Background
1. Graph란?
점들과 그 점들을 잇는 선으로 이루어진 데이터 구조이다.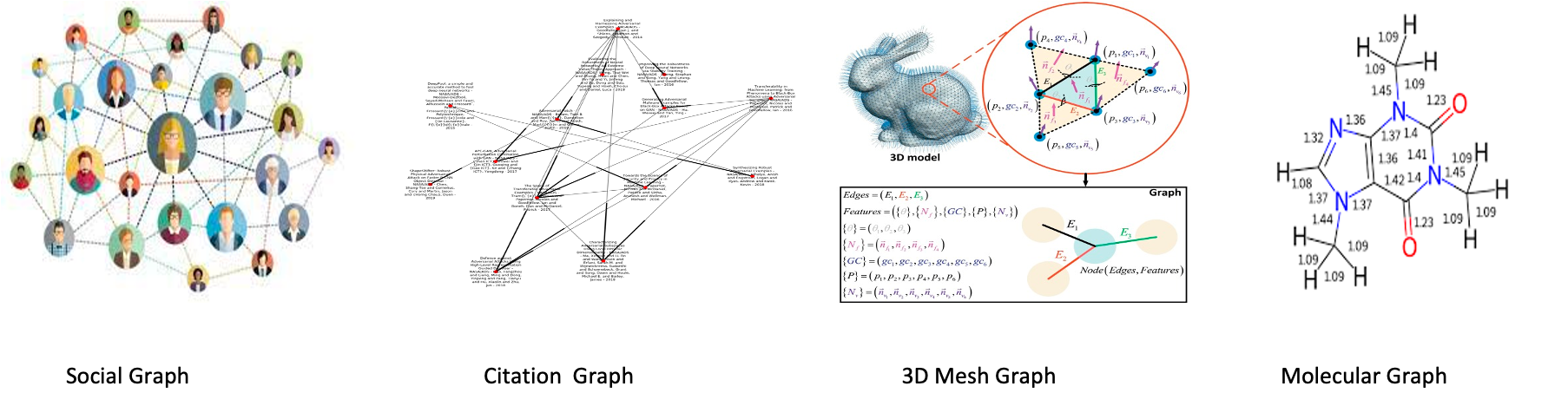 위그림과 같이 사람과 사람간의 관곌르 나타내거나, paper들 사이의 관계 3D model에서 mash들 사이의 관계 분자 구조를 나타낼 때 graph 데이터가 사용될 수 있다.
위그림과 같이 사람과 사람간의 관곌르 나타내거나, paper들 사이의 관계 3D model에서 mash들 사이의 관계 분자 구조를 나타낼 때 graph 데이터가 사용될 수 있다.
2. Graph Structure
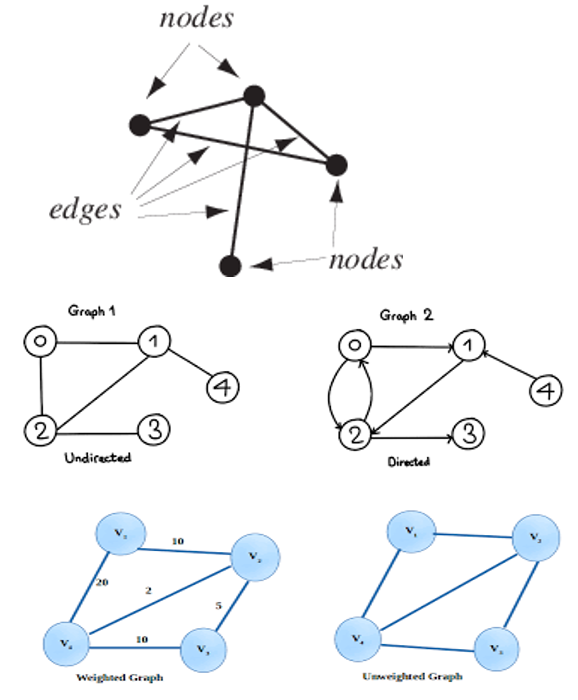
Node/Vertex라 불리는 정점, Node들 사이의 관계를 표현해주는 Edge(간선)으로 이루어져있으며 Edge는 데이터에 따라 weighted/unweighted(가중),directed/undirected(방향성)일 수 있다.
