혼잡(폭주) 제어 (Congestion Control)
흐름 제어가 송·수신 측 사이의 패킷 수를 제어하는 기능이라면, 혼잡 제어는 네트워크 내의 패킷 수를 조절하여 네트워크의 오버플로(overflow)를 방지하는 기능을 한다.
좀 더 자세히!
데이터의 양이 라우터가 처리할 수 있는 양을 초과하면 초과된 데이터는 라우터가 처리하지 못한다.
송신 측에서는 라우터가 처리하지 못한 데이터를 손실 데이터로 간주하고 계속 재전송하게 되므로 네트워크는 더욱 더 혼잡하게 된다.
이런 상황은 송신 측의 전송 속도를 적절히 조절하여 예방할 수 있는데 이것을 혼잡 제어라고 한다.
혼잡 제어 방법
AIMD (Additive Increse/Multicative Decrease)
우리말로 직역하면 합 증가/ 곱 감소 방식이다.
-
처음에 패킷을 하나씩 보내고 문제없이 도착하면 윈도우의 크기를 1씩 증가시켜가며 전송한다.
-
만약 전송에 실패하면 윈도우 크기를 반으로 줄인다.
-
윈도우 크기를 너무 조금씩 늘리기 때문에 네트워크의 모든 대역을 활용하여 제대로 된 속도로 통신하기까지 시간이 오래 걸린다.
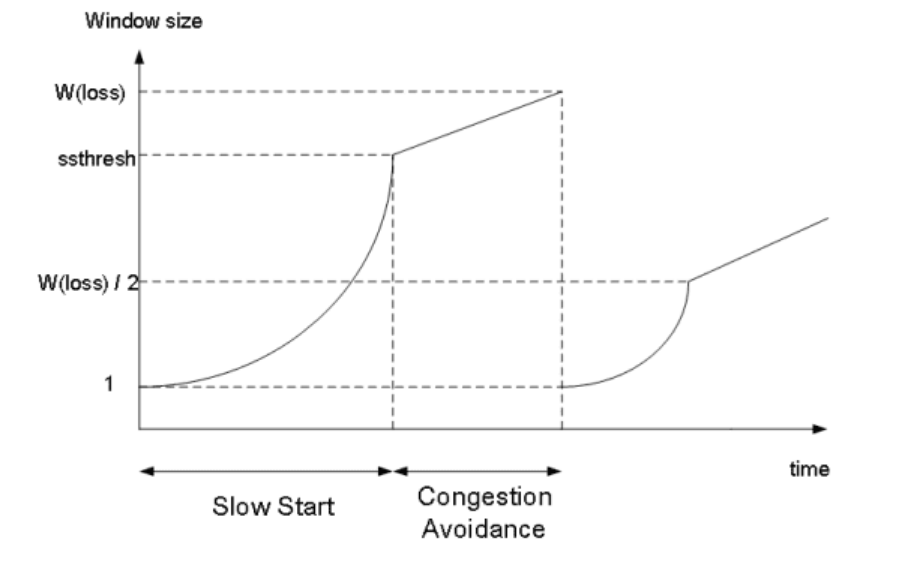
Slow Start (느린 시작)
-
윈도우의 크기를 1, 2, 4, 8... 과 같이 2배씩 증가시킨다.
-
혼잡이 감지되면 윈도우 크기를 1로 줄여버린다.
-
시간이 지날수록
AIMD보다 빠르게 윈도우 크기를 증가시킨다.
🤚 임계점 (Threshold)
임계점은 여기까지만 Slow Start를 사용하겠다 라는 의미를 가진다.
slow start threshold (ssthresh) 라고도 한다.이 값을 사용하는 이유는 윈도우 크기를 지수적으로 증가시키다보면 크기가 기하급수적으로 늘어나 제어가 힘들어지기 때문이다.
따라서 전송 데이터의 크기가 임계점 (Threshold)에 도달하면 선형적으로 1씩 윈도우를 증가시킨다.
빠른 재전송 (Fast Retransmit)
패킷을 받는 수신자 입장에서는 세그먼트로 분할된 내용들이 순서대로 도착하지 않는 경우가 생길 수 있다.
