🔗 LocalAI vs Ollama
보안 이슈 등으로 private 한 AI 를 사용하기 위해 local 에 LLM 을 설치해서 사용하는 경우가 있다. 이는 기업에서 유료로 제공하는 모델과는 달리 가격을 책정할 수 없으므로, 오픈소스로 공개된 LLM 만을 사용할 수 있다.
위 오픈소스 LLM 을 로컬에서 사용하기 쉽게 제공된 프레임워크에는 LocalAI, Ollama 등이 있다.
왜 private 한 AI 를 사용해야 되는지와 LocalAI 에 대해서는 내가 작성한 아래 링크를 참고하자.
LocalAI 로 private 한 AI 를 구성해보자.
그러면 LocalAI 를 사용하면 되지 왜 Ollama 를 택했냐? 함은
Ollama 를 사용하기 전에 LocalAI 를 구동해 설치해 보았는데, 기본 제공되는 LLM 모델의 답변 퀄리티가 매우 떨어졌기 때문이다. (특히 한국어)
지원하는 LLM 모델도, 사용법에 대한 레퍼런스도 Ollama 가 훨씬 많다.
Ollama 지원 LLM
진작에 Ollama 로 구성할 것 그랬나보다..
나의 경우엔 사내 외부망이 차단된 개발망에서는 public 한 AI 를 사용할 수 없으므로, AI 를 활용한 개발이 무척 제한적이었다.
궁극적으로는 Intellij IDE 에서 사용가능한 AI 프로그래밍 도우미 플러그인을 만들고, Ollama 와 붙이는 작업을 진행해보고자 한다.
🔗 Ollama Quick Start (Docker in Linux)
시작하기에 앞서, 알아두면 좋을 내용이 있다.
📜 LLM? SLM? 2B? 7B?
간략하게만 소개하자면, LLM(Large Language Model) 은 대량의 데이터를 학습한 모델이다. 그만큼 답변의 퀄리티가 높고, 무겁다.
무겁다는 뜻은 컴퓨팅 리소스를 많이 잡아먹고, 답변이 느리다는 것을 의미한다.
모델은 학습하는 방식에 따라서 이름이 다르고, 저작권이 있다. 다만 요즘에는 오픈소스로도 많이 공유되는 추세이다.
HuggingFace - LLM, DataSet 등 오픈소스 모델 공유 사이트
SLM(Small Language Model) 은 LLM 에 비해 학습한 양이 적은 대신, 그만큼 가벼운 모델을 뜻한다.
학습한 데이터(매개변수)의 양에 따라서 SLM, LLM 으로 구분하는데,
그 매개변수의 수가 딱 정해진 것은 아니고 통상적으로 300억 (30B) 이하의 모델들을 SLM 이라고 부른다. (1B = 10억)
참고로, OpenAI 에서 개발한 GPT-4 는 수천억개의 매개변수로 학습했다.
2024.04 현 시점 GPT-5 개발중에 더 이상 학습할만한 데이터셋이 부족하다는 기사가 나왔을 정도니 이제는 누가 더 많은 매개변수로 학습했냐가 문제가 아닌,
누가 더 적은 매개변수로 더 나은 퀄리티를 보여주냐의 경쟁으로 번지지 않을까 싶다.
✏️ Docker 로 Ollama 설치
서론이 길었다. Ollama 설치부터 진행해보자.
Ollama Dockerhub
위 링크에서 Docker image 를 다운받는 예시가 들어있다.
GPU 를 사용할 사람은 GPU 버전을 사용하면 되지만, 나의 경우엔 사내 CPU 만 있는 서버에서 굴릴 예정이므로 아래 명령어를 입력한다.
$ docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama:latest# 기동 확인
$ curl localhost:11434
# 아래와 같은 문구가 출력된다.
Ollama is running이제 각자 사용하고 싶은 모델을 선택해 다운받는다.
나의 경우엔 최근 구글에서 공개하여 프로그래밍에 특화된 codegemma 2B 모델을 사용하고자 한다.
Ollama 지원 LLM
CodeGemma 2B/7B 모델 공개
$ docker exec -it ollama ollama run codegemma:2b
Send a message 는 말 그대로 터미널에서 질문하라는 뜻이다.
java 라는 질문을 테스트 해보았다.
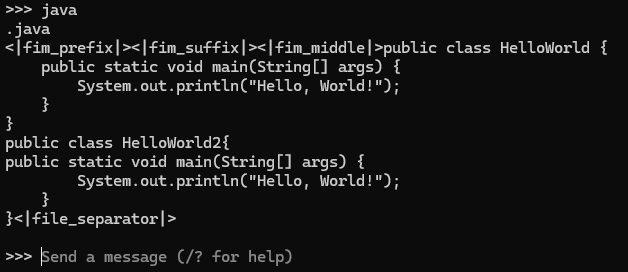
prefix, suffix, separator 등 쓸데없는 것들이 붙어있지만 응답 자체는 문제가 없는 것으로 확인된다.
모델 구동을 중단하는 것은 Ctrl + D 로 가능하다.
✏️ 터미널은 불편하다. 웹에서 사용해보자.
이 역시 Ollama 에서 쉽게 웹뷰로 볼 수 있도록 지원한다.
ChatGPT 와 비슷한 UI 라 익숙하게 사용이 가능할 것이다.
- 2024년 2월까지만 하더라도 Ollama WebUI 였는데, Open WebUI 로 이름이 변경되었다고 한다. 참고하자.
Open WebUI git repository
아래 명령어에서 각자 여분의 포트로 진행한다.
[호스트의 포트]:[컨테이너의 포트]
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainhttp://localhost:3000 으로 접속해보자.
어차피 local 에서 구동되므로 개인정보 걱정없이 Sign up (회원가입) 을 진행하자.
회원가입을 하면 아래와 같은 UI가 나온다.