해당 graph structure를 matrix로 표현하는 방법으로는 Adjancency matrix, Degree matrix, Laplacian matrix가 있다.
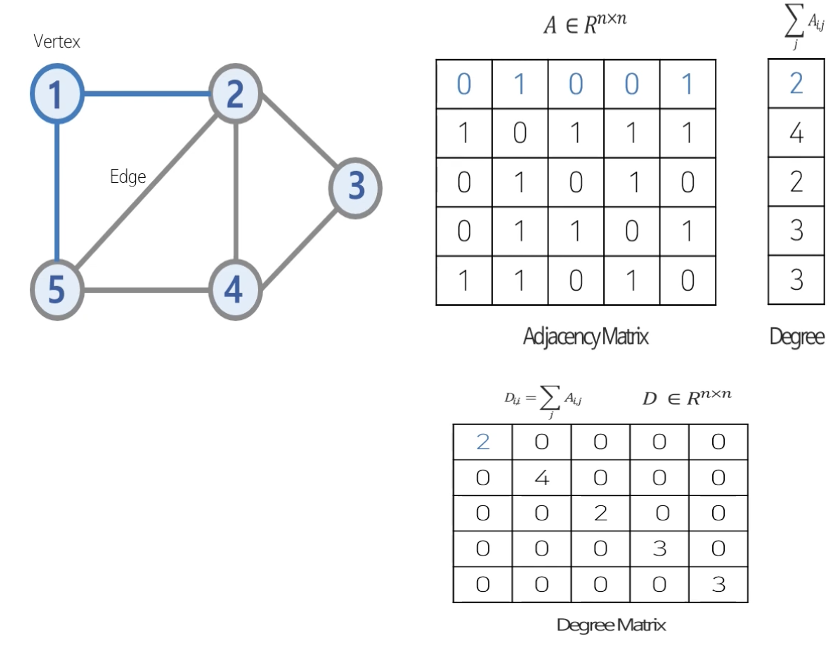
Adjacency matrix는 center node(중심 노드)와 neighbor node(이웃 노드) 사이의 edge 유무, 방향성, 가중치 등을 표현할 수 있다.
Degree matrix는 center node에 이어진 edge의 수를 표현한다.
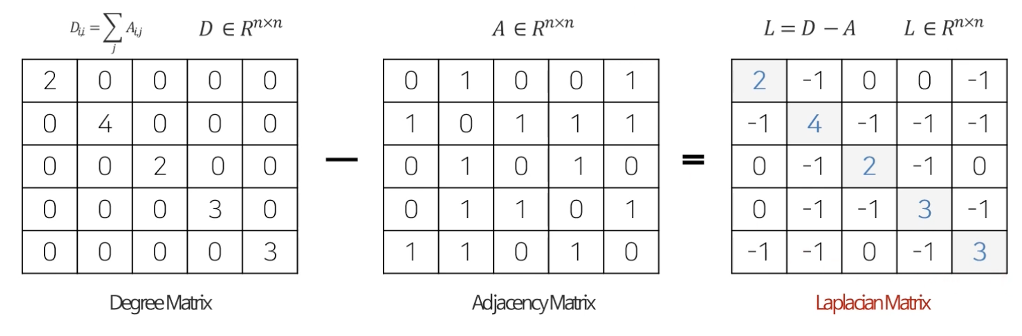
Laplacian matrix는 Adjacency matrix와 Degree matrix를 이용하여 중심 노드와 이웃노드 사이의 관계를 표현한다(D(degree matrix)-A(adjacency matrix)).
이렇게 Laplacian matrix를 표현하였을 때 아래와 같이 중심 노드와 이웃노드 사이의 관계 표현이 가능하다.

