가비지 컬렉션 기본 개념
가비지 컬렉션이란
가비지 컬렉션 이란 메모리 관리 기법중 하나로 프로그램이 동적으로 할당했던 메모리 영역 중에서 필요없게 된 영역을 해제하는 기법이다.
예를들어 아래 코드를 보자.
public void go() {
Person p = new Person();
p.walk();
}go() 메소드가 실행될 때 새로운 Person 객체 하나가 메모리에 할당된다.
이후 go() 메소드가 끝까지 실행되었다면?
go() 메소드에서 생성한 Person 객체에 더 이상 접근할 방법이 없다.
하지만 메모리의 Heap 영역에는 그대로 남아있는 상태이다.
Person 객체는 더 이상 코드 어디에서도 접근할 수 없는 쓸데없이 메모리만 차지하는 객체가 되었다. 따라서 차지하고 있던 메모리 영역을 해제시켜 주는 작업이 필요한데 이 작업을 바로 가비지 컬렉션 이라고 한다.
가비지 컬렉션의 종류
Reference Counting
Reference Counting 은 객체를 참조하는 레퍼런스의 개수를 저장하여 이 개수가 0이 되었을 때 메모리에서 해제하는 방법이다.

이 방법은 구현하기 쉽고 빠르다는 장점이 있지만, 순환참조가 생겼을 때는 이를 탐지하지 못하고 가비지 컬렉션 을 실행시키지 않는다는 단점이 있다.
순환 참조란 아래와 같은 경우를 말한다. 이 경우 메소드가 수행이 된 후에 레퍼런스 카운트 가 0이 아니라 1이다.
public void go() {
Car c = new Car();
Person p = new Person();
// car, person 사이에서 순환참조 발생
car.person = p;
person.car = c;
}Mark and Sweep
Mark and Sweep 이란 시작 노드(Root)에서 부터 시작하여 참조할 수 있는 객체들을 탐지해 내려가며 Mark 한다. 그리고 Mark 가 끝나면 힙 내부를 돌면서 Mark 되지 않은 메모리들을 해제(Sweep)한다.
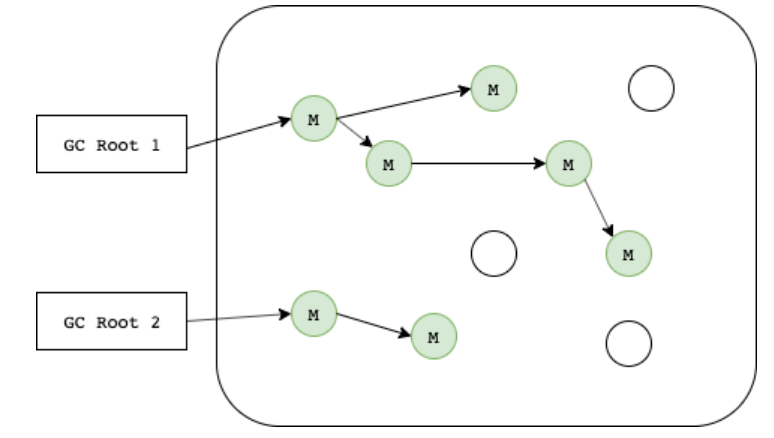
GC Root가 될 수 있는 것들은 아래와 같다.
- Java 스택, 즉 Java 메서드 실행 시에 사용하는 지역 변수와 파라미터들에 의한 참조
- 네이티브 스택, 즉 JNI에 의해 생성된 객체에 대한 참조
- 메서드 영역의 정적 변수에 의한 참조
Mark and Sweep 방식은 순환참조 문제를 해결한다!
자바에서 GC의 동작 방식
Heap 메모리 구조
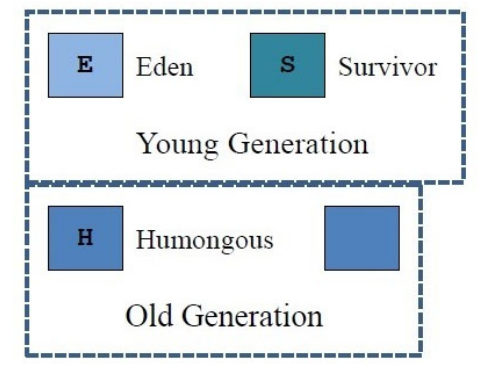
Heap은 크게 2개의 물리적 공간으로 나뉘어져 있다. 둘로 나눈 공간이Young 영역과 Old 영역이다.
