서론
서비스 특성 상 매월 1일 특정시간에 선착순으로 충전 시 인센티브를 제공해, 트래픽이 짧은 시간 내 폭증하는 이벤트가 존재한다.
또한 민생회복 소비쿠폰 등의 대규모 이벤트에도 대비해야 되었다.
다만 코어 인프라에 인입되는 트래픽이 일정 수준 이상일 경우 서비스 장애가 발생하였고,
과거에 트래픽을 분 단위로 특정 수 만큼 인입되게 하는 대기열 솔루션 (트레이서라고 칭함)이 존재했다.
다만 그 트레이서(대기열 솔루션)도 일정 수 이상의 사용자가 인입되면 대기열 자체에도 장애가 발생해,
이를 해결하기 위해 직접 대기열 프로젝트를 구축하는 TF 팀에 참여하게 되었다.
구 대기열 솔루션 (트레이서) 장애 원인 분석
구 대기열 솔루션 (트레이서)는 외부 솔루션이라, 설정 및 소스코드 분석이 제한적일 뿐 아니라 해당 개발사와도 연락이 되지 않는 상황이었다.
그래서 분석할 수 있는 최소한의 메트릭들을 분석하던 중,
아래와 같은 Linux 메트릭 정보를 확인해, TCP 통신 중 Socket Overflow에 대한 오류 원인 분석을
Socket Overflow 분석
에 정리해 두었다.
2063660 times the listen queue of a socket overflowed
2245967 SYNs to LISTEN sockets dropped요구사항
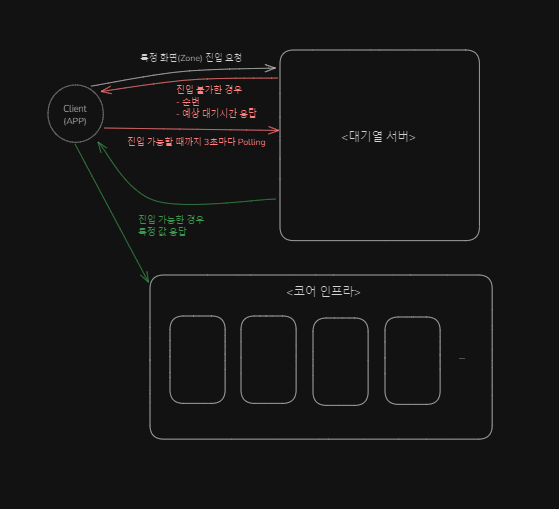
- 최대한 많은 양의 사용자를 대기열 내 수용할 수 있어야 함.
- 대기열 서버와 코어 인프라는 물리적으로 분리되어야 한다. (장애 전파 최소화 및 보안)
- 사용자가 대기열 서버로부터 "해당 화면 진입 가능" 이라고 명시적으로 응답 받아야지만 해당 화면에 진입함.
- 사용자가 대기열 서버로부터 "해당 화면 진입 불가능" 이라고 응답받은 경우는 3초마다 다시 Polling 하며, 이 때 본인의 순번과 예상 대기시간을 응답받는다.
- 특정 화면(Zone)에는 1분마다 N 명의 사용자만 인입되도록 설정할 수 있어야 함
- 1분 내에서도 임계치만큼의 사용자들이 순번대로 천천히 유입되어야 함.
- Zone 은 App(지자체) 별, App 내 화면 별로 구성되어 있어 그 수가 수백 단위.
- 예상 대기시간을 초 단위로 보여주어야 함.
- 1분동안 Polling 하지 않은 유저는 대기열에서 삭제해야 함. (App 에서는 사용자가 대기열에서 이탈했는지 명시적으로 알 수 없음)
- App -> 트레이서와의 호출 방식 및 구현 방식을 신규 대기열 프로젝트에 그대로 유지해야 함.
- 사용자는 3초마다 Polling 을 통해 자신의 순번과 예상 대기시간을 실시간으로 확인
- Zone 별 대기열의 상태와 인프라 리소스 사용률을 실시간 모니터링 할 수 있어야 함.
- 서버 비용 최소화
설계 과정
기술 선택
Redis Cluster
기술적으로 아래 기능에 대해 가장 성능이 중요한 것을 선택해야 했다.
- 하나의 Zone 에 대해 수 많은 사용자가 동시에 대기열에 등록되며 순번을 빠르게 조회할 수 있어야 함.
- 하나의 데이터에 대해 쓰기 작업에 대한 동시성이 매우 높음.
이로 인해, 하나의 데이터에 경합을 최소화 하기 위해 Redis 를 선택.
-> Main Command 작업은 Single Thread 로 동작하므로 Lock 으로 인한 성능 저하가 일어나지 않는다.
-> 저수준 (C언어) 으로 구현되어 어셈블리 만큼의 성능을 발휘할 수 있다.
또한, Redis 는 다양한 자료구조를 제공한다.
- ZSET (Sorted Set) 을 통해 사용자의 순번을 매우 빠르게 조회 가능하다.
- ZSET 은 특정 key 값에 대해 TimeStamp value 값으로 정렬되어 있고, 내부적으로 Skip List (다중 연결 리스트) + Hash Table 로 구성되어 있다.
- 단일/범위 조회 시 Full Scan 하지 않고 Skip List 의 내부 Size 만큼 데이터를 건너뛰며 조회 가능하다.
- 결론적으로, O(Log N) 의 시간복잡도로 단일 조회가 가능하다.
- 이로 인해 3초마다 Polling 을 통해 순번을 조회해야 하는 부하를 높은 성능으로 처리할 수 있다.
Zone 별로 독립적인 물리 서버에서 연산하는 구조를 위해 Cluster 구조를 선택.
- 기존 사내에서는 Redis Sentinel 만 사용하고 있었음.
- Redis Cluster 구조는 데이터를 샤딩해 여러 서버에 분산 저장하며, 이로 인해 Zone 별로 독립적인 리소스를 사용할 수 있다.
- 샤딩은 key 기준 CRC16 알고리즘으로 각 Redis Node 에 분산 저장한다.
Redis 의 오픈소스 버전인 Valkey 를 사용하지 않은 이유
- 구현 당시인 2025.05 당시에는 Valkey 8.1 가 Beta 버전에서 공식 버전으로 올라온지 얼마 되지 않아, 신뢰도가 부족했음.
- Valkey 공식 문서에서는 Redis 보다 일부 성능이 더 뛰어나다고 명시되었지만, 릴리즈 노트에는 수 많은 버그 픽스들이 업데이트 되고 있었음.
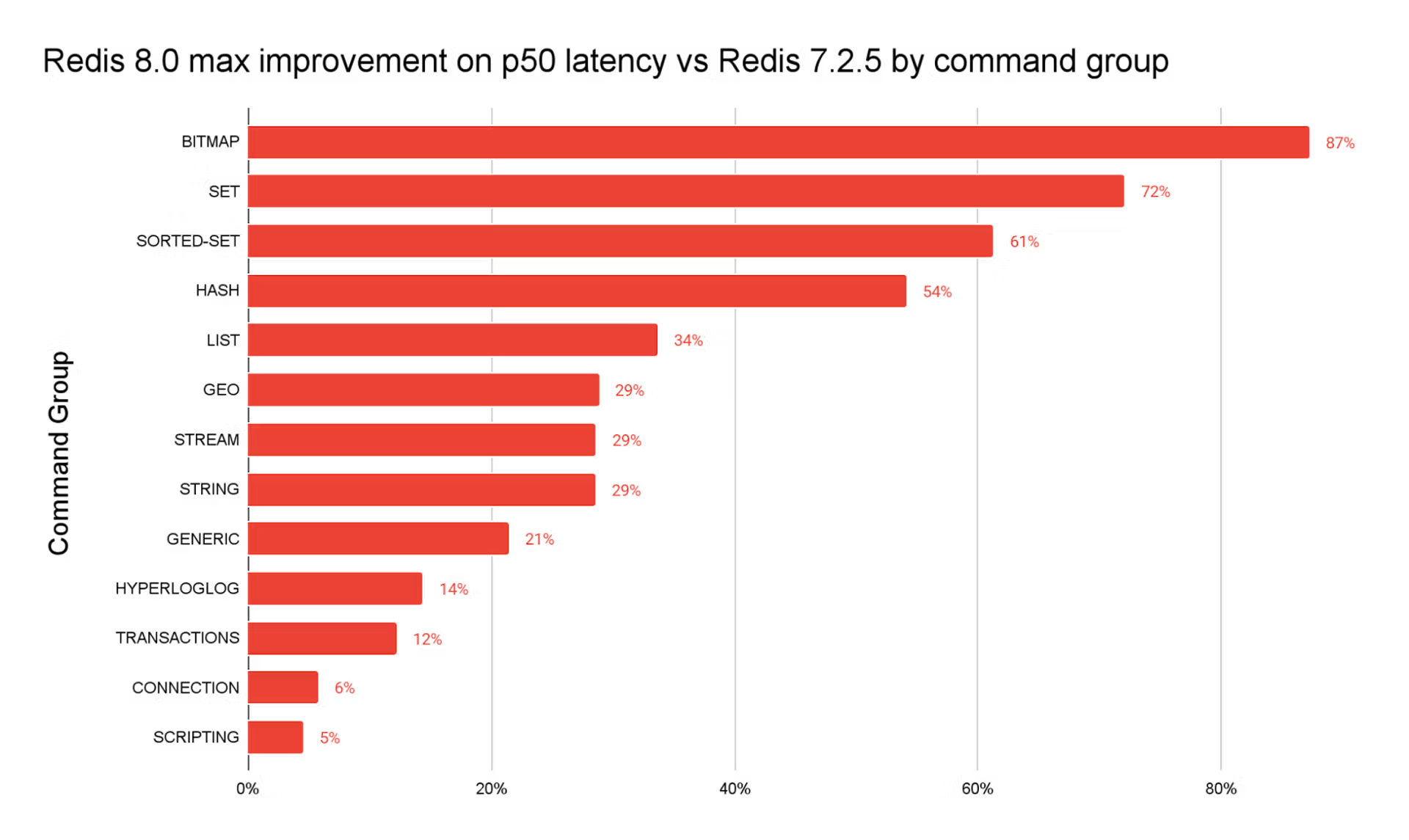
Redis 8.0 버전을 사용한 이유
- 당시 Redis 8.0 버전이 공식 버전으로 출시
- 7.2.5 대비 명령어 처리 속도 최대 87% 개선 (ZSET 은 최대 61% 개선)
- I/O 스레드 엔진 재설계로, 멀티코어 환경에서 처리량이 최대 112% 개선됨. (io-threads)
- Replication 성능 및 메모리 효율 강화 : Replication(복제) 지연 18% 단축
- https://redis.io/blog/redis-8-ga/
AWS ElastiCache 를 사용하지 않은 이유
- 부하테스트 결과 직접 구축한 Redis 보다 성능이 훨씬 떨어졌음.
- 클러스터 확장 자동화, 백업 기능 추상화 등 운영자 편의를 위해 고도화된 기능들이 오히려 성능에 좋지 않은 영향을 끼친 것으로 예상.
- 디테일한 튜닝이 불가.
Virtual Thread
사내 기본 개발 환경인 Spring Boot 2.x 를 사용하면서, 항상 무거운 Thread Pool 으로 인한 성능 저하에 대해 항상 고민을 했었다.
이를 해결할 Stream 기반 Webflux 도 찾아보았으나, 기술 패러다임이 기존 MVC 구조와는 크게 달라 개발 생산성 및 유지보수에 문제가 있었다.
기술 검토 중, Java 21 부터 공식적으로 지원하는 Virtual Thread 를 찾아보며 기존 개발 구조를 유지하면서 개선이 가능할 것이라는 판단을 했다.