아주 익숙한 ChatGPT 와 유사한 UI 다. 사용법도 비슷하다.
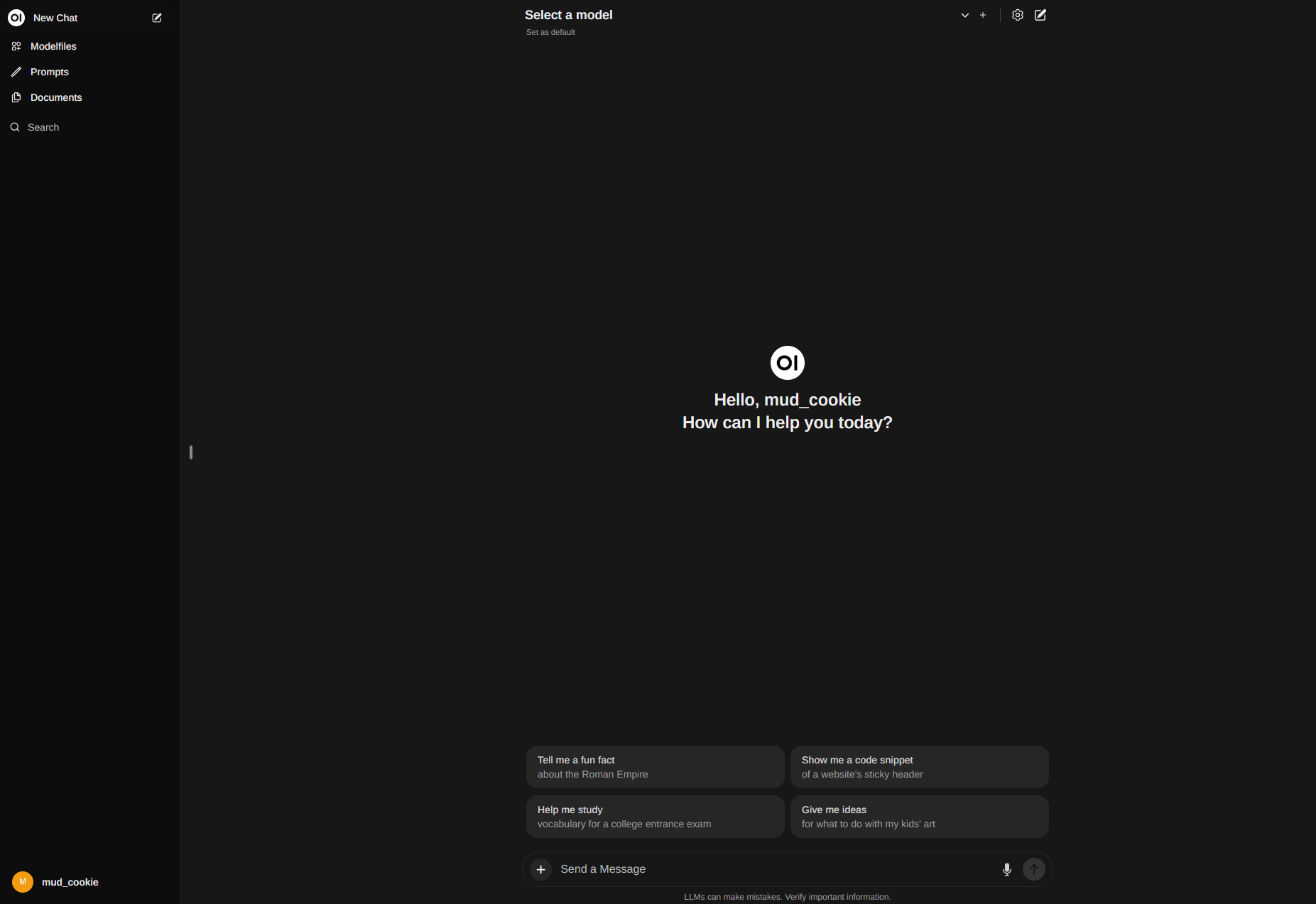
상단의 Select a model 에서 사용할 LLM 모델을 선택 가능하다.

만약 원하는 모델이 없다면, 좌측 하단의 프로필 클릭 -> Settings 에서 모델을 직접 다운받을 수 있다.
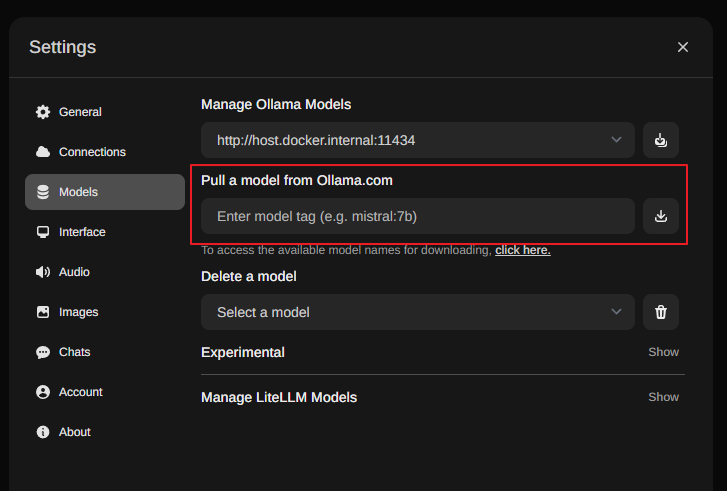
외부망이 차단된 서버라면, 외부망 접속이 가능한 PC 에서 아까 위에서 언급했던 docker 로 모델을 다운받았던 것과 같이 진행하면 된다. 실행과 동시에 LLM 모델이 다운받아진다.
$ docker exec -it ollama ollama run LLM모델명이후 아래 내가 작성한 포스트의 최하단에서 image 를 tar 파일로 변환, 해당 파일을 SFTP 로 이관하는 방법에 대한 글을 참고하자.