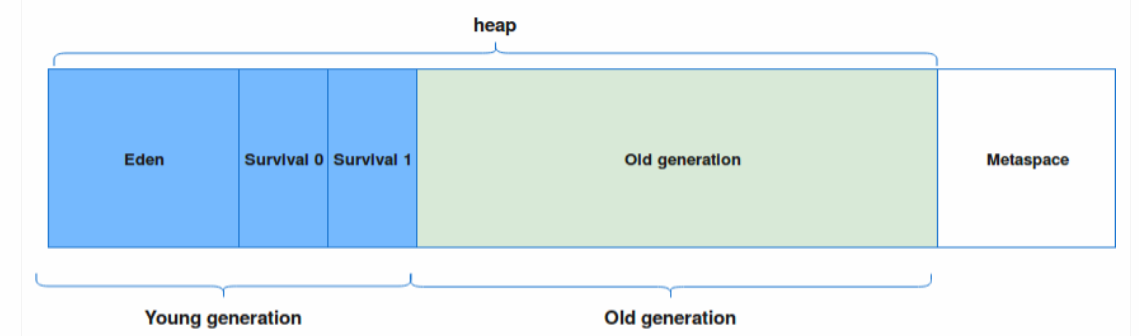
-
Young 영역
새롭게 생성한 객체의 대부분이 여기에 위치한다. 대부분의 객체가 금방 접근 불가능 상태가 되기 때문에 매우 많은 객체가 Young 영역에 생성되었다가 사라진다. 이 영역에서 객체가 사라질때Minor GC가 발생한다고 말한다. -
Old 영역
접근 불가능 상태로 되지 않아 Young 영역에서 살아남은 객체가 여기로 복사된다. 대부분 Young 영역보다 크게 할당하며, 크기가 큰 만큼 Young 영역보다 GC는 적게 발생한다. 이 영역에서 객체가 사라질 때Major GC(혹은 Full GC)가 발생한다고 말한다.
GC를 실행할 때 GC를 실행하는 쓰레드 이외에 모든 쓰레드는 작업을 멈추는데 이를 stop-the-world 라고 한다.
Young 영역에 대한 GC
Young 영역은 또다시 Eden, Survivor 영역(2개)로 나뉘어진다.
Young 영역의 가비지 컬렉션 절차는 다음과 같다.
- 새로 생성한 대부분의 객체는 Eden 영역에 위치한다.
- Eden 영역에서 GC가 한 번 발생한 후 살아남은 객체는 Survivor 영역 중 하나로 이동된다.
- Eden 영역에서 GC가 발생하면 이미 살아남은 객체가 존재하는 Survivor 영역으로 객체가 계속 쌓인다.
- 하나의 Survivor 영역이 가득 차게 되면 그 중에서 살아남은 객체를 다른 Survivor 영역으로 이동한다. 그리고 가득 찬 Survivor 영역은 아무 데이터도 없는 상태로 된다.
- 이 과정을 반복하다가 계속해서 살아남아 있는 객체는 Old 영역으로 이동하게 된다.
Card Taable
Card Table이란 Old 영역의 메모리를 대표하는 별도의 메모리구조이다.(실제로 Old 영역의 일부는 Card Table로 구성됨) 만약 Young 영역의 객체를 참조하는 Old 영역의 객체가 있다면 해당 Old 영역의 객체의 시작주소에 카드를 Dirty로 표시하고 해당 내용을 Card Table에 기록한다.
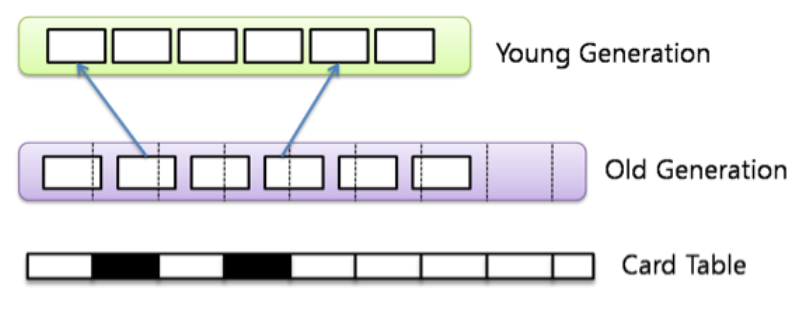
이후 해당 참조가 해제되면 표시한 Dirty Card도 사라지게끔 하여 참조 관계를 쉽게 파악할 수 있게 한다.
