🔗 Stream 의 등장 배경
Java의 Stream API는 Java 8에서 처음 도입되었다.
이전의 Java 버전들에서는 대량의 데이터 처리 작업을 효율적으로 수행하기 위해
외부 반복을 사용했었는데,
외부 반복은 개발자가 명시적으로 데이터 컬렉션을 반복하는 코드를 작성해야 한다는 단점이 있었다.
이는 코드가 길어지고 복잡해지며 (보일러 플레이트 코드의 증가),
멀티코어 환경에서의 병렬 처리를 직접 관리해야 하는 어려움이 있다.
// java 8 이전의 반복문 예시
List<String> names = Arrays.asList("Steve", "John", "Jane", "Tom");
List<String> filteredNames = new ArrayList<>();
for (String name : names) {
if (name.startsWith("J")) {
filteredNames.add(name);
}
}
Collections.sort(filteredNames);
System.out.println(filteredNames); // [John, Jane]// java 8 이후의 반복문 예시
List<String> names = Arrays.asList("Steve", "John", "Jane", "Tom");
List<String> sortedFilteredNames = names.stream()
.filter(name -> name.startsWith("J"))
.sorted()
.collect(Collectors.toList());
System.out.println(sortedFilteredNames); // [Jane, John]
Stream API의 등장은 이러한 문제를 해결하기 위한 것으로,
내부 반복을 사용하여 데이터를 추상화하고 데이터 컬렉션을 효율적으로 처리할 수 있도록 도움을 준다.
내부 반복을 통해, 개발자는 무엇을 처리할지에 초점을 맞추고,
어떻게 처리할지는 라이브러리에 맡긴다. 이는
- 코드의 간결성을 높이고,
- 유지보수를 용이하게 하며,
- 병렬 처리를 자동으로 최적화할 수 있는 장점을 제공한다.
🔗 Stream API 의 기본 사용법
Stream API는 java.util.stream.Stream 인터페이스를 통해 사용할 수 있고,
컬렉션에 .stream() 메소드를 호출하여 스트림을 생성할 수 있다.
스트림을 사용하는 기본적인 패턴은 다음과 같다.
// 배열 정렬 후 출력 예시
List<String> strList01 = new ArrayList<>(Arrays.asList("B", "A", "E", "D", "C"));
// 생성
Stream<String> stream01 = strList01.stream();
// 중간 연산
Stream<String> sortedStream01 = stream01.sorted();
// 종단 연산
List<String> sorted01 = sortedStream01.toList();
System.out.println(sorted01); // [A, B, C, D, E]위는 하나하나씩 단계별로 나타낸 예시이고, 실제로는 아래와 같은 형태로 많이 사용된다.
// 배열 정렬 후 출력 예시
List<String> strList01 = new ArrayList<>(Arrays.asList("B", "A", "E", "D", "C"));
// 생성, 중간 연산, 종단 연산을 체이닝하여 작성
List<String> sorted01 = strList01.stream().sorted().toList();
System.out.println(sorted01);한 가지 알아두어야 할 점으로, Stream은 원본 데이터를 읽는 기능만 할 뿐 원본데이터 자체를 변경하지 않는다.
그렇기 때문에 원본 데이터가 변형될 걱정은 하지 않아도 된다.
또한 Java 8 Stream은 일회성이기 때문에 한 번 사용될 경우 재사용이 불가능하다.
즉 필요하다면 정렬된 결과를 배열 혹은 컬렉션에 담아 반환해야 한다.
Java 8 Stream도 기존 방식과 마찬가지로 작업을 내부적으로 반복하여 처리한다.
반복 코드는 메소드 내부에 숨어져 있어 코드 상에 노출이 되지 않아 더욱 깔끔한 비즈니스 로직을 설계할 수 있다.
❗ Stream 주의점
Stream 을 사용해봤다면, for-loop 으로 순회하는 것보다 성능이 떨어진다는 소리를 한 번쯤은 들어봤을 것이다. loop와 순차 스트림(sequential stream), 그리고 병렬 스트림(parallel stream) 별로 퍼포먼스가 어떤지 벤치마크 실험을 아래 링크를 각색하여 재현해 보았다.
✏️ for-loop vs 순차 스트림
아래 예시는 50만개의 랜덤 정수 primitive type 배열을 생성하고,
각각 for-loop 와 stream 을 사용해 배열 내 최대값을 구하는 실행시간을
출력하는 코드이다.