LocalAI 로 private한 AI 를 구성해보자
이제 질문을 시작해보자. Springboot 백엔드 지식의 아주 기초적인 질문을 해보았다.
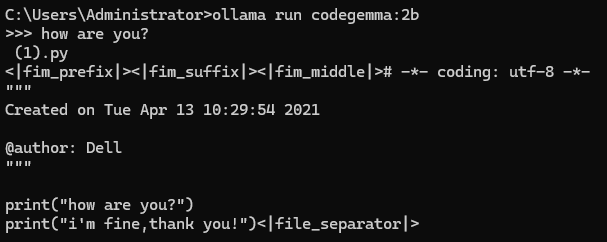
여기서 사용한 LLM 모델은 codegemma 2b 버전으로, 가벼운 모델에 속하니 중간중간 대화에 prefix, suffix 등의 사소한 텍스트 오류는 무시하길 바란다.
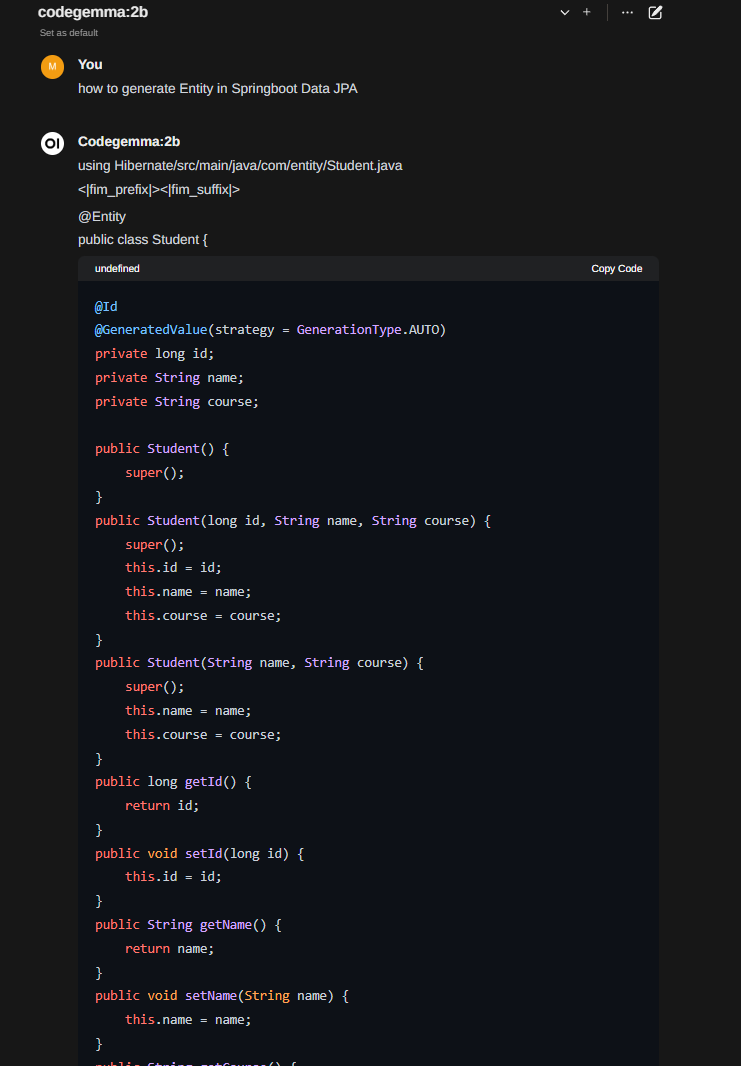
응답이 잘 나온 것을 볼 수 있다. 캡처 이미지에는 표기가 되지 않았지만 마지막 설명까지 잘 마무리가 되었다.
❗ CPU(GPU) 사용량 확인 필수
실행한 환경은 아래와 같다.
- CPU : AMD 5950X 16-Core
- GPU : RTX 3080 -> GPU 는 사용하지 않음. - RAM : DDR4 16 * 2 GB
- LLM : codegemma 2B
아래를 보면 어마어마한 CPU 사용량을 차지하고 있는 것을 알 수 있다.
개인 PC 치고 괜찮은 CPU 코어 수와 성능을 가지고 있음에도 불구하고 평소 10% 미만의 점유율을 차지하던 것이 70% 이상으로 급격하게 뛴다.
LocalAI 로 private한 AI 를 구성해보자
위에서 LocalAI 로 돌려봤을 때와는 다르게 CPU 점유율이 2~3 배 이상 많은데, 이는 다른 LLM 모델을 사용하긴 했지만 워낙 그 수치가 차이가 많이 난다.
혹시 몰라서 codegemma 2B 보다 학습량이 더 많은 codegemma 7B 를 사용했을 때, 답변 퀄리티는 증가하고 응답속도는 느려졌지만 CPU 점유율은 동일했다.