이러한 Card Table 덕분에 Minor GC 과정에서 Card Table의 Dirty Card만 검색하면 빠르게 Old 영역에서 참조되는 Young 영역의 객체를 알 수 있다. 참고로 Card Table은 Old 영역 512byte당 1byte의 공간을 차지한다고 한다.
Old 영역에대한 GC
Serial GC
하나의 CPU로 Young 영역과 Old 영역을 연속적으로 처리한다.
컬렉션이 수행될 때 애플리케이션이 정지된다.
Young 영역에서의 GC는 앞에서 설명한 방식으로 동작한다.
Old 영역의 GC는 mark-sweep-compact 라는 알고리즘을 사용한다.
이 알고리즘의 첫 단계는 Old 영역에 살아있는 객체를 식별(Mark)하는 것이다. 이후 Old 영역을 스캔하여 살아있는 것만 남긴다(Sweep). 마지막 단계에서는 각 객체들이 연속되게 쌓이도록 힙의 가장 앞 부분부터 채운다.
Serial GC는 적은 메모리와 CPU 코어 개수가 적을 때 적합한 방식이다.
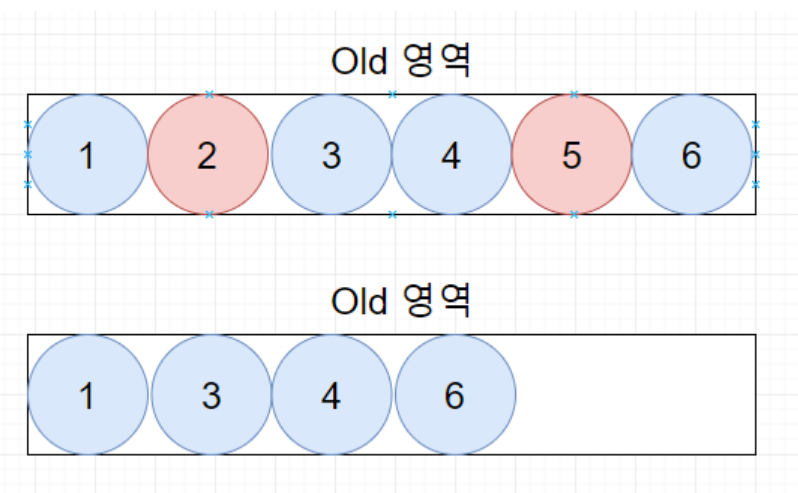
Parallel GC
Parallel GC 의 목표는 다른 CPU가 GC의 진행시간 동안 대기 상태로 남아 있는 것을 최소화 하는 것이다.
Serial GC 의 Young 영역에서 진행하는 컬렉션을 병렬 방식으로 처리하여 GC의 부하를 줄이고 성능을 향상시킬 수 있다.
또한, -XX:+UseParallelOldGC 옵션을 사용한다면, old generation 의 가비지 컬렉션에서도 멀티스레딩을 활용할 수 있다.
CMS(Concurrent Mark Sweep) GC
Young 영역에 대한 처리 방법은 Parallel GC 의 방식과 동일하다.
Old 영역에 대해서는 다음의 네 단계를 따른다.
- Initial Mark
- 애플리케이션 일시 정지(stop-the world)
- GC에 싱글 스레드를 사용.
- 애플리케이션의 Root set과 직접적으로 관계가 살아있는 객체만 마크한다. 따라서 멈추는 시간이 매우 짧다.
- Concurrent Mark
- GC 스레드는 GC 작업을 하고, Working 스레드는 애플리케이션 작업을 한다.
- GC에 싱글 스레드를 사용
- 바로 전 단계에서 체크한 객체에서 참조하고 있는 객체들을 추적해 살아있는 마크한다.
- Remark
- 애플리케이션 일시 정지(stop-the world)
- GC에 멀티 스레드 사용
- 마크한 객체를 다시 추적해 새로 추가되거나 참조가 끊긴 객체를 확인한다.