3. Convolution
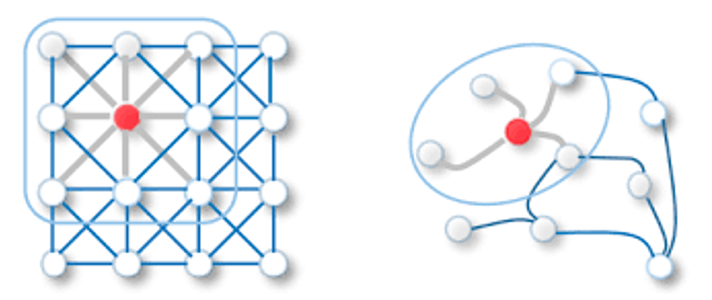
위에서 살펴봤다싶이 그래프의 특징은 이웃 노드들의 정보(edge, feature)가 중심 노드의 정보와 관계가 있다.
→ Convolution을 적용할 수 없을까? Local Feature을 뽑아내고 싶어!
일반적인 Convolution을 Graph에 적용하기 어려운 이유
그래프는 이미지와 같이 regular grid한 형태도 아닐 뿐더러 적용한다 해도 필터의 크기가 유동적이다.
→ 위 사진을 보면 이미지와 같은 regular grid형태는 이웃 노드들의 갯수가 일정하다. 그래프의 경우엔 중심 노드가 무엇이냐에 따라 이웃노드들의 갯수가 달라진다. 즉 필터의 크기가 일정하지 않다.
4. Graph Convolution
Grpah Convolution에서는 연구가 두 가지 방향으로 나뉜다.
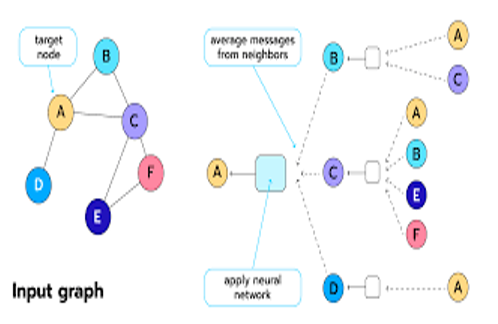
Graph Convolution을 Graph signal processing 일환으로 보는 Spectral Convolution, 중심 노드를 이웃 노드의 feature로 업데이트 하는 방식인 Spatial Convolution이 있다.
위에서 언급했다 싶이 일반적인 Convolution은 초기에 적용하기 어려웠기에 연구는 Spectral Convolution에서 Spatial Convolution으로 발전됐다.
4.1 Spectral Convolution
단순 Convolutin을 사용하기 어렵지만 Convolution의 장점을 이용하고 싶어 사용하고 싶음. 신호처리에 쓰이는 Convolution Theoremd을 가지고 온다.
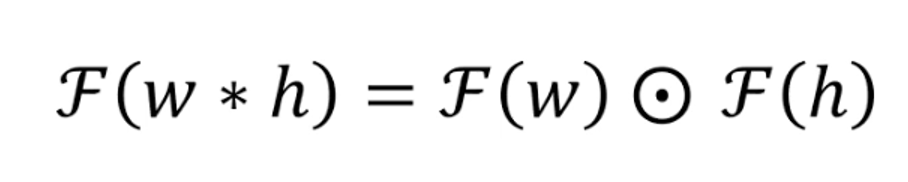
Convolution Theorem
두 개 함수의 Convolution을 푸리에 변환하는 것은 각각의 함수를 푸리에 변환하여 pointwise product 하는 것과 같다.
Fourier Transform?