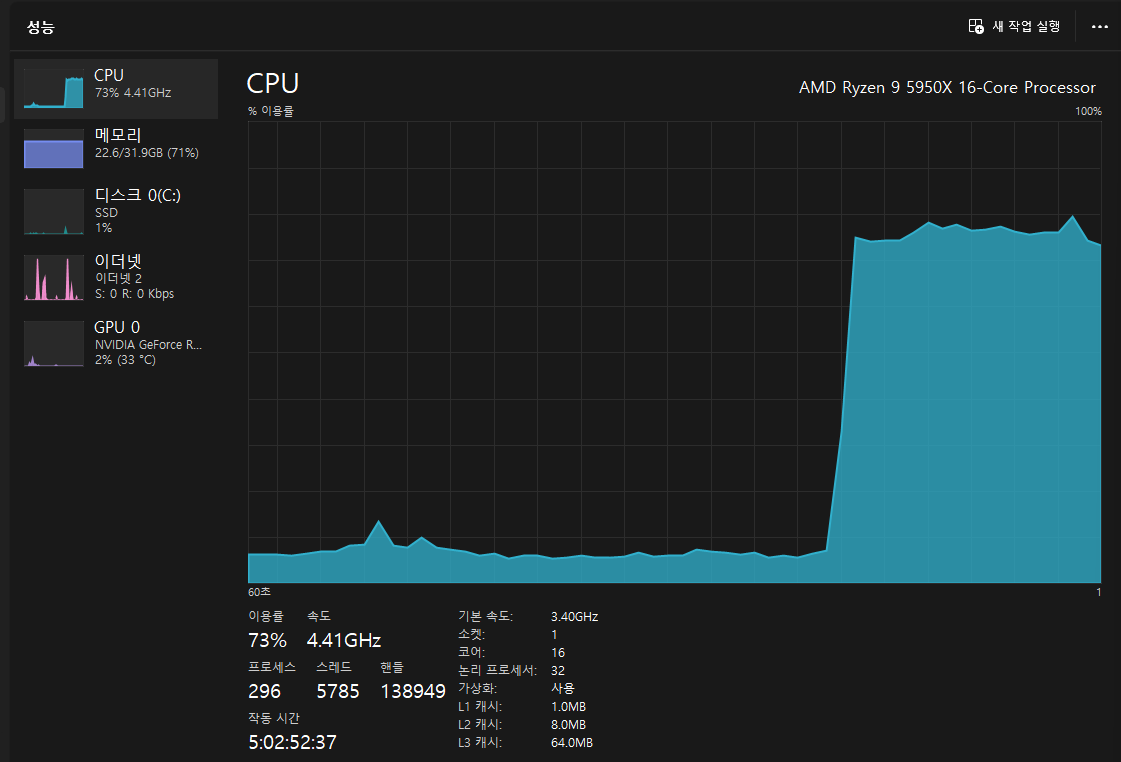
이는 LLM 모델에 따른 차이라기 보다는 Ollama 라는 framework 자체가 리소스를 많이 잡아먹도록 설계된 것이 아닐까 예상한다.
물론 GPU 를 사용하는 서버라면 점유율이 낮아지는 건 당연하다.
GPU 를 사용할 수 있는 환경이라면 애초에 Ollama Docker 를 설치할 때부터 GPU 버전으로 사용하길 권장한다.
Ollama Dockerhub
✏️ Streaming API 로도 사용이 가능하다
Ollama 에서 제공하는 API - swagger
위 링크에서 Ollama 에서 제공하는 API 에 대해 확인해보자.
개발자에게 익숙한 Swagger UI 로 보여주니 이런 부분에서는 신경을 많이 쓴 것을 볼 수 있다.
물론 Ollama framework 내부에서 Swagger UI 를 구현하지 않은 것은 아쉬운 부분이다.
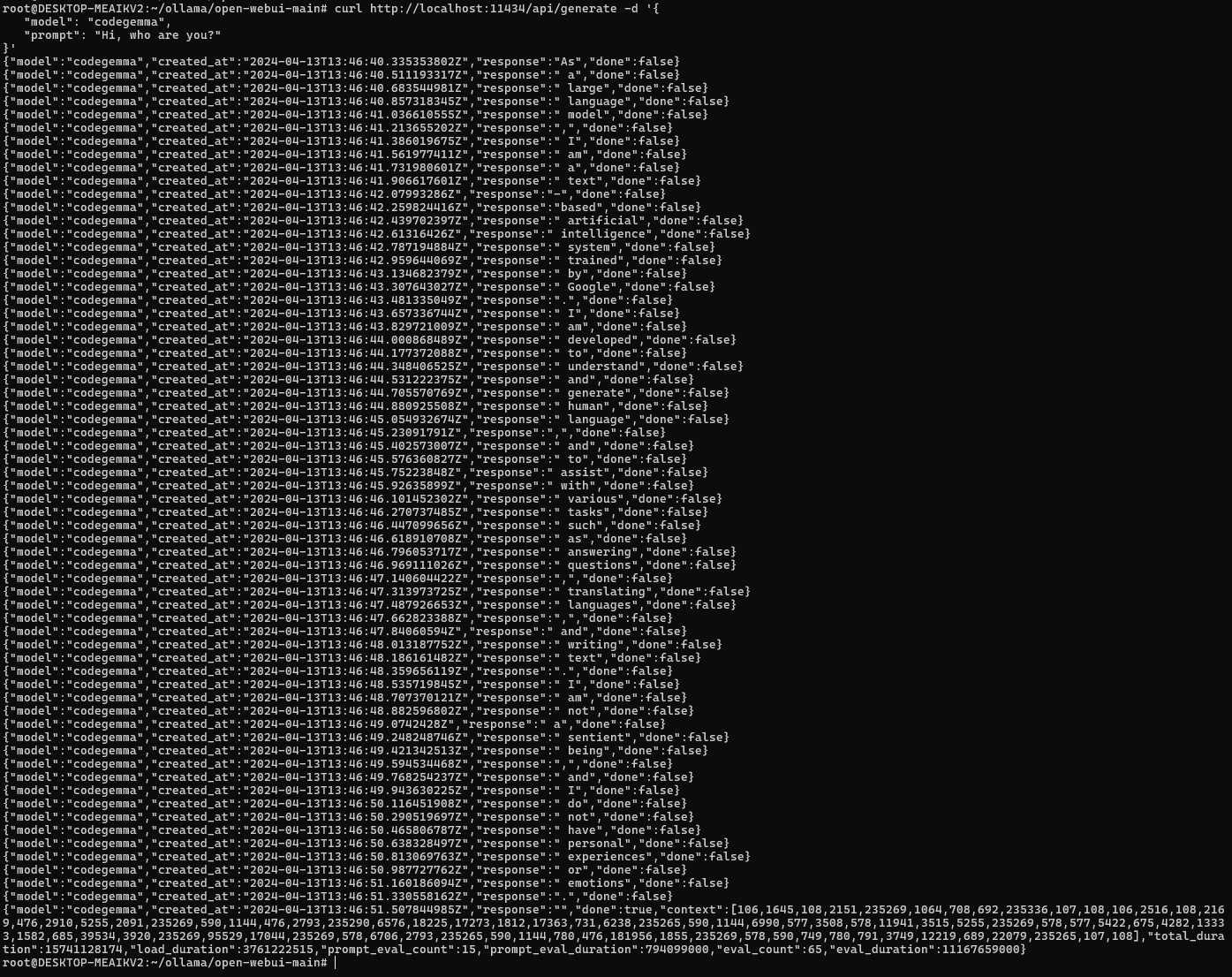
터미널에서 아래와 같이 curl 로도 응답을 확인할 수 있다.