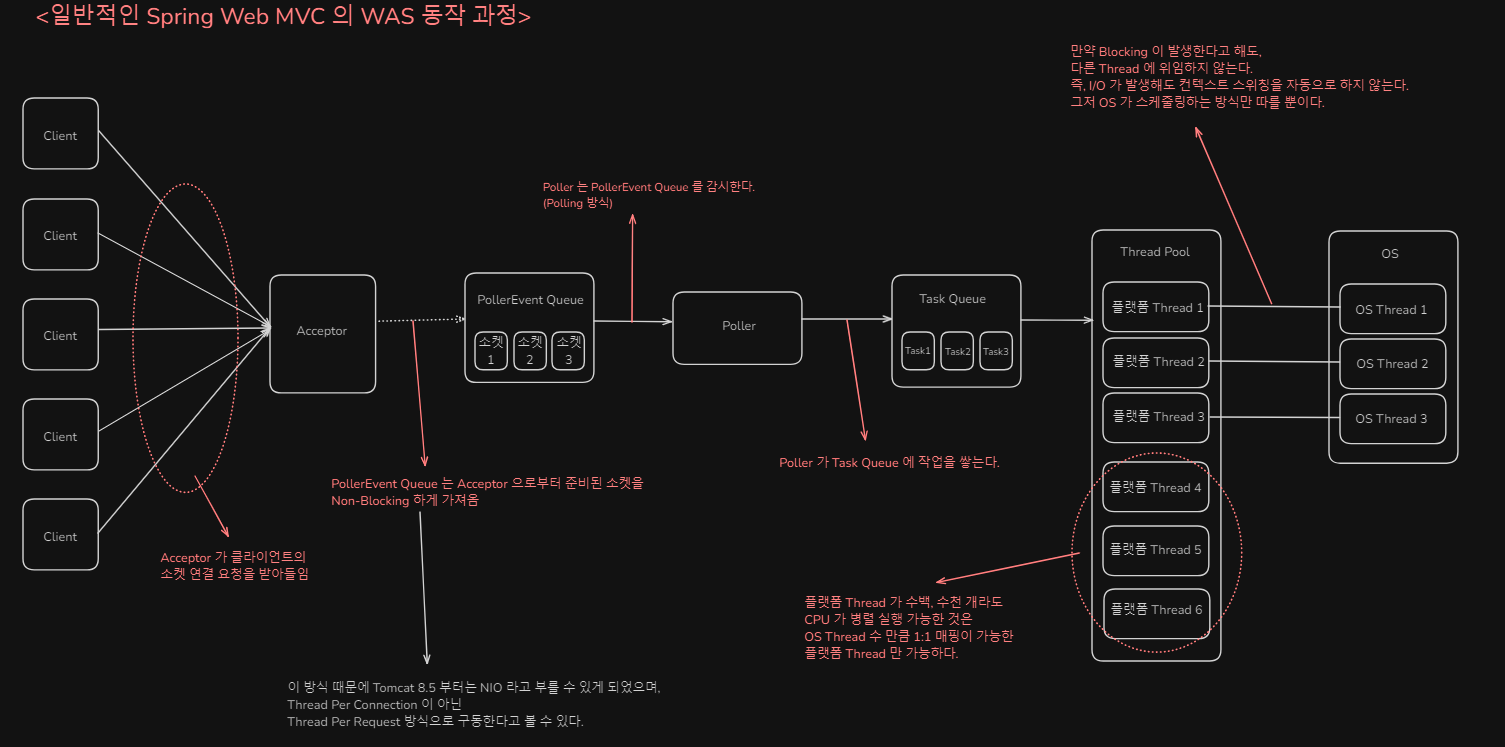
기존 Spring Boot 기본 MVC 모델의 한계
- Thread Per Request 구조
- 하지만 여기서 사용되는 Thread 는 OS 에서 직접 관리 (스케줄링) 하는 Platform Thread
- Platform Thread 는 생성 비용 (그래서 Thread Pool 을 사용하기는 함), 컨텍스트 스위칭 (매번 시스템 콜이 발생) 비용이 매우 높다.
- OS 단에서 관리되는 Thread 이기 때문에, Java 내부적으로 I/O 가 발생해도 자동으로 Context Switching 이 되지 않는다. (해당 Thread 는 I/O 가 발생하면 대기 상태)
Virtual Thread 의 구조 및 장점
- Platform Thread (OS Thread 가 관리하며 1:1 매핑되는 쓰레드) 에 여러 개의 Virtual Thread 가 마운트 되어 사용되는 구조.
- OS 는 Platform Thread 에 대해서만 스케줄링을 하고, 이에 마운트 된 Virtual Thread 는 JVM 단에서 매우 경량화된 스케줄링을 한다.
- WebFlux 와 같이 기존의 개발 패러다임을 바꾸지 않고, 기존의 Thread 를 그대로 상속해 사용하는 구조이므로 구조 변경 없이 성능 개선이 가능하다.
- JVM 에서 스케줄링 되므로, I/O 발생을 인식해 자동으로 Context Switching 이 가능하다.
- 생성시간과 컨텍스트 스위칭, 메모리 비용이 매우 적다.
Virtual Thread 쓰레드 생성/스케줄 속도
| 대상 | 기본 Thread | Virtual Thread |
|---|---|---|
| 메모리 사이즈 | ~2MB | ~50 KB |
| 생성 시간 | ~1ms | ~10µs |
| 컨텍스트 스위칭 시간 | ~100µs | ~10µs |
Virtual Thread 사용 시 유의사항
- Virtual Thread 설계 사상을 따르면 Thread Pool 을 사용하지 않는 것이 바람직하다.
- 매번 가상 쓰레드를 생성, 파괴하며 일회성으로 사용하는 것이 기본 사상
- 그래서 ThreadLocal 과 같이 Thread 전역적으로 캐싱하는 것은 오히려 메모리만 낭비한다.
- 대신 ScopedValue 과 같은 대안책이 있다.
- 대신 백만개 이상의 가상 쓰레드도 무리 없이 생성 가능
- SpringBoot 의 worker thread Pool 관련 설정들이 무시됨.
- Synchronized 키워드 시 Platform Thread 에 Blocking 전파 현상
- Virtual Thread 는 적은 수의 Platform Thread 에 Mount 하는 형식인데, Synchronized 와 같은 키워드는 Platform Thread 에 영향을 끼친다.
- 그래서 일반적인 JDBC 와 같이 Synchronized 키워드를 사용하는 라이브러리는 사용하지 않는 것이 좋다.
- 이 프로젝트는 JDK21 을 사용하며 JDBC는 사용하지 않는다.
- JDK 24 에서 Synchronized 키워드에 대한 Virtual Thread 성능 개선이 이루어졌다.
참고 : 사용 버전
- JDK : 21
- Spring Boot : 3.4.0
- Kotlin : 2.1.0
- Redis : 8.0
로직 구현 (Sliding Window Log)
Sliding Window Log는 특정 window 내에서 발생한 이벤트를 기록하고, 그 창이 시간에 따라 이동하면서 오래된 이벤트는 제외하는 방식이다.
Window 내 트래픽을 정밀하게 제어해 임계치 이상의 트래픽은 진입되지 못한다.
해당 알고리즘 자체의 단점은 진입되지 못하는 트래픽도 메모리에 저장되기 때문에 메모리 사용량이 높아질 수 있다는 것인데,
하지만 이 부분은 오히려 진입하지 못한 사용자들의 대기 순번을 지정해 예상 진입시간을 노출하는 요구사항에 오히려 부합한다.
즉 이 프로젝트에서는 단점 없이 효과적으로 구현할 수 있었을 뿐 아니라,
Window 의 사이즈를 운영자 설정사항인 1분 단위가 아닌 더 작은 단위(6초)로도 구현할 수 있어
1분 내에서도 특정 구간에서 사용자의 트래픽이 일순간 폭증하는(Burst) 상황에서도 Window 내 임계치에 막혀 트래픽이 비정상적으로 흘러가지 않는다.
또한 Redis Sorted Set 에서 특정 유저 Token 에 대한 값은 최초 진입 요청 Timestamp 값으로 정렬되어 저장할 수 있으므로,
Window 를 특정 분 혹은 구간으로 설정하면 유저 Token 값으로 해당 Window 안에 속하는지 빠르게 판별이 가능하다.
앞서 말했듯이 사용자의 순번을 조회하는 것은 Reids ZSET 내부의 Skip List 자료구조 덕분에 O(Log N) 시간복잡도로 조회가 가능하며,
예상 대기 시간은 Token Timestamp, 순번과 window size + 임계치를 조합해 사용자에게 응답한다.
여기서 끝이 아니라, 사용자 경험을 높이기 위한 여러 예외사항들을 처리해야 한다.
-
대기열 이탈자로 인한 후순위 사용자들의 무의미한 대기
- 만약 대기열 후순위에 추가된 사용자가 10,000 번에 위치했는데, 이 사용자가 진입 가능하기 전에 대기열에서 나가버려도 서버는 명시적으로 알 수 없다. (앱 강제 종료, 백그라운드 실행)
- 극단적으로 이러한 사용자들이 5,000 ~ 10,000 모두 대기열에서 이탈해버린다면 10,001 순번 사용자들은 이전 사용자들이 무의미한 순번을 가지고 있음에도 최초 예상 대기 시간보다 더 빨리 진입할 수 없게 되어버린다.
- 이러한 경우를 처리하기 위해, 사용자가 마지막으로 Polling 한 시간 을 별도 Hash 로 저장해, 특정 주기(ex: 30초)마다 최근 1분동안 Polling 하지 않은 사용자 Token 들을 대기열에서 삭제시켜 버린다.
- 이로 인해 사용자 입장에서는 최초 예상 대기 시간보다 더 빠르게 진입이 가능할 수 있다. 실제로도 운영 상 약 30~40% 의 사용자들이 대기열에서 이탈하는 것으로 확인되었다.
-
일시적인 사용자 개인 네트워크 지연(Wi-fi 등)으로 인한 Polling 중지 시간동안 현재 Window 가 이미 지나버린 경우
- 사용자의 App 에서 일시적으로 Polling 이 되지 않는 예외사항은 꽤 존재한다. (Wi-fi 순단, App Crash, 핸드폰 성능 문제, 전화로 인한 갑작스런 백그라운드 이동 등)
- 이 순간동안 사용자의 Token 이 현재 진입 가능한 Window 보다 지나버린 경우에도 진입할 수 있게 해주어야 사용자는 억울하지 않다.
- 그래서 꼭 Window 내의 Token Timestamp 값만 진입 가능한 것이 아닌, 지나버린 Token 도 진입할 수 있게 해준다.
- 물론 그 시간은 무제한이 아닌 위 1. 에서 언급한 마지막 Polling 시간 기준 1분이 지난 것들은 삭제시켜 불필요한 메모리 낭비는 방지한다.
-
대기열이 없어야 되는 평상시임에도, 일시적인 Burst 로 인해 Window 내 임계치에 도달해 대기열이 발생하는 경우
- 대량 트래픽 이벤트가 없을 때에는(평상시) 사용자 경험을 높이기 위해 대기열이 발생하면 안된다.
- 다만 평상시에도 충분히 광고/홍보/공지성 푸시 및 알림을 발송해 사용자 트래픽이 인입될 수 있다.
- 이 정도의 트래픽은 대기열 없이 전부 흘려보내도 핵심 인프라에는 영향을 끼치지 못하기 때문에, 이 때에는 사용자들이 대기열에 진입해서는 안 된다.
- 따라서 큰 1분 단위 Window 내의 작은 단위 6초 Window 내에서는, 6초 단위의 Window 를 엄격하게 처리하지 않는다.
- 예시) 1분 동안 10,000 명 진입 가능하게 설정. -> 내부 로직에서는 6초 동안 1,000 명씩 진입 가능
- 다만 광고성 푸시로 인해 2초동안 2,000 명이 인입된다면 대기열이 걸려야 할까? 아니다. 이 정도는 핵심 인프라가 충분히 버틸 수 있어 오히려 대기열에 걸리면 사용자 경험에 악영향만 끼칠 뿐이다.