- 임의의 입력 신호를 다양한 주파수를 갖는 주기함수들의 합으로 분해하여 표현하는 것
- 고주파~저주파까지 다양한 주파수 대역의 sin, cos 함수들로 분해하는 것
→ Graph에서의 Fourier Transform?
node의 feature을 신호로 보고 Frequency(feature 사이 차이)별로 분해하는 것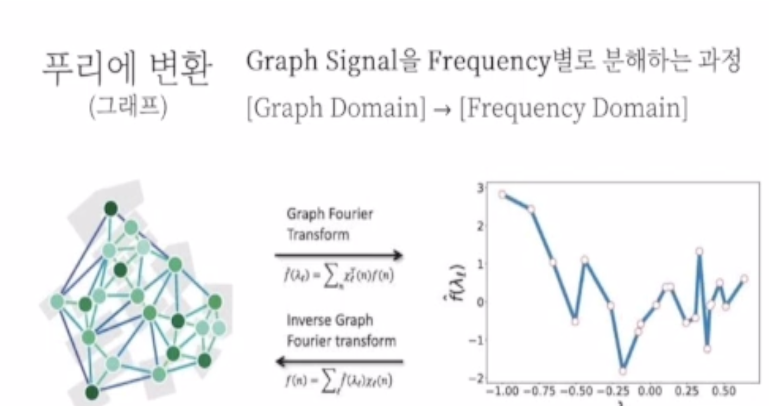
4.2 Graph Fourier Transform
- Signal: Node Featrue
- Frequency: Central node와 Neighbor node 간의 차이
Graph Fourier Transform -> Frequency가 낮은 feature들을 우선 반영하겠다. 즉 중심노드의 feature와 차이가 적은 이웃 노드들을 우선 반영하겠다는 의미이다.
위의 Fourier transform 식을 보면 convolution을 이렇게 나타낼 수 있다.
즉 featur을 푸리에 변환한 것과 weight를 푸리에 변환 한 것의 pointwise product에 푸리에 역변환을 취한 것은 featur와 weight의 convolution과 같다.
근데 참 웃기게도 이 모든것이 feature matrix에 laplacian matrix를 곱한것과 같다.
왜? laplacian matrix를 eigen decomposition을 하면 아래와 같은 식이 나온다.
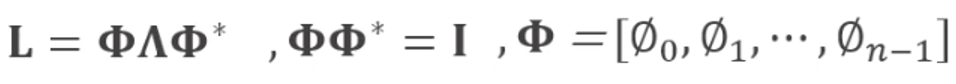 는 Fourier basis를 말한다. 즉 laplacian matrix를 곱하는 것은 feature에 푸리에 변환을 하고 역변환하는 것과 유사하다. 아래 이미지 참고. weight는 laplacian matrix의 eigen value
는 Fourier basis를 말한다. 즉 laplacian matrix를 곱하는 것은 feature에 푸리에 변환을 하고 역변환하는 것과 유사하다. 아래 이미지 참고. weight는 laplacian matrix의 eigen value

5. Spectral GCN
5.1 SPECTRAL GCN
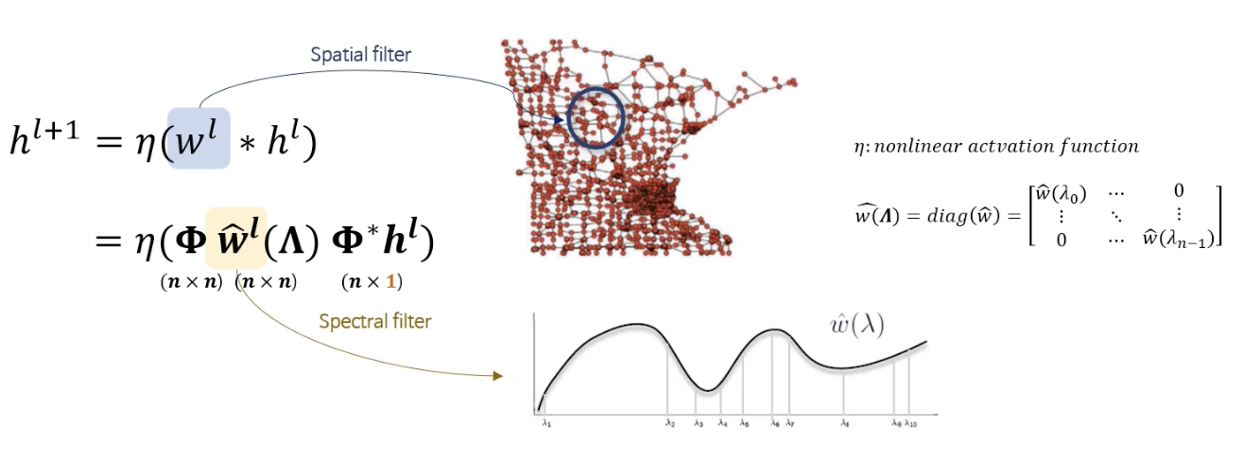 기존의 Graph Fourier Transform과 동일하다. 다음 레이어의 업데이트는 Fourier domain에서 계산된 후 Inverse Fourier Transform을 한 것에 비선형 함수를 씌워 계산된다.