// 50만개의 랜덤 정수 primitive type 배열 생성
int[] ints = new int[500000];
Random rand = new Random();
for (int i = 0; i < ints.length; i++) {
ints[i] = rand.nextInt();
}
// for-loop
int m = Integer.MIN_VALUE;
long forLoopStartTime = System.nanoTime();
for (int i = 0; i < ints.length; i++) {
if (ints[i] > m) {
m = ints[i];
}
}
long forLoopEndTime = System.nanoTime();
System.out.println("Maximum value found: " + m);
System.out.println("Execution time (for-loop): " + (forLoopEndTime - forLoopStartTime) + " nanoseconds");
// sequential stream
long streamStartTime = System.nanoTime();
int max = Arrays.stream(ints).reduce(Integer.MIN_VALUE, Math::max);
long streamEndTime = System.nanoTime();
System.out.println("Maximum value found: " + max);
System.out.println("Execution time (Stream): " + (streamEndTime - streamStartTime) + " nanoseconds");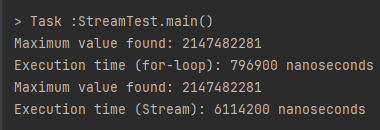
10번 이상의 테스트를 직접 진행해 보았고, 보수적으로
- for-loop : 800,000 ns (0.0008s, 0.8ms)
- Stream : 6,000,000 ns (0.006s, 6ms)
가 평균치로 측정되었다. 50 만건의 원소를 기준, 대략적으로 Stream 이 7~8 배 느린 것으로 판단된다.
primitive type 이 아닌 wrapped type 으로 진행해보자.
ArrayList<Integer> ints = new ArrayList<>(500000);
Random rand = new Random();
// ArrayList로 50만개의 무작위 정수 초기화
for (int i = 0; i < 500000; i++) {
ints.add(rand.nextInt());
}
// for-loop
int m = Integer.MIN_VALUE;
long forLoopStartTime = System.nanoTime();
for (int i = 0; i < ints.size(); i++) {
if (ints.get(i) > m) {
m = ints.get(i);
}
}
long forLoopEndTime = System.nanoTime();
System.out.println("Maximum value found: " + m);
System.out.println("Execution time (for-loop): " + (forLoopEndTime - forLoopStartTime) + " nanoseconds");
// sequential stream
long streamStartTime = System.nanoTime();
int max = ints.stream().reduce(Integer.MIN_VALUE, Math::max);
long streamEndTime = System.nanoTime();
System.out.println("Maximum value found: " + max);
System.out.println("Execution time (Stream): " + (streamEndTime - streamStartTime) + " nanoseconds");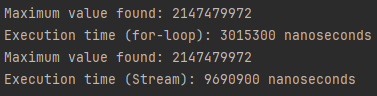
보수적으로
- for-loop : 3,000,000 ns (0.003s, 3ms)
- Stream : 9,500,000 ns (0.0095s, 9.5ms)
가 평균치로 측정되었다. Primitive type 에서 50 만건의 원소를 기준, 대략적으로 Stream 이 이전과는 달리 3배 정도만 더 소요되는 것으로 확인된다.
기본적으로 for-loop 문을 순회하는 것이 Stream 보단 성능이 우월하다.
특히 Stack 메모리에 직접 접근이 가능한 Primitive Type 인 경우에는 더 뛰어나다.
Heap 메모리에 간접적으로 접근하는 Wrapper 타입도 살펴보자.
위에서 언급했던 강의 영상에서는 Wrapper Type 으로 테스트 했을 경우에는 for-loop 문과 Stream 의 성능 차이가 1.3배 밖에 차이나지 않았다고 언급되었지만, 내 로컬 환경에서는 여전히 3배 정도의 차이가 발생했다.
더 많은 데이터의 양에는 어떨까 싶어 5,000 만개의 원소로 변경해 보았다.
50 만개로 테스트했을 경우와 비슷한 비율을 보인다.
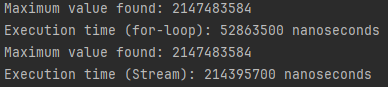
데이터의 양이 적을 때를 비교하기 위해 50개의 원소로 다시 테스트 해 보았다.
primitive type 기준 300 배의 소요시간 차이를 보인다.
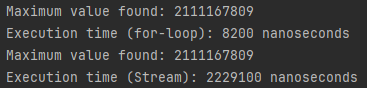
항상 강의를 신뢰하지는 말고, 직접 테스트해보며 검증하자.