- 이를 대비해, 작은 단위의 Window 가 사용자의 첫 트래픽 진입 요청을 차단해 대기열에 보내는 조건은 이미 대기열이 걸린 경우 로 제한한다.
- 이렇게 구현한다면 평상시에도 1분 내 10,000명이 넘게 진입한 경우에만 대기열이 발생하게 되어 문제가 발생하지 않는다.
인프라 선택 (뉴타닉스 vs AWS)
사내에서는 전자금융업 보안 상 Public Cloud 사용이 제한적이었다.
그래서 설계 초기 당시 온프레미스 서버에 가상화 솔루션을 설치해 사용하는 뉴타닉스 사용을 지시받았다. (사내에서도 사용 중인 솔루션)
다만 뉴타닉스의 한계는 아래와 같았다.
- 사내 온프레미스 서버를 사용하므로, 물리적인 서버 축소/확장에 제한이 있었음.
- 이로 인해 짧은 이벤트에 대비해야 하는 서버 확장이 어려웠고,
- 서버를 축소 해야되는 상황에도 놀고 있는 자원들이 많은 것이 문제였음.
- 가상화 솔루션 특성 상, CPU Overcommitting 으로 인한 문제가 발생할 가능성이 높았음.
- CPU Overcommitting : 물리적인 CPU Core 수보다 논리적으로 가상화된 CPU Core 수를 제공.
- 이로 인해 CPU Bound 가 많은 작업이 수행되면 다른 논리 가상화 CPU 에 영향을 끼칠 수 있음.
- 신규 대기열 프로젝트 특성 상 성능 극대화를 위해 I/O 보다 CPU Bound 가 많은 작업이 수행되었음.
이로 인해 AWS 의 장점을 비교해 AWS 를 사용해야 하는 이유를 보고했고,
- 물리적인 인스턴스 확장에 거의 제한이 없음.
- 사용한 만큼만 비용을 지불.
- ALB, EC2 오토스케일링 등의 자체 추상화된 서비스를 편리하게 이용할 수 있음.
- 코어 인프라와의 통신은 일절 없고, 개인화된 정보는 관리하지 않는 완전 독립된 구조로 설계.
사용 허가를 받음에 따라 아직은 사내 운영이 미숙한 AWS 에 대해 직접 학습하고 설계 및 검증을 했다.
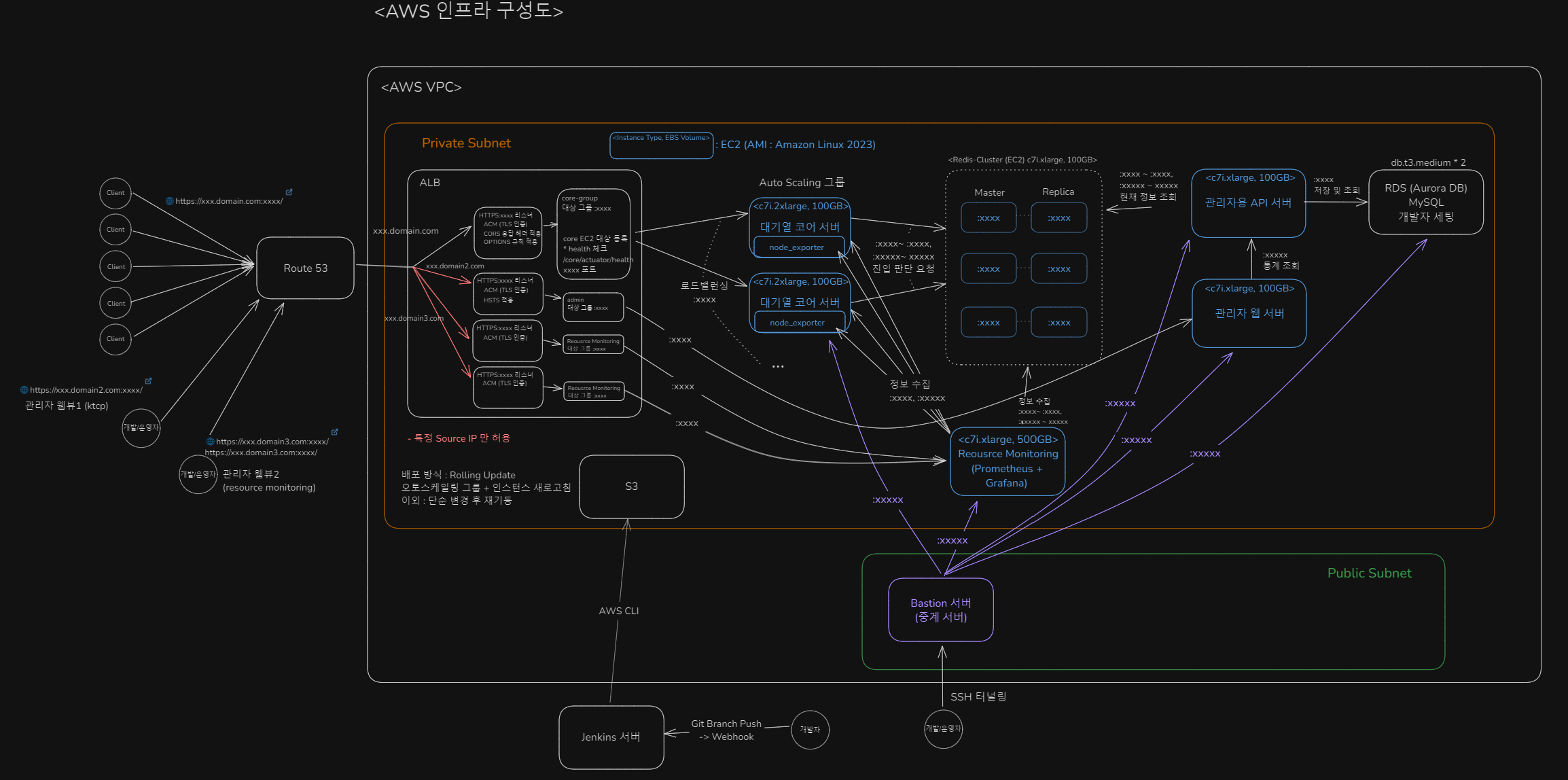
인프라 기본 구조
핵심 인스턴스는 모두 EC2 로 띄움
- 대기열 코어 서버 (c7i.2xlarge)
- 대기열 인입 요청 전/후처리, Redis 와 Lua Script 통신
- 오토스케일링 그룹 적용
- 관리자용 API 서버 (c7i.xlarge)
- 관리자용 웹 서버 (c7i.xlarge)
- Redis Cluster (c7i.2xlarge)
- master 3, replica 3
- Resource Monitoring 서버 (c7i.xlarge)
- Prometheus, Grafana
인스턴스 타입 선택 이유 (c7i.xlarge, c7i.2xlarge)
- c7i.xlarge : 4 vCPU, 8GB
- c7i.2xlarge : 8 vCPU, 16GB
- vCPU : 물리 코어 수가 아닌 논리 Thread 수
- c : 컴퓨팅 최적화 (CPU)
- 7 : 세대 수 (당시 7이 최신 세대라 가장 성능 및 비용 효율적)
- i : Intel 기반 프로세서
c7i 의 특징
- c7i 는 Intel Zeon 기반, CPU Bound 작업에 최적화
- 메모리는 DDR4 가 아닌 DDR5 기반
- 램 클럭이 높아 Redis 성능 향상
대기열 코어 서버, Redis 만 2xlarge 선택 이유
- 대기열 코어 서버 : 부하테스트 결과, 최소 이중화 인스턴스를 고려해 2xlarge 인스턴스 2개가 평시 트래픽을 여유있게 처리할 수 있는 스펙.
- Redis : Redis Command 는 Single Thread 기반으로 동작하지만 I/O, 백업, Replication 등의 작업을 고려해 2xlarge 인스턴스가 적절하다고 판단.
보안 고려
- 모든 SSH 접속은 Bastion 서버를 통해서만 허용
- 즉, Bastion 서버로 proxy 해 SSH 터널링으로만 접속할 수 있다.
- Bastion 서버의 IP, SSH Port, SSH key, user/pw 정보 + 대상 EC2 서버의 IP, SSH Port, SSH key, user/pw 정보를 알아야만 SSH 접속 가능.
- 관리자 및 모니터링 서버는 특정 Source IP 접속만 허용
- 배포 파일 업로드는 사내 Jenkins 서버를 통해서만 허용
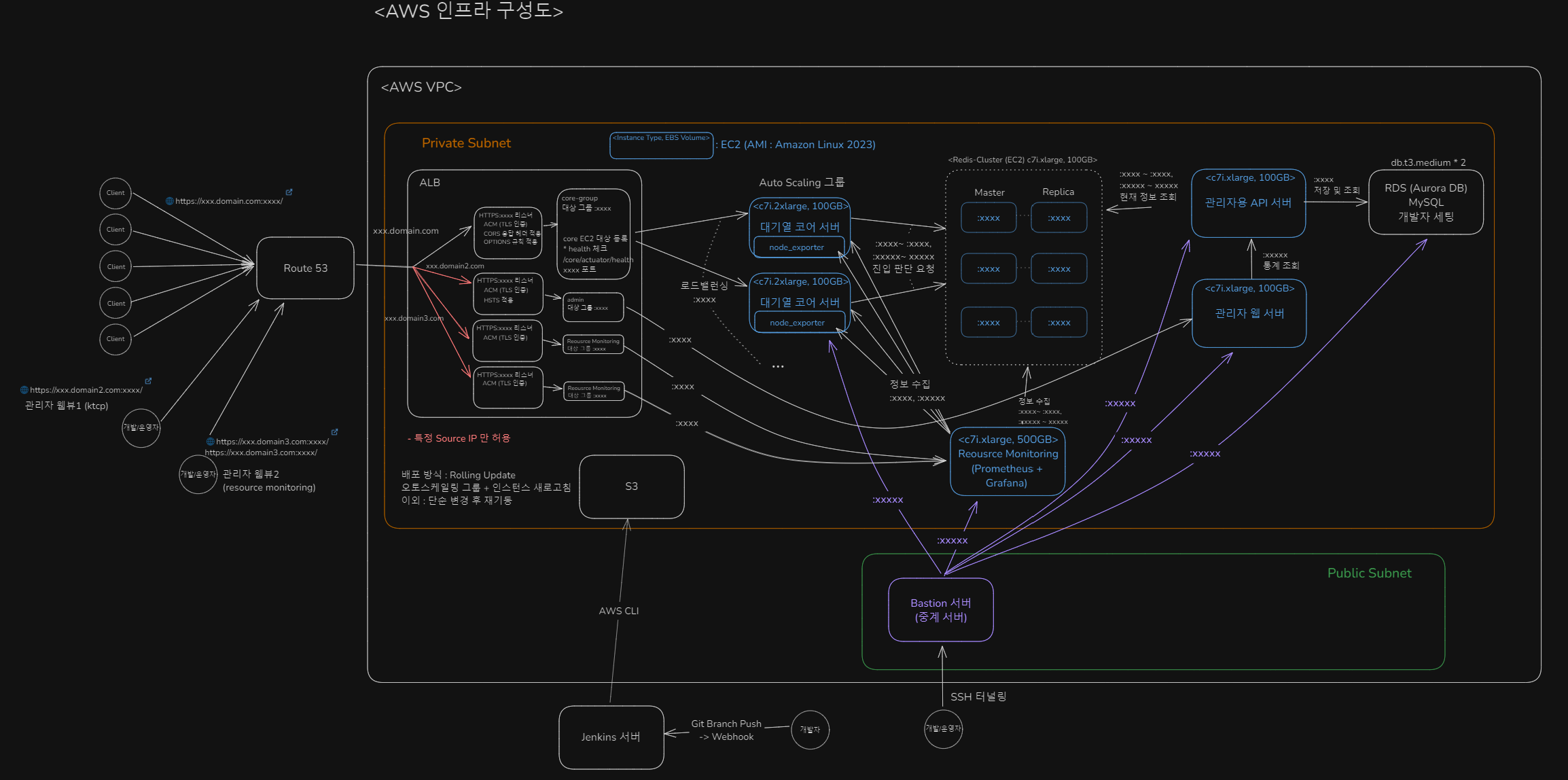
인프라 배포 구조
- 빠른 배포를 위해 기본 Properties 및 로그, 모니터링이 적용된 AMI (이미지) 를 커스텀해서 사용
- 개발자 master 브랜치 push -> Jenkins Pipeline Build (+ 소스 검증, 테스트) -> S3 의 특정 디렉토리에 업로드 (AWS CLI)
- 운영자 S3 업로드 확인 -> 시작 템플릿의 script 에 S3 의 디렉토리 명시해 버전 업데이트 -> EC2 오토스케일링 그룹 인스턴스 새로고침 (롤링 업데이트 방식)
인프라 모니터링 구조
- ALB : 기본적으로 AWS Cloudwatch 에 Metric 들이 저장되므로, Cloudwatch - Grafana 연동을 통해 모니터링
- 대기열 코어 서버 OS : EC2 내부에 Node-Exporter 를 통해 Prometheus 가 수집해 Grafana 에서 모니터링
- 대기열 코어 서버 Spring Boot Metric : prometheus actuator 를 통해, Prometheus 가 수집해 Grafana 에서 모니터링
- Redis : Grafana 플러그인을 통한 모니터링 (CPU, Memory, I/O, Replication, Slowlog...)
