1. 학습목표

2. 학습내용
2-1. "robots.txt"를 통해서 대상 웹 페이지 조건 확인
웹사이트 마다 "robots.txt"파일을 통해서
클로링 불가한 부분을 표시하고 있다
- 루트 이하 모두 크롤링 금지하는 사이트
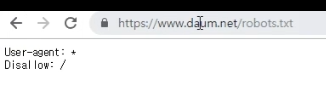
- 특정 디렉터리 하위만 금지하는 사이트
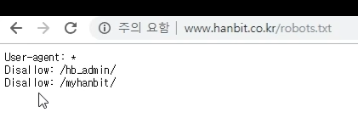
2-2. 크롤러 분류
- 상태유무
- 어떤 데이터는 로그인해야만 보임
- Javascrtip 유무 (ajax 등으로 비동기적으로 렌더링 하는)
- javascript로 데이터를 보여주는 경우, 셀레니움과 같은 다른 엔진을 사용해야 함
2-3. Request 요청 주의 할 점! 중요!
- request 요청시 주의 할 점은! 서버부하 고려! 중요!!
- 크롤링 타임을 여유있게 (사람의 보는 것처럼) 조절할 필요가 있다!
2-4. 콘텐츠 저작권 문제
- 라이센스 확인 필요!
2-5. 페이지 구조 변경 가능성 숙지
- 구조 변경 가능성 숙지! 중요!
기타
- 요즘은 사이트들에서 크롤링을 위한 "data api"를 제공한다
- 그러니, 되도록이면 먼저 data api 유무를 먼저 확인하자!
3. 느낀 점

#의식의흐름 #순간순간 #생각의스냅샷