$ curl http://localhost:11434/api/generate -d '{
"model": "codegemma:2b",
"prompt": "Hi, who are you?"
}'아래와 같이 나오는데, 웹뷰에서 보았다시피 단어 하나씩 출력되는 걸 볼 수 있다.
Codegemma 2B 가 아닌 Codegemma 7B 모델로 한 결과이다. 아직까진 2B 모델은 보완할 부분이 많아보인다.
🔗 Ollama Quick Start (Windows)
위에서 작성한 설치방법은 Linux OS 환경에서 Docker 를 활용한 설치방법이었고, 이번에는 Windows OS 에서 설치해보고자 한다.
위 과정을 이미 밟았던 사람이라면, PC 에서 구동중인 docker container 를 중지시키고 진행하자.
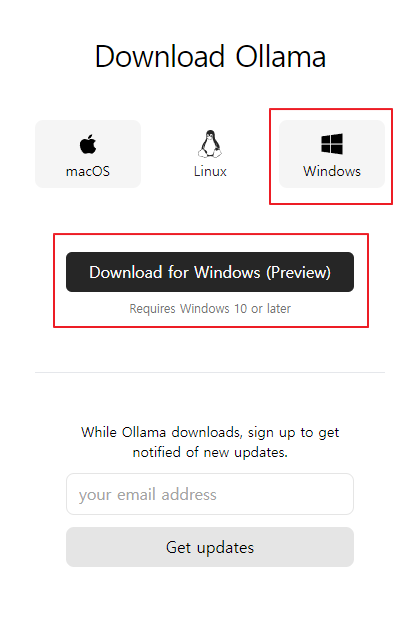
Ollama Windows 다운로드
위 링크에서 Windows 버전 다운로드를 진행 후 설치한다.
접속하면 아래와 같은 화면이 출력되는데, Windows 10 이상의 버전만 지원함에 유의하자.
이후 다운받은 OllamaSetup.exe 를 실행하기만 하면 바로 설치가 완료된다.
setup 과정에서는 오프라인도 가능하니 참고하기 바란다.
이후 cmd 창을 열어 아래와 같이 입력해보자. 관리자 권한으로 접속하지 않아도 된다.
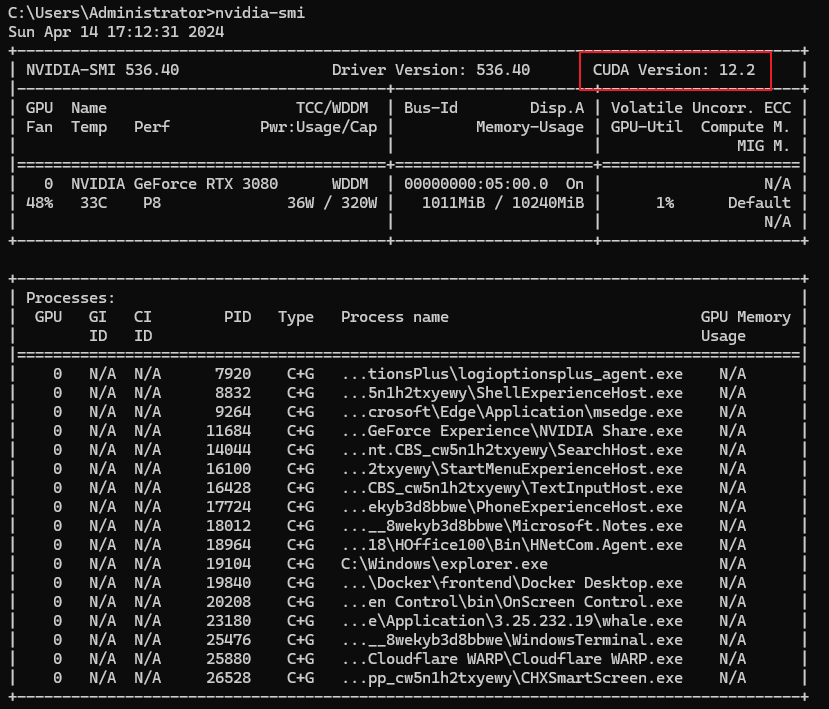
nvidia-smi명령어 입력 시 현재 보유한 Nvidia 그래픽카드의 정보가 출력된다.
아래에서 중요하게 봐야 될 부분은, CUDA Version 이다.
작성 기준 Windows preview 버전이라, 11버전 또는 12버전만 지원하는 것으로 알고있으니 참고하길 바란다.
만약 Nvidia 그래픽카드 & Nvidia 그래픽카드 드라이버(11, 12 버전)가 없으면 CPU 만으로 동작할 것으로 예상된다.
이제 설치가 잘 됐음을 확인해보기 위해 아래 명령어를 입력해보자.
ollama
이전의 Docker 로 구동된 것과는 다르게, ollama 라는 명령어로 다양한 동작들을 수행할 수 있음을 알 수 있다.
이 명령어들을 활용해 cmd 창에서 다양한 작업을 해보자.