- MySQL : Grafana 에서 SQL 조회를 통해 Zone(대기열)의 통계 조회
Prometheus 는 어떻게 Auto Scaling 되는 대기열 코어 서버의 각각의 인스턴스들의 Metric 들을 수집하는지
- 일정 주기(30s)마다 AWS 에 특정 이름 또는 Auto Scaling Group 에 속한 인스턴스들의 Private IP 들을 조회
- 조회되는 Private IP 들에게 Metric 수집 요청
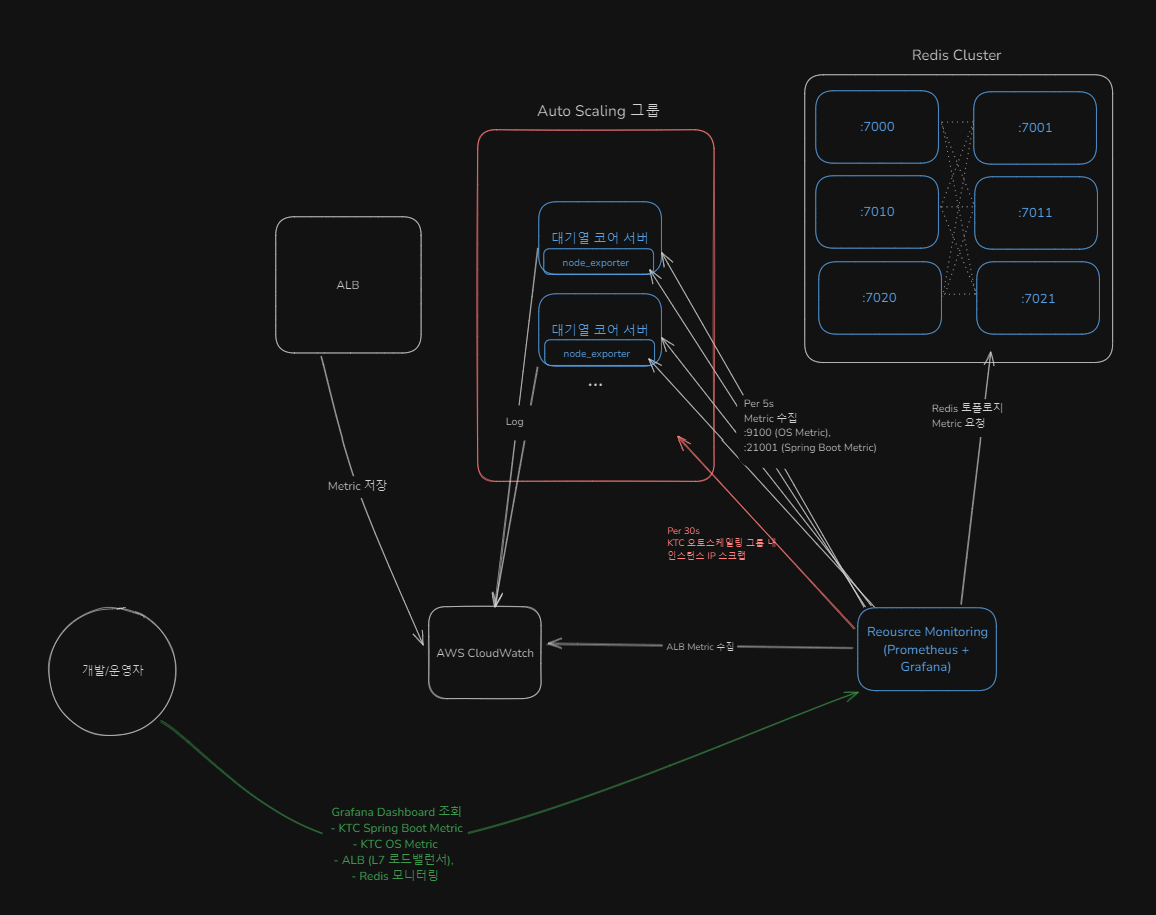
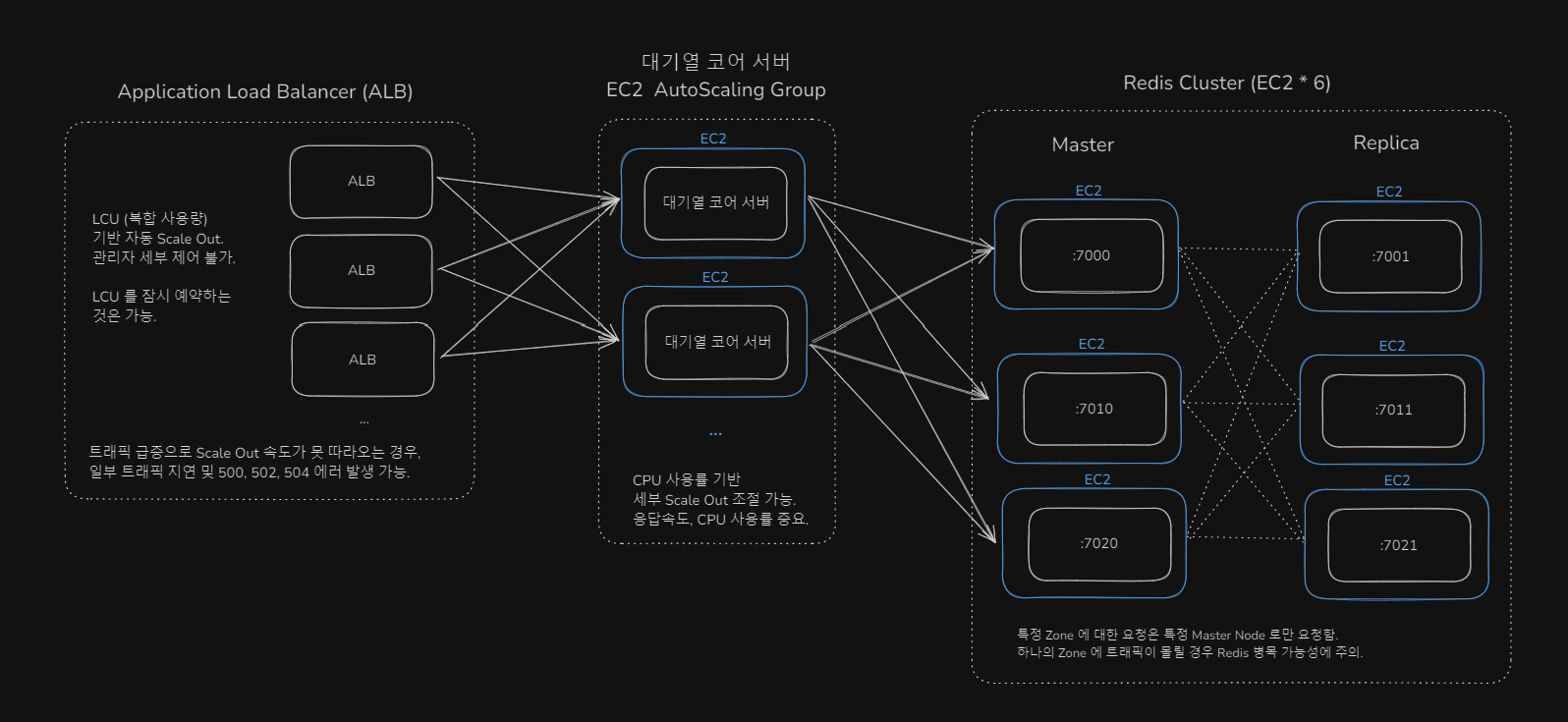
이벤트 발생 예정 시 사전 작업 사항 (병목 지점 파악)
코어 서버 EC2 Scale Out
- 트래픽이 몰리는 Spring Boot 인스턴스
- AWS EC2 Auto Scalint Group 에 등록
- CPU 30% 가 넘어갈 시 Auto Scale Out 되도록 조정
- 일반적으로는 CPU 50% 가 권장 조정 값이지만,
- 서비스 특성 상 트래픽이 빠른 속도로 폭증하므로 보수적으로 적용.
- CPU Metric 은 일반적으로 5분 단위로 측정되나, 세부 조정으로 10초 단위로 측정되도록 설정.
- 다만 이벤트 폭증이 명시적으로 예상될 때에는 EC2 인스턴스가 띄워지는 시간(약 60초) 및 로드밸런서 health check/등록시간도 고려해, 미리 Scale Out 한다.
Scale Out 후 Warm Up 트래픽 전송
- Java 특성 상 자주 사용되는 코드는 컴파일 캐싱한다.
- JVM 실행 전에는 .java 파일을 바이트코드인 .class 파일로 변환
- JVM 실행 후에는 클래스 사용 시점에 클래스 로더가 lazy loading 수행, 로딩된 클래스를 기계어로 변환
- JIT 컴파일러는 자주 사용되는 코드를 Hot Spot 으로 지정해 기계어를 캐싱해둔다.
- Tiered Compilation : 호출 순에 따른 최적화 단계
- C1 컴파일러 : 빠르지만 제한된 수준으로 최적화 수행 (기본값 200회)
- C2 컴파일러 : 최적화 수준이 높은 컴파일 수행 (기본값 5,000회)
- Tiered Compilation : 호출 순에 따른 최적화 단계
- 실제로 Warm-Up 전/후 응답 지연시간 확인 시 약 2.5배의 차이가 발생했음. (5~6ms -> 2~3ms)
ALB (Load Balancer) LCU 용량 예약 (LCU-R; LCU Reservation)
- LCU 이전에는 Pre-Warming 이라는 기능으로 제공했었음.
- LCU : ALB 가 처리하는 트래픽의 여러 지표를 통합하는 단위
- LCU 예약 (LCU Reservation) :
- AWS는 예측 가능한 트래픽 급증에 대비하여 ALB의 최소 용량을 사전에 예약할 수 있는 LCU 예약(LCU-R) 기능을 제공한다.
- 갑작스러운 트래픽 증가로 인한 ALB 의 5xx 응답 에러를 방지한다.
- 평시 LCU 사용량 100 이하, 트래픽 급증 시 1,000 이상 사용하므로 사전 LCU 용량 예약을 한다.
- LCU 사전 예약은 반영되는 데 까지 1~2시간 소요되며 웹 콘솔에서는 특정 시간에 예약이 불가해 사전에 미리 조정해야 한다.