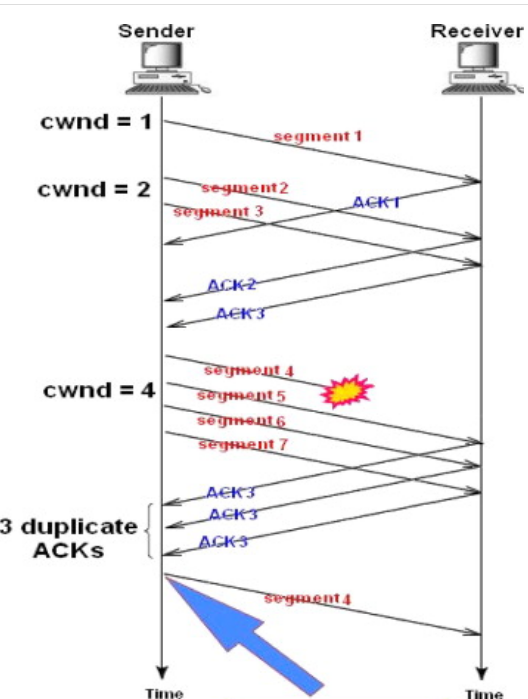
예를들어 1, 2, 3, 4, 5... 번의 데이터가 순서대로 와야하는데 2, 3 다음 5번이 온 것이다.
이런 상황이 발생했을 때 수신측에서는 순서대로 잘 도착한 마지막 패킷의 다음 순번을 ACK 패킷에 실어서 보낸다. 그리고 이런 중복 ACK를 3개 받으면 재전송이 이루어진다.
송신 측은 자신이 설정한 타임아웃 시간이 지나지 않았어도 바로 해당 패킷을 재전송할 수 있기 때문에 보다 빠른 전송률을 유지할 수 있다.
참고로, 송신측에서 설정한 타임아웃 까지 ACK를 받지 못하면 혼잡(Congestion)이 발싱한 것으로 판단하여 혼잡 회피를 한다.
빠른 회복 (Fast Recovery)
빠른 회복은 혼잡한 상태가 되면 윈도우 크기를 1로 줄이지 않고 반으로 줄이고 선형증가시키는 방법이다. 이 방법을 적용하면 혼잡 상황을 한번 겪고 나서부터는 AIMD 방식으로 동작한다.
TCP 혼잡 제어 정책
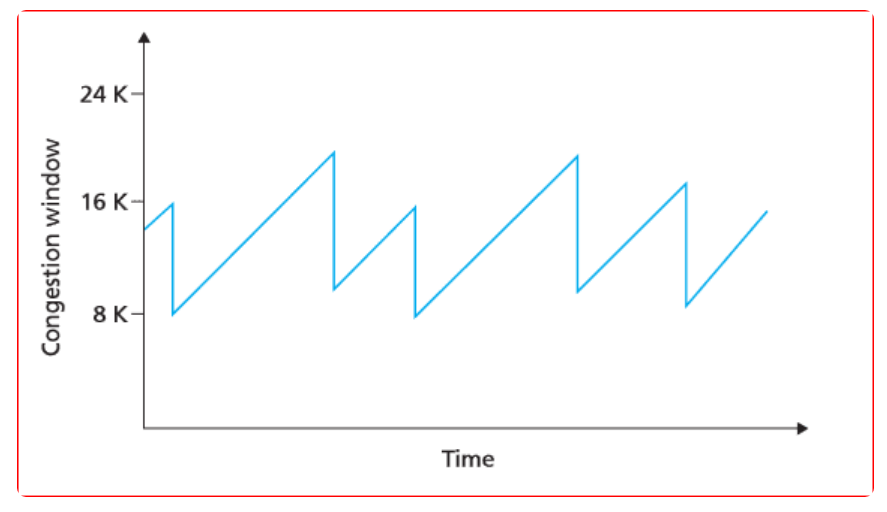
TCP Tahoe
TCP Tahoe는 처음에는 Slow Start를 사용하다가 임계점에 도달하면 AIMD 방식을 사용한다. 그러다가 3 ACK Duplicated 또는 타임아웃이 발생하면 혼잡이라고 판단하여 임계점은 혼잡이 발생한 윈도우 크기의 절반으로, 윈도우 크기는 1로 줄인다.