- Concurrent Sweep
- 애플리케이션은 멈추지 않고 작업을 계속 한다.
- GC에 싱글 스레드 사용
- Sweep: 살아있는 객체를 제외한 죽은 객체를 모두 삭제한다.
- Compaction은 하지 않는다.
- 따라서 Sweep을 하다보면 단편화가 발생한다.
- 다른 옵션을 사용해 메모리를 모아주는 작업이 필요하다.
Serial GC와 비교한 그림은 다음과 같다.
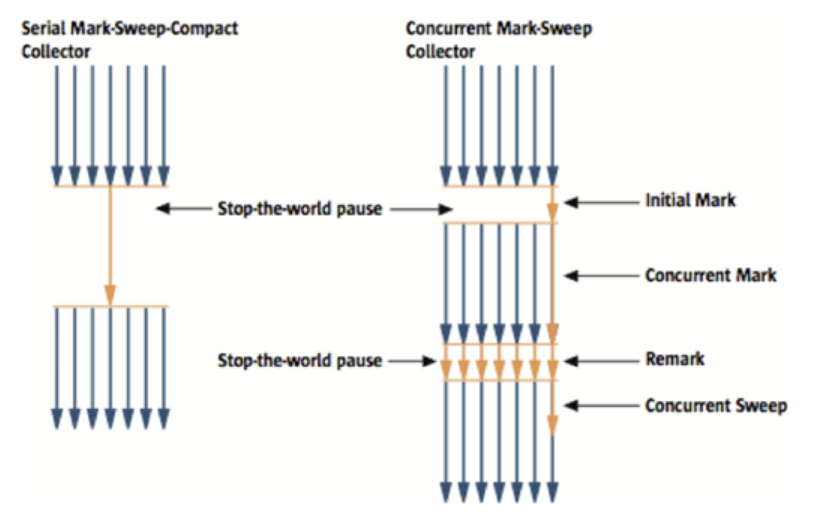
이러한 방식으로 진행되는 GC 방식이기 때문에 stop-the-world 시간이 매우 짧다. 따라서 응답속도가 중요한 애플리케이션에서 주로 사용한다.
그런데 CMS GC는 stop-the-world 시간이 짧다는 장점에 반해 다음과 같은 단점이 존재한다.
- 다른 GC 방식보다 메모리와 CPU를 더 많이 사용한다.
- Compaction 단계가 기본적으로 제공되지 않는다.
- GC 풀 사이클 자체는 Parallel GC 보다 길다.
따라서, CMS GC를 사용할 때에는 신중히 검토한 후에 사용해야 한다. 그리고 조각난 메모리가 많아 Compaction 작업을 실행하면 다른 GC 방식의 stop-the-world 시간보다 stop-the-world 시간이 더 길기 때문에 Compaction 작업이 얼마나 자주, 오랫동안 수행되는지 확인해야 한다.
G1(Garbage First) GC
G1 GC 는 장기적으로 말도 많고 탈도 많은 CMS GC 를 대체하기 위해서 만들어 졌다.
G1 GC 를 이해하기 위해서는 기존에 사용했던 방식인 heap 메모리를 young 영역과 old 영역으로 나누는 개념을 잊어야 한다. 대신, region 이라는 개념을 새로 도입했다.
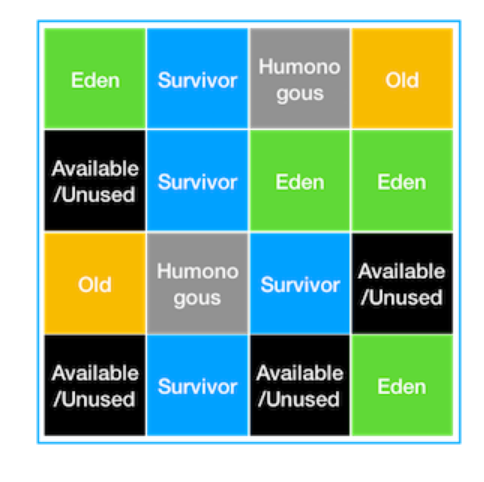
큰 자바 heap 공간을 고정된 크기의 region으로 나눈다. 메모리 공간이 필요해지면 free region은 young 영역이나 old 영역으로 할당한다. region의 크기는 1MB 에서 32MB로 전체 heap 사이즈 용량이 2048개의 region으로 나누어 질 수 있도록 하는 범위 내에서 결정된다. region이 비어지면 이 region은 다시 free region 리스트로 돌아간다.