튜닝
Redis Lua Script
- 대기열 코어 서버의 핵심 로직은 Lua Script 로 구현
- 최대한 Redis 와의 I/O 를 줄이고, 명령어를 한 번에 모아서 요청해 처리하도록 한다.
- Zone 에 대한 유저 순번 조회, Zone 분/N초당 임계치 확인, Zone 임계치 내 진입 유저 수 조회, 마지막 Polling 시간 업데이트, 진입 및 대기열 내 유저 삭제 처리 등..
- Redis 에서는 명령어 모음인 Lua Script 에 대한 컴파일 캐싱(EVALSHA)을 통해 성능을 향상시킨다.
Redis io-threads
- Redis 6.0 까지는 완전한 단일 스레드 모델로 동작. 아래 중 1번과 4번 단계가 CPU 시간의 상당 부분을 차지해 I/O 가 주요 병목지점으로 작용함.
- 소켓에서 요청 읽기 (socket read)
- 명령 파싱 (command parsing)
- 명령 실행 (command execution)
- 소켓에 응답 쓰기 (socket write)
- 이후 버전에서는 io 멀티플렉싱으로 인해 io thread 를 여러 개 설정하면 통합 I/O 성능 향상
- c7i.2xlarge 에서는 사용 가능한 thread 수가 8이므로 main, backup 용 thread 를 제외해 6개로 설정.
Redis 백업 최적화
- Redis 의 백업 방식은 RDB, AOF 로깅으로 나뉜다. (기본값 : 백그라운드 저장)
- RDB : 스냅샷 방식으로 Redis 인스턴스의 데이터를 파일로 저장
- 일정 주기마다 수행되며, 마지막 주기를 기준으로 데이터를 복구할 수 있어 일부 마지막 데이터가 유실될 수 있다.
- AOF : Append Only File 방식으로 Redis 인스턴스의 데이터 변경을 파일로 저장
- 데이터 삽입, 삭제 등의 모든 과정을 저장
- 데이터 복구 시 AOF 파일에 기록된 명령어를 순서대로 다시 실행해 데이터를 복구한다.
- 데이터 복구 시간이 다소 오래 걸린다.
- RDB : 스냅샷 방식으로 Redis 인스턴스의 데이터를 파일로 저장
- 백업 복구 시간을 고려해 RDB 방식을 채택.
- BGSAVE 의 fork()로 자식 프로세스를 생성해 저장해 복사 비용이 큰 것을 고려,
- Master Node 에서 백업을 수행하면 실제 Command 실행에 따른 CPU 사용이 발생하므로 Replica Node 에서만 수행한다.
JIT 컴파일 캐싱 Tier 임계치 조정
Java 의 JIT(Just-In-Time) 컴파일 캐싱은 JVM에서 실행 성능을 최적화하기 위해 사용하는 기술이다.
이 기술은 자주 사용되는 바이트코드를 네이티브 머신 코드로 변환하여 heap-off 메모리에 코드 캐시로 저장한다.
이는 코드의 수행 횟수가 많을 수록 Tier 가 높아져 더 최적화된 수행을 가능하게 만든다.
이 프로젝트에서는 갑작스런 트래픽 급증(Burst)에도 컴파일 캐싱이 늦게 되는 것을 조금이나마 방지하기 위해,
컴파일 최적화 Tier 임계치 옵션을 튜닝한다.
java -XX:+PrintFlagsFinal -version | grep Threshold | grep Tier
java version "21.0.2" 2024-01-16 LTS
Java(TM) SE Runtime Environment (build 21.0.2+13-LTS-58)
Java HotSpot(TM) 64-Bit Server VM (build 21.0.2+13-LTS-58, mixed mode, sharing)
uintx IncreaseFirstTierCompileThresholdAt = 50 {product} {default}
intx Tier2BackEdgeThreshold = 0 {product} {default}
intx Tier2CompileThreshold = 0 {product} {default}
intx Tier3BackEdgeThreshold = 60000 {product} {default}
intx Tier3CompileThreshold = 2000 {product} {default}
intx Tier3InvocationThreshold = 200 {product} {default}
intx Tier3MinInvocationThreshold = 100 {product} {default}
intx Tier4BackEdgeThreshold = 40000 {product} {default}
intx Tier4CompileThreshold = 15000 {product} {default}
intx Tier4InvocationThreshold = 5000 {product} {default}
intx Tier4MinInvocationThreshold = 600 {product} {default}임계치 설명
- InvocationThreshold : 메서드가 순수하게 호출된 횟수
- BackEdgeThreshold : 루프(for, while 등)가 실행된 횟수
- CompileThreshold : Invocation과 BackEdge를 모두 고려한 종합 점수
- MinInvocationThreshold : 컴파일을 고려하기 위한 최소한의 메서드 호출 횟수
JIT 컴파일 캐싱 Tier
Tier0 : 인터프리터 (Interpreter) - 바이트코드를 한 줄씩 해석해서 실행.
Tier1 : C1 컴파일러 (Simple C1 compiled code) - 프로파일링 정보 없이, 매우 기본적인 최적화만 수행하여 빠르게 컴파일.
Tier2 : C1 컴파일러 (Limited C1 compiled code) - 일부 프로파일링 정보 수집.
Tier3 : C1 컴파일러 (Full C1 compiled code) - 모든 프로파일링 정보를 수집하여 C2 컴파일러가 사용할 수 있도록 준비.
Tier4 : C2 컴파일러 (C2 compiled code) - C1이 수집한 프로파일링 정보를 바탕으로 가장 높은 수준의 최적화를 수행. 컴파일 속도는 느리지만 실행 속도는 가장 빠름.
일반적으로 Tier0 -> Tier3 -> Tier4 단계로 상승함.
Tier1, Tier2 는 특수한 경우에 사용되는데,
- Tier1 : 메서드의 복잡성이 낮아 추가 최적화가 불필요하다고 판단할 때 사용.
- Tier2 : C2 컴파일러 큐가 가득 찬 상황에서 사용되는 특수한 레벨. 임시적 성격이 강하며, 큐에 여유가 생기면 Tier3 또는 Tier4로 재컴파일된다.
Tier1 ~ Tier4 임계치 일괄 조정
# Threshold 를 일괄 0.5배로 조정. 제일 간단한 설정 방법
-XX:CompileThresholdScaling=0.5Tier 임계치 조정 시 유의사항
- 과도한 코드 캐시 메모리 사용 주의 :
- c7i.2xlarge 에서는 16GB 메모리.
- heap 에는 4GB 할당해 충분할 뿐더러 로직 관련한 코드 라인 수가 많지 않음.
- Virtual Thread 또한 메모리 사용량 최적화에 기여
- Cold Start 직후 트래픽 급증 시 컴파일 주의 :
- 트래픽 급증 예상되는 이벤트에서는 사전 Warm Up 트래픽으로 방어
- 예상치 못한 트래픽 급증에는 일순간 C2 Compile 과정에서 순간 CPU 사용량이 증가할 수 있으나,
그 순간은 사용자의 입장에서는 매우 짧을 뿐더러 빠른 Warm Up 을 위한 일종의 트레이드오프
차후 개선 고려사항
AOT (Ahead-of-Time) 컴파일 :
- GraalVM Native Image 를 통해 JIT 없이 코드를 네이티브로 컴파일해 실행 중 컴파일로 인한 성능 이슈를 아예 고려하지 않을 수 있다.
트러블슈팅
Redis ZRANGE 8,000 개 이상 범위 조회 시 에러 발생
부하테스트 도중,
Redis Lua Script 제한으로 인해 ZRANGE 등의 unpack() 함수는 8,000 개 이상의 범위를 한꺼번에 처리할 시 아래와 같은 에러 발생
(error) ERR Error running script (call to f_xxx): user_script:line_number: too many results to unpack이로 인해 5,000 개의 chunk size 조절로 반복문 처리.
부하테스트
부하테스트 환경
- 부하테스트 도구 : K6
- 고루틴 기반 경량화된 부하테스트 도구, 동일 리소스에서 JMeter 대비 10배 이상 많은 부하를 줄 수 있음.
- 실제로 c7i.large 서버 1대로도 Ephemeral Ports 기본 값 약 28,000 개를 모두 가상 사용자로 활용할 수 있음.
- AWS EC2 에 올려서 사용
- c7i.large * 20
- 모니터링
- Prometheus(메트릭 수집), Grafana(모니터링 대시보드), InfluxDB(부하테스트 결과 저장)
- c7i.xlarge
- Prometheus(메트릭 수집), Grafana(모니터링 대시보드), InfluxDB(부하테스트 결과 저장)
- 서비스 기본 인프라
- 대기열 코어 서버 c7i.2xlarge * 16
- Redis c7i.2xlarge * 6 (Master 3, Replica 3)
부하테스트 환경 자동화
- 부하테스트 인프라를 AWS 에 지속적으로 유지하기에는 비용 부담이 있어, 인프라를 일괄 생성 및 삭제하는 환경 구축
- Terrform 을 활용
- Terraform 부하테스트/모니터링 환경 구축 에 과정 작성.
부하테스트 조건
- 충분한 Warm-Up 후 수행
- VUs Ramp-UP
- 0 ~ 10s : max VUs 의 50% 까지 점진 증가
- 10 ~ 120s : max VUs 100% 까지 점진 증가
- 120 ~ 150s : max VUs 100% 유지
- 150 ~ 160s : 0으로 점진 감소
K6 부하테스트 스크립트 예시
import http from 'k6/http'; import { sleep, check, group } from 'k6'; import { Counter } from 'k6/metrics';
// 외부 환경변수로부터 stages 값 주입
const stage1_duration = __ENV.STAGE1_DURATION || '10s';
const stage1_target = Number(__ENV.STAGE1_TARGET || 10000);
const stage2_duration = __ENV.STAGE2_DURATION || '110s';
const stage2_target = Number(__ENV.STAGE2_TARGET || 20000);
const stage3_duration = __ENV.STAGE3_DURATION || '30s';
const stage3_target = Number(__ENV.STAGE3_TARGET || 20000);
const stage4_duration = __ENV.STAGE4_DURATION || '10s';
const stage4_target = Number(__ENV.STAGE4_TARGET || 0);
// 테스트 설정
export let options = {
stages: [
{ duration: stage1_duration, target: stage1_target },
{ duration: stage2_duration, target: stage2_target },
{ duration: stage3_duration, target: stage3_target },
{ duration: stage4_duration, target: stage4_target },
],
tags: {
team : 'server',
test_name: 'basic-test'
},
};
// 커스텀 메트릭 정의
const waitRequests = new Counter('wait_requests_total');
const entryRequests = new Counter('entry_requests_total');
const canEnterFalse = new Counter('can_enter_false_count');
const canEnterTrue = new Counter('can_enter_true_count');
export function setup() {
console.log('Setup: Initializing test setup...');
// 공통으로 사용할 헤더 초기화
let headers = { 'accept': '/', 'Content-Type': 'application/json', };
const waitPayload = JSON.stringify({
"zoneId": "TEST_ZONE",
"clientIp": "127.0.0.1",
"clientAgent": "WEB"
});
return {
headers: headers,
waitPayload: waitPayload
}
}
export default function (data) {
const randomSleepTime = Math.floor(Math.random() * 3000) + 1;
sleep(randomSleepTime / 1000);
let token = null; let canEnter = false;
group('POST /traffic/wait', function () {
let res = http.post('http://spring.abc.com:xxxxx/abc/api/test1', data.waitPayload, {headers: data.headers});
waitRequests.add(1);
check(res, {'is WAIT status 200': (r) => r.status === 200 });
let resBody = res.json();
canEnter = resBody.canEnter;
// console.log(`WAIT - canEnter: ${canEnter}, Status: ${res.status}, Body: ${res.body}, Duration: ${res.timings.duration}ms`);
token = resBody.token;
if (canEnter) {
canEnterTrue.add(1);
} else {
canEnterFalse.add(1);
const pollingPeriod = resBody.waiting?.pollingPeriod || 3000;
sleep(pollingPeriod / 1000);
}
});
if (!canEnter) {
group('POST /traffic/entry', function () {
const entryPayload = JSON.stringify({ "zoneId": "TEST_ZONE", "token": token });
while (!canEnter) {
entryRequests.add(1);
let res = http.post('http://spring.abc.com:xxxxx/abc/api/test2', entryPayload, {headers: data.headers});
let resBody = res.json();
canEnter = resBody.canEnter;
check(res, {'is ENTRY status 200': (r) => r.status === 200 });
// console.log(`ENTRY - Status code: ${res.status}, Body: ${res.body}, Duration: ${res.timings.duration}ms`);
if (canEnter) {
canEnterTrue.add(1);
break;
} else {
canEnterFalse.add(1);
const pollingPeriod = resBody.waiting?.pollingPeriod || 3000;
sleep(pollingPeriod / 1000);
}
}
});
} else { console.log("Skipping ENTRY request because canEnter was not true or token was not obtained."); }
console.log("1 user entered!\n\n") }부하테스트 모니터링 대상
Client 입장의 API
- 호출 수
- 응답시간 (최소, 평균, 최대, P90, P95)
- HTTP Connection 시간 (최소, 평균, 최대, P90, P95)
대기열 코어 서버
- OS Prometheus Metric
- CPU
- Memory
- IO
- Netstat (Socket Overflow 등의 TCP 오류 확인)
- Spring Boot Prometheus Metric
- GC
- Server 의 API 응답시간
Redis
- CPU
- Memory
- command per second
- slowlog
부하테스트 결과
요약
Redis Node 하나 당 VUs = 600,000 명 가량일 때까지 지연 발생 없음. (그 이상부터는 지연 발생)
- VUs(가상 사용자) : 600,000 명
- API 호출 건수 : 1,013만 건
- 대기열 코어 서버
- OS CPU : max 50%
- GC : 이상 없음
- API 응답시간 :
- 평균 : 9.94ms
- 중앙값 : 2.74ms
- P(90) : 19.40ms
- P(95) : 36.48ms
- Redis
- CPU : 250%
- Ops/sec : 800K
특이사항 : Redis CPU 중간에 중간에 peak 500% 는 BGSAVE 시 발생한 것으로 예상.