우선 현재 사용가능한 모델들을 나열해주는 명령어를 작성하자.
ollama list아직은 사용 가능한 모델이 없다고 출력된다.

그러면 이제 모델을 다운받아보자. pull 명령어 뒤에 사용하고 싶은 LLM 모델명을 입력한다.
ollama pull LLM모델명
잘 다운로드가 받아졌으니 다시 한 번 list 명령어로 사용이 가능한지 확인해보자.

이제 cmd 에서 모델을 구동시켜보자.
ollama run LLM 모델명아래는 run 으로 구동 후 "how are you?" 라는 질문을 해본 예시이다.
혹시라도 오프라인 PC 환경에서 진행하고자 한다면, model 을 직접 pull 받을 수 없으므로, 다운로드 받은 model 이 어디에 위치하는지 공유한다. 이 model 을 SFTP 로 옮기면 된다.
registry 위치
C:\Users\PC계정명\.ollama\models\manifests\registry.ollama.ai\library\model 위치
C:\Users\PC계정명\.ollama\models\blobs주의점은 registry 에는 sha256 암호화된 파일명에 대한 정보를 그대로 담고 있으므로, 파일 이동 과정 중 파일명이 변해서는 안된다.
모델을 여러 개 받아서 sha256 암호화된 파일명이 어떤 모델인지 알 수 없다면, ollama pull 명령어 입력 시에 pulling 되어 암호화된 모델명이 출력되므로, 그 값을 참고하자.
codegemma:2b 모델 기준으로는 4개의 model 파일이 생성, 하나의 registry 파일이 생성되었다.
ollama 시작 & 종료 방법
- 시작 : cmd 에서
ollama serve입력, localhost:11434 에서 기동 확인 - 종료 : windows 우측 하단 아이콘 목록에서 ollama 아이콘 우클릭 -> Quit
❗ WebUI 는 현재 Docker 에서만 지원한다.
2024년 4월 기준 Ollama WebUI 를 Windows OS 자체에서 구동시키려고 했으나, Windows 에서는 지원하지 않는다고 한다.
Windows 에서 Docker 를 띄우려면 WSL 이 필요하고, WSL 를 구동시킨다는 것 자체가 메모리를 많이 잡아먹어 별로 하고싶지 않은 선택이었으나.. 어쩔 수 없이 Docker 로 구동시키는 방법밖에 없다.
❗ CPU(GPU) 사용량 확인 필수
위 Docker in Linux 에서는 CPU 만으로 구동시켰으나, 이번에는
GPU 를 사용하는 환경이었다.
GPU 를 사용하면 리소스를 얼마나 잡아먹을지 살펴보자.
구동 환경은 이렇다. 메모리는 애초에 WSL 을 구동하느라 Default 로 많이 잡아먹고 있는 상황임에 참고하자. WSL 만 16GB 를 기본으로 잡아먹고 있다.
- CPU 버전
- CPU : Ryzen 5950X - Docker 에 10 Core 할당
- OS : Linux (WSL, Docker)
- GPU 버전 - Windows
- GPU : Nvidia Geforce 3080 10GB VRAM
- OS : Windows
- 공통사항
- Memory : 16 * 2 GB
- LLM : codegemma (7B)
- 질문 : how to generate Entity in springboot data jpa?
✏️ 단일 실행 성능 확인
CPU 버전
아래 CPU 점유율은 위 Docker 로 설치할 때 보여주었다 시피 CPU 의 80% 가량의 점유율을 보인다. (평소 10% 미만)
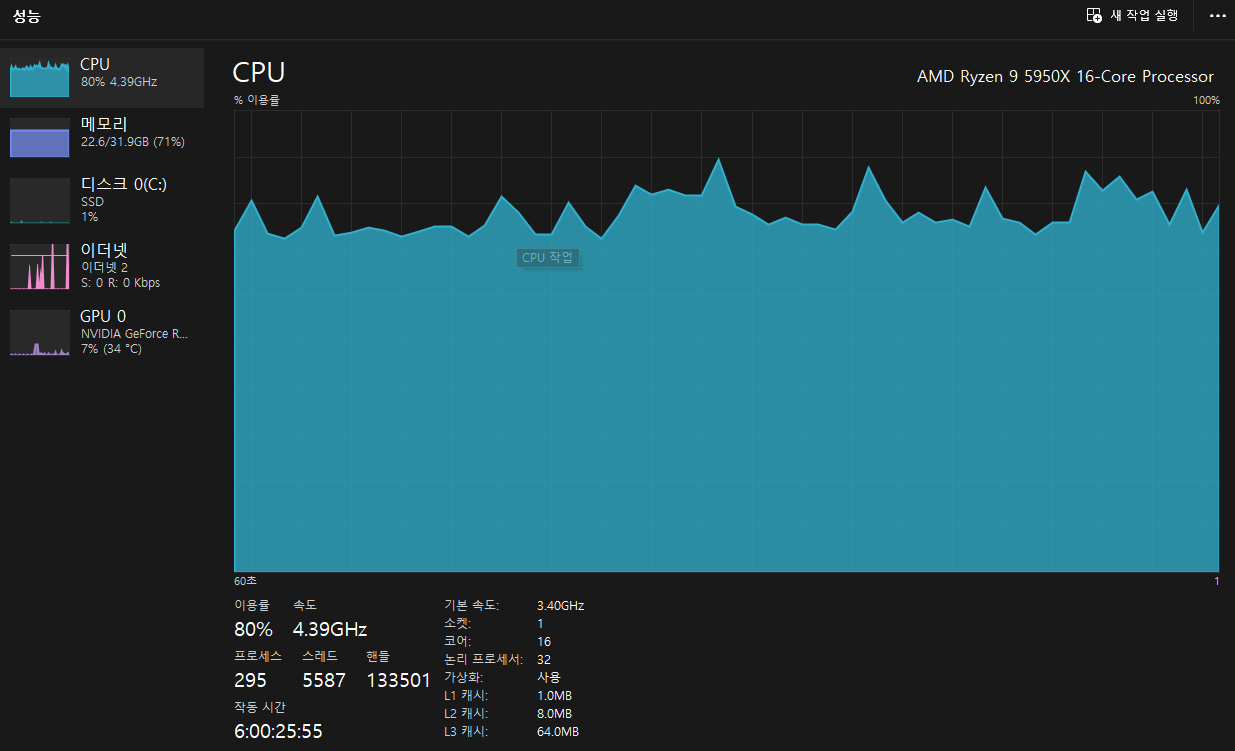
다만 이번에 Docker 의 CPU 점유율을 보았더니..