G1 GC 의 기본 원리는 자바 heap 메모리를 회수할 때 최대한 살아 있는 객체가 적게 들어있는 region을 수집하는 것이다. (목표 정지시간에 최대한 부합하게 하며)
G1 GC 는 Young 영역과 Old 영역이 존재하나, 고정된 크기와 위치로 존재하지 않는다. 가장 살아있는 객체가 적을 수록 쓰레기란 의미고 따라서 이름도 쓰레기 우선 수집이란 이름이 붙게되었다.
G1 GC 에서 중요한 점은, 전통적인 GC의 힙 구조와는 달리 Young 영역이나 Old 영역이 인접해 있지 않다는 것이다. 이는 영역의 사이즈가 필요에 따라서 동적으로 바뀔 수 있다는 점에서 편리하다.
G1 GC 알고리즘은 기존 GC의 기본적인 개념을 활용한다. 예를들어 Survivor 영역으로 카피하고, Old 영역으로 이동하는 등의 개념은 기존 GC(Hotspot GC)의 구현과 비슷하다. Eden Region과 Survivor Region이 여전히 Young 영역을 만든다. 무지하게 큰 메모리 할당이 아닌 경우 대부분의 할당은 Eden에서 발생한다. 만약 객체가 region 영역의 크기보다 1/2 보다 큰 경우 Humongous region을 사용한다. (Humongous region에 대한 GC 동작은 최적화 되어있지 않다.)
G1 GC 수행 단계
G1 GC 수행 과정은 Evacuation Pauses(=Minor GC), Concurrent Cycle, Mixed GC가 있다.
Evacuation Pauses(=Minor GC)
-
Evacuation Pauses(=Minor GC)일 때 eden과 survivor에 있는 유효 객체(Live objects)를 적절한 region을 찾아 대피시키도록(Copying) 한다.
-
Evacuation Pauses(=Minor GC)일 때 GC 대상의 region 선택은 사용자가 옵션으로 지정한 pause time과 G1 GC 내부에서 사용하는 휴리스틱 알고리즘에 의해 선택된다. 그 이유는 G1 GC의 중요한 목표 중 하나는 실시간성 향상에 있기 때문이다.
-
Evacuation Pauses는 빨리 완수하기 위해 JVM에서 Multi-threaded로 동작한다.
-
Young Generation Stop-the-world 구간이다. (CMS와 다름)
-
Survivor region은 liveness objects를 판단하기 위해, Eden region은 pause time을 예측하는데 사용된다.
-
minor GC 때마다 Eden과 Survivor 영역 크기는 변경될 수 있다.(CMS와 다름.)
-
Eden에 있는 live object는 Survivor 영역으로, Survivor from은 Survivor to로, Survivor to는 Old 영역으로 이동한다는 내용이 있는 반면, 유효 객체(live objects)가 Available/Unused region으로 이동되고, survivor region으로 바뀐다는 내용도 있다. (전자가 맞는 듯 하다. 기존 Generation 기반 GC 개념 자체를 바꿀 필요가 없을 테니까..)
-
논문에서는 첫 Evacuation Pauses는 일정 용량이상 차면 수행 되고, 그 이후에는 사용자가 지정한 pause duration과 per-byte copying Cost에 의해 결정된다고 한다. 얼마나 많은 Live object를 to-survivor regions에 복사할지 추정하는데 단위 바이트당 소요될 Cost와 pause duration P의 곱이 제한 시간 내 복사할 수 있는 용량으로 산정해서 동작한다.
-
각 region에는 Live Data Counting 정보를 가지고 있다. 이 정보를 바탕으로 region 영역이 먼저 Garbage 되어야 하는지 결정된다.(그래서 이름이 Garbage First, G1 이다).
-
External Root Scanning: gc thread들이 registers, thread stacks에서 root 노드를 검색하는 단계
-
Update Remembered Sets: RSet 정보를 갱신하는 단계
-
Processed Buffers: worker thread가 얼마나 많은 update 버퍼 정보를 갱신했는지 보여준다.
-
Scan Rsets: 업데이트 된 Rset 정보를 기반으로 region을 향해 가진 reference를 가진 객체들을 탐색한다.