기존의 Graph Fourier Transform과 동일하다. 다음 레이어의 업데이트는 Fourier domain에서 계산된 후 Inverse Fourier Transform을 한 것에 비선형 함수를 씌워 계산된다.
Limitation
-spatial filter가 특정 지역에 대한 특징을 잘 추출한다는 보장이 없다
-계산 비용이 비싸다(eigen decomposition 비용)
5.2 ChebNet
eigen decomposition의 계산 비용 문제로 나온 아이디어.



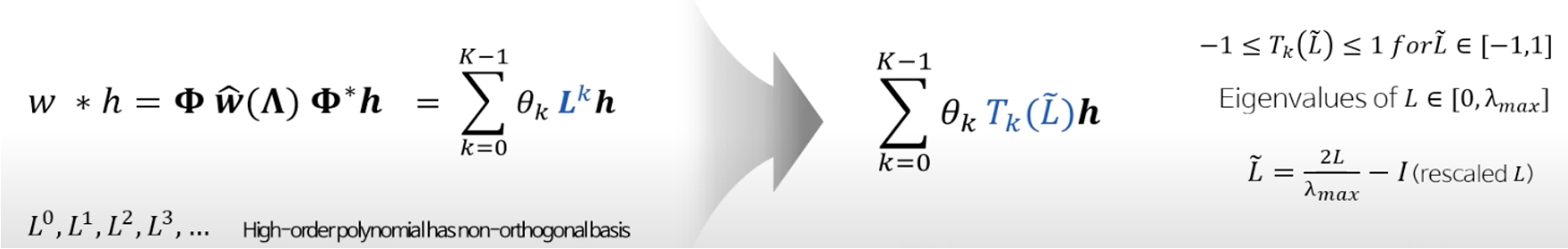
다항 근사를 시켜 eigen decomposition을 없앴다.
이 부분은 이해가 부족한 관계로 더 찾아봐야한다.
5.3 GCN(Spatial GCN)
위 식을 보면 학습 파라미터가 가 된다. k를 늘리게 되면 학습 파라미터도 많아질 뿐더러 오버피팅의 위험성이 있어 해당 논문에서는 k를 1로 고정하였다. 그리고 로 고정하였다.