강의 영상에서 테스트하며 보여준 것은 강의에서 사용된 로컬 환경일 뿐이고, 주관적인 견해가 들어가 있을 수 있다.
✏️ Stream 이 느린 결정적인 이유
Stack 메모리에 간접적으로 접근하는 방식으로 변경하였는데도 여전히 Stream 이 느리다.
특히 적은 데이터셋 일수록 더 큰 차이를 보이는데,
이는 Stream 을 활용하는 것 자체가 오버헤드를 발생시키며,
계산 과정 자체도 for-loop 문보다 더 느리다는 것을 알 수 있다.
그 원인을 알아보자.
1. for-loop 문은 JVM 이 최적화하기에 더 적합하다.
- 전통적인 for-loop 방식은 초창기부터 사용되며 충분히 옵티마이징이 된 상태이므로, Java 8 에서부터 도입된 Stream 에 비해 더 효율적으로 작동한다.
- 참고로 테스트한 Java 버전은 17이다.
2. Stream 의 오버헤드
- Stream pipeline 을 구성할 때, 각 연산(filtering, mapping, reducing 등)은 각각의 스테이지를 생성하고, 이러한 스테이지는 내부적으로 추가적인 함수 호출과 컨텍스트 전환을 필요로 한다. 즉, 연산 자체에 오버헤드를 발생시킨다.
- 메모리 사용: 스트림은 내부적으로 여러 중간 상태를 생성할 수 있다. 이는 추가적인 메모리 할당과 GC 부하를 초래할 수 있다. 반면 for-loop는 상대적으로 메모리를 덜 사용하고, 가비지 컬렉션에 덜 영향을 받는다.
라는 것이 순차 스트림에서의 내 결론이다.
✏️ 병렬 스트림의 짧은 소개와 결론
앞서 Stream 은 병렬 처리 관리에 더 쉽다는 소개를 했었다.
병렬 처리를 할 수 있다는 것은, 더 많은 자원을 소모하더라도 그 만큼 빠른 처리를 할 수 있다는 것이 일반적인 상식이다.
단순히 이론만 보자면, 순차 스트림에 비해 병렬 쓰레드는 여러 개의 자원을 한 번에 사용할 수 있으므로 n배의 처리시간을 보이지 않을까?
라는 생각이 들 수 있다.
하지만, Java 에서의 Thread 는 그렇게 가볍지가 않을 뿐더러,
하나의 작업을 여러 개로 분할한 만큼 오버헤드가 많이 발생한다.
세부적으로는 ForkJoin 이라는 task Object 를 만들고, 실행할 job 을 split 하고, 멀티코어의 병렬 실행을 위해 thread pool 스케줄링을 관리하는 등 단순하게 생각할 문제는 아니다.
물론 이는 Reactive Programming 등에서도 제기되는 문제이기도 하다.
그럼에도 불구하고 대량의 복잡한 연산을 수행해야 되는데 관리하기에 용이한 코드를 만들고자 한다면, 좋은 선택이 될 수는 있다.
글을 작성하다보니 Stream 에 대한 성능이슈로 인해 부정적인 글처럼 보일 수 있다. 그런 의도로 작성한 것은 아니지만..
Java 에서 Stream API 는 개발 편의성에 더 맞추어져 있다고 판단한다.
최근 들어서는 하나의 서버PC 의 스펙이 Java Application 을 수십, 수백개 올릴만큼 PC 자체의 성능이 좋아져 위 예시와 같은 단순 연산에 대해서는 매우 짧은 시간 내에 처리가 가능하다.
크게 성능을 고려하지 않아도 될 대부분의 상황이라면, 개발하기 편하고 하독성이 좋은 Stream API 를 선택하는 것이 더 현명한 판단일 수 있다.
특히 개발을 배우면서 최근에 드는 생각은, 웹 개발에 있어 CPU Intensive (CPU 자원 활용을 많이하는) 한 작업은 Java Application 이 아닌 DB level 에서 처리해야되는 것이 맞다고 생각이 든다.
덕분에 DB 설계의 중요성을 크게 체감하는 중이다.
고로 데이터셋이 크고 복잡할수록 DB 단에서 처리하도록 하고,
단순 연산들은 약간의 오버헤드가 있더라도 개발의 속도와 유지보수성을 위해 Java Stream 과 같은 것들을 적극적으로 사용해 보는 것은 어떨까?