-
Object Copy: Scan Rsets에서 탐색한 객체들을 복사하기 시작한다. Eden에 있는 객체들을 from-space로, from-space에 있는 객체들을 to-space로, to-space에 있던 객체들을 Old 영역으로 복사한다.
-
Termination: GC thread들은 객체 탐색 및 객체 복사의 일이 끝나면 Termination 단계에 들어간다. Task 처리의 로드밸런싱 효율을 높이기 위한 방법으로 Work-stealing 기법을 사용하고 있다.
-
Parallel Worker Other time: 위에서 언급한 일 이외의 다른 부수적인 일을 처리한 시간
Concurrent Cycle
-
Old 영역을 GC하기위한 전초 작업이다.
-
initial mark: multi-threaded로 동작하며, minor GC때 수행 한다. (CMS와 다름. CMS에서 initial mark는 stop-the-world 구간이다.)
-
Root region Scanning: multi-threaded로 동작하며, Application과 Concurrent하게 동작한다. 이때 Old 영역으로 reference를 가진 survivor-regions을 검색한다. 이 단계가 끝나야 Evacuation Pauses(Minor GC)가 동시에 실행될 여지가 발생한다.(Survivor regions 영역은 Evacuation Pauses(Minor GC)에서도 탐색하기 때문)
-
Concurrent marking: multi-threaded로 동작하고, Application과 Concurrent하게 동작한다. 모든 reachable / live 객체들을 마킹한다. 이 때부터 Evacuation Pauses와 동시에 실행 가능하다.
-
Remark: Stop-the-world 구간이다. multi-threaded로 동작한다. marking 작업을 마무리.
-
Cleanup: Partly Stop-the-world 구간이다. multi-threaded로 동작한다. region 영역의 liveness 정보를 갱신하고, 적절한 free region을 식별한다. 논문에 의하면 Cleanup 할 때, 각 region의 GC 효율을 기준으로 정렬하는데(G1 first, cost efficiency), GC 효율 측정 factor에 remember set의 size등을 고려하는데 이러한 작업을 하기 위한 기본 데이터 값들을 정리한다.
-
Concurrent-Cleanup: empty region 자료구조를 Reset하고, available/Unused regions list에 추가한다.
Mixed GC
-
이 이전까지는 G1 GC가 Old 영역에 해당하는 region의 marking 정보를 들고 있지 않았기 때문에 Old 영역의 GC가 불가능 했다. Old 영역을 Compacting하고 비우는게 가능한 Collection 작업은 G1 GC 에서는 mixed GC라고 부른다.
-
Mixed GC일 때 Young영역과 Old 영역을 Garbage collection 한다.(단어에서 의미하듯 Mixed이다.)
-
Old region 영역의 GC 선택 기준은 liveness를 기준으로 판단한다. Garbage Collection 효율을 높이기 위해 liveness가 높은 것은 재사용될 가능성이 높다고 판단하기에 liveness가 적은 것을 GC하도록 한다.(따라서 Garbage First, G1이라는 이름이 붙었다.)
-
Mixed GC는 기본적으로 8회 수행되도록 되어 있다. 1회의 Mixed GC에 모든 Old 영역이 Garbage collection되지 않는다. 한번에 Garbage를 정리하기에 Cost가 매우 크기 때문이다.
minor GC 처럼 Eden과 Survivor 영역 크기는 변경될 수 있다. -
Mixed GC는 Evacuation Pauses때 수행하는 단계와 동일하다. Evacuation Pauses인데 Old region을 추가적으로 GC 하는 것이다. Mixed GC = Evacuation Pauses(Young GC + Old GC)
G1 GC 에서 사용하는 자료구조
-
Remember Set (RSet)
- reference를 가진 Object들이 어느 Region에 있는지 알기 위해 사용하는 자료구조다. (이 Reference를 왜 알아야 하냐면 Live Object을 알기 위함이다. Object가 가진 Reference의 Origin을 왜 알아야 하는지는 Baker's Incremental GC 알고리즘을 이해하자. 참고자료는 Baker's Incremental Copying Collector 알고리즘, 간략히 이야기하면 Reference를 가진 Objects를 찾아 live object를 복사하는 알고리즘이다. Baker's에서는 live object 검색 시간이 O(n)*rootset 의 시간 복잡도가 걸리지만, Rset을 사용해서 개선 시킬 수 있다.)
