MQ는 어떤 장점이 있고 왜 사용하는 것일까?
Case 1.
한가지 시나리오를 생각해보자. 시스템 A 는 시스템 B,C,D 에게 동일한 데이터를 전송중이다.
만약 시스템 E도 이 데이터를 원한다면 어떻게 될까?
만약 시스템 C가 이 데이터를 더이상 원하지 않는다면 어떻게 될까?
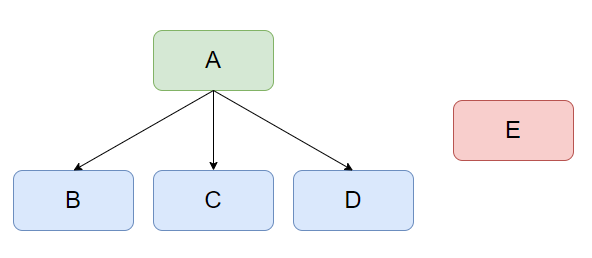
A는 B,C,D 와 강하게 커플링되어 있다.
만약 데이터 전송이 실패한다면? 재전송을 해야한다면? 시스템 A 는 B,C,D 를 모두 고려해야한다.
여기에 MQ를 사용해보자
A는 MQ 에 데이터를 전송한다. 이 데이터를 필요로한는 시스템은 MQ 에서 데이터를 컨슘한다.
새로운 시스템이 이 데이터가 필요하다면 MQ 에서 컨슘할 수 있고 더 이상 데이터가 필요없는 시스템은 컨슘을 중단하면 된다.
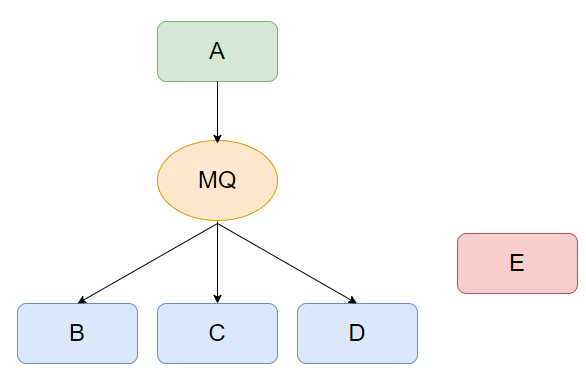
시스템 A는 더이상 누구에게 데이터를 보내야할지, 전송이 누구에게 성공했고 누구에게 실패했는지 고려할 필요가 없다.
MQ 모델을 통해 시스템 A 는 다른 시스템으로부터 완전히 decoupling 된다.
여기에 더해 만약 이런 데이터전송 라인이 매우 많다고 생각해보자.
데이터 흐름을 중앙에서 관리해주는 MQ 덕분에 데이터 파이프라인이 간소화되고 관리하기 편해지는 효과가 있다.
Case 2.
다른 시나리오를 생각해보자
시스템 A 는 사용자로부터 요청을 받으면 시스템 B,C,D 에게 특정한 task 를 수행하도록 요청해야 한다.
B,C,D 로의 요청/응답이 500ms씩 걸린다고 한다면 A는 사용자에게 응답하기까지 총 1.5초의 시간이 걸린다.
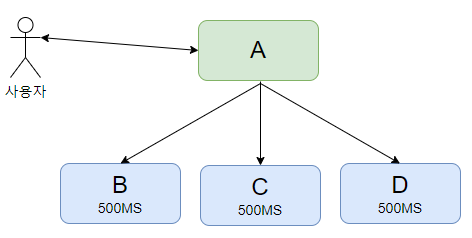
만약 B,C,D 가 수행해야할 task 가 반드시 동기적으로 수행되되어야 할 필요가 없다면 MQ를 사용하여 응답시간을 줄일 수 있다.
시스템 A 는 MQ 에 B,C,D가 컨슘해야할 메세지를 보내고 사용자에게 바로 응답을 보낸다. B,C,D 를 기다릴 필요가 없으므로 사용자는 더 빠르게 응답을 받을 수 있다.
Case 3.
시스템 A가 시간마다 받는 요청수가 다르다고 생각해보자
피크시간에 초당 5k 의 요청이 들어오고 아닐 때는 50개의 요청만 들어온다.
DB 가 초당 2k 이상의 요청이 들어오면 다운되는 스펙이라면 피크시간을 견디지 못하고 시스템이 다운될 것이다.
여기에서 MQ 를 사용해보자
피크시간에 초당 5k 의 메세지를 MQ 로 보낸다. 시스템A는 DB 스펙때문에 최대 초당 2k의 요청만 처리할 수 있으므로 해당 처리량을 초과하지 않을 정도로만 메세지를 컨슘한다.
초당 5k의 메세지가 쌓이는 동안 초당 최대 2k의 메세지만 처리하므로 피크시간동안 수십 또는 수백만의 메세지가 쌓일 수 있다. 하지만 피크시간이 지나면 초당 50개의 메세지만 들어오므로 쌓여있는 메세지를 빠르게 처리할 수 있다.
MQ 는 위에서 언급했던 시나리오들에서 장점을 갖는다.
그렇다면 어떤 단점이 있을까
MQ 의 단점
- MQ 가 다운되면 MQ 에 메세지를 발행/컨슘하는 모든 시스템 또한 다운된다.
- MQ 가
고가용성을 보장하는 방법은 무엇이 있을까?
- MQ 가
- 데이터 일관성 문제가 발생할 수 있다.
- 시스템 A가 발행한 메세지를 B,C,D가 컨슘하여 DB를 업데이트한다. 만약 시스템 C가 업데이트에 실패했다면 데이터의 일관성이 깨지게 된다.
참고
https://github.com/doocs/advanced-java/blob/main/docs/high-concurrency/why-mq.md