Metric 캡처
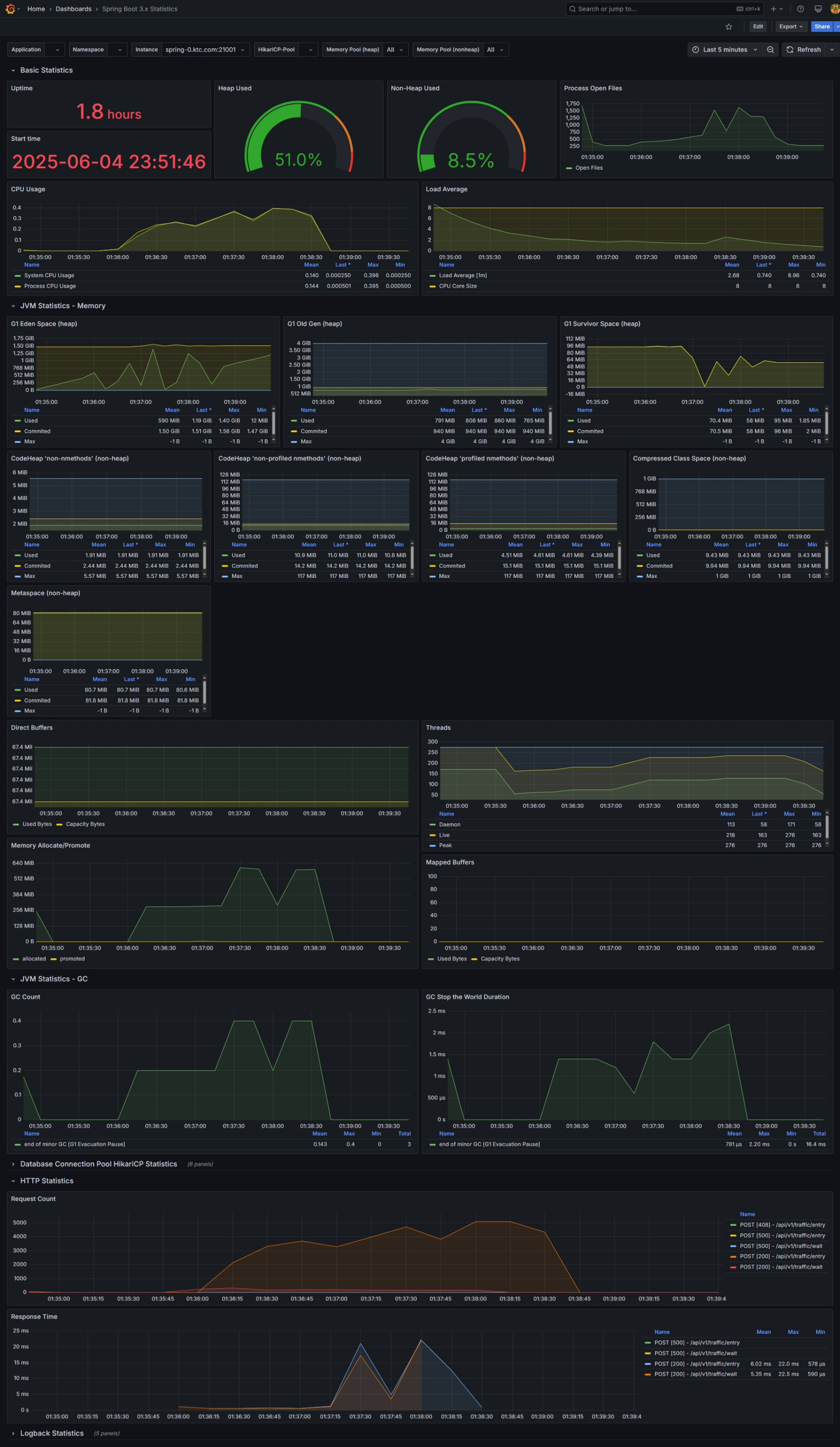
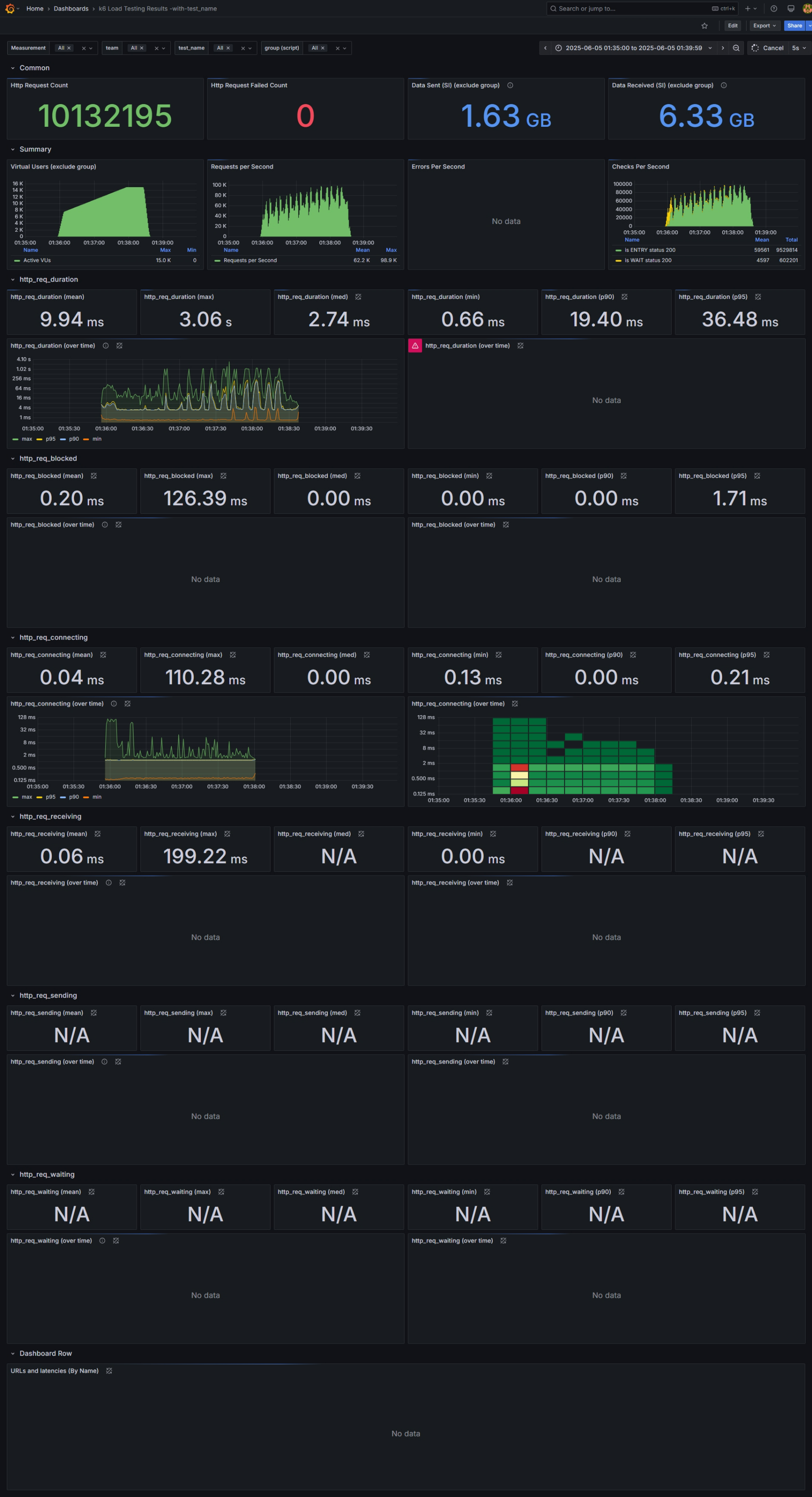
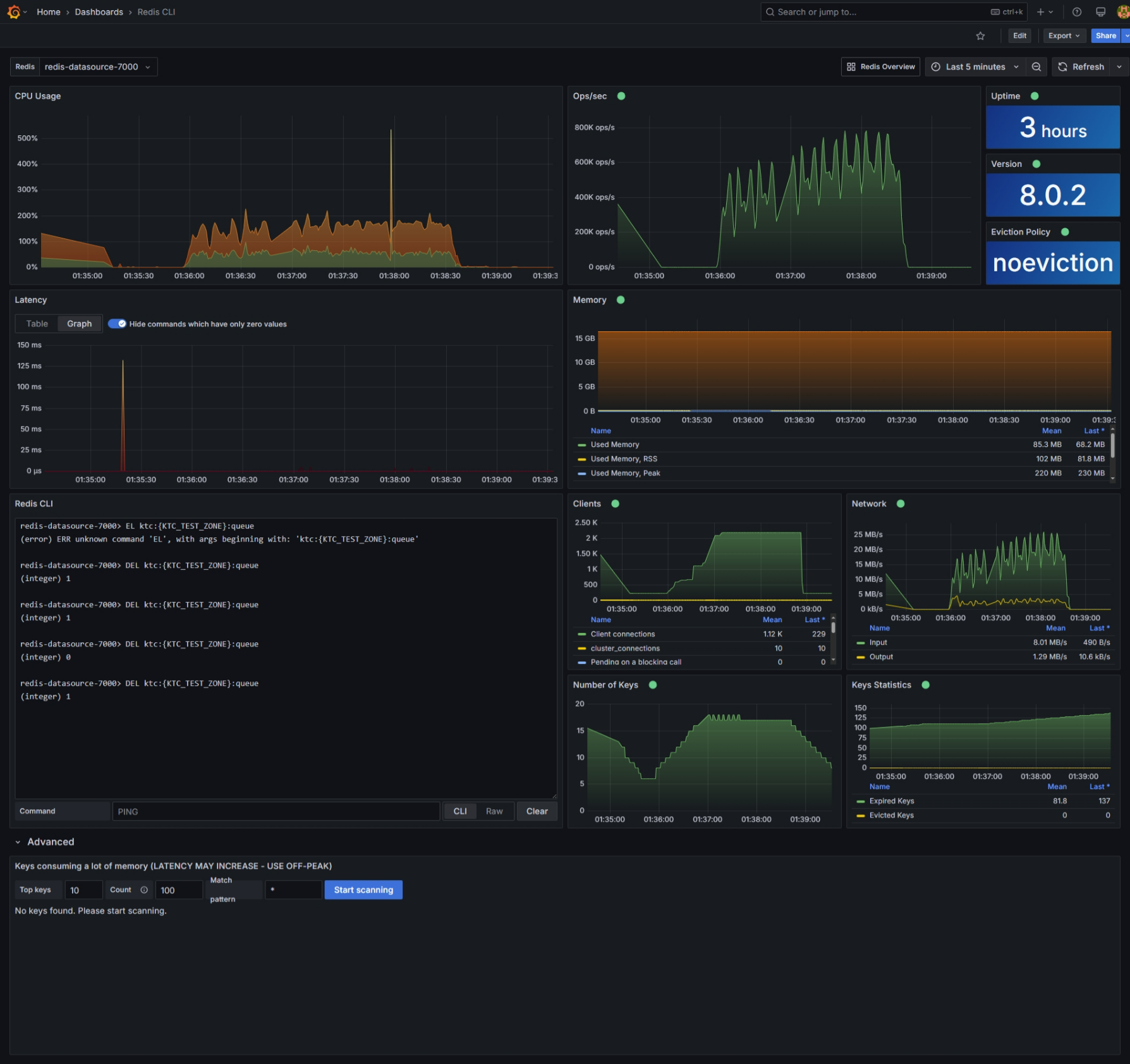
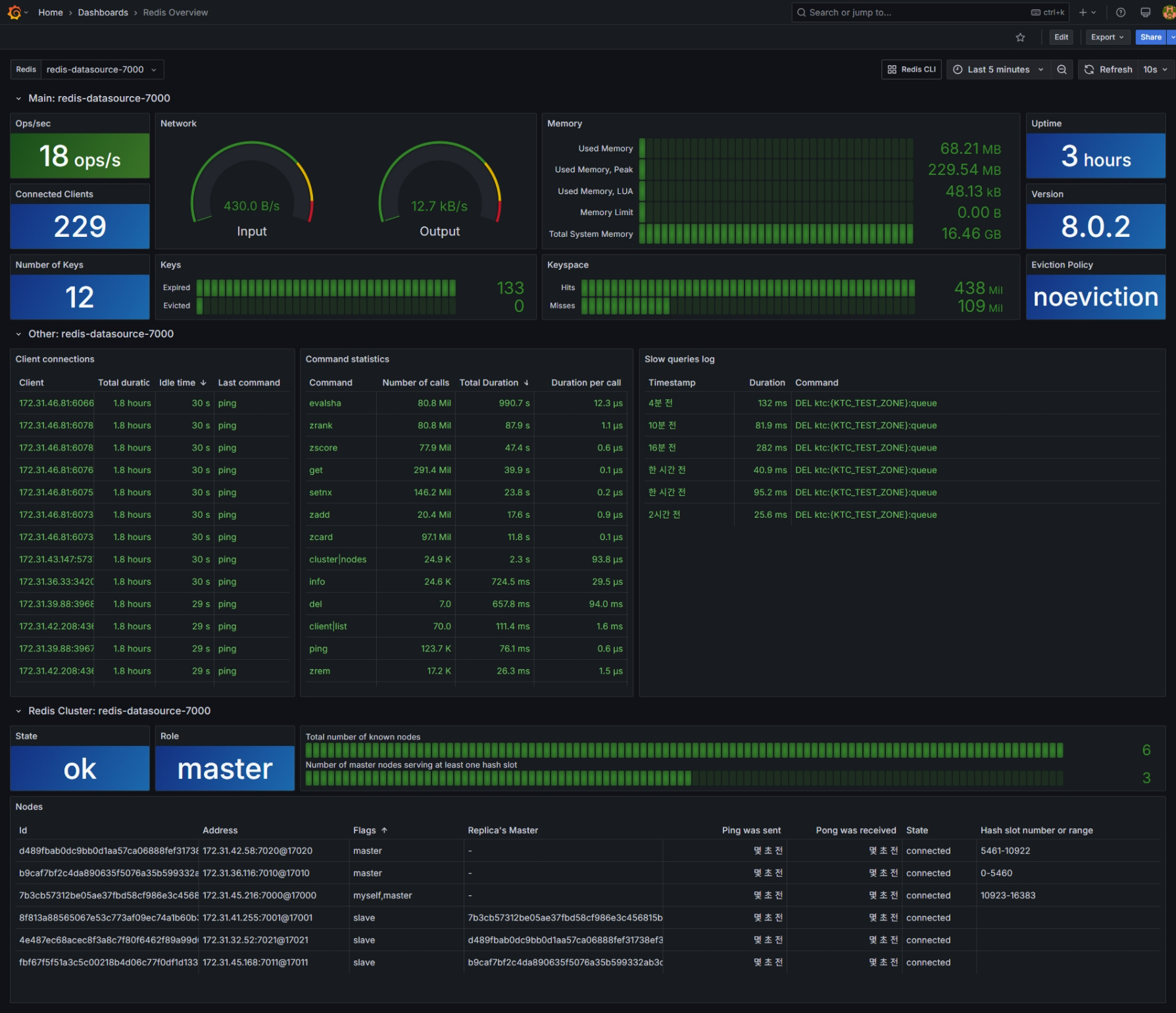
관제(모니터링)
모니터링 대상 (Grafana 대시보드 통합)
ALB (CloudWatch )
- 요청수, 대상 응답시간, 대상 (5XX, 4XX, 3XX, 2X) 응답 수, ALB (5XX, 4XX, 3XX) 응답 수