-
Collection Set (CSet)
-
GC가 수행될 Region의 모음.
-
GC 로그에서 CSet을 선택하고, Processing 후 CSet을 해제하는데 걸린 시간을 볼 수 있다. Evacuation Pauses와 Mixed GC할 때 사용하는 자료구조이다.
-
G1 GC 정리
-
기존 GC가 Space based 동작이라면 G1 GC는 Time based 동작으로 적시에 GC를 수행할 수 있게 되었다.
-
Young 영역에 대한 GC 시작은 사용자가 지정한 Pause time에 의해 휴리스틱하게 결정된다. Young 영역에서 GC할 CSet의 선택도 역시 Pause time에 영향 받는다. GC 수행 종료 시점도 마찬가지로 Pause time에 종속된다.
-
Concurrent Cycle은 Old 영역을 GC하기 전에 필요한 정보를(region별 gc cost, 객체 liveness count) 얻기 위해 수행한다. Mixed GC의 전 작업이다.
-
Old 영역에 대한 GC 수행 시작은 IHOP(heap 사용률의 임계점)이 결정한다.
-
Old 영역 GC 수행시 선택될 CSet은 다음 두 옵션에 의해 영향 받는다.
- XX:G1MixedGCCountTarget (defaults to 8): Mixed GC 최소 수행 작업 횟수
- XX:G1OldCSetRegionThresholdPercent (defaults to 10): Mixed GC 수행시 선택할 최대 Old region 개수, 자바 Heap의 Percentage로 값을 설정한다.
-
CMS의 경우 Eden, Survivor 영역의 크기는 고정되어 있지만, G1은 GC이전과 GC이후에 각 영역의 Size는 변동(Adaptable) 될 수 있다.
-
기존 Young, OLD 컨셉을 버리고 Region으로 나누고 Region별 live object정도를 판단함으로써 더 명확한 Garbage 객체 결정을 할 수 있게 되었다. 또한 프로그램 구조적으로 Parallel, Concurrent하게 동작하기에 용이한 구조이기에 Multi Processor에 사용하기 적합한 구조이다. 이와 더불어 GC 시점과 대상에 대한 휴리스틱한 알고리즘을 넣음으로써 High allocation Rate, Large Heap을 요구하는 Application의 요구사항을 충족시켜줄 수 있게 되었다.
-
Collection 단계를 Evacuation, Concurrent Cycle, Mixed GC 단계로 나눈 이유
- CMS 혹은 Parallel GC같은 기존의 GC 수행 형태는 Minor GC와 Old(Major) GC 이 두 단계로 나눌 수 있다. 최대한 Concurrent 그리고 Parallel하게 동작하기 위해 기존의 Old GC의 단계를 Concurrent Cycle(GC 객체 검색 및 마킹:Scanning and Mark)과 Mixed GC(GC 수행 및 정리:Evacuation and Cleanup) 이 두 단계로 분리한 것이다. G1 GC에서 Concurrent Cycle은 Minor GC와 동시에 수행이 가능하다.(단 Root region scanning 이후에 가능하다.) 그리고 Concurrent Cycle이 끝나면 이때 Marking한 정보를 기반으로 Mixed GC가 수행된다.
-
Snapshot At The Begging(SATB): 논문에서 SATB란 단어가 나오는데, 이 단어의 의미는 특정 순간의 내용을 기록한다는 의미이다. G1 GC에서는 IHOP이 넘는 그 순간에 Concurrent Cycle을 시작해서 Snapshot을 찍고(Old 영역의 GC할 대상을 찾아 기록함) Mixed GC에서 SATB에서 정리한 정보를 바탕으로 Old region garbage collection이 연속(기본 8회) 수행된다. 당연하지만 Mixed GC때 Young 영역의 region도 같이 Garbage collection된다.
레퍼런스
https://d2.naver.com/helloworld/1329
https://yaboong.github.io/java/2018/06/09/java-garbage-collection/
https://johngrib.github.io/wiki/jvm-memory/
https://velog.io/@agugu95/%EC%9E%90%EB%B0%94-GC-Garbage-Collection
https://b.luavis.kr/server/g1-gc
https://initproc.tistory.com/entry/G1-Garbage-Collection