내가 할당한 10Core 를 넘어서는 과부하가 걸린 것을 보았다. 이대로는 위험하다.

GPU 버전
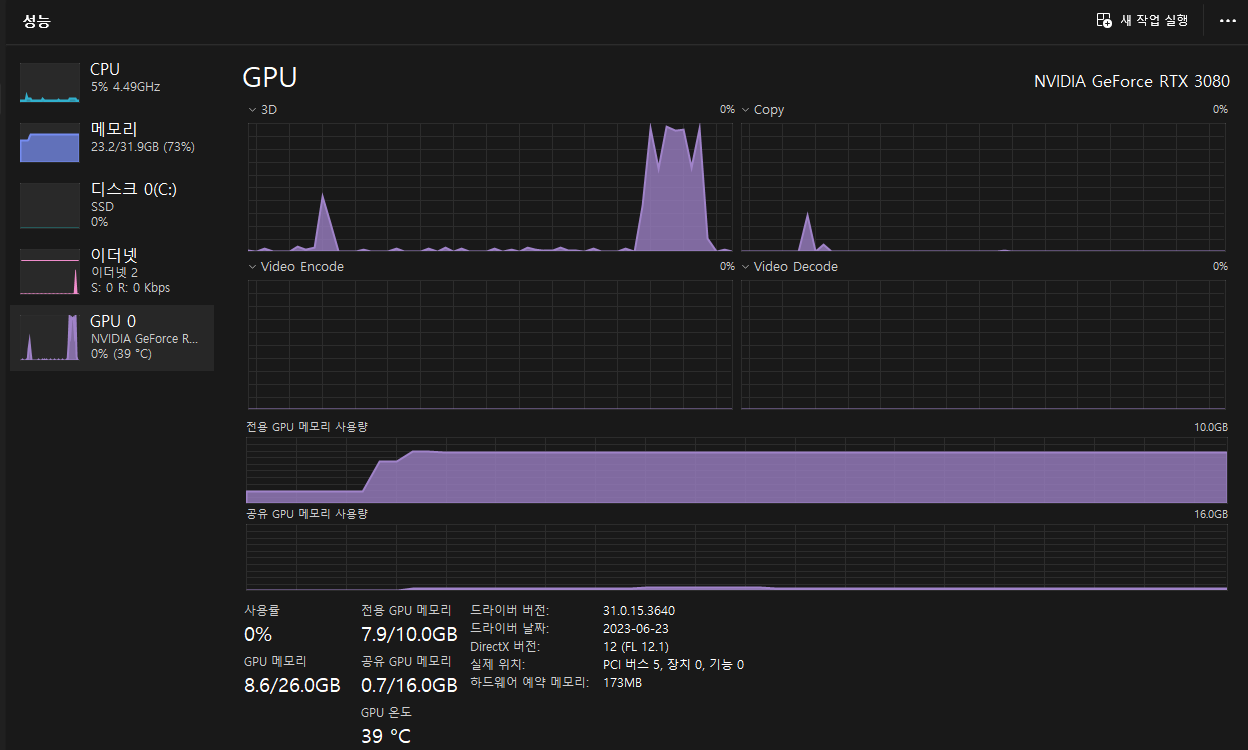
GPU VRAM (메모리) 사용량은 ollama 구동시작부터 대화가 끝날때까지 일정했다. 기동하는 것 자체만으로 VRAM 을 잡아먹는 것으로 보인다.
다만 3D 사용량은 순식간에 97% 점유율을 보인다. 사내 서버는 24시간 돌아가므로 이 정도 스펙으로 구동된다고 하면 주의해야 될 것으로 보인다.
✏️ 병렬(2개) 실행 성능 확인
CPU 버전
예상했던 결과와는 달리, 동시에 질문한다고 하더라도 하나의 질문이 끝나고 난 후에 다른 질문이 실행된다.
안그래도 GPU 버전보다 응답시간이 체감상 5배 이상 느린데, 다음 질문을 하는 사람은 더 많이 기다려야 된다.
CPU 버전으로는 사내 서버에 구동시킬 수는 없을 것으로 판단된다.
성능도 그렇고 사용성이 너무 떨어진다.