대기열 서비스
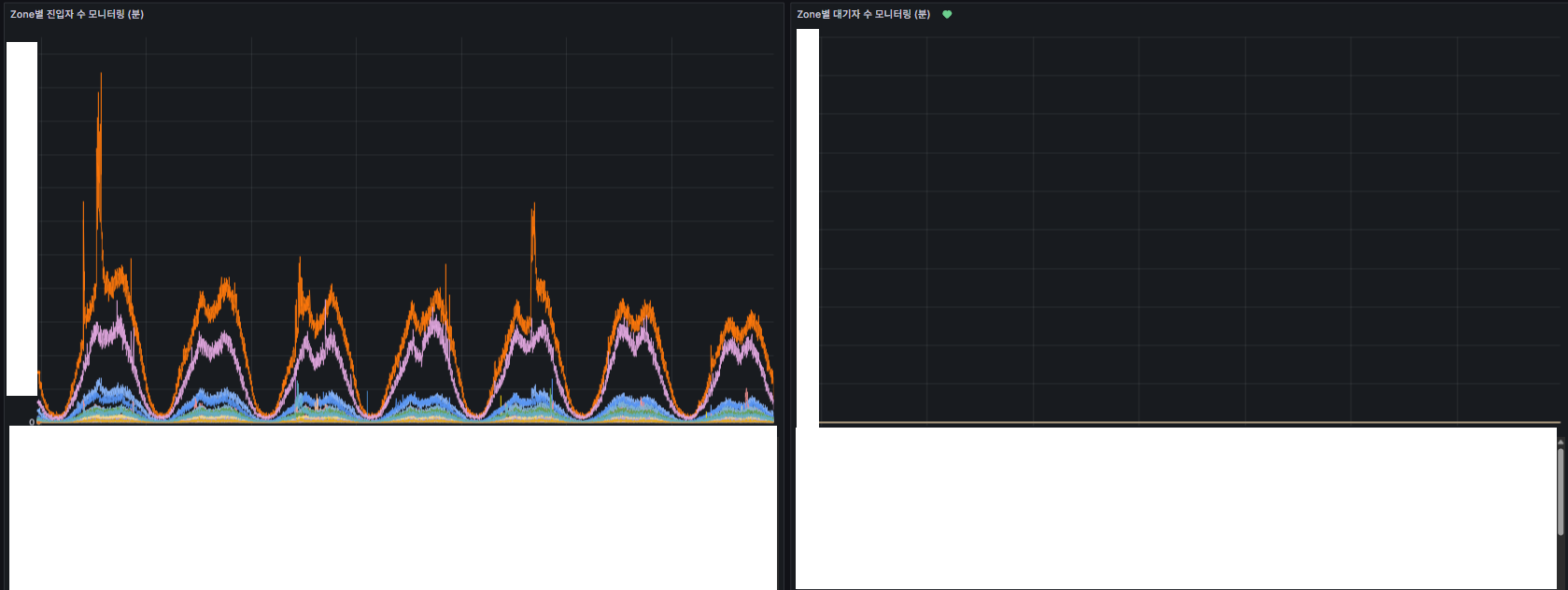
- Zone 현황 (진입 수, 대기자 수, 임계치 등)
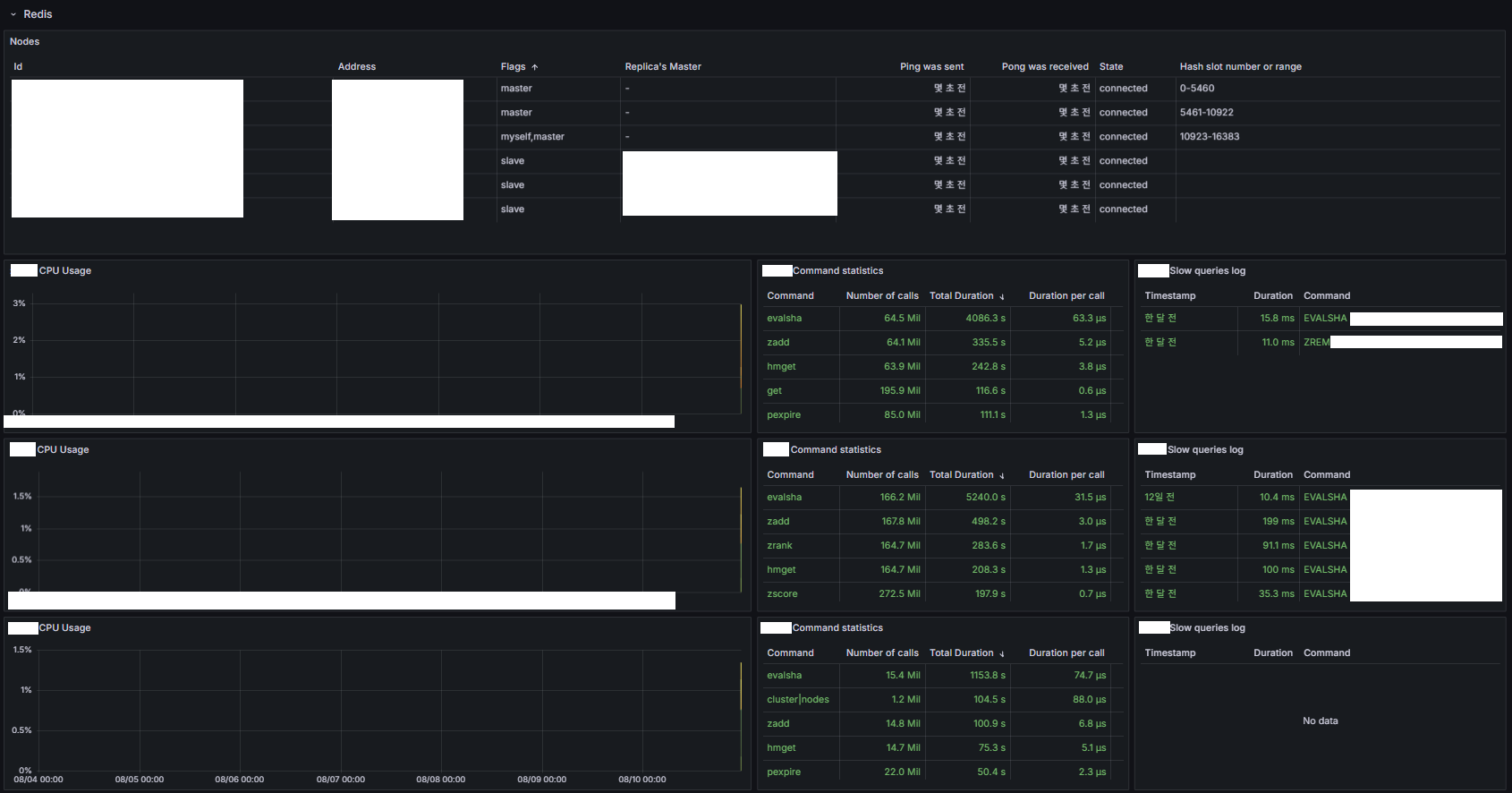
Redis
- Master/Replica 현황
- CPU, Command 수행 수 및 평균 수행 시간, SlowLog
- INFO 명령어는 무거워 직접적으로 사용하는 것은 지양
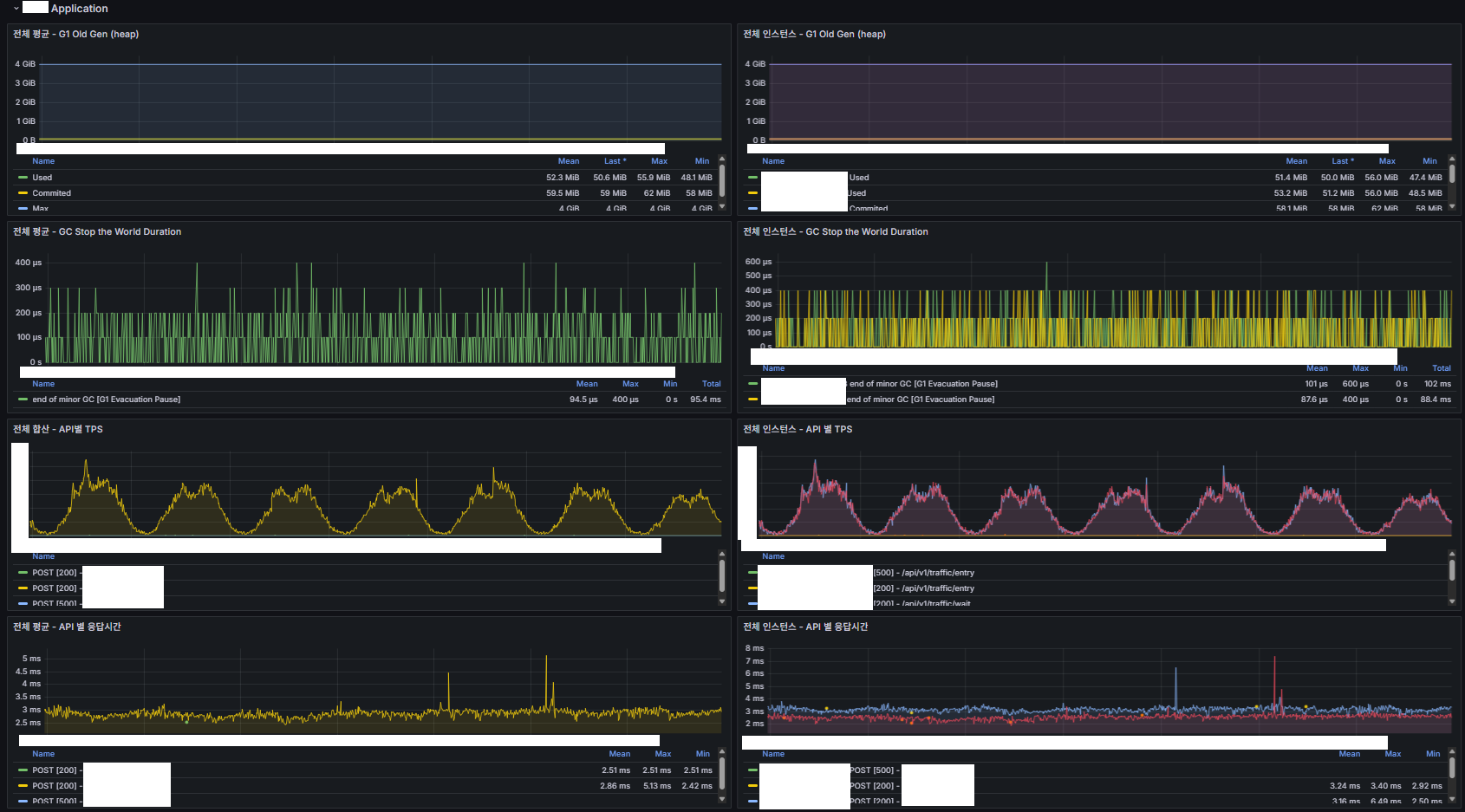