(Renomalization trick)Adjancey matrix에 self connection을 추가하였다.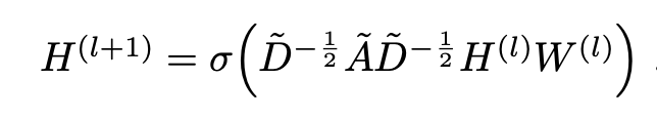
Model
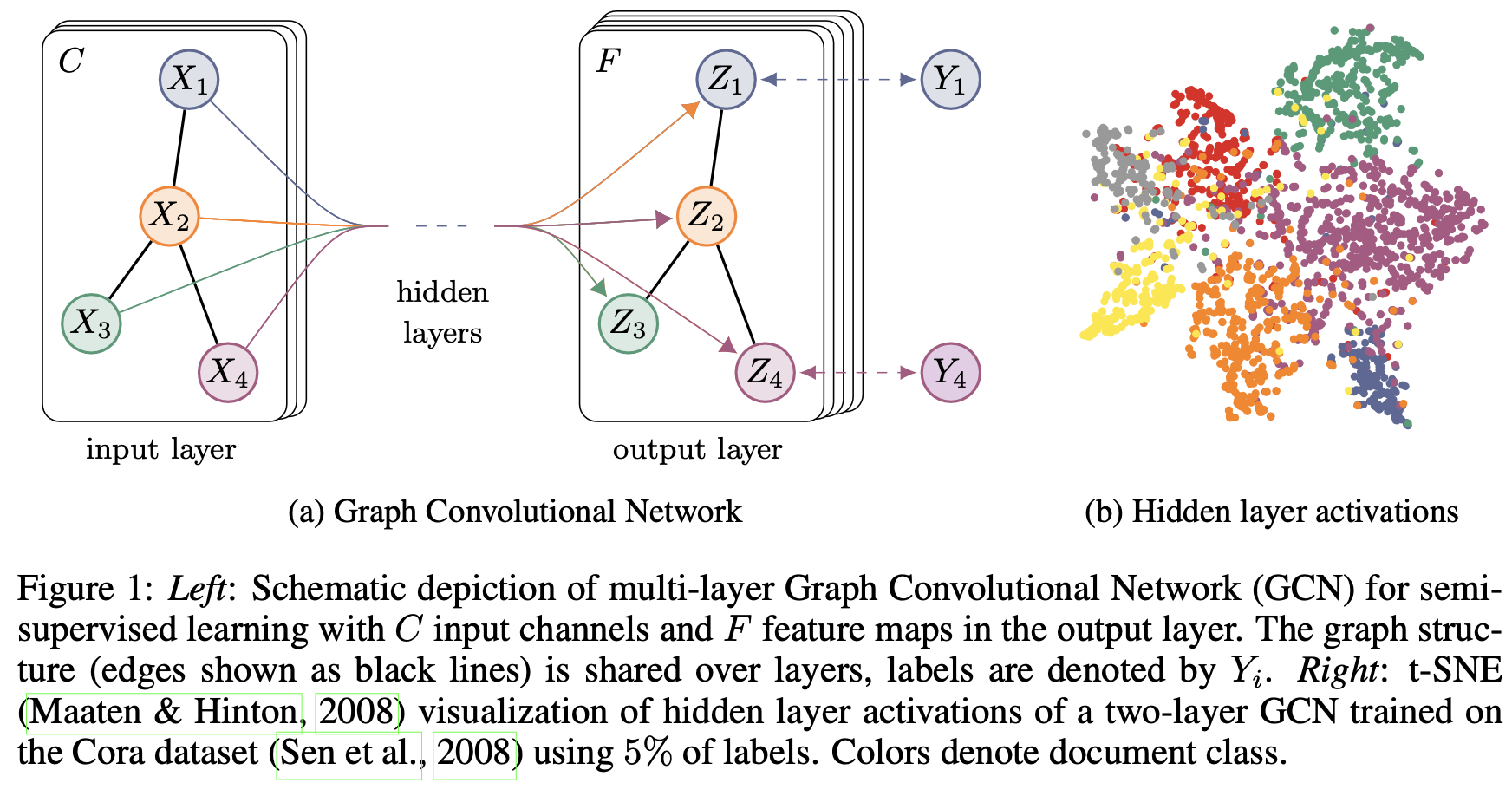
6. Experiment
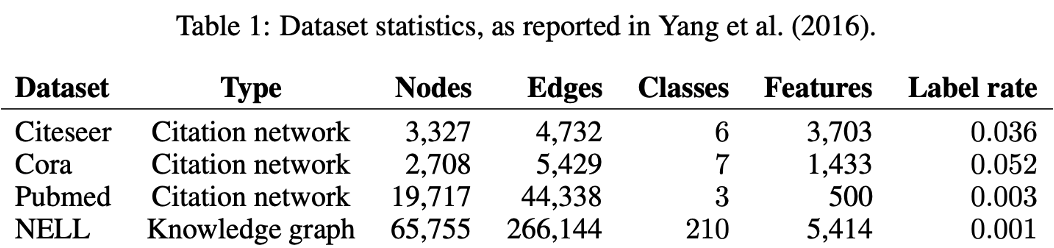
Node: Documents (논문)
Edge: 인용
Label: Node Label (어떤 종류의 논문인지에 대한 Label)
Node Feature: (Sparse) Bag of words
