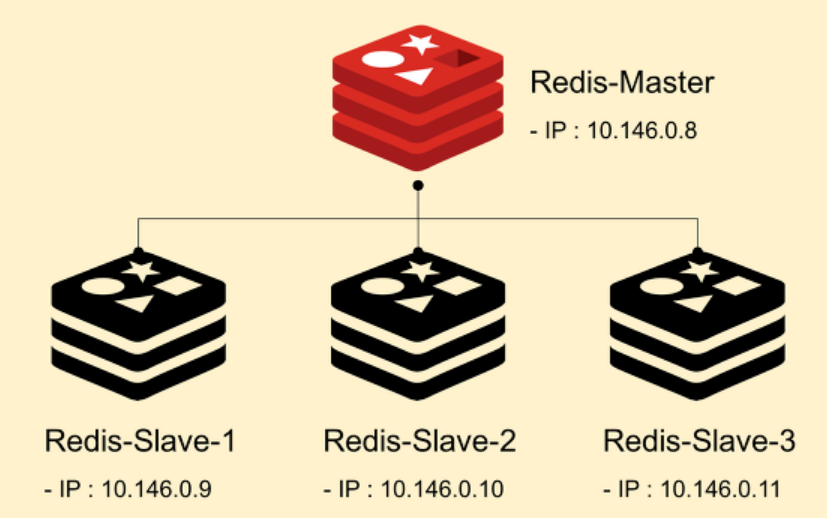
레디스에는 다른 컴퓨터로 복제를 하는 기능이 있어, 갱신이 가능한 1대를 마스터로, 그 복제된 읽기 전용의 복수의 컴퓨터를 슬레이브로 구성하여 분산환경을 만들 수 있다.
메모리 파편화

메모리를 할당하고 해제하는 과정에서 위 그림과 같이 메모리 파편화가 발생할 수 있다. 따라서 메모리 공간을 할당하지 못해 프로세스가 죽는 문제가 발생할 수 있다.
싱글 스레드
레디스는 싱글 스레드로 동작한다.
따라서 race condition 을 피해 데이터의 정합성을 보장하기 쉽다.
반면, 처리 시간이 긴 명령어가 들어올 경우 싱글 스레드이기 때문에 다른 명령어들을 처리할 수 없는 상태가 된다. 왠만하면 처리 시간이 긴 명령어는 피하고 O(1) 로 동작하는 명령을 실행시키는 것을 권고한다.
사용 사례
레디스는 빠른 데이터 접근 속도와 데이터의 consistency를 보장한다. 따라서 이런 장점을 살릴 수 있는 캐싱과 세션스토어에 많이 사용된다.
그 외에도 레디스의 장점들을 살릴 수 있는 곳이라면 어디든지 사용할 수 있다.
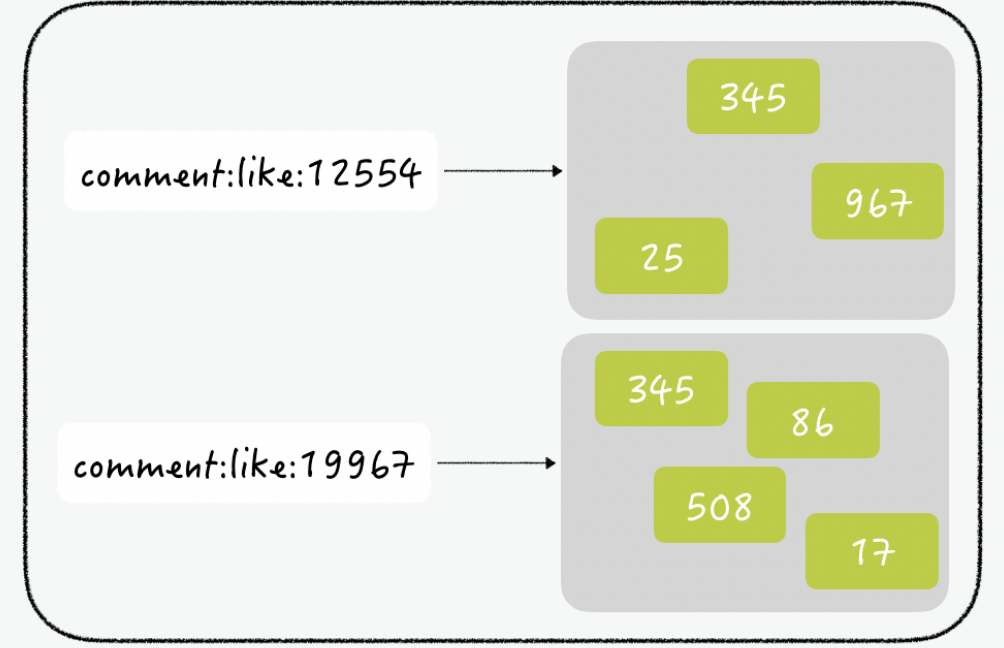
ex) 한 사용자가 한 번만 좋아요를 할 수 있도록 레디스의 set 이용
레퍼런스