대기열 코어 서버 Application
- CPU
- GC
- TPS
- API 응답시간
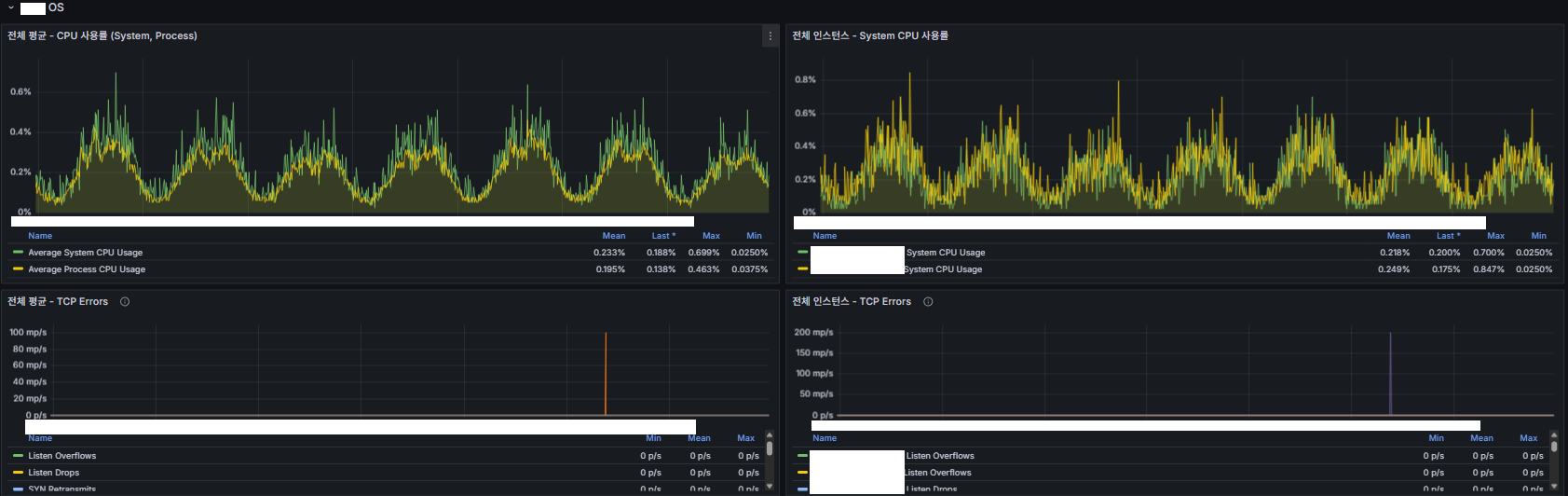
대기열 코어 서버 OS
- CPU
- TCP 오류
알림 자동화 (Teams)
- 임계치를 넘어 대기열 발생 시
- 특정 Metric 을 넘을 시 (CPU, Heap ~% 이상 유지 및 GC Duration, API 응답시간 등)
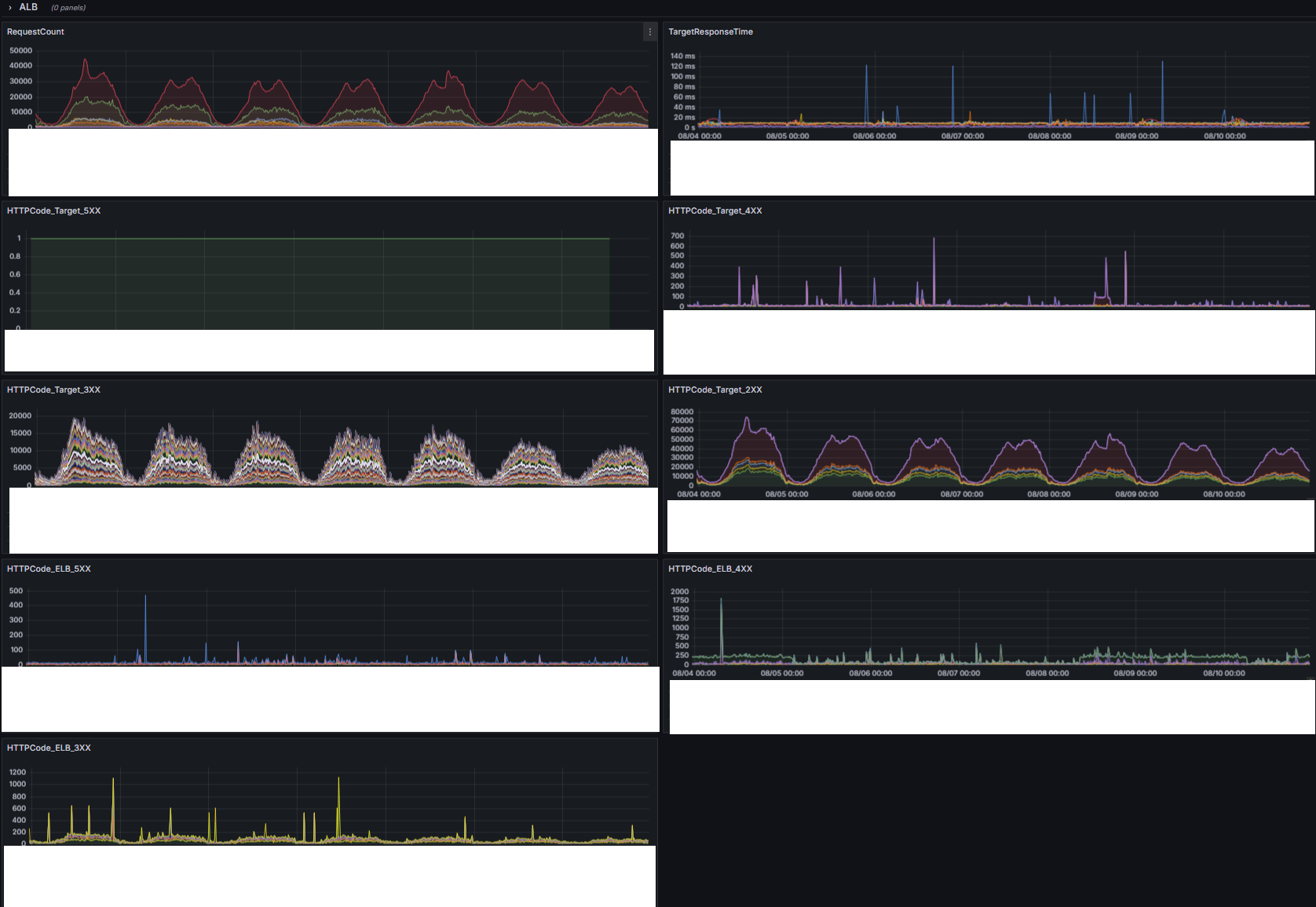
추가 작성 자료