Label rate: 각 데이터셋에서 훈련에 활용되는 training node를 전체 노드 개수로 나눈 것
각 문서마다 Sparse한 Bag of words로 이루어진 feature vector로 구성되며, 문서들간의 Citation links를 담고 있음
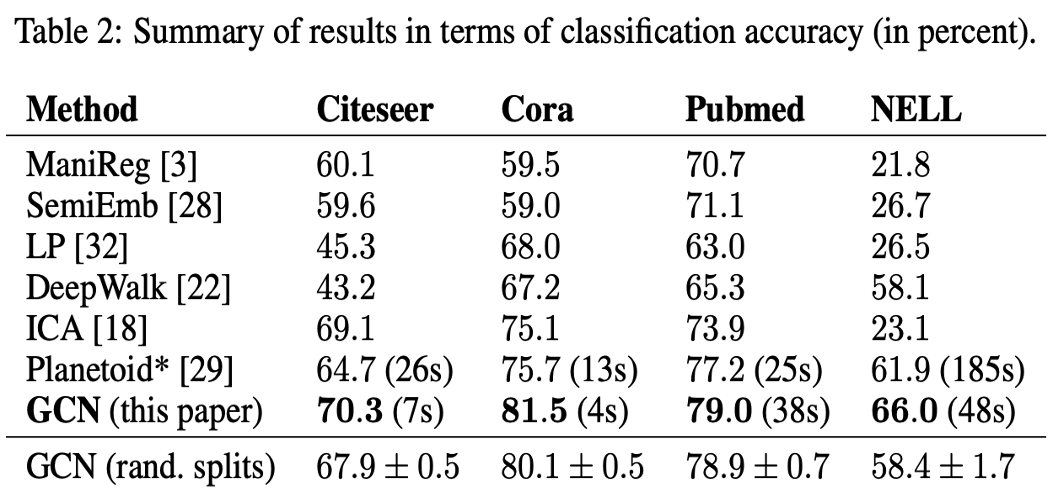

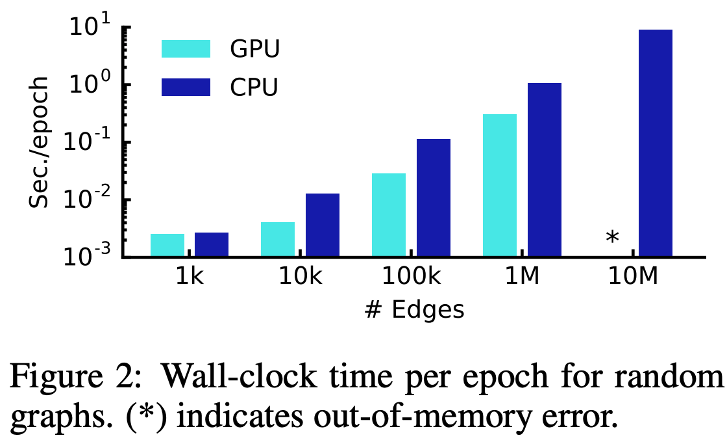
Random Graph에 대한 Epoch당 평균적인 Training Time을 보여줌
이는 Forward Pass, Cross-Entropy 계산, Backward Pass에 대한 평균을 말함
뭔가 급하게 대충 넘어간거 같아.. 보충이 필요해보인다...