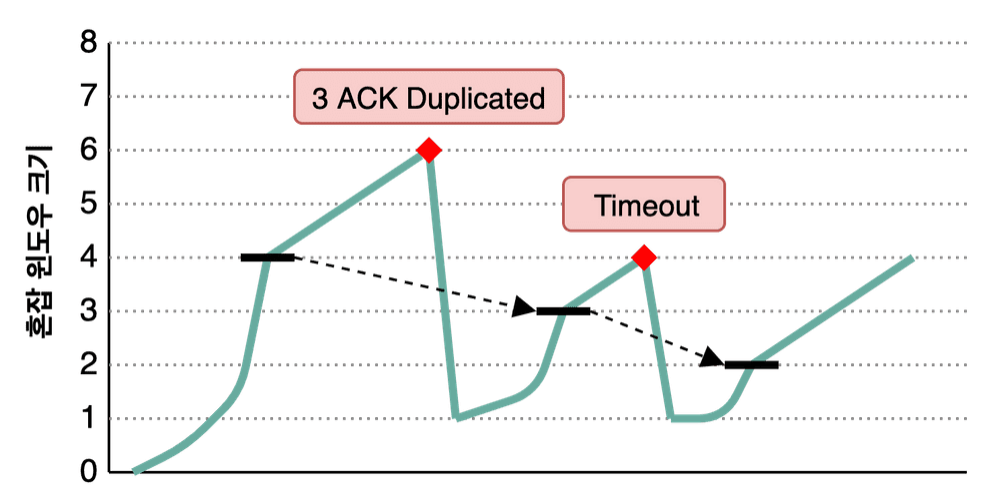
위 그래프에서 청록색 선은 송신 측의 혼잡 윈도우 크기를, 굵은 검정선은 ssthresh 값을 보여주고 있다.
이 방식은 혼잡 이후 Slow Start 구간에서 윈도우 크기를 키울 때 너무 오래걸린다는 단점이 있다. 1부터 키워나가야 하기 때문이다.
그래서 나온 방법이 빠른 회복 방식을 활용한 TCP Reno 이다.
TCP Reno
TCP Tahoe와 마찬가지로 Slow Start로 시작하여 임계점을 넘어가면 AIMD 방식으로 변경한다.
TCP Tahoe와의 차이점은 바로 3 ACK Duplicaed와 타임아웃을 구분한다는 점이다. TCP Reno는 3 ACK Duplicated가 발생하면 빠른회복 방식을 사용한다.
즉, 윈도우 크기를 1로 줄이는 것이 아니라 반으로 줄이고 윈도우 크기를 선형적으로 증가시킨다. 그리고 임계점을 줄어든 윈도우 값으로 설정한다.
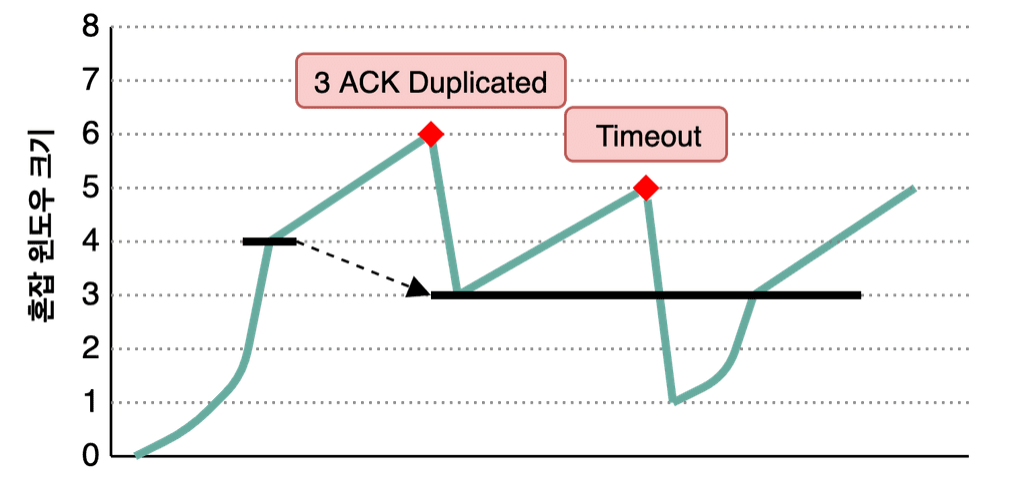
만약, 타임아웃이 발생하면 TCP Tahoe와 마찬가지로 윈도우 크기를 1로 줄이고 Slow Start를 진행한다. 이때는 임계점을 변경하지 않는다.
그 외
최근에는 아래와 같은 방법을 많이 사용한다고 한다.
- CUBIC
- RED
- Elastic TCP
참고한 곳
https://evan-moon.github.io/2019/11/26/tcp-congestion-control/#tcp-tahoe