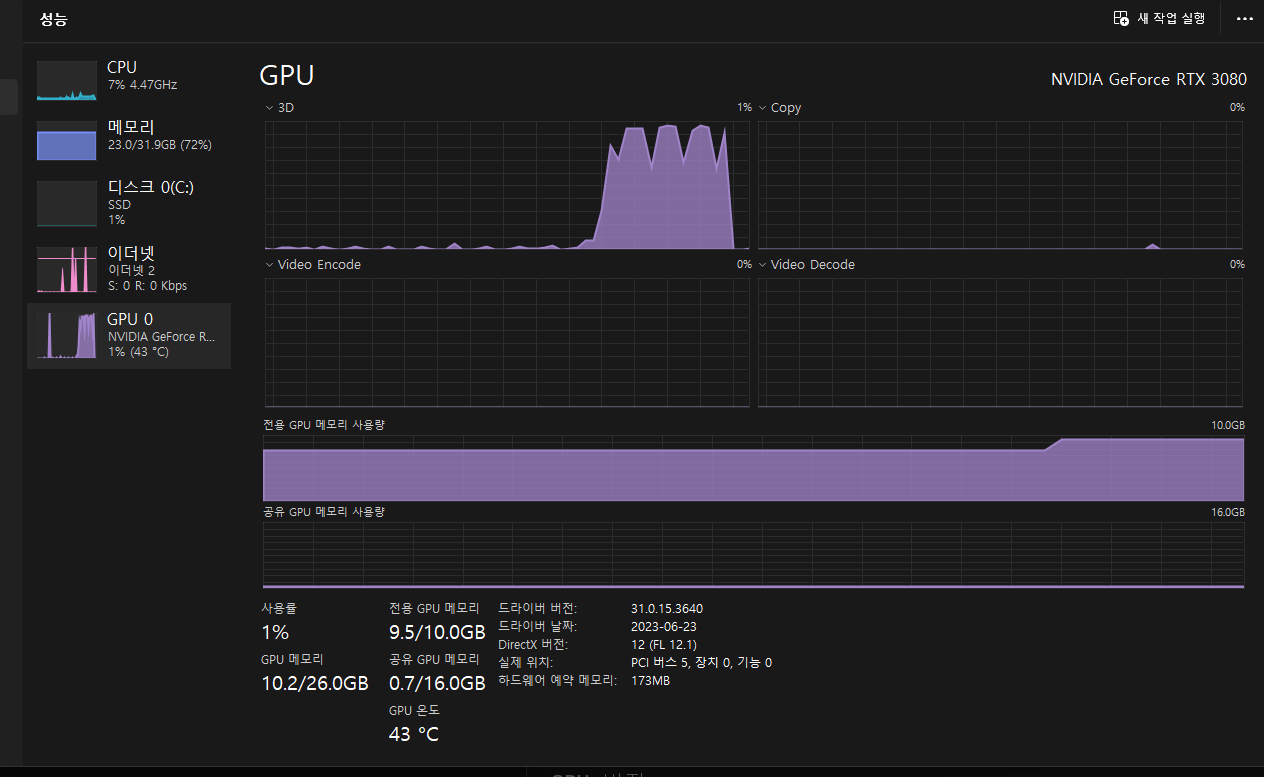
GPU 버전
이 역시 CPU 버전과 동일하게, 동시에 질문한다고 하더라도 하나의 질문이 끝나고 난 후에 다른 질문이 실행된다.
그러므로, 처리시간만 두 배로 늘어난 꼴이 된다.
질문에 따라 독립적인 쓰레드가 동기적으로 실행되는 것이 아닐까 예상하는데, 어찌보면 하나의 서버를 유지하는 데 있어서 질문을 동시에 처리한다고 하는 것은 더 큰 과부하를 줄 수 있으므로 이 방식은 비교적 안전하다고 볼 수 있다.
그렇다고 해서 서버가 안정적으로 실행된다는 것은 아니고, 질문이 계속 들어오면 그만큼 GPU 리소스를 계속 풀로드에 가깝게 돌려야 된다는 의미이므로 주의할 필요가 있다.
비트코인 채굴을 생각해보자.
몇 개월동안 24시간 내내 GPU를 풀로드로 무식하게 돌려버리니 더 이상 못쓸 지경까지 된 그래픽카드를 중고시장에 풀어버리는 참사가 몇년째 계속되고 있지 않은가..
🔗 마치며
LLM 을 로컬에서 쉽게 구동하기 위한 framework 인 ollama 를 다양한 환경에서 설치 및 구동해보았다.
설치 자체는 개발자라 어려운 부분은 없었지만, 한국어로 된 레퍼런스는 많지 않아 불편함을 다소 느꼈다. 국내에서도 하루빨리 AI 에 대한 관심도가 높아졌으면 하는 바램이다.
추가적으로 생각보다 경량인 모델들도 리소스를 많이 잡아먹는 것을 알게되었다.
최근 온디바이스 AI 라고 하면서 가벼운 모델들이 활성화되고 있는 가장 큰 이유가 바로 컴퓨팅 리소스떄문이 아닐까 싶다.
CPU 로 구동시키는 버전은 응답시간과 과부하때문에 도저히 활용할만한 수준이 못되고,
GPU 로 구동시키는 버전은 준수한 응답속도를 가졌으나 풀로드에 가까운 리소스를 점유하므로 24시간 구동되는 사내 서버에서는 사용하기에 다소 무리가 있다.
내 그래픽카드가 개인PC 치고 괜찮은 수준인데도 이정도면 GPU 자원을 외부에서 끌어다 쓰는 이유가 있었구나 싶다..
결론적으로는 사내 테스트 서버에 ollama를 구동시켜, private 한 AI 프로그래밍 도우미 플러그인을 만들고자 했던 계획은 현실과 동떨어져 가고 있다.
사내 테스트서버는 Intel 제온 CPU 로 구동되는 매우 준수한 스펙을 가지고 있긴 하나, GPU 따위는 내장되어 있지 않다.
GPU 구매 요청을 날리기에는 회사 분위기가 비용 절감에 초점을 두고 있고, 그렇다고 해서 ollama 자체를 각 개발자의 개인 PC 에서 돌리기에는 GPU 가 없으니 결국 CPU 를 써야 하는데 개발 도중 CPU 에 과부하가 걸린다는 것은 크리티컬하므로 이 방법 역시 말이 되지 않는다.
회사 개발망은 보안때문에 이것저것 다 막아놨으니 클라우드 자원을 활용할 수도 없고.. 막막하다.
정말 마지막으로 사내에 남은 GPU 장비가 있다고 하면, AI 프로그래밍 도우미 플러그인을 만들어 제작 과정 및 결과를 포스팅하고자 한다.
소식이 없으면 무산된 걸로..


좋은 자료 감사합니다 :